
 Peranti teknologi
AI
Bahasa pengaturcaraan OpenAI mempercepatkan penaakulan Bert 12 kali, dan enjin menarik perhatian
Peranti teknologi
AI
Bahasa pengaturcaraan OpenAI mempercepatkan penaakulan Bert 12 kali, dan enjin menarik perhatian
Bahasa pengaturcaraan OpenAI mempercepatkan penaakulan Bert 12 kali, dan enjin menarik perhatian

Sejauh manakah kuasa satu baris kod? Pustaka Kernl yang akan kami perkenalkan hari ini membolehkan pengguna menjalankan model pengubah Pytorch beberapa kali lebih pantas pada GPU dengan hanya satu baris kod, sekali gus mempercepatkan inferens model tersebut.
Secara khusus, dengan restu Kernl, kelajuan inferens Bert adalah 12 kali lebih pantas daripada garis dasar Memeluk Wajah. Pencapaian ini disebabkan terutamanya oleh Kernl menulis kernel GPU tersuai dalam bahasa pengaturcaraan OpenAI baharu Triton dan TorchDynamo. Pengarang projek adalah dari Lefebvre Sarrut.
Alamat GitHub: https://github.com/ELS-RD/kernl/
Berikut ialah perbandingan antara Kernl dan enjin inferens lain Nombor dalam kurungan dalam absis masing-masing mewakili saiz kelompok dan panjang jujukan, dan ordinat ialah pecutan inferens.
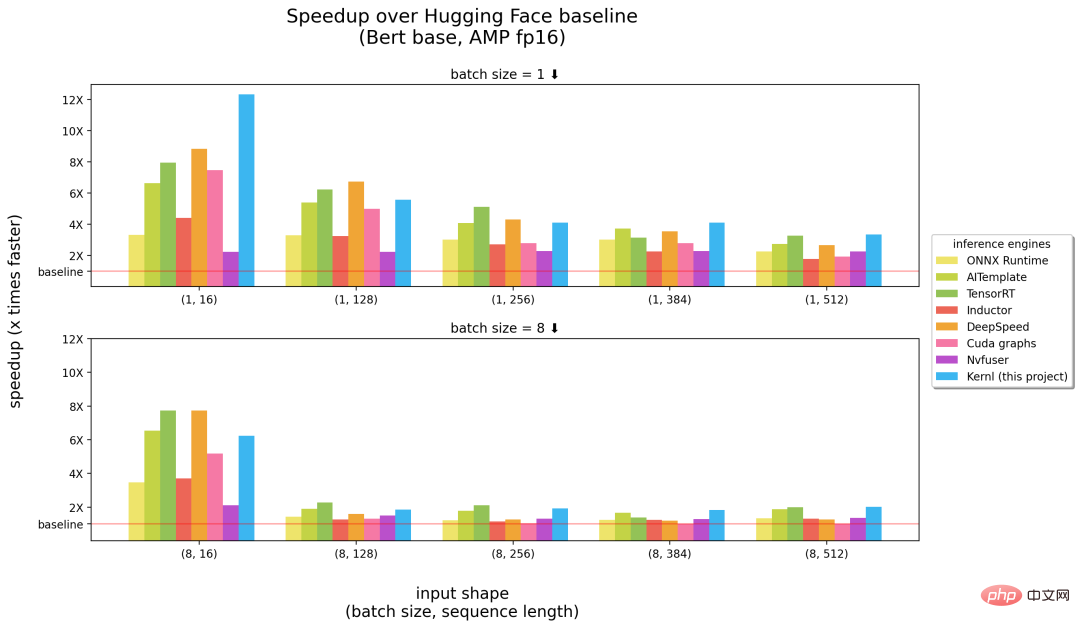
Tanda aras dijalankan pada GPU 3090 RTX dan CPU Intel 12 teras.
Daripada keputusan di atas, Kernl boleh dikatakan sebagai enjin inferens terpantas apabila melibatkan input jujukan panjang (betul-betul dalam gambar di atas ) separuh), hampir dengan TensorRT NVIDIA (separuh kiri dalam rajah di atas) pada jujukan input pendek. Jika tidak, kod kernel Kernl adalah sangat pendek dan mudah difahami serta diubah suai. Projek ini juga menambah penyahpepijat dan alat Triton (berdasarkan Fx) untuk memudahkan penggantian kernel, jadi tiada pengubahsuaian pada kod sumber model PyTorch diperlukan.
Pengarang projek Michaël Benesty meringkaskan penyelidikan ini Kernl yang mereka keluarkan adalah perpustakaan untuk mempercepatkan penaakulan transformer .
Mereka juga mengujinya pada T5 dan ia adalah 6 kali lebih pantas, dan Benesty berkata ini hanyalah permulaan.
Mengapa Kernl dicipta?
Di Lefebvre Sarrut, pengarang projek menjalankan beberapa model transformer dalam pengeluaran, beberapa daripadanya sensitif kependaman, terutamanya carian dan recsys. Mereka juga menggunakan OnnxRuntime dan TensorRT, malah mencipta perpustakaan OSS yang menggunakan transformer untuk berkongsi pengetahuan mereka dengan komuniti.
Baru-baru ini, pengarang telah menguji bahasa generatif dan bekerja keras untuk mempercepatkannya. Walau bagaimanapun, melakukan ini menggunakan alat tradisional telah terbukti sangat sukar. Pada pandangan mereka, Onnx adalah satu lagi format yang menarik Ia adalah format fail terbuka yang direka untuk pembelajaran mesin Ia digunakan untuk menyimpan model terlatih dan mempunyai sokongan perkakasan yang luas.
Walau bagaimanapun, ekosistem Onnx (terutamanya enjin inferens) mempunyai beberapa batasan semasa mereka berurusan dengan seni bina LLM baharu:
- Mengeksport model tanpa aliran kawalan ke Onnx adalah mudah kerana penjejakan boleh dipercayai. Tetapi tingkah laku dinamik adalah lebih sukar untuk diperoleh; >TensorRT tidak boleh mengurus 2 paksi dinamik untuk model pengubah dengan fail konfigurasi yang sama. Tetapi kerana anda biasanya ingin dapat memberikan input dengan panjang yang berbeza, anda perlu membina 1 model setiap saiz kelompok; ) dalam fail Terdapat beberapa batasan dari segi saiz dan perlu diselesaikan dengan menyimpan pemberat di luar model.
- Fakta yang sangat menjengkelkan ialah model baharu tidak akan dipercepatkan, anda perlu menunggu orang lain menulis kernel CUDA tersuai untuk ini. Bukannya penyelesaian sedia ada adalah buruk, salah satu perkara hebat tentang OnnxRuntime ialah sokongan berbilang perkakasannya, dan TensorRT diketahui sangat pantas.
- Jadi, pengarang projek mahu mempunyai pengoptimum sepantas TensorRT pada Python/PyTorch, itulah sebabnya mereka mencipta Kernl.
Bagaimana untuk melakukannya?
Jalur lebar memori biasanya merupakan hambatan pembelajaran mendalam Untuk mempercepatkan inferens, mengurangkan akses memori selalunya merupakan strategi yang baik. Pada urutan input pendek, kesesakan biasanya berkaitan dengan overhed CPU, yang mesti dihapuskan. Pengarang projek terutamanya menggunakan 3 teknologi berikut:
Yang pertama ialah OpenAI Triton, iaitu bahasa untuk menulis kernel GPU seperti CUDA. Jangan kelirukan dengan inferens Nvidia Triton pelayan lebih cekap. Penambahbaikan dicapai dengan gabungan beberapa operasi supaya pengiraan rantaian tanpa mengekalkan hasil perantaraan dalam memori GPU. Pengarang menggunakannya untuk menulis semula perhatian (digantikan dengan Flash Attention), lapisan linear dan pengaktifan, dan Layernorm/Rmsnorm.
Yang kedua ialah graf CUDA. Semasa langkah pemanasan, ia menyimpan setiap teras yang dilancarkan dan parameternya. Pengarang projek kemudian membina semula keseluruhan proses penaakulan.
Akhir sekali, terdapat TorchDynamo, prototaip yang dicadangkan oleh Meta untuk membantu pengarang projek menangani tingkah laku dinamik. Semasa langkah memanaskan badan, ia menjejaki model dan menyediakan graf Fx (graf pengiraan statik). Mereka menggantikan beberapa operasi graf Fx dengan kernel mereka sendiri, yang disusun semula dalam Python.
Pada masa hadapan, pelan hala tuju projek akan merangkumi pemanasan badan yang lebih pantas, inferens lusuh (tiada pengiraan kerugian dalam padding), sokongan latihan (sokongan jujukan panjang), sokongan berbilang GPU (berbilang -mod penyejajaran), kuantisasi (PTQ), ujian kernel Cutlass bagi kelompok baharu, dan sokongan perkakasan yang dipertingkatkan, dsb.
Sila rujuk projek asal untuk butiran lanjut.
Atas ialah kandungan terperinci Bahasa pengaturcaraan OpenAI mempercepatkan penaakulan Bert 12 kali, dan enjin menarik perhatian. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1381
1381
 52
52

 Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Mengkonfigurasi firewall pelayan Mail Debian adalah langkah penting dalam memastikan keselamatan pelayan. Berikut adalah beberapa kaedah konfigurasi firewall yang biasa digunakan, termasuk penggunaan iptables dan firewalld. Gunakan iptables untuk mengkonfigurasi firewall untuk memasang iptables (jika belum dipasang): sudoapt-getupdateudoapt-getinstalliplesview peraturan iptables semasa: konfigurasi sudoiptable-l
 Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Fungsi Readdir dalam sistem Debian adalah panggilan sistem yang digunakan untuk membaca kandungan direktori dan sering digunakan dalam pengaturcaraan C. Artikel ini akan menerangkan cara mengintegrasikan Readdir dengan alat lain untuk meningkatkan fungsinya. Kaedah 1: Menggabungkan Program Bahasa C dan Pipeline Pertama, tulis program C untuk memanggil fungsi Readdir dan output hasilnya:#termasuk#termasuk#includeintMain (intargc, char*argv []) {dir*dir; structdirent*entry; if (argc! = 2) {
 Cara Melaksanakan Penyortiran Fail oleh Debian Readdir
Apr 13, 2025 am 09:06 AM
Cara Melaksanakan Penyortiran Fail oleh Debian Readdir
Apr 13, 2025 am 09:06 AM
Dalam sistem Debian, fungsi Readdir digunakan untuk membaca kandungan direktori, tetapi urutan yang dikembalikannya tidak ditentukan sebelumnya. Untuk menyusun fail dalam direktori, anda perlu membaca semua fail terlebih dahulu, dan kemudian menyusunnya menggunakan fungsi QSORT. Kod berikut menunjukkan cara menyusun fail direktori menggunakan ReadDir dan QSORT dalam sistem Debian:#termasuk#termasuk#termasuk#termasuk // fungsi perbandingan adat, yang digunakan untuk qSortintCompare (Constvoid*A, Constvoid*b) {Returnstrcmp (*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(
 Kaedah pemasangan sijil SSL Server Server Debian
Apr 13, 2025 am 11:39 AM
Kaedah pemasangan sijil SSL Server Server Debian
Apr 13, 2025 am 11:39 AM
Langkah -langkah untuk memasang sijil SSL pada pelayan mel Debian adalah seperti berikut: 1. Pasang OpenSSL Toolkit terlebih dahulu, pastikan bahawa OpenSSL Toolkit telah dipasang pada sistem anda. Jika tidak dipasang, anda boleh menggunakan arahan berikut untuk memasang: sudoapt-getupdateudoapt-getinstallopenssl2. Menjana permintaan kunci dan sijil peribadi seterusnya, gunakan OpenSSL untuk menjana kunci peribadi RSA 2048-bit dan permintaan sijil (CSR): Membuka
 Cara Melakukan Pengesahan Tandatangan Digital dengan Debian Openssl
Apr 13, 2025 am 11:09 AM
Cara Melakukan Pengesahan Tandatangan Digital dengan Debian Openssl
Apr 13, 2025 am 11:09 AM
Menggunakan OpenSSL untuk Pengesahan Tandatangan Digital pada Sistem Debian, anda boleh mengikuti langkah -langkah berikut: Penyediaan untuk memasang OpenSSL: Pastikan sistem Debian anda telah dipasang. Jika tidak dipasang, anda boleh menggunakan arahan berikut untuk memasangnya: sudoaptdateudoaptininstallopenssl untuk mendapatkan kunci awam: Pengesahan tandatangan digital memerlukan kunci awam penandatangan. Biasanya, kunci awam akan disediakan dalam bentuk fail, seperti public_key.pe
 Bagaimana Debian OpenSSL Menghalang Serangan Man-dalam-Middle
Apr 13, 2025 am 10:30 AM
Bagaimana Debian OpenSSL Menghalang Serangan Man-dalam-Middle
Apr 13, 2025 am 10:30 AM
Dalam sistem Debian, OpenSSL adalah perpustakaan penting untuk pengurusan penyulitan, penyahsulitan dan sijil. Untuk mengelakkan serangan lelaki-dalam-pertengahan (MITM), langkah-langkah berikut boleh diambil: Gunakan HTTPS: Pastikan semua permintaan rangkaian menggunakan protokol HTTPS dan bukannya HTTP. HTTPS menggunakan TLS (Protokol Keselamatan Lapisan Pengangkutan) untuk menyulitkan data komunikasi untuk memastikan data tidak dicuri atau diganggu semasa penghantaran. Sahkan Sijil Pelayan: Sahkan secara manual Sijil Pelayan pada klien untuk memastikan ia boleh dipercayai. Pelayan boleh disahkan secara manual melalui kaedah perwakilan urlSession
 Cara Melakukan Pengurusan Log Debian Hadoop
Apr 13, 2025 am 10:45 AM
Cara Melakukan Pengurusan Log Debian Hadoop
Apr 13, 2025 am 10:45 AM
Menguruskan Log Hadoop pada Debian, anda boleh mengikuti langkah-langkah berikut dan amalan terbaik: Agregasi log membolehkan pengagregatan log: tetapkan benang.log-agregasi-enable untuk benar dalam fail benang-site.xml untuk membolehkan pengagregatan log. Konfigurasikan dasar pengekalan log: tetapkan yarn.log-aggregasi.Retain-seconds Untuk menentukan masa pengekalan log, seperti 172800 saat (2 hari). Nyatakan Laluan Penyimpanan Log: Melalui Benang
 Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Perintah shutdown CentOS adalah penutupan, dan sintaks adalah tutup [pilihan] [maklumat]. Pilihan termasuk: -h menghentikan sistem dengan segera; -P mematikan kuasa selepas penutupan; -r mulakan semula; -T Waktu Menunggu. Masa boleh ditentukan sebagai segera (sekarang), minit (minit), atau masa tertentu (HH: mm). Maklumat tambahan boleh dipaparkan dalam mesej sistem.
