
 Peranti teknologi
AI
Model SOTA yang inovatif Meta boleh menghasilkan video yang menakjubkan berdasarkan satu ayat, mencetuskan kegilaan Internet!
Peranti teknologi
AI
Model SOTA yang inovatif Meta boleh menghasilkan video yang menakjubkan berdasarkan satu ayat, mencetuskan kegilaan Internet!
Model SOTA yang inovatif Meta boleh menghasilkan video yang menakjubkan berdasarkan satu ayat, mencetuskan kegilaan Internet!

Saya akan bagi satu perenggan dan minta awak buat video, boleh tak?
Meta berkata, saya boleh melakukannya.
Anda mendengarnya dengan betul: menggunakan AI, anda juga boleh menjadi pembuat filem!
Baru-baru ini, Meta melancarkan model AI baharu dengan nama yang sangat mudah: Make-A-Video.
Berapa kuasa model ini?
Hanya dengan satu ayat, anda boleh merealisasikan adegan "Tiga Kuda Berlumba-lumba".

LeCun pun cakap, apa yang sepatutnya datang akan sentiasa datang.

Kesan visual yang menakjubkan
Tanpa berlengah lagi, mari kita lihat kesannya.
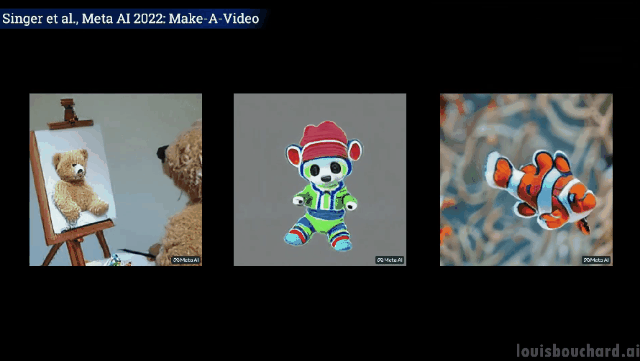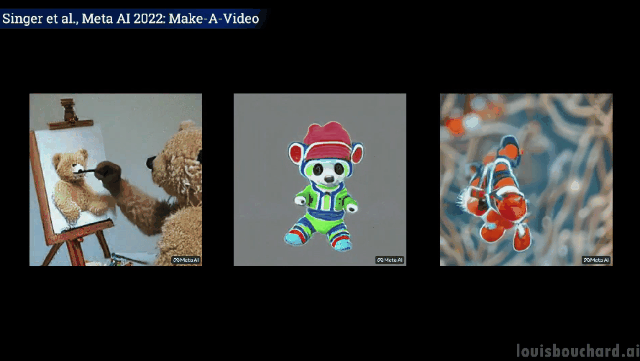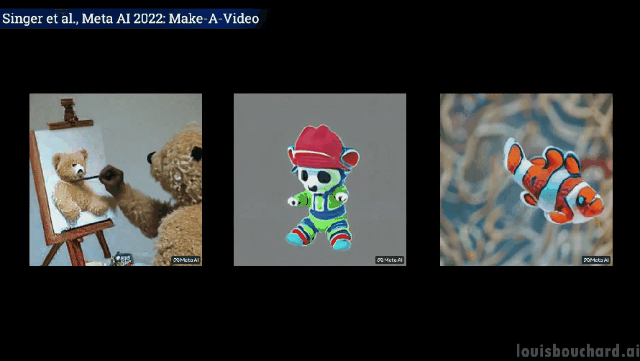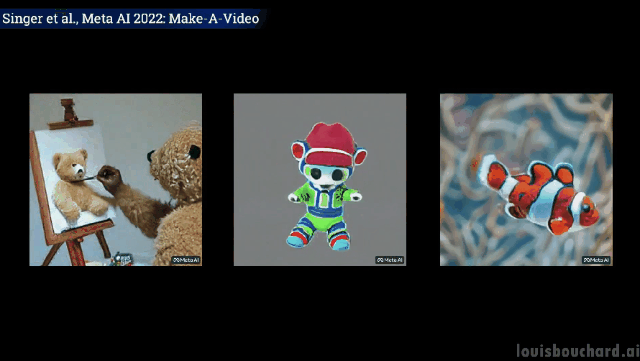
Dua ekor kanggaru sedang sibuk memasak di dapur (sama ada boleh dimakan itu perkara lain)

Gambar dekat: Pelukis sedang melukis di atas kanvas

Dunia dua orang berjalan dalam hujan lebat (bersama-sama melangkah)

Air minuman kuda

Gadis balet menari di atas pencakar langit

Golden retriever sedang makan ais krim (cakar telah berkembang) di pantai tropika yang indah pada musim panas

Pemilik kucing sedang menonton TV dengan alat kawalan jauh (kaki telah berkembang)

Teddy bear memberikan Lukis potret diri anda sendiri

Tidak dijangka tetapi munasabah, anjing itu mengambil ais krim, kucing mengambil alat kawalan jauh dan teddy bear melukis " "Tangan" memang "berkembang" seperti manusia! (Tactical Backward)
Sudah tentu, selain menukar teks kepada video, Make-A-Video juga boleh menukar imej statik kepada Gif.
Input:

Output:

Input:

Output: (Cahaya kelihatan agak tidak pada tempatnya)

2 imej statik ke GIF, masukkan imej meteorit

Output:

Dan, jadikan video itu sebagai video?
Input:

Output:

Input:

Output:

Prinsip Teknikal
Hari ini, Meta mengeluarkan penyelidikan terbarunya MAKE-A-VIDEO: TEKS-TO-VIDEO GENERATION TANPA TEKS-VIDEO DATA.

Alamat kertas: https://makeavideo.studio/Make-A-Video.pdf
Sebelum model ini muncul, kami sudah mempunyai Stable Diffusion.
Saintis pintar telah meminta AI untuk menghasilkan imej dengan hanya satu ayat Apakah yang akan mereka lakukan seterusnya?
Jelas sekali, ia menjana video.

Anjing superhero memakai jubah merah terbang di langit
Berbanding dengan menjana imej, menjana video adalah lebih sukar. Kita bukan sahaja perlu menjana berbilang bingkai subjek dan pemandangan yang sama, kita juga perlu menjadikannya tepat pada masanya dan koheren.
Ini meningkatkan kerumitan tugas penjanaan imej - kita tidak boleh menggunakan DALLE untuk menjana 60 imej dan kemudian mencantumkannya ke dalam video. Kesannya akan menjadi sangat buruk dan tidak realistik.
Oleh itu, kita memerlukan model yang boleh memahami dunia dengan cara yang lebih berkuasa, dan membolehkannya menjana satu siri imej yang koheren berdasarkan tahap pemahaman ini. Hanya selepas itu imej boleh digabungkan dengan lancar.
Dalam erti kata lain, matlamat kami adalah untuk mensimulasikan dunia dan kemudian mensimulasikan rekodnya. Bagaimana untuk melakukannya?

Menurut idea terdahulu, penyelidik akan menggunakan sebilangan besar pasangan teks-video untuk melatih model, tetapi dalam keadaan semasa, kaedah pemprosesan ini tidak realistik. Kerana data ini sukar diperoleh dan kos latihan sangat mahal.
Oleh itu, para penyelidik membuka minda mereka dan menggunakan pendekatan yang sama sekali baru.
Mereka memilih untuk membangunkan model teks ke imej dan kemudian menggunakannya pada video.
Kebetulan, suatu ketika dahulu, Meta membangunkan Make-A-Scene, model daripada teks ke imej.
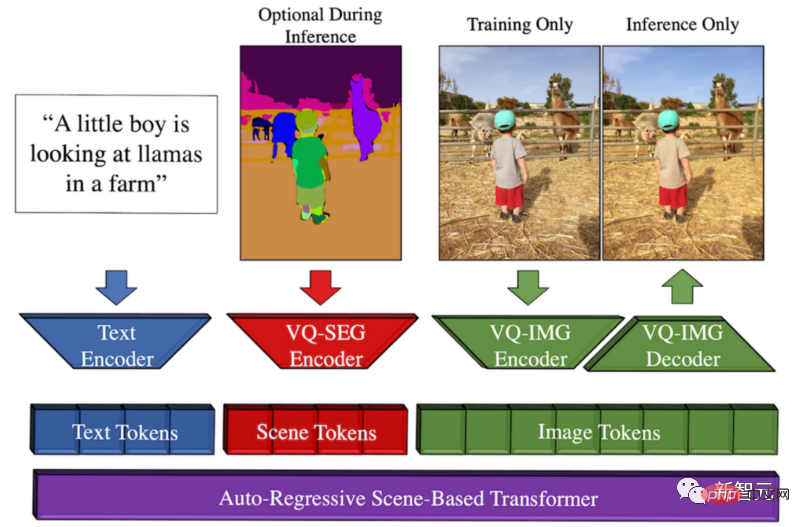
Ikhtisar kaedah Make-A-Scene
Model ini menjana Peluangnya ialah Meta ingin mempromosikan ekspresi kreatif, menggabungkan trend teks-ke-imej ini dengan model lakaran-ke-imej sebelumnya, menghasilkan gabungan yang indah antara teks dan penjanaan imej terkondisi lakaran.
Ini bermakna kita boleh dengan cepat melakar kucing dan menulis jenis imej yang kita mahukan. Mengikuti panduan lakaran dan teks, model ini akan menghasilkan ilustrasi sempurna yang kita inginkan dalam beberapa saat.

Anda boleh menganggap pendekatan AI generatif pelbagai mod ini sebagai model Dall-E dengan lebih kawalan ke atas penjanaan kerana lakaran pantas juga boleh digunakan sebagai input.
Sebab mengapa ia dipanggil berbilang modal adalah kerana ia boleh mengambil berbilang modaliti sebagai input, seperti teks dan imej. Sebaliknya, Dall-E hanya boleh menjana imej daripada teks.
Untuk menghasilkan video, adalah perlu untuk menambah dimensi masa, jadi penyelidik menambah saluran paip spatio-temporal pada model Make-A-Scene.
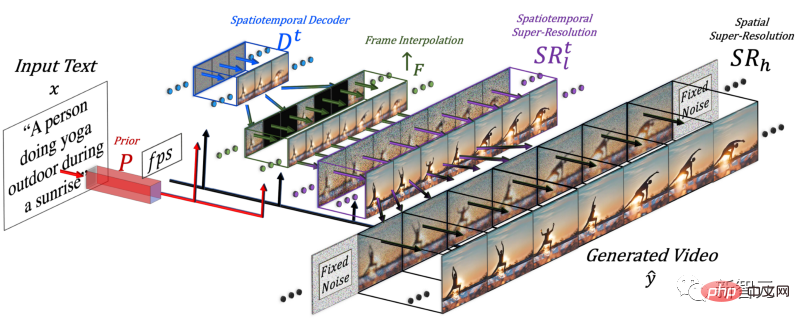
Selepas menambah dimensi masa, model ini tidak menjana hanya satu imej, tetapi menjana 16 imej resolusi rendah untuk mencipta video pendek yang koheren .
Kaedah ini sebenarnya serupa dengan model teks-ke-imej, tetapi perbezaannya ialah ia menambah konvolusi satu dimensi berdasarkan konvolusi dua dimensi konvensional.
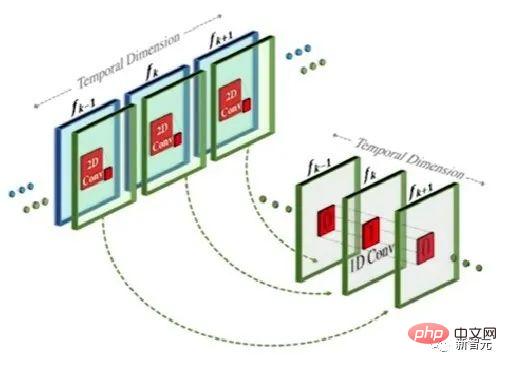
Dengan hanya menambah konvolusi satu dimensi, penyelidik dapat memastikan konvolusi dua dimensi yang telah dilatih tidak berubah sambil menambah dimensi masa . Penyelidik kemudian boleh melatih dari awal, menggunakan semula kebanyakan kod dan parameter model imej Make-A-Scene.
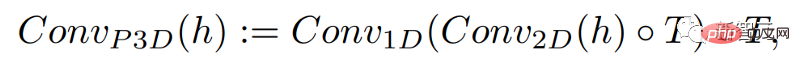
Pada masa yang sama, penyelidik juga ingin menggunakan input teks untuk membimbing model ini, yang akan sangat serupa dengan model imej menggunakan CLIP membenamkan.
Dalam kes ini, penyelidik meningkatkan dimensi spatial apabila mencampurkan ciri teks dengan ciri imej, menggunakan kaedah yang sama seperti di atas: mengekalkan modul perhatian dalam model Make-A-Scene , dan tambah modul perhatian satu dimensi untuk masa - salin-tampal model penjana imej, ulang modul penjanaan untuk satu dimensi lagi untuk mendapatkan 16 bingkai awal.
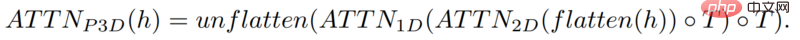
Tetapi hanya bergantung pada 16 bingkai awal ini, video tidak boleh dijana.
Penyelidik perlu menghasilkan video definisi tinggi daripada 16 bingkai utama ini. Pendekatan mereka adalah untuk mengakses bingkai sebelumnya dan akan datang dan menginterpolasinya secara berulang dalam kedua-dua dimensi temporal dan ruang secara serentak.
Dengan cara ini, antara 16 bingkai awal ini, mereka menghasilkan bingkai baharu yang lebih besar berdasarkan bingkai sebelum dan selepas, supaya pergerakan menjadi koheren dan keseluruhan video menjadi Mesti lancar .
Ini dilakukan melalui rangkaian interpolasi bingkai, yang boleh mengambil imej sedia ada untuk mengisi jurang dan menjana maklumat perantaraan. Dalam dimensi spatial, ia melakukan perkara yang sama: membesarkan imej, mengisi ruang dalam piksel dan menjadikan imej lebih definisi tinggi.

Untuk meringkaskan, untuk menjana video, penyelidik memperhalusi model teks-ke-imej. Mereka mengambil model berkuasa yang telah dilatih, diubah suai dan dilatih agar sesuai dengan video.
Oleh kerana penambahan modul spatial dan temporal, anda boleh menyesuaikan model dengan data baharu ini tanpa perlu melatihnya semula, yang menjimatkan banyak kos.
Latihan semula jenis ini menggunakan video tidak berlabel dan hanya perlu mengajar model untuk memahami ketekalan video dan bingkai video, yang menjadikannya lebih mudah untuk membina set data.
Akhir sekali, penyelidik sekali lagi menggunakan model pengoptimuman imej untuk memperbaik resolusi spatial dan menggunakan komponen interpolasi bingkai untuk menambah lebih banyak bingkai untuk menjadikan video lebih lancar.
Sudah tentu, hasil semasa Make-A-Video masih mempunyai kekurangan, sama seperti model teks-ke-imej. Tetapi kita semua tahu betapa pesatnya kemajuan dalam bidang AI.
Kalau nak tahu lebih lanjut, boleh rujuk kertas Meta AI di link. Komuniti juga sedang membangunkan pelaksanaan PyTorch, jadi nantikan jika anda mahu melaksanakannya sendiri.
Pengenalan Pengarang
Sebilangan penyelidik Cina mengambil bahagian dalam kertas kerja ini: Yin Xi, An Jie, Zhang Songyang , Qiyuan Hu .
Yin Xi, saintis penyelidikan FAIR. Sebelum ini bekerja untuk Microsoft sebagai saintis aplikasi kanan untuk Microsoft Cloud dan AI. Beliau menerima PhD dari Jabatan Sains Komputer dan Kejuruteraan di Michigan State University dan ijazah sarjana muda dalam kejuruteraan elektrik dari Universiti Wuhan pada 2013. Bidang penyelidikan utama ialah pemahaman pelbagai modal, pengesanan sasaran berskala besar, penaakulan muka, dsb.
Anjie ialah pelajar kedoktoran di Jabatan Sains Komputer di Universiti Rochester. Kajian di bawah Profesor Roger Bo. Sebelum ini menerima ijazah sarjana muda dan sarjana dari Universiti Peking pada 2016 dan 2019. Minat penyelidikan termasuk penglihatan komputer, model generatif mendalam dan seni AI+. Mengambil bahagian dalam penyelidikan Make-A-Video sebagai pelatih.
Zhang Songyang ialah pelajar kedoktoran di Jabatan Sains Komputer di Universiti Rochester, belajar di bawah Profesor Roger Bo. Beliau menerima ijazah sarjana muda dari Universiti Tenggara dan ijazah sarjana dari Universiti Zhejiang. Minat penyelidikan termasuk penyetempatan detik bahasa semula jadi, induksi tatabahasa tanpa pengawasan, pengecaman tindakan berasaskan rangka, dsb. Mengambil bahagian dalam penyelidikan Make-A-Video sebagai pelatih.
Qiyuan Hu, yang ketika itu merupakan Residen AI di FAIR, terlibat dalam penyelidikan tentang model generatif pelbagai mod yang meningkatkan kreativiti manusia. Beliau menerima PhD dalam fizik perubatan dari University of Chicago dan bekerja pada analisis imej perubatan berbantukan AI. Kini bekerja di Tempus Labs sebagai saintis pembelajaran mesin.
Netizen terkejut
Beberapa ketika dahulu, syarikat besar seperti Google mengeluarkan model teks-ke-imej mereka sendiri, seperti Parti, dsb.
Malah ada yang berpendapat bahawa model generatif teks-ke-video masih lagi agak lama.
Tidak disangka-sangka, Meta membuat kejutan kali ini.
Malah, hari ini, terdapat juga model penjanaan teks-ke-video Phenaki, yang telah diserahkan kepada ICLR 2023. Memandangkan ia masih dalam peringkat semakan buta, institusi penulis masih tidak diketahui.

Netizen berkata daripada DALLE hingga Stable Diffuson hingga Make-A-Video, semuanya berlaku terlalu pantas.

Atas ialah kandungan terperinci Model SOTA yang inovatif Meta boleh menghasilkan video yang menakjubkan berdasarkan satu ayat, mencetuskan kegilaan Internet!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1386
1386
 52
52

 Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Panduan Lengkap untuk Memeriksa Konfigurasi HDFS Dalam Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk memeriksa konfigurasi dan menjalankan status HDFS secara berkesan pada sistem CentOS. Langkah -langkah berikut akan membantu anda memahami sepenuhnya persediaan dan operasi HDFS. Sahkan Pembolehubah Alam Sekitar Hadoop: Pertama, pastikan pembolehubah persekitaran Hadoop ditetapkan dengan betul. Di terminal, laksanakan arahan berikut untuk mengesahkan bahawa Hadoop dipasang dan dikonfigurasi dengan betul: Hadoopversion Semak fail konfigurasi HDFS: Fail konfigurasi teras HDFS terletak di/etc/hadoop/conf/direktori, di mana core-site.xml dan hdfs-site.xml adalah kritikal. gunakan
 Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Perintah shutdown CentOS adalah penutupan, dan sintaks adalah tutup [pilihan] [maklumat]. Pilihan termasuk: -h menghentikan sistem dengan segera; -P mematikan kuasa selepas penutupan; -r mulakan semula; -T Waktu Menunggu. Masa boleh ditentukan sebagai segera (sekarang), minit (minit), atau masa tertentu (HH: mm). Maklumat tambahan boleh dipaparkan dalam mesej sistem.
 Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Dasar sandaran dan pemulihan Gitlab di bawah sistem CentOS untuk memastikan keselamatan data dan pemulihan, Gitlab pada CentOS menyediakan pelbagai kaedah sandaran. Artikel ini akan memperkenalkan beberapa kaedah sandaran biasa, parameter konfigurasi dan proses pemulihan secara terperinci untuk membantu anda menubuhkan strategi sandaran dan pemulihan GitLab lengkap. 1. Backup Manual Gunakan Gitlab-Rakegitlab: Backup: Buat Perintah untuk Melaksanakan Backup Manual. Perintah ini menyokong maklumat utama seperti repositori Gitlab, pangkalan data, pengguna, kumpulan pengguna, kunci, dan kebenaran. Fail sandaran lalai disimpan dalam direktori/var/opt/gitlab/sandaran. Anda boleh mengubah suai /etc /gitlab
 CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
Memasang MySQL pada CentOS melibatkan langkah -langkah berikut: Menambah sumber MySQL YUM yang sesuai. Jalankan YUM Pasang Perintah MySQL-Server untuk memasang pelayan MySQL. Gunakan perintah mysql_secure_installation untuk membuat tetapan keselamatan, seperti menetapkan kata laluan pengguna root. Sesuaikan fail konfigurasi MySQL seperti yang diperlukan. Tune parameter MySQL dan mengoptimumkan pangkalan data untuk prestasi.
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 Cara Memilih Pangkalan Data Gitlab di CentOs
Apr 14, 2025 pm 05:39 PM
Cara Memilih Pangkalan Data Gitlab di CentOs
Apr 14, 2025 pm 05:39 PM
Apabila memasang dan mengkonfigurasi GitLab pada sistem CentOS, pilihan pangkalan data adalah penting. GitLab serasi dengan pelbagai pangkalan data, tetapi PostgreSQL dan MySQL (atau MariaDB) paling biasa digunakan. Artikel ini menganalisis faktor pemilihan pangkalan data dan menyediakan langkah pemasangan dan konfigurasi terperinci. Panduan Pemilihan Pangkalan Data Ketika memilih pangkalan data, anda perlu mempertimbangkan faktor -faktor berikut: PostgreSQL: Pangkalan data lalai Gitlab adalah kuat, mempunyai skalabilitas yang tinggi, menyokong pertanyaan kompleks dan pemprosesan transaksi, dan sesuai untuk senario aplikasi besar. MySQL/MariaDB: Pangkalan data relasi yang popular digunakan secara meluas dalam aplikasi web, dengan prestasi yang stabil dan boleh dipercayai. MongoDB: Pangkalan Data NoSQL, mengkhususkan diri dalam
 Cara Melihat Log Gitlab Di Bawah Centos
Apr 14, 2025 pm 06:18 PM
Cara Melihat Log Gitlab Di Bawah Centos
Apr 14, 2025 pm 06:18 PM
Panduan Lengkap untuk Melihat Log Gitlab Di bawah Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk melihat pelbagai log Gitlab dalam sistem CentOS, termasuk log utama, log pengecualian, dan log lain yang berkaitan. Sila ambil perhatian bahawa laluan fail log mungkin berbeza -beza bergantung pada versi GitLab dan kaedah pemasangan. Jika laluan berikut tidak wujud, sila semak fail Direktori Pemasangan dan Konfigurasi GitLab. 1. Lihat log Gitlab utama Gunakan arahan berikut untuk melihat fail log utama aplikasi GitLabRails: Perintah: Sudocat/var/Log/Gitlab/Gitlab-Rails/Production.log Perintah ini akan memaparkan produk
