

Adakah struktur rangkaian penglihatan komputer akan menjalani satu lagi inovasi?
Daripada rangkaian neural konvolusi kepada Transformer visual dengan mekanisme perhatian, model rangkaian saraf menganggap imej input sebagai jujukan grid atau tampalan, tetapi kaedah ini tidak dapat menangkap perubahan atau kerumitan objek.
Contohnya, apabila orang memerhati gambar, mereka secara semula jadi akan membahagikan keseluruhan gambar kepada berbilang objek dan mewujudkan hubungan spatial dan kedudukan lain antara objek dengan kata lain, keseluruhan gambar adalah sangat penting untuk otak manusia . Ia sebenarnya graf, dan objek adalah nod pada graf.
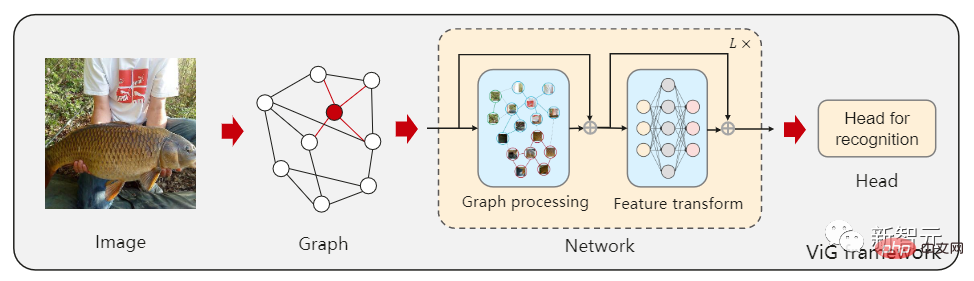
Baru-baru ini, penyelidik dari Institut Perisian, Akademi Sains China, Makmal Bahtera Nuh Huawei, Universiti Peking dan Universiti Macau bersama-sama mencadangkan seni bina model baharu Vision GNN (ViG) boleh mengekstrak ciri peringkat graf daripada imej untuk tugas penglihatan.

Pautan kertas: https://arxiv.org/pdf/2206.00272.pdf
Pertama, imej perlu dibahagikan kepada beberapa patch seperti dalam nod angka, dan bina graf dengan menyambungkan tampalan jiran terdekat, dan kemudian gunakan model ViG untuk mengubah dan menukar maklumat semua nod dalam keseluruhan graf.
ViG terdiri daripada dua modul asas Modul Grapher menggunakan konvolusi graf untuk mengagregat dan mengemas kini maklumat graf, dan modul FFN menggunakan dua lapisan linear untuk mengubah ciri nod.
Eksperimen yang dijalankan ke atas pengecaman imej dan tugas pengesanan objek juga telah membuktikan keunggulan seni bina ViG Penyelidikan perintis GNN mengenai tugas penglihatan umum akan memberikan inspirasi dan pengalaman yang berguna untuk penyelidikan masa hadapan.
Penulis kertas kerja itu ialah Profesor Wu Enhua, penyelia kedoktoran di Institut Perisian, Akademi Sains China, dan profesor kehormat di Universiti Macau, beliau lulus dari Jabatan Mekanik Kejuruteraan dan Matematik daripada Universiti Tsinghua pada tahun 1970 dan PhD beliau daripada Jabatan Sains Komputer di Universiti Manchester di UK pada tahun 1980. Bidang penyelidikan utama ialah grafik komputer dan realiti maya, termasuk: realiti maya, penjanaan grafik fotorealistik, simulasi berasaskan fizik dan pengkomputeran masa nyata, pemodelan dan rendering berasaskan fizik, pemprosesan dan pemodelan imej dan video, pengkomputeran visual dan kajian mesin.
Struktur rangkaian selalunya merupakan faktor yang paling kritikal dalam meningkatkan prestasi Selagi kuantiti dan kualiti data dapat dijamin, menukar model daripada CNN kepada ViT akan mengakibatkan a model prestasi yang lebih baik.
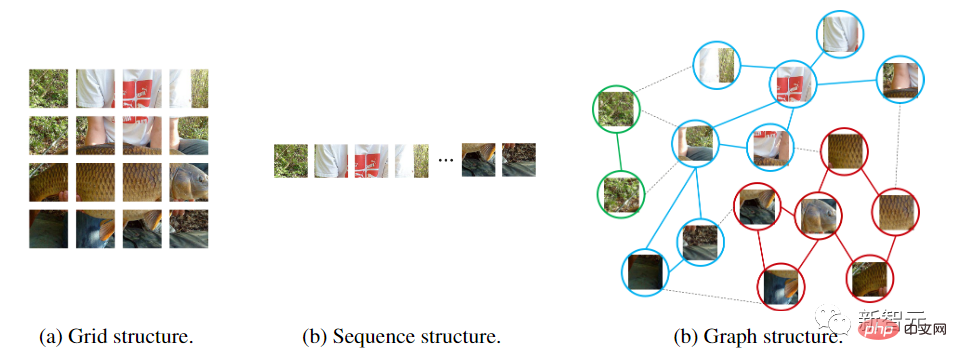
Tetapi rangkaian yang berbeza memproses imej input secara berbeza CNN meluncurkan tetingkap pada imej dan memperkenalkan invarian terjemahan dan ciri setempat.
ViT dan multi-layer perceptron (MLP) menukar imej kepada jujukan tampalan, seperti membahagikan imej 224×224 kepada beberapa tampalan 16×16, dan akhirnya membentuk input dengan panjang jujukan 196.
Rangkaian saraf graf lebih fleksibel Contohnya, dalam penglihatan komputer, tugas asas adalah untuk mengenal pasti objek dalam imej. Memandangkan objek biasanya bukan segi empat dan mungkin mempunyai bentuk yang tidak sekata, grid atau struktur jujukan yang biasa digunakan dalam rangkaian sebelumnya seperti ResNet dan ViT adalah berlebihan dan tidak fleksibel untuk dikendalikan.
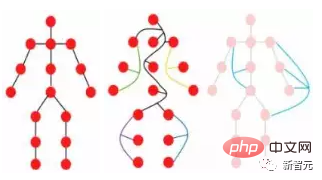
Sesuatu objek boleh dilihat sebagai terdiri daripada beberapa bahagian Sebagai contoh, seseorang boleh dibahagikan secara kasar kepada kepala, bahagian atas badan, lengan dan kaki.
Bahagian ini yang disambungkan oleh sendi secara semula jadi membentuk struktur grafik Dengan menganalisis graf, kami akhirnya dapat mengenal pasti bahawa objek itu mungkin manusia.
Selain itu, graf ialah struktur data umum dan grid serta jujukan boleh dianggap sebagai kes khas graf. Memikirkan imej sebagai graf adalah lebih fleksibel dan cekap untuk persepsi visual.
Menggunakan struktur graf memerlukan membahagikan imej input kepada beberapa tampalan dan merawat setiap tampalan sebagai nod Jika setiap piksel dianggap sebagai nod, ia akan membawa kepada terlalu banyak nod dalam graf ( >10K).
Selepas menubuhkan graf, ciri antara nod bersebelahan diagregatkan terlebih dahulu melalui rangkaian neural convolutional (GCN) graf dan perwakilan imej diekstrak.
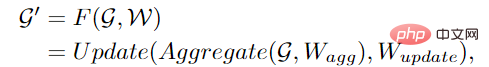
Untuk membolehkan GCN memperoleh lebih banyak ciri yang pelbagai, pengarang menggunakan operasi berbilang kepala pada lilitan graf Ciri agregat dikemas kini oleh kepala dengan pemberat yang berbeza peringkat akhir Sambungan adalah perwakilan imej.
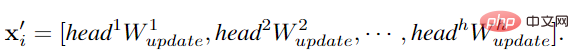
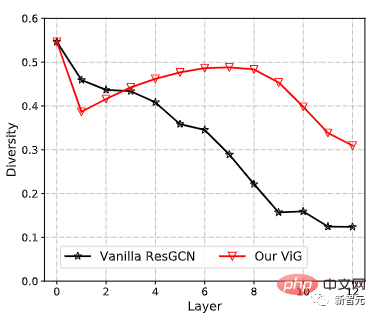
GCN sebelumnya biasanya menggunakan semula beberapa lapisan lilitan graf untuk mengekstrak ciri agregat data graf, manakala fenomena pelicinan yang berlebihan dalam GCN dalam akan mengurangkan keunikan ciri nod, mengakibatkan prestasi pengecaman visual terdegradasi.
Untuk mengurangkan masalah ini, penyelidik memperkenalkan lebih banyak transformasi ciri dan fungsi pengaktifan tak linear dalam blok ViG.
Mula-mula gunakan lapisan linear sebelum dan selepas lilitan graf untuk menayangkan ciri nod ke dalam domain yang sama dan meningkatkan kepelbagaian ciri. Memasukkan fungsi pengaktifan tak linear selepas lilitan graf untuk mengelakkan keruntuhan lapisan.
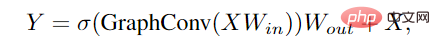
Untuk meningkatkan lagi keupayaan penukaran ciri dan mengurangkan fenomena kelicinan yang berlebihan, ia juga perlu menggunakan rangkaian suapan hadapan (FFN) pada setiap nod. Modul FFN ialah perceptron berbilang lapisan mudah dengan dua lapisan bersambung sepenuhnya.
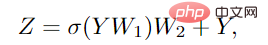
Dalam modul Grapher dan FFN, penormalan kelompok dilakukan selepas setiap lapisan bersambung sepenuhnya atau lapisan lilitan graf Timbunan modul Grapher dan modul FFN membentuk Blok ViG juga unit asas untuk membina rangkaian besar.
Berbanding dengan ResGCN yang asal, ViG yang baru dicadangkan boleh mengekalkan kepelbagaian ciri, dan apabila lebih banyak lapisan ditambah, rangkaian juga boleh mempelajari perwakilan yang lebih kukuh.
Dalam seni bina rangkaian penglihatan komputer, model Transformer yang biasa digunakan biasanya mempunyai struktur isotropik (seperti ViT), manakala CNN lebih suka menggunakan struktur piramid (seperti ResNet).
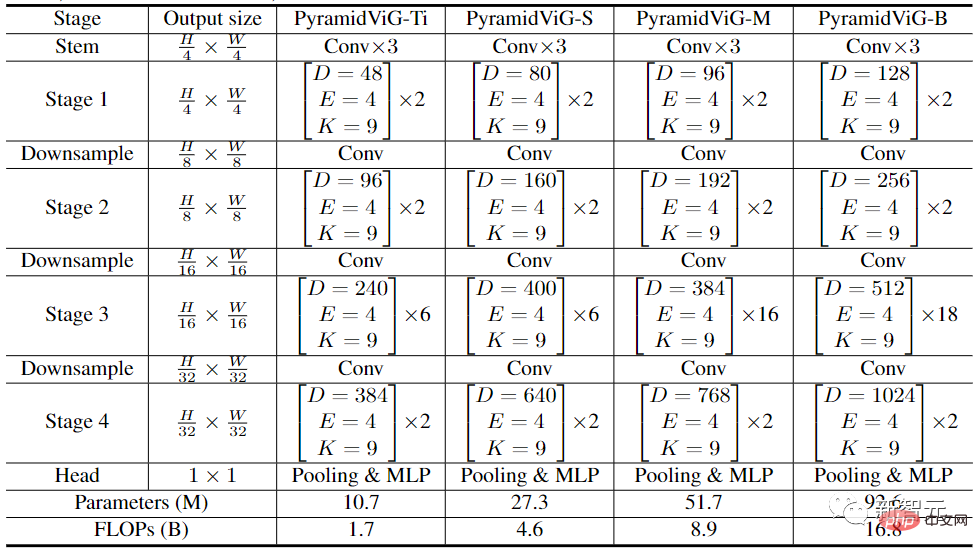
Untuk membandingkan dengan jenis rangkaian neural yang lain, penyelidik menubuhkan dua seni bina rangkaian untuk ViG: isotropik dan piramid.
Dalam peringkat perbandingan percubaan, penyelidik memilih set data ImageNet ILSVRC 2012 dalam tugas pengelasan imej, yang mengandungi 1000 kategori, imej latihan 120M dan imej pengesahan 50K.
Untuk tugas pengesanan sasaran, set data COCO 2017 dengan 80 kategori sasaran telah dipilih, termasuk 118k imej latihan dan 5000 imej set pengesahan.

Dalam seni bina ViG isotropik, saiz ciri boleh dikekalkan tidak berubah semasa proses pengiraan utamanya, yang mudah dikembangkan dan mesra kepada pecutan perkakasan. Selepas membandingkannya dengan CNN, Transformer dan MLP isotropik sedia ada, kita dapat melihat bahawa ViG berprestasi lebih baik daripada jenis rangkaian lain. Antaranya, ViG-Ti mencapai ketepatan top-1 sebanyak 73.9%, iaitu 1.7% lebih tinggi daripada model DeiT-Ti, manakala kos pengiraan adalah serupa.
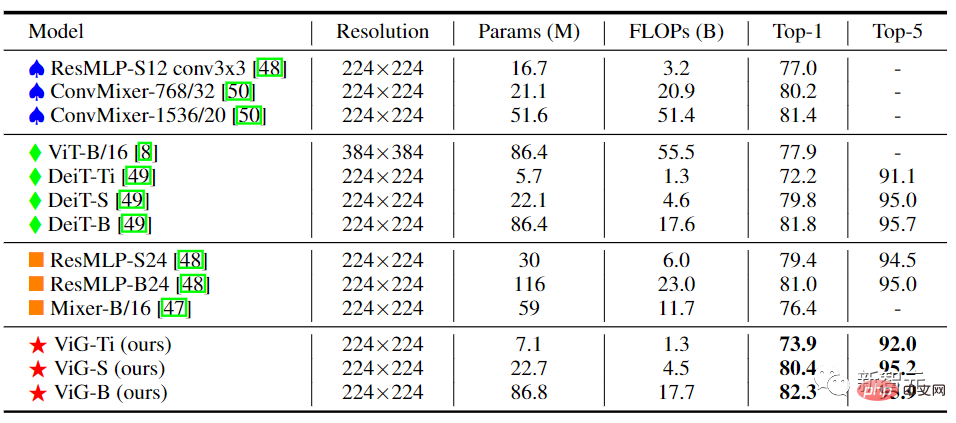
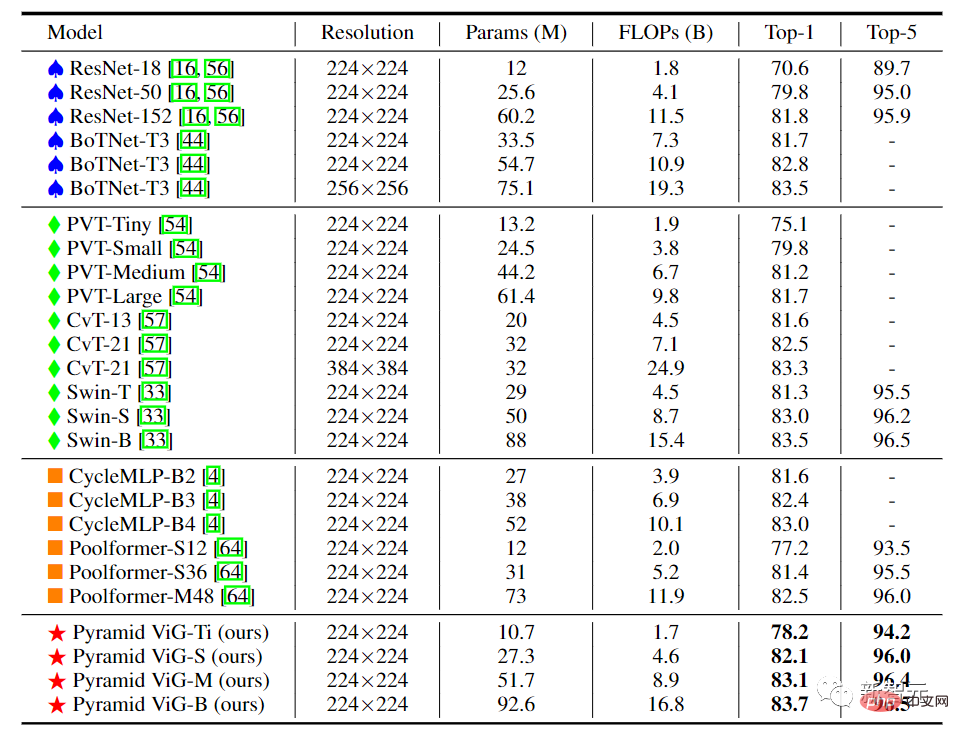
Dalam ViG berstruktur piramid, saiz spatial peta ciri dikurangkan secara beransur-ansur apabila rangkaian semakin mendalam, menggunakan ciri invarian skala imej untuk menjana pelbagai skala ciri pada masa yang sama.
Rangkaian berprestasi tinggi kebanyakannya menggunakan struktur piramid, seperti ResNet, Swin Transformer dan CycleMLP. Selepas membandingkan Pyramid ViG dengan rangkaian piramid perwakilan ini, dapat dilihat bahawa siri Pyramid ViG boleh mengatasi atau menandingi rangkaian piramid tercanggih termasuk CNN, MLP dan Transformer.
Hasilnya menunjukkan bahawa rangkaian saraf graf boleh menyelesaikan tugas visual dengan baik dan mungkin menjadi komponen asas dalam sistem penglihatan komputer.
Untuk lebih memahami aliran kerja model ViG, penyelidik memvisualisasikan struktur graf yang dibina dalam ViG-S. Plot sampel pada dua kedalaman yang berbeza (blok 1 dan 12). Pentagram ialah nod pusat dan nod dengan warna yang sama adalah jirannya. Hanya dua nod pusat divisualisasikan kerana lukisan semua tepi akan kelihatan bersepah.

Dapat diperhatikan bahawa model ViG boleh memilih nod berkaitan kandungan sebagai jiran pesanan pertama. Pada tahap cetek, nod jiran sering dipilih berdasarkan ciri peringkat rendah dan setempat, seperti warna dan tekstur. Pada tahap dalam, jiran nod pusat lebih semantik dan tergolong dalam kategori yang sama. Rangkaian ViG boleh menyambungkan nod secara beransur-ansur melalui kandungan dan perwakilan semantiknya, membantu mengenal pasti objek dengan lebih baik.
Atas ialah kandungan terperinci Perisian Akademi Sains China mengeluarkan model CV baharu ViG yang mengatasi prestasi ViT Adakah ia akan menjadi wakil rangkaian saraf graf pada masa hadapan?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk membuka kunci sekatan kebenaran android
Bagaimana untuk membuka kunci sekatan kebenaran android
 Terdapat beberapa fungsi output dan input dalam bahasa C
Terdapat beberapa fungsi output dan input dalam bahasa C
 Penyelesaian kepada pengecualian pengecualian perisian yang tidak diketahui dalam aplikasi komputer
Penyelesaian kepada pengecualian pengecualian perisian yang tidak diketahui dalam aplikasi komputer
 Cara menggunakan spyder
Cara menggunakan spyder
 Platform dagangan riak
Platform dagangan riak
 Apakah faedah corak kilang java
Apakah faedah corak kilang java
 penggunaan fungsi memcpy
penggunaan fungsi memcpy
 Apakah perisian tayangan perdana
Apakah perisian tayangan perdana








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



