


Pustaka apakah yang akan anda gunakan untuk visualisasi data dalam Python?
Hari ini saya akan berkongsi dengan anda ahli perpustakaan visualisasi data Python-Altair yang berkuasa!
Ia sangat ringkas, mesra dan dibina pada spesifikasi Vega-Lite JSON yang berkuasa, kami hanya memerlukan kod pendek untuk menjana visualisasi yang cantik dan berkesan.
Altair ialah perpustakaan Python visualisasi statistik yang pada masa ini mempunyai lebih daripada 3,000 bintang di GitHub.
Dengan Altair, kami boleh menumpukan lebih banyak tenaga dan masa untuk memahami data itu sendiri dan maksudnya, serta dibebaskan daripada proses visualisasi data yang kompleks.
Ringkasnya, Altair ialah tatabahasa visual dan bahasa pengisytiharan untuk mencipta, menyimpan dan berkongsi reka bentuk visual interaktif Ia boleh menggunakan format JSON untuk menerangkan penampilan visual dan proses interaksi, serta menjana imej berasaskan rangkaian.
Mari kita lihat kesan visualisasi yang dibuat dengan Altair!
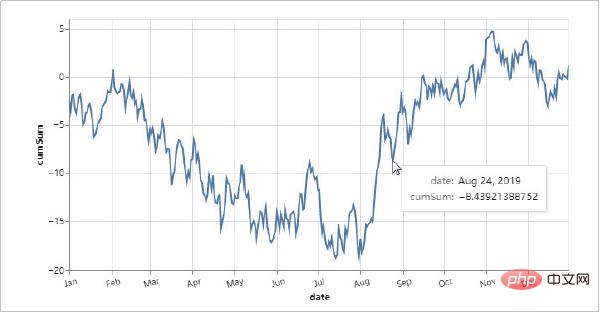
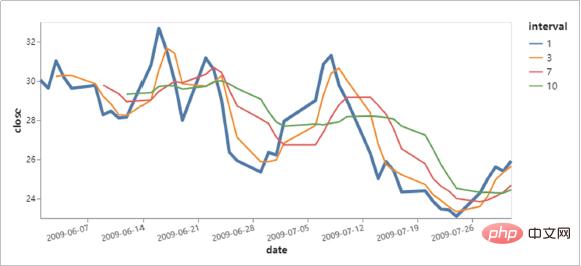
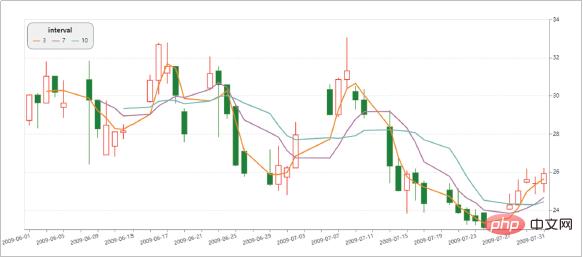
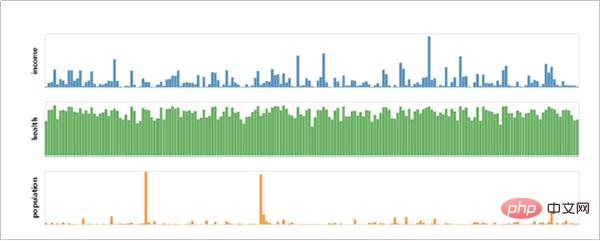
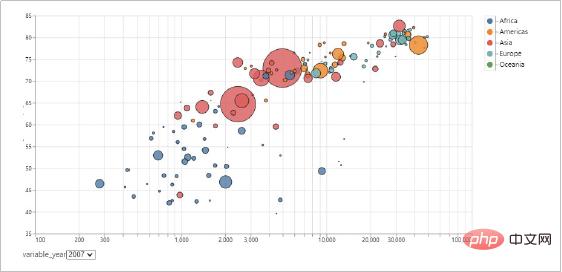
Altair boleh memahami, memahami dan menganalisis data secara menyeluruh melalui pengagregatan, transformasi data, interaksi data, komposit grafik dan kaedah lain. Proses ini boleh membantu kami meningkatkan pemahaman kami tentang data itu sendiri dan maknanya, dan memupuk pemikiran analisis data intuitif.
Secara umumnya, ciri-ciri Altair merangkumi aspek-aspek berikut.
Dalam Altair, set data yang digunakan dimuatkan dalam "format bersih". DataFrame dalam Pandas adalah salah satu struktur data utama yang digunakan oleh Altair. Altair mempunyai kesan pemuatan yang baik pada Pandas DataFrame, dan kaedah pemuatan adalah mudah dan cekap. Contohnya, gunakan Pandas untuk membaca set data Excel dan gunakan Altair untuk memuatkan kod pelaksanaan nilai pulangan Pandas, seperti yang ditunjukkan di bawah:
import altair as alt import pandas as pd data = pd.read_excel( "Index_Chart_Altair.xlsx", sheet_name="Sales", parse_dates=["Year"] ) alt.Chart( data )
Altair sangat Menekankan perbezaan dan gabungan jenis pembolehubah. Nilai pembolehubah adalah data, dan terdapat perbezaan Ia boleh dinyatakan dalam bentuk nilai berangka, rentetan, tarikh, dll. Pembolehubah ialah bekas storan untuk data, dan data ialah kandungan unit storan pembolehubah.
Sebaliknya, dari perspektif persampelan statistik, pembolehubah ialah populasi dan data adalah sampel perlu digunakan untuk mengkaji dan menganalisis populasi. Graf statistik boleh dijana dengan menggabungkan jenis pembolehubah yang berbeza antara satu sama lain untuk memberikan pemahaman yang lebih intuitif tentang data.
Mengikut gabungan jenis pembolehubah yang berbeza, gabungan jenis pembolehubah boleh dibahagikan kepada jenis berikut.
Antaranya, pembolehubah masa ialah jenis pembolehubah kuantitatif khas Pembolehubah masa boleh ditetapkan sebagai pembolehubah nominal (N) atau pembolehubah ordinal (O) untuk merealisasikan pembolehubah masa untuk membentuk gabungan dengan pembolehubah kuantitatif.
Di sini kami akan menerangkan salah satu pembolehubah nominal + pembolehubah kuantitatif.
Jika anda memetakan pembolehubah kuantitatif ke paksi-x dan pembolehubah nominal ke paksi-y, dan masih menggunakan lajur sebagai gaya pengekodan (gaya penandaan) data, anda boleh melukis carta bar. Carta bar boleh menggunakan perubahan panjang dengan lebih baik untuk membandingkan jurang keuntungan daripada jualan barangan, seperti yang ditunjukkan dalam rajah di bawah.
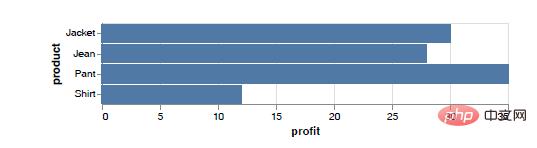
Berbanding dengan kod pelaksanaan carta lajur, perubahan dalam kod pelaksanaan carta bar adalah seperti berikut.
chart = alt.Chart(df).mark_bar().encode(x="profit:Q",y="product:N")
Berikut ialah demonstrasi yang menunjukkan purata hujan bulanan dalam tahun berbeza mengikut sekatan!
我们可以使用面积图描述西雅图从2012 年到2015 年的每个月的平均降雨量统计情况。接下来,进一步拆分平均降雨量,以年份为分区标准,使用阶梯图将具体年份的每月平均降雨量分区展示,如下图所示。
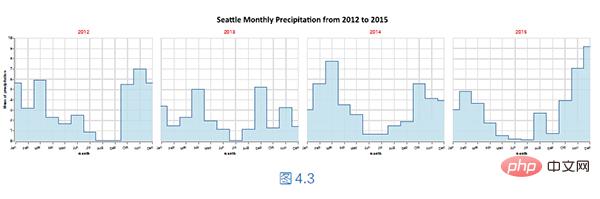
核心的实现代码如下所示。
…
chart = alt.Chart(df).mark_area(
color="lightblue",
interpolate="step",
line=True,
opacity=0.8
).encode(
alt.X("month(date):T",
axis=alt.Axis(format="%b",
formatType="time",
labelAngle=-15,
labelBaseline="top",
labelPadding=5,
title="month")),
y="mean(precipitation):Q",
facet=alt.Facet("year(date):Q",
columns=4,
header=alt.Header(
labelColor="red",
labelFontSize=15,
title="Seattle Monthly Precipitation from 2012 to 2015",
titleFont="Calibri",
titleFontSize=25,
titlePadding=15)
)
0)
…在类alt.X()中,使用month 提取时间型变量date 的月份,映射在位置通道x轴上,使用汇总函数mean()计算平均降雨量,使用折线作为编码数据的标记样式。
在实例方法encode()中,使用子区通道facet 设置分区,使用year 提取时间型变量date 的年份,作为拆分从2012 年到2015 年每个月的平均降雨量的分区标准,从而将每年的不同月份的平均降雨量分别显示在对应的子区上。使用关键字参数columns设置子区的列数,使用关键字参数header 设置子区序号和子区标题的相关文本内容。
具体而言,使用Header 架构包装器设置文本内容,也就是使用类alt.Header()的关键字参数完成文本内容的设置任务,关键字参数的含义如下所示。
Atas ialah kandungan terperinci Apakah perpustakaan visualisasi data Python yang biasa digunakan?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



