
 pembangunan bahagian belakang
Tutorial Python
Analisis kod sumber dict jenis terbina dalam Python
pembangunan bahagian belakang
Tutorial Python
Analisis kod sumber dict jenis terbina dalam Python
Analisis kod sumber dict jenis terbina dalam Python

Pemahaman mendalam tentang jenis terbina dalam Python - dict
Nota: Artikel ini berdasarkan nota yang direkodkan dalam tutorial Sesetengah kandungan adalah sama seperti tutorial, kerana cetakan semula memerlukan pautan, tetapi tiada, jadi Isi kandungan asal, jika terdapat sebarang pelanggaran, ia akan dipadam terus.
Bahagian "Pemahaman mendalam tentang jenis terbina dalam Python" ini akan memperkenalkan anda kepada pelbagai jenis terbina dalam yang biasa digunakan dalam Python dari perspektif kod sumber.
dict ialah salah satu jenis terbina dalam yang paling biasa digunakan dalam pembangunan harian, dan pengendalian mesin maya Python juga sangat bergantung pada objek dict. Menguasai pengetahuan asas dict seharusnya membantu, sama ada memahami pengetahuan asas struktur data atau meningkatkan kecekapan pembangunan.
1 Kecekapan pelaksanaan
Sama ada Hashmap dalam Java atau dict dalam Python, kedua-duanya adalah struktur data yang sangat cekap. Hashmap juga merupakan titik ujian asas dalam temu bual Java: tatasusunan + senarai terpaut + jadual cincang pokok merah-hitam, yang sangat cekap masa. Begitu juga, dict dalam Python juga mempunyai purata kerumitan O(1) (O(n) dalam kes terburuk) untuk operasi seperti penyisipan, pemadaman dan carian disebabkan oleh struktur jadual hash yang mendasarinya. Di sini kami membandingkan senarai dan dict untuk melihat betapa besar perbezaan antara kecekapan carian daripada kedua-duanya: (Data datang daripada artikel asal, anda boleh mengujinya sendiri)
| 容器规模 | 规模增长系数 | dict消耗时间 | dict耗时增长系数 | list消耗时间 | list耗时增长系数 |
|---|---|---|---|---|---|
| 1000 | 1 | 0.000129s | 1 | 0.036s | 1 |
| 10000 | 10 | 0.000172s | 1.33 | 0.348s | 9.67 |
| 100000 | 100 | 0.000216s | 1.67 | 3.679s | 102.19 |
| 1000000 | 1000 | 0.000382s | 2.96 | 48.044s | 1335.56 |
思考: Artikel asal di sini membandingkan data yang akan dicari sebagai elemen senarai dan kunci dict Secara peribadi, saya rasa perbandingan ini tidak bermakna. Kerana senarai pada asasnya ialah jadual cincang, dengan kuncinya ialah 0 hingga n-1, dan nilainya ialah elemen yang kita cari dan dict di sini menggunakan elemen yang kita cari sebagai kunci, dan nilainya adalah Benar ( kod dalam artikel asal ditetapkan seperti ini). Jika anda benar-benar ingin membandingkan, anda boleh membandingkan 0~n-1 senarai pertanyaan dengan kunci yang sepadan bagi dict pertanyaan Ini ialah kaedah pembolehubah kawalan, hh. Sudah tentu, sebab penting mengapa saya secara peribadi berasa tidak sesuai di sini ialah tempat di mana senarai mempunyai kepentingan storan adalah bahagian nilainya, dan kunci serta nilai dict kedua-duanya mempunyai kepentingan storan tertentu, secara peribadi saya rasa tidak perlu terlalu risau tentang kecekapan carian kedua-duanya, adalah paling penting untuk memahami prinsip asas kedua-duanya dan memilih untuk menerapkannya dalam projek sebenar.
2 Struktur Dalaman
2.1 PyDictObject
Memandangkan bekas bersekutu digunakan dalam pelbagai senario, hampir semua bahasa pengaturcaraan moden menyediakan beberapa jenis Bekas bersekutu, dan memberi perhatian khusus kepada kecekapan carian utama. Sebagai contoh, peta dalam pustaka standard C++ ialah bekas bersekutu, yang dilaksanakan secara dalaman berdasarkan pokok merah-hitam Selain itu, terdapat juga Hashmap dalam Java yang baru sahaja disebut. Pokok merah-hitam ialah pokok binari seimbang yang boleh memberikan kecekapan operasi yang baik Kerumitan masa operasi utama seperti sisipan, pemadaman dan carian ialah O(logn).
Pengendalian mesin maya Python sangat bergantung pada objek dict Konsep asas seperti ruang nama dan ruang atribut objek menggunakan objek dict untuk mengurus data. Oleh itu, Python mempunyai keperluan kecekapan yang lebih ketat untuk objek dict. Oleh itu, dict dalam Python menggunakan jadual hash dengan kecekapan lebih baik daripada O(logn).
Objek dict diwakili oleh struktur PyDictObject di dalam Python Kod sumber adalah seperti berikut:
typedef struct {
PyObject_HEAD
/* Number of items in the dictionary */
Py_ssize_t ma_used;
/* Dictionary version: globally unique, value change each time
the dictionary is modified */
uint64_t ma_version_tag;
PyDictKeysObject *ma_keys;
/* If ma_values is NULL, the table is "combined": keys and values
are stored in ma_keys.
If ma_values is not NULL, the table is splitted:
keys are stored in ma_keys and values are stored in ma_values */
PyObject **ma_values;
} PyDictObject;Analisis kod sumber:
ma_used: Bilangan pasangan nilai kunci pada masa ini disimpan oleh objek
ma_version_tag: Nombor versi semasa objek, dikemas kini setiap kali ia diubah suai (versi nombor juga agak biasa dalam pembangunan perniagaan)
ma_keys: Menunjuk kepada struktur jadual cincang yang dipetakan oleh objek utama, taip PyDictKeysObject
ma_values: Tuding kepada semua objek nilai dalam Array mod split (jika mod digabungkan, nilai akan disimpan dalam ma_keys dan ma_values kosong pada masa ini)
2.2 PyDictKeysObject
Seperti yang dapat dilihat daripada kod sumber PyDictObject, berkaitan Jadual cincang dilaksanakan melalui PyDictKeysObject Kod sumber adalah seperti berikut:
struct _dictkeysobject {
Py_ssize_t dk_refcnt;
/* Size of the hash table (dk_indices). It must be a power of 2. */
Py_ssize_t dk_size;
/* Function to lookup in the hash table (dk_indices):
- lookdict(): general-purpose, and may return DKIX_ERROR if (and
only if) a comparison raises an exception.
- lookdict_unicode(): specialized to Unicode string keys, comparison of
which can never raise an exception; that function can never return
DKIX_ERROR.
- lookdict_unicode_nodummy(): similar to lookdict_unicode() but further
specialized for Unicode string keys that cannot be the <dummy> value.
- lookdict_split(): Version of lookdict() for split tables. */
dict_lookup_func dk_lookup;
/* Number of usable entries in dk_entries. */
Py_ssize_t dk_usable;
/* Number of used entries in dk_entries. */
Py_ssize_t dk_nentries;
/* Actual hash table of dk_size entries. It holds indices in dk_entries,
or DKIX_EMPTY(-1) or DKIX_DUMMY(-2).
Indices must be: 0 <= indice < USABLE_FRACTION(dk_size).
The size in bytes of an indice depends on dk_size:
- 1 byte if dk_size <= 0xff (char*)
- 2 bytes if dk_size <= 0xffff (int16_t*)
- 4 bytes if dk_size <= 0xffffffff (int32_t*)
- 8 bytes otherwise (int64_t*)
Dynamically sized, SIZEOF_VOID_P is minimum. */
char dk_indices[]; /* char is required to avoid strict aliasing. */
/* "PyDictKeyEntry dk_entries[dk_usable];" array follows:
see the DK_ENTRIES() macro */
};Analisis kod sumber:
- .
dk_refcnt: pengiraan rujukan, berkaitan dengan pelaksanaan paparan pemetaan, Kiraan rujukan objek serupa
dk_size: saiz jadual cincang, mestilah kuasa integer 2, supaya operasi modular boleh dioptimumkan ke dalam operasi bit (
可以学习一下,结合实际业务运用)dk_lookup: Penunjuk fungsi carian hash, fungsi optimum boleh dipilih mengikut status semasa dict
dk_usable: Bilangan tatasusunan pasangan nilai kunci yang tersedia
dk_nentries: bilangan tatasusunan pasangan nilai kunci yang digunakan
< . Seperti yang anda lihat daripada PyDictKeysObject, struktur pasangan nilai kunci dilaksanakan oleh PyDictKeyEntry Kod sumber adalah seperti berikut:
typedef struct {
/* Cached hash code of me_key. */
Py_hash_t me_hash;
PyObject *me_key;
PyObject *me_value; /* This field is only meaningful for combined tables */
} PyDictKeyEntry;- me_key: penunjuk objek utama
- me_value: penunjuk objek nilai
- 2.4 Ilustrasi dan contoh
Jadual cincang di dalam dict ditunjukkan di bawah:
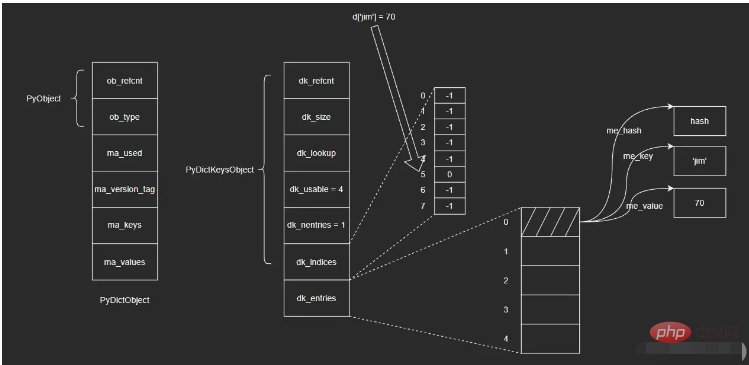 i Simpan pasangan nilai kunci di hujung tatasusunan dk_entry (tatasusunan di sini pada mulanya kosong, penghujungnya ialah kedudukan di mana subskrip tatasusunan ialah "0");
i Simpan pasangan nilai kunci di hujung tatasusunan dk_entry (tatasusunan di sini pada mulanya kosong, penghujungnya ialah kedudukan di mana subskrip tatasusunan ialah "0");
ii (iaitu, modulo 8, panjang tatasusunan dk_indices ialah 8, Seperti yang dinyatakan sebelum ini, mengekalkan panjang tatasusunan sebagai kuasa integer 2 boleh menukar operasi modular kepada operasi bit. Di sini, ambil 3 digit yang betul). Andaikan bahawa nilai akhir yang diperolehi ialah 5, yang sepadan dengan subskrip dalam tatasusunan dk_indices 5
iii. kedudukan subskrip 5 dalam tatasusunan indeks hash dk_indices.
Lakukan operasi carian, langkah-langkahnya adalah seperti berikut:
i Kira nilai cincang objek utama 'jim', dan ambil 3 digit kanan untuk mendapatkan kunci bawah bagi. masukkan dalam tatasusunan indeks cincang dk_indices Mark 5;
ii. Cari kedudukan dengan indeks 5 dalam tatasusunan indeks cincang dk_indices, dan keluarkan nilai yang disimpan di sana - 0, iaitu kedudukan nilai kunci. pasangkan dalam tatasusunan dk_entry
iii. 找到dk_entries数组下标为0的位置,取出值对象me_value。(这里我不确定在查找时会不会再次验证me_key是否为'jim',感兴趣的读者可以自行去查看一下相应的源码)
这里涉及到的结构比较多,直接看图示可能也不是很清晰,但是通过上面的插入和查找两个过程,应该可以帮助大家理清楚这里的关系。我个人觉得这里的设计还是很巧妙的,可能暂时还看不出来为什么这么做,后续我会继续为大家介绍。
3 容量策略
示例:
>>> import sys
>>> d1 = {}
>>> sys.getsizeof(d1)
240
>>> d2 = {'a': 1}
>>> sys.getsizeof(d1)
240可以看到,dict和list在容量策略上有所不同,Python会为空dict对象也分配一定的容量,而对空list对象并不会预先分配底层数组。下面简单介绍下dict的容量策略。
哈希表越密集,哈希冲突则越频繁,性能也就越差。因此,哈希表必须是一种稀疏的表结构,越稀疏则性能越好。但是由于内存开销的制约,哈希表不可能无限度稀疏,需要在时间和空间上进行权衡。实践经验表明,一个1/3到2/3满的哈希表,性能是较为理想的——以相对合理的内存换取相对高效的执行性能。
为保证哈希表的稀疏程度,进而控制哈希冲突频率,Python底层通过USABLE_FRACTION宏将哈希表内元素控制在2/3以内。USABLE_FRACTION根据哈希表的规模n,计算哈希表可存储元素个数,也就是键值对数组dk_entries的长度。以长度为8的哈希表为例,最多可以保持5个键值对,超出则需要扩容。USABLE_FRACTION是一个非常重要的宏定义:
# define USABLE_FRACTION(n) (((n) << 1)/3)
此外,哈希表的规模一定是2的整数次幂,即Python对dict采用翻倍扩容策略。
4 内存优化
在Python3.6之前,dict的哈希表并没有分成两个数组实现,而是由一个键值对数组(结构和PyDictKeyEntry一样,但是会有很多“空位”)实现,这个数组也承担哈希索引的角色:
entries = [ ['--', '--', '--'],
[hash, key, value],
['--', '--', '--'],
[hash, key, value],
['--', '--', '--'],
]哈希值直接在数组中定位到对应的下标,找到对应的键值对,这样一步就能完成。Python3.6之后通过两个数组来实现则是出于对内存的考量。
由于哈希表必须保持稀疏,最多只有2/3满(太满会导致哈希冲突频发,性能下降),这意味着至少要浪费1/3的内存空间,而一个键值对条目PyDictKeyEntry的大小达到了24字节。试想一个规模为65536的哈希表,将浪费:
65536 * 1/3 * 24 = 524288 B 大小的空间(512KB)
为了尽量节省内存,Python将键值对数组压缩到原来的2/3(原来只能2/3满,现在可以全满),只负责存储,索引由另一个数组负责。由于索引数组indices只需要保存键值对数组的下标,即保存整数,而整数占用的空间很小(例如int为4字节),因此可以节省大量内存。
此外,索引数组还可以根据哈希表的规模,选择不同大小的整数类型。对于规模不超过256的哈希表,选择8位整数即可;对于规模不超过65536的哈希表,16位整数足以;其他以此类推。
对比一下两种方式在内存上的开销:
| 哈希表规模 | entries表规模 | 旧方案所需内存(B) | 新方案所需内存(B) | 节约内存(B) |
|---|---|---|---|---|
| 8 | 8 * 2/3 = 5 | 24 * 8 = 192 | 1 * 8 + 24 * 5 = 128 | 64 |
| 256 | 256 * 2/3 = 170 | 24 * 256 = 6144 | 1 * 256 + 24 * 170 = 4336 | 1808 |
| 65536 | 65536 * 2/3 = 43690 | 24 * 65536 = 1572864 | 2 * 65536 + 24 * 43690 = 1179632 | 393232 |
5 dict中哈希表
这一节主要介绍哈希函数、哈希冲突、哈希攻击以及删除操作相关的知识点。
5.1 哈希函数
根据哈希表性质,键对象必须满足以下两个条件,否则哈希表便不能正常工作:
i. 哈希值在对象的整个生命周期内不能改变
ii. 可比较,并且比较结果相等的两个对象的哈希值必须相同
满足这两个条件的对象便是可哈希(hashable)对象,只有可哈希对象才可作为哈希表的键。因此,像dict、set等底层由哈希表实现的容器对象,其键对象必须是可哈希对象。在Python的内建类型中,不可变对象都是可哈希对象,而可变对象则不是:
>>> hash([])
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
hash([])
TypeError: unhashable type: 'list'dict、list等不可哈希对象不能作为哈希表的键:
>>> {[]: 'list is not hashable'}
Traceback (most recent call last):
File "<pyshell#1>", line 1, in <module>
{[]: 'list is not hashable'}
TypeError: unhashable type: 'list'
>>> {{}: 'list is not hashable'}
Traceback (most recent call last):
File "<pyshell#2>", line 1, in <module>
{{}: 'list is not hashable'}
TypeError: unhashable type: 'dict'而用户自定义的对象默认便是可哈希对象,对象哈希值由对象地址计算而来,且任意两个不同对象均不相等:
>>> class A:
pass
>>> a = A()
>>> b = A()
>>> hash(a), hash(b)
(160513133217, 160513132857)
>>>a == b
False
>>> a is b
False那么,哈希值是如何计算的呢?答案是——哈希函数。哈希值计算作为对象行为的一种,会由各个类型对象的tp_hash指针指向的哈希函数来计算。对于用户自定义的对象,可以实现__hash__()魔法方法,重写哈希值计算方法。
5.2 哈希冲突
理想的哈希函数必须保证哈希值尽量均匀地分布于整个哈希空间,越是接近的值,其哈希值差别应该越大。而一方面,不同的对象哈希值有可能相同;另一方面,与哈希值空间相比,哈希表的槽位是非常有限的。因此,存在多个键被映射到哈希索引同一槽位的可能性,这就是哈希冲突。
解决哈希冲突的常用方法有两种:
i. 链地址法(seperate chaining)
ii. 开放定址法(open addressing)
为每个哈希槽维护一个链表,所有哈希到同一槽位的键保存到对应的链表中
这是Python采用的方法。将数据直接保存于哈希槽位中,如果槽位已被占用,则尝试另一个。一般而言,第i次尝试会在首槽位基础上加上一定的偏移量di。因此,探测方法因函数di而异。常见的方法有线性探测(linear probing)以及平方探测(quadratic probing)
线性探测:di是一个线性函数,如:di = 2 * i
平方探测:di是一个二次函数,如:di = i ^ 2
线性探测和平方探测很简单,但同时也存在一定的问题:固定的探测序列会加大冲突的概率。Python对此进行了优化,探测函数参考对象哈希值,生成不同的探测序列,进一步降低哈希冲突的可能性。Python探测方法在lookdict()函数中实现,关键代码如下:
static Py_ssize_t _Py_HOT_FUNCTION
lookdict(PyDictObject *mp, PyObject *key, Py_hash_t hash, PyObject **value_addr)
{
size_t i, mask, perturb;
PyDictKeysObject *dk;
PyDictKeyEntry *ep0;
top:
dk = mp->ma_keys;
ep0 = DK_ENTRIES(dk);
mask = DK_MASK(dk);
perturb = hash;
i = (size_t)hash & mask;
for (;;) {
Py_ssize_t ix = dk_get_index(dk, i);
// 省略键比较部分代码
// 计算下个槽位
// 由于参考了对象哈希值,探测序列因哈希值而异
perturb >>= PERTURB_SHIFT;
i = (i*5 + perturb + 1) & mask;
}
Py_UNREACHABLE();
}源码分析:第20~21行,探测序列涉及到的参数是与对象的哈希值相关的,具体计算方式大家可以看下源码,这里我就不赘述了。
5.3 哈希攻击
Python在3.3之前,哈希算法只根据对象本身计算哈希值。因此,只要Python解释器相同,对象哈希值也肯定相同。执行Python2解释器的两个交互式终端,示例如下:(来自原文章)
>>> import os >>> os.getpid() 2878 >>> hash('fashion') 3629822619130952182
>>> import os >>> os.getpid() 2915 >>> hash('fashion') 3629822619130952182
如果我们构造出大量哈希值相同的key,并提交给服务器:例如向一台Python2Web服务器post一个json数据,数据包含大量的key,这些key的哈希值均相同。这意味哈希表将频繁发生哈希冲突,性能由O(1)直接下降到了O(n),这就是哈希攻击。
产生上述问题的原因是:Python3.3之前的哈希算法只根据对象本身来计算哈希值,这样会导致攻击者很容易构建哈希值相同的key。于是,Python之后在计算对象哈希值时,会加盐。具体做法如下:
i. Python解释器进程启动后,产生一个随机数作为盐
ii. 哈希函数同时参考对象本身以及盐计算哈希值
这样一来,攻击者无法获知解释器内部的随机数,也就无法构造出哈希值相同的对象了。
5.4 删除操作
示例:向dict依次插入三组键值对,键对象依次为key1、key2、key3,其中key2和key3发生了哈希冲突,经过处理后重新定位到dk_indices[6]的位置。图示如下:
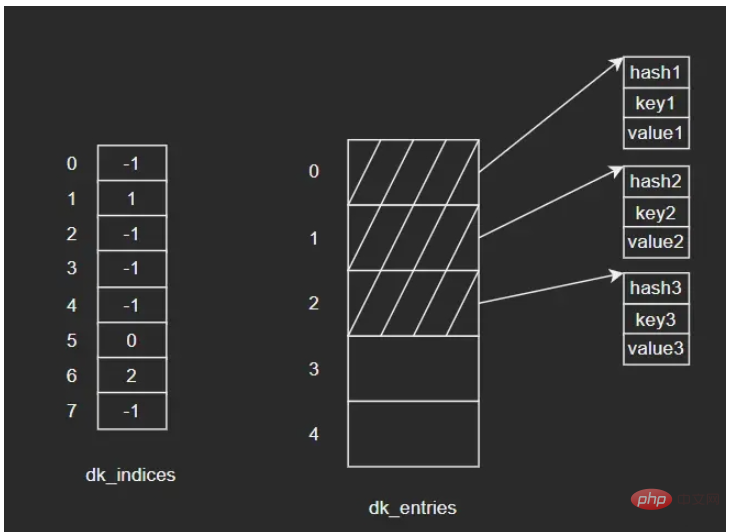
如果要删除key2,假设我们将key2对应的dk_indices[1]设置为-1,那么此时我们查询key3时就会出错——因为key3初始对应的操作就是dk_indices[1],只是发生了哈希冲突蔡最终分配到了dk_indices[6],而此时dk_indices[1]的值为-1,就会导致查询的结果是key3不存在。因此,在删除元素时,会将对应的dk_indices设置为一个特殊的值DUMMY,避免中断哈希探索链(也就是通过标志位来解决,很常见的做法)。
哈希槽位状态常量如下:
#define DKIX_EMPTY (-1) #define DKIX_DUMMY (-2) /* Used internally */ #define DKIX_ERROR (-3)
对于被删除元素在dk_entries中对应的存储单元,Python是不做处理的。假设此时再插入key4,Python会直接使用dk_entries[3],而不会使用被删除的key2所占用的dk_entries[1]。这里会存在一定的浪费。
5.5 问题
删除操作不会将dk_entries中的条目回收重用,随着插入地进行,dk_entries最终会耗尽,Python将创建一个新的PyDictKeysObject,并将数据拷贝过去。新PyDictKeysObject尺寸由GROWTH_RATE宏计算。这里给大家简单列下源码:
static int
dictresize(PyDictObject *mp, Py_ssize_t minsize)
{
/* Find the smallest table size > minused. */
for (newsize = PyDict_MINSIZE;
newsize < minsize && newsize > 0;
newsize <<= 1)
;
// ...
}源码分析:
如果此前发生了大量删除(没记错的话是可用个数为0时才会缩容,这里大家可以自行看下源码),剩余元素个数减少很多,PyDictKeysObject尺寸就会变小,此时就会完成缩容(大家还记得前面提到过的dk_usable,dk_nentries等字段吗,没记错的话它们在这里就发挥作用了,大家可以自行看下源码)。总之,缩容不会在删除的时候立刻触发,而是在当插入并且dk_entries耗尽时才会触发。
函数dictresize()的参数Py_ssize_t minsize由GROWTH_RATE宏传入:
#define GROWTH_RATE(d) ((d)->ma_used*3)
static int
insertion_resize(PyDictObject *mp)
{
return dictresize(mp, GROWTH_RATE(mp));
}这里的for循环就是不断对newsize进行翻倍变化,找到大于minsize的最小值
扩容时,Python分配新的哈希索引数组和键值对数组,然后将旧数组中的键值对逐一拷贝到新数组,再调整数组指针指向新数组,最后回收旧数组。这里的拷贝并不是直接拷贝过去,而是逐个插入新表的过程,这是因为哈希表的规模改变了,相应的哈希函数值对哈希表长度取模后的结果也会变化,所以不能直接拷贝。
Atas ialah kandungan terperinci Analisis kod sumber dict jenis terbina dalam Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1391
1391
 52
52

 PHP dan Python: Paradigma yang berbeza dijelaskan
Apr 18, 2025 am 12:26 AM
PHP dan Python: Paradigma yang berbeza dijelaskan
Apr 18, 2025 am 12:26 AM
PHP terutamanya pengaturcaraan prosedur, tetapi juga menyokong pengaturcaraan berorientasikan objek (OOP); Python menyokong pelbagai paradigma, termasuk pengaturcaraan OOP, fungsional dan prosedur. PHP sesuai untuk pembangunan web, dan Python sesuai untuk pelbagai aplikasi seperti analisis data dan pembelajaran mesin.
 Memilih antara php dan python: panduan
Apr 18, 2025 am 12:24 AM
Memilih antara php dan python: panduan
Apr 18, 2025 am 12:24 AM
PHP sesuai untuk pembangunan web dan prototaip pesat, dan Python sesuai untuk sains data dan pembelajaran mesin. 1.Php digunakan untuk pembangunan web dinamik, dengan sintaks mudah dan sesuai untuk pembangunan pesat. 2. Python mempunyai sintaks ringkas, sesuai untuk pelbagai bidang, dan mempunyai ekosistem perpustakaan yang kuat.
 Boleh kod vs dijalankan di Windows 8
Apr 15, 2025 pm 07:24 PM
Boleh kod vs dijalankan di Windows 8
Apr 15, 2025 pm 07:24 PM
Kod VS boleh dijalankan pada Windows 8, tetapi pengalaman mungkin tidak hebat. Mula -mula pastikan sistem telah dikemas kini ke patch terkini, kemudian muat turun pakej pemasangan kod VS yang sepadan dengan seni bina sistem dan pasangnya seperti yang diminta. Selepas pemasangan, sedar bahawa beberapa sambungan mungkin tidak sesuai dengan Windows 8 dan perlu mencari sambungan alternatif atau menggunakan sistem Windows yang lebih baru dalam mesin maya. Pasang sambungan yang diperlukan untuk memeriksa sama ada ia berfungsi dengan betul. Walaupun kod VS boleh dilaksanakan pada Windows 8, disyorkan untuk menaik taraf ke sistem Windows yang lebih baru untuk pengalaman dan keselamatan pembangunan yang lebih baik.
 Adakah sambungan vscode berniat jahat?
Apr 15, 2025 pm 07:57 PM
Adakah sambungan vscode berniat jahat?
Apr 15, 2025 pm 07:57 PM
Sambungan kod VS menimbulkan risiko yang berniat jahat, seperti menyembunyikan kod jahat, mengeksploitasi kelemahan, dan melancap sebagai sambungan yang sah. Kaedah untuk mengenal pasti sambungan yang berniat jahat termasuk: memeriksa penerbit, membaca komen, memeriksa kod, dan memasang dengan berhati -hati. Langkah -langkah keselamatan juga termasuk: kesedaran keselamatan, tabiat yang baik, kemas kini tetap dan perisian antivirus.
 Cara menjalankan program di terminal vscode
Apr 15, 2025 pm 06:42 PM
Cara menjalankan program di terminal vscode
Apr 15, 2025 pm 06:42 PM
Dalam kod VS, anda boleh menjalankan program di terminal melalui langkah -langkah berikut: Sediakan kod dan buka terminal bersepadu untuk memastikan bahawa direktori kod selaras dengan direktori kerja terminal. Pilih arahan Run mengikut bahasa pengaturcaraan (seperti python python your_file_name.py) untuk memeriksa sama ada ia berjalan dengan jayanya dan menyelesaikan kesilapan. Gunakan debugger untuk meningkatkan kecekapan debug.
 Bolehkah kod studio visual digunakan dalam python
Apr 15, 2025 pm 08:18 PM
Bolehkah kod studio visual digunakan dalam python
Apr 15, 2025 pm 08:18 PM
Kod VS boleh digunakan untuk menulis Python dan menyediakan banyak ciri yang menjadikannya alat yang ideal untuk membangunkan aplikasi python. Ia membolehkan pengguna untuk: memasang sambungan python untuk mendapatkan fungsi seperti penyempurnaan kod, penonjolan sintaks, dan debugging. Gunakan debugger untuk mengesan kod langkah demi langkah, cari dan selesaikan kesilapan. Mengintegrasikan Git untuk Kawalan Versi. Gunakan alat pemformatan kod untuk mengekalkan konsistensi kod. Gunakan alat linting untuk melihat masalah yang berpotensi lebih awal.
 Boleh vscode digunakan untuk mac
Apr 15, 2025 pm 07:36 PM
Boleh vscode digunakan untuk mac
Apr 15, 2025 pm 07:36 PM
VS Kod boleh didapati di Mac. Ia mempunyai sambungan yang kuat, integrasi git, terminal dan debugger, dan juga menawarkan banyak pilihan persediaan. Walau bagaimanapun, untuk projek yang sangat besar atau pembangunan yang sangat profesional, kod VS mungkin mempunyai prestasi atau batasan fungsi.
 Python vs JavaScript: Keluk Pembelajaran dan Kemudahan Penggunaan
Apr 16, 2025 am 12:12 AM
Python vs JavaScript: Keluk Pembelajaran dan Kemudahan Penggunaan
Apr 16, 2025 am 12:12 AM
Python lebih sesuai untuk pemula, dengan lengkung pembelajaran yang lancar dan sintaks ringkas; JavaScript sesuai untuk pembangunan front-end, dengan lengkung pembelajaran yang curam dan sintaks yang fleksibel. 1. Sintaks Python adalah intuitif dan sesuai untuk sains data dan pembangunan back-end. 2. JavaScript adalah fleksibel dan digunakan secara meluas dalam pengaturcaraan depan dan pelayan.
