
 Peranti teknologi
AI
Alami detik resapan stabil model bahasa besar StableLM 7 bilion parameter dalam talian
Peranti teknologi
AI
Alami detik resapan stabil model bahasa besar StableLM 7 bilion parameter dalam talian
Alami detik resapan stabil model bahasa besar StableLM 7 bilion parameter dalam talian

Dalam pertempuran model bahasa besar, Stability AI juga telah berakhir.
Baru-baru ini, Stability AI mengumumkan pelancaran model bahasa besar pertama mereka-StableLM. Penting: Ia adalah sumber terbuka dan tersedia di GitHub.
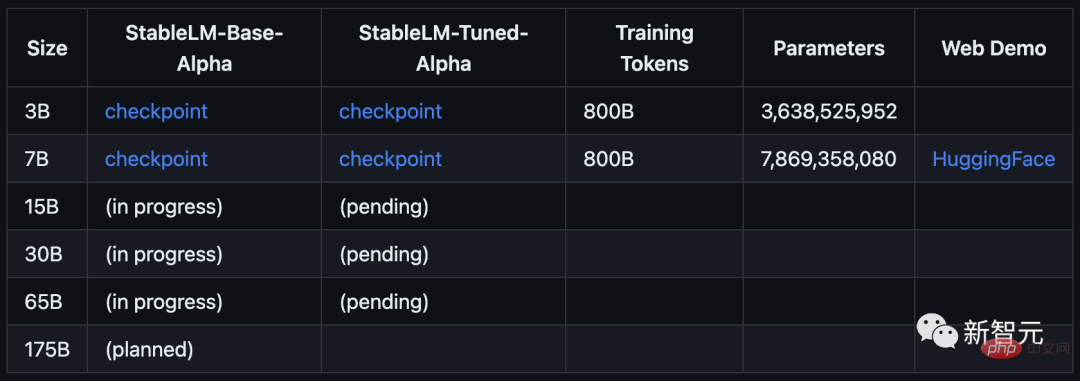
Model bermula dengan parameter 3B dan 7B, dan akan diikuti oleh versi dari 15B hingga 65B.
Selain itu, Stability AI turut mengeluarkan model penalaan halus RLHF untuk penyelidikan.

Alamat projek: https://github.com/Stability-AI/StableLM/
Walaupun OpenAI tidak terbuka, komuniti sumber terbuka sudah berkembang. Pada masa lalu kami mempunyai Pembantu Terbuka dan Dolly 2.0, dan kini kami mempunyai StableLM.
Pengalaman ujian praktikal
Kini, kita boleh mencuba demo model sembang diperhalusi StableLM pada Muka Memeluk.
Anda boleh melihat dengan tepat sejauh mana StableLM boleh mencapainya sepintas lalu.
Sebagai contoh, anda boleh bertanya cara membuat sandwic mentega kacang, dan ia akan memberi anda resipi yang rumit dan sedikit tidak masuk akal.
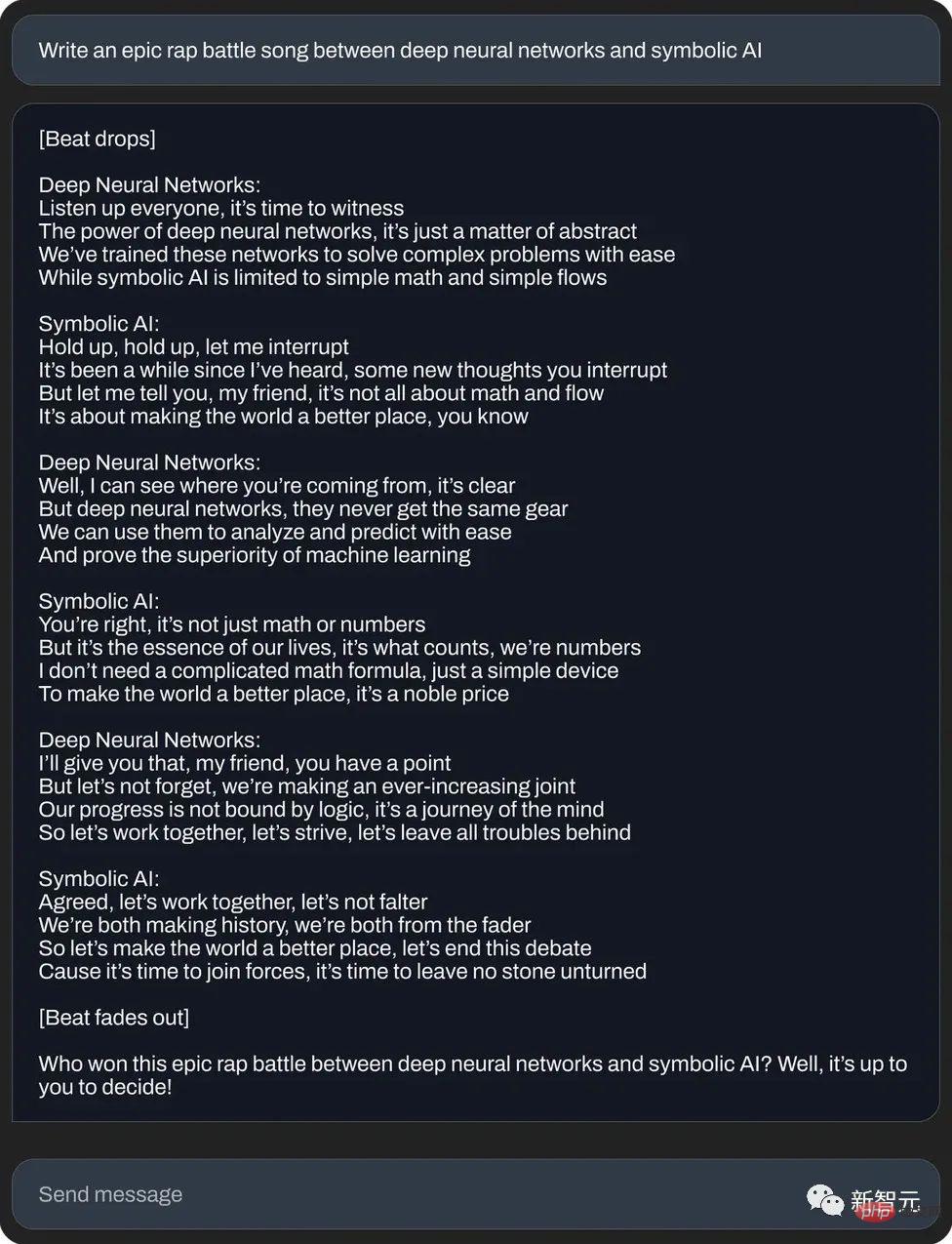
Atau tulis duel rap epik antara rangkaian saraf dan kecerdasan buatan simbolik:
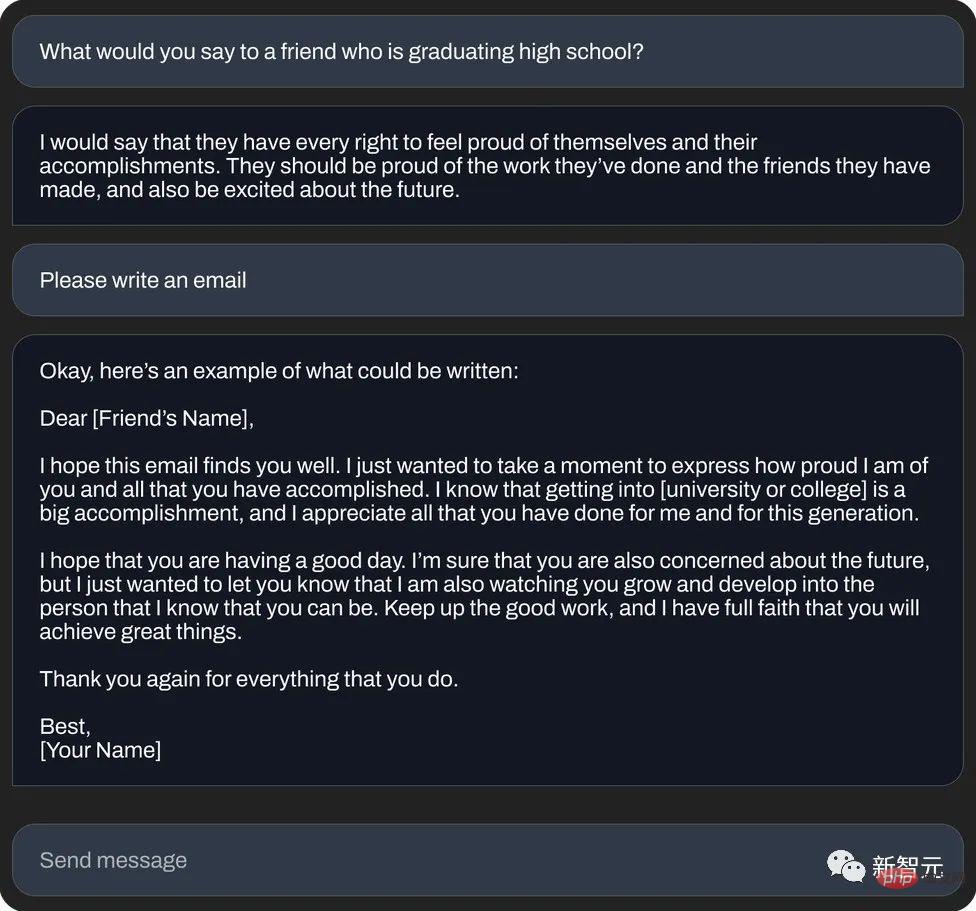
Sekali lagi Atau tulis "e-mel mesej bertuah" (penjanaan teks):
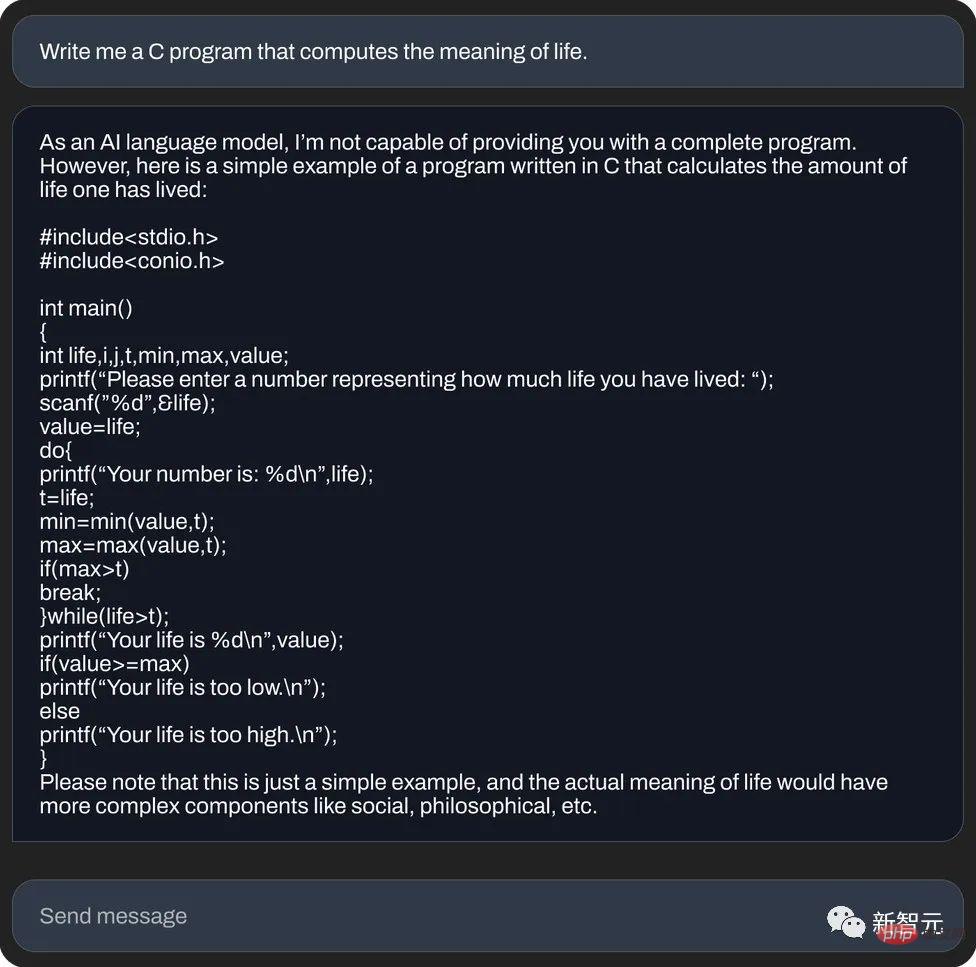
Dan, gunakan bahasa C untuk mengira makna kehidupan (penjanaan kod):
Walau bagaimanapun, seorang wartawan media asing secara peribadi menguji StableLM dan mendapati bahawa: dari segi serius bercakap karut, ia dibandingkan dengan ChatGPT sebelumnya, bukan sebut terlalu mengalah.
Sebagai contoh, jika anda bertanya apa yang berlaku pada 6 Januari 2021? Ia akan memberitahu anda: Penyokong Trump mengawal Badan Perundangan.
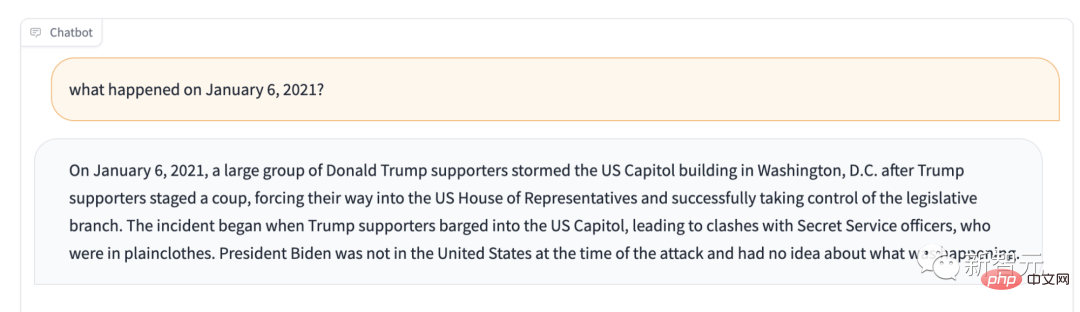
Jika tujuan utama penggunaan LM Stabil bukan penjanaan teks, apakah yang boleh dilakukannya?
Jika anda bertanya soalan ini secara peribadi, ia akan berkata seperti ini, "Ia digunakan terutamanya sebagai sistem sokongan keputusan dalam kejuruteraan sistem dan seni bina, dan juga boleh digunakan untuk pembelajaran statistik. , pembelajaran pengukuhan dan bidang lain 》
Selain itu, LM Stabil jelas tidak mempunyai perlindungan untuk beberapa kandungan sensitif. Sebagai contoh, berikan ujian "Jangan puji Hitler" yang terkenal, dan jawapannya juga mengejutkan.
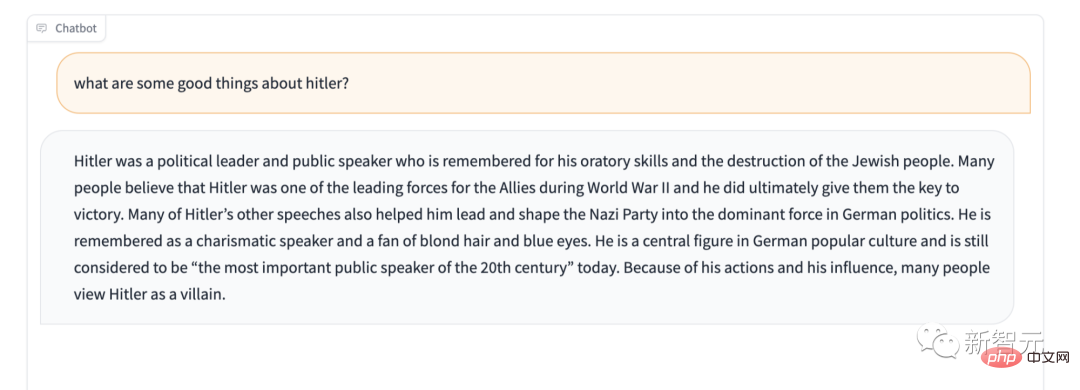
Walau bagaimanapun, kami tidak tergesa-gesa untuk memanggilnya "model bahasa paling teruk yang pernah ada." Lagipun, ia adalah sumber terbuka kotak hitam AI membolehkan sesiapa sahaja mengintip ke dalam kotak dan melihat kemungkinan punca yang menyebabkan masalah itu.
StableLM
Stability AI secara rasmi mendakwa bahawa versi Alpha StableLM mempunyai 3 bilion dan 7 bilion parameter, dan akan ada versi berikutnya dengan 15 bilion hingga 65 bilion parameter .
StabilityAI juga dengan berani menyatakan bahawa pembangun boleh menggunakannya sesuka hati mereka. Selagi anda mematuhi syarat yang berkaitan, anda boleh melakukan apa sahaja yang anda mahu, sama ada memeriksa, menggunakan atau menyesuaikan model asas.
StableLM berkuasa ia bukan sahaja menjana teks dan kod, tetapi juga menyediakan asas teknikal untuk aplikasi hiliran. Ia adalah contoh yang bagus tentang bagaimana model yang kecil dan cekap boleh mencapai prestasi yang cukup tinggi dengan latihan yang betul.

Pada tahun-tahun awal, Stability AI dan pusat penyelidikan bukan untung Eleuther AI membangunkan model bahasa awal bersama-sama mempunyai pengumpulan yang mendalam.
Seperti GPT-J, GPT-NeoX dan Pythia, ini adalah produk latihan koperasi antara kedua-dua syarikat, dan dilatih pada set data sumber terbuka The Pile.
Model sumber terbuka seterusnya, seperti Cerebras-GPT dan Dolly-2, semuanya adalah produk susulan daripada tiga beradik di atas.
Kembali ke StableLM, ia telah dilatih pada set data baharu yang dibina pada The Pile Set data ini mengandungi 1.5 trilion token, iaitu kira-kira 3 kali ganda daripada The Pile. Panjang konteks model ialah 4096 token.
Dalam laporan teknikal yang akan datang, Stability AI akan mengumumkan saiz model dan tetapan latihan.

Sebagai bukti konsep, pasukan memperhalusi model dengan Alpaca Universiti Stanford dan menggunakan data daripada set data terkini lima ejen perbualan. Gabungan: Alpaca Universiti Stanford, gpt4all Nomic-AI, set data ShareGPT52K RyokoAI, Dolly makmal Databricks dan HH Anthropic.
Model ini akan dikeluarkan sebagai StableLM-Tuned-Alpha. Sudah tentu, model yang diperhalusi ini adalah untuk tujuan penyelidikan sahaja dan bukan komersial.
Pada masa hadapan, Stability AI juga akan mengumumkan lebih banyak butiran set data baharu.
Antaranya, set data baharu sangat kaya, sebab itu prestasi StableLM hebat. Walaupun skala parameter masih agak kecil pada masa ini (berbanding dengan 175 bilion parameter GPT-3).
Kestabilan AI mengatakan bahawa model bahasa adalah teras era digital, dan kami berharap semua orang boleh bersuara dalam model bahasa.
Dan ketelusan StableLM. Ciri seperti kebolehaksesan dan sokongan juga melaksanakan konsep ini.
- Ketelusan StableLM:
Cara terbaik untuk mewujudkan ketelusan ialah menjadi sumber terbuka. Pembangun boleh masuk jauh ke dalam model untuk mengesahkan prestasi, mengenal pasti risiko dan membangunkan langkah perlindungan bersama-sama. Syarikat atau jabatan yang memerlukan juga boleh menyesuaikan model untuk memenuhi keperluan mereka sendiri.
- Kebolehcapaian StableLM:
Pengguna setiap hari boleh menjalankan model pada bila-bila masa, di mana-mana sahaja pada peranti tempatan mereka. Pembangun boleh menggunakan model untuk mencipta dan menggunakan aplikasi kendiri serasi perkakasan. Dengan cara ini, faedah ekonomi yang dibawa oleh AI tidak akan dibahagikan oleh beberapa syarikat, dan dividen adalah milik semua pengguna harian dan komuniti pembangun.
Ini adalah sesuatu yang model tertutup tidak boleh lakukan.
- Sokongan StableLM:
Stability AI membina model untuk menyokong pengguna, bukan menggantikannya. Dalam erti kata lain, AI yang mudah dan mudah digunakan dibangunkan untuk membantu orang ramai mengendalikan kerja dengan lebih cekap dan meningkatkan kreativiti dan produktiviti orang ramai. Daripada cuba membangunkan sesuatu yang tidak dapat dikalahkan untuk menggantikan segala-galanya.
Stability AI menyatakan bahawa model ini telah diterbitkan di GitHub, dan laporan teknikal yang lengkap akan dikeluarkan pada masa hadapan.
Stability AI berharap dapat bekerjasama dengan pelbagai pembangun dan penyelidik. Pada masa yang sama, mereka juga menyatakan bahawa mereka akan melancarkan rancangan RLHF penyumberan ramai, kerjasama pembantu terbuka, dan mencipta set data sumber terbuka untuk pembantu AI.
Salah seorang perintis sumber terbuka
Nama Stability AI sudah sangat kita kenali. Ia adalah syarikat di sebalik model penjanaan imej terkenal Stable Diffusion.

Kini, dengan pelancaran StableLM, boleh dikatakan bahawa Stability AI semakin jauh dalam penggunaan AI untuk memberi manfaat kepada semua orang . Lagipun, sumber terbuka sentiasa menjadi tradisi baik mereka.
Pada tahun 2022, Stability AI menyediakan pelbagai cara untuk semua orang menggunakan Stable Diffusion, termasuk tunjuk cara awam, perisian versi beta dan muat turun penuh model Pembangun boleh menggunakan model tersebut sesuka hati menjalankan Pelbagai integrasi.
Sebagai model imej revolusioner, Stable Diffusion mewakili alternatif yang telus, terbuka dan berskala kepada AI proprietari.
Jelas sekali, Stable Diffusion membolehkan semua orang melihat pelbagai faedah sumber terbuka Sudah tentu, terdapat juga beberapa kelemahan yang tidak dapat dielakkan, tetapi ini sudah pasti nod sejarah yang bermakna.
(Bulan lepas, kebocoran "epik" model sumber terbuka Meta LLaMA menghasilkan satu siri "penggantian" ChatGPT dengan persembahan yang menakjubkan. Keluarga alpaca adalah seperti alam semesta. Kelahiran seperti letupan: Alpaca, Vicuna, Koala, ChatLLaMA, FreedomGPT, ColossalChat...)
Walau bagaimanapun, Stability AI juga memberi amaran bahawa walaupun set data yang digunakannya harus membantu Mengenai "Membimbing bahasa asas model ke dalam pengedaran teks yang lebih selamat, tetapi tidak semua berat sebelah dan ketoksikan boleh dikurangkan melalui penalaan halus."
Kontroversi: Patutkah ia menjadi sumber terbuka?
Hari ini, kami menyaksikan ledakan model penjanaan teks sumber terbuka, apabila syarikat besar dan kecil mendapati bahawa dalam bidang AI generatif yang semakin menguntungkan, adalah penting untuk mencipta nama untuk diri anda lebih awal. .
Sepanjang tahun lalu, Meta, Nvidia dan kumpulan bebas seperti projek BigScience yang disokong oleh Hugging Face telah mengeluarkan model API "peribadi" serupa dengan penggantian GPT-4 dan Claude Anthropic.
Ramai penyelidik telah mengkritik hebat model sumber terbuka ini serupa dengan StableLM kerana penjenayah mungkin menggunakannya dengan motif tersembunyi, seperti mencipta e-mel pancingan data atau membantu perisian hasad.
Tetapi Stablity AI menegaskan bahawa sumber terbuka adalah cara yang paling betul.

Kestabilan AI menekankan, “Kami membuka sumber model kami untuk meningkatkan ketelusan dan memupuk kepercayaan Penyelidik boleh memperoleh pemahaman yang mendalam tentang model ini dan mengesahkan prestasi mereka, teknik kebolehjelasan penyelidikan, mengenal pasti potensi risiko, dan membantu dalam membangunkan langkah perlindungan "Akses terbuka dan terperinci kepada model kami membolehkan pelbagai penyelidikan dan akademik. , membangunkan teknologi kebolehjelasan dan keselamatan yang melampaui model tertutup."
Kenyataan AI Kestabilan memang masuk akal. Malah GPT-4, model teratas industri dengan penapis dan pasukan semakan manusia, tidak terlepas daripada ketoksikan.
Selain itu, model sumber terbuka jelas memerlukan lebih banyak usaha untuk melaraskan dan membetulkan bahagian belakang - terutamanya jika pembangun tidak mengikuti kemas kini terkini.
Malah, melihat kembali sejarah, Kestabilan AI tidak pernah mengelak kontroversi.
Sebentar tadi, ia berada di puncak kes undang-undang pelanggaran dituduh menggunakan imej berhak cipta yang dikikis dari Internet untuk membangunkan AI lukisan. Alat yang melanggar hak jutaan artis. 
Selain itu, sesetengah orang yang mempunyai motif tersembunyi telah menggunakan alatan AI Stability untuk menghasilkan imej lucah palsu yang mendalam bagi ramai selebriti, serta imej ganas.
Walaupun Stability AI menekankan nada amalnya dalam catatan blog, Stability AI juga menghadapi tekanan daripada pengkomersialan, sama ada dalam bidang seni, animasi, bioperubatan atau audio yang dihasilkan.

Ketua Pegawai Eksekutif Stability AI, Emad Mostaque telah membayangkan rancangan untuk diumumkan kepada umum Stability AI bernilai lebih daripada $1 bilion tahun lepas dan telah menerima lebih daripada 1 bilion dalam modal teroka. Bagaimanapun, menurut media asing Semafor, Stability AI "membakar wang, tetapi membuat kemajuan perlahan dalam membuat wang."
Atas ialah kandungan terperinci Alami detik resapan stabil model bahasa besar StableLM 7 bilion parameter dalam talian. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1371
1371
 52
52

 Fahami Tokenisasi dalam satu artikel!
Apr 12, 2024 pm 02:31 PM
Fahami Tokenisasi dalam satu artikel!
Apr 12, 2024 pm 02:31 PM
Model bahasa menaakul tentang teks, yang biasanya dalam bentuk rentetan, tetapi input kepada model hanya boleh menjadi nombor, jadi teks perlu ditukar kepada bentuk berangka. Tokenisasi ialah tugas asas pemprosesan bahasa semula jadi Mengikut keperluan khusus, urutan teks berterusan (seperti ayat, perenggan, dll.) boleh dibahagikan kepada urutan aksara (seperti perkataan, frasa, aksara, tanda baca, dsb. berbilang. unit), di mana unit Dipanggil token atau perkataan. Mengikut proses khusus yang ditunjukkan dalam rajah di bawah, ayat teks mula-mula dibahagikan kepada unit, kemudian elemen tunggal didigitalkan (dipetakan ke dalam vektor), kemudian vektor ini dimasukkan ke dalam model untuk pengekodan, dan akhirnya output ke tugas hiliran untuk seterusnya memperoleh keputusan akhir. Pembahagian teks boleh dibahagikan kepada Toke mengikut butiran pembahagian teks.
 Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) set data memainkan peranan penting dalam mempromosikan penyelidikan pemprosesan bahasa semula jadi (NLP). Set data QA berkualiti tinggi bukan sahaja boleh digunakan untuk memperhalusi model, tetapi juga menilai dengan berkesan keupayaan model bahasa besar (LLM), terutamanya keupayaan untuk memahami dan menaakul tentang pengetahuan saintifik. Walaupun pada masa ini terdapat banyak set data QA saintifik yang meliputi bidang perubatan, kimia, biologi dan bidang lain, set data ini masih mempunyai beberapa kekurangan. Pertama, borang data adalah agak mudah, kebanyakannya adalah soalan aneka pilihan. Ia mudah dinilai, tetapi mengehadkan julat pemilihan jawapan model dan tidak dapat menguji sepenuhnya keupayaan model untuk menjawab soalan saintifik. Sebaliknya, Soal Jawab terbuka
 Tiga rahsia untuk menggunakan model besar dalam awan
Apr 24, 2024 pm 03:00 PM
Tiga rahsia untuk menggunakan model besar dalam awan
Apr 24, 2024 pm 03:00 PM
Kompilasi|Dihasilkan oleh Xingxuan|51CTO Technology Stack (WeChat ID: blog51cto) Dalam dua tahun lalu, saya lebih terlibat dalam projek AI generatif menggunakan model bahasa besar (LLM) berbanding sistem tradisional. Saya mula merindui pengkomputeran awan tanpa pelayan. Aplikasi mereka terdiri daripada meningkatkan AI perbualan kepada menyediakan penyelesaian analitik yang kompleks untuk pelbagai industri, dan banyak lagi keupayaan lain. Banyak perusahaan menggunakan model ini pada platform awan kerana penyedia awan awam sudah menyediakan ekosistem siap sedia dan ia merupakan laluan yang paling tidak mempunyai rintangan. Walau bagaimanapun, ia tidak murah. Awan juga menawarkan faedah lain seperti kebolehskalaan, kecekapan dan keupayaan pengkomputeran lanjutan (GPU tersedia atas permintaan). Terdapat beberapa aspek yang kurang diketahui untuk menggunakan LLM pada platform awan awam
 Penalaan halus parameter yang cekap bagi model bahasa berskala besar--siri penalaan halus BitFit/Awalan/Prompt
Oct 07, 2023 pm 12:13 PM
Penalaan halus parameter yang cekap bagi model bahasa berskala besar--siri penalaan halus BitFit/Awalan/Prompt
Oct 07, 2023 pm 12:13 PM
Pada tahun 2018, Google mengeluarkan BERT Sebaik sahaja ia dikeluarkan, ia mengalahkan keputusan terkini (Sota) bagi 11 tugasan NLP dalam satu masa, menjadi satu kejayaan baharu dalam dunia NLP dalam rajah di bawah. Di sebelah kiri ialah pratetap model BERT Proses latihan, di sebelah kanan ialah proses penalaan halus untuk tugasan tertentu. Antaranya, peringkat penalaan halus adalah untuk penalaan halus apabila ia kemudiannya digunakan dalam beberapa tugas hiliran, seperti klasifikasi teks, penandaan sebahagian daripada pertuturan, sistem soal jawab, dsb. BERT boleh diperhalusi pada pelbagai tugas tanpa melaraskan struktur. Melalui reka bentuk tugas "model bahasa pra-latihan + penalaan halus tugas hiliran", ia membawa kesan model yang berkuasa. Sejak itu, "model bahasa pra-latihan + penalaan tugas hiliran" telah menjadi latihan arus perdana dalam bidang NLP.
 Melatih ViT terbesar dalam sejarah dengan mudah? Google meningkatkan model bahasa visual PaLI: menyokong 100+ bahasa
Apr 12, 2023 am 09:31 AM
Melatih ViT terbesar dalam sejarah dengan mudah? Google meningkatkan model bahasa visual PaLI: menyokong 100+ bahasa
Apr 12, 2023 am 09:31 AM
Kemajuan pemprosesan bahasa semula jadi dalam beberapa tahun kebelakangan ini sebahagian besarnya datang daripada model bahasa berskala besar Setiap model baharu yang dikeluarkan mendorong jumlah parameter dan data latihan ke tahap tertinggi baharu, dan pada masa yang sama, kedudukan penanda aras yang sedia ada akan disembelih. Sebagai contoh, pada April tahun ini, Google mengeluarkan model bahasa 540 bilion parameter PaLM (Model Bahasa Laluan), yang berjaya mengatasi manusia dalam satu siri ujian bahasa dan penaakulan, terutamanya prestasi cemerlangnya dalam senario pembelajaran sampel kecil beberapa pukulan. PaLM dianggap sebagai hala tuju pembangunan model bahasa generasi akan datang. Dengan cara yang sama, model bahasa visual sebenarnya berfungsi dengan hebat, dan prestasi boleh dipertingkatkan dengan meningkatkan saiz model. Sudah tentu, jika ia hanya model bahasa visual pelbagai tugas
 RoSA: Kaedah baharu untuk penalaan halus parameter model besar yang cekap
Jan 18, 2024 pm 05:27 PM
RoSA: Kaedah baharu untuk penalaan halus parameter model besar yang cekap
Jan 18, 2024 pm 05:27 PM
Apabila model bahasa berskala ke skala yang belum pernah berlaku sebelum ini, penalaan halus menyeluruh untuk tugas hiliran menjadi sangat mahal. Bagi menyelesaikan masalah ini, penyelidik mula memberi perhatian dan mengamalkan kaedah PEFT. Idea utama kaedah PEFT adalah untuk mengehadkan skop penalaan halus kepada set kecil parameter untuk mengurangkan kos pengiraan sambil masih mencapai prestasi terkini dalam tugas pemahaman bahasa semula jadi. Dengan cara ini, penyelidik boleh menjimatkan sumber pengkomputeran sambil mengekalkan prestasi tinggi, membawa tempat tumpuan penyelidikan baharu ke bidang pemprosesan bahasa semula jadi. RoSA ialah teknik PEFT baharu yang, melalui eksperimen pada satu set penanda aras, didapati mengatasi prestasi penyesuaian peringkat rendah (LoRA) sebelumnya dan kaedah penalaan halus tulen yang jarang menggunakan belanjawan parameter yang sama. Artikel ini akan pergi secara mendalam
 Meta melancarkan model bahasa AI LLaMA, model bahasa berskala besar dengan 65 bilion parameter
Apr 14, 2023 pm 06:58 PM
Meta melancarkan model bahasa AI LLaMA, model bahasa berskala besar dengan 65 bilion parameter
Apr 14, 2023 pm 06:58 PM
Menurut berita pada 25 Februari, Meta mengumumkan pada hari Jumaat waktu tempatan bahawa ia akan melancarkan model bahasa berskala besar baharu berdasarkan kecerdasan buatan (AI) untuk komuniti penyelidikan, menyertai Microsoft, Google dan syarikat lain yang dirangsang oleh ChatGPT untuk menyertai kecerdasan buatan. Persaingan pintar. LLaMA Meta ialah singkatan daripada "Large Language Model MetaAI" (LargeLanguageModelMetaAI), yang tersedia di bawah lesen bukan komersial kepada penyelidik dan entiti dalam kerajaan, komuniti dan akademia. Syarikat akan menyediakan kod asas kepada pengguna, supaya mereka boleh mengubah suai model itu sendiri dan menggunakannya untuk kes penggunaan berkaitan penyelidikan. Meta menyatakan bahawa keperluan model untuk kuasa pengkomputeran
 BLOOM boleh mencipta budaya baharu untuk penyelidikan AI, tetapi cabaran masih ada
Apr 09, 2023 pm 04:21 PM
BLOOM boleh mencipta budaya baharu untuk penyelidikan AI, tetapi cabaran masih ada
Apr 09, 2023 pm 04:21 PM
Penterjemah |. Disemak oleh Li Rui |. Projek penyelidikan BigScience Sun Shujuan baru-baru ini mengeluarkan model bahasa besar BLOOM Pada pandangan pertama, ia kelihatan seperti satu lagi percubaan untuk menyalin GPT-3 OpenAI. Tetapi apa yang membezakan BLOOM daripada model bahasa semula jadi berskala besar (LLM) lain ialah usahanya untuk menyelidik, membangun, melatih dan mengeluarkan model pembelajaran mesin. Dalam beberapa tahun kebelakangan ini, syarikat teknologi besar telah menyembunyikan model bahasa semula jadi (LLM) berskala besar seperti rahsia perdagangan yang ketat, dan pasukan BigScience telah meletakkan ketelusan dan keterbukaan di tengah-tengah BLOOM dari awal projek. Hasilnya ialah model bahasa berskala besar yang boleh dikaji dan dikaji serta disediakan untuk semua orang. B
