

Penapis Bloom telah dicadangkan oleh seorang lelaki tua bernama Bloom pada tahun 1970.
Ia sebenarnya boleh dilihat sebagai struktur data yang terdiri daripada vektor binari (atau tatasusunan bit) dan satu siri fungsi pemetaan rawak (fungsi cincang).
Kelebihannya ialah kecekapan ruang dan masa pertanyaan jauh lebih baik daripada algoritma biasa. Kelemahannya ialah ia mempunyai kadar salah pengiktirafan tertentu dan kesukaran pemadaman.

Jom ambil gambar dulu

Algoritma penapis Bloom Yang utama ideanya ialah menggunakan n fungsi cincang untuk melaksanakan pencincangan untuk mendapatkan nilai cincang yang berbeza, yang dipetakan kepada kedudukan indeks yang berbeza bagi tatasusunan (panjang tatasusunan ini mungkin sangat panjang) mengikut cincang, dan kemudian bit indeks yang sepadan ialah The nilai hidup ditetapkan kepada 1.
Untuk menentukan sama ada elemen muncul dalam set adalah menggunakan k fungsi cincang yang berbeza untuk mengira nilai cincang dan lihat sama ada nilai pada kedudukan indeks yang sepadan bagi nilai cincang ialah 1. Jika terdapat satu yang bukan 1 , menunjukkan bahawa elemen itu tidak wujud dalam koleksi.
Tetapi adalah mungkin untuk menilai bahawa elemen itu berada dalam set, tetapi elemen itu tidak berada di atas semua kedudukan indeks elemen ini ditetapkan oleh elemen lain, yang membawa kepada kebarangkalian salah penilaian tertentu. (inilah sebabnya perkara di atas disiarkan secara langsung Punca utama mungkin dalam koleksi, kerana akan terdapat konflik cincang tertentu).
Nota: Semakin rendah kadar positif palsu, semakin rendah prestasi yang sepadan.
Penapis Bloom boleh digunakan untuk menentukan sama ada sesuatu elemen berada (mungkin) dalam satu set, dan berbanding dengan struktur data lain, Penapis Bloom Terdapat kelebihan besar dalam kedua-dua ruang dan masa.
Perhatikan perkataan di atas: mungkin. Terdapat saspens yang dikhaskan di sini, yang akan dianalisis secara terperinci di bawah.
Hakim sama ada data yang diberikan wujud
Halang penembusan cache (nilai sama ada data yang diminta adalah sah untuk mengelakkan terus memintas cache untuk meminta pangkalan data), dsb., penapisan spam peti mel, fungsi senarai hitam , dsb. tunggu.
Selepas membaca idea algoritma penapis Bloom, mari mulakan untuk menerangkan pelaksanaan khusus.
Mula-mula saya berikan contoh Katakan terdapat dua rentetan, Wangcai dan Xiaoqiang masing-masing telah dicincang tiga kali, dan kemudian indeks tatasusunan yang sepadan (dengan mengandaikan panjang tatasusunan ialah 16) dikira berdasarkan. pada hasil cincang. Nilai kedudukan ditetapkan kepada 1. Mari kita lihat frasa Wangcai dahulu:
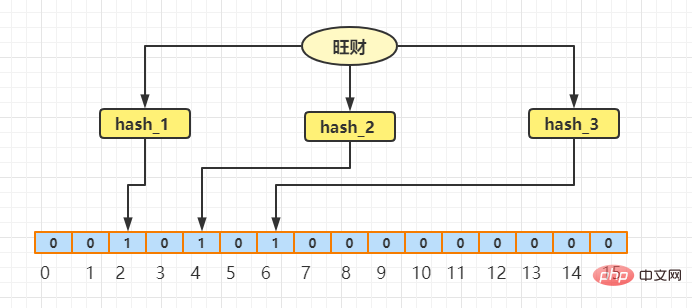
Selepas tiga cincang Wangcai, nilainya ialah 2 , 4, dan 6 masing-masing Kemudian kita boleh mendapatkan Nilai indeks masing-masing adalah 2, 4, dan 6, jadi nilai indeks (2, 4, 6) kedudukan tatasusunan ditetapkan kepada 1, dan selebihnya. dianggap sebagai 0. Sekarang andaikan anda perlu mencari Wangcai, dan juga melalui ketiga-tiga cincang ini dan kemudian Didapati bahawa nilai-nilai kedudukan yang sepadan dengan indeks 2, 4, dan 6 adalah semuanya 1, maka ia boleh dinilai bahawa kekayaan yang makmur mungkin wujud.
Kemudian masukkan Xiaoqiang ke dalam penapis Bloom Proses sebenar adalah sama seperti di atas. Anggapkan bahawa subskrip yang diperolehi ialah 1, 3, 5
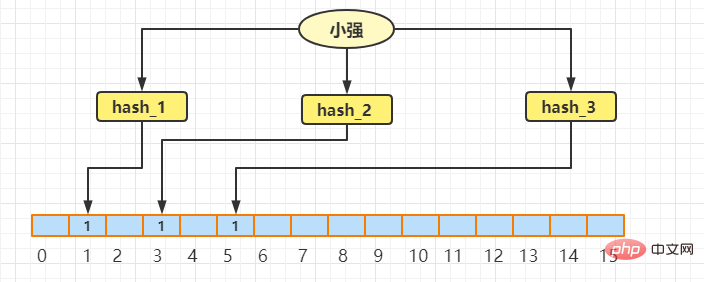
Meletakkan. mengetepikan kewujudan Wangcai, Xiaoqiang kelihatan seperti ini dalam penapis Bloom pada masa ini Menggabungkan tatasusunan Wangcai dan Xiaoqiang yang sebenar kelihatan seperti ini:

Kini terdapat data: 9527. . Ternyata nilai kedudukan dengan subskrip 7 adalah 0, jadi ia pasti boleh dinilai bahawa 9527 mesti tidak wujud.
Kemudian 007 domestik lain datang Selepas tiga cincang, subskrip yang diperolehi ialah: 2, 3, 5. Didapati bahawa nilai yang sepadan dengan subskrip 2, 3, dan 5 semuanya adalah 1, jadi. ia boleh secara kasar Ia dinilai bahawa domestik 007 mungkin wujud. Tetapi sebenarnya, selepas demonstrasi kami tadi, domestik 007 tidak wujud sama sekali Sebab mengapa nilai kedudukan indeks 2, 3, dan 5 adalah 1 adalah kerana tetapan data lain.
Setelah berkata ini, saya tertanya-tanya sama ada semua orang memahami peranan penapis Bloom.
Sebagai pengaturcara Java, kami sangat gembira menggunakan banyak rangka kerja dan alatan, dan ia pada dasarnya dirangkumkan dalam penapis Bloom , kami akan menggunakan kelas alat yang dibungkus oleh Google . Sudah tentu ada kaedah lain yang boleh anda terokai.
Tambah kebergantungan pertama
<!--布隆过滤依赖-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>25.1-jre</version>
</dependency>Pelaksanaan kod
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import java.nio.charset.Charset;
public class BloomFilterDemo {
public static void main(String[] args) {
/**
* 创建一个插入对象为一亿,误报率为0.01%的布隆过滤器
* 不存在一定不存在
* 存在不一定存在
* ----------------
* Funnel 对象:预估的元素个数,误判率
* mightContain :方法判断元素是否存在
*/
BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf-8")), 100000000, 0.0001);
bloomFilter.put("死");
bloomFilter.put("磕");
bloomFilter.put("Redis");
System.out.println(bloomFilter.mightContain("Redis"));
System.out.println(bloomFilter.mightContain("Java"));
}
}Penjelasan khusus telah ditulis dalam ulasan. Sekarang saya percaya semua orang mesti memahami penapis Bloom dan cara menggunakannya.
Mari kita simulasi senario ini: menyelesaikan penembusan cache melalui penapis bloom.
Pertama sekali, adakah anda tahu apa itu penembusan cache?
Penembusan cache bermakna pengguna mengakses data yang tiada dalam cache mahupun dalam pangkalan data Kerana ia tidak wujud dalam cache, ia akan mengakses pangkalan data jika konkurensi tinggi. Mudah untuk mengalahkan pangkalan data
Jadi bagaimana penapis Bloom menyelesaikan masalah ini? Dia
的原理是这样子的:将数据库中所有的查询条件,放入布隆过滤器中,当一个查询请求过来时,先经过布隆过滤器进行查,如果判断请求查询值存在,则继续查;如果判断请求查询不存在,直接丢弃。
其代码如下:
String get(String key) {
String value = redis.get(key);
if (value == null) {
if(!bloomfilter.mightContain(key)){
return null;
}else{
value = db.get(key);
redis.set(key, value);
}
}
return value;
}Atas ialah kandungan terperinci Bagaimana untuk menentukan dengan cepat sama ada elemen berada dalam koleksi di java. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



