

Awal bulan ini, Meta mengeluarkan model AI “Segmen Anything” - Model Segmen Anything (SAM). SAM dianggap sebagai model asas universal untuk pembahagian imej Ia mempelajari konsep umum tentang objek dan boleh menjana topeng untuk sebarang objek dalam mana-mana imej atau video, termasuk objek dan jenis imej yang belum ditemui semasa proses latihan. Keupayaan "penghijrahan sampel sifar" ini sangat mengagumkan, malah ada yang mengatakan bahawa medan CV telah membawa kepada "detik GPT-3."
Baru-baru ini, makalah baharu "Segmen Semuanya Di Mana-mana Sekali Lagi" sekali lagi menarik perhatian. Dalam makalah ini, beberapa penyelidik China dari University of Wisconsin-Madison, Microsoft, dan Universiti Sains dan Teknologi Hong Kong mencadangkan model interaksi berasaskan segera SEEM yang baharu. SEEM boleh membahagikan semua kandungan dalam imej atau video sekali gus dan mengenal pasti kategori objek berdasarkan pelbagai input modal yang diberikan oleh pengguna (termasuk teks, imej, grafiti, dll.). Projek ini telah menjadi sumber terbuka dan alamat percubaan disediakan untuk semua orang mengalaminya.

Pautan kertas: https://arxiv.org/pdf/2304.06718.pdf
Pautan projek: https://github.com/UX-Decoder/Segment-Everything-Everywhere-All-At-Once
Alamat percubaan: https://huggingface.co/spaces/xdecoder/SEEM
Kajian ini mengesahkan keberkesanan SEEM melalui eksperimen komprehensif Keberkesanan pada pelbagai tugasan segmentasi. Walaupun SEEM tidak mempunyai keupayaan untuk memahami niat pengguna, ia menunjukkan keupayaan generalisasi yang kukuh kerana ia belajar menulis pelbagai jenis gesaan dalam ruang perwakilan bersatu. Tambahan pula, SEEM boleh mengendalikan berbilang pusingan interaksi dengan cekap melalui penyahkod segera yang ringan.
Mari kita lihat kesan segmentasi dahulu:
Dalam Transformers Segmen "Optimus Prime" dalam foto kumpulan:

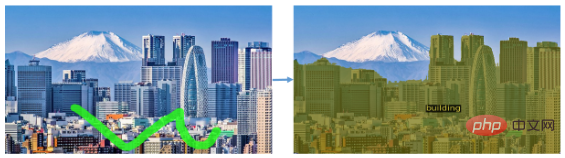
Ia juga boleh membahagikan jenis objek, seperti membahagikannya dalam gambar landskap Semua bangunan:
SEEM juga boleh membahagikan objek bergerak dengan mudah dalam video:

Kesan segmentasi ini boleh dikatakan sangat lancar. Mari kita lihat pendekatan yang dicadangkan dalam kajian ini.
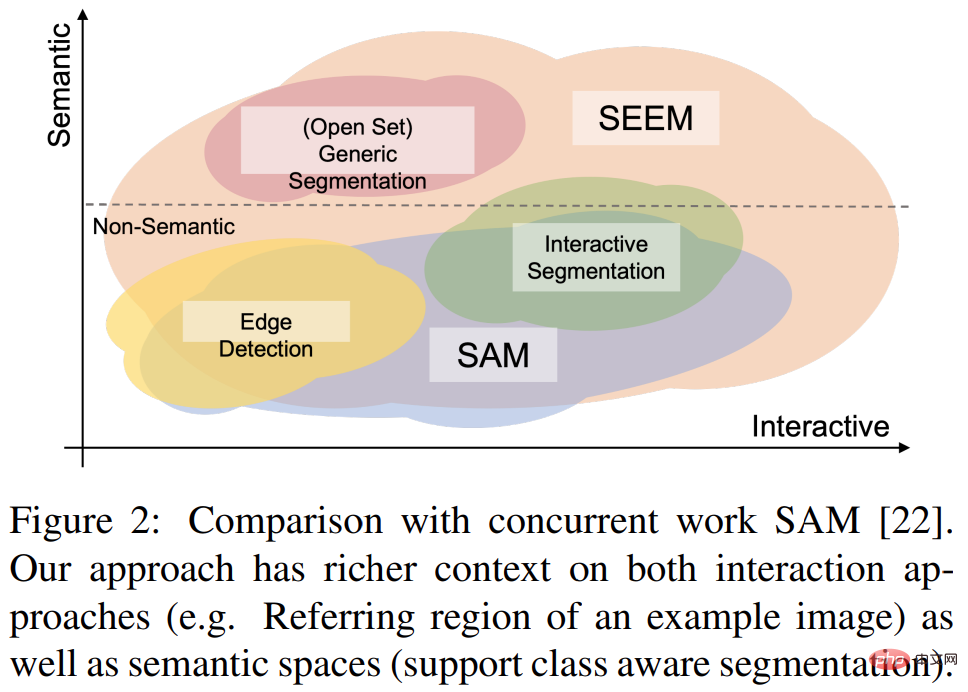
Kajian ini bertujuan untuk mencadangkan antara muka umum untuk pembahagian imej dengan bantuan gesaan berbilang modal. Untuk mencapai matlamat ini, mereka mencadangkan penyelesaian baharu yang mengandungi 4 atribut, termasuk fleksibiliti, komposisi, interaktiviti dan kesedaran semantik, termasuk
1) Kepelbagaian Penyelidikan ini mencadangkan untuk menggabungkan elemen heterogen. seperti titik, topeng, teks, kotak pengesanan (kotak) dan juga kawasan rujukan (rantau yang dirujuk) imej lain , dikodkan menjadi gesaan dalam ruang semantik visual bersama yang sama.
2) Kekomposisian membolehkan penulisan pertanyaan dengan cepat untuk penaakulan dengan mempelajari ruang semantik visual bersama gesaan visual dan teks. SEEM boleh mengendalikan sebarang kombinasi gesaan input.
3) Interaktiviti: Kajian ini memperkenalkan pengekalan maklumat sejarah perbualan dengan menggabungkan gesaan ingatan yang boleh dipelajari dan perhatian silang berpandukan topeng.
4) Kesedaran semantik: Gunakan pengekod teks untuk mengekod pertanyaan teks dan label topeng, dengan itu menyediakan semantik set terbuka untuk semua hasil pembahagian output.

Dari segi seni bina, SEEM mengikuti seni bina penyahkod-pengekod Transformer yang ringkas dan menambah peranti pengekodan teks tambahan. Dalam SEEM, proses penyahkodan adalah serupa dengan LLM generatif, tetapi dengan input multimodal dan output multimodal. Semua pertanyaan disalurkan kembali kepada penyahkod sebagai gesaan, dan pengekod imej dan teks digunakan sebagai pengekod segera untuk mengekod semua jenis pertanyaan.
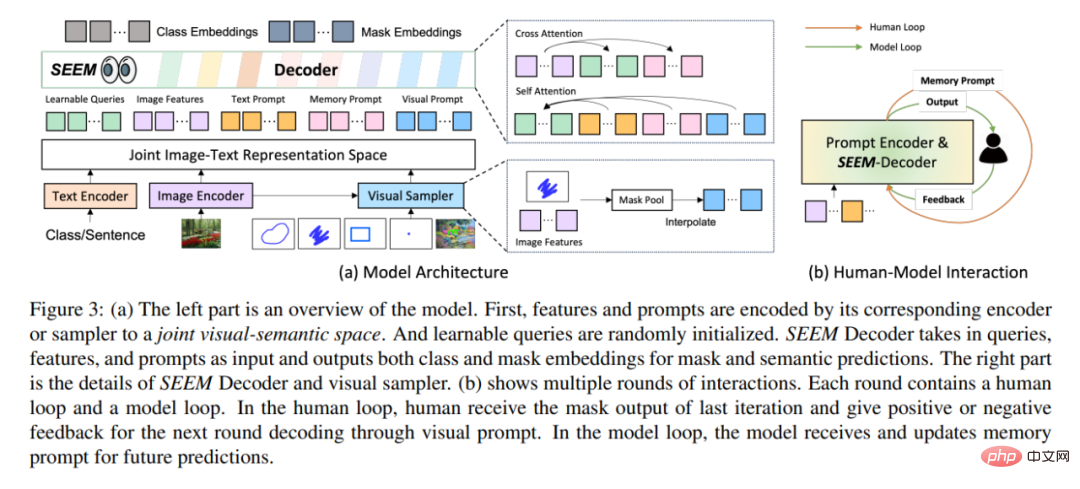
Secara khususnya, kajian ini mengekod semua pertanyaan (seperti mata, kotak dan topeng) sebagai gesaan visual, Juga gunakan pengekod teks untuk menukar pertanyaan teks kepada gesaan teks supaya gesaan visual dan teks kekal sejajar. Lima jenis gesaan yang berbeza semuanya boleh dipetakan ke dalam ruang semantik visual bersama, dan gesaan pengguna yang tidak kelihatan boleh diproses melalui penyesuaian tangkapan sifar. Dengan melatih tugas pembahagian yang berbeza, model ini mempunyai keupayaan untuk mengendalikan pelbagai gesaan. Selain itu, pelbagai jenis gesaan boleh membantu antara satu sama lain dengan perhatian silang. Akhirnya, model SEEM boleh menggunakan pelbagai gesaan untuk mencapai hasil pembahagian yang unggul.
Selain keupayaan generalisasi yang kukuh, SEEM juga sangat cekap dalam operasi. Para penyelidik menggunakan gesaan sebagai input kepada penyahkod, jadi SEEM hanya perlu menjalankan pengekstrak ciri sekali pada permulaan dalam beberapa pusingan interaksi dengan manusia. Pada setiap lelaran, hanya jalankan penyahkod ringan sekali lagi dengan gesaan baharu. Oleh itu, apabila menggunakan model, pengekstrak ciri dengan sejumlah besar parameter dan beban masa jalan yang berat boleh dijalankan pada pelayan, manakala hanya penyahkod yang agak ringan dijalankan pada mesin pengguna untuk mengurangkan masalah kependaman rangkaian dalam berbilang panggilan jauh.
Seperti yang ditunjukkan dalam Rajah 3(b) di atas, dalam berbilang pusingan interaksi, setiap interaksi mengandungi gelung manual dan gelung model. Dalam gelung buatan, manusia menerima output topeng daripada lelaran sebelumnya dan memberikan maklum balas positif atau negatif untuk pusingan seterusnya penyahkodan melalui gesaan visual. Semasa gelung model, model menerima dan mengemas kini gesaan memori untuk ramalan masa hadapan.
Kajian ini secara eksperimen membandingkan model SEEM dengan model segmentasi interaktif SOTA, dan hasilnya ditunjukkan dalam Jadual 1 di bawah.
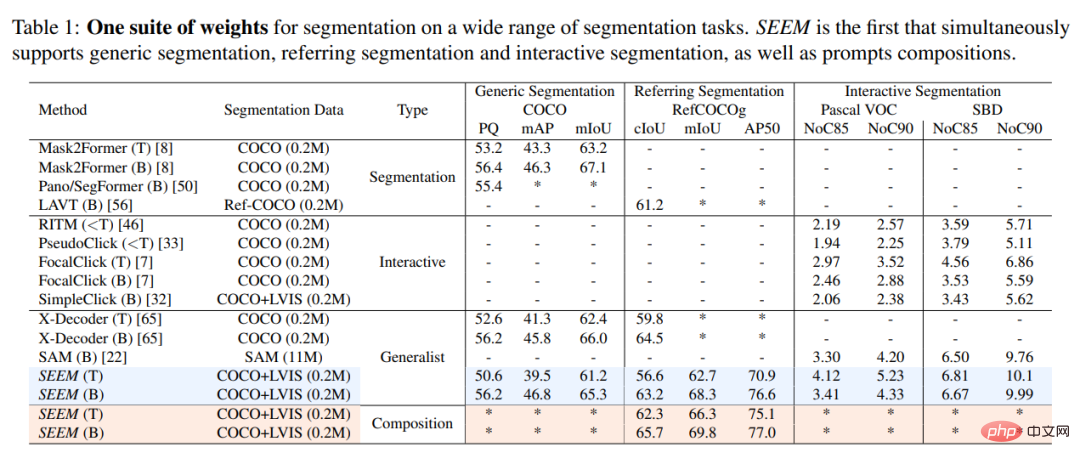
Sebagai model umum, SEEM mencapai prestasi yang setanding dengan model seperti RITM, SimpleClick dan setanding dengan prestasi SAM Sangat dekat, manakala SAM menggunakan 50 kali lebih banyak data bersegmen untuk latihan daripada SEEM.
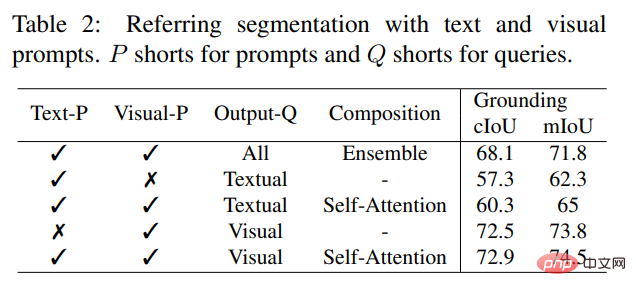
Tidak seperti model interaktif sedia ada, SEEM ialah antara muka universal pertama yang menyokong bukan sahaja tugasan segmentasi klasik tetapi juga pelbagai jenis input pengguna, termasuk teks, titik, grafiti, Bingkai dan imej, memberikan kuasa keupayaan gabungan. Seperti yang ditunjukkan dalam Jadual 2 di bawah, dengan menambahkan gesaan boleh digabungkan, SEEM telah meningkatkan prestasi pembahagian dengan ketara dalam cIoU, mIoU dan penunjuk lain.
Mari kita lihat hasil visualisasi pembahagian imej interaktif. Pengguna hanya perlu melukis mata atau hanya coretan, SEEM boleh memberikan hasil segmentasi yang sangat baik

juga boleh dimasukkan Teks , biarkan SEEM melakukan pembahagian imej

Anda juga boleh memasukkan terus imej rujukan dan menunjukkan kawasan rujukan, membahagikan imej lain dan mencari objek yang konsisten dengan kawasan rujukan:

Projek ini kini tersedia untuk percubaan dalam talian. Pembaca yang berminat harus pergi dan mencubanya.
Atas ialah kandungan terperinci SEEM, model segmentasi universal yang dicipta oleh pasukan China, membawa segmentasi sekali ke tahap yang baharu. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk membersihkan pemacu C komputer apabila ia penuh
Bagaimana untuk membersihkan pemacu C komputer apabila ia penuh
 harga mata wang fil harga masa nyata
harga mata wang fil harga masa nyata
 Bagaimana untuk mempertahankan pelayan awan daripada serangan DDoS
Bagaimana untuk mempertahankan pelayan awan daripada serangan DDoS
 Bagaimana untuk memuat turun Binance
Bagaimana untuk memuat turun Binance
 Bagaimana untuk membeli dan menjual Bitcoin di Huobi.com
Bagaimana untuk membeli dan menjual Bitcoin di Huobi.com
 Bagaimana untuk membuka fail iso
Bagaimana untuk membuka fail iso
 Apakah fungsi rangkaian komputer
Apakah fungsi rangkaian komputer
 bagaimana untuk menyembunyikan alamat ip
bagaimana untuk menyembunyikan alamat ip
 Bagaimana untuk menyelesaikan masalah semasa menghuraikan pakej
Bagaimana untuk menyelesaikan masalah semasa menghuraikan pakej








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



