

Dalam artikel ini, kita akan mempelajari lebih lanjut tentang prinsip asas HTTP dan memahami perkara yang berlaku antara menaip URL dalam penyemak imbas dan mendapatkan kandungan halaman web. Memahami kandungan ini akan membantu kami memahami lebih lanjut prinsip asas perangkak.
Di sini kita mula-mula belajar tentang URI dan URL Nama penuh URI ialah Uniform Resource Identifier, iaitu pengecam sumber bersatu Nama penuh URL ialah Universal Resource Locator , yang merupakan sumber bersatu.
URL ialah subset URI, yang bermaksud setiap URL ialah URI, tetapi bukan setiap URI ialah URL. Jadi, apakah jenis URI yang bukan URL juga termasuk subkelas yang dipanggil URN, yang bermaksud Nama Sumber Sejagat. URN hanya menamakan sumber tanpa menyatakan cara untuk mencari sumber Contohnya, urn:isbn:0451450523 menentukan ISBN buku, yang boleh mengenal pasti buku secara unik, tetapi tidak menyatakan tempat untuk mencari buku. Hubungan antara URL, URN dan URI.
Tetapi dalam Internet semasa, URN jarang digunakan, jadi hampir semua URI adalah URL umum boleh dipanggil URL atau URI secara peribadi saya menggunakannya sebagai URL.
Seterusnya, mari kita pelajari tentang satu lagi konsep - hiperteks, nama Inggerisnya hiperteks, tapak web yang kita lihat dalam penyemak imbas
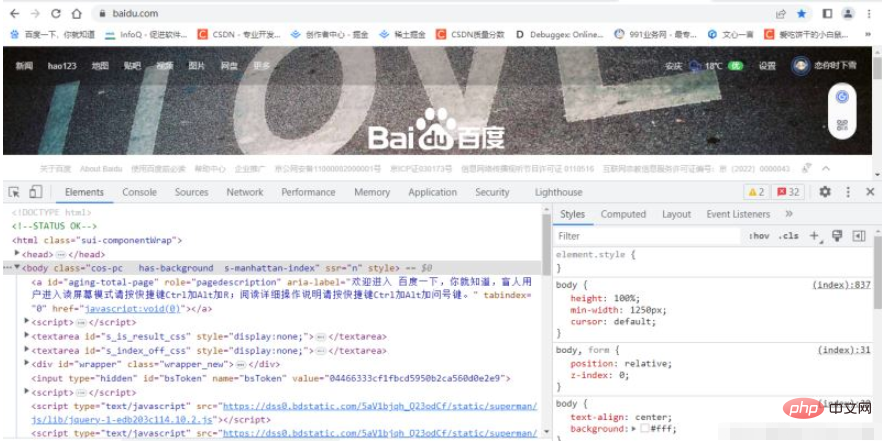
Halaman dihuraikan oleh hiperteks dan sumbernya kod ialah satu siri kod HTML, yang mengandungi satu siri - tag, seperti img untuk memaparkan gambar, p untuk menentukan perenggan, dsb. Selepas pelayar menghuraikan teg ini, ia membentuk halaman web yang biasa kita lihat, dan kod sumber HTML halaman web boleh dipanggil hiperteks.
(atau terus tekan kekunci pintasan F12). alat pembangun penyemak imbas, dan kemudian anda boleh melihat kod sumber halaman web
semasa dalam tab Elemen Kod sumber ini semuanya hiperteks, seperti yang ditunjukkan dalam rajah.
saluran yang bertujuan untuk keselamatan, ia adalah versi HTTP yang selamat, iaitu menambah SSL lapisan di bawah HTTP, dirujuk sebagai HTTPS.
kepada dua jenis.
Proses permintaan HTTP
- Apple mewajibkan semua ioS All apl mesti menggunakan penyulitan HTTPS sebelum 1 Januari 2017, jika tidak, apl itu tidak akan disenaraikan di gedung aplikasi.
- Bermula dari Chrome 56, dilancarkan pada Januari 2017, Google telah memaparkan amaran risiko untuk pautan URL yang tidak disulitkan HTTPS, iaitu, mengingatkan pengguna dalam kedudukan yang menonjol dalam bar alamat bahawa "Halaman web ini tidak dibenarkan" .
- Dokumen keperluan rasmi Tencent WeChat Mini Program memerlukan latar belakang menggunakan permintaan HTTPS untuk komunikasi rangkaian dan nama domain yang tidak memenuhi syarat tidak boleh diminta.
Kami memasukkan URL dalam penyemak imbas dan tekan Enter untuk memerhatikannya dalam kandungan Halaman penyemak imbas. Sebenarnya, proses ini ialah penyemak imbas menghantar permintaan kepada pelayan di mana tapak web itu terletak Selepas menerima permintaan, pelayan laman web memproses dan menghuraikan permintaan itu, kemudian mengembalikan respons yang sepadan, dan kemudian menghantarnya kembali ke penyemak imbas. Respons mengandungi kod sumber halaman dan kandungan lain, dan penyemak imbas menghuraikannya dan memaparkan halaman web. Pelanggan di sini mewakili PC atau penyemak imbas mudah alih kami sendiri, dan pelayan ialah pelayan di mana tapak web yang ingin kami lawati berada.Permintaan dihantar daripada klien ke pelayan dan boleh dibahagikan kepada 4 bahagian: kaedah permintaan (Kaedah Permintaan), URL yang dimintaPermintaan
Terdapat dua kaedah permintaan biasa: GET dan POST.
Masukkan URL terus ke dalam penyemak imbas dan tekan Enter Ini akan memulakan permintaan GET dan parameter permintaan akan dimasukkan terus dalam URL. Sebagai contoh, mencari Python dalam Baidu ialah permintaan GET dengan pautan https://www baidu com/. Permintaan POST kebanyakannya dimulakan apabila borang diserahkan. Sebagai contoh, untuk borang log masuk, selepas memasukkan nama pengguna dan kata laluan, mengklik butang "Log Masuk" biasanya akan memulakan permintaan POST, dan data biasanya dihantar dalam bentuk borang dan tidak akan ditunjukkan dalam URL.
Perbezaan antara kaedah permintaan GET dan POST adalah seperti berikut:
Parameter dalam permintaan GET disertakan dalam URL, dan data boleh dilihat dalam URL, manakala POST URL yang diminta tidak akan mengandungi data ini Data dihantar melalui borang dan akan disertakan dalam badan permintaan.
Data yang diserahkan oleh permintaan GET adalah paling banyak hanya 1024 bait, manakala kaedah POST tiada had.
Secara umumnya, apabila log masuk, anda perlu menyerahkan nama pengguna dan kata laluan, yang mengandungi maklumat sensitif Jika anda menggunakan GET untuk meminta, kata laluan akan didedahkan dalam URL, menyebabkan kebocoran kata laluan, jadi Sebaiknya hantar melalui POST di sini. Semasa memuat naik fail, kaedah POST juga akan digunakan kerana kandungan fail agak besar.
Kebanyakan permintaan yang biasa kami hadapi adalah permintaan GET atau POST Terdapat juga beberapa kaedah permintaan, seperti GET, HEAD,
POST, PUT, DELETE, OPTIONS, CONNECT, TRACE, dll.
URL yang diminta
请求的网址,即统一资源定 位符URL,它可以唯一确定 我们想请求的资源。
Tajuk permintaan
请求头,用来说明服务器要使用的附加信息,比较重要的信息有Cookie . Referer. User-Agent等。
Permintaan badan
请求体一般承载的内容是 POST请求中的表单数据,而对于GET请求,请求体则为空。
Respons, dikembalikan oleh pelayan kepada pelanggan, boleh dibahagikan kepada tiga Bahagian: Kod Status Respons, Pengepala Respons dan Badan Respons.
Kod status respons
响应状态码表示服务器的响应状态,如200代表服务器正常响应,404代表页面未找到,500代表 服务器内部发生错误。在爬虫中,我们可以根据状态码来判断服务器响应状态,如状态码为200,则 证明成功返回数据,再进行进一步的处理, 否则直接忽略。
Pengepala respons
响应头包含了服务器对请求的应答信息,如Content-Type、Server、 Set-Cookie 等。
Badan tindak balas
最重要的当属响应体的内容了。响应的正文数据都在响应体中,比如请求网页时,它的响应体 就是网页的HTML代码;请求- -张图片时 ,它的响应体就是图片的二进制数据。我们做爬虫请 求网页后,要解析的内容就是响应体.
Atas ialah kandungan terperinci Apakah prinsip protokol HTTP dalam perangkak web Python?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



