
 Peranti teknologi
AI
'Menggunakan teknologi Stable Diffusion untuk menghasilkan semula imej, penyelidikan berkaitan telah diterima oleh persidangan CVPR'
Peranti teknologi
AI
'Menggunakan teknologi Stable Diffusion untuk menghasilkan semula imej, penyelidikan berkaitan telah diterima oleh persidangan CVPR'
'Menggunakan teknologi Stable Diffusion untuk menghasilkan semula imej, penyelidikan berkaitan telah diterima oleh persidangan CVPR'

Bagaimana jika kecerdasan buatan dapat membaca imaginasi anda dan mengubah imej dalam kepala anda menjadi realiti?

Namun ini kedengaran agak cyberpunk. Tetapi kertas kerja yang diterbitkan baru-baru ini telah menyebabkan kekecohan dalam kalangan AI.
Kertas kerja ini mendapati bahawa mereka menggunakan Stable Diffusion yang sangat popular baru-baru ini untuk membina semula aktiviti otak resolusi tinggi Kecekapan tinggi, imej berketepatan tinggi. Penulis menulis bahawa tidak seperti kajian terdahulu, mereka tidak perlu melatih atau memperhalusi model kecerdasan buatan untuk mencipta imej ini.

- Alamat kertas: https://www .biorxiv.org/content/10.1101/2022.11.18.517004v2.full.pdf
- Alamat halaman web: https://sites.google.com/view / stablediffusion-with-brain/
Bagaimana mereka melakukannya?
Dalam kajian ini, penulis menggunakan Stable Diffusion untuk membina semula imej aktiviti otak manusia yang diperoleh melalui pengimejan resonans magnetik berfungsi (fMRI). Penulis juga menyatakan bahawa ia juga berguna untuk memahami mekanisme model resapan terpendam dengan mengkaji pelbagai komponen fungsi berkaitan otak (seperti vektor terpendam imej Z, dsb.).
Kertas kerja ini juga telah diterima oleh CVPR 2023.
Sumbangan utama kajian ini termasuk:
- Menunjukkan bahawa rangka kerja ringkasnya boleh menjana data daripada aktiviti otak dengan kesetiaan semantik yang tinggi Bina semula imej resolusi tinggi (512×512) dalam sederhana tanpa perlu melatih atau memperhalusi model generatif dalam yang kompleks, seperti yang ditunjukkan dalam rajah di bawah; kawasan otak yang berbeza, kajian ini secara kuantitatif menerangkan setiap komponen LDM dari perspektif neurosains; maklumat sambil mengekalkan rupa imej asal.
- Tinjauan Metodologi
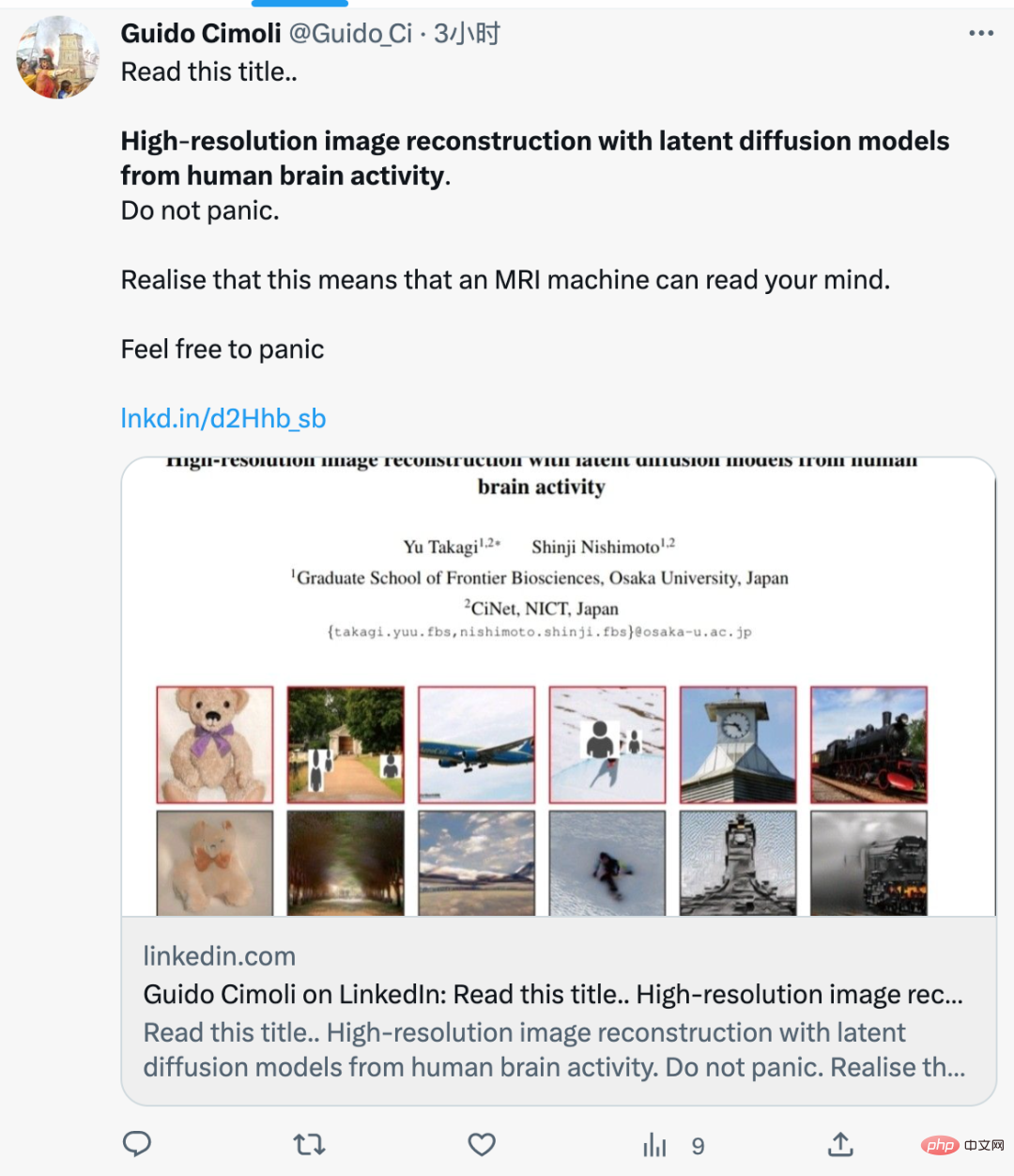
- Metodologi keseluruhan kajian ini ditunjukkan dalam Rajah 2 di bawah. Rajah 2 (atas) ialah gambarajah skematik LDM yang digunakan dalam kajian ini, di mana ε mewakili pengekod imej, D mewakili penyahkod imej, dan τ mewakili pengekod teks (CLIP).
Rajah 2 (bawah) ialah gambarajah skematik analisis pengekodan kajian ini. Kami membina model pengekodan untuk meramal isyarat fMRI daripada komponen LDM yang berbeza, termasuk z, c dan z_c.
Saya tidak akan memperkenalkan terlalu banyak tentang Stable Diffusion di sini, saya percaya ramai yang sudah biasa dengannya.
Keputusan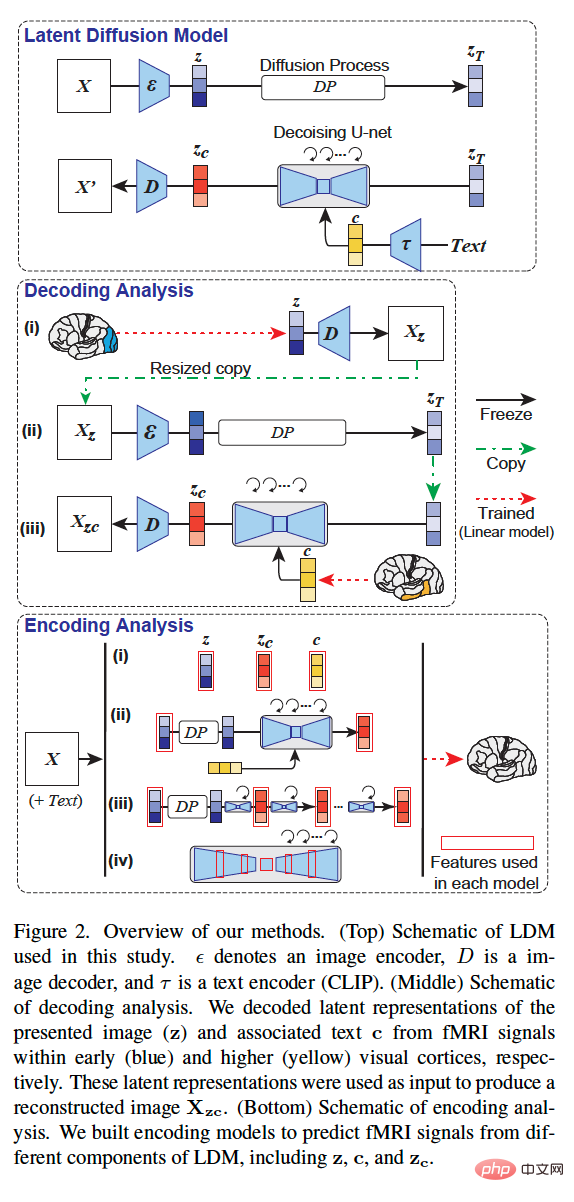
Menyahkod
Rajah 3 di bawah menunjukkan hasil pembinaan semula visual bagi subjek (subj01). Kami menghasilkan lima imej untuk setiap imej ujian dan memilih imej dengan PSM tertinggi. Di satu pihak, imej yang dibina semula hanya menggunakan z adalah konsisten secara visual dengan imej asal tetapi gagal menangkap kandungan semantiknya. Sebaliknya, imej yang dibina semula dengan hanya c menghasilkan imej dengan kesetiaan semantik yang tinggi tetapi tidak konsisten secara visual. Akhir sekali, menggunakan imej z_c yang dibina semula boleh menghasilkan imej resolusi tinggi dengan kesetiaan semantik yang tinggi. 
Rajah 4 menunjukkan imej yang dibina semula bagi imej yang sama oleh semua penguji (semua imej dijana dengan z_c) . Secara keseluruhannya, kualiti pembinaan semula merentas penguji adalah stabil dan tepat.

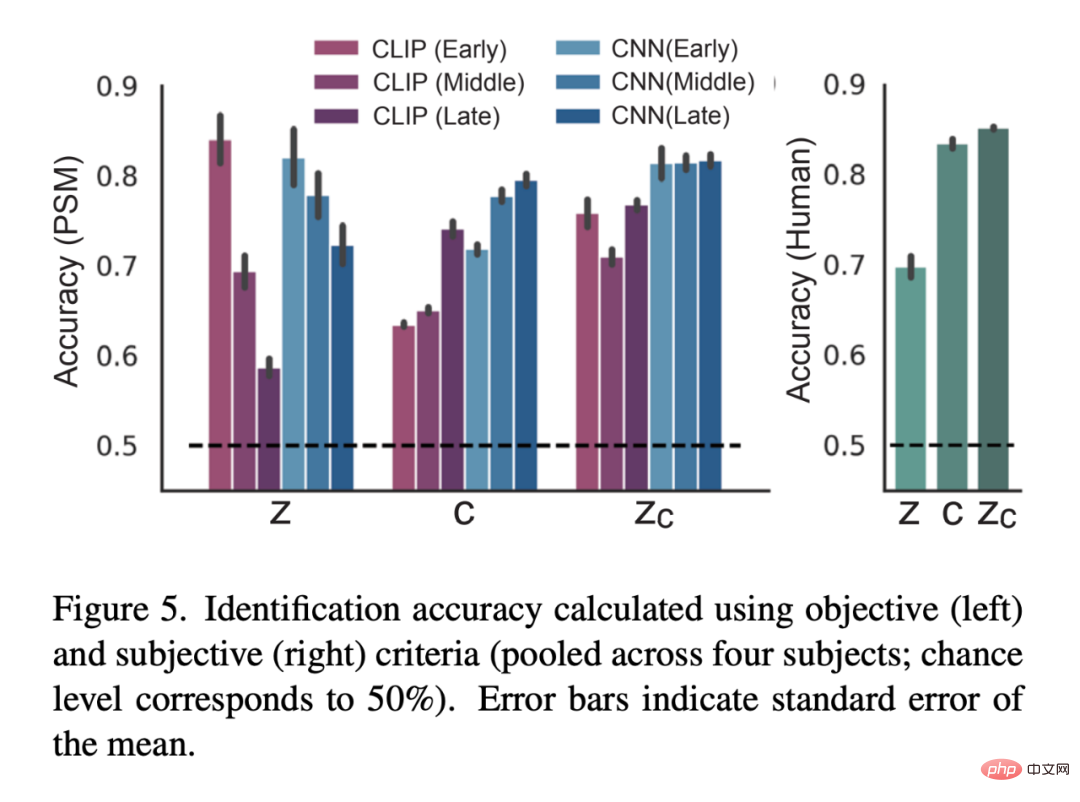
Rajah 5 ialah hasil penilaian kuantitatif:
Model pengekodan
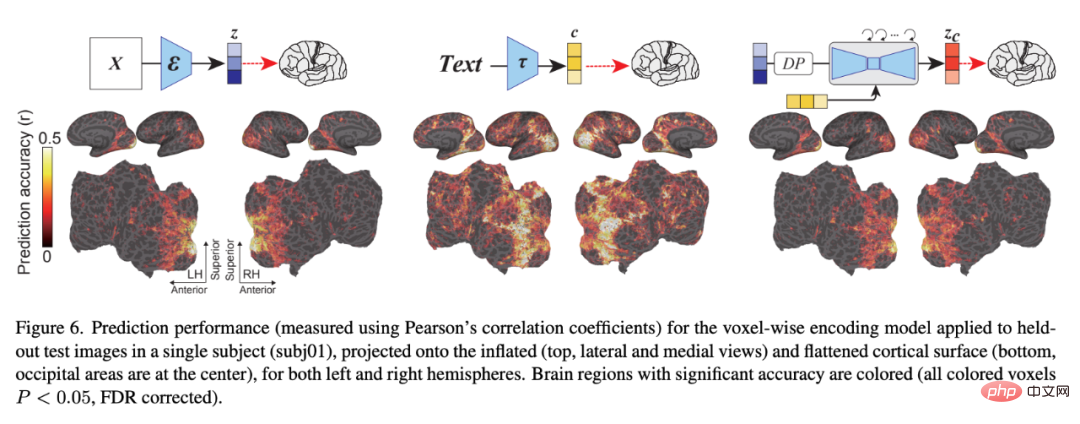
Rajah 6 menunjukkan pasangan model pengekodan yang berkaitan dengan LDM Ketepatan ramalan bagi tiga imej terpendam: z, imej terpendam bagi imej asal c, imej terpendam anotasi teks imej dan z_c, perwakilan imej terpendam yang bising selepas proses resapan belakang perhatian silang dengan c.
Rajah 7 menunjukkan bahawa z meramalkan aktiviti voxel merentas korteks lebih baik daripada z_c apabila sejumlah kecil hingar ditambah. Menariknya, z_c meramalkan aktiviti voxel dalam korteks visual tinggi lebih baik daripada z apabila meningkatkan tahap hingar, menunjukkan bahawa kandungan semantik imej ditekankan secara beransur-ansur.

Bagaimanakah gambaran asas bunyi tambahan berubah semasa penyahnosan berulang? Rajah 8 menunjukkan bahawa pada peringkat awal proses denoising, isyarat z mendominasi ramalan isyarat fMRI. Pada peringkat pertengahan proses denoising, z_c meramalkan aktiviti dalam korteks visual tinggi jauh lebih baik daripada z, menunjukkan bahawa kebanyakan kandungan semantik muncul pada peringkat ini. Hasilnya menunjukkan cara LDM menapis dan menjana imej daripada hingar.
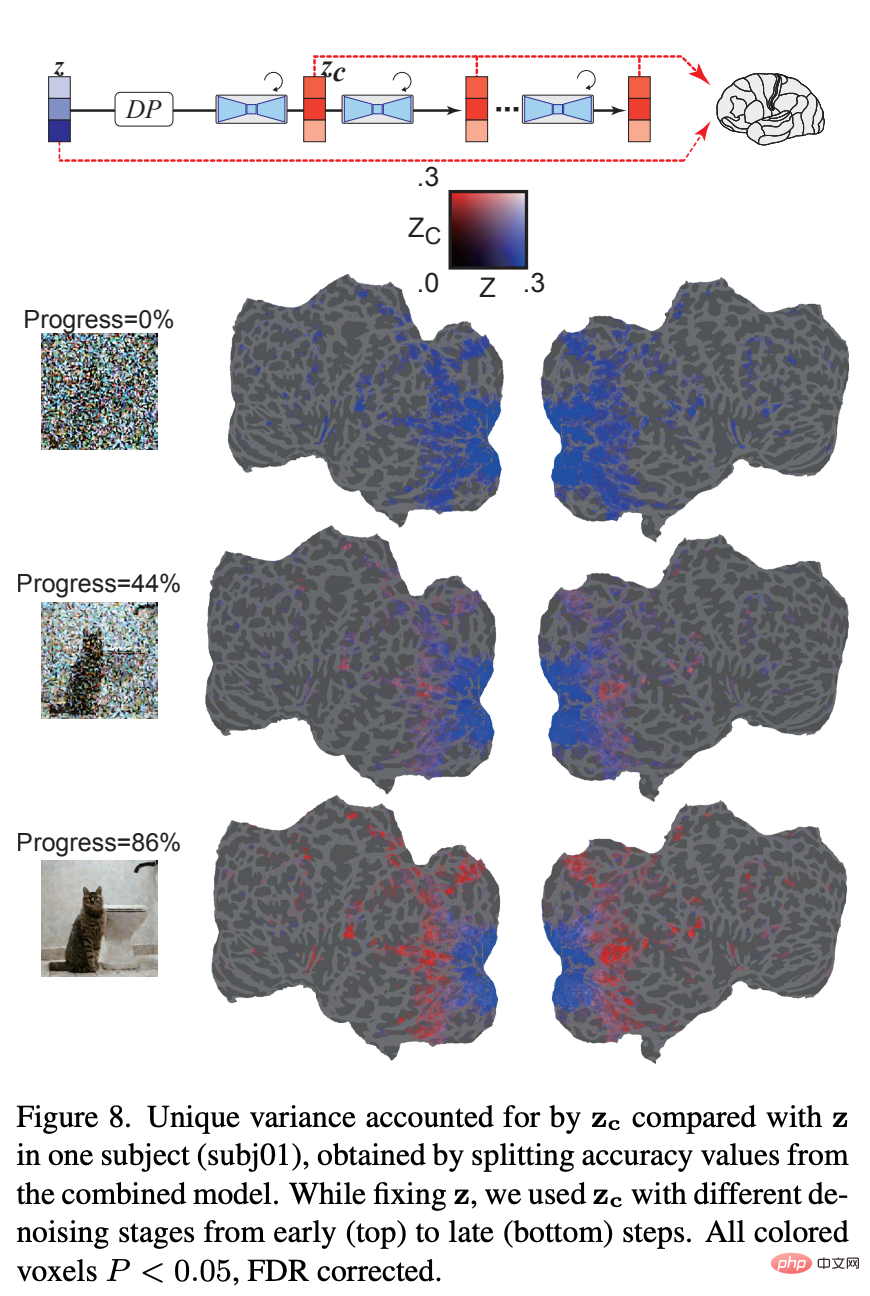
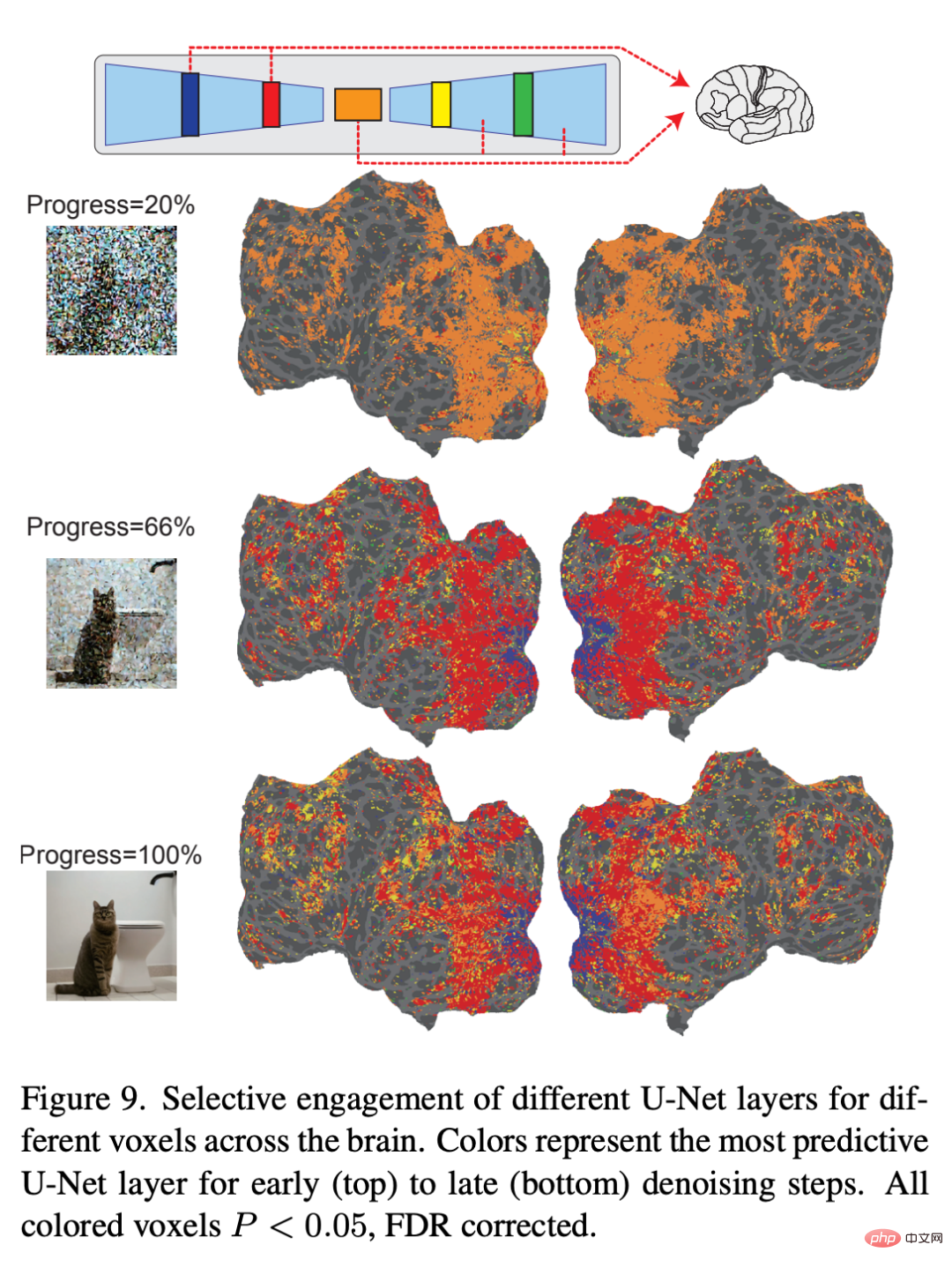
Akhir sekali, penyelidik meneroka maklumat yang diproses oleh setiap lapisan U-Net. Rajah 9 menunjukkan keputusan langkah yang berbeza bagi proses penyahnosan (awal, pertengahan, lewat) dan model pengekodan lapisan berbeza U-Net. Pada peringkat awal proses denoising, lapisan bottleneck U-Net (oren) menghasilkan prestasi ramalan tertinggi di seluruh korteks. Walau bagaimanapun, apabila denoising berterusan, lapisan awal U-Net (biru) meramalkan aktiviti dalam korteks visual awal, manakala lapisan kesesakan beralih kepada kuasa ramalan yang unggul untuk korteks visual yang lebih tinggi.
Untuk butiran penyelidikan lanjut, sila lihat kertas asal.
Atas ialah kandungan terperinci 'Menggunakan teknologi Stable Diffusion untuk menghasilkan semula imej, penyelidikan berkaitan telah diterima oleh persidangan CVPR'. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Bagaimana untuk Muat Turun Imej Kertas Dinding Spotlight Windows pada PC
Aug 23, 2023 pm 02:06 PM
Bagaimana untuk Muat Turun Imej Kertas Dinding Spotlight Windows pada PC
Aug 23, 2023 pm 02:06 PM
Windows tidak pernah mengabaikan estetika. Daripada bidang hijau bucolic XP kepada reka bentuk berputar biru Windows 11, kertas dinding desktop lalai telah menjadi sumber kegembiraan pengguna selama bertahun-tahun. Dengan Windows Spotlight, anda kini mempunyai akses terus kepada imej yang cantik dan mengagumkan untuk skrin kunci dan kertas dinding desktop anda setiap hari. Malangnya, imej ini tidak melepak. Jika anda telah jatuh cinta dengan salah satu imej sorotan Windows, maka anda pasti ingin tahu cara memuat turunnya supaya anda boleh mengekalkannya sebagai latar belakang anda buat seketika. Ini semua yang anda perlu tahu. Apakah WindowsSpotlight? Sorotan Tetingkap ialah pengemas kini kertas dinding automatik yang tersedia daripada Pemperibadian > dalam apl Tetapan
 Menyelam mendalam ke dalam model, data dan rangka kerja: tinjauan menyeluruh 54 halaman model bahasa besar yang cekap
Jan 14, 2024 pm 07:48 PM
Menyelam mendalam ke dalam model, data dan rangka kerja: tinjauan menyeluruh 54 halaman model bahasa besar yang cekap
Jan 14, 2024 pm 07:48 PM
Model bahasa berskala besar (LLM) telah menunjukkan keupayaan yang menarik dalam banyak tugas penting, termasuk pemahaman bahasa semula jadi, penjanaan bahasa dan penaakulan yang kompleks, dan telah memberi kesan yang mendalam kepada masyarakat. Walau bagaimanapun, keupayaan cemerlang ini memerlukan sumber latihan yang ketara (ditunjukkan di sebelah kiri) dan masa inferens yang panjang (ditunjukkan di sebelah kanan). Oleh itu, penyelidik perlu membangunkan cara teknikal yang berkesan untuk menyelesaikan masalah kecekapan mereka. Di samping itu, seperti yang dapat dilihat dari sebelah kanan rajah, beberapa LLM (Model Bahasa) yang cekap seperti Mistral-7B telah berjaya digunakan dalam reka bentuk dan penggunaan LLM. LLM yang cekap ini boleh mengurangkan memori inferens dengan ketara sambil mengekalkan ketepatan yang serupa dengan LLaMA1-33B
 Bagaimana untuk menggunakan teknologi segmentasi semantik imej dalam Python?
Jun 06, 2023 am 08:03 AM
Bagaimana untuk menggunakan teknologi segmentasi semantik imej dalam Python?
Jun 06, 2023 am 08:03 AM
Dengan pembangunan berterusan teknologi kecerdasan buatan, teknologi segmentasi semantik imej telah menjadi hala tuju penyelidikan yang popular dalam bidang analisis imej. Dalam segmentasi semantik imej, kami membahagikan kawasan yang berbeza dalam imej dan mengelaskan setiap kawasan untuk mencapai pemahaman yang menyeluruh tentang imej. Python ialah bahasa pengaturcaraan yang terkenal dengan keupayaan analisis data dan visualisasi datanya yang hebat menjadikannya pilihan pertama dalam bidang penyelidikan teknologi kecerdasan buatan. Artikel ini akan memperkenalkan cara menggunakan teknologi segmentasi semantik imej dalam Python. 1. Pengetahuan prasyarat semakin mendalam
 Menghancurkan H100, GPU generasi seterusnya Nvidia didedahkan! Reka bentuk modul berbilang cip 3nm pertama, diperkenalkan pada 2024
Sep 30, 2023 pm 12:49 PM
Menghancurkan H100, GPU generasi seterusnya Nvidia didedahkan! Reka bentuk modul berbilang cip 3nm pertama, diperkenalkan pada 2024
Sep 30, 2023 pm 12:49 PM
Proses 3nm, prestasi melepasi H100! Baru-baru ini, media asing DigiTimes mengumumkan bahawa Nvidia sedang membangunkan GPU generasi akan datang, B100, dengan nama kod "Blackwell" Dikatakan bahawa sebagai produk untuk aplikasi kecerdasan buatan (AI) dan pengkomputeran berprestasi tinggi (HPC). , B100 akan menggunakan proses proses 3nm TSMC, serta reka bentuk modul berbilang cip (MCM) yang lebih kompleks, dan akan muncul pada suku keempat 2024. Bagi Nvidia, yang memonopoli lebih daripada 80% pasaran GPU kecerdasan buatan, ia boleh menggunakan B100 untuk menyerang semasa seterika panas dan seterusnya menyerang pencabar seperti AMD dan Intel dalam gelombang penggunaan AI ini. Menurut anggaran NVIDIA, menjelang 2027, nilai output medan ini dijangka mencapai lebih kurang
 Semakan paling komprehensif tentang model besar multimodal ada di sini! 7 penyelidik Microsoft bekerjasama bersungguh-sungguh, 5 tema utama, 119 halaman dokumen
Sep 25, 2023 pm 04:49 PM
Semakan paling komprehensif tentang model besar multimodal ada di sini! 7 penyelidik Microsoft bekerjasama bersungguh-sungguh, 5 tema utama, 119 halaman dokumen
Sep 25, 2023 pm 04:49 PM
Kajian yang paling komprehensif tentang model besar berbilang mod ada di sini! Ditulis oleh 7 penyelidik Cina di Microsoft, ia mempunyai 119 halaman - ia bermula daripada dua jenis arahan penyelidikan model besar berbilang modal yang telah selesai dan masih berada di barisan hadapan, dan meringkaskan secara komprehensif lima topik penyelidikan khusus: pemahaman visual dan penjanaan visual Ejen berbilang modal model besar berbilang modal yang disokong oleh model visual bersatu LLM memfokuskan pada fenomena: model asas berbilang modal telah beralih daripada khusus kepada universal. Ps. Inilah sebabnya penulis melukis secara langsung imej Doraemon pada permulaan kertas. Siapa yang patut membaca ulasan (laporan) ini? Dalam kata-kata asal Microsoft: Selagi anda berminat untuk mempelajari pengetahuan asas dan kemajuan terkini model asas pelbagai mod, sama ada anda seorang penyelidik profesional atau pelajar, kandungan ini sangat sesuai untuk anda berkumpul.
 iOS 17: Cara menggunakan pemangkasan satu klik dalam foto
Sep 20, 2023 pm 08:45 PM
iOS 17: Cara menggunakan pemangkasan satu klik dalam foto
Sep 20, 2023 pm 08:45 PM
Dengan apl iOS 17 Photos, Apple memudahkan untuk memangkas foto mengikut spesifikasi anda. Baca terus untuk mengetahui caranya. Sebelum ini dalam iOS 16, memangkas imej dalam apl Foto melibatkan beberapa langkah: Ketik antara muka pengeditan, pilih alat pangkas dan kemudian laraskan pemangkasan menggunakan gerak isyarat picit untuk zum atau seret penjuru alat pangkas. Dalam iOS 17, Apple bersyukur telah memudahkan proses ini supaya apabila anda mengezum masuk pada mana-mana foto yang dipilih dalam pustaka Foto anda, butang Pangkas baharu muncul secara automatik di penjuru kanan sebelah atas skrin. Mengklik padanya akan memaparkan antara muka pemangkasan penuh dengan tahap zum pilihan anda, jadi anda boleh memangkas ke bahagian imej yang anda suka, memutar imej, menyongsangkan imej atau menggunakan nisbah skrin atau menggunakan penanda
 Bagaimana untuk mengubah saiz kumpulan imej menggunakan PowerToys pada Windows
Aug 23, 2023 pm 07:49 PM
Bagaimana untuk mengubah saiz kumpulan imej menggunakan PowerToys pada Windows
Aug 23, 2023 pm 07:49 PM
Mereka yang perlu bekerja dengan fail imej setiap hari selalunya perlu mengubah saiznya agar sesuai dengan keperluan projek dan pekerjaan mereka. Walau bagaimanapun, jika anda mempunyai terlalu banyak imej untuk diproses, saiz semula imej secara individu boleh mengambil banyak masa dan usaha. Dalam kes ini, alat seperti PowerToys boleh berguna untuk, antara lain, mengubah saiz fail kumpulan menggunakan utiliti pengubah semula imejnya. Begini cara untuk menyediakan tetapan Image Resizer anda dan mulakan saiz semula kumpulan imej dengan PowerToys. Cara Mengubah Saiz Imej Secara Berkelompok dengan PowerToys PowerToys ialah program semua-dalam-satu dengan pelbagai utiliti dan ciri untuk membantu anda mempercepatkan tugas harian anda. Salah satu utilitinya ialah imej
 Penyesuai I2V daripada komuniti SD: tiada konfigurasi diperlukan, pasang dan main, serasi sempurna dengan pemalam video Tusheng
Jan 15, 2024 pm 07:48 PM
Penyesuai I2V daripada komuniti SD: tiada konfigurasi diperlukan, pasang dan main, serasi sempurna dengan pemalam video Tusheng
Jan 15, 2024 pm 07:48 PM
Tugas penjanaan imej-ke-video (I2V) merupakan satu cabaran dalam bidang penglihatan komputer yang bertujuan untuk menukar imej statik kepada video dinamik. Kesukaran tugas ini adalah untuk mengekstrak dan menjana maklumat dinamik dalam dimensi temporal daripada imej tunggal sambil mengekalkan keaslian dan keselarasan visual kandungan imej. Kaedah I2V sedia ada selalunya memerlukan seni bina model yang kompleks dan sejumlah besar data latihan untuk mencapai matlamat ini. Baru-baru ini, hasil penyelidikan baharu "I2V-Adapter: AGeneralImage-to-VideoAdapter for VideoDiffusionModels" yang diketuai oleh Kuaishou telah dikeluarkan. Kajian ini memperkenalkan kaedah penukaran imej-ke-video yang inovatif dan mencadangkan modul penyesuai ringan, i.e.
