

Sebagai salah satu daripada tiga elemen kecerdasan buatan, data memainkan peranan penting.
Tetapi pernahkah anda memikirkannya: Bagaimana jika suatu hari nanti, semua data di dunia kehabisan?
Sebenarnya orang yang bertanya soalan ini pasti tiada masalah mental, kerana hari ini - mungkin akan datang tidak lama lagi! ! !
Baru-baru ini, penyelidik Pablo Villalobos dan yang lain menerbitkan artikel bertajuk "Adakah kita akan kehabisan data?" Makalah "Analisis Had Penskalaan Set Data dalam Pembelajaran Mesin" telah diterbitkan di arXiv.
Berdasarkan analisis sebelumnya terhadap aliran saiz set data, mereka meramalkan pertumbuhan saiz set data dalam bidang bahasa dan penglihatan dan menganggarkan aliran pembangunan jumlah stok data tidak berlabel yang tersedia dalam beberapa dekad akan datang.
Penyelidikan mereka menunjukkan bahawa data bahasa berkualiti tinggi akan habis seawal 2026! Kepantasan pembangunan pembelajaran mesin juga akan menjadi perlahan akibatnya. Ia benar-benar tidak optimistik.
Pasukan penyelidik kertas ini terdiri daripada 11 penyelidik dan 3 perunding, dengan ahli daripada semua seluruh dunia, khusus untuk mengecilkan AI Jurang antara pembangunan teknologi dan strategi AI, dan memberikan nasihat kepada pembuat keputusan utama dalam keselamatan AI.

Chinchilla ialah model pengoptimuman pengkomputeran ramalan baharu yang dicadangkan oleh penyelidik di DeepMind.
Malah, semasa percubaan sebelumnya tentang Chinchilla, seorang penyelidik pernah mencadangkan bahawa "data latihan akan menjadi hambatan dalam mengembangkan model bahasa besar tidak lama lagi."
Jadi mereka menganalisis pertumbuhan dalam saiz set data pembelajaran mesin untuk pemprosesan bahasa semula jadi dan penglihatan komputer, dan menggunakan dua kaedah untuk mengekstrapolasi: menggunakan kadar pertumbuhan sejarah, dan untuk masa hadapan Belanjawan pengiraan yang diramalkan dianggarkan untuk mengira saiz set data yang optimum.
Sebelum ini, mereka telah mengumpul data tentang aliran input pembelajaran mesin, termasuk beberapa data latihan, dsb., dan juga dengan menganggarkan jumlah stok data tidak berlabel yang tersedia di Internet dalam beberapa dekad akan datang, untuk menyiasat pertumbuhan penggunaan data.
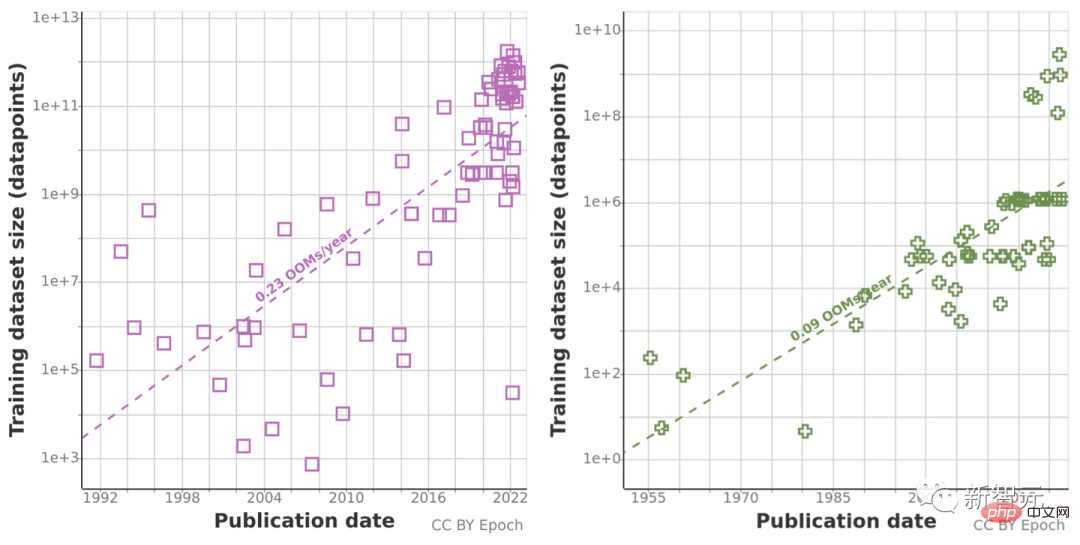
Oleh kerana trend ramalan sejarah mungkin "mengelirukan" oleh pertumbuhan tidak normal dalam volum pengkomputeran sepanjang dekad yang lalu, pasukan penyelidik juga menggunakan undang-undang penskalaan Chinchilla untuk Anggarkan saiz set data dalam beberapa tahun akan datang untuk meningkatkan ketepatan keputusan pengiraan.
Akhirnya, penyelidik menggunakan satu siri model kebarangkalian untuk menganggarkan jumlah inventori bahasa Inggeris dan data imej dalam beberapa tahun akan datang dan membandingkan ramalan saiz set data latihan dan jumlah inventori data Keputusan adalah seperti berikut Seperti yang ditunjukkan dalam rajah.
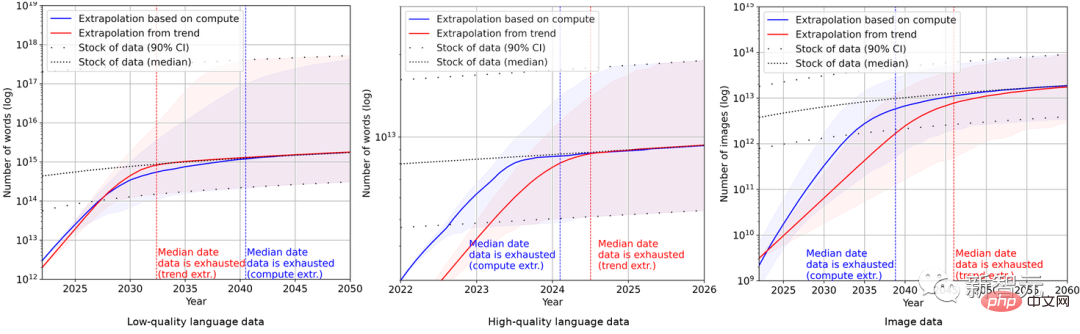
Ini menunjukkan bahawa kadar pertumbuhan set data akan jauh lebih cepat daripada stok data.
Oleh itu, jika trend semasa berterusan, sudah pasti stok data akan habis. Jadual di bawah menunjukkan bilangan median tahun hingga keletihan pada setiap persimpangan pada lengkung ramalan.
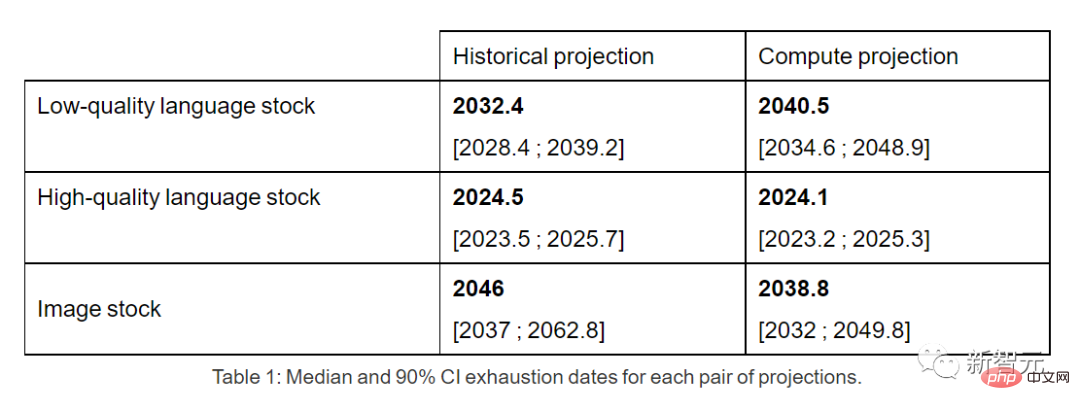
Inventori data bahasa berkualiti tinggi mungkin akan kehabisan paling awal pada tahun 2026.
Sebaliknya, keadaan data bahasa dan data imej berkualiti rendah adalah lebih baik sedikit: yang pertama akan digunakan antara 2030 dan 2050, dan yang terakhir akan digunakan antara 2030 dan 2060. antara.
Pada akhir kertas kerja, pasukan penyelidik membuat kesimpulan: Jika kecekapan data tidak dipertingkatkan dengan ketara atau sumber data baharu tersedia, trend pertumbuhan model pembelajaran mesin yang kini bergantung pada set data besar yang sentiasa berkembang berkemungkinan perlahan.
Namun, di ruangan komen artikel ini, kebanyakan netizen berpendapat bahawa penulis adalah tidak rasional untuk dibimbangkan.
Di Reddit, seorang netizen bernama ktpr berkata:
"Apa salahnya dengan pembelajaran penyeliaan kendiri? Jika tugasan dinyatakan dengan baik, ia malah boleh digabungkan untuk mengembangkan saiz set data "
Seorang netizen bernama lostmsn lebih tidak baik. Terus terang dia berkata:
"Awak tak faham Efficient Zero? Saya rasa penulisnya sudah terputus hubungan dengan zaman." >
Efficient Zero ialah algoritma pembelajaran pengukuhan yang boleh menjadi sampel dengan cekap, yang dicadangkan oleh Dr. Gao Yang dari Universiti Tsinghua. 
Dengan jumlah data yang terhad, Efficient Zero telah menyelesaikan masalah prestasi pembelajaran pengukuhan pada tahap tertentu, dan telah disahkan pada Permainan Atari, penanda aras ujian universal untuk algoritma.
Di blog pasukan pengarang kertas ini, malah mereka sendiri mengaku: 
" Semua kesimpulan kami adalah berdasarkan andaian yang tidak realistik bahawa trend semasa dalam penggunaan dan pengeluaran data pembelajaran mesin akan berterusan tanpa peningkatan ketara dalam kecekapan data."
"Model yang lebih dipercayai harus mengambil kira mengambil kira peningkatan kecekapan data pembelajaran mesin, penggunaan data sintetik dan faktor algoritmik dan ekonomi yang lain."
"Jadi dari segi praktikal, analisis ini mempunyai had yang serius daripada model itu sangat tinggi."
"Walau bagaimanapun, secara keseluruhan, kami masih percaya bahawa disebabkan kekurangan data latihan, model pembelajaran mesin tidak akan dibangunkan sepenuhnya menjelang 2040. Terdapat kira-kira 20% kemungkinan pengembangan akan perlahan dengan ketara."
Atas ialah kandungan terperinci Stok global data bahasa berkualiti tinggi adalah kekurangan dan tidak boleh diabaikan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk mengikat data dalam senarai lungsur
Bagaimana untuk mengikat data dalam senarai lungsur
 Apakah perbezaan antara format panduan dan mbr
Apakah perbezaan antara format panduan dan mbr
 Apakah sebab kegagalan resolusi DNS?
Apakah sebab kegagalan resolusi DNS?
 Bagaimana untuk mengoptimumkan prestasi Tomcat
Bagaimana untuk mengoptimumkan prestasi Tomcat
 Bagaimana untuk melaksanakan skrip shell
Bagaimana untuk melaksanakan skrip shell
 Apakah rangka kerja kecerdasan buatan Python?
Apakah rangka kerja kecerdasan buatan Python?
 Bagaimana untuk mendapatkan panjang tatasusunan dalam js
Bagaimana untuk mendapatkan panjang tatasusunan dalam js
 Apakah fungsi utama redis?
Apakah fungsi utama redis?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



