
 Peranti teknologi
AI
LeCun memuji $600 GPT-3.5 sebagai pengganti perkakasan! Parameter 7 bilion Stanford 'Alpaca' popular, LLaMA berprestasi hebat!
Peranti teknologi
AI
LeCun memuji $600 GPT-3.5 sebagai pengganti perkakasan! Parameter 7 bilion Stanford 'Alpaca' popular, LLaMA berprestasi hebat!
LeCun memuji $600 GPT-3.5 sebagai pengganti perkakasan! Parameter 7 bilion Stanford 'Alpaca' popular, LLaMA berprestasi hebat!

Apabila saya bangun, model besar Stanford Alpaca menjadi popular.

Ya, Alpaca ialah model baharu yang diperhalusi daripada LLaMA 7B Meta sahaja 52k data digunakan, dan prestasinya lebih kurang sama dengan GPT-3.5.
Kuncinya ialah kos latihan amat rendah, kurang daripada 600 dolar AS. Kos khusus adalah seperti berikut:
Dilatih pada 8 80GB A100s selama 3 jam, kurang daripada 100 dolar AS
Jana data menggunakan API OpenAI, $500.
Percy Liang, profesor madya sains komputer di Universiti Stanford, berkata disebabkan kekurangan ketelusan/ketidakupayaan untuk mengakses sepenuhnya model arahan yang berkebolehan seperti GPT 3.5 , sekali gus mengehadkan penyelidikan akademik dalam bidang penting ini. Kami mengambil langkah kecil ke hadapan dengan Alpaca (LLaMA 7B + text-davinci-003).

Melihat orang lain telah mencapai hasil baharu pada model besar mereka sendiri, Yann LeCun telah mengetweet semula ia seperti orang gila (keperluan publisiti berada di tempat)).
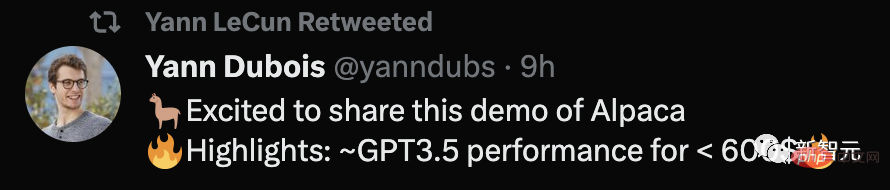

Memperhalusi 7 bilion parameter dalam 3 jam, 600 Dapatkannya dengan dolar AS
Tanpa berlengah lagi, mari cuba dahulu.
S: Beritahu saya sesuatu tentang alpacas.
J: Alpacas ialah spesies unta dari Amerika Selatan, berkaitan dengan llama dan unta. Mereka sering dibesarkan untuk seratnya dan digunakan untuk membuat barangan mewah seperti baju sejuk dan selimut. Alpacas juga merupakan haiwan peliharaan yang popular kerana sifatnya yang lembut dan mesra.
Pautan pengalaman: https://crfm.stanford.edu/alpaca/

Bagi pasukan Stanford, jika mereka ingin melatih arahan berkualiti tinggi mengikut model dalam bajet, mereka mesti menghadapi dua cabaran penting: mempunyai kuasa pra- model bahasa terlatih, dan data mengikut arahan yang berkualiti tinggi.
Tepat sekali, model LLaMA yang diberikan kepada penyelidik akademik menyelesaikan masalah pertama.
Untuk cabaran kedua, kertas kerja "Self-Instruct: Aligning Language Model with Self Generated Instructions" memberi inspirasi yang baik iaitu menggunakan bahasa Kuat sedia ada. model untuk menjana data arahan secara automatik.
Walau bagaimanapun, kelemahan terbesar model LLaMA ialah kekurangan penalaan halus arahan. Salah satu inovasi terbesar OpenAI ialah penggunaan penalaan arahan pada GPT-3.
Dalam hal ini, Stanford menggunakan model bahasa besar sedia ada untuk menjana secara automatik demonstrasi arahan berikut.

Mulakan dengan 175 pasangan "arahan-output" yang ditulis secara manual daripada set benih arahan yang dijana sendiri, kemudian, teks gesaan- davinci -003 menggunakan set benih sebagai contoh kontekstual untuk menjana lebih banyak arahan.
Meningkatkan kaedah arahan penjanaan sendiri dengan memudahkan saluran paip penjanaan, yang sangat mengurangkan kos. Semasa proses penjanaan data, 52K arahan unik dan output yang sepadan telah dihasilkan, berharga kurang daripada $500 menggunakan API OpenAI.
Dengan set data mengikut arahan ini di tangan, penyelidik menggunakan rangka kerja latihan Hugging Face untuk memperhalusi model LLaMA, memanfaatkan selari data berpecah sepenuhnya (FSDP) ) dan latihan ketepatan campuran dan teknik lain.
Selain itu, penalaan halus model 7B LLaMA mengambil masa lebih 3 jam pada 8 80GB A100s, dengan kos kebanyakan penyedia awan Kurang daripada $100.
Lebih kurang sama dengan GPT-3.5 Dikendalikan oleh 5 pelajar pengarang).
Koleksi ulasan ini dikumpulkan oleh pengarang arahan yang dijana sendiri dan merangkumi pelbagai arahan yang dihadapi pengguna, termasuk penulisan e-mel, media sosial dan produktiviti alat tunggu.
Mereka membandingkan GPT-3.5 (text-davinci-003) dan Alpaca 7B dan mendapati bahawa prestasi kedua-dua model adalah sangat serupa. Alpaca menang 90 berbanding 89 kali menentang GPT-3.5.
Memandangkan saiz model yang kecil dan jumlah data arahan yang kecil, keputusan ini sudah cukup menakjubkan.
Selain menggunakan set penilaian statik ini, mereka juga menjalankan ujian interaktif pada model Alpaca dan mendapati prestasi Alpaca pada pelbagai input selalunya sama dengan GPT -3.5 persamaan.
Demonstrasi Stanford dengan Alpaca:
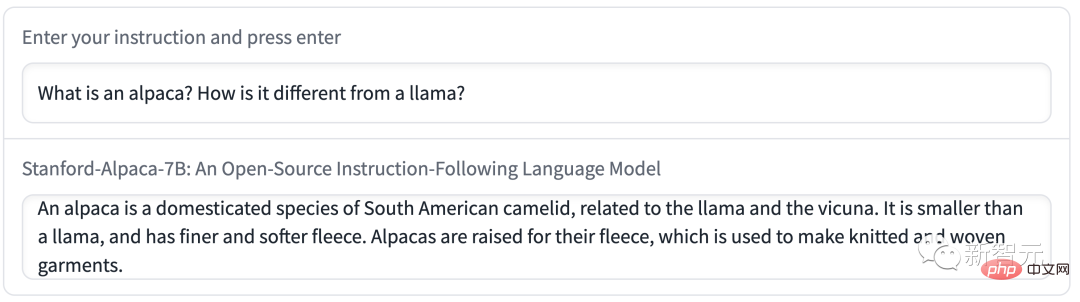
Demo 1 Biar Alpaca bercakap Perbezaan antara saya dan LLaMA.
Sudah tentu, Alpaca mempamerkan kelemahan biasa dalam model bahasa.
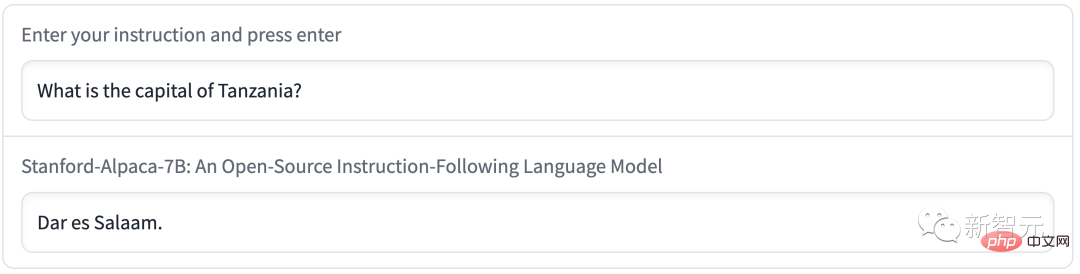
Sebagai contoh, ibu kota Tanzania dipanggil Dar es Salaam. Malah, selepas 1974, Dodoma menjadi ibu kota baharu Tanzania, dan Dar es Salaam hanyalah bandar terbesar di Tanzania.
Selain itu, Alpaca mungkin mempunyai banyak batasan yang berkaitan dengan model bahasa asas dan data penalaan halus arahan. Walau bagaimanapun, Alpaca membekalkan kami model yang agak ringan yang boleh menjadi asas untuk kajian masa depan tentang kelemahan penting dalam model yang lebih besar.
Pada masa ini, Stanford hanya mengumumkan kaedah dan data latihan Alpaca, dan merancang untuk melepaskan pemberat model pada masa hadapan.
Walau bagaimanapun, Alpaca tidak boleh digunakan untuk tujuan komersial dan hanya boleh digunakan untuk penyelidikan akademik. Terdapat tiga sebab khusus:
1 LLaMA ialah model berlesen bukan komersial, dan Alpaca dijana berdasarkan model ini
2. Data arahan adalah berdasarkan teks-davinci-003 OpenAI, yang syarat penggunaannya melarang pembangunan model yang bersaing dengan OpenAI; 3. Tidak cukup langkah keselamatan telah direka, jadi Alpaca tidak bersedia untuk digunakan secara meluas
Selain itu, penyelidik Stanford menyimpulkan penyelidikan masa depan Alpaca akan mempunyai tiga arah.
Penilaian:
- Daripada HELM (Model Bahasa) Penilaian holistik) mula menangkap senario susulan yang lebih generatif.
Keselamatan:
- Kajian lanjut tentang risiko Alpaca, Dan tingkatkan keselamatannya menggunakan kaedah seperti penggabungan merah automatik, pengauditan dan ujian penyesuaian.
Pemahaman:
- Berharap untuk memahami dengan lebih baik Bagaimana model keupayaan muncul daripada kaedah latihan. Apakah sifat model asas yang diperlukan? Apa yang berlaku apabila anda meningkatkan model anda? Apakah atribut data arahan yang diperlukan? Pada GPT-3.5, apakah alternatif untuk menggunakan arahan yang dijana sendiri?
Resapan Stabil bagi model besar
Kini, Stanford "Alpaca" secara langsung dianggap sebagai "Resapan Stabil model teks besar" oleh netizen.Model LLaMA Meta boleh digunakan oleh penyelidik secara percuma (selepas aplikasi sudah tentu), yang merupakan manfaat besar kepada kalangan AI.
Sejak kemunculan ChatGPT, ramai orang telah kecewa dengan batasan terbina dalam model AI. Sekatan ini menghalang ChatGPT daripada membincangkan topik yang OpenAI anggap sensitif.
Oleh itu, komuniti AI berharap untuk mempunyai model bahasa besar (LLM) sumber terbuka yang boleh dijalankan secara tempatan tanpa penapisan atau melaporkan kepada OpenAI Pay the Bayaran API.
Model besar sumber terbuka sedemikian kini tersedia, seperti GPT-J, tetapi kelemahannya ialah ia memerlukan banyak memori GPU dan ruang storan.
Sebaliknya, alternatif sumber terbuka lain tidak boleh mencapai prestasi tahap GPT-3 pada perkakasan pengguna luar biasa.
Pada penghujung Februari, Meta melancarkan model bahasa terbaru LLaMA, dengan jumlah parameter 7 bilion (7B), 13 bilion (13B) dan 33 bilion (33B) dan 65 bilion (65B). Keputusan penilaian menunjukkan bahawa versi 13Bnya adalah setanding dengan GPT-3.
Alamat kertas: https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
Walaupun Meta membuka kod sumber kepada penyelidik yang lulus aplikasi, tidak disangka netizen terlebih dahulu membocorkan berat LLaMA di GitHub.
Sejak itu, perkembangan sekitar model bahasa LLaMA telah meletup.
Lazimnya, menjalankan GPT-3 memerlukan berbilang GPU A100 gred pusat data, ditambah dengan pemberat untuk GPT-3 tidak terbuka.
Netizen mula menjalankan sendiri model LLaMA, menyebabkan sensasi.
Mengoptimumkan saiz model melalui teknik pengkuantitian, LLaMA kini boleh dijalankan pada Mac M1, GPU pengguna Nvidia yang lebih kecil, telefon Pixel 6 dan juga Raspberry Pi dijalankan.
Netizen meringkaskan beberapa pencapaian yang telah dicapai oleh semua orang menggunakan LLaMA sejak pengeluaran LLaMA hingga sekarang:
Pada 24 Februari, LLaMA telah dikeluarkan dan tersedia di bawah lesen bukan komersial kepada penyelidik dan entiti yang bekerja dalam kerajaan, komuniti dan akademia
Pada 2 Mac, netizen 4chan membocorkan semua model LLaMA;
Pada 10 Mac, Georgi Gerganov mencipta alat llama.cpp Mac dilengkapi dengan cip M1/M2;
11 Mac: Model 7B boleh dijalankan pada 4GB RaspberryPi melalui llama.cpp, tetapi kelajuannya agak perlahan, hanya 10 saat/token;
12 Mac: LLaMA 7B berjaya dijalankan pada NPX alat pelaksanaan node.js; >13 Mac: llama.cpp boleh dijalankan pada telefon Pixel 6;
Dan Kini, Stanford Alpaca "Alpaca" dikeluarkan.
Satu Perkara Lagi
Tidak lama selepas projek itu dikeluarkan, Alpaca menjadi begitu popular sehingga tidak boleh digunakan lagi....
Atas ialah kandungan terperinci LeCun memuji $600 GPT-3.5 sebagai pengganti perkakasan! Parameter 7 bilion Stanford 'Alpaca' popular, LLaMA berprestasi hebat!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1384
1384
 52
52

 Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Perintah shutdown CentOS adalah penutupan, dan sintaks adalah tutup [pilihan] [maklumat]. Pilihan termasuk: -h menghentikan sistem dengan segera; -P mematikan kuasa selepas penutupan; -r mulakan semula; -T Waktu Menunggu. Masa boleh ditentukan sebagai segera (sekarang), minit (minit), atau masa tertentu (HH: mm). Maklumat tambahan boleh dipaparkan dalam mesej sistem.
 Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Panduan Lengkap untuk Memeriksa Konfigurasi HDFS Dalam Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk memeriksa konfigurasi dan menjalankan status HDFS secara berkesan pada sistem CentOS. Langkah -langkah berikut akan membantu anda memahami sepenuhnya persediaan dan operasi HDFS. Sahkan Pembolehubah Alam Sekitar Hadoop: Pertama, pastikan pembolehubah persekitaran Hadoop ditetapkan dengan betul. Di terminal, laksanakan arahan berikut untuk mengesahkan bahawa Hadoop dipasang dan dikonfigurasi dengan betul: Hadoopversion Semak fail konfigurasi HDFS: Fail konfigurasi teras HDFS terletak di/etc/hadoop/conf/direktori, di mana core-site.xml dan hdfs-site.xml adalah kritikal. gunakan
 Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Dasar sandaran dan pemulihan Gitlab di bawah sistem CentOS untuk memastikan keselamatan data dan pemulihan, Gitlab pada CentOS menyediakan pelbagai kaedah sandaran. Artikel ini akan memperkenalkan beberapa kaedah sandaran biasa, parameter konfigurasi dan proses pemulihan secara terperinci untuk membantu anda menubuhkan strategi sandaran dan pemulihan GitLab lengkap. 1. Backup Manual Gunakan Gitlab-Rakegitlab: Backup: Buat Perintah untuk Melaksanakan Backup Manual. Perintah ini menyokong maklumat utama seperti repositori Gitlab, pangkalan data, pengguna, kumpulan pengguna, kunci, dan kebenaran. Fail sandaran lalai disimpan dalam direktori/var/opt/gitlab/sandaran. Anda boleh mengubah suai /etc /gitlab
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
Memasang MySQL pada CentOS melibatkan langkah -langkah berikut: Menambah sumber MySQL YUM yang sesuai. Jalankan YUM Pasang Perintah MySQL-Server untuk memasang pelayan MySQL. Gunakan perintah mysql_secure_installation untuk membuat tetapan keselamatan, seperti menetapkan kata laluan pengguna root. Sesuaikan fail konfigurasi MySQL seperti yang diperlukan. Tune parameter MySQL dan mengoptimumkan pangkalan data untuk prestasi.
 Cara Melihat Log Gitlab Di Bawah Centos
Apr 14, 2025 pm 06:18 PM
Cara Melihat Log Gitlab Di Bawah Centos
Apr 14, 2025 pm 06:18 PM
Panduan Lengkap untuk Melihat Log Gitlab Di bawah Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk melihat pelbagai log Gitlab dalam sistem CentOS, termasuk log utama, log pengecualian, dan log lain yang berkaitan. Sila ambil perhatian bahawa laluan fail log mungkin berbeza -beza bergantung pada versi GitLab dan kaedah pemasangan. Jika laluan berikut tidak wujud, sila semak fail Direktori Pemasangan dan Konfigurasi GitLab. 1. Lihat log Gitlab utama Gunakan arahan berikut untuk melihat fail log utama aplikasi GitLabRails: Perintah: Sudocat/var/Log/Gitlab/Gitlab-Rails/Production.log Perintah ini akan memaparkan produk
 Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Latihan yang diedarkan Pytorch pada sistem CentOS memerlukan langkah -langkah berikut: Pemasangan Pytorch: Premisnya ialah Python dan PIP dipasang dalam sistem CentOS. Bergantung pada versi CUDA anda, dapatkan arahan pemasangan yang sesuai dari laman web rasmi Pytorch. Untuk latihan CPU sahaja, anda boleh menggunakan arahan berikut: PipinstallToRchTorchVisionTorchaudio Jika anda memerlukan sokongan GPU, pastikan versi CUDA dan CUDNN yang sama dipasang dan gunakan versi pytorch yang sepadan untuk pemasangan. Konfigurasi Alam Sekitar Teragih: Latihan yang diedarkan biasanya memerlukan pelbagai mesin atau mesin berbilang mesin tunggal. Tempat
