

Menurut definisi yang diberikan oleh Solanki, Nayyar dan Naved dalam makalah, terjemahan imej ke imej ialah proses menukar imej dari satu domain ke domain lain, dengan matlamat pembelajaran Pemetaan antara imej input dan imej output.
Dalam erti kata lain, kami berharap model tersebut dapat mengubah satu imej a kepada imej b yang lain dengan mempelajari fungsi pemetaan f.

Seseorang mungkin tertanya-tanya apakah kegunaan model ini dan apakah kaitannya dalam dunia kecerdasan buatan. Terdapat banyak aplikasi, dan ia bukan hanya terhad kepada seni atau reka bentuk grafik. Sebagai contoh, dapat mengambil imej dan menukarnya kepada imej lain untuk mencipta data sintetik (seperti imej bersegmen) sangat berguna untuk melatih model kereta pandu sendiri. Satu lagi aplikasi yang diuji ialah reka bentuk peta, di mana model itu mampu melakukan kedua-dua transformasi (pandangan satelit ke peta dan sebaliknya). Transformasi flip imej juga boleh digunakan pada seni bina, dengan model membuat pengesyoran tentang cara menyelesaikan projek yang belum selesai.
Salah satu aplikasi penukaran imej yang paling menarik ialah mengubah lukisan mudah menjadi landskap atau lukisan yang cantik.
Sejak beberapa tahun kebelakangan ini, beberapa kaedah telah dibangunkan untuk menyelesaikan masalah terjemahan imej-ke-imej dengan memanfaatkan model generatif . Kaedah yang paling biasa digunakan adalah berdasarkan seni bina berikut:
Pix2Pix ialah model berasaskan GAN bersyarat. Ini bermakna seni binanya terdiri daripada rangkaian Generator (G) dan Discriminator (D). Kedua-dua rangkaian dilatih dalam permainan lawan, di mana matlamat G adalah untuk menjana imej baharu yang serupa dengan set data, dan D perlu memutuskan sama ada imej itu dijana (palsu) atau daripada set data (benar).
Perbezaan utama antara Pix2Pix dan model GAN lain ialah: (1) Penjana pertama mengambil imej sebagai input untuk memulakan proses penjanaan, manakala GAN biasa menggunakan hingar rawak; (2) Pix2Pix diselia sepenuhnya model , yang bermaksud set data terdiri daripada pasangan imej daripada dua domain.
Seni bina yang diterangkan dalam makalah ditakrifkan oleh U-Net untuk penjana dan Diskriminator Markovian atau Patch Discriminator untuk diskriminator:
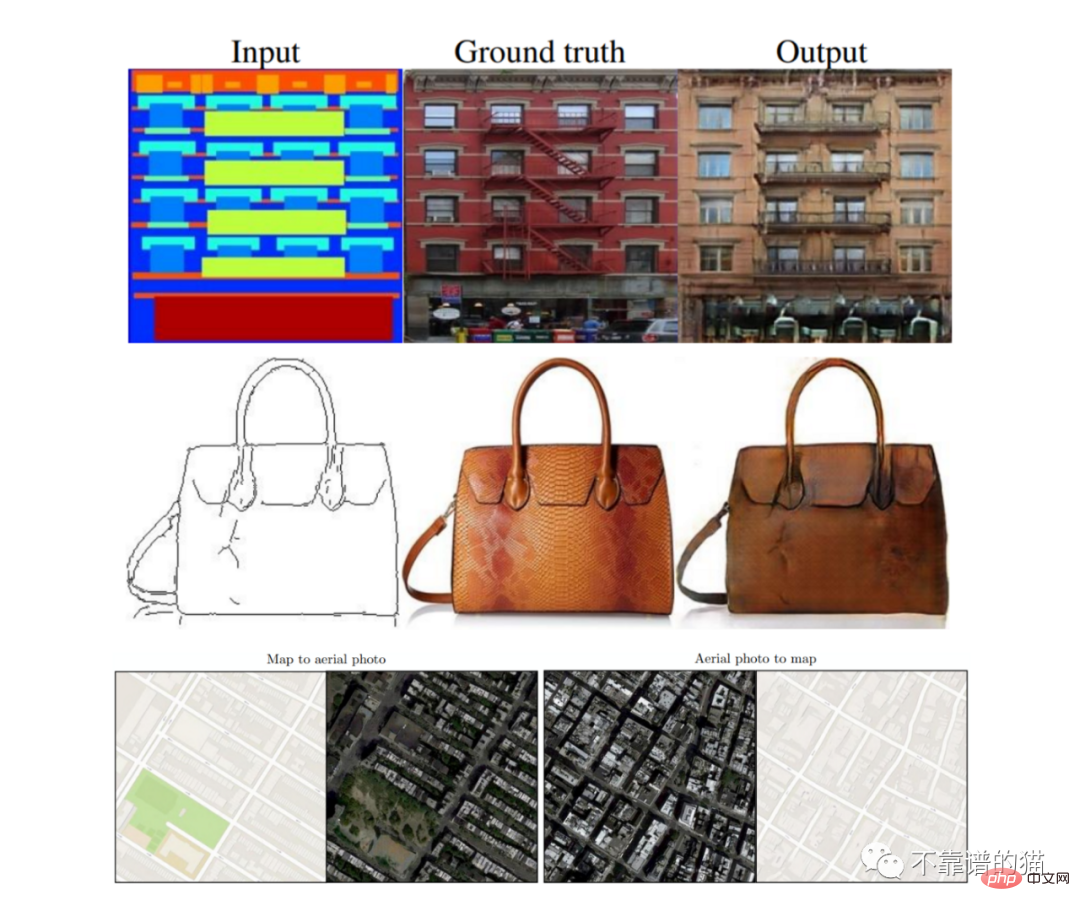
Keputusan Pix2Pix
Dalam Pix2Pix, proses latihan diselia sepenuhnya ( iaitu kita memerlukan pasangan input imej). Tujuan kaedah UNIT adalah untuk mempelajari fungsi yang memetakan imej A kepada imej B tanpa latihan pada dua imej berpasangan.
Model bermula dengan mengandaikan bahawa dua domain (A dan B) berkongsi ruang terpendam sepunya (Z). Secara intuitif, kita boleh memikirkan ruang terpendam ini sebagai peringkat perantaraan antara domain imej A dan B. Jadi, menggunakan contoh lukisan-ke-imej, kita boleh menggunakan ruang terpendam yang sama untuk menjana imej lukisan ke belakang atau untuk melihat imej yang menakjubkan ke hadapan (lihat Rajah X).
Dalam rajah: (a) ruang terpendam yang dikongsi. (b) Seni bina UNIT: , penjana G2, D1, D2 diskriminator. Garis putus-putus mewakili lapisan yang dikongsi antara rangkaian.
Model UNIT dibangunkan di bawah sepasang seni bina VAE-GAN (lihat gambar di atas), di mana lapisan terakhir pengekod (E1, E2) dan lapisan pertama penjana (G1, G2) dikongsi .

hasil UNIT
Palet ialah model resapan bersyarat yang dibangunkan oleh pasukan penyelidik Google Kanada. Model ini dilatih untuk melaksanakan 4 tugas berbeza yang berkaitan dengan penukaran imej, menghasilkan hasil yang berkualiti tinggi:
(i) Pewarnaan: Menambah warna pada imej skala kelabu
(ii) Mengecat: Mengisi pengguna -kawasan imej yang ditentukan dengan kandungan realistik
(iii) Nyahpangkas: Membesarkan bingkai imej
(iv) Pemulihan JPEG: Memulihkan imej JPEG yang rosak
Dalam kertas kerja, penulis meneroka perbezaan antara model umum berbilang tugas dan berbilang model khusus, kedua-duanya dilatih untuk satu juta lelaran. Seni bina model adalah berdasarkan model U-Net bersyarat kelas Dhariwal dan Nichol 2021, menggunakan saiz kelompok 1024 imej untuk langkah latihan 1M. Praproses dan tala pelan hingar sebagai hiperparameter, gunakan pelan berbeza untuk latihan dan ramalan.

Hasil Palet
Sila ambil perhatian bahawa walaupun dua model berikut tidak direka khusus untuk transformasi imej , tetapi mereka adalah langkah yang jelas ke hadapan dalam membawa model berkuasa seperti transformer ke dalam bidang penglihatan komputer.
Vision Transformers (ViT) ialah pengubahsuaian seni bina Transformers (Vaswani et al., 2017) dan dibangunkan untuk klasifikasi imej. Model mengambil imej sebagai input dan mengeluarkan kebarangkalian kepunyaan setiap kelas yang ditentukan.
Masalah utama ialah Transformer direka untuk mengambil jujukan satu dimensi sebagai input, bukan matriks dua dimensi. Untuk mengisih, pengarang mengesyorkan untuk membahagikan imej kepada ketulan kecil, memikirkan imej sebagai urutan (atau ayat dalam NLP) dan ketulan sebagai token (atau perkataan).
Untuk meringkaskan secara ringkas, kita boleh membahagikan keseluruhan proses kepada 3 peringkat:
1) Pembenaman: belah dan ratakan kepingan kecil → gunakan transformasi linear → tambah tag kelas (tag ini akan Sebagai ringkasan imej dipertimbangkan semasa mengelaskan) → Pembenaman kedudukan
2) Blok Transformer-Encoder: Letakkan tampalan terbenam ke dalam satu siri blok pengekod pengubah. Mekanisme perhatian mempelajari bahagian imej yang hendak difokuskan.
3) Pengepala MLP Klasifikasi: Lulus token kelas melalui pengepala MLP, yang menghasilkan kebarangkalian akhir bahawa imej itu tergolong dalam setiap kelas.
Kebaikan menggunakan ViT: susunannya kekal tidak berubah. Berbanding dengan CNN, Transformer tidak terjejas oleh terjemahan (perubahan kedudukan elemen) dalam imej.
Kelemahan: Memerlukan sejumlah besar data berlabel untuk latihan (sekurang-kurangnya 14M imej)
TransGAN ialah model GAN berasaskan transformasi yang direka untuk penjanaan imej dan tidak tidak menggunakan sebarang lapisan konvolusi. Sebaliknya, penjana dan diskriminator terdiri daripada satu siri Transformer yang disambungkan oleh blok pensampelan naik dan turun.
Pas hadapan penjana mengambil tatasusunan sampel hingar rawak satu dimensi dan menghantarnya melalui MLP. Secara intuitif, kita boleh memikirkan tatasusunan sebagai ayat dan nilai piksel sebagai perkataan (perhatikan bahawa tatasusunan 64 elemen boleh dibentuk semula menjadi imej 8✕8 bagi 1 saluran Seterusnya, pengarang menggunakan A siri Transformer blok, setiap satu diikuti dengan lapisan upsampling yang menggandakan saiz tatasusunan (imej).
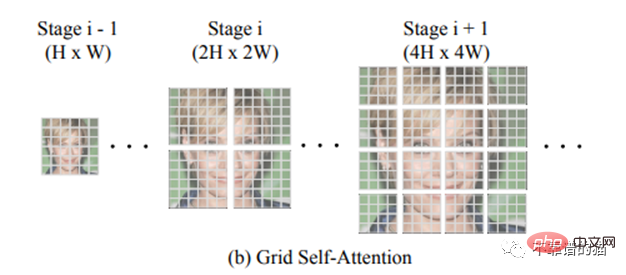
Ciri utama TransGAN ialah Grid-self-attention. Apabila mencapai imej berdimensi tinggi (iaitu tatasusunan yang sangat panjang 32✕32 = 1024), menggunakan pengubah boleh membawa kepada kos letupan mekanisme perhatian kendiri, kerana anda perlu membandingkan setiap piksel tatasusunan 1024 dengan kesemua 255 piksel yang mungkin ( dimensi RGB). Oleh itu, bukannya mengira korespondensi antara token yang diberikan dan semua token lain, perhatian kendiri grid membahagikan peta ciri dimensi penuh kepada beberapa grid tidak bertindih dan mengira interaksi token dalam setiap grid tempatan .
Seni bina diskriminator sangat serupa dengan ViT yang dipetik sebelum ini.

Hasil TransGAN pada set data berbeza
Atas ialah kandungan terperinci Lima model AI yang menjanjikan untuk terjemahan imej. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Aplikasi kecerdasan buatan dalam kehidupan
Aplikasi kecerdasan buatan dalam kehidupan
 Apakah konsep asas kecerdasan buatan
Apakah konsep asas kecerdasan buatan
 Bagaimana untuk mendapatkan alamat url
Bagaimana untuk mendapatkan alamat url
 Perkara yang perlu dilakukan mengenai ralat sambungan
Perkara yang perlu dilakukan mengenai ralat sambungan
 Peranan fungsi float() dalam python
Peranan fungsi float() dalam python
 Bagaimana untuk menetapkan pembalut baris automatik dalam perkataan
Bagaimana untuk menetapkan pembalut baris automatik dalam perkataan
 Apakah yang perlu saya lakukan jika pemacu C saya bertukar merah?
Apakah yang perlu saya lakukan jika pemacu C saya bertukar merah?
 Bagaimana oracle berputar
Bagaimana oracle berputar








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



