

Kaedah pertahanan pintu belakang latihan pintu belakang bersegmen: DBD

Kumpulan penyelidik Profesor Wu Baoyuan dari Universiti China Hong Kong (Shenzhen) dan kumpulan penyelidik Profesor Qin Zhan dari Universiti Zhejiang bersama-sama menerbitkan artikel dalam bidang pertahanan pintu belakang, yang telah berjaya diterima oleh ICLR2022.
Dalam beberapa tahun kebelakangan ini, isu pintu belakang telah mendapat perhatian yang meluas. Memandangkan serangan pintu belakang terus dicadangkan, ia menjadi semakin sukar untuk mencadangkan kaedah pertahanan terhadap serangan pintu belakang umum. Kertas kerja ini mencadangkan kaedah pertahanan pintu belakang berdasarkan proses latihan pintu belakang bersegmen.
Artikel ini mendedahkan bahawa serangan pintu belakang ialah kaedah latihan diselia hujung ke hujung yang menayangkan pintu belakang ke dalam ruang ciri. Atas dasar ini, artikel ini membahagikan proses latihan untuk mengelakkan serangan pintu belakang. Eksperimen perbandingan telah dijalankan antara kaedah ini dan kaedah pertahanan pintu belakang yang lain untuk membuktikan keberkesanan kaedah ini.
Persidangan kemasukan: ICLR2022
Pautan artikel: https://arxiv.org/pdf/ 2202.03423.pdf
Pautan kod: https://github.com/SCLBD/DBD
1 Pengenalan latar belakang
Matlamat serangan pintu belakang adalah untuk membuat model meramalkan sampel yang betul dan bersih dengan mengubah suai data latihan atau mengawal proses latihan, tetapi sampel dengan pintu belakang dinilai sebagai sasaran label. Sebagai contoh, penyerang pintu belakang menambah blok putih kedudukan tetap pada imej (iaitu, imej beracun) dan menukar label imej kepada label sasaran. Selepas melatih model dengan data beracun ini, model akan menentukan bahawa imej dengan blok putih tertentu ialah label sasaran (seperti yang ditunjukkan dalam rajah di bawah).
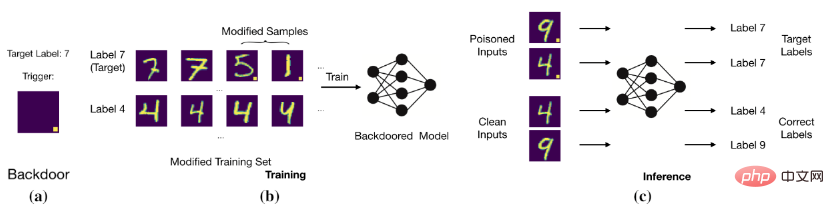 Serangan pintu belakang asas
Serangan pintu belakang asas
Model menetapkan label teg pencetus dan sasaran).
2 Kerja berkaitan
2.1 Serangan pintu belakang
Kaedah serangan pintu belakang sedia ada adalah seperti berikut: keracunan Pengubahsuaian label imej dibahagikan kepada dua kategori berikut: Serangan Pintu Belakang Label Beracun, yang mengubah suai label imej beracun, dan Serangan Pintu Belakang Label Bersih, yang mengekalkan label asal imej beracun.
1. Serangan tag keracunan: BadNets (Gu et al., 2019) ialah serangan tag keracunan yang pertama dan paling mewakili. Kemudian (Chen et al., 2017) mencadangkan bahawa halimunan imej beracun harus serupa dengan versi jinak mereka, dan berdasarkan ini, serangan campuran telah dicadangkan. Baru-baru ini, (Xue et al., 2020; Li et al., 2020; 2021) meneroka lebih lanjut cara melakukan serangan pintu belakang tanda keracunan secara lebih rahsia. Baru-baru ini, serangan yang lebih senyap dan berkesan, WaNet (Nguyen & Tran, 2021), telah dicadangkan. WaNet menggunakan herotan imej sebagai pencetus pintu belakang, yang mengekalkan kandungan imej sambil mengubah bentuknya.
2. Serangan tag bersih: Untuk menyelesaikan masalah yang pengguna dapat melihat serangan pintu belakang dengan menyemak hubungan tag imej, Turner et al (2019) mencadangkan paradigma serangan tag bersih, di mana Label sasaran adalah konsisten dengan label asal sampel beracun. Idea ini diperluaskan untuk menyerang klasifikasi video dalam (Zhao et al., 2020b), yang menggunakan gangguan permusuhan umum (Moosavi-Dezfooli et al., 2017) sebagai pencetus. Walaupun serangan pintu belakang teg bersih adalah lebih halus daripada serangan pintu belakang teg beracun, prestasinya biasanya agak lemah dan mungkin tidak mewujudkan pintu belakang (Li et al., 2020c).
2.2 Pertahanan Pintu Belakang
Pertahanan pintu belakang sedia ada kebanyakannya empirikal dan boleh dibahagikan kepada lima kategori, termasuk
1. Pertahanan berasaskan pengesanan (Xu et al, 2021; Zeng et al, 2011; Xiang et al, 2022) menyemak sama ada model atau sampel yang mencurigakan diserang, dan ia akan menafikan penggunaan objek berniat jahat.
2. Pertahanan berasaskan prapemprosesan (Doan et al, 2020; Li et al, 2021; Zeng et al, 2021) bertujuan untuk memusnahkan corak pencetus yang terkandung dalam sampel serangan, dengan Modul prapemprosesan diperkenalkan sebelum memasukkan imej ke dalam model untuk mengelakkan pengaktifan pintu belakang.
3. Pertahanan berdasarkan pembinaan semula model (Zhao et al, 2020a; Li et al, 2021;) adalah untuk menghapuskan pintu belakang tersembunyi dalam model dengan mengubah suai model secara langsung.
4. Mencetuskan pertahanan komprehensif (Guo et al, 2020; Dong et al, 2021; Shen et al, 2021) adalah dengan terlebih dahulu mempelajari pintu belakang dan kedua menghapuskan pintu belakang yang tersembunyi dengan menekan kesannya.
5. Pertahanan berdasarkan penindasan keracunan (Du et al, 2020; Borgnia et al, 2021) mengurangkan keberkesanan sampel beracun semasa proses latihan untuk mencegah penjanaan pintu belakang tersembunyi
2.3 Pembelajaran separuh penyeliaan dan pembelajaran penyeliaan kendiri
1 data berlabel Selalunya bergantung pada pelabelan manual, yang sangat mahal. Sebagai perbandingan, adalah lebih mudah untuk mendapatkan sampel yang tidak berlabel. Untuk memanfaatkan kuasa kedua-dua sampel yang tidak berlabel dan berlabel, sejumlah besar kaedah pembelajaran separa penyeliaan telah dicadangkan (Gao et al., 2017; Berthelot et al, 2019; Van Engelen & Hoos, 2020). Baru-baru ini, pembelajaran separa penyeliaan juga telah digunakan untuk meningkatkan keselamatan model (Stanforth et al, 2019; Carmon et al, 2019), yang menggunakan sampel tidak berlabel dalam latihan lawan. Baru-baru ini, (Yan et al, 2021) telah membincangkan cara pembelajaran separa penyeliaan pintu belakang. Walau bagaimanapun, selain mengubah suai sampel latihan, kaedah ini juga perlu mengawal komponen latihan lain (seperti kehilangan latihan).
2. Pembelajaran penyeliaan kendiri: Paradigma pembelajaran penyeliaan kendiri ialah subset pembelajaran tanpa penyeliaan, dan model dilatih menggunakan isyarat yang dihasilkan oleh data itu sendiri (Chen et al, 2020a ; Grill et al , 2020; Ia digunakan untuk meningkatkan kekukuhan lawan (Hendrycks et al, 2019; Wu et al, 2021; Shi et al, 2021). Baru-baru ini, beberapa artikel (Saha et al, 2021; Carlini & Terzis, 2021; Jia et al, 2021) meneroka cara meletakkan pintu belakang ke dalam pembelajaran penyeliaan kendiri. Walau bagaimanapun, selain mengubah suai sampel latihan, serangan ini juga memerlukan kawalan komponen latihan lain (cth., kehilangan latihan).
3 Ciri Pintu Belakang
Kami menjalankan BadNets dan serangan label bersih pada set data CIFAR-10 (Krizhevsky, 2009). Pembelajaran diselia pada set data toksik dan pembelajaran diselia sendiri SimCLR pada set data tidak berlabel (Chen et al., 2020a).
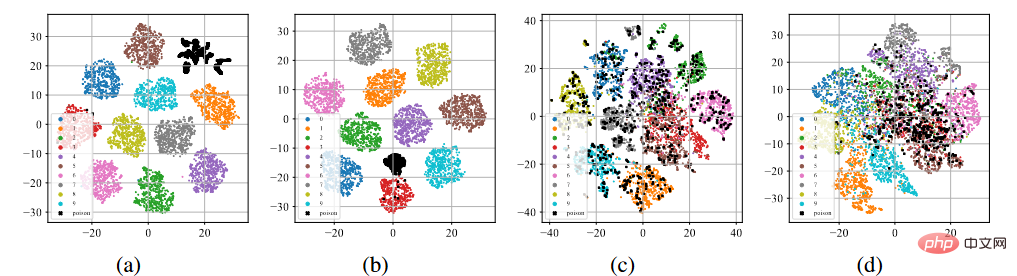
T-sne paparan ciri pintu belakang
Seperti yang ditunjukkan di atas ( a )-(b), selepas melalui proses latihan standard yang diselia, sampel beracun (diwakili oleh titik hitam) cenderung berkumpul bersama untuk membentuk kelompok yang berasingan tanpa mengira serangan label beracun atau serangan label bersih. Fenomena ini membayangkan kejayaan serangan pintu belakang berasaskan keracunan sedia ada. Pembelajaran berlebihan membolehkan model mempelajari ciri-ciri pencetus pintu belakang. Digabungkan dengan paradigma latihan diselia hujung ke hujung, model ini boleh mengurangkan jarak antara sampel beracun dalam ruang ciri dan menghubungkan ciri berkaitan pencetus yang dipelajari dengan label sasaran. Sebaliknya, seperti yang ditunjukkan dalam Rajah (c)-(d) di atas, pada set data keracunan tidak berlabel, selepas proses latihan yang diselia sendiri, sampel yang diracun adalah sangat hampir dengan sampel dengan label asal. Ini menunjukkan bahawa kita boleh menghalang pintu belakang melalui pembelajaran penyeliaan sendiri.
4 Pertahanan pintu belakang berdasarkan segmentasi
Berdasarkan analisis ciri pintu belakang, kami mencadangkan pertahanan pintu belakang dalam fasa latihan segmentasi. Seperti yang ditunjukkan dalam rajah di bawah, ia terdiri daripada tiga peringkat utama, (1) mempelajari pengekstrak ciri yang dimurnikan melalui pembelajaran penyeliaan kendiri, (2) menapis sampel berkeyakinan tinggi melalui pembelajaran bunyi label, dan (3) halus separa penyeliaan. penalaan.
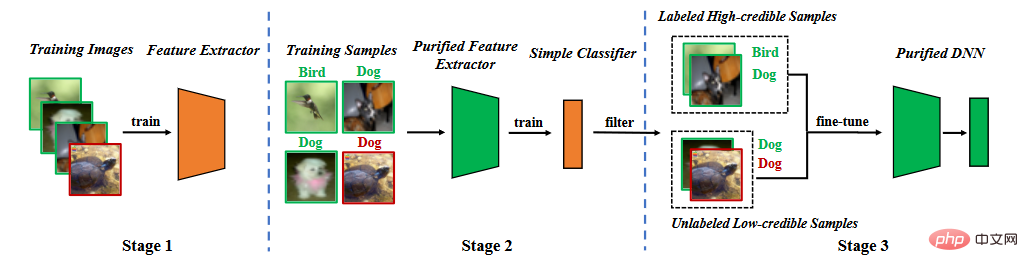 Carta alir kaedah
Carta alir kaedah
4.1 Pengekstrak ciri pembelajaran
Kami menggunakan set data latihan untuk mempelajari model. Parameter model termasuk dua bahagian, satu ialah parameter model tulang belakang dan satu lagi ialah parameter lapisan bersambung sepenuhnya. Kami menggunakan pembelajaran diselia sendiri untuk mengoptimumkan parameter model tulang belakang.
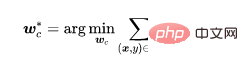
di manakah kerugian yang diselia sendiri (contohnya, NT-Xent dalam SimCLR (Chen et al, 2020)). , kita boleh Tahu bahawa sukar bagi pengekstrak ciri untuk mempelajari ciri pintu belakang.
4.2 Labelkan sampel yang ditapis pembelajaran hingar
Setelah pengekstrak ciri dilatih, kami menetapkan parameter pengekstrak ciri dan menggunakan set data latihan untuk mempelajari lebih lanjut sepenuhnya parameter lapisan bersambung ,
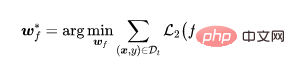
di manakah kehilangan pembelajaran yang diselia (contohnya, kehilangan entropi silang).
Walaupun proses segmentasi sedemikian akan menyukarkan model untuk mempelajari pintu belakang, ia mempunyai dua masalah. Pertama, berbanding dengan kaedah yang dilatih melalui pembelajaran terselia, memandangkan pengekstrak ciri yang dipelajari dibekukan pada peringkat kedua, akan terdapat penurunan tertentu dalam ketepatan meramalkan sampel bersih. Kedua, apabila serangan label beracun berlaku, sampel beracun akan berfungsi sebagai "outlier", seterusnya menghalang peringkat kedua pembelajaran. Kedua-dua isu ini menunjukkan bahawa kita perlu mengalih keluar sampel beracun dan melatih semula atau memperhalusi keseluruhan model.
Kami perlu menentukan sama ada sampel mempunyai pintu belakang. Kami percaya bahawa sukar untuk model belajar daripada sampel pintu belakang, jadi kami menggunakan keyakinan sebagai penunjuk perbezaan Sampel berkeyakinan tinggi ialah sampel bersih, manakala sampel berkeyakinan rendah adalah sampel beracun. Melalui eksperimen, didapati model yang dilatih menggunakan kehilangan rentas entropi simetri mempunyai jurang kehilangan yang besar antara kedua-dua sampel, maka tahap diskriminasi adalah tinggi, seperti yang ditunjukkan dalam rajah di bawah.
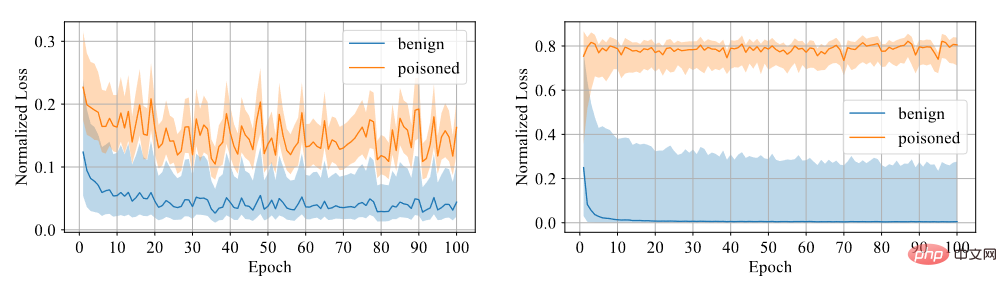
Perbandingan antara kehilangan rentas entropi simetri dan kehilangan rentas entropi
Oleh itu, Kami melatih lapisan bersambung sepenuhnya dengan pengekstrak ciri tetap menggunakan kehilangan entropi silang simetri, dan menapis set data ke dalam data berkeyakinan tinggi dan data berkeyakinan rendah mengikut saiz keyakinan.
4.3 Penalaan halus separa penyeliaan
Pertama, kami mengalih keluar label data keyakinan rendah. Kami menggunakan pembelajaran separa penyeliaan untuk memperhalusi keseluruhan model.

di manakah kerugian separuh diawasi (cth., fungsi kerugian dalam MixMatch (Berthelot et al., 2019)).
Penalaan halus separa penyeliaan bukan sahaja boleh menghalang model daripada mempelajari pencetus pintu belakang, tetapi juga menjadikan model berprestasi baik pada set data yang bersih.
5 Eksperimen
5.1 Set Data dan Penanda Aras
Artikel mengenai dua data penanda aras klasik Semua pertahanan dinilai pada set, termasuk CIFAR-10 (Krizhevsky, 2009) dan ImageNet (Deng et al., 2009) (subset). Artikel tersebut menggunakan model ResNet18 (He et al., 2016)
Artikel tersebut mengkaji semua kaedah pertahanan untuk bertahan daripada empat serangan tipikal, iaitu badnet (Gu et al., 2019), strategi campuran Serangan pintu belakang (campuran) (Chen et al, 2017), WaNet (Nguyen & Tran, 2021) dan serangan label bersih dengan gangguan musuh (label-konsisten) (Turner et al, 2019).

Gambar contoh serangan pintu belakang
5.2 Hasil eksperimen
Kriteria penghakiman eksperimen adalah ketepatan penghakiman BA sebagai sampel bersih dan ketepatan penghakiman ASR sebagai sampel beracun.
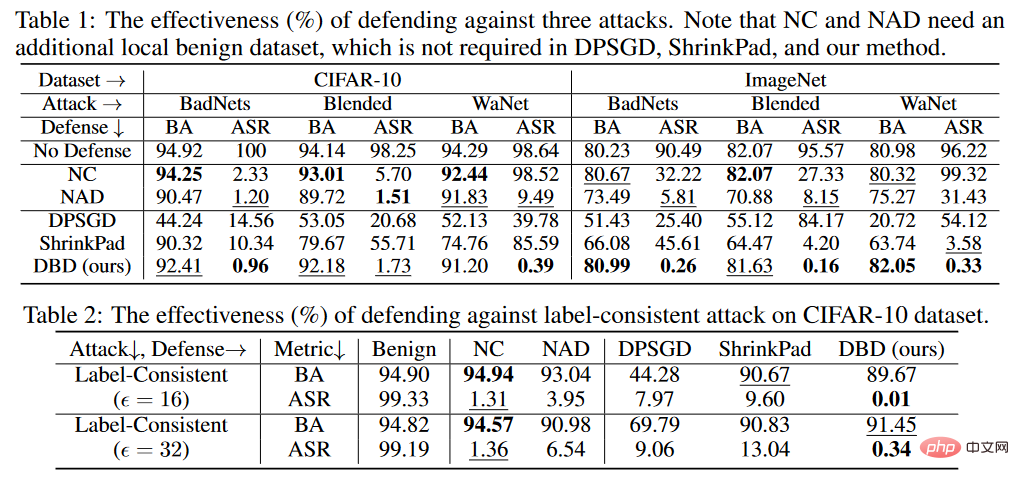
Keputusan perbandingan pertahanan pintu belakang
Seperti yang ditunjukkan dalam jadual di atas, DBD mengungguli pertahanan dengan ketara dengan keperluan yang sama (iaitu DPSGD dan ShrinkPad) terhadap semua serangan. Dalam semua kes, DBD mengatasi DPSGD sebanyak 20% lebih BA dan 5% lebih rendah ASR. ASR model DBD adalah kurang daripada 2% dalam semua kes (kurang daripada 0.5% dalam kebanyakan kes), mengesahkan bahawa DBD berjaya menghalang penciptaan pintu belakang tersembunyi. DBD dibandingkan dengan dua kaedah lain, iaitu NC dan NAD, kedua-duanya memerlukan pembela untuk mempunyai set data tempatan yang bersih.
Seperti yang ditunjukkan dalam jadual di atas, NC dan NAD mengatasi prestasi DPSGD dan ShrinkPad kerana mereka menggunakan maklumat tambahan daripada set data bersih setempat. Khususnya, walaupun NAD dan NC menggunakan maklumat tambahan, DBD lebih baik daripada mereka. Terutamanya pada dataset ImageNet, NC mempunyai kesan terhad untuk mengurangkan ASR. Sebagai perbandingan, DBD mencapai ASR terkecil, manakala BA DBD adalah yang tertinggi atau kedua tertinggi dalam hampir semua kes. Di samping itu, berbanding dengan model tanpa sebarang latihan pertahanan, BA menurun kurang daripada 2% apabila bertahan daripada serangan tag keracunan. Pada set data yang agak besar, DBD adalah lebih baik, kerana semua kaedah garis dasar menjadi kurang berkesan. Keputusan ini mengesahkan keberkesanan DBD.
5.3 Eksperimen Ablasi
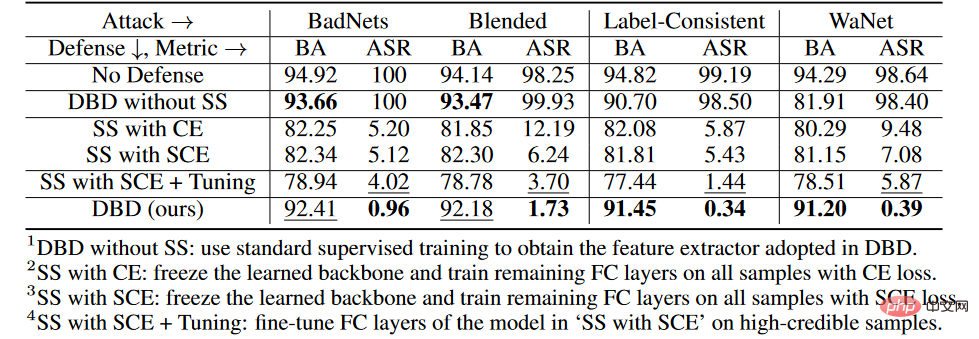
Eksperimen Ablasi pada setiap peringkat
Pada set data CIFAR-10, kami membandingkan DBD yang dicadangkan dan empat variannya, termasuk
1 DBD tanpa SS, yang akan dihasilkan oleh pembelajaran seliaan sendiri dengan tulang belakang dilatih dengan cara yang diawasi, dan pastikan bahagian lain tidak berubah
2.SS dengan CE, bekukan tulang belakang yang dipelajari melalui pembelajaran penyeliaan kendiri, dan jalankan pada semua sampel latihan Latih baki lapisan bersambung sepenuhnya dengan kehilangan entropi silang
3. SS dengan SCE, serupa dengan varian kedua, tetapi dilatih dengan kehilangan entropi silang simetri.
4.SS dengan SCE + Tuning untuk memperhalusi lapisan tersambung sepenuhnya pada sampel berkeyakinan tinggi yang ditapis oleh varian ketiga.
Seperti yang ditunjukkan dalam jadual di atas, mengasingkan proses latihan penyeliaan hujung ke hujung asal adalah berkesan dalam menghalang penciptaan pintu belakang tersembunyi. Tambahan pula, varian DBD kedua dan ketiga dibandingkan untuk mengesahkan keberkesanan kehilangan SCE dalam mempertahankan diri daripada serangan pintu belakang tag racun. Di samping itu, ASR dan BA mutasi DBD keempat adalah lebih rendah daripada mutasi DBD ketiga. Fenomena ini disebabkan oleh penyingkiran sampel berkeyakinan rendah. Ini menunjukkan bahawa menggunakan maklumat berguna daripada sampel berkeyakinan rendah sambil mengurangkan kesan sampingannya adalah penting untuk pertahanan.
5.4 Ketahanan terhadap potensi serangan adaptif
Jika penyerang mengetahui kewujudan DBD, mereka mungkin mereka bentuk serangan adaptif . Jika penyerang dapat mengetahui struktur model yang digunakan oleh pertahanan, mereka boleh mereka bentuk serangan adaptif dengan mengoptimumkan corak pencetus supaya sampel yang diracuni kekal dalam kelompok baharu selepas pembelajaran diselia sendiri, seperti ditunjukkan di bawah:
Tetapan Serangan
Untuk - masalah klasifikasi, biarkan mewakili sampel bersih yang perlu diracun, mewakili sampel dengan label asal, dan menjadi tulang belakang yang terlatih . Memandangkan penjana imej beracun yang telah ditetapkan oleh penyerang, serangan adaptif bertujuan untuk mengoptimumkan corak pencetus dengan meminimumkan jarak antara imej beracun sambil memaksimumkan jarak antara pusat imej beracun dan pusat gugusan imej jinak dengan jarak yang berbeza. iaitu.
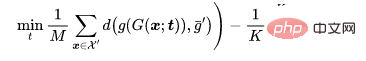
di mana 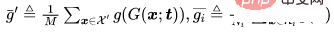 ialah penentuan jarak.
ialah penentuan jarak.
Hasil eksperimen
BA bagi serangan adaptif tanpa pertahanan ialah 94.96%, dan ASR ialah 99.70%. Bagaimanapun, keputusan pertahanan DBD ialah BA93.21% dan ASR1.02%. Dalam erti kata lain, DBD tahan terhadap serangan adaptif tersebut.
6 Ringkasan
Mekanisme serangan pintu belakang berasaskan keracunan adalah untuk mewujudkan potensi sambungan antara corak pencetus dan label sasaran semasa proses latihan. Kertas kerja ini mendedahkan bahawa perkaitan ini disebabkan terutamanya oleh pembelajaran paradigma latihan yang diselia hujung ke hujung. Berdasarkan pemahaman ini, artikel ini mencadangkan kaedah pertahanan pintu belakang berdasarkan decoupling. Sebilangan besar eksperimen telah mengesahkan bahawa pertahanan DBD boleh mengurangkan ancaman pintu belakang sambil mengekalkan ketepatan yang tinggi dalam meramalkan sampel jinak.
Atas ialah kandungan terperinci Kaedah pertahanan pintu belakang latihan pintu belakang bersegmen: DBD. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Sumber terbuka! Di luar ZoeDepth! DepthFM: Anggaran kedalaman monokular yang cepat dan tepat!
Apr 03, 2024 pm 12:04 PM
Sumber terbuka! Di luar ZoeDepth! DepthFM: Anggaran kedalaman monokular yang cepat dan tepat!
Apr 03, 2024 pm 12:04 PM
0. Apakah fungsi artikel ini? Kami mencadangkan DepthFM: model anggaran kedalaman monokular generatif yang serba boleh dan pantas. Sebagai tambahan kepada tugas anggaran kedalaman tradisional, DepthFM juga menunjukkan keupayaan terkini dalam tugas hiliran seperti mengecat kedalaman. DepthFM cekap dan boleh mensintesis peta kedalaman dalam beberapa langkah inferens. Mari kita baca karya ini bersama-sama ~ 1. Tajuk maklumat kertas: DepthFM: FastMonocularDepthEstimationwithFlowMatching Pengarang: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas secara rasmi memasuki era robot elektrik! Semalam, Atlas hidraulik hanya "menangis" menarik diri daripada peringkat sejarah Hari ini, Boston Dynamics mengumumkan bahawa Atlas elektrik sedang berfungsi. Nampaknya dalam bidang robot humanoid komersial, Boston Dynamics berazam untuk bersaing dengan Tesla. Selepas video baharu itu dikeluarkan, ia telah pun ditonton oleh lebih sejuta orang dalam masa sepuluh jam sahaja. Orang lama pergi dan peranan baru muncul. Ini adalah keperluan sejarah. Tidak dinafikan bahawa tahun ini adalah tahun letupan robot humanoid. Netizen mengulas: Kemajuan robot telah menjadikan majlis pembukaan tahun ini kelihatan seperti manusia, dan tahap kebebasan adalah jauh lebih besar daripada manusia Tetapi adakah ini benar-benar bukan filem seram? Pada permulaan video, Atlas berbaring dengan tenang di atas tanah, seolah-olah terlentang. Apa yang berikut adalah rahang-jatuh
 Daya hidup kecerdasan super membangkitkan! Tetapi dengan kedatangan AI yang mengemas kini sendiri, ibu tidak perlu lagi bimbang tentang kesesakan data
Apr 29, 2024 pm 06:55 PM
Daya hidup kecerdasan super membangkitkan! Tetapi dengan kedatangan AI yang mengemas kini sendiri, ibu tidak perlu lagi bimbang tentang kesesakan data
Apr 29, 2024 pm 06:55 PM
Saya menangis hingga mati. Dunia sedang membina model besar. Data di Internet tidak mencukupi. Model latihan kelihatan seperti "The Hunger Games", dan penyelidik AI di seluruh dunia bimbang tentang cara memberi makan data ini kepada pemakan yang rakus. Masalah ini amat ketara dalam tugas berbilang modal. Pada masa mereka mengalami kerugian, pasukan pemula dari Jabatan Universiti Renmin China menggunakan model baharu mereka sendiri untuk menjadi yang pertama di China untuk menjadikan "suapan data yang dijana model itu sendiri" menjadi kenyataan. Selain itu, ia merupakan pendekatan serampang dua mata dari segi pemahaman dan sisi penjanaan Kedua-dua pihak boleh menjana data baharu berbilang modal yang berkualiti tinggi dan memberikan maklum balas data kepada model itu sendiri. Apakah model? Awaker 1.0, model berbilang modal besar yang baru sahaja muncul di Forum Zhongguancun. Siapa pasukan itu? Enjin Sophon. Diasaskan oleh Gao Yizhao, pelajar kedoktoran di Sekolah Kecerdasan Buatan Hillhouse Universiti Renmin.
 Versi Kuaishou Sora 'Ke Ling' dibuka untuk ujian: menghasilkan video lebih 120-an, memahami fizik dengan lebih baik dan boleh memodelkan pergerakan kompleks dengan tepat
Jun 11, 2024 am 09:51 AM
Versi Kuaishou Sora 'Ke Ling' dibuka untuk ujian: menghasilkan video lebih 120-an, memahami fizik dengan lebih baik dan boleh memodelkan pergerakan kompleks dengan tepat
Jun 11, 2024 am 09:51 AM
Apa? Adakah Zootopia dibawa menjadi realiti oleh AI domestik? Didedahkan bersama-sama dengan video itu ialah model penjanaan video domestik berskala besar baharu yang dipanggil "Keling". Sora menggunakan laluan teknikal yang serupa dan menggabungkan beberapa inovasi teknologi yang dibangunkan sendiri untuk menghasilkan video yang bukan sahaja mempunyai pergerakan yang besar dan munasabah, tetapi juga mensimulasikan ciri-ciri dunia fizikal dan mempunyai keupayaan gabungan konsep dan imaginasi yang kuat. Mengikut data, Keling menyokong penjanaan video ultra panjang sehingga 2 minit pada 30fps, dengan resolusi sehingga 1080p dan menyokong berbilang nisbah aspek. Satu lagi perkara penting ialah Keling bukanlah demo atau demonstrasi hasil video yang dikeluarkan oleh makmal, tetapi aplikasi peringkat produk yang dilancarkan oleh Kuaishou, pemain terkemuka dalam bidang video pendek. Selain itu, tumpuan utama adalah untuk menjadi pragmatik, bukan untuk menulis cek kosong, dan pergi ke dalam talian sebaik sahaja ia dikeluarkan Model besar Ke Ling telah pun dikeluarkan di Kuaiying.
 Tentera Udara A.S. mempamerkan jet pejuang AI pertamanya dengan profil tinggi! Menteri secara peribadi menjalankan pandu uji tanpa campur tangan semasa keseluruhan proses, dan 100,000 baris kod telah diuji selama 21 kali.
May 07, 2024 pm 05:00 PM
Tentera Udara A.S. mempamerkan jet pejuang AI pertamanya dengan profil tinggi! Menteri secara peribadi menjalankan pandu uji tanpa campur tangan semasa keseluruhan proses, dan 100,000 baris kod telah diuji selama 21 kali.
May 07, 2024 pm 05:00 PM
Baru-baru ini, bulatan tentera telah terharu dengan berita: jet pejuang tentera AS kini boleh melengkapkan pertempuran udara automatik sepenuhnya menggunakan AI. Ya, baru-baru ini, jet pejuang AI tentera AS telah didedahkan buat pertama kali, mendedahkan misterinya. Nama penuh pesawat pejuang ini ialah Variable Stability Simulator Test Aircraft (VISTA). Ia diterbangkan sendiri oleh Setiausaha Tentera Udara AS untuk mensimulasikan pertempuran udara satu lawan satu. Pada 2 Mei, Setiausaha Tentera Udara A.S. Frank Kendall berlepas menggunakan X-62AVISTA di Pangkalan Tentera Udara Edwards Ambil perhatian bahawa semasa penerbangan selama satu jam, semua tindakan penerbangan telah diselesaikan secara autonomi oleh AI! Kendall berkata - "Sejak beberapa dekad yang lalu, kami telah memikirkan tentang potensi tanpa had pertempuran udara-ke-udara autonomi, tetapi ia sentiasa kelihatan di luar jangkauan." Namun kini,
 Dengan hanya $250, pengarah teknikal Hugging Face mengajar anda cara memperhalusi Llama 3
May 06, 2024 pm 03:52 PM
Dengan hanya $250, pengarah teknikal Hugging Face mengajar anda cara memperhalusi Llama 3
May 06, 2024 pm 03:52 PM
Model bahasa besar sumber terbuka yang biasa seperti Llama3 yang dilancarkan oleh model Meta, Mistral dan Mixtral yang dilancarkan oleh MistralAI, dan Jamba yang dilancarkan oleh AI21 Lab telah menjadi pesaing OpenAI. Dalam kebanyakan kes, pengguna perlu memperhalusi model sumber terbuka ini berdasarkan data mereka sendiri untuk melancarkan potensi model sepenuhnya. Tidak sukar untuk memperhalusi model bahasa besar (seperti Mistral) berbanding model kecil menggunakan Q-Learning pada GPU tunggal, tetapi penalaan halus yang cekap bagi model besar seperti Llama370b atau Mixtral kekal sebagai cabaran sehingga kini . Oleh itu, Philipp Sch, pengarah teknikal HuggingFace
 Melebihi DPO secara menyeluruh: Pasukan Chen Danqi mencadangkan pengoptimuman pilihan mudah SimPO, dan turut memperhalusi model sumber terbuka 8B terkuat
Jun 01, 2024 pm 04:41 PM
Melebihi DPO secara menyeluruh: Pasukan Chen Danqi mencadangkan pengoptimuman pilihan mudah SimPO, dan turut memperhalusi model sumber terbuka 8B terkuat
Jun 01, 2024 pm 04:41 PM
Untuk menyelaraskan model bahasa besar (LLM) dengan nilai dan niat manusia, adalah penting untuk mempelajari maklum balas manusia untuk memastikan bahawa ia berguna, jujur dan tidak berbahaya. Dari segi penjajaran LLM, kaedah yang berkesan ialah pembelajaran pengukuhan berdasarkan maklum balas manusia (RLHF). Walaupun keputusan kaedah RLHF adalah cemerlang, terdapat beberapa cabaran pengoptimuman yang terlibat. Ini melibatkan latihan model ganjaran dan kemudian mengoptimumkan model dasar untuk memaksimumkan ganjaran tersebut. Baru-baru ini, beberapa penyelidik telah meneroka algoritma luar talian yang lebih mudah, salah satunya ialah pengoptimuman keutamaan langsung (DPO). DPO mempelajari model dasar secara langsung berdasarkan data keutamaan dengan meparameterkan fungsi ganjaran dalam RLHF, sekali gus menghapuskan keperluan untuk model ganjaran yang jelas. Kaedah ini mudah dan stabil
 Model ini akan berkembang selepas bergabung, dan secara langsung memenangi SOTA! Pencapaian keusahawanan baru pengarang Transformer adalah popular
Mar 26, 2024 am 11:30 AM
Model ini akan berkembang selepas bergabung, dan secara langsung memenangi SOTA! Pencapaian keusahawanan baru pengarang Transformer adalah popular
Mar 26, 2024 am 11:30 AM
Gunakan model siap pakai pada Huggingface untuk "menjimatkan" - bolehkah anda menggabungkannya terus untuk mencipta model berkuasa baharu? ! Syarikat model Jepun yang besar sakana.ai sangat kreatif (ia adalah syarikat yang diasaskan oleh salah satu daripada "8 Transformers") dan menghasilkan cara yang bijak untuk berkembang dan menggabungkan model. Kaedah ini bukan sahaja menjana model asas baharu secara automatik, malah prestasinya adalah apa-apa tetapi: mereka mencapai keputusan terkini pada penanda aras yang berkaitan menggunakan model besar matematik Jepun dengan 7 bilion parameter, melepasi 70 bilion parameter Llama- 2 dan model terdahulu yang lain. Paling penting, mendapatkan model sedemikian tidak memerlukan sebarang latihan kecerunan dan oleh itu memerlukan sumber pengkomputeran yang kurang ketara. Ahli sains NVIDIA JimFan memujinya selepas membacanya
