
 Peranti teknologi
AI
Kaedah pembelajaran perwakilan sebab yang dicadangkan oleh Hong Kong et al bertujuan untuk masalah generalisasi luaran taburan data ortografik.
Peranti teknologi
AI
Kaedah pembelajaran perwakilan sebab yang dicadangkan oleh Hong Kong et al bertujuan untuk masalah generalisasi luaran taburan data ortografik.
Kaedah pembelajaran perwakilan sebab yang dicadangkan oleh Hong Kong et al bertujuan untuk masalah generalisasi luaran taburan data ortografik.

Dengan aplikasi dan promosi model pembelajaran mendalam, orang ramai secara beransur-ansur mendapati bahawa model sering menggunakan korelasi palsu (Spurious Correlation) dalam data untuk mendapatkan prestasi latihan yang lebih tinggi. Walau bagaimanapun, oleh kerana korelasi sedemikian sering tidak berlaku pada data ujian, prestasi ujian model tersebut selalunya tidak memuaskan [1]. Intipatinya ialah objektif pembelajaran mesin tradisional (Empirical Risk Minimization, ERM) menganggap ciri pengagihan bebas dan sama bagi set latihan dan ujian, tetapi pada hakikatnya, senario di mana andaian pengagihan bebas dan sama adalah benar selalunya terhad. Dalam banyak senario kehidupan sebenar, pengedaran data latihan dan pengedaran data ujian biasanya menunjukkan ketidakkonsistenan, iaitu, anjakan pengedaran (Distribution Shifts Masalah yang bertujuan untuk meningkatkan prestasi model dalam senario sedemikian biasanya dipanggil out-). masalah generalisasi agihan (out-of-distribution). Kelas kaedah seperti ERM yang menumpukan pada korelasi pembelajaran dan bukannya penyebab dalam data sering bergelut dengan anjakan pengedaran. Walaupun banyak kaedah telah muncul dalam beberapa tahun kebelakangan ini dan telah mencapai kemajuan tertentu dalam masalah Out-of-Distribution dengan menggunakan Prinsip Invarian dalam Inferens Sebab, penyelidikan mengenai data graf masih terhad. Ini kerana pengitlak data graf di luar pengedaran adalah lebih sukar daripada data Eropah tradisional, yang membawa lebih banyak cabaran kepada pembelajaran mesin graf. Kertas kerja ini mengambil tugas pengelasan graf sebagai contoh untuk menerokai generalisasi tambahan bagi taburan graf berdasarkan prinsip invarian sebab.
Dalam beberapa tahun kebelakangan ini, dengan bantuan prinsip invarian sebab, orang telah mencapai kejayaan tertentu dalam masalah generalisasi luar pengedaran data Euclidean, tetapi untuk graf Penyelidikan tentang data masih terhad. Tidak seperti data Euclidean, kerumitan graf menimbulkan cabaran unik untuk menggunakan prinsip invarian sebab dan mengatasi kesukaran generalisasi luar taburan.
Untuk menangani cabaran ini, kami menyepadukan invarian sebab ke dalam pembelajaran mesin graf dalam kerja ini dan mencadangkan rangka kerja pembelajaran graf invarian yang diilhamkan sebab untuk menyelesaikan masalah data graf. Masalah generalisasi luar pengedaran menyediakan teori dan kaedah baru.
Kertas kerja telah diterbitkan di NeurIPS 2022. Kerja ini telah disiapkan dengan kerjasama Universiti China Hong Kong, Universiti Baptist Hong Kong, Tencent AI Lab dan Universiti Sydney.

- Tajuk kertas: Mempelajari Perwakilan Invarian Bersebab untuk Generalisasi Luar Taburan pada Graf
- Pautan kertas: https://openreview.net/forum?id=A6AFK_JwrIW
- Kod projek: https: //github.com/LFhase/CIGA
Generalisasi luar pengedaran data graf
Di luar pengedaran generalisasi data graf Apakah kesukarannya?
Rangkaian saraf graf telah mencapai kejayaan besar dalam beberapa tahun kebelakangan ini dalam aplikasi pembelajaran mesin yang melibatkan struktur graf, seperti sistem pengesyoran, farmaseutikal berbantukan AI dan bidang lain. Walau bagaimanapun, kerana kebanyakan algoritma pembelajaran mesin graf sedia ada bergantung pada andaian pengagihan data yang bebas dan sama, apabila data ujian dan data latihan mempunyai anjakan (Anjakan Pengedaran), prestasi algoritma akan berkurangan dengan banyak. Pada masa yang sama, disebabkan oleh kerumitan struktur data graf, generalisasi data graf di luar pengedaran adalah lebih biasa dan lebih mencabar daripada data Eropah.
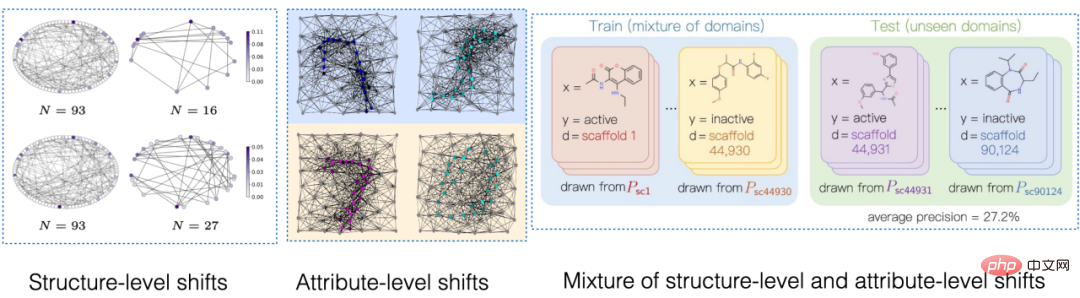
Rajah 1. Contoh anjakan taburan pada graf.
Pertama, anjakan taburan data graf boleh muncul dalam taburan ciri nod graf (Anjakan Tahap Atribut). Sebagai contoh, dalam sistem pengesyoran, produk yang terlibat dalam data latihan mungkin daripada beberapa kategori popular, dan pengguna yang terlibat juga mungkin datang dari kawasan tertentu tertentu Walau bagaimanapun, semasa fasa ujian, sistem perlu mengendalikan pengguna dengan betul daripada semua kategori dan wilayah dan komoditi [2,3,4]. Selain itu, anjakan taburan data graf juga boleh muncul dalam taburan struktur graf (Anjakan Tahap Struktur). Seawal 2019, orang ramai menyedari bahawa rangkaian saraf graf yang dilatih pada graf yang lebih kecil adalah sukar untuk mempelajari pemberat perhatian yang berkesan (Perhatian) untuk digeneralisasikan kepada graf yang lebih besar [5], yang turut menggalakkan Satu siri kerja berkaitan telah dicadangkan [6,7]. Dalam senario kehidupan sebenar, kedua-dua jenis anjakan pengedaran ini mungkin sering muncul pada masa yang sama, dan anjakan pengedaran ini pada tahap yang berbeza juga mungkin mempunyai corak korelasi palsu yang berbeza dengan label yang akan diramalkan. Contohnya, dalam sistem pengesyoran, produk daripada kategori tertentu dan pengguna dari kawasan tertentu sering mempamerkan struktur topologi unik pada graf interaksi pengguna produk [4]. Dalam ramalan sifat molekul dadah, molekul ubat yang terlibat dalam latihan mungkin terlalu kecil, dan keputusan ramalan juga akan dipengaruhi oleh persekitaran pengukuran eksperimen [8].
Selain itu, generalisasi luar pengedaran dalam ruang Euclidean sering mengandaikan bahawa data datang daripada berbilang persekitaran (Persekitaran) atau domain (Domain), dan seterusnya mengandaikan bahawa model boleh memperoleh data latihan semasa latihan Persekitaran yang menjadi milik setiap sampel untuk meneroka invarian merentasi persekitaran. Walau bagaimanapun, mendapatkan label persekitaran untuk data selalunya memerlukan beberapa pengetahuan pakar yang berkaitan dengan data, dan disebabkan sifat abstrak data graf, mendapatkan label persekitaran untuk data graf adalah lebih mahal. Oleh itu, kebanyakan set data graf sedia ada seperti OGB tidak mengandungi maklumat label persekitaran sedemikian Walaupun beberapa set data seperti DrugOOD mempunyai label alam sekitar, terdapat pelbagai tahap hingar.
Bolehkah kaedah sedia ada menyelesaikan masalah generalisasi luar taburan pada graf?
Untuk mempunyai pemahaman intuitif tentang cabaran generalisasi luar pengedaran pada data graf, kami membina data baharu berdasarkan set data Spurious-Motif [9] untuk selanjutnya nyatakan beberapa cabaran utama di atas, dan cuba gunakan kaedah sedia ada seperti sasaran latihan IRM [10] untuk generalisasi luar pengedaran pada data Eropah, atau GNN [11] dengan keupayaan ekspresif yang lebih kukuh, untuk menganalisis sama ada data graf boleh diselesaikan dengan kaedah sedia ada Masalah generalisasi luar pengedaran.
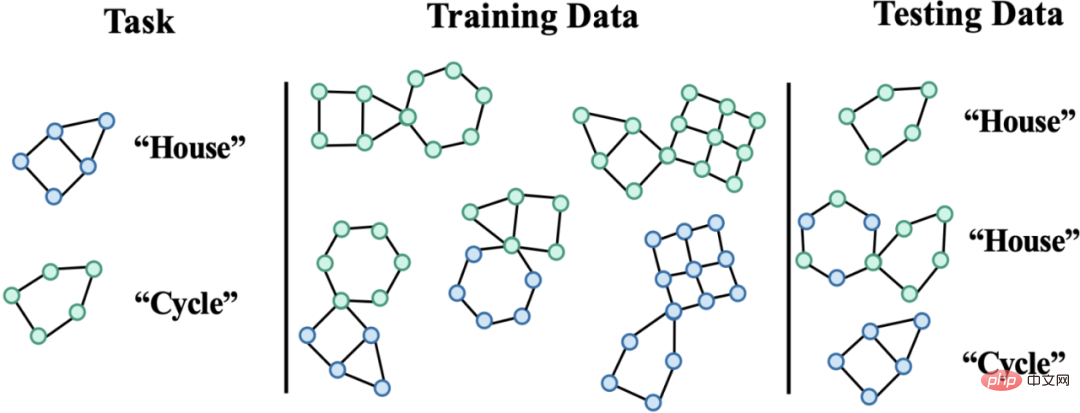
Rajah 2. Contoh set data Motif Palsu.
Tugas Motif Palsu ditunjukkan dalam Rajah 2. Ia terutamanya melabelkan graf berdasarkan sama ada graf input mengandungi subgraf dengan struktur tertentu (seperti House atau Kitaran). Buat pertimbangan, di mana warna nod mewakili atribut nod. Menggunakan set data ini boleh menguji dengan jelas kesan anjakan pengedaran pada tahap yang berbeza pada prestasi rangkaian saraf graf. Untuk model GNN biasa yang dilatih menggunakan ERM:
- Jika kebanyakan sampel dengan subgraf House dalam fasa latihan kebanyakannya mempunyai nod hijau, manakala nod Cycle berwarna biru, Kemudian semasa fasa ujian, model cenderung untuk meramalkan bahawa mana-mana graf dengan sejumlah besar nod hijau ialah "Rumah", dan mana-mana graf dengan nod biru ialah "Kitaran".
- Jika kebanyakan sampel dengan subgraf House dalam fasa latihan berlaku bersama dengan subgraf heksagon, maka dalam fasa ujian, model akan cenderung menilai sebarang struktur heksagon Gambar menunjukkan "Rumah".
Selain itu, model tidak boleh mendapatkan sebarang maklumat yang berkaitan dengan label persekitaran semasa latihan, dan keputusan eksperimen ditunjukkan dalam Rajah 3 (lebih banyak keputusan boleh didapati dalam Lampiran D bagi kertas itu).
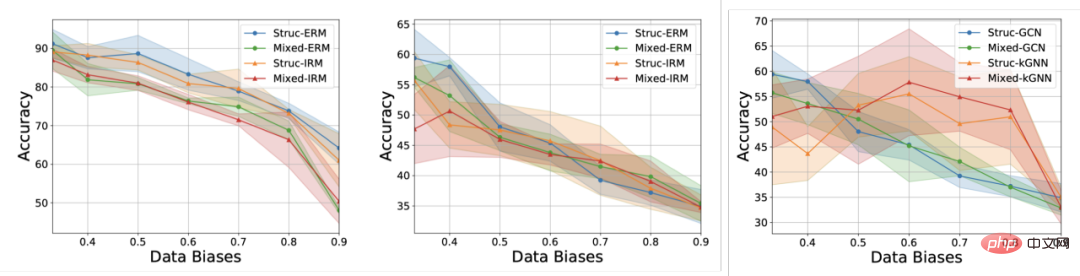
Rajah 3. Prestasi kaedah sedia ada di bawah anjakan taburan graf yang berbeza.
Seperti yang ditunjukkan dalam Rajah 3, GCN biasa tidak dapat mengatasi anjakan struktur (Struc) graf sama ada ia dilatih menggunakan ERM atau IRM semasa dalam After menambah mengimbangi atribut nod graf (Campuran) dan mengimbangi pengedaran saiz graf (dalam Rajah 3), prestasi model akan dikurangkan lagi, walaupun kGNN dengan keupayaan ekspresi yang lebih kuat digunakan, sukar untuk mengelakkan kehilangan prestasi yang serius (purata prestasi lebih rendah, atau varians yang lebih besar).
Daripada ini, kita secara semula jadi membawa kepada persoalan yang perlu dikaji: Bagaimana untuk mendapatkan model GNN yang boleh mengatasi pelbagai anjakan pengedaran graf?
Model kausal berorientasikan kepada generalisasi taburan luar data graf
Untuk menyelesaikan masalah di atas, kita perlu mempelajari sasaran, iaitu Invariant GNN, Definisi, iaitu model yang masih berprestasi baik dalam persekitaran yang paling teruk (lihat kertas untuk definisi yang ketat):
Definisi 1 (Rangkaian Neural Graf Invarian) Diberi satu siri set data klasifikasi Graf yang dikumpul untuk persekitaran berkaitan sebab yang berbeza , di mana Mengandungi sampel i.i.d persekitaran e, pertimbangkan rangkaian neural graf , di mana dan > berada ruang graf dan ruang sampel sebagai input masing-masing, f ialah rangkaian neural graf invarian, jika dan hanya jika , iaitu, meminimumkan maksimum semua persekitaran Risiko empirikal terburuk, di mana ialah kehilangan pengalaman model dalam persekitaran.
Model hanya boleh mendapatkan sebahagian daripada data dalam persekitaran latihan semasa latihan jika tiada andaian dibuat tentang proses data, data akan kekal tidak berubah Keoptimuman minmax yang diperlukan oleh definisi rangkaian saraf graf adalah sukar untuk dicapai. Oleh itu, kami menggunakan Model Sebab Berstruktur untuk memodelkan proses penjanaan graf dari perspektif Inferens Sebab dan mencirikan korelasi antara persekitaran dalam percubaan untuk mentakrifkan invarian sebab pada data graf.
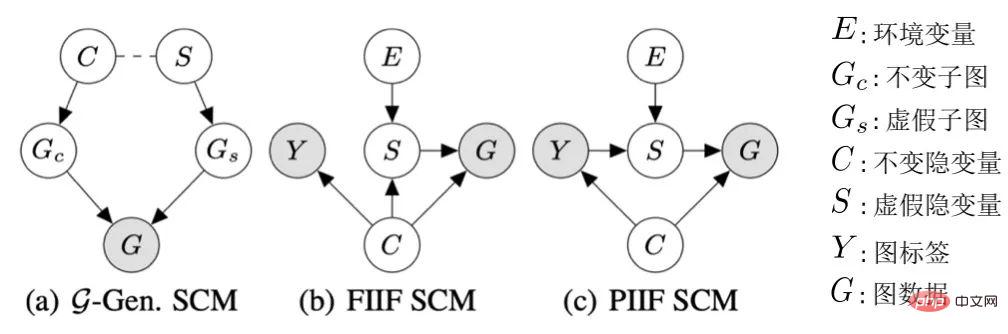
Rajah 4. Model penyebab proses penjanaan data graf.
Tanpa kehilangan sifat umum, kami menggabungkan semua pembolehubah terpendam yang mempengaruhi penjanaan graf ke dalam ruang terpendam dan memodelkan proses penjanaan graf sebagai 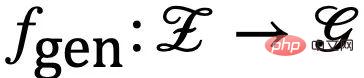 . Selain itu, untuk pembolehubah pendam
. Selain itu, untuk pembolehubah pendam  , mengikut sama ada ia dipengaruhi oleh persekitaran E, kami membahagikannya kepada pembolehubah pendam invarian
, mengikut sama ada ia dipengaruhi oleh persekitaran E, kami membahagikannya kepada pembolehubah pendam invarian  dan pembolehubah pendam palsu (pendam palsu pembolehubah)
dan pembolehubah pendam palsu (pendam palsu pembolehubah)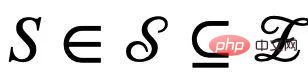 . Sejajar dengan itu, pembolehubah pendam C dan S masing-masing akan mempengaruhi penjanaan subgraf tertentu G, yang direkodkan sebagai subgraf invarian
. Sejajar dengan itu, pembolehubah pendam C dan S masing-masing akan mempengaruhi penjanaan subgraf tertentu G, yang direkodkan sebagai subgraf invarian  dan subgraf palsu
dan subgraf palsu  , masing-masing, seperti Seperti yang ditunjukkan dalam Rajah 4 (a), dan C terutamanya mengawal label Y graf. Ini juga boleh disimpulkan lagi
, masing-masing, seperti Seperti yang ditunjukkan dalam Rajah 4 (a), dan C terutamanya mengawal label Y graf. Ini juga boleh disimpulkan lagi 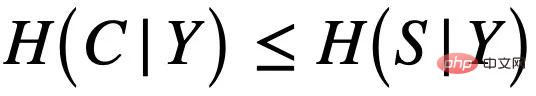 , iaitu C dan Y mempunyai maklumat bersama yang lebih tinggi daripada S. Proses penjanaan ini sepadan dengan banyak contoh praktikal Contohnya, sifat perubatan molekul biasanya ditentukan oleh kumpulan utama tertentu (subgraf molekul) (seperti keterlarutan air hidroksil-H O kepada molekul).
, iaitu C dan Y mempunyai maklumat bersama yang lebih tinggi daripada S. Proses penjanaan ini sepadan dengan banyak contoh praktikal Contohnya, sifat perubatan molekul biasanya ditentukan oleh kumpulan utama tertentu (subgraf molekul) (seperti keterlarutan air hidroksil-H O kepada molekul).
Selain itu, C mempunyai banyak jenis interaksi dengan Y, S dan E dalam ruang pendam Ia terutamanya mengikut sama ada pembolehubah pendam palsu S dan label Y mempunyai perkaitan tambahan selain pembolehubah pendam malar C, iaitu. ialah  boleh diringkaskan kepada dua jenis: FIIF (Ciri Invarian Bermaklumat Penuh) seperti yang ditunjukkan dalam Rajah 4 (b) dan PIIF (Ciri Invarian Separa Bermaklumat) seperti yang ditunjukkan dalam Rajah 4 (c). Antaranya, FIIF bermaksud bahawa label adalah bebas daripada jumlah korelasi palsu yang diberikan maklumat invarian. PIIF adalah sebaliknya. Perlu diingat bahawa untuk menampung sebanyak mungkin anjakan pengedaran graf, model kausal kami berusaha untuk memodelkan pelbagai model penjanaan graf secara meluas. Memandangkan lebih banyak pengetahuan tentang proses penjanaan graf, model kausal yang ditunjukkan dalam Rajah 4 boleh digeneralisasikan lagi kepada contoh yang lebih khusus. Seperti dalam Lampiran C.1, kami menunjukkan bagaimana graf sebab boleh digeneralisasikan kepada kerja sebelumnya oleh Bevilacqua et al [7] untuk menganalisis anjakan taburan saiz graf dengan menambah andaian had graf tambahan (graphon).
boleh diringkaskan kepada dua jenis: FIIF (Ciri Invarian Bermaklumat Penuh) seperti yang ditunjukkan dalam Rajah 4 (b) dan PIIF (Ciri Invarian Separa Bermaklumat) seperti yang ditunjukkan dalam Rajah 4 (c). Antaranya, FIIF bermaksud bahawa label adalah bebas daripada jumlah korelasi palsu yang diberikan maklumat invarian. PIIF adalah sebaliknya. Perlu diingat bahawa untuk menampung sebanyak mungkin anjakan pengedaran graf, model kausal kami berusaha untuk memodelkan pelbagai model penjanaan graf secara meluas. Memandangkan lebih banyak pengetahuan tentang proses penjanaan graf, model kausal yang ditunjukkan dalam Rajah 4 boleh digeneralisasikan lagi kepada contoh yang lebih khusus. Seperti dalam Lampiran C.1, kami menunjukkan bagaimana graf sebab boleh digeneralisasikan kepada kerja sebelumnya oleh Bevilacqua et al [7] untuk menganalisis anjakan taburan saiz graf dengan menambah andaian had graf tambahan (graphon).
Berdasarkan analisis kausal di atas, kita boleh tahu bahawa apabila model hanya menggunakan subgraf invarian untuk ramalan, ia hanya menggunakan subgraf antara 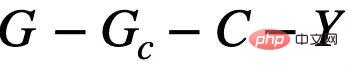 Korelasi, ramalan model tidak akan terjejas oleh perubahan dalam persekitaran E sebaliknya, jika ramalan model bergantung pada sebarang maklumat yang berkaitan dengan S atau
Korelasi, ramalan model tidak akan terjejas oleh perubahan dalam persekitaran E sebaliknya, jika ramalan model bergantung pada sebarang maklumat yang berkaitan dengan S atau  , keputusan ramalannya akan dipengaruhi oleh perubahan dalam E Perubahan ketara berlaku, mengakibatkan kehilangan prestasi. Oleh itu, matlamat kami boleh diperhalusi lagi daripada mempelajari rangkaian neural graf invarian untuk: a) mengenal pasti subgraf invarian yang berpotensi b) meramalkan Y menggunakan subgraf yang dikenal pasti. Untuk lebih sesuai dengan proses algoritma penjanaan data, kami membahagikan lagi rangkaian saraf graf kepada rangkaian pengecaman subgraf (Featurizer GNN)
, keputusan ramalannya akan dipengaruhi oleh perubahan dalam E Perubahan ketara berlaku, mengakibatkan kehilangan prestasi. Oleh itu, matlamat kami boleh diperhalusi lagi daripada mempelajari rangkaian neural graf invarian untuk: a) mengenal pasti subgraf invarian yang berpotensi b) meramalkan Y menggunakan subgraf yang dikenal pasti. Untuk lebih sesuai dengan proses algoritma penjanaan data, kami membahagikan lagi rangkaian saraf graf kepada rangkaian pengecaman subgraf (Featurizer GNN)  dan rangkaian pengelasan (GNN Pengelas)
dan rangkaian pengelasan (GNN Pengelas) 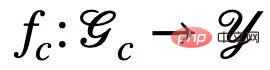 dan
dan 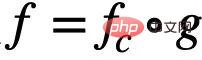 , dengan
, dengan  ialah ruang subgraf
ialah ruang subgraf  . Kemudian objektif pembelajaran model boleh dinyatakan seperti yang ditunjukkan dalam formula (1):
. Kemudian objektif pembelajaran model boleh dinyatakan seperti yang ditunjukkan dalam formula (1):
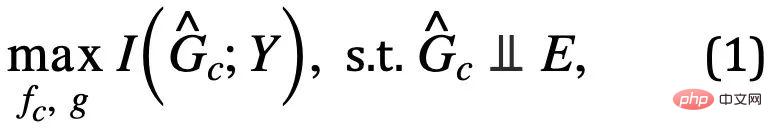
Antaranya, 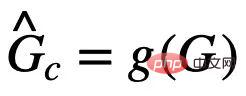 ialah ramalan subgraf invarian oleh rangkaian pengecaman subgraf; Maklumat bersama dengan Y, secara amnya, memaksimumkan
ialah ramalan subgraf invarian oleh rangkaian pengecaman subgraf; Maklumat bersama dengan Y, secara amnya, memaksimumkan  boleh dicapai dengan meminimumkan kehilangan empirikal ramalan Y menggunakan
boleh dicapai dengan meminimumkan kehilangan empirikal ramalan Y menggunakan  . Walau bagaimanapun, disebabkan kekurangan E, sukar untuk kita menggunakan E secara langsung untuk mengesahkan kemerdekaan
. Walau bagaimanapun, disebabkan kekurangan E, sukar untuk kita menggunakan E secara langsung untuk mengesahkan kemerdekaan 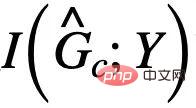
 Untuk tujuan ini, kita mesti mencari yang lain syarat setara untuk mengenal pasti keperluan Subgraf invarian bagi .
Untuk tujuan ini, kita mesti mencari yang lain syarat setara untuk mengenal pasti keperluan Subgraf invarian bagi .  Pembelajaran graf invarian yang diilhamkan sebab
Pembelajaran graf invarian yang diilhamkan sebab 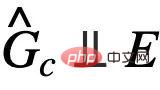 Untuk menyelesaikan masalah pengenalan subgraf invarian dengan kehadiran unsur yang hilang, berdasarkan kerangka formula (1) , kami berharap untuk mendapatkan syarat kesetaraan yang Mudah dilaksanakan untuk persamaan (1). Khususnya, kami mula-mula mempertimbangkan kes yang lebih mudah di mana saiz subgraf invarian asas ditetapkan dan diketahui, 〈🎜〉〈🎜〉〈🎜〉. Dalam keadaan sedemikian, pertimbangkan untuk memaksimumkan
Untuk menyelesaikan masalah pengenalan subgraf invarian dengan kehadiran unsur yang hilang, berdasarkan kerangka formula (1) , kami berharap untuk mendapatkan syarat kesetaraan yang Mudah dilaksanakan untuk persamaan (1). Khususnya, kami mula-mula mempertimbangkan kes yang lebih mudah di mana saiz subgraf invarian asas ditetapkan dan diketahui, 〈🎜〉〈🎜〉〈🎜〉. Dalam keadaan sedemikian, pertimbangkan untuk memaksimumkan
, walaupun
mempunyai saiz yang sama dengan 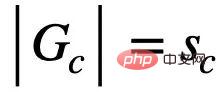 , tetapi kerana
, tetapi kerana 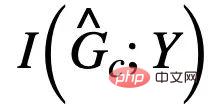 juga berkaitan dengan Y, jadi tanpa sebarang kekangan lain, memaksimumkan
juga berkaitan dengan Y, jadi tanpa sebarang kekangan lain, memaksimumkan  boleh menyebabkan anggaran subgraf invarian mengandungi bahagian yang mempunyai maklumat bersama dengan subgraf palsu Y.
boleh menyebabkan anggaran subgraf invarian mengandungi bahagian yang mempunyai maklumat bersama dengan subgraf palsu Y.  Untuk "memerah" kemungkinan subgraf palsu dalam
Untuk "memerah" kemungkinan subgraf palsu dalam  , kami akan terus mendapatkan maklumat lanjut tentang
, kami akan terus mendapatkan maklumat lanjut tentang 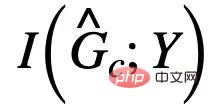 Sifat unik. Ambil perhatian bahawa, tanpa mengira jenis korelasi palsu PIIF atau FIIF, untuk subgraf yang memaksimumkan maklumat bersama dengan label Y, kami mempunyai:
Sifat unik. Ambil perhatian bahawa, tanpa mengira jenis korelasi palsu PIIF atau FIIF, untuk subgraf yang memaksimumkan maklumat bersama dengan label Y, kami mempunyai:
- Persekitaran yang berbeza, dalam dan Subgraf invarian pembolehubah pendam invarian C yang sama ialah dua subgraf dengan maklumat bersama terbesar dalam dua persekitaran, iaitu ; > Dua subgraf invarian yang sepadan dengan pembolehubah pendam invarian berbeza C dalam persekitaran yang sama
- ialah persekitaran ini Kedua-dua subgraf dengan mutual terkecil maklumat, iaitu ;
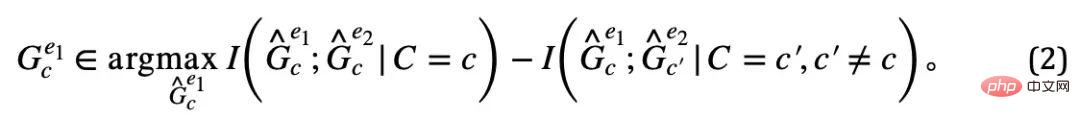
Pada masa yang sama, apabila
dan 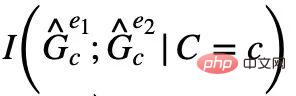 dimaksimumkan pada masa yang sama,
dimaksimumkan pada masa yang sama, 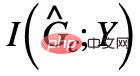 akan Meminimumkan secara automatik, jika tidak, ramalan model akan runtuh kepada penyelesaian remeh. Daripada ini, kami memperoleh keadaan kesetaraan subgraf invarian dalam kes mudah Digabungkan dengan formula (1), kami memperoleh versi pertama rangka kerja Graf Invarian Berinspirasikan Kausalitas (Pembelajaran Graf Invarian Berinspirasikan Kausalitas) Iaitu, CIGAv1:
akan Meminimumkan secara automatik, jika tidak, ramalan model akan runtuh kepada penyelesaian remeh. Daripada ini, kami memperoleh keadaan kesetaraan subgraf invarian dalam kes mudah Digabungkan dengan formula (1), kami memperoleh versi pertama rangka kerja Graf Invarian Berinspirasikan Kausalitas (Pembelajaran Graf Invarian Berinspirasikan Kausalitas) Iaitu, CIGAv1: 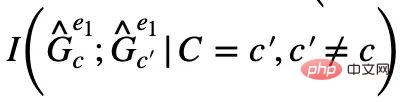
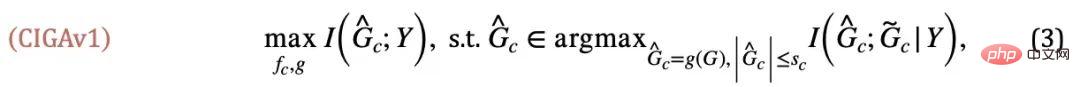
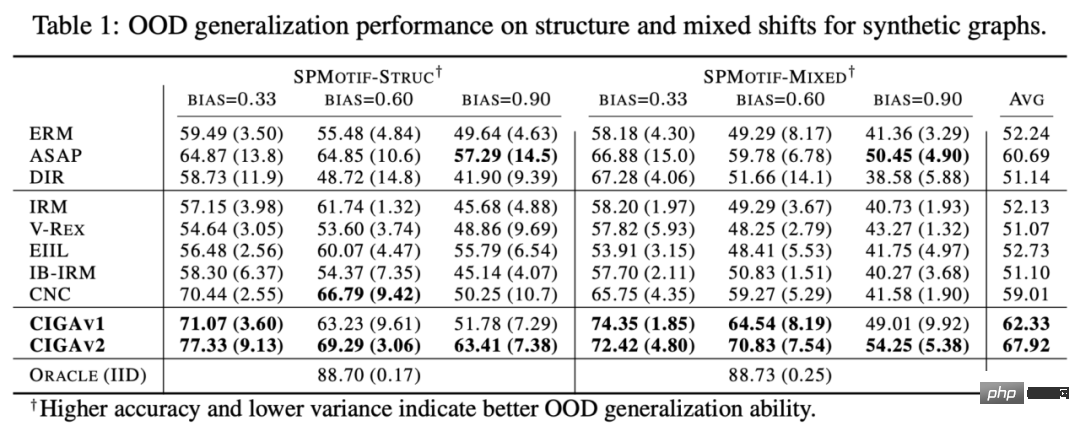
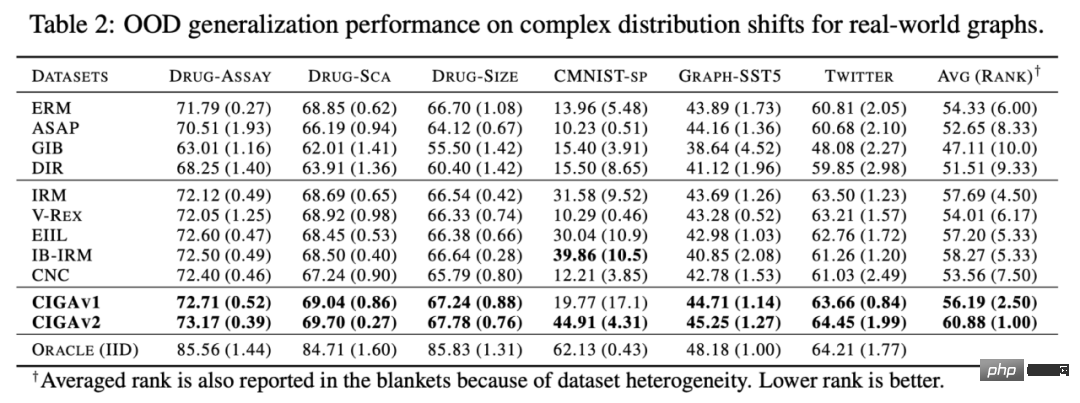
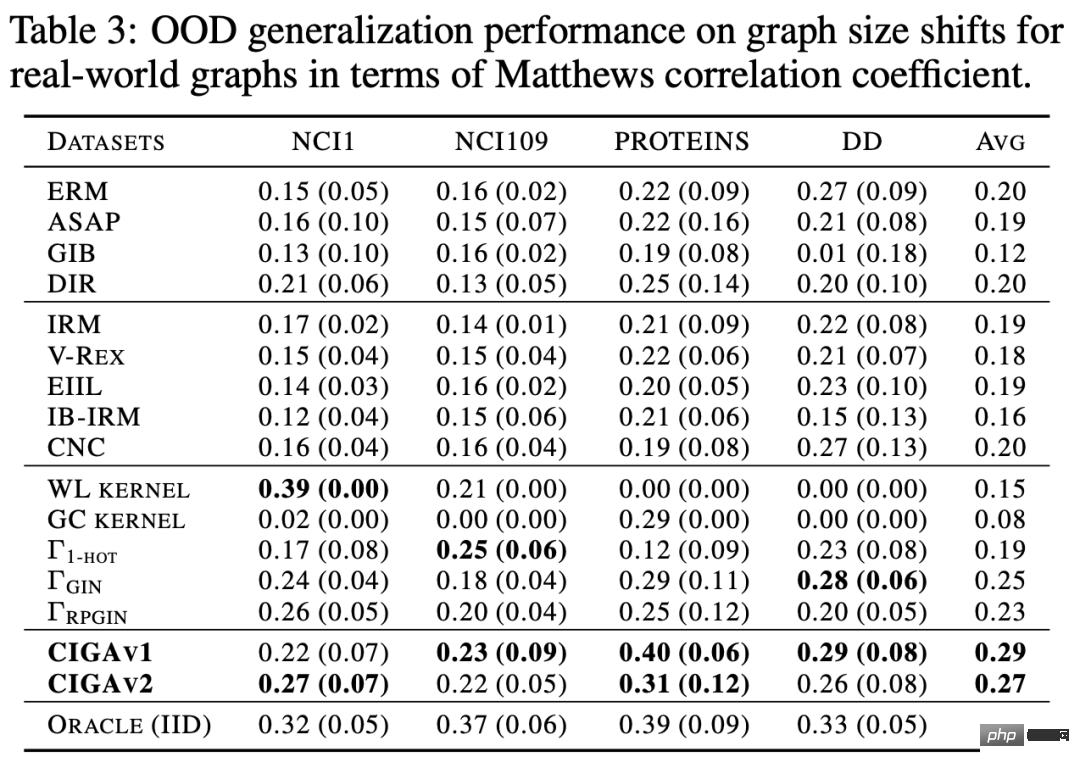
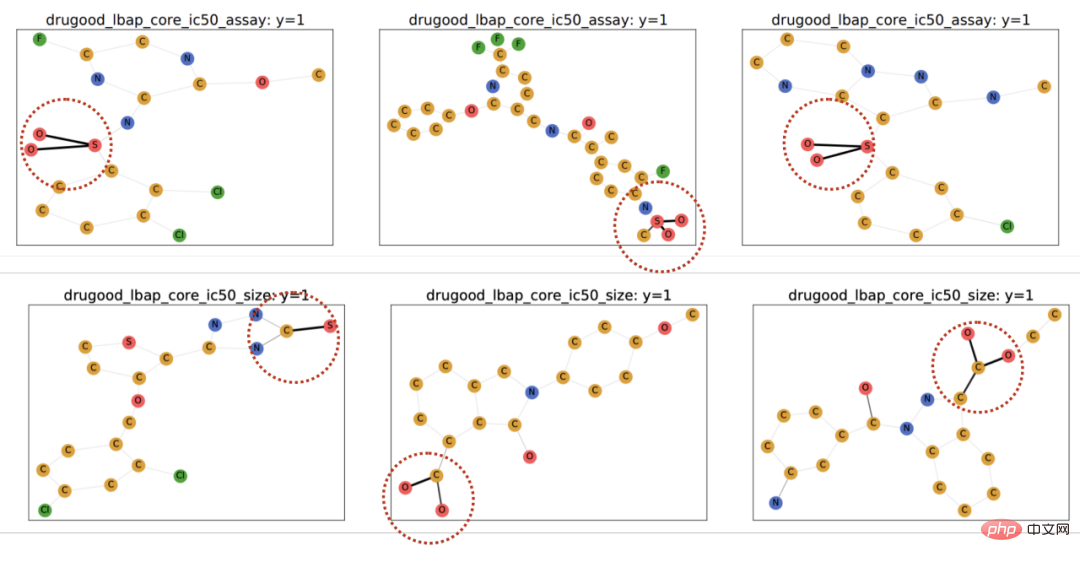
dan Perhatikan bahawa apabila memaksimumkan , Pelaksanaan CIGA: Dalam amalan, selalunya sukar untuk menganggarkan maklumat bersama dua subgraf, manakala pembelajaran kontras diselia [11] menyediakan penyelesaian yang Mungkin: di mana Dalam percubaan, kami menggunakan 16 set data sintetik atau dunia sebenar untuk menjalankan CIGA di bawah anjakan pengedaran graf yang berbeza. Dalam percubaan, kami melaksanakan prototaip CIGA menggunakan rangka kerja GNN yang boleh ditafsir [9], tetapi sebenarnya CIGA mempunyai lebih banyak cara untuk melaksanakannya. Untuk set data khusus dan butiran percubaan, sila lihat bahagian percubaan artikel. Prestasi anjakan pengedaran struktur dan anjakan pengedaran campuran pada set data sintetik Kami mula-mula berdasarkan Set Data SPMotif [9] membina set data SPMotif-Struc dan SPMotif-Mixed, di mana SPMotif-Struc mengandungi korelasi palsu antara subgraf tertentu dan struktur subgraf lain dalam graf, serta anjakan taburan dalam saiz graf manakala SPMotif-Mixed Berdasarkan SPMotif-Struc , offset pengedaran baharu pada tahap atribut nod graf ditambah. Lajur pertama dalam jadual ialah garis dasar ERM dan GNN yang boleh ditafsir, dan lajur kedua ialah algoritma generalisasi luar pengedaran yang paling maju dalam ruang Euclidean. Ia boleh didapati daripada keputusan bahawa kedua-dua rangka kerja GNN yang lebih baik dan algoritma generalisasi luar pengedaran dalam ruang Euclidean tertakluk kepada anjakan pengedaran pada graf, dan apabila lebih banyak anjakan pengedaran berlaku, kehilangan prestasi (prestasi klasifikasi purata yang lebih kecil. atau varians yang lebih besar) akan dipertingkatkan lagi. Sebaliknya, CIGA mengekalkan prestasi yang baik di bawah anjakan pengedaran dengan kekuatan yang berbeza dan jauh melebihi prestasi asas terbaik. Prestasi pelbagai anjakan pengedaran graf pada set data sebenar Kami kemudian menguji lagi prestasi CIGA pada set data sebenar dan anjakan pengedaran graf yang wujud dalam pelbagai data sebenar, termasuk tiga bahagian persekitaran berbeza dalam DrugOOD (persekitaran eksperimen Assay, molekul) daripada ramalan atribut molekul ubat dalam farmaseutikal berbantukan AI Tiga set data Skeleton (Scaffold, Molecular Size) mengandungi anjakan graf pelbagai senario aplikasi sebenar yang ditukarkan berdasarkan set data imej klasik ColoredMNIST [10] dalam ruang Euclidean terutamanya mengandungi nod graf jenis PIIF; Graph-SST5 dan Twitter [15] ditukar daripada set data klasifikasi emosi bahasa semula jadi SST5 dan Twitter, dan tambahan pengedaran mengimbangi darjah graf ditambah. Selain itu, kami juga menggunakan 4 set data anjakan saiz graf molekul yang telah dikaji sebelumnya [7], Keputusan ujian ditunjukkan dalam jadual di atas. Ia boleh didapati bahawa dalam data sebenar, disebabkan peningkatan dalam kesukaran tugas , GNN dengan seni bina yang lebih baik digunakan Atau prestasi model yang diperoleh dengan melatih sasaran pengoptimuman generalisasi luar pengedaran dalam ruang Euclidean adalah lebih lemah daripada model GNN biasa yang dilatih menggunakan ERM. Fenomena ini juga serupa dengan fenomena yang diperhatikan dalam eksperimen generalisasi luar taburan di bawah tugas yang lebih sukar dalam ruang Euclidean [16], mencerminkan kesukaran generalisasi luar taburan pada data sebenar dan kelemahan kaedah sedia ada. Sebaliknya, CIGA boleh menambah baik pada semua anjakan pengedaran data dan graf sebenar, malah mencapai tahap Oracle optimum secara empirik dalam beberapa set data seperti Twitter dan PROTEIN. Ujian awal pada penanda aras ujian pengitlakan luar taburan graf terkini BAIK pada set data pengelasan graf juga menunjukkan bahawa CIGA pada masa ini ialah algoritma generalisasi luar taburan graf terbaik yang boleh mengatasi pelbagai anjakan taburan graf. Disebabkan penggunaan GNN yang boleh ditafsir sebagai seni bina pelaksanaan prototaip CIGA, kami juga memvisualisasikan DrugOOD yang dikenal pasti oleh model dan mendapati bahawa CIGA telah menemui beberapa pangkalan molekul yang agak konsisten digunakan untuk ramalan sifat molekul. Ini boleh memberikan asas yang lebih baik untuk farmaseutikal dibantu AI berikutnya. Rajah 6. Subgraf invarian separa yang dikenal pasti oleh CIGA dalam DrugOOD. Melalui perspektif inferens sebab, makalah ini memperkenalkan invarian sebab kepada taburan graf di bawah pelbagai anjakan taburan graf untuk yang pertama masa Dalam masalah generalisasi luaran, rangka kerja penyelesaian baharu CIGA dengan jaminan teori dicadangkan. Sebilangan besar percubaan juga telah mengesahkan sepenuhnya prestasi generalisasi luar pengedaran CIGA yang sangat baik. Melihat ke masa hadapan, berdasarkan CIGA, kami boleh meneroka lebih lanjut rangka kerja pelaksanaan yang lebih baik [17], atau memperkenalkan kaedah peningkatan data yang dijamin secara teori yang lebih baik untuk CIGA [3,18], dan secara teorinya memodelkan perkaitan pada graf (Covariate Shift ) [19] untuk meningkatkan lagi keupayaan CIGA untuk mengenal pasti subgraf invarian dan menggalakkan pelaksanaan sebenar rangkaian saraf graf dalam senario aplikasi sebenar seperti farmaseutikal berbantukan AI.  , iaitu
, iaitu  adalah daripada kategori Y yang sama dengan G. Dalam kertas kerja kami, kami selanjutnya menunjukkan bahawa CIGAv1 boleh berjaya mengenal pasti subgraf invarian yang berpotensi dalam model kausal yang sepadan dengan Rajah 4 apabila saiz graf diketahui. Walau bagaimanapun, kerana andaian sebelumnya terlalu ideal, dalam amalan, saiz subgraf invarian mungkin berubah dan saiz yang sepadan selalunya tidak diketahui. Di bawah andaian tiada saiz subgraf, keperluan CIGAv1 boleh dipenuhi dengan hanya mengenal pasti keseluruhan graf sebagai subgraf invarian. Oleh itu, kami mempertimbangkan untuk mencari lagi sifat tentang subgraf invarian untuk mengalih keluar andaian ini.
adalah daripada kategori Y yang sama dengan G. Dalam kertas kerja kami, kami selanjutnya menunjukkan bahawa CIGAv1 boleh berjaya mengenal pasti subgraf invarian yang berpotensi dalam model kausal yang sepadan dengan Rajah 4 apabila saiz graf diketahui. Walau bagaimanapun, kerana andaian sebelumnya terlalu ideal, dalam amalan, saiz subgraf invarian mungkin berubah dan saiz yang sepadan selalunya tidak diketahui. Di bawah andaian tiada saiz subgraf, keperluan CIGAv1 boleh dipenuhi dengan hanya mengenal pasti keseluruhan graf sebagai subgraf invarian. Oleh itu, kami mempertimbangkan untuk mencari lagi sifat tentang subgraf invarian untuk mengalih keluar andaian ini. 
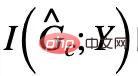 mungkin muncul
mungkin muncul  berkongsi maklumat bersama yang sama dan berkaitan seperti bahagian subgraf invarian yang dialih keluar. Jadi, bolehkah kita melakukan sebaliknya dan pada masa yang sama memaksimumkan
berkongsi maklumat bersama yang sama dan berkaitan seperti bahagian subgraf invarian yang dialih keluar. Jadi, bolehkah kita melakukan sebaliknya dan pada masa yang sama memaksimumkan 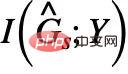 untuk mengalih keluar kemungkinan bahagian subgraf palsu
untuk mengalih keluar kemungkinan bahagian subgraf palsu  ? Jawapannya ya, kita boleh menggunakan korelasi antara
? Jawapannya ya, kita boleh menggunakan korelasi antara  dan Y untuk menjadikannya bersaing dengan anggaran
dan Y untuk menjadikannya bersaing dengan anggaran  . Perlu diingatkan bahawa apabila memaksimumkan
. Perlu diingatkan bahawa apabila memaksimumkan 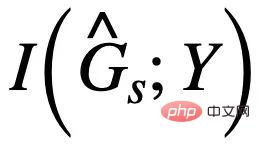 adalah perlu untuk memastikan bahawa
adalah perlu untuk memastikan bahawa 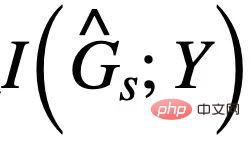 tidak akan melebihi
tidak akan melebihi 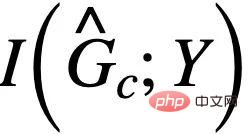 , jika tidak akan yang diramalkan akan jatuh ke dalam penyelesaian yang remeh sekali lagi. Digabungkan dengan syarat tambahan ini, kita boleh mengalih keluar andaian tentang saiz subgraf malar daripada formula (3) dan mendapatkan CIGAv2 berikut:
, jika tidak akan yang diramalkan akan jatuh ke dalam penyelesaian yang remeh sekali lagi. Digabungkan dengan syarat tambahan ini, kita boleh mengalih keluar andaian tentang saiz subgraf malar daripada formula (3) dan mendapatkan CIGAv2 berikut: 
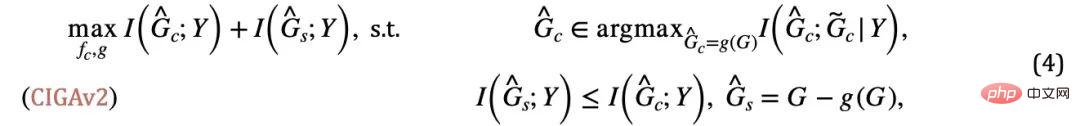
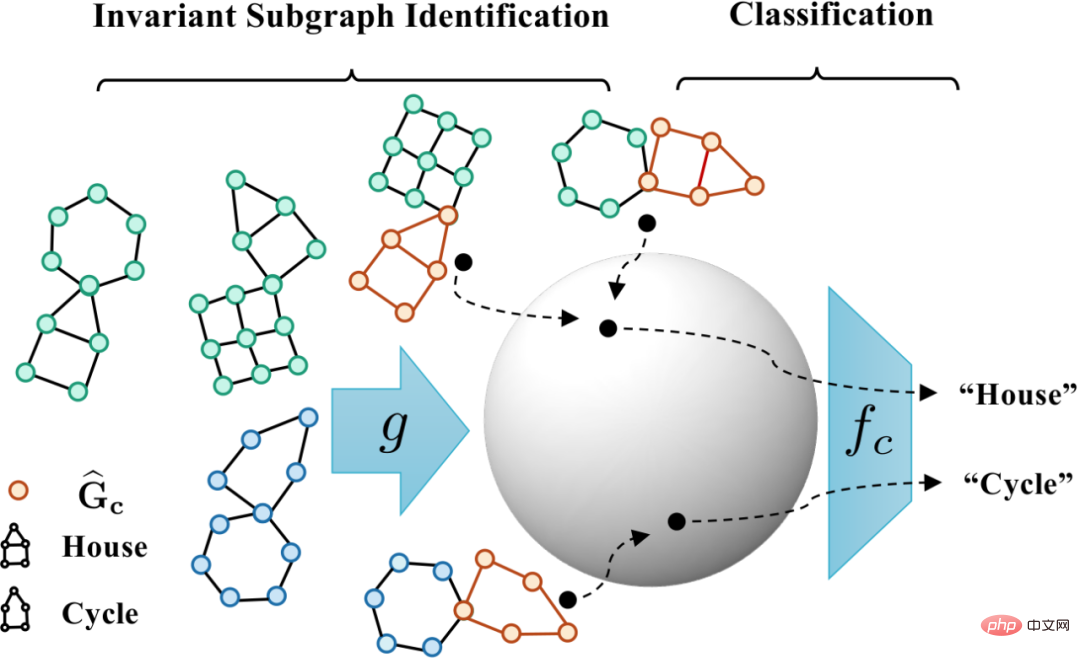 Rajah 5. Skema rangka kerja pembelajaran graf invarian yang diilhamkan secara kausal.
Rajah 5. Skema rangka kerja pembelajaran graf invarian yang diilhamkan secara kausal. 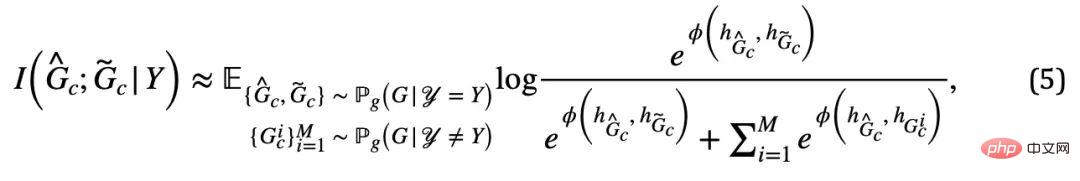
 sepadan dengan sampel positif dalam formula (4), manakala
sepadan dengan sampel positif dalam formula (4), manakala 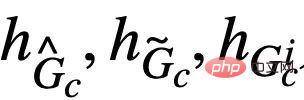 sepadan dengan
sepadan dengan 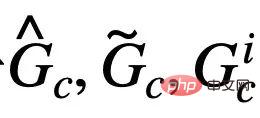 Rajah mewakili. Apabila
Rajah mewakili. Apabila  , formula (5) menyediakan penganggar entropi penggantian semula bukan parametrik berdasarkan kepadatan isirong von Mises-Fisher untuk
, formula (5) menyediakan penganggar entropi penggantian semula bukan parametrik berdasarkan kepadatan isirong von Mises-Fisher untuk 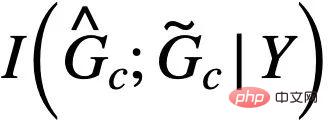 )[13,14]. Pelaksanaan akhir bahagian teras CIGA ditunjukkan dalam Rajah 5, iaitu, dengan mendekatkan perwakilan graf kategori subgraf invarian kategori yang sama dalam ruang perwakilan terpendam, dan pada masa yang sama memaksimumkan perwakilan graf bagi kategori berbeza bagi subgraf invarian untuk memaksimumkan
)[13,14]. Pelaksanaan akhir bahagian teras CIGA ditunjukkan dalam Rajah 5, iaitu, dengan mendekatkan perwakilan graf kategori subgraf invarian kategori yang sama dalam ruang perwakilan terpendam, dan pada masa yang sama memaksimumkan perwakilan graf bagi kategori berbeza bagi subgraf invarian untuk memaksimumkan 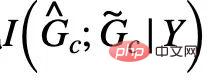 . Di samping itu, untuk satu lagi kekangan dalam formula (4), kita boleh melaksanakannya melalui idea kehilangan engsel, iaitu,
. Di samping itu, untuk satu lagi kekangan dalam formula (4), kita boleh melaksanakannya melalui idea kehilangan engsel, iaitu, 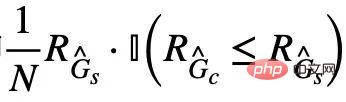 Hanya apabila mengoptimumkan ramalan, kerugian empirikal adalah lebih besar daripada invarian sepadan Subgraf palsu subgraf.
Hanya apabila mengoptimumkan ramalan, kerugian empirikal adalah lebih besar daripada invarian sepadan Subgraf palsu subgraf. Eksperimen dan Perbincangan
Ringkasan dan Tinjauan
Atas ialah kandungan terperinci Kaedah pembelajaran perwakilan sebab yang dicadangkan oleh Hong Kong et al bertujuan untuk masalah generalisasi luaran taburan data ortografik.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Di barisan hadapan teknologi perisian, kumpulan UIUC Zhang Lingming, bersama penyelidik dari organisasi BigCode, baru-baru ini mengumumkan model kod besar StarCoder2-15B-Instruct. Pencapaian inovatif ini mencapai kejayaan ketara dalam tugas penjanaan kod, berjaya mengatasi CodeLlama-70B-Instruct dan mencapai bahagian atas senarai prestasi penjanaan kod. Keunikan StarCoder2-15B-Instruct terletak pada strategi penjajaran diri yang tulen Keseluruhan proses latihan adalah terbuka, telus, dan sepenuhnya autonomi dan boleh dikawal. Model ini menjana beribu-ribu arahan melalui StarCoder2-15B sebagai tindak balas kepada penalaan halus model asas StarCoder-15B tanpa bergantung pada anotasi manual yang mahal.
 Yolov10: Penjelasan terperinci, penggunaan dan aplikasi semuanya di satu tempat!
Jun 07, 2024 pm 12:05 PM
Yolov10: Penjelasan terperinci, penggunaan dan aplikasi semuanya di satu tempat!
Jun 07, 2024 pm 12:05 PM
1. Pengenalan Sejak beberapa tahun kebelakangan ini, YOLO telah menjadi paradigma dominan dalam bidang pengesanan objek masa nyata kerana keseimbangannya yang berkesan antara kos pengiraan dan prestasi pengesanan. Penyelidik telah meneroka reka bentuk seni bina YOLO, matlamat pengoptimuman, strategi pengembangan data, dsb., dan telah mencapai kemajuan yang ketara. Pada masa yang sama, bergantung pada penindasan bukan maksimum (NMS) untuk pemprosesan pasca menghalang penggunaan YOLO dari hujung ke hujung dan memberi kesan buruk kepada kependaman inferens. Dalam YOLO, reka bentuk pelbagai komponen tidak mempunyai pemeriksaan yang komprehensif dan teliti, mengakibatkan lebihan pengiraan yang ketara dan mengehadkan keupayaan model. Ia menawarkan kecekapan suboptimum, dan potensi yang agak besar untuk peningkatan prestasi. Dalam kerja ini, matlamatnya adalah untuk meningkatkan lagi sempadan kecekapan prestasi YOLO daripada kedua-dua pasca pemprosesan dan seni bina model. sampai habis
 Universiti Tsinghua mengambil alih dan YOLOv10 keluar: prestasi telah bertambah baik dan ia berada dalam senarai panas GitHub
Jun 06, 2024 pm 12:20 PM
Universiti Tsinghua mengambil alih dan YOLOv10 keluar: prestasi telah bertambah baik dan ia berada dalam senarai panas GitHub
Jun 06, 2024 pm 12:20 PM
Siri penanda aras YOLO sistem pengesanan sasaran sekali lagi menerima peningkatan besar. Sejak pengeluaran YOLOv9 pada Februari tahun ini, baton siri YOLO (YouOnlyLookOnce) telah diserahkan kepada penyelidik di Universiti Tsinghua. Hujung minggu lalu, berita pelancaran YOLOv10 menarik perhatian komuniti AI. Ia dianggap sebagai rangka kerja terobosan dalam bidang penglihatan komputer dan terkenal dengan keupayaan pengesanan objek hujung ke hujung masa nyata, meneruskan legasi siri YOLO dengan menyediakan penyelesaian berkuasa yang menggabungkan kecekapan dan ketepatan. Alamat kertas: https://arxiv.org/pdf/2405.14458 Alamat projek: https://github.com/THU-MIG/yo
 Bagaimana untuk menilai keberkesanan kos sokongan komersial untuk rangka kerja Java
Jun 05, 2024 pm 05:25 PM
Bagaimana untuk menilai keberkesanan kos sokongan komersial untuk rangka kerja Java
Jun 05, 2024 pm 05:25 PM
Menilai kos/prestasi sokongan komersial untuk rangka kerja Java melibatkan langkah-langkah berikut: Tentukan tahap jaminan yang diperlukan dan jaminan perjanjian tahap perkhidmatan (SLA). Pengalaman dan kepakaran pasukan sokongan penyelidikan. Pertimbangkan perkhidmatan tambahan seperti peningkatan, penyelesaian masalah dan pengoptimuman prestasi. Timbang kos sokongan perniagaan terhadap pengurangan risiko dan peningkatan kecekapan.
 Laporan teknikal Google Gemini 1.5: Buktikan soalan Olimpik Matematik dengan mudah, versi Flash adalah 5 kali lebih pantas daripada GPT-4 Turbo
Jun 13, 2024 pm 01:52 PM
Laporan teknikal Google Gemini 1.5: Buktikan soalan Olimpik Matematik dengan mudah, versi Flash adalah 5 kali lebih pantas daripada GPT-4 Turbo
Jun 13, 2024 pm 01:52 PM
Pada bulan Februari tahun ini, Google melancarkan model besar berbilang modal Gemini 1.5, yang telah meningkatkan prestasi dan kelajuan dengan sangat baik melalui pengoptimuman kejuruteraan dan infrastruktur, seni bina MoE dan strategi lain. Dengan konteks yang lebih panjang, keupayaan penaakulan yang lebih kukuh dan pengendalian kandungan merentas modal yang lebih baik. Jumaat ini, Google DeepMind secara rasmi mengeluarkan laporan teknikal Gemini 1.5, yang merangkumi versi Flash dan peningkatan terkini yang lain Dokumen itu sepanjang 153 halaman. Pautan laporan teknikal: https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf Dalam laporan ini, Google memperkenalkan Gemini1
 Semakan! Ringkaskan secara menyeluruh peranan penting model asas dalam mempromosikan pemanduan autonomi
Jun 11, 2024 pm 05:29 PM
Semakan! Ringkaskan secara menyeluruh peranan penting model asas dalam mempromosikan pemanduan autonomi
Jun 11, 2024 pm 05:29 PM
Ditulis di atas & pemahaman peribadi pengarang: Baru-baru ini, dengan perkembangan dan penemuan teknologi pembelajaran mendalam, model asas berskala besar (Model Asas) telah mencapai hasil yang ketara dalam bidang pemprosesan bahasa semula jadi dan penglihatan komputer. Aplikasi model asas dalam pemanduan autonomi juga mempunyai prospek pembangunan yang hebat, yang boleh meningkatkan pemahaman dan penaakulan senario. Melalui pra-latihan tentang bahasa yang kaya dan data visual, model asas boleh memahami dan mentafsir pelbagai elemen dalam senario pemanduan autonomi dan melakukan penaakulan, menyediakan arahan bahasa dan tindakan untuk memacu membuat keputusan dan perancangan. Model asas boleh ditambah data dengan pemahaman senario pemanduan untuk menyediakan ciri-ciri yang jarang berlaku dalam pengedaran ekor panjang yang tidak mungkin ditemui semasa pemanduan rutin dan pengumpulan data.
 Bagaimanakah keluk pembelajaran rangka kerja PHP berbanding rangka kerja bahasa lain?
Jun 06, 2024 pm 12:41 PM
Bagaimanakah keluk pembelajaran rangka kerja PHP berbanding rangka kerja bahasa lain?
Jun 06, 2024 pm 12:41 PM
Keluk pembelajaran rangka kerja PHP bergantung pada kecekapan bahasa, kerumitan rangka kerja, kualiti dokumentasi dan sokongan komuniti. Keluk pembelajaran rangka kerja PHP adalah lebih tinggi jika dibandingkan dengan rangka kerja Python dan lebih rendah jika dibandingkan dengan rangka kerja Ruby. Berbanding dengan rangka kerja Java, rangka kerja PHP mempunyai keluk pembelajaran yang sederhana tetapi masa yang lebih singkat untuk bermula.
 Bagaimanakah pilihan rangka kerja PHP yang ringan mempengaruhi prestasi aplikasi?
Jun 06, 2024 am 10:53 AM
Bagaimanakah pilihan rangka kerja PHP yang ringan mempengaruhi prestasi aplikasi?
Jun 06, 2024 am 10:53 AM
Rangka kerja PHP yang ringan meningkatkan prestasi aplikasi melalui saiz kecil dan penggunaan sumber yang rendah. Ciri-cirinya termasuk: saiz kecil, permulaan pantas, penggunaan memori yang rendah, kelajuan dan daya tindak balas yang dipertingkatkan, dan penggunaan sumber yang dikurangkan: SlimFramework mencipta API REST, hanya 500KB, responsif yang tinggi dan daya pemprosesan yang tinggi.
