
 Peranti teknologi
AI
Daripada U-Net ke DiT: Aplikasi Teknologi Transformer dalam Model Resapan Dominasi
Peranti teknologi
AI
Daripada U-Net ke DiT: Aplikasi Teknologi Transformer dalam Model Resapan Dominasi
Daripada U-Net ke DiT: Aplikasi Teknologi Transformer dalam Model Resapan Dominasi

Dalam beberapa tahun kebelakangan ini, didorong oleh Transformer, pembelajaran mesin sedang mengalami kebangkitan. Sepanjang lima tahun yang lalu, seni bina saraf untuk pemprosesan bahasa semula jadi, penglihatan komputer dan bidang lain sebahagian besarnya telah didominasi oleh transformer.
Walau bagaimanapun, terdapat banyak model generatif peringkat imej yang kekal tidak terjejas oleh aliran ini, contohnya, model penyebaran telah mencapai hasil yang menakjubkan dalam penjanaan imej pada tahun lalu model Gunakan U-Net konvolusi sebagai tulang belakang. Ini agak mengejutkan! Kisah besar dalam pembelajaran mendalam sejak beberapa tahun lalu ialah penguasaan Transformer merentasi bidang. Adakah terdapat sesuatu yang istimewa tentang U-Net atau konvolusi yang menjadikan mereka berprestasi begitu baik dalam model resapan?
Penyelidikan yang mula-mula memperkenalkan rangkaian tulang belakang U-Net ke dalam model penyebaran boleh dikesan kembali kepada Ho et al Corak reka bentuk ini mewarisi model generatif autoregresif PixelCNN++ dengan hanya sedikit perubahan. PixelCNN++ terdiri daripada lapisan konvolusi, yang mengandungi banyak blok ResNet. Berbanding dengan U-Net standard, blok perhatian kendiri spatial tambahan PixelCNN++ menjadi komponen asas dalam pengubah. Tidak seperti kerja orang lain, Dhariwal dan Nichol et al menghapuskan beberapa pilihan seni bina untuk U-Net, seperti menggunakan lapisan normalisasi penyesuaian untuk menyuntik maklumat keadaan dan kiraan saluran ke dalam lapisan konvolusi.
Dalam artikel ini, William Peebles dari UC Berkeley dan Xie Senin dari Universiti New York menulis "Model Resapan Boleh Skala dengan Transformer." Matlamatnya adalah untuk mendedahkan kepentingan pilihan seni bina dalam model penyebaran dan menyediakan panduan untuk kajian model Generatif masa hadapan menyediakan garis dasar empirikal. Kajian ini menunjukkan bahawa bias induktif U-Net tidak kritikal kepada prestasi model resapan dan boleh digantikan dengan mudah dengan reka bentuk standard seperti transformer.
Penemuan ini menunjukkan bahawa model resapan boleh mendapat manfaat daripada trend penyatuan seni bina Contohnya, model resapan boleh mewarisi amalan terbaik dan kaedah latihan daripada bidang lain, mengekalkan kebolehskalaan model ini dan kecekapan. Seni bina piawai juga akan membuka kemungkinan baharu untuk penyelidikan merentas domain.

- Alamat kertas: https://arxiv.org/pdf/2212.09748.pdf
- Alamat projek: https://github.com/facebookresearch/DiT
- Halaman utama kertas: https:// www.wpeebles.com/DiT
Penyelidikan ini memfokuskan kepada kelas baharu model resapan berasaskan Transformer: Diffusion Transformers (pendek kata DiT). DiT mengikuti amalan terbaik Pengubah Penglihatan (ViT), dengan beberapa tweak kecil tetapi penting. DiT telah ditunjukkan untuk berskala lebih cekap daripada rangkaian konvolusi tradisional seperti ResNet.
Secara khusus, artikel ini mengkaji gelagat penskalaan Transformer dari segi kerumitan rangkaian dan kualiti sampel. Kajian menunjukkan bahawa dengan membina dan menanda aras ruang reka bentuk DiT di bawah rangka kerja model resapan terpendam (LDM), di mana model resapan dilatih dalam ruang terpendam VAE, adalah mungkin untuk berjaya menggantikan tulang belakang U-Net dengan pengubah. Makalah ini selanjutnya menunjukkan bahawa DiT ialah seni bina berskala untuk model penyebaran: terdapat korelasi yang kuat antara kerumitan rangkaian (diukur oleh Gflops) dan kualiti sampel (diukur oleh FID). Dengan hanya memperluaskan DiT dan melatih LDM dengan tulang belakang berkapasiti tinggi (118.6 Gflops), hasil terkini 2.27 FID dicapai pada penanda aras penjanaan ImageNet 256 × 256 bersyarat kelas.
Pengubah Resapan
DiTs ialah seni bina baharu untuk model resapan yang bertujuan untuk setia kepada seni bina pengubah standard yang mungkin untuk mengekalkan kebolehskalaannya. DiT mengekalkan banyak amalan terbaik ViT, dan Rajah 3 menunjukkan seni bina DiT yang lengkap.
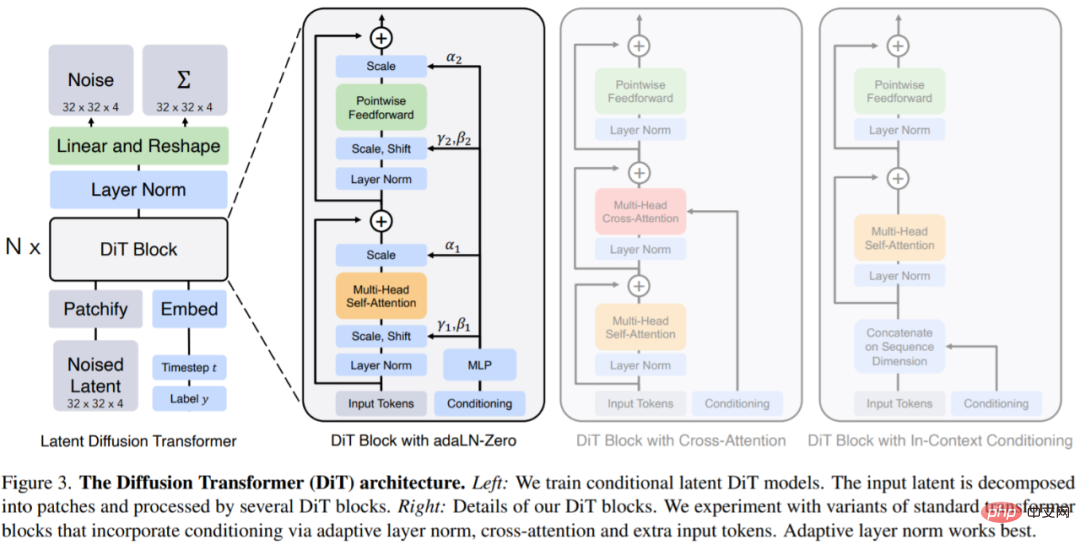
Input kepada DiT ialah perwakilan spatial z (untuk imej 256 × 256 × 3, bentuk z ialah 32 × 32 × 4 ). Lapisan pertama DiT ialah tampalan, yang menukarkan input spatial ke dalam urutan token T dengan membenamkan setiap tampalan secara linear ke dalam input. Selepas menampal, kami menggunakan benam kedudukan berasaskan frekuensi ViT standard pada semua token input.
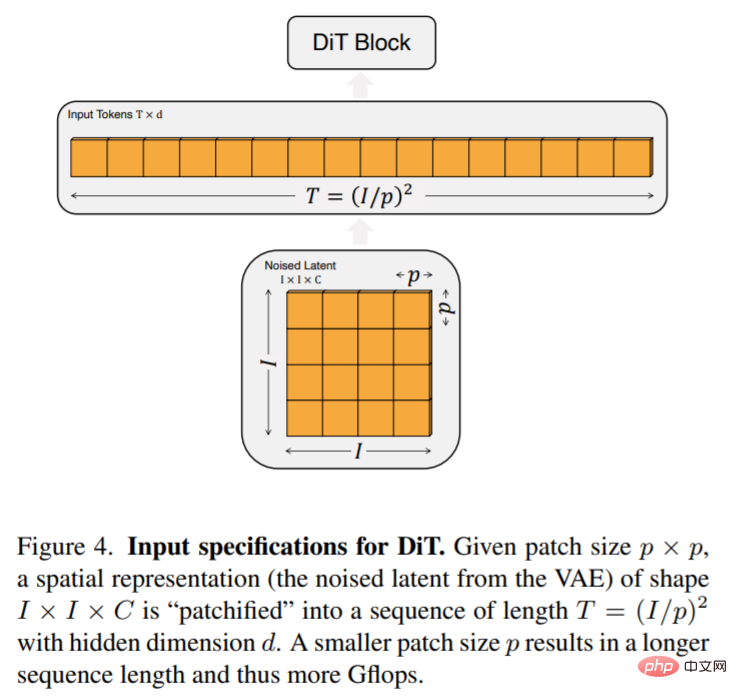
Bilangan token T yang dicipta oleh patchify ditentukan oleh hiperparameter saiz patch p. Seperti yang ditunjukkan dalam Rajah 4, membahagi p empat kali ganda T dan oleh itu sekurang-kurangnya empat kali ganda Gflop pengubah. Artikel ini menambah p = 2,4,8 pada ruang reka bentuk DiT.
Reka bentuk blok DiT: Selepas tampalan, token input diproses oleh satu siri blok pengubah. Selain input imej bising, model resapan kadangkala mengendalikan maklumat bersyarat tambahan, seperti langkah masa bunyi t, label kelas c, bahasa semula jadi, dsb. Artikel ini meneroka empat variasi blok pengubah yang mengendalikan input bersyarat dengan cara yang berbeza. Reka bentuk ini menampilkan pengubahsuaian kecil tetapi ketara pada reka bentuk blok ViT standard. Reka bentuk semua modul ditunjukkan dalam Rajah 3.
Artikel ini mencuba empat konfigurasi yang berbeza mengikut kedalaman dan lebar model: DiT-S, DiT-B, DiT-L dan DiT-XL. Konfigurasi model ini terdiri daripada parameter 33M hingga 675M dan Gflops dari 0.4 hingga 119.
Eksperimen
Para penyelidik melatih empat model DiT-XL/2 dengan Gflop tertinggi, setiap satu menggunakan reka bentuk blok yang berbeza - dalam konteks (119.4 Gflops), silang -perhatian (137.6Gflops), norma lapisan penyesuaian (adaLN, 118.6Gflops) atau adaLN-sifar (118.6Gflops). FID kemudiannya diukur semasa latihan, dan Rajah 5 menunjukkan keputusan.
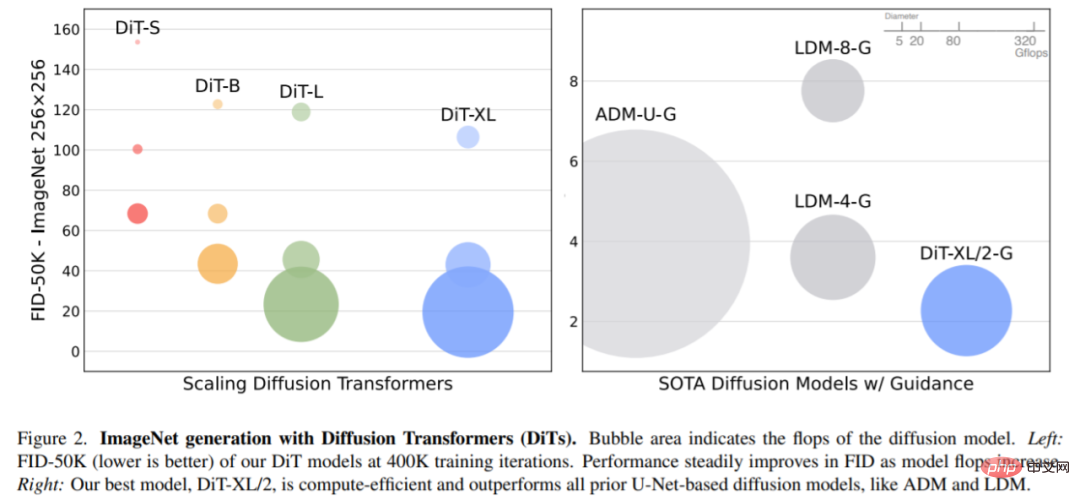
Kembangkan saiz model dan saiz tampalan. Rajah 2 (kiri) memberikan gambaran keseluruhan Gflops untuk setiap model dan FID mereka pada lelaran latihan 400K. Ia boleh dilihat bahawa meningkatkan saiz model dan mengurangkan saiz tampalan menghasilkan peningkatan yang ketara dalam model penyebaran.
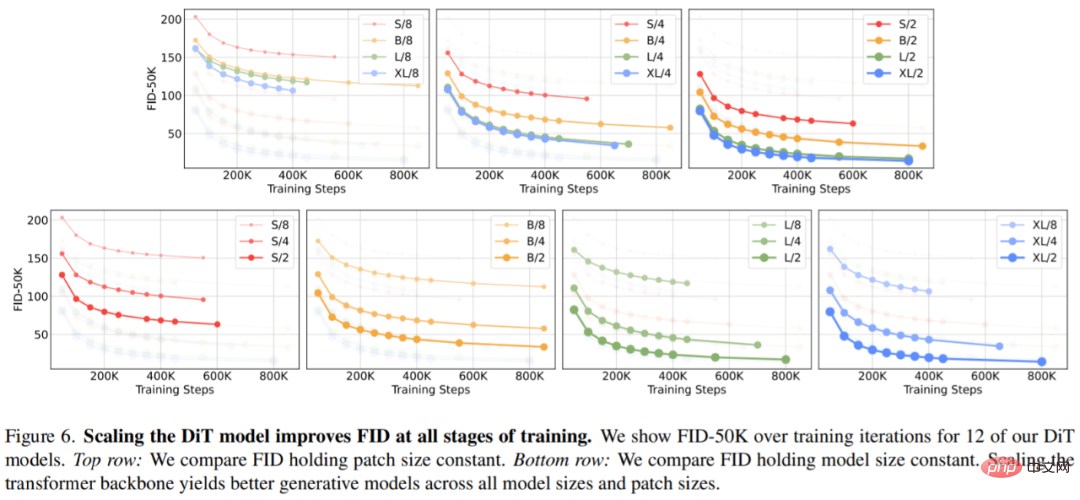
Rajah 6 (atas) menunjukkan bagaimana FID berubah apabila saiz model bertambah dan saiz tampalan dikekalkan tetap. Merentasi empat tetapan, peningkatan ketara dalam FID diperoleh pada semua peringkat latihan dengan menjadikan Transformer lebih mendalam dan lebih luas. Begitu juga, Rajah 6 (bawah) menunjukkan FID apabila saiz tampalan dikurangkan dan saiz model kekal malar. Para penyelidik sekali lagi memerhatikan bahawa FID bertambah baik dengan hanya mengembangkan bilangan token yang diproses oleh DiT dan mengekalkan parameter secara kasarnya tetap sepanjang proses latihan.
Rajah 8 menunjukkan perbandingan antara FID-50K dan model Gflops pada langkah latihan 400K:
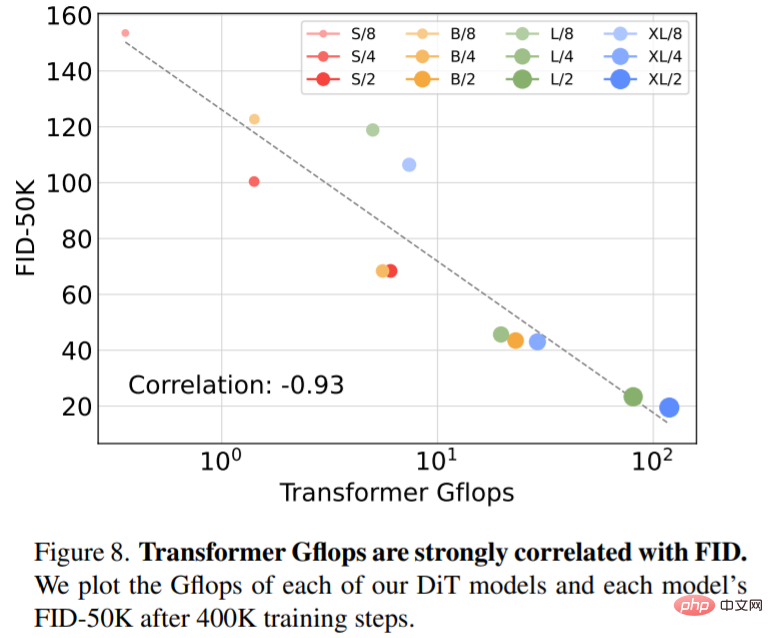
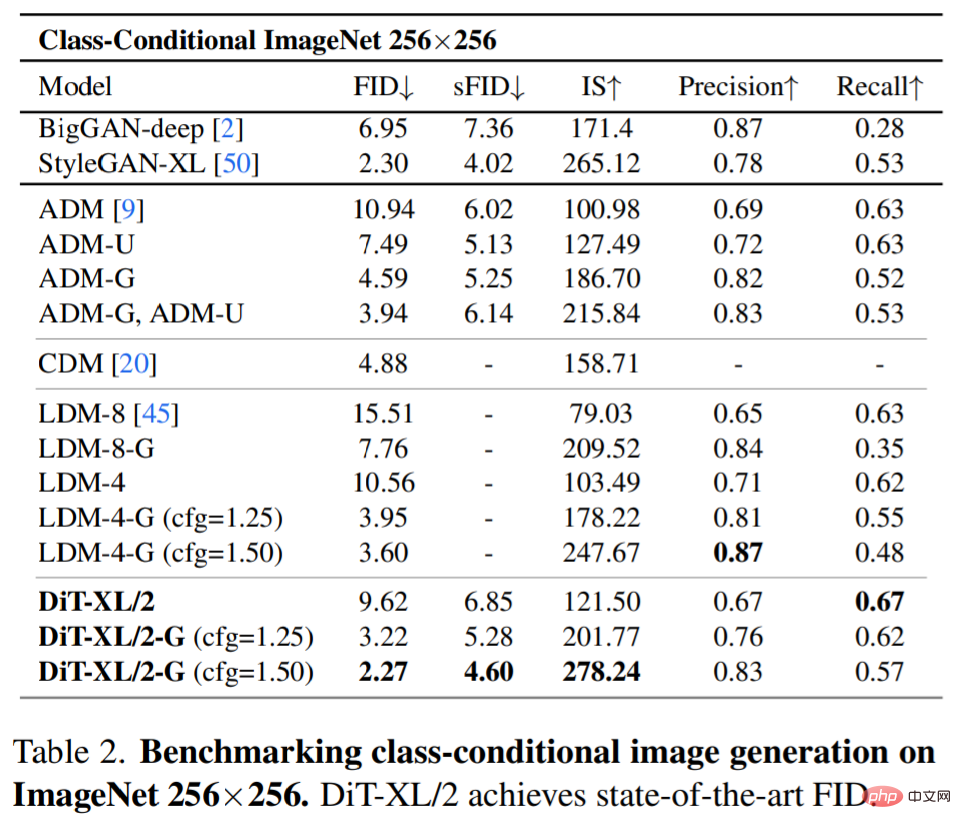
Model penyebaran SOTA 256×256 ImageNet. Selepas analisis lanjutan, penyelidik terus melatih model Gflop tertinggi, DiT-XL/2, dengan kiraan langkah 7M. Rajah 1 menunjukkan sampel model ini dan membandingkannya dengan model SOTA generasi bersyarat kategori, dan keputusan ditunjukkan dalam Jadual 2.

Apabila tidak menggunakan panduan pengelas, DiT-XL/2 mengatasi semua model resapan sebelumnya, mengatasi 3.60 yang dicapai sebelum ini oleh LDM Best FID-50K menurun hingga 2.27. Seperti yang ditunjukkan dalam Rajah 2 (kanan), berbanding model U-Net ruang terpendam seperti LDM-4 (103.6 Gflops), DiT-XL/2 (118.6 Gflops) jauh lebih cekap dari segi pengiraan daripada ADM (1120 Gflops ) atau ADM-U (742 Gflops), model U-Net ruang piksel jauh lebih cekap.
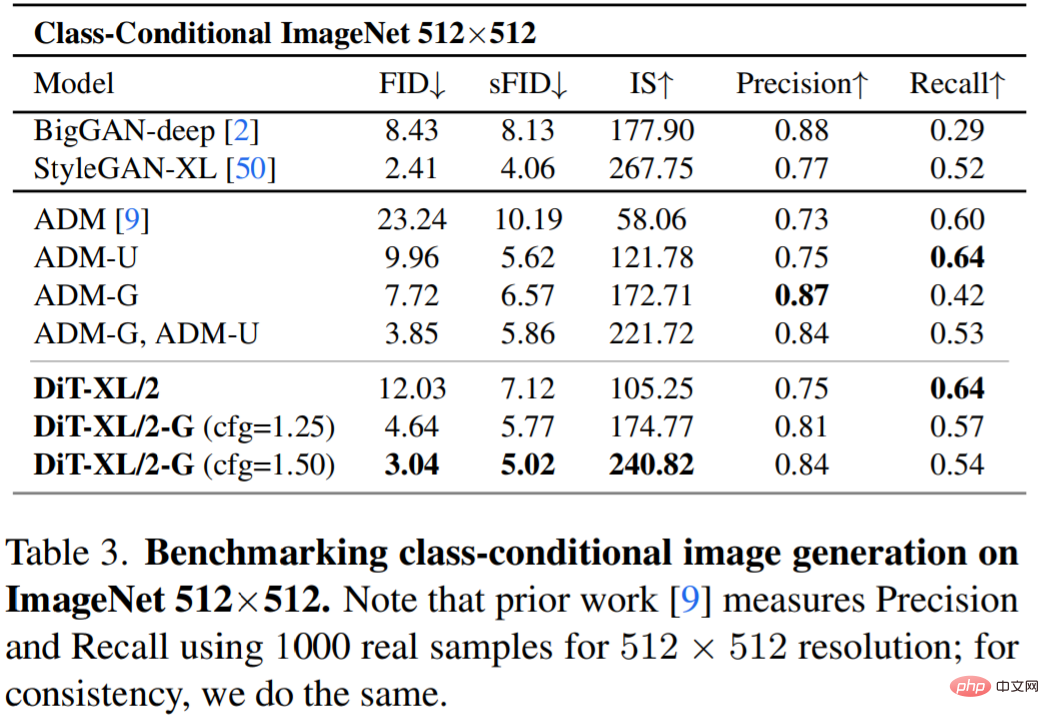
Jadual 3 menunjukkan perbandingan dengan pendekatan SOTA. XL/2 sekali lagi mengatasi semua model resapan sebelumnya pada resolusi ini, meningkatkan FID terbaik ADM sebelum ini iaitu 3.85 kepada 3.04.
Untuk butiran penyelidikan lanjut, sila rujuk kertas asal.
Atas ialah kandungan terperinci Daripada U-Net ke DiT: Aplikasi Teknologi Transformer dalam Model Resapan Dominasi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Ramalan Harga Worldcoin (WLD) 2025-2031: Adakah WLD akan mencapai $ 4 menjelang 2031?
Apr 21, 2025 pm 02:42 PM
Ramalan Harga Worldcoin (WLD) 2025-2031: Adakah WLD akan mencapai $ 4 menjelang 2031?
Apr 21, 2025 pm 02:42 PM
Worldcoin (WLD) menonjol dalam pasaran cryptocurrency dengan mekanisme pengesahan biometrik dan perlindungan privasi yang unik, menarik perhatian banyak pelabur. WLD telah melakukan yang luar biasa di kalangan altcoin dengan teknologi inovatifnya, terutamanya dalam kombinasi dengan teknologi kecerdasan buatan terbuka. Tetapi bagaimanakah aset digital akan berkelakuan dalam beberapa tahun akan datang? Mari kita meramalkan harga masa depan WLD bersama -sama. Ramalan harga WLD 2025 dijangka mencapai pertumbuhan yang signifikan di WLD pada tahun 2025. Analisis pasaran menunjukkan bahawa harga WLD purata boleh mencapai $ 1.31, dengan maksimum $ 1.36. Walau bagaimanapun, dalam pasaran beruang, harga mungkin jatuh ke sekitar $ 0.55. Harapan pertumbuhan ini disebabkan terutamanya oleh WorldCoin2.
 Apakah yang dimaksudkan dengan transaksi rantaian rantaian? Apakah urus niaga salib?
Apr 21, 2025 pm 11:39 PM
Apakah yang dimaksudkan dengan transaksi rantaian rantaian? Apakah urus niaga salib?
Apr 21, 2025 pm 11:39 PM
Pertukaran yang menyokong urus niaga rantaian: 1. Binance, 2. Uniswap, 3 Sushiswap, 4. Kewangan Curve, 5. Thorchain, 6. 1 inci Pertukaran, 7.
 Mengapa kenaikan atau kejatuhan harga mata wang maya? Mengapa kenaikan atau kejatuhan harga mata wang maya?
Apr 21, 2025 am 08:57 AM
Mengapa kenaikan atau kejatuhan harga mata wang maya? Mengapa kenaikan atau kejatuhan harga mata wang maya?
Apr 21, 2025 am 08:57 AM
Faktor kenaikan harga mata wang maya termasuk: 1. Peningkatan permintaan pasaran, 2. Menurunkan bekalan, 3. Berita positif yang dirangsang, 4. Sentimen pasaran optimis, 5. Persekitaran makroekonomi; Faktor penurunan termasuk: 1. Mengurangkan permintaan pasaran, 2. Peningkatan bekalan, 3.
 Aavenomics adalah cadangan untuk mengubah suai token protokol AAVE dan memperkenalkan pembelian semula token, yang telah mencapai bilangan kuorum orang.
Apr 21, 2025 pm 06:24 PM
Aavenomics adalah cadangan untuk mengubah suai token protokol AAVE dan memperkenalkan pembelian semula token, yang telah mencapai bilangan kuorum orang.
Apr 21, 2025 pm 06:24 PM
Aavenomics adalah cadangan untuk mengubah token protokol AAVE dan memperkenalkan repos token, yang telah melaksanakan kuorum untuk Aavedao. Marc Zeller, pengasas Rantaian Projek AAVE (ACI), mengumumkan ini pada X, dengan menyatakan bahawa ia menandakan era baru untuk perjanjian itu. Marc Zeller, pengasas Inisiatif Rantaian AAVE (ACI), mengumumkan pada X bahawa cadangan aavenomik termasuk mengubah token protokol AAVE dan memperkenalkan repos token, telah mencapai kuorum untuk Aavedao. Menurut Zeller, ini menandakan era baru untuk perjanjian itu. Ahli -ahli Aavedao mengundi untuk menyokong cadangan itu, yang 100 seminggu pada hari Rabu
 Cara Memenangi Ganjaran Airdrop Kernel pada Strategi Proses Penuh Binance
Apr 21, 2025 pm 01:03 PM
Cara Memenangi Ganjaran Airdrop Kernel pada Strategi Proses Penuh Binance
Apr 21, 2025 pm 01:03 PM
Dalam dunia kriptografi yang ramai, peluang baru selalu muncul. Pada masa ini, aktiviti udara Kerneldao (kernel) menarik banyak perhatian dan menarik perhatian banyak pelabur. Jadi, apakah asalnya projek ini? Apakah faedah yang boleh diperoleh oleh pemegang BNB? Jangan risau, perkara berikut akan mendedahkannya satu demi satu untuk anda.
 Apakah platform perdagangan blockchain hibrid?
Apr 21, 2025 pm 11:36 PM
Apakah platform perdagangan blockchain hibrid?
Apr 21, 2025 pm 11:36 PM
Cadangan untuk memilih pertukaran cryptocurrency: 1. Untuk keperluan kecairan, keutamaan adalah Binance, Gate.io atau Okx, kerana kedalaman pesanannya dan rintangan volatilitas yang kuat. 2. Pematuhan dan Keselamatan, Coinbase, Kraken dan Gemini mempunyai sokongan pengawalseliaan yang ketat. 3. Fungsi inovatif, reka bentuk derivatif Kucoin yang lembut dan Bybit sesuai untuk pengguna lanjutan.
 Sepuluh cadangan platform percuma untuk data masa nyata mengenai pasaran bulatan mata wang dikeluarkan
Apr 22, 2025 am 08:12 AM
Sepuluh cadangan platform percuma untuk data masa nyata mengenai pasaran bulatan mata wang dikeluarkan
Apr 22, 2025 am 08:12 AM
Platform data cryptocurrency yang sesuai untuk pemula termasuk coinmarketcap dan sangkakala bukan kecil. 1. CoinMarketCap menyediakan harga masa nyata global, nilai pasaran, dan kedudukan volum perdagangan untuk keperluan analisis pemula dan asas. 2. Petikan bukan kecil menyediakan antara muka yang mesra Cina, sesuai untuk pengguna Cina untuk cepat menyaring projek berpotensi berisiko rendah.
 Rexas Finance (RXS) boleh melepasi Solana (SOL), Cardano (ADA), XRP dan Dogecoin (Doge) pada tahun 2025
Apr 21, 2025 pm 02:30 PM
Rexas Finance (RXS) boleh melepasi Solana (SOL), Cardano (ADA), XRP dan Dogecoin (Doge) pada tahun 2025
Apr 21, 2025 pm 02:30 PM
Dalam pasaran cryptocurrency yang tidak menentu, pelabur mencari alternatif yang melampaui mata wang yang popular. Walaupun cryptocurrency yang terkenal seperti Solana (SOL), Cardano (ADA), XRP dan Dogecoin (Doge) juga menghadapi cabaran seperti sentimen pasaran, ketidakpastian dan skalabiliti pengawalseliaan. Walau bagaimanapun, projek baru muncul, Rexasfinance (RXS), sedang muncul. Ia tidak bergantung kepada kesan selebriti atau gembar-gembur, tetapi memberi tumpuan kepada menggabungkan aset dunia nyata (RWA) dengan teknologi blockchain untuk menyediakan pelabur dengan cara yang inovatif untuk melabur. Strategi ini menjadikannya sebagai salah satu projek yang paling berjaya pada tahun 2025. Rexasfi
