

Pengarang |
AbstrakPeningkatan teknologi revolusioner, keluaran ChatGPT 4.0 mengejutkan seluruh AI industri. Kini, bukan sahaja komputer boleh mengenali dan menjawab soalan bahasa semula jadi setiap hari, ChatGPT juga boleh menyediakan penyelesaian yang lebih tepat dengan memodelkan data industri. Artikel ini akan memberi anda pemahaman yang mendalam tentang prinsip seni bina ChatGPT dan prospek pembangunannya. Ia juga akan memperkenalkan cara menggunakan API ChatGPT untuk melatih data industri. Marilah kita meneroka bidang baharu dan menjanjikan ini bersama-sama dan mencipta era baharu AI.
Pengeluaran ChatGPT 4.0ChatGPT 4.0 telah dikeluarkan secara rasmi! Versi ChatGPT ini memperkenalkan inovasi yang pesat Berbanding dengan ChatGPT 3.5 sebelumnya, ia telah meningkatkan prestasi dan kelajuan model . Sebelum keluaran ChatGPT 4.0, ramai orang telah memberi perhatian kepada ChatGPT dan menyedari kepentingannya dalam bidang pemprosesan bahasa semula jadi. Walau bagaimanapun, dalam versi 3.5
dan sebelumnya, had ChatGPT masih wujud kerana data latihannya tertumpu terutamanya dalam domain umum Dalam model bahasa, sukar untuk menjana kandungan yang berkaitan dengan industri tertentu. Walau bagaimanapun, dengan keluaran ChatGPT 4.0, semakin ramai orang telah mula menggunakannya untuk melatih data industri mereka sendiri, dan ia telah digunakan secara meluas dalam pelbagai industri. Ini membuatkan semakin ramai orang memberi perhatian kepada ChatGPT. Seterusnya, saya akan memperkenalkan kepada anda prinsip seni bina, prospek pembangunan dan aplikasi ChatGPT dalam data industri latihan. Keupayaan ChatGPTCtGPT Seni bina adalah berdasarkan rangkaian neural pembelajaran mendalam, yang merupakan teknologi pemprosesan bahasa semulajadi Prinsipnya ialah menggunakan model bahasa berskala besar yang telah dilatih untuk menjana teks, supaya mesin boleh memahami dan menjana bahasa semula jadi. Prinsip model ChatGPT adalah berdasarkan rangkaian Transformer, yang dilatih menggunakan teknologi pemodelan bahasa tanpa pengawasan untuk meramalkan taburan kebarangkalian perkataan seterusnya menjana teks berterusan. Parameter yang digunakan termasuk bilangan lapisan rangkaian, bilangan neuron dalam setiap lapisan, kebarangkalian Keciciran, Saiz Kelompok, dsb. Skop pembelajaran melibatkan model bahasa umum dan model bahasa khusus domain. Model umum domain boleh digunakan untuk menjana pelbagai teks, manakala model khusus domain boleh diperhalusi dan dioptimumkan untuk tugasan tertentu.
OpenAI menggunakan data teks besar-besaran sebagai data latihan untuk GPT-3. Khususnya, mereka menggunakan lebih daripada 45TB data teks bahasa Inggeris dan beberapa data bahasa lain, termasuk teks web, e-buku, ensiklopedia, Wikipedia, forum, blog, dsb. Mereka juga menggunakan beberapa set data yang sangat besar seperti Common Crawl, WebText, BooksCorpus, dll. Set data ini mengandungi trilion perkataan dan berbilion ayat yang berbeza, memberikan maklumat yang sangat kaya untuk latihan model. Memandangkan anda perlu mempelajari begitu banyak kandungan, kuasa pengkomputeran yang digunakan juga besar.
ChatGPT menggunakan banyak kuasa pengkomputeran dan memerlukan banyak sumber GPU untuk latihan. Menurut laporan teknikal oleh OpenAI pada 2020, GPT-3 menggunakan kira-kira 17.5 bilion parameter dan 28,500 pemproses TPU v3 semasa latihan.
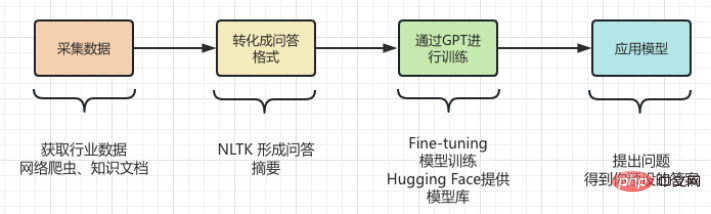
Daripada pengenalan di atas , kita tahu bahawa ChatGPT mempunyai keupayaan yang hebat , dan juga memerlukan pengiraan yang besar dan penggunaan sumber, latihan ini Besar model bahasa memerlukan kos yang tinggi. Tetapi alat AIGC yang dihasilkan pada kos yang begitu tinggi sebenarnya wujud Its Keterbatasan, Ia tidak mempunyai pengetahuan dalam beberapa bidang profesional Sertai. Contohnya, apabila ia berkaitan dengan bidang profesional seperti perubatan atau undang-undang, ChatGPT tidak dapat menjana jawapan yang tepat. Ini kerana data pembelajaran ChatGPT datang daripada korpus am di Internet, dan data ini tidak termasuk istilah dan pengetahuan profesional dalam bidang tertentu tertentu. Oleh itu, jika anda mahu ChatGPT mempunyai prestasi yang lebih baik dalam bidang profesional tertentu, anda perlu menggunakan korpora profesional dalam bidang itu untuk latihan, iaitu, gunakan korpus profesional pakar dalam bidang profesional. Walau bagaimanapun, ChatGPT tidak mengecewakan kami. Jika menggunakan ChatGPT pada industri tertentu, anda perlu mengekstrak data profesional industri itu terlebih dahulu dan melakukan prapemprosesan. Khususnya, satu siri proses seperti pembersihan, penyahduplikasian, pembahagian dan pelabelan data perlu dilakukan. Selepas itu, data yang diproses diformat dan ditukar kepada format data yang memenuhi keperluan input model ChatGPT. Kemudian, anda boleh menggunakan antara muka API ChatGPT untuk memasukkan data yang diproses ke dalam model untuk latihan. Masa dan kos latihan bergantung pada jumlah data dan kuasa pengkomputeran. Selepas latihan selesai, model boleh digunakan pada senario sebenar untuk menjawab soalan pengguna.
Gunakan ChatGPT untuk melatih pengetahuan domain profesional! Sebenarnya, tidak sukar untuk mewujudkan pangkalan pengetahuan dalam bidang profesional Operasi khusus<.>
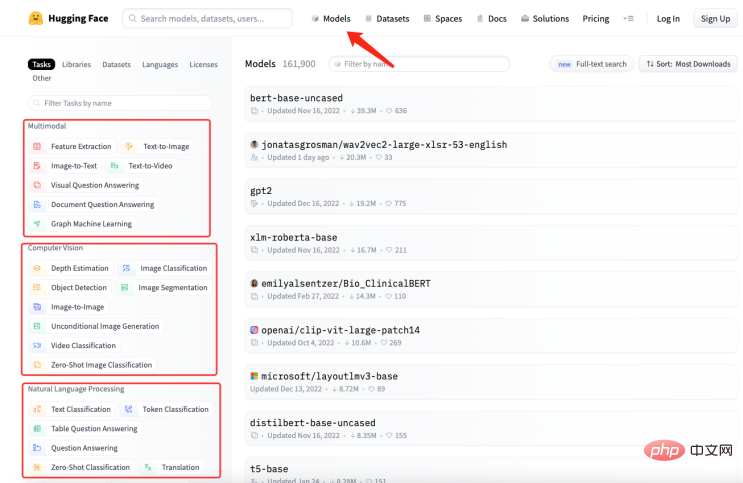
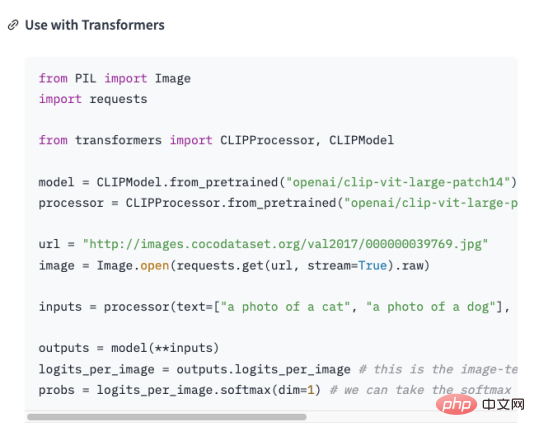
Iaitu untuk menukar data industri ke dalam format soal jawab , dan kemudian Modelkan format soalan dan jawapan melalui teknologi Pemprosesan Bahasa Asli (NLP) untuk menjawab soalan. Gunakan OpenAI GPT-3 API (dengan GPT3 sebagai contoh) Anda boleh mencipta model soal jawab yang hanya menyediakan beberapa contoh dan ia boleh menjana jawapan berdasarkan soalan yang anda berikan. Langkah kasar untuk mencipta model soal jawab menggunakan API GPT-3 adalah seperti berikut: , yang menyediakan pelbagai jenis pelan langganan API, termasuk pelan Pembangun, Pengeluaran dan Tersuai. Setiap pelan menawarkan ciri yang berbeza dan akses API, dan datang pada harga yang berbeza. Oleh kerana bukan fokus artikel ini, saya tidak akan huraikan di sini. Buat set dataDari langkah di atas, penukaran 2 langkah ke dalam format Soal Jawab merupakan satu cabaran bagi kami. Anggapkan bahawa mempunyai Pengetahuan domain tentang sejarah kecerdasan buatan perlu diajar kepada GPT, Dan ubah pengetahuan ini menjadi model yang menjawab soalan yang berkaitan. Kemudian ia mesti ditukar kepada bentuk berikut : Sudah tentu tidak cukup untuk menyusunnya ke dalam format soal jawab Ia perlu dalam format yang boleh difahami oleh GPT, seperti yang ditunjukkan di bawah: Malah, "nn" ditambah selepas soalan , dan menambah “n selepas jawapan ”. Menyelesaikan masalah format soalan dan jawapan, Soalan baharu datang lagi, bagaimana kita menyusun pengetahuan industri ke dalam format soalan dan jawapan ? Dalam kebanyakan kes, kami merangkak banyak pengetahuan domain daripada Internet, atau mencari banyak dokumen domain dalam mana-mana kes, memasukkan dokumen adalah yang paling mudah untuk kami. Walau bagaimanapun, jelas tidak realistik untuk menggunakan ungkapan biasa atau kaedah manual untuk memproses sejumlah besar teks ke dalam format soalan dan jawapan. Oleh itu, adalah perlu untuk memperkenalkan kaedah yang dipanggil Teknologi ringkasan automatik boleh mengekstrak maklumat utama daripada artikel dan menjana ringkasan ringkas. Terdapat dua jenis ringkasan automatik: ringkasan automatik ekstraktif dan ringkasan automatik generatif. Ringkasan automatik ekstraktif mengekstrak ayat yang paling mewakili daripada teks asal untuk menghasilkan ringkasan, manakala ringkasan automatik generatif mengekstrak maklumat penting daripada teks asal melalui pembelajaran model dan menjana ringkasan berdasarkan maklumat ini. Malah, Ringkasan automatik adalah untuk menjana mod soalan dan jawapan daripada teks input. Selepas masalah dijelaskan, langkah seterusnya ialah memasang alatan kami menggunakan NLTK untuk melakukan sesuatu, NLTK Ia adalah singkatan dari Natural Language Toolkit dan merupakan perpustakaan Python yang digunakan terutamanya dalam bidang pemprosesan bahasa semula jadi. Ia termasuk pelbagai alatan dan perpustakaan untuk memproses bahasa semula jadi, seperti prapemprosesan teks, penandaan sebahagian daripada pertuturan, pengecaman entiti bernama, analisis sintaks, analisis sentimen, dsb. Kami hanya perlu menyerahkan teks kepada NLTK, yang akan melaksanakan operasi prapemprosesan data pada teks . Termasuk penyingkiran kata henti, pembahagian perkataan, penandaan sebahagian daripada pertuturan, dsb. Selepas prapemprosesan, modul penjanaan ringkasan teks dalam NLTK boleh digunakan untuk menjana ringkasan. Anda boleh memilih algoritma yang berbeza, seperti berdasarkan kekerapan perkataan, berdasarkan TF-IDF, dsb. Semasa menjana ringkasan, templat soalan boleh digabungkan untuk menghasilkan ringkasan soalan dan jawapan, menjadikan ringkasan yang dijana lebih mudah dibaca dan difahami. Pada masa yang sama, rumusan juga boleh diperhalusi, seperti ayat yang tidak koheren, jawapan yang tidak tepat dan sebagainya boleh dilaraskan. Lihat kod berikut: daripada transformer import AutoTokenizer, AutoModelForSeq2SeqLM, saluran paip import nltk # Masukkan teks text = """Natural Language Toolkit (NLTK) ialah satu set perpustakaan Python yang digunakan untuk menyelesaikan masalah pemprosesan data bahasa manusia, seperti: Participle penandaan POS Analisis sintaksis Analisis Sentimen Analisis semantik Pengecaman Pertuturan Penjanaan teks dan banyak lagi """ # Jana ringkasan ayat = nltk.sent_tokenize(text) summary = " ".join(ayat[:2]) # Ambil dua ayat pertama sebagai ringkasan print("ringkasan:", ringkasan) # Gunakan ringkasan yang dijana untuk Fine-tuning, dapatkan modelnya tokenizer = AutoTokenizer.from_pretrained("t5- asas") model = AutoModelForSeq2SeqLM. from_pretrained("t5-base") text = "summarize: " + summary # Bina format input input = tokenizer(text, return_tensors="pt", padding=True) # Model latihan model_name = "first-model" model.save_pretrained(model_name) # Model ujian qa = saluran paip("menjawab soalan", model=model_name, tokenizer=model_name) context = "Untuk apa NLTK digunakan?" # Soalan untuk dijawab jawapan = qa(questinotallow=context , cnotallow=text["input_ids"]) print("Soalan:", konteks) print("Jawapan:", jawab["jawapan"]) Keputusan output adalah seperti berikut: 摘要: Natural Language Toolkit(自然语言处理工具包,缩写 NLTK)是一套Python库,用于解决人类语言数据的处理问题,例如: - 分词 - 词性标注 问题: NLTK用来做什么的? 答案:自然语言处理工具包 Kod di atas menggunakan kaedah nltk.sent_tokenize untuk mengekstrak ringkasan teks input, iaitu, untuk memformat soalan dan jawapan. Kemudian , memanggil Fkaedah AutoModelForSeq2SeqLM.from_pretrained ine-tuning memodelkannya, dan kemudian akan dinamakan "model pertama" Model disimpan . Akhir sekali, hubungi model terlatih untuk menguji keputusan. Di atas bukan sahaja lulus NLTK menjana ringkasan soalan dan jawapan, dan anda juga perlu menggunakan Fine-tfungsi uning. Fine-tuning adalah berdasarkan model pra-latihan dan memperhalusi model melalui sejumlah kecil data berlabel untuk menyesuaikan diri dengan tugasan khusus . Sebenarnya ialah menggunakan model asal untuk memasang data anda bagi membentuk model anda juga hasil model Contohnya, tetapan dan parameter lapisan tersembunyi, dsb. Di sini kita hanya menggunakan fungsinya yang paling mudah , Anda boleh mengetahui lebih lanjut tentang Fine-tuning melalui gambar di bawah. Apa yang perlu dijelaskan ialah : Kelas AutoModelForSeq2SeqLM, memuatkan Tokenizer dan model daripada model "t5-base" yang telah dilatih. AutoTokenizer ialah kelas dalam perpustakaan Hugging Face Transformers yang boleh memilih dan Memuatkan Tokenizer. Tokenizer digunakan untuk mengekod teks input ke dalam format yang model boleh fahami untuk input model seterusnya. AutoModelForSeq2SeqLM juga merupakan kelas dalam pustaka Hugging Face Transformers yang boleh memilih dan memuatkan urutan yang sesuai secara automatik berdasarkan model pra-latihan kepada model jujukan. Di sini, model jujukan ke jujukan berdasarkan seni bina T5 digunakan untuk tugasan seperti ringkasan atau terjemahan. Selepas memuatkan model pra-latihan, anda boleh menggunakan model ini untuk menyelaraskan atau menjana output berkaitan tugas. Apakah hubungan antara Penalaan Halus dan Wajah Memeluk? Kami menerangkan kod pemodelan di atas, yang melibatkan Fine penalaan dan Berpeluk Bahagian Muka mungkin berbunyi mengelirukan. Berikut ialah contoh untuk membantu anda memahami. Andaikan anda mahu memasak, walaupun Anda sudah ada bahan-bahannya (pengetahuan industri), tetapi tidak tahu cara membuatnya. Jadi anda minta rakan chef anda untuk mendapatkan nasihat, dan anda beritahu dia bahan apa yang anda ada (pengetahuan industri) dan hidangan apa yang anda mahu untuk memasak (soalan yang diselesaikan), rakan anda berdasarkan pengalaman dan pengetahuannya (model umum) memberi anda Berikan beberapa cadangan, prosesnya adalahFi- talaan (Letakkan pengetahuan industri ke dalam model umum untuk latihan). Anda pengalaman dan pengetahuan rakan anda ialah Model pra-latihan, Anda perlu memasukkan pengetahuan industri dan masalah yang perlu diselesaikan, dan menggunakan Model model pra-latihan, Sudah tentu, anda boleh memperhalusi model ini, seperti kandungan bahan perasa dan bahang masakan Tujuannya adalah untuk menyelesaikan masalah industri anda. Dan Memeluk Muka ialah gudang resipi ("t5-base" dalam kod ialah recipe) , yang mengandungi banyak resipi (model) yang ditentukan, seperti: daging babi cincang berperisa ikan, ayam Kung Pao dan hirisan daging babi rebus. Resipi siap ini boleh digunakan untuk mencipta resipi kami berdasarkan bahan yang kami sediakan dan hidangan yang perlu kami masak. Kami hanya perlu menyesuaikan resipi ini dan melatihnya, dan ia akan menjadi resipi kami sendiri. Mulai sekarang, kita boleh menggunakan resipi kita sendiri untuk memasak (menyelesaikan masalah industri). Bagaimana untuk memilih model yang sesuai dengan anda? Anda boleh mencari model yang anda perlukan dalam perpustakaan model Hugging Face. Seperti yang ditunjukkan dalam rajah di bawah, di laman web rasmi Hugging Face, klik "Model" untuk melihat klasifikasi model, dan anda juga boleh menggunakan kotak carian untuk mencari nama model. Seperti yang ditunjukkan dalam rajah di bawah, setiap halaman model akan memberikan penerangan tentang model, contoh penggunaan, pautan muat turun berat pra-latihan dan maklumat lain yang berkaitan. Di sini kami akan membimbing anda melalui proses mengumpul, mengubah, melatih dan menggunakan keseluruhan pengetahuan industri. Seperti yang ditunjukkan dalam rajah di bawah: Cui Hao, editor komuniti 51CTO dan arkitek kanan, mempunyai 18 tahun pengalaman pembangunan perisian dan seni bina serta 10 tahun pengalaman seni bina yang diedarkan. 
Sejarah Kepintaran Buatan Apakah itu? nnKecerdasan buatan berasal pada tahun 1950-an dan merupakan cabang sains komputer yang bertujuan untuk mengkaji bagaimana membolehkan komputer berfikir dan bertindak seperti manusia. n
Model yang cepat menjana format soalan dan jawapan
Abstrak: Natural Language Toolkit (NLTK) ialah satu set perpustakaan Python yang digunakan untuk menyelesaikan masalah pemprosesan data bahasa manusia, seperti: - Pembahagian perkataan - Penandaan sebahagian daripada pertuturan
Soalan: NLTKUntuk apa ia digunakan? Jawapan: Alat Pemprosesan Bahasa Asli
-
Ringkasan
Pengenalan kepada pengarang
Atas ialah kandungan terperinci Seorang veteran IT selama 20 tahun berkongsi cara menggunakan ChatGPT untuk mencipta pengetahuan domain. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Aplikasi kecerdasan buatan dalam kehidupan
Aplikasi kecerdasan buatan dalam kehidupan
 Pendaftaran ChatGPT
Pendaftaran ChatGPT
 Ensiklopedia ChatGPT percuma domestik
Ensiklopedia ChatGPT percuma domestik
 Apakah konsep asas kecerdasan buatan
Apakah konsep asas kecerdasan buatan
 Bagaimana untuk memasang chatgpt pada telefon bimbit
Bagaimana untuk memasang chatgpt pada telefon bimbit
 Bolehkah chatgpt digunakan di China?
Bolehkah chatgpt digunakan di China?
 Bagaimana untuk mendapatkan data dalam html
Bagaimana untuk mendapatkan data dalam html
 Apakah yang perlu saya lakukan jika pemacu C saya bertukar merah?
Apakah yang perlu saya lakukan jika pemacu C saya bertukar merah?
 Penyelesaian kepada kejayaan java dan kegagalan javac
Penyelesaian kepada kejayaan java dan kegagalan javac








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



