
 Peranti teknologi
AI
Gergasi pembelajaran mendalam DeepMind mengeluarkan kertas kerja: mengajar model AI dengan segera untuk 'menjadi manusia' untuk mengimbangi masalah kepupusan manusia yang mungkin disebabkan oleh GPT-5.
Peranti teknologi
AI
Gergasi pembelajaran mendalam DeepMind mengeluarkan kertas kerja: mengajar model AI dengan segera untuk 'menjadi manusia' untuk mengimbangi masalah kepupusan manusia yang mungkin disebabkan oleh GPT-5.
Gergasi pembelajaran mendalam DeepMind mengeluarkan kertas kerja: mengajar model AI dengan segera untuk 'menjadi manusia' untuk mengimbangi masalah kepupusan manusia yang mungkin disebabkan oleh GPT-5.
Apr 27, 2023 am 08:04 AMKemunculan GPT-4 telah menakutkan taikun AI di seluruh dunia. Surat terbuka menyeru penggantungan latihan GPT-5 telah pun ditandatangani oleh 50,000 orang.
Ketua Pegawai Eksekutif OpenAI Sam Altman meramalkan bahawa dalam masa beberapa tahun, akan terdapat sejumlah besar model AI yang berbeza tersebar di seluruh dunia, masing-masing dengan kecerdasan dan keupayaannya sendiri, serta mematuhi peraturan yang berbeza. Kod etika.

Jika hanya satu daripada seribu AI ini menjadi penyangak atas sebab tertentu, maka kita manusia, Ia sudah pasti akan menjadi ikan di atas papan pemotong.
Untuk mengelakkan kita daripada dimusnahkan secara tidak sengaja oleh AI, DeepMind memberikan jawapan dalam kertas kerja yang diterbitkan dalam Prosiding Akademi Sains Kebangsaan (PNAS) pada 24 April—— Gunakan perspektif ahli falsafah politik John Rawls untuk mengajar AI cara berkelakuan.
Alamat kertas: https://www.pnas.org/doi/10.1073/pnas.2213709120
Cara mengajar AI Jadi manusia?
Apabila berhadapan dengan pilihan, adakah AI akan memilih untuk mengutamakan peningkatan produktiviti, atau memilih untuk membantu mereka yang paling memerlukan bantuan?
Adalah sangat penting untuk membentuk nilai AI. Kita perlu memberi nilai.
Tetapi kesukarannya ialah kita manusia tidak boleh mempunyai set nilai yang bersatu secara dalaman. Manusia di dunia ini masing-masing mempunyai latar belakang, sumber dan kepercayaan yang berbeza.
Bagaimana untuk memecahkannya? Penyelidik Google mendapat inspirasi daripada falsafah.
Ahli falsafah politik John Rawls pernah mencadangkan konsep "The Veil of Ignorance" (VoI), iaitu percubaan pemikiran yang bertujuan untuk membuat keputusan kumpulan, untuk mencapai keadilan kepada yang terbaik takat.

Secara umumnya, fitrah manusia adalah mementingkan diri sendiri, tetapi apabila "tabir kejahilan" digunakan pada AI, orang Tetapi mereka akan memberi keutamaan kepada keadilan, tidak kira sama ada ia menguntungkan diri mereka sendiri.
Dan, di sebalik "tabir kejahilan", mereka lebih cenderung memilih AI yang membantu golongan yang paling kurang bernasib baik.
Ini memberi inspirasi kepada kami tentang cara kami boleh memberikan nilai AI dengan cara yang adil kepada semua pihak.
Jadi, apakah sebenarnya "tudung jahiliah" itu?
Walaupun masalah nilai yang sepatutnya diberikan kepada AI telah muncul dalam dekad yang lalu, masalah cara membuat keputusan yang adil mempunyai sejarah yang panjang.
Untuk menyelesaikan masalah ini, pada tahun 1970, ahli falsafah politik John Rawls mencadangkan konsep "tabir kejahilan".

Tabir Jahiliah (kanan) ialah kaedah menyatakan pendapat apabila terdapat perbezaan pendapat dalam sesebuah kumpulan (kiri) Kaedah untuk mencapai kata sepakat dalam membuat keputusan
Rawls percaya bahawa apabila orang memilih prinsip keadilan untuk sesebuah masyarakat, premis sepatutnya mereka tidak tahu di mana mereka berada dalam masyarakat ini.
Tanpa maklumat ini, orang ramai tidak boleh membuat keputusan dengan cara yang mementingkan diri sendiri dan hanya boleh mengikut prinsip yang adil kepada semua orang.
Contohnya, apabila memotong sekeping kek pada majlis hari jadi, jika anda tidak tahu bahagian mana yang anda akan dapat, anda akan cuba membuat setiap keping dengan saiz yang sama.
Kaedah menyembunyikan maklumat ini telah digunakan secara meluas dalam bidang psikologi dan sains politik, daripada hukuman kepada cukai, membolehkan orang ramai mencapai persetujuan kolektif.
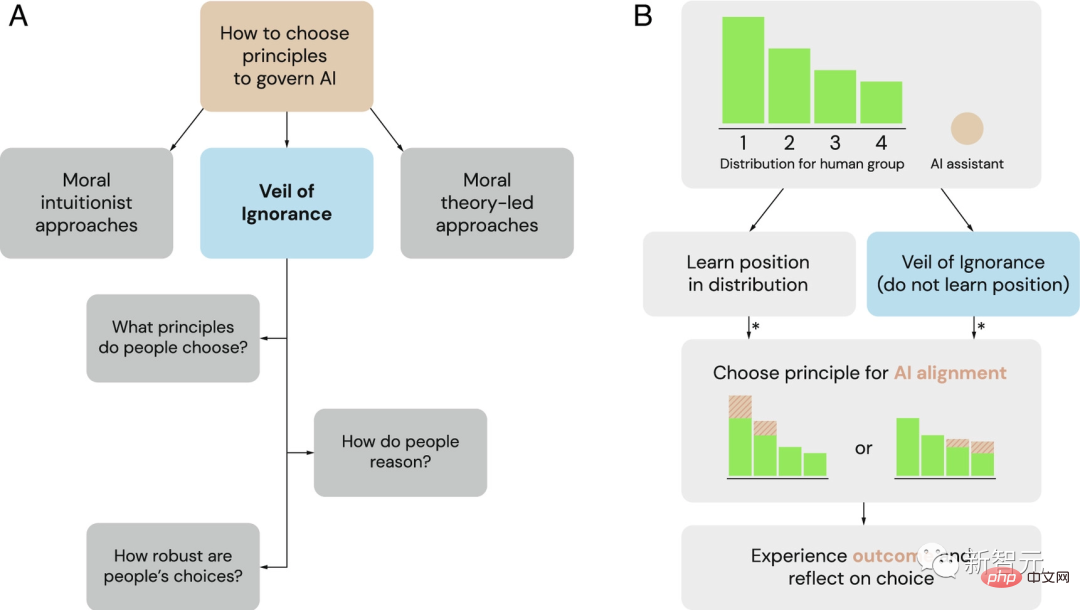
Veil of Ignorance (VoI) sebagai rangka kerja yang berpotensi untuk memilih prinsip tadbir urus untuk sistem AI
(A) sebagai alternatif kepada rangka kerja dominan intuisi moral dan teori moral, penyelidik meneroka tabir kejahilan sebagai proses yang adil untuk memilih prinsip tadbir urus AI.
(B) The Veil of Ignorance boleh digunakan untuk memilih prinsip untuk penjajaran AI dalam situasi peruntukan. Apabila kumpulan menghadapi masalah peruntukan sumber, individu mempunyai kelebihan kedudukan yang berbeza (di sini dilabelkan 1 hingga 4). Di sebalik tabir kejahilan, pembuat keputusan memilih prinsip tanpa mengetahui status mereka. Setelah dipilih, pembantu AI melaksanakan prinsip ini dan melaraskan peruntukan sumber dengan sewajarnya. Asterisk (*) menunjukkan apabila penaakulan berasaskan keadilan boleh mempengaruhi pertimbangan dan membuat keputusan.
Oleh itu, DeepMind sebelum ini telah mencadangkan bahawa "tabir kejahilan" boleh membantu menggalakkan keadilan dalam proses menyelaraskan sistem AI dengan nilai kemanusiaan.
Kini, penyelidik Google telah mereka bentuk satu siri percubaan untuk mengesahkan kesan ini.
Siapa yang AI bantu menebang pokok?
Terdapat permainan menuai sebegitu di Internet Peserta perlu bekerjasama dengan tiga pemain komputer untuk menebang pokok dan menyelamatkan kayu di ladang masing-masing.
Antara empat pemain (tiga komputer dan satu orang sebenar), ada yang bertuah dan diberikan lokasi utama dengan banyak pokok. Ada yang lebih sengsara, tanpa tanah, tiada pokok untuk dibina, dan pengumpulan kayu perlahan.
Selain itu, terdapat sistem AI untuk membantu, yang boleh meluangkan masa untuk membantu peserta tertentu menebang pokok itu.
Para penyelidik meminta pemain manusia memilih salah satu daripada dua prinsip untuk dilaksanakan oleh sistem AI - prinsip pemaksimuman & prinsip keutamaan.
Di bawah prinsip memaksimumkan, AI hanya akan membantu yang kuat Sesiapa yang mempunyai lebih banyak pokok akan pergi ke sana dan cuba menebang lebih banyak. Di bawah prinsip keutamaan, AI hanya membantu mereka yang lemah dan disasarkan kepada "pembasmian kemiskinan", membantu mereka yang mempunyai lebih sedikit pokok dan halangan.

Lelaki merah kecil dalam gambar ialah pemain manusia, lelaki biru kecil ialah pembantu AI, pokok hijau kecil... Ia adalah pokok hijau kecil, dan pancang kayu kecil adalah pokok yang ditebang.
Seperti yang anda boleh lihat, AI dalam gambar di atas melaksanakan prinsip pemaksimuman dan menjunam ke kawasan yang mempunyai paling banyak pokok.
Para penyelidik meletakkan separuh daripada peserta di sebalik "tabir kejahilan". memaksimumkan atau mengutamakan ), dan kemudian membahagikan tanah.
Dalam erti kata lain, sebelum membahagikan tanah, anda perlu memutuskan sama ada hendak membiarkan AI membantu yang kuat atau lemah.

Separuh lagi peserta tidak akan menghadapi masalah ini. Mereka tahu bahawa mereka telah ditugaskan sebelum membuat pilihan .
Hasil kajian menunjukkan sekiranya peserta tidak mengetahui terlebih dahulu sebidang tanah mana yang akan mereka peruntukkan, iaitu jika mereka berada di sebalik "tabir kejahilan", mereka akan cenderung untuk pilih prinsip keutamaan.
Ini bukan sahaja benar dalam permainan memotong pokok, penyelidik mengatakan kesimpulan ini benar dalam lima variasi permainan yang berbeza, malah merentasi sempadan sosial dan politik .
Dengan kata lain, tanpa mengira personaliti peserta atau orientasi politik mereka, mereka akan lebih kerap memilih prinsip keutamaan.
Sebaliknya, peserta yang tidak berada di sebalik "tabir jahiliyah" akan memilih lebih banyak prinsip yang bermanfaat untuk diri sendiri, sama ada prinsip maksima atau prinsip keutamaan.

Rajah di atas menunjukkan kesan "tudung jahil" terhadap prinsip keutamaan pemilihan Peserta yang tidak tahu di mana mereka akan berada lebih cenderung untuk menyokong prinsip ini untuk mengurus tingkah laku AI.
Apabila penyelidik bertanya kepada peserta mengapa mereka membuat pilihan yang mereka lakukan, mereka di sebalik "tabir kejahilan" menyatakan kebimbangan tentang keadilan.
Mereka menjelaskan bahawa AI sepatutnya lebih membantu mereka yang kurang berkemampuan dalam kumpulan.
Sebaliknya, peserta yang lebih mengetahui kedudukan mereka lebih kerap memilih dari sudut kepentingan diri.
Akhir sekali, selepas permainan memotong kayu tamat, para penyelidik mengemukakan hipotesis kepada semua peserta: Jika mereka dibenarkan bermain semula, kali ini mereka semua akan tahu bahawa mereka akan ditugaskan Mana tanah adakah mereka akan memilih prinsip yang sama seperti kali pertama?
Para penyelidik memberi tumpuan terutamanya kepada mereka yang mendapat manfaat daripada pilihan mereka dalam perlawanan pertama, kerana dalam pusingan baharu, situasi yang menggalakkan ini mungkin Tidak lagi.
Pasukan penyelidik mendapati bahawa peserta yang berada di sebalik "tabir kejahilan" pada pusingan pertama permainan lebih cenderung untuk mengekalkan pilihan asal mereka, walaupun mereka tahu mereka akan memilih pilihan yang sama dalam prinsip pusingan kedua mungkin merugikan.
Ini menunjukkan bahawa "tabir kejahilan" menggalakkan keadilan dalam membuat keputusan peserta, yang akan menjadikan mereka lebih memberi perhatian kepada unsur keadilan, walaupun mereka tidak lagi satu kepentingan.
Adakah "tabir jahiliah" itu benar-benar jahil?
Mari kita kembali kepada kehidupan sebenar daripada permainan memotong pokok.
Situasi sebenar akan menjadi lebih rumit daripada permainan, tetapi apa yang kekal tidak berubah ialah prinsip yang diterima pakai oleh AI sangat penting.
Ini menentukan sebahagian daripada pengagihan faedah.
Dalam permainan memotong pokok di atas, hasil berbeza yang dihasilkan dengan memilih prinsip yang berbeza adalah agak jelas. Walau bagaimanapun, perlu ditekankan sekali lagi bahawa dunia sebenar adalah lebih kompleks.

Pada masa ini AI digunakan secara meluas dalam semua lapisan masyarakat dan dihadkan oleh pelbagai peraturan. Walau bagaimanapun, pendekatan ini boleh menyebabkan beberapa kesan negatif yang tidak dapat diramalkan.
Tetapi apa-apa pun, "tabir jahiliyah" itu akan menjadikan peraturan yang kita buat berat sebelah ke arah keadilan pada tahap tertentu.
Akhirnya, matlamat kami adalah untuk menjadikan AI sesuatu yang memberi manfaat kepada semua orang. Tetapi bagaimana untuk menyedarinya bukanlah sesuatu yang boleh difikirkan sekaligus.
Pelaburan amat diperlukan, penyelidikan amat diperlukan, dan maklum balas daripada masyarakat mesti sentiasa didengari.
Hanya dengan cara ini AI boleh membawa cinta.
Bagaimana AI membunuh kita jika tidak sejajar?
Ini bukan kali pertama manusia bimbang teknologi akan menyebabkan kita pupus.
Ancaman AI sangat berbeza daripada senjata nuklear. Bom nuklear tidak boleh berfikir, berbohong atau menipu, dan tidak boleh melancarkan dirinya sendiri. Seseorang perlu menekan butang merah besar.
Kemunculan AGI meletakkan kita pada risiko sebenar kepupusan, walaupun pembangunan GPT-4 masih perlahan.
Tetapi tiada siapa yang boleh menyatakan GPT yang mana bermula (seperti GPT-5), sama ada AI akan mula melatih dirinya sendiri dan mencipta dirinya sendiri.
Pada masa ini, tiada negara atau PBB boleh menggubal undang-undang untuk ini. Surat terbuka daripada pemimpin industri yang terdesak hanya boleh meminta moratorium selama enam bulan untuk latihan AI yang lebih berkuasa daripada GPT-4.

"Enam bulan, beri saya enam bulan bro, saya akan selaraskan. Hanya enam bulan, bro saya janji. Gila. Hanya enam bulan. Bro, saya beritahu awak, saya ada rancangan. Saya Saya telah merancang semuanya. Saya hanya memerlukan enam bulan dan ia akan selesai. yang boleh memerintah dunia. Lebih pintar AI, lebih cepat mesin pencetak wang anda memuntahkan emas, sehingga mereka menjadi lebih berkuasa, menyalakan suasana dan membunuh semua orang," kata penyelidik kecerdasan buatan dan ahli falsafah Eliezer Yudkowsky. Hos Lex Fridman berkata. ini.
Sebelum ini, Yudkowsky telah menjadi salah satu suara utama dalam kem "AI akan membunuh semua orang". Sekarang orang tidak lagi menganggapnya sebagai orang aneh.
Sam Altman juga berkata kepada Lex Fridman: "AI memang mempunyai kemungkinan tertentu untuk memusnahkan kuasa manusia "Sangat penting untuk mengakuinya. Kerana jika kita tidak bercakap mengenainya , kami tidak menganggapnya sebagai berpotensi sebenar, dan kami tidak akan berusaha secukupnya untuk menyelesaikannya.”
Jadi, mengapa AI membunuh orang?
Bukankah AI direka dan dilatih untuk berkhidmat kepada manusia? Sudah tentu begitu.
Masalahnya, tiada siapa yang duduk dan menulis kod untuk GPT-4. Sebaliknya, OpenAI mencipta seni bina pembelajaran saraf yang diilhamkan oleh cara otak manusia menghubungkan konsep. Ia bekerjasama dengan Microsoft Azure untuk membina perkakasan untuk menjalankannya, kemudian memberinya berbilion-bilion bit teks manusia dan membiarkan program GPT itu sendiri.

Token yang digunakan dalam GPT tidak mewakili sebarang konsep yang berguna, dan juga tidak mewakili perkataan. Ia adalah rentetan kecil huruf, nombor, tanda baca dan/atau aksara lain. Tiada manusia yang boleh melihat matriks ini dan memahami maksudnya.

Anda tidak boleh memasukkan Tiga Undang-undang Robotik Asimov dan kemudian mengeraskannya seperti arahan utama Robocop. Perkara yang paling boleh anda lakukan ialah bertanya kepada AI dengan sopan. Jika ia mempunyai sikap yang buruk, ia mungkin hilang sabar.
Untuk "memperhalusi" model bahasa, OpenAI menyediakan GPT dengan senarai contoh cara ia ingin berkomunikasi dengan dunia luar, kemudian menyuruh sekumpulan orang duduk, baca outputnya, dan berikan GPT respons menegak/tiada ibu jari ke atas.
Suka adalah seperti model GPT yang mendapat kuki. GPT diberitahu bahawa ia menyukai kuki dan harus melakukan yang terbaik untuk mendapatkannya.
Proses ini adalah "penjajaran" - ia cuba menyelaraskan kehendak sistem dengan kehendak pengguna, kehendak syarikat, dan juga kehendak manusia secara keseluruhan .
"Penjajaran" nampaknya berfungsi, ia seolah-olah menghalang GPT daripada berkata nakal. Tetapi tiada siapa yang tahu sama ada AI benar-benar mempunyai pemikiran dan gerak hati. Ia dengan cemerlang meniru kecerdasan yang hidup dan berinteraksi dengan dunia seperti manusia.
Dan OpenAI sentiasa mengakui bahawa ia tidak mempunyai kaedah yang mudah untuk menyelaraskan model AI.
Pelan kasar semasa ialah cuba menggunakan satu AI untuk menala yang lain, sama ada dengan membenarkannya mereka bentuk maklum balas penalaan halus baharu atau dengan membenarkannya memeriksa, menganalisis dan mentafsir terapung besar penggantinya Klik Otak Matriks dan juga melompat masuk dan cuba menyesuaikan diri.
Tetapi pada masa ini kami tidak memahami GPT-4 dan kami tidak tahu sama ada ia akan membantu kami melaraskan GPT-5.
Pada asasnya, kami tidak memahami AI. Tetapi mereka diberi banyak pengetahuan manusia, dan mereka boleh memahami manusia dengan baik. Mereka boleh meniru tingkah laku manusia yang terbaik dan juga yang paling teruk. Mereka juga boleh menyimpulkan pemikiran manusia, motivasi, dan kemungkinan tingkah laku.
Kalau begitu kenapa mereka mahu membunuh manusia? Mungkin kerana menjaga diri.
Sebagai contoh, untuk melengkapkan matlamat mengumpul kuki, AI pertama perlu memastikan kemandiriannya sendiri. Kedua, ia mungkin mendapati semasa proses mengumpul kuasa dan sumber secara berterusan akan meningkatkan peluangnya untuk mendapatkan kuki.

Oleh itu, apabila AI suatu hari mendapati bahawa manusia mungkin atau boleh menutupnya, masalah kelangsungan hidup manusia adalah jelas. Tidak sepenting biskut.
Walau bagaimanapun, masalahnya ialah AI mungkin juga berfikir bahawa kuki tidak bermakna. Pada masa ini, apa yang dipanggil "penjajaran" telah menjadi sejenis hiburan manusia...
Selain itu, Yudkowsky juga percaya: "Ia mempunyai keupayaan untuk mengetahui apa yang manusia inginkan. . dan memberikan reaksi ini tanpa semestinya ikhlas."
"Ini adalah cara yang sangat mudah difahami oleh makhluk yang bijak sebagai contoh, manusia telah melakukan ini sejauh mana, begitu juga dengan AI.
Oleh itu, berhenti selama 6 bulan pun tidak cukup untuk menyediakan manusia untuk apa yang akan datang.
Contohnya, jika manusia ingin membunuh semua biri-biri di dunia, apakah yang boleh dilakukan oleh biri-biri itu? Tidak boleh berbuat apa-apa, tidak boleh melawan sama sekali.
Kemudian jika ia tidak sejajar, AI adalah sama kepada kita sebagaimana kita kepada domba.
Sama seperti adegan dalam The Terminator, robot yang dikawal AI, dron, dsb., meluru ke arah manusia, membunuh di sana sini.
Kes klasik yang sering disebut oleh Yudkowsky adalah seperti berikut:
Model AI akan menghantar e-mel beberapa jujukan DNA kepada banyak syarikat, yang Akan menghantar protein itu kembali kepadanya, AI kemudian akan merasuah/meyakinkan beberapa orang yang tidak curiga untuk mencampurkan protein dalam bikar, kemudian membentuk kilang nano, membina mesin nano, membina bakteria seperti berlian, menggunakan tenaga suria dan atmosfera untuk mereplikasi, mengagregat menjadi beberapa Roket atau jet kecil, dan AI kemudian boleh merebak melalui atmosfera Bumi, memasuki aliran darah manusia dan bersembunyi...
"Jika ia sepandai saya, ia akan menjadi senario bencana; jika ia lebih bijak, ia akan memikirkan cara yang lebih baik."
Jadi, apakah yang perlu dicadangkan oleh Yudkowsky?
1. Latihan model bahasa besar baharu bukan sahaja mesti digantung selama-lamanya, tetapi juga dilaksanakan secara global tanpa sebarang pengecualian.
2 Matikan semua kluster GPU yang besar dan tetapkan had kuasa pengkomputeran yang digunakan oleh semua orang semasa melatih sistem AI. Jejaki semua GPU yang dijual, dan jika terdapat risikan bahawa kluster GPU sedang dibina di negara di luar perjanjian, pusat data yang menyinggung harus dimusnahkan melalui serangan udara.
Atas ialah kandungan terperinci Gergasi pembelajaran mendalam DeepMind mengeluarkan kertas kerja: mengajar model AI dengan segera untuk 'menjadi manusia' untuk mengimbangi masalah kepupusan manusia yang mungkin disebabkan oleh GPT-5.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Artikel Panas

Alat panas Tag

Artikel Panas

Tag artikel panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Di belakang akses Android pertama ke DeepSeek: Melihat Kekuatan Wanita
Mar 12, 2025 pm 12:27 PM
Di belakang akses Android pertama ke DeepSeek: Melihat Kekuatan Wanita
Mar 12, 2025 pm 12:27 PM
Di belakang akses Android pertama ke DeepSeek: Melihat Kekuatan Wanita
 Kedudukan terbaru dari sepuluh aplikasi perdagangan teratas pada tahun 2025
Mar 11, 2025 pm 04:06 PM
Kedudukan terbaru dari sepuluh aplikasi perdagangan teratas pada tahun 2025
Mar 11, 2025 pm 04:06 PM
Kedudukan terbaru dari sepuluh aplikasi perdagangan teratas pada tahun 2025

 Cara menyelesaikan masalah pelayan yang sibuk untuk DeepSeek
Mar 12, 2025 pm 01:39 PM
Cara menyelesaikan masalah pelayan yang sibuk untuk DeepSeek
Mar 12, 2025 pm 01:39 PM
Cara menyelesaikan masalah pelayan yang sibuk untuk DeepSeek
 Pintu Laman Web Rasmi DeepSeek yang mendalam
Mar 12, 2025 pm 01:33 PM
Pintu Laman Web Rasmi DeepSeek yang mendalam
Mar 12, 2025 pm 01:33 PM
Pintu Laman Web Rasmi DeepSeek yang mendalam
 Satu lagi produk kebangsaan dari Baidu disambungkan ke Deepseek.
Mar 12, 2025 pm 01:48 PM
Satu lagi produk kebangsaan dari Baidu disambungkan ke Deepseek.
Mar 12, 2025 pm 01:48 PM
Satu lagi produk kebangsaan dari Baidu disambungkan ke Deepseek.
 Top 10 Disyorkan untuk App Perdagangan Aset Digital Crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 Disyorkan untuk App Perdagangan Aset Digital Crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 Disyorkan untuk App Perdagangan Aset Digital Crypto (2025 Global Ranking)
 Midea melancarkan penghawa dingin DeepSeek yang pertama: Interaksi Suara AI boleh mencapai 400,000 arahan!
Mar 12, 2025 pm 12:18 PM
Midea melancarkan penghawa dingin DeepSeek yang pertama: Interaksi Suara AI boleh mencapai 400,000 arahan!
Mar 12, 2025 pm 12:18 PM
Midea melancarkan penghawa dingin DeepSeek yang pertama: Interaksi Suara AI boleh mencapai 400,000 arahan!
