

Nota: Teks ujian dikodkan dalam UTF-8 dan aksara Cina biasanya menduduki tiga bait. Aksara Cina dalam GBK biasanya menduduki 2 bait.
import os
# 对于单个文件进行操作的函数,如果需要对文件夹进行操作,可以使用一个函数包装它,这样不用修改本函数,即达到扩展的目的了。
def transfer_encode(source_path, target_path, source_encode='GBK', target_encode='UTF-8'):
with open(source_path, mode='r', errors='ignore', encoding=source_encode) as source_file: # 读取文件时,如果直接忽略报错,则程序正常执行,但是文件已经损坏了。
with open(target_path, mode='w', encoding=target_encode) as target_file: # 所以,应该捕获异常,停止程序执行。
line = source_file.readline()
while line != '':
target_file.write(line)
line = source_file.readline()
print("Execute End!")
# 这个函数的功能和上面是一样的,区别在于它是以二进制读取的,然后解码、转码再写入的
def transfer_encode2(source_path, target_path, source_encode='GBK', target_encode='UTF-8'):
with open(source_path, mode='rb') as source_file:
with open(target_path, mode="wb") as target_file:
bs = source_file.read(1024)
while len(bs) != 0:
target_file.write(bs.decode(source_encode).encode(target_encode))
bs = source_file.read(1024)
print("Execute End!")
source_path = r'C:\Users\Alfred\Desktop\test_data\test\data.txt'
target_path = r'C:\Users\Alfred\Desktop\test_data\test\data1.txt'
transfer_encode(source_path=source_path, target_path=target_path, source_encode="UTF-8", target_encode="GBK")
# transfer_encode2(source_path=source_path, target_path=target_path)
# 在cmd中使用 type命令,可以查看文件的内容,并且使用cmd默认的编码。
# 使用 chcp 命令可以查看当前使用的编码的数字编号Output konsol Output pelaksanaan fungsi ini tidak bermakna, tetapi saya ingin tahu bahawa ia melaksanakan Tidak, jadi saya mencetaknya.

Folder ujian data1.txt ialah teks yang ditukar dan dikodkan.
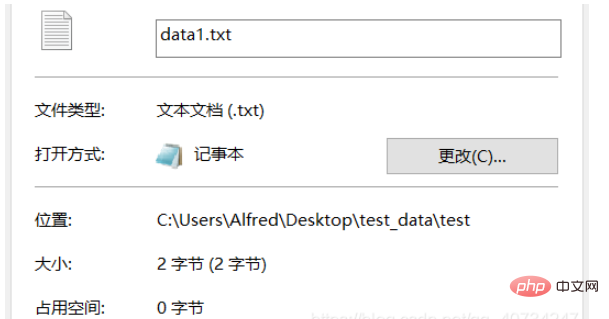
Berdasarkan fail yang dijana, kerana ia hanya mengandungi satu perkataan, anda boleh mengetahui sama ada penukaran berjaya dengan hanya membandingkan saiz . Sudah tentu, ia juga boleh dibuka terus untuk tontonan, tetapi jika anda membukanya terus untuk tontonan, ia tidak akan memberi kesan dan aksara Cina 龙 akan dipaparkan. Jadi, di sini kami mengambil pendekatan yang berbeza dan menggunakan kaedah tontonan yang berbeza!
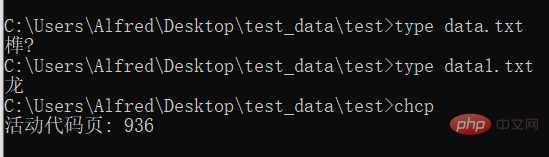
Nota: data.txt dikodkan dalam UTF-8, manakala data1.txt dikodkan dalam GBK. Oleh kerana Windows yang digunakan di China menggunakan kaedah pengekodan China secara lalai, ia tidak boleh memaparkan teks yang dikodkan UTF-8. Output ketiga adalah untuk melihat pengekodan yang sedang digunakan. Ia mengembalikan kod pengekodan Lihat rajah di bawah untuk butiran:
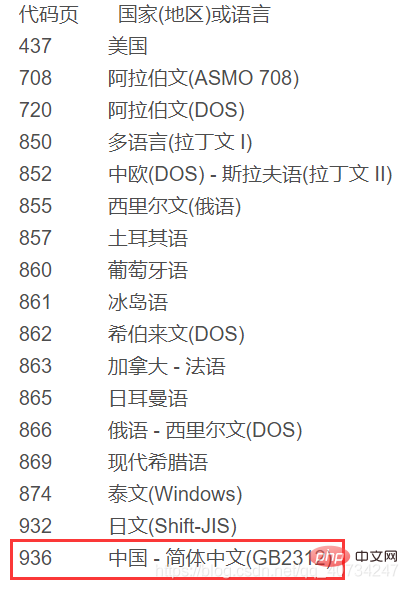
Nota: GBK ialah pengekodan yang serasi dengan GB2312.
Jika anda menggunakan python, anda hanya memerlukan 7 baris kod untuk menukar satu fail! Saya menulis dua fungsi di atas, tetapi fungsinya adalah sama Perbezaannya ialah fungsi pertama membaca maklumat teks dalam pengekodan tertentu dan kemudian menulisnya terus dalam pengekodan lain. Fungsi kedua membaca kandungan fail dalam bentuk binari, kemudian menyahkod dan mentranskodkannya untuk menulis. Prinsipnya adalah sama, iaitu, ia mesti termasuk operasi penyahkodan dan transkod berjujukan.
Pengekodan, penyahkodan dan set aksara itu sendiri adalah sangat rumit dan saya tidak tahu bagaimana untuk menerangkannya secara mendalam. Pemahaman di sini boleh dipermudahkan seperti ini Dua set aksara pengekodan berbeza mempunyai aksara yang sama, jadi tujuan membaca fail yang dikodkan UTF-8 adalah untuk mendapatkan aksara yang dipetakan, dan kemudian menulisnya semula untuk memetakannya ke pengekodan An yang lain. set aksara, jadi aksara adalah serupa dengan fungsi stesen pemindahan. Jika anda terus menggunakan satu set aksara untuk membaca kandungan set aksara lain, aksara bercelaru yang dipaparkan dalam cmd di atas akan muncul.
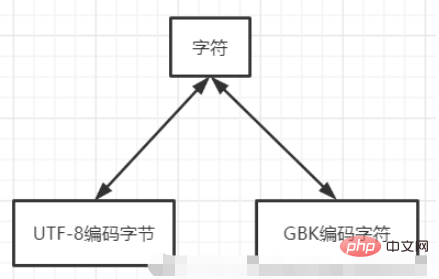
PS: Oleh itu, ia juga boleh menjelaskan masalah, iaitu, mengapa membuka fail teks yang besar akan menyebabkan program menjadi beku! Kerana fail teks yang besar mengandungi banyak aksara yang perlu dinyahkodkan. Ini agak serupa dengan beratur Setiap aksara sedang menunggu untuk dinyahkodkan Walaupun memproses satu aksara adalah pantas, fail teks yang besar mengandungi sejumlah besar aksara. Sebagai contoh, Notepad++ tidak mempunyai masalah untuk membuka teks yang besar Tetapi apabila saya membuka teks yang sangat besar ini, ia masih tersekat! (Beratur di sini hanyalah metafora, dan saya tidak tahu keadaan sebenar, tetapi ia mesti diproses satu persatu.)
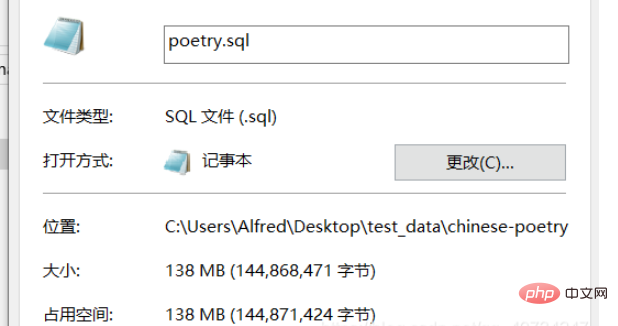
Kami menganggarkannya, dengan andaian bahawa semua Aksara adalah semua bahasa Cina (sebenarnya, beberapa bahasa Inggeris disertakan, tetapi secara umum bahasa Cina masih majoriti.) Di sini ditunjukkan bahawa terdapat kira-kira 50 juta aksara yang perlu dinyahkod, jadi ia masih sangat sukar untuk komputer untuk memproses. Anda boleh melihatnya dengan notepad++ Ringkasan, tetapi ia tersekat apabila saya membukanya secara langsung, jadi saya tidak akan mencubanya di sini.

Atas ialah kandungan terperinci Bagaimana untuk menyelesaikan masalah pengekodan penukaran fail teks dalam Python?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



