

Bagaimana untuk menilai kebolehpercayaan asas teori pembelajaran mesin?

Dalam bidang pembelajaran mesin, sesetengah model sangat berkesan, tetapi kami tidak pasti sepenuhnya mengapa. Sebaliknya, beberapa bidang penyelidikan yang agak difahami mempunyai kebolehgunaan terhad dalam amalan. Artikel ini meneroka kemajuan dalam pelbagai subbidang berdasarkan utiliti dan pemahaman teori pembelajaran mesin.

Utiliti eksperimen di sini ialah pertimbangan menyeluruh yang mengambil kira keluasan kebolehgunaan sesuatu kaedah, kemudahan pelaksanaan, dan faktor yang paling penting, kegunaan realiti dalam dunia. Sesetengah kaedah bukan sahaja sangat praktikal, tetapi juga mempunyai pelbagai aplikasi manakala beberapa kaedah, walaupun sangat berkuasa, terhad kepada kawasan tertentu. Kaedah yang boleh dipercayai, boleh diramal dan bebas daripada kelemahan utama dianggap mempunyai utiliti yang lebih tinggi.
Apa yang dipanggil pemahaman teori adalah untuk mempertimbangkan kebolehtafsiran kaedah model, iaitu, apakah hubungan antara input dan output, bagaimana untuk mendapatkan hasil yang diharapkan, apakah mekanisme dalaman kaedah ini, dan pertimbangkan kaedah yang terlibat Kedalaman dan kesempurnaan dokumentasi.
Kaedah dengan pemahaman teori yang rendah biasanya menggunakan kaedah heuristik atau sejumlah besar kaedah percubaan dan kesilapan dalam pelaksanaan kaedah dengan pemahaman teori yang tinggi selalunya mempunyai pelaksanaan formula dengan asas teori yang kukuh dan hasil yang boleh diramal. Kaedah yang lebih mudah, seperti regresi linear, mempunyai batas atas teori yang lebih rendah, manakala kaedah yang lebih kompleks, seperti pembelajaran mendalam, mempunyai batas atas teori yang lebih tinggi. Apabila bercakap tentang kedalaman dan kesempurnaan kesusasteraan dalam bidang, bidang tersebut dinilai berdasarkan batas atas teori andaian bidang, yang bergantung sebahagiannya pada gerak hati.
Kita boleh membina matriks utiliti sebagai empat kuadran, dengan persilangan paksi mewakili domain rujukan hipotesis dengan pemahaman purata dan utiliti purata. Pendekatan ini membolehkan kita mentafsir medan secara kualitatif mengikut kuadran di mana ia berada Seperti yang ditunjukkan dalam rajah di bawah, medan dalam kuadran tertentu mungkin mempunyai beberapa atau semua ciri kuadran tersebut.
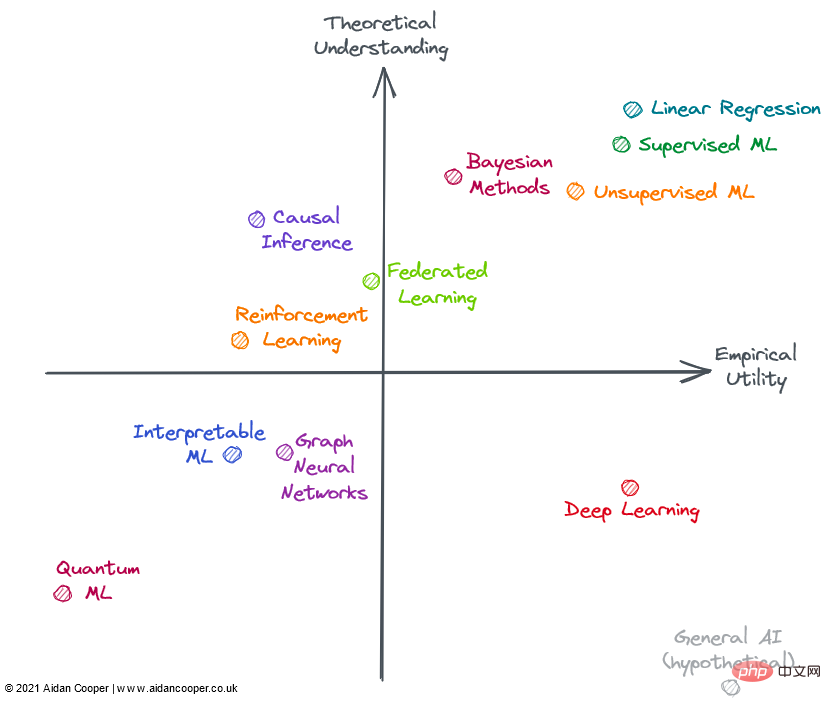
Secara amnya, kami menjangkakan utiliti dan pemahaman berkaitan secara longgar, supaya kaedah dengan tahap pemahaman teori yang tinggi adalah lebih berguna daripada kaedah dengan tahap pemahaman teori yang rendah. Ini bermakna kebanyakan medan hendaklah berada di kuadran kiri bawah atau kuadran kanan atas. Kawasan yang jauh dari pepenjuru kiri bawah kanan atas mewakili pengecualian. Biasanya, utiliti praktikal harus ketinggalan daripada teori kerana ia mengambil masa untuk menterjemahkan teori penyelidikan yang baru lahir kepada aplikasi praktikal. Oleh itu, pepenjuru ini harus berada di atas asal, bukan terus melaluinya.
Bidang Pembelajaran Mesin pada 2022
Bukan semua medan yang digambarkan di atas disertakan sepenuhnya dalam Pembelajaran Mesin (ML), tetapi semuanya boleh digunakan dalam konteks ML atau berkait rapat dengannya . Banyak bidang yang dinilai bertindih dan tidak dapat diterangkan dengan jelas: kaedah lanjutan dalam pembelajaran pengukuhan, pembelajaran bersekutu dan graf ML selalunya berdasarkan pembelajaran mendalam. Oleh itu, saya mempertimbangkan aspek pembelajaran tidak mendalam bagi kegunaan teori dan praktikal mereka.
Kuadran kanan atas: pemahaman tinggi, utiliti tinggi
Regresi linear ialah kaedah yang mudah, mudah difahami dan cekap. Walaupun sering dipandang remeh dan tidak dipedulikan. , tetapi keluasan penggunaannya dan asas teori yang menyeluruh meletakkannya di sudut kanan atas rajah.
Pembelajaran mesin tradisional telah berkembang menjadi bidang pemahaman teori dan praktikal yang tinggi. Algoritma ML yang kompleks, seperti pepohon keputusan yang dirangsang kecerunan (GBDT), telah ditunjukkan sering mengatasi regresi linear dalam beberapa tugas ramalan yang kompleks. Ini sudah tentu berlaku dengan masalah data besar. Boleh dikatakan, masih terdapat jurang dalam pemahaman teori model terparameter berlebihan, tetapi melaksanakan pembelajaran mesin adalah proses metodologi yang halus, dan apabila dilakukan dengan baik, model boleh berjalan dengan pasti dalam industri.
Walau bagaimanapun, kerumitan dan fleksibiliti tambahan memang membawa kepada beberapa ralat, itulah sebabnya saya meletakkan pembelajaran mesin di sebelah kiri regresi linear. Secara umum, pembelajaran mesin yang diselia adalah lebih canggih dan memberi kesan berbanding rakan sejawatnya yang tidak diselia, tetapi kedua-dua kaedah berkesan menyelesaikan ruang masalah yang berbeza.
Kaedah Bayesian mempunyai pengikut kultus pengamal yang menonjolkan keunggulannya berbanding kaedah statistik klasik yang lebih popular. Model Bayesian amat berguna dalam situasi tertentu: anggaran mata sahaja tidak mencukupi dan anggaran ketidakpastian adalah penting apabila data adalah terhad atau sangat tiada dan apabila anda memahami proses penjanaan data yang anda ingin sertakan secara eksplisit dalam jam model; Kegunaan model Bayesian dihadkan oleh fakta bahawa untuk banyak masalah anggaran titik adalah cukup baik dan orang ramai hanya lalai kepada kaedah bukan Bayesian. Lebih-lebih lagi, terdapat cara untuk mengukur ketidakpastian dalam ML tradisional (ia jarang digunakan). Selalunya lebih mudah untuk hanya menggunakan algoritma ML pada data tanpa perlu mempertimbangkan mekanisme penjanaan data dan sebelumnya. Model Bayesian juga mahal dari segi pengiraan dan akan mempunyai utiliti yang lebih besar jika kemajuan teori menghasilkan kaedah pensampelan dan penghampiran yang lebih baik.
Kuadran kanan bawah: pemahaman rendah, utiliti tinggi
Bertentangan dengan kemajuan dalam kebanyakan bidang, pembelajaran mendalam telah mencapai beberapa kejayaan yang menakjubkan, walaupun aspek teori telah terbukti secara asasnya sukar untuk mencapai kemajuan. Pembelajaran mendalam merangkumi banyak ciri pendekatan yang kurang diketahui: model tidak stabil, sukar dibina dengan pasti, mengkonfigurasi berdasarkan heuristik yang lemah dan menghasilkan keputusan yang tidak dapat diramalkan. Amalan yang boleh dipersoalkan seperti "tweaking" benih rawak adalah sangat biasa, dan mekanik model kerja sukar untuk dijelaskan. Walau bagaimanapun, pembelajaran mendalam terus meningkat dan mencapai tahap prestasi luar biasa dalam bidang seperti penglihatan komputer dan pemprosesan bahasa semula jadi, membuka dunia tugas yang tidak dapat difahami, seperti pemanduan autonomi.
Secara hipotesis, AI am akan menduduki sudut kanan bawah kerana, mengikut definisi, superintelligence berada di luar pemahaman manusia dan boleh digunakan untuk menyelesaikan sebarang masalah. Pada masa ini, ia dimasukkan hanya sebagai percubaan pemikiran.
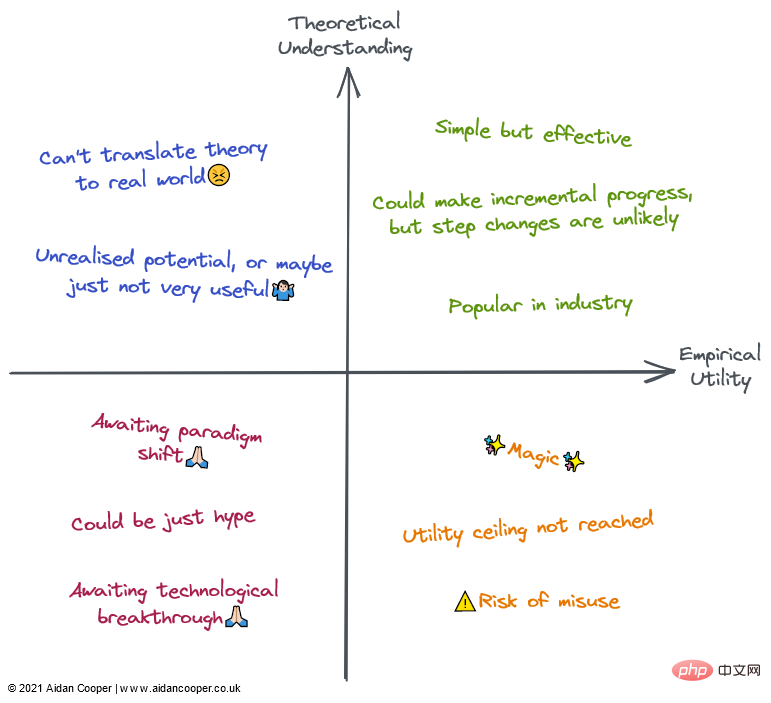
Penerangan kualitatif bagi setiap kuadran. Medan boleh diterangkan oleh beberapa atau semua perihalan dalam kawasan yang sepadan
Kuadran kiri atas: pemahaman tinggi, utiliti rendah
Kebanyakan bentuk inferens sebab bukan pembelajaran mesin, tetapi kadangkala ia adalah , dan Sentiasa berminat dengan model ramalan. Kausalitas boleh dibahagikan kepada percubaan terkawal rawak (RCT) dan kaedah inferens sebab yang lebih canggih, yang cuba mengukur hubungan sebab akibat daripada data pemerhatian. RCT adalah mudah dalam teori dan memberikan hasil yang ketat, tetapi selalunya mahal dan tidak praktikal—jika tidak mustahil—untuk dijalankan di dunia nyata dan oleh itu mempunyai utiliti yang terhad. Kaedah inferens sebab pada dasarnya meniru RCT tanpa melakukan apa-apa, yang menjadikannya lebih mudah untuk dilakukan, tetapi terdapat beberapa batasan dan perangkap yang boleh membatalkan keputusan. Secara keseluruhannya, kausalitas kekal sebagai usaha yang mengecewakan, di mana kaedah semasa selalunya tidak mencukupi untuk soalan yang ingin kita tanyakan, melainkan soalan ini boleh diterokai melalui ujian terkawal rawak atau ia sesuai dengan kemas ke dalam beberapa rangka kerja (cth., sebagai hasil tidak sengaja daripada "semula jadi percubaan").
Pembelajaran Bersekutu (FL) ialah konsep hebat yang kurang mendapat perhatian - mungkin kerana aplikasinya yang paling menarik memerlukan pengedaran kepada sejumlah besar peranti telefon pintar, jadi FL hanya mempunyai dua pemain Untuk benar-benar menyelidik: Apple dan Google . Kes penggunaan lain untuk FL wujud, seperti mengumpulkan set data proprietari, tetapi terdapat cabaran politik dan logistik dalam menyelaraskan inisiatif ini, mengehadkan kegunaannya dalam amalan. Namun, untuk apa yang terdengar seperti konsep mewah (kira-kira diringkaskan sebagai: "Letakkan model ke dalam data, bukannya data ke dalam model"), FL berfungsi dan mempunyai aplikasi dalam bidang seperti ramalan teks papan kekunci dan cadangan berita yang diperibadikan kisah kejayaan. Teori asas dan teknologi di sebalik FL nampaknya mencukupi untuk aplikasi FL yang lebih luas.
Pembelajaran pengukuhan (RL) telah mencapai tahap keupayaan yang belum pernah terjadi sebelumnya dalam permainan seperti catur, Go, poker dan DotA. Tetapi di luar permainan video dan persekitaran simulasi, pembelajaran pengukuhan masih belum diterjemahkan dengan meyakinkan ke dalam aplikasi dunia sebenar. Robotik sepatutnya menjadi sempadan seterusnya dalam RL, tetapi itu tidak berlaku - realiti kelihatan lebih mencabar daripada persekitaran mainan yang sangat terhad. Walau bagaimanapun, pencapaian RL setakat ini adalah memberangsangkan, dan seseorang yang benar-benar menyukai catur mungkin berpendapat bahawa utilitinya sepatutnya lebih tinggi. Saya ingin melihat RL menyedari beberapa aplikasi praktikalnya yang berpotensi sebelum meletakkannya di sebelah kanan matriks.
Kuadran kiri bawah: pemahaman rendah, utiliti rendah
Rangkaian saraf graf (GNN) kini merupakan bidang yang sangat popular dalam pembelajaran mesin dan telah mencapai hasil yang menjanjikan dalam banyak bidang. Tetapi bagi kebanyakan contoh ini, tidak jelas sama ada GNN adalah lebih baik daripada alternatif yang menggunakan lebih banyak data berstruktur tradisional yang dipasangkan dengan seni bina pembelajaran mendalam. Masalah di mana data berstruktur graf secara semula jadi, seperti molekul dalam cheminformatics, nampaknya mempunyai keputusan GNN yang lebih menarik (walaupun ini secara amnya lebih rendah daripada kaedah berkaitan bukan graf). Lebih daripada dalam kebanyakan bidang, nampaknya terdapat jurang yang besar antara alat sumber terbuka untuk melatih GNN pada skala dan alatan dalaman yang digunakan dalam industri, yang mengehadkan kemungkinan GNN besar di luar taman berdinding ini. Kerumitan dan keluasan bidang mencadangkan had atas teori yang tinggi, jadi perlu ada ruang untuk GNN matang dan menunjukkan kelebihan untuk tugas tertentu secara meyakinkan, yang akan membawa kepada utiliti yang lebih besar. GNN juga boleh mendapat manfaat daripada kemajuan teknologi, kerana graf pada masa ini tidak sesuai secara semula jadi pada perkakasan pengkomputeran sedia ada.
Pembelajaran Mesin Boleh Ditafsir (IML) ialah bidang penting dan menjanjikan yang terus mendapat perhatian. Teknologi seperti SHAP dan LIME telah menjadi alat yang sangat berguna untuk menyoal siasat model ML. Walau bagaimanapun, disebabkan penggunaan terhad, kegunaan pendekatan sedia ada masih belum direalisasikan sepenuhnya—amalan terbaik yang teguh dan garis panduan pelaksanaan masih belum diwujudkan. Walau bagaimanapun, kelemahan utama semasa IML ialah ia tidak menangani persoalan penyebab yang kita benar-benar berminat. IML menerangkan cara model membuat ramalan, tetapi tidak menerangkan bagaimana data asas berkaitan secara kausal dengannya (walaupun ia sering disalahtafsirkan seperti ini). Sebelum kemajuan teori utama, penggunaan IML yang sah kebanyakannya terhad kepada penyahpepijatan/pemantauan model dan penjanaan hipotesis.
Pembelajaran Mesin Kuantum (QML) berada di luar ruang roda saya, tetapi pada masa ini nampaknya merupakan latihan hipotesis yang menunggu dengan sabar untuk komputer kuantum yang berdaya maju tersedia. Sehingga itu, QML duduk tidak ketara di sudut kiri bawah.
Kemajuan tambahan, lonjakan teknologi dan anjakan paradigma
Terdapat tiga mekanisme utama di mana bidang ini merentasi pemahaman teori dan matriks utiliti empirikal (Rajah 2).
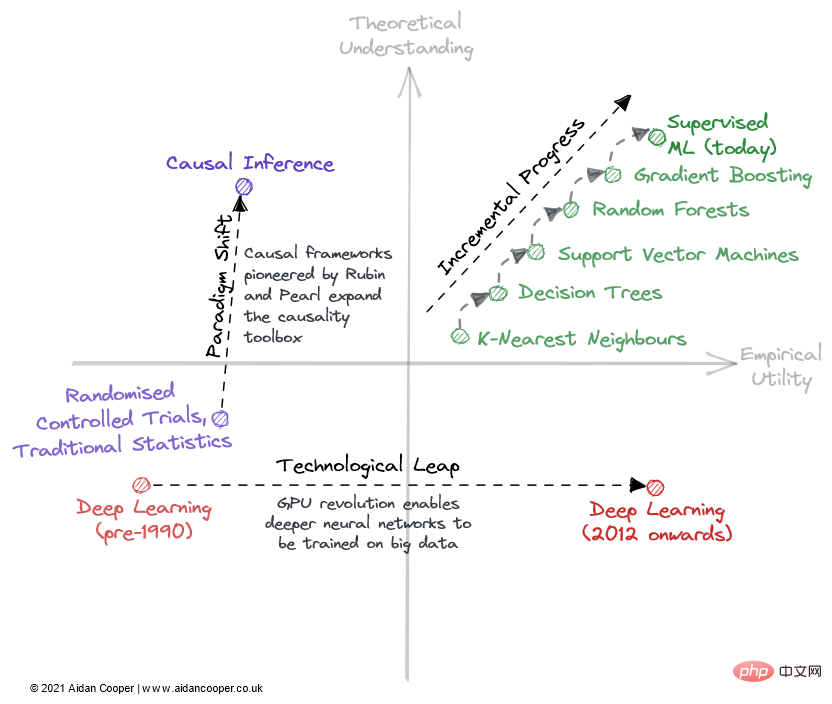
Contoh ilustrasi cara sesuatu matriks boleh dilalui oleh medan.
Janjang progresif ialah janjang perlahan dan mantap yang bergerak ke atas medan inci di sebelah kanan matriks. Contoh yang baik tentang ini ialah pembelajaran mesin yang diselia sejak beberapa dekad yang lalu, pada masa itu algoritma ramalan yang semakin berkesan telah diperhalusi dan diterima pakai, memberikan kami kotak alat berkuasa yang kami nikmati hari ini. Kemajuan tambahan ialah status quo dalam semua bidang matang, kecuali untuk tempoh pergerakan yang lebih dramatik akibat lonjakan teknologi dan anjakan paradigma.
Hasil daripada lonjakan teknologi, beberapa bidang telah melihat perubahan langkah dalam kemajuan saintifik. Bidang *pembelajaran mendalam* tidak dirungkai oleh asas teorinya, yang ditemui lebih 20 tahun sebelum ledakan pembelajaran mendalam pada 2010-an - ia adalah pemprosesan selari yang didayakan oleh GPU pengguna yang menyemarakkan kebangkitannya. Lompatan teknologi biasanya muncul sebagai lompatan ke kanan di sepanjang paksi utiliti empirikal. Walau bagaimanapun, tidak semua kemajuan yang diterajui teknologi adalah pesat. Pembelajaran mendalam hari ini dicirikan oleh kemajuan tambahan yang dicapai dengan melatih model yang lebih besar dan lebih besar menggunakan lebih banyak kuasa pengkomputeran dan perkakasan yang semakin khusus.
Mekanisme muktamad kemajuan saintifik dalam rangka kerja ini ialah anjakan paradigma. Seperti yang dinyatakan oleh Thomas Kuhn dalam bukunya The Structure of Scientific Revolutions, anjakan paradigma mewakili perubahan penting dalam konsep asas dan amalan eksperimen disiplin saintifik. Rangka kerja kausal yang dipelopori oleh Donald Rubin dan Judea Pearl adalah satu contoh sedemikian, meningkatkan bidang kausalitas daripada percubaan terkawal rawak dan analisis statistik tradisional kepada disiplin matematik yang lebih berkuasa dalam bentuk inferens sebab akibat. Anjakan paradigma sering nyata sebagai pergerakan ke atas dalam pemahaman, yang mungkin mengikuti atau disertai dengan peningkatan dalam utiliti.
Walau bagaimanapun, anjakan paradigma boleh merentasi matriks ke mana-mana arah. Apabila rangkaian saraf (dan seterusnya rangkaian saraf yang mendalam) menetapkan diri mereka sebagai paradigma yang berasingan daripada ML tradisional, ini pada mulanya sepadan dengan penurunan dalam praktikal dan pemahaman. Banyak bidang baru muncul bercabang dari bidang penyelidikan yang lebih mantap dengan cara ini.
Revolusi Saintifik Ramalan dan Pembelajaran Mendalam
Untuk meringkaskan, berikut ialah beberapa ramalan spekulatif tentang perkara yang saya fikir mungkin berlaku pada masa hadapan (Jadual 1). Medan di kuadran atas sebelah kanan ditinggalkan kerana terlalu matang untuk melihat kemajuan yang ketara.
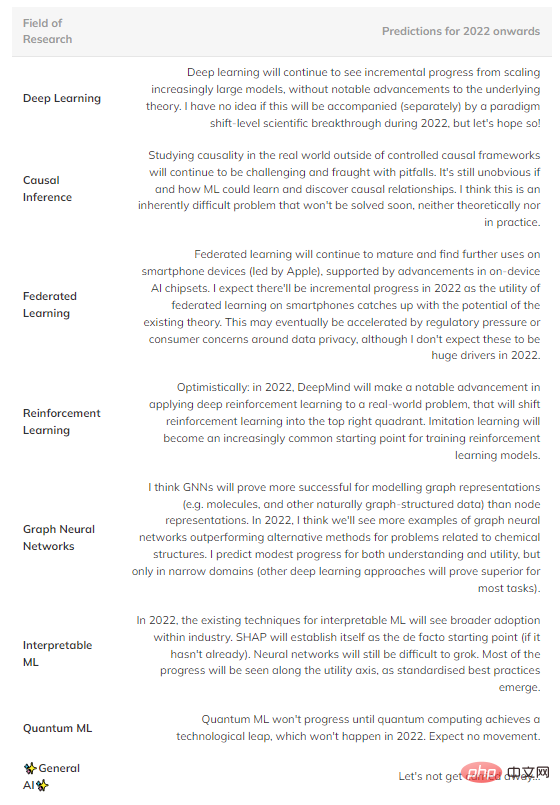
Jadual 1: Ramalan kemajuan masa depan dalam beberapa bidang utama pembelajaran mesin.
Walau bagaimanapun, pemerhatian yang lebih penting daripada bagaimana bidang individu berkembang ialah trend umum ke arah empirisme dan peningkatan kesediaan untuk mengakui pemahaman teori yang komprehensif.
Daripada pengalaman sejarah, teori (hipotesis) biasanya muncul dahulu, dan kemudian idea dirumuskan. Tetapi pembelajaran mendalam telah membawa kepada proses saintifik baru yang mematahkan ini. Iaitu, kaedah dijangka menunjukkan prestasi terkini sebelum sesiapa memberi tumpuan kepada teori. Keputusan empirikal adalah raja, teori adalah pilihan.
Ini telah membawa kepada permainan meluas secara sistematik dalam penyelidikan pembelajaran mesin untuk mendapatkan yang terkini dengan hanya mengubah suai kaedah sedia ada dan bergantung pada rawak untuk mengatasi garis dasar, dan bukannya memajukan teori secara bermakna dalam lapangan. Tetapi mungkin itulah harga yang kami bayar untuk gelombang ledakan pembelajaran mesin baharu ini.
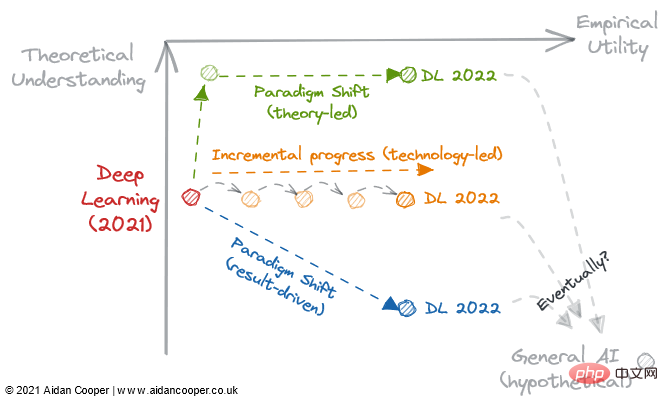
Rajah 3: 3 trajektori yang berpotensi untuk pembangunan pembelajaran mendalam pada tahun 2022.
Sama ada pembelajaran mendalam secara tidak dapat dipulihkan menjadi proses yang didorong oleh hasil dan mengasingkan pemahaman teori kepada pilihan, 2022 mungkin menjadi titik perubahan. Kita harus memikirkan soalan berikut:
Adakah penemuan teori membolehkan pemahaman kita mengejar kepraktisan dan mengubah pembelajaran mendalam kepada disiplin yang lebih berstruktur seperti pembelajaran mesin tradisional?
Adakah literatur pembelajaran mendalam sedia ada mencukupi untuk membolehkan utiliti meningkat selama-lamanya, hanya dengan menskalakan kepada model yang lebih besar dan lebih besar?
Atau adakah kejayaan empirikal akan membawa kita lebih jauh ke bawah lubang arnab, ke paradigma baharu yang meningkatkan utiliti, walaupun kita kurang mengetahui tentangnya?
Adakah mana-mana laluan ini membawa kepada kecerdasan buatan am? Hanya masa yang akan menentukan.
Atas ialah kandungan terperinci Bagaimana untuk menilai kebolehpercayaan asas teori pembelajaran mesin?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Bytedance Cutting melancarkan keahlian super SVIP: 499 yuan untuk langganan tahunan berterusan, menyediakan pelbagai fungsi AI
Jun 28, 2024 am 03:51 AM
Bytedance Cutting melancarkan keahlian super SVIP: 499 yuan untuk langganan tahunan berterusan, menyediakan pelbagai fungsi AI
Jun 28, 2024 am 03:51 AM
Laman web ini melaporkan pada 27 Jun bahawa Jianying ialah perisian penyuntingan video yang dibangunkan oleh FaceMeng Technology, anak syarikat ByteDance Ia bergantung pada platform Douyin dan pada asasnya menghasilkan kandungan video pendek untuk pengguna platform tersebut Windows , MacOS dan sistem pengendalian lain. Jianying secara rasmi mengumumkan peningkatan sistem keahliannya dan melancarkan SVIP baharu, yang merangkumi pelbagai teknologi hitam AI, seperti terjemahan pintar, penonjolan pintar, pembungkusan pintar, sintesis manusia digital, dsb. Dari segi harga, yuran bulanan untuk keratan SVIP ialah 79 yuan, yuran tahunan ialah 599 yuan (nota di laman web ini: bersamaan dengan 49.9 yuan sebulan), langganan bulanan berterusan ialah 59 yuan sebulan, dan langganan tahunan berterusan ialah 499 yuan setahun (bersamaan dengan 41.6 yuan sebulan) . Di samping itu, pegawai yang dipotong juga menyatakan bahawa untuk meningkatkan pengalaman pengguna, mereka yang telah melanggan VIP asal
 Pembantu pengekodan AI yang ditambah konteks menggunakan Rag dan Sem-Rag
Jun 10, 2024 am 11:08 AM
Pembantu pengekodan AI yang ditambah konteks menggunakan Rag dan Sem-Rag
Jun 10, 2024 am 11:08 AM
Tingkatkan produktiviti, kecekapan dan ketepatan pembangun dengan menggabungkan penjanaan dipertingkatkan semula dan memori semantik ke dalam pembantu pengekodan AI. Diterjemah daripada EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, pengarang JanakiramMSV. Walaupun pembantu pengaturcaraan AI asas secara semulajadi membantu, mereka sering gagal memberikan cadangan kod yang paling relevan dan betul kerana mereka bergantung pada pemahaman umum bahasa perisian dan corak penulisan perisian yang paling biasa. Kod yang dijana oleh pembantu pengekodan ini sesuai untuk menyelesaikan masalah yang mereka bertanggungjawab untuk menyelesaikannya, tetapi selalunya tidak mematuhi piawaian pengekodan, konvensyen dan gaya pasukan individu. Ini selalunya menghasilkan cadangan yang perlu diubah suai atau diperhalusi agar kod itu diterima ke dalam aplikasi
 Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Untuk mengetahui lebih lanjut tentang AIGC, sila layari: 51CTOAI.x Komuniti https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou berbeza daripada bank soalan tradisional yang boleh dilihat di mana-mana sahaja di Internet memerlukan pemikiran di luar kotak. Model Bahasa Besar (LLM) semakin penting dalam bidang sains data, kecerdasan buatan generatif (GenAI) dan kecerdasan buatan. Algoritma kompleks ini meningkatkan kemahiran manusia dan memacu kecekapan dan inovasi dalam banyak industri, menjadi kunci kepada syarikat untuk kekal berdaya saing. LLM mempunyai pelbagai aplikasi Ia boleh digunakan dalam bidang seperti pemprosesan bahasa semula jadi, penjanaan teks, pengecaman pertuturan dan sistem pengesyoran. Dengan belajar daripada sejumlah besar data, LLM dapat menjana teks
 Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Model Bahasa Besar (LLM) dilatih pada pangkalan data teks yang besar, di mana mereka memperoleh sejumlah besar pengetahuan dunia sebenar. Pengetahuan ini dibenamkan ke dalam parameter mereka dan kemudiannya boleh digunakan apabila diperlukan. Pengetahuan tentang model ini "diperbaharui" pada akhir latihan. Pada akhir pra-latihan, model sebenarnya berhenti belajar. Selaraskan atau perhalusi model untuk mempelajari cara memanfaatkan pengetahuan ini dan bertindak balas dengan lebih semula jadi kepada soalan pengguna. Tetapi kadangkala pengetahuan model tidak mencukupi, dan walaupun model boleh mengakses kandungan luaran melalui RAG, ia dianggap berfaedah untuk menyesuaikan model kepada domain baharu melalui penalaan halus. Penalaan halus ini dilakukan menggunakan input daripada anotasi manusia atau ciptaan LLM lain, di mana model menemui pengetahuan dunia sebenar tambahan dan menyepadukannya
 Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) set data memainkan peranan penting dalam mempromosikan penyelidikan pemprosesan bahasa semula jadi (NLP). Set data QA berkualiti tinggi bukan sahaja boleh digunakan untuk memperhalusi model, tetapi juga menilai dengan berkesan keupayaan model bahasa besar (LLM), terutamanya keupayaan untuk memahami dan menaakul tentang pengetahuan saintifik. Walaupun pada masa ini terdapat banyak set data QA saintifik yang meliputi bidang perubatan, kimia, biologi dan bidang lain, set data ini masih mempunyai beberapa kekurangan. Pertama, borang data adalah agak mudah, kebanyakannya adalah soalan aneka pilihan. Ia mudah dinilai, tetapi mengehadkan julat pemilihan jawapan model dan tidak dapat menguji sepenuhnya keupayaan model untuk menjawab soalan saintifik. Sebaliknya, Soal Jawab terbuka
 Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Pembelajaran mesin ialah cabang penting kecerdasan buatan yang memberikan komputer keupayaan untuk belajar daripada data dan meningkatkan keupayaan mereka tanpa diprogramkan secara eksplisit. Pembelajaran mesin mempunyai pelbagai aplikasi dalam pelbagai bidang, daripada pengecaman imej dan pemprosesan bahasa semula jadi kepada sistem pengesyoran dan pengesanan penipuan, dan ia mengubah cara hidup kita. Terdapat banyak kaedah dan teori yang berbeza dalam bidang pembelajaran mesin, antaranya lima kaedah yang paling berpengaruh dipanggil "Lima Sekolah Pembelajaran Mesin". Lima sekolah utama ialah sekolah simbolik, sekolah sambungan, sekolah evolusi, sekolah Bayesian dan sekolah analogi. 1. Simbolisme, juga dikenali sebagai simbolisme, menekankan penggunaan simbol untuk penaakulan logik dan ekspresi pengetahuan. Aliran pemikiran ini percaya bahawa pembelajaran adalah proses penolakan terbalik, melalui sedia ada
 Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama
Jul 17, 2024 pm 06:37 PM
Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama
Jul 17, 2024 pm 06:37 PM
Editor |. KX Dalam bidang penyelidikan dan pembangunan ubat, meramalkan pertalian pengikatan protein dan ligan dengan tepat dan berkesan adalah penting untuk pemeriksaan dan pengoptimuman ubat. Walau bagaimanapun, kajian semasa tidak mengambil kira peranan penting maklumat permukaan molekul dalam interaksi protein-ligan. Berdasarkan ini, penyelidik dari Universiti Xiamen mencadangkan rangka kerja pengekstrakan ciri berbilang mod (MFE) novel, yang buat pertama kalinya menggabungkan maklumat mengenai permukaan protein, struktur dan jujukan 3D, dan menggunakan mekanisme perhatian silang untuk membandingkan ciri modaliti yang berbeza penjajaran. Keputusan eksperimen menunjukkan bahawa kaedah ini mencapai prestasi terkini dalam meramalkan pertalian mengikat protein-ligan. Tambahan pula, kajian ablasi menunjukkan keberkesanan dan keperluan maklumat permukaan protein dan penjajaran ciri multimodal dalam rangka kerja ini. Penyelidikan berkaitan bermula dengan "S
 Meletakkan pasaran seperti AI, GlobalFoundries memperoleh teknologi gallium nitrida Tagore Technology dan pasukan berkaitan
Jul 15, 2024 pm 12:21 PM
Meletakkan pasaran seperti AI, GlobalFoundries memperoleh teknologi gallium nitrida Tagore Technology dan pasukan berkaitan
Jul 15, 2024 pm 12:21 PM
Menurut berita dari laman web ini pada 5 Julai, GlobalFoundries mengeluarkan kenyataan akhbar pada 1 Julai tahun ini, mengumumkan pemerolehan teknologi power gallium nitride (GaN) Tagore Technology dan portfolio harta intelek, dengan harapan dapat mengembangkan bahagian pasarannya dalam kereta dan Internet of Things dan kawasan aplikasi pusat data kecerdasan buatan untuk meneroka kecekapan yang lebih tinggi dan prestasi yang lebih baik. Memandangkan teknologi seperti AI generatif terus berkembang dalam dunia digital, galium nitrida (GaN) telah menjadi penyelesaian utama untuk pengurusan kuasa yang mampan dan cekap, terutamanya dalam pusat data. Laman web ini memetik pengumuman rasmi bahawa semasa pengambilalihan ini, pasukan kejuruteraan Tagore Technology akan menyertai GLOBALFOUNDRIES untuk membangunkan lagi teknologi gallium nitride. G
