
 Peranti teknologi
AI
Google mengembangkan parameter model pemindahan visual kepada 22 bilion, dan penyelidik mengambil tindakan kolektif sejak ChatGPT menjadi popular
Peranti teknologi
AI
Google mengembangkan parameter model pemindahan visual kepada 22 bilion, dan penyelidik mengambil tindakan kolektif sejak ChatGPT menjadi popular
Google mengembangkan parameter model pemindahan visual kepada 22 bilion, dan penyelidik mengambil tindakan kolektif sejak ChatGPT menjadi popular

Sama seperti pemprosesan bahasa semula jadi, pemindahan tulang belakang visual yang telah terlatih meningkatkan prestasi model pada pelbagai tugas penglihatan. Set data yang lebih besar, seni bina berskala dan kaedah latihan baharu semuanya telah mendorong peningkatan dalam prestasi model.
Walau bagaimanapun, model visual masih ketinggalan jauh daripada model bahasa. Secara khusus, ViT, model penglihatan terbesar setakat ini, hanya mempunyai parameter 4B, manakala model bahasa peringkat permulaan selalunya melebihi parameter 10B, apatah lagi model bahasa besar dengan parameter 540B.
Untuk meneroka had prestasi model AI, Google Research baru-baru ini menjalankan kajian dalam bidang CV, menerajui dalam mengembangkan saiz parameter Vision Transformer kepada 22B dan mencadangkan ViT -22B, yang serupa dengan yang sebelumnya Berbanding dengan jumlah parameter model 4B, boleh dikatakan bahawa ini adalah model ViT padat terbesar setakat ini.

Alamat kertas: https://arxiv.org/pdf/2302.05442.pdf
Membandingkan ViT-G dan ViT-e terbesar sebelumnya, Jadual 1 memberikan hasil perbandingan Daripada jadual di bawah, dapat dilihat bahawa ViT-22B terutamanya mengembangkan lebar model , menjadikan parameter Isipadu lebih besar dan kedalaman adalah sama dengan ViT-G.
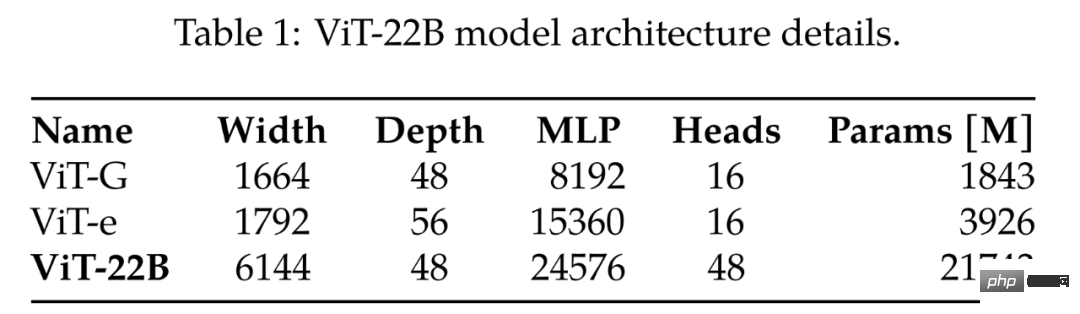
Model besar ViT semasa
Sebagai netizen Zhihu ini berkata, mungkinkah Google kalah satu pusingan di ChatGPT dan pasti akan bersaing dalam bidang CV?

Bagaimana untuk melakukannya? Ternyata pada peringkat awal penyelidikan, mereka mendapati bahawa ketidakstabilan latihan berlaku semasa pengembangan ViT, yang mungkin membawa kepada perubahan seni bina. Para penyelidik kemudian mereka bentuk model dengan teliti dan melatihnya selari dengan kecekapan yang belum pernah terjadi sebelumnya. Kualiti ViT-22B dinilai melalui set tugasan yang komprehensif, daripada klasifikasi (sedikit pukulan) kepada tugas keluaran padat, di mana ia memenuhi atau melebihi tahap SOTA semasa. Sebagai contoh, ViT-22B mencapai ketepatan 89.5% pada ImageNet walaupun digunakan sebagai pengekstrak ciri visual beku. Dengan melatih menara teks untuk memadankan ciri visual ini, ia mencapai 85.9% ketepatan tangkapan sifar pada ImageNet. Di samping itu, model itu boleh dianggap sebagai guru dan digunakan sebagai sasaran penyulingan Para penyelidik melatih model pelajar ViT-B dan mencapai ketepatan 88.6% pada ImageNet, mencapai tahap SOTA untuk model skala ini.
Seni Bina Model
ViT-22B ialah model pengekod berasaskan Transformer serupa dengan seni bina Vision Transformer asal, tetapi mengandungi tiga pengubahsuaian utama berikut untuk meningkatkan Kecekapan dan kestabilan dalam latihan berskala besar: lapisan selari, penormalan pertanyaan/kunci (QK) dan berat sebelah ditinggalkan.
Lapisan selari. Seperti yang dinyatakan dalam kajian Wang dan Komatsuzaki, kajian ini mereka bentuk struktur selari Perhatian dan MLP: Unjuran linear MLP dan blok perhatian untuk mencapai selari tambahan. Terutamanya, pendaraban matriks untuk unjuran pertanyaan/kunci/nilai dan lapisan linear pertama MLP digabungkan menjadi satu operasi, seperti halnya untuk unjuran luar perhatian dan lapisan linear kedua MLP.
Penormalan QK. Satu kesukaran dalam melatih model besar ialah kestabilan model Dalam proses memanjangkan ViT, penyelidik mendapati bahawa kehilangan latihan berbeza selepas beribu-ribu pusingan langkah. Fenomena ini amat ketara dalam model parameter 8B. Untuk menstabilkan latihan model, penyelidik menggunakan kaedah Gilmer et al untuk menggunakan operasi normalisasi LayerNorm pada pertanyaan dan kunci sebelum pengiraan perhatian produk titik untuk meningkatkan kestabilan latihan. Secara khusus, berat perhatian dikira sebagai: 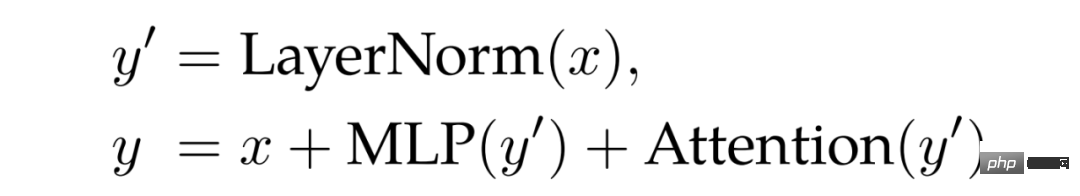
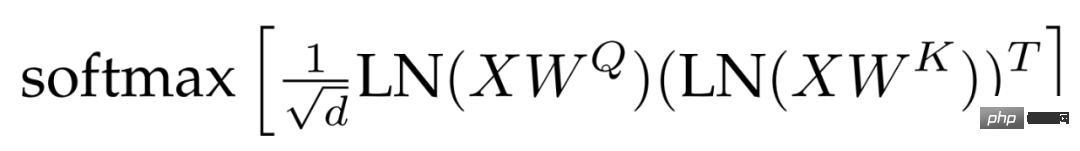
meninggalkan berat sebelah. Selepas PaLM, istilah bias dialih keluar daripada unjuran QKV dan semua norma lapisan digunakan tanpa berat sebelah, menghasilkan penggunaan pemecut yang lebih baik (3%) tanpa penurunan kualiti. Walau bagaimanapun, tidak seperti PaLM, penyelidik menggunakan istilah berat sebelah untuk lapisan padat MLP, dan walaupun begitu, pendekatan ini tidak menjejaskan kelajuan sambil mengambil kira kualiti.
Rajah 2 menunjukkan blok pengekod ViT-22B. Lapisan benam menjalankan operasi seperti pengekstrakan tampalan, unjuran linear dan penambahan kedudukan berdasarkan ViT asal. Para penyelidik menggunakan pengumpulan perhatian berbilang kepala untuk mengagregat setiap perwakilan token dalam kepala.

ViT-22B menggunakan tampalan 14 × 14 dengan resolusi imej 224 × 224. ViT-22B menggunakan pembenaman kedudukan satu dimensi yang dipelajari. Semasa penalaan halus pada imej beresolusi tinggi, penyelidik melakukan interpolasi dua dimensi berdasarkan tempat benam kedudukan pra-latihan berada dalam imej asal.
Infrastruktur dan Kecekapan Latihan
ViT-22B menggunakan perpustakaan FLAX, dilaksanakan sebagai JAX, dan dibina dalam Scenic. Ia mengeksploitasi kedua-dua model dan selari data. Terutamanya, penyelidik menggunakan API jax.xmap, yang menyediakan kawalan eksplisit ke atas serpihan semua perantaraan (seperti pemberat dan pengaktifan) serta komunikasi antara cip. Para penyelidik menyusun cip ke dalam grid logik 2D bersaiz t × k, di mana t ialah saiz paksi selari data dan k ialah saiz paksi model. Kemudian, bagi setiap kumpulan t, peranti k memperoleh kumpulan imej yang sama, dengan setiap peranti hanya mengekalkan 1/k pengaktifan dan bertanggungjawab untuk mengira 1/k daripada semua output lapisan linear (butiran di bawah).
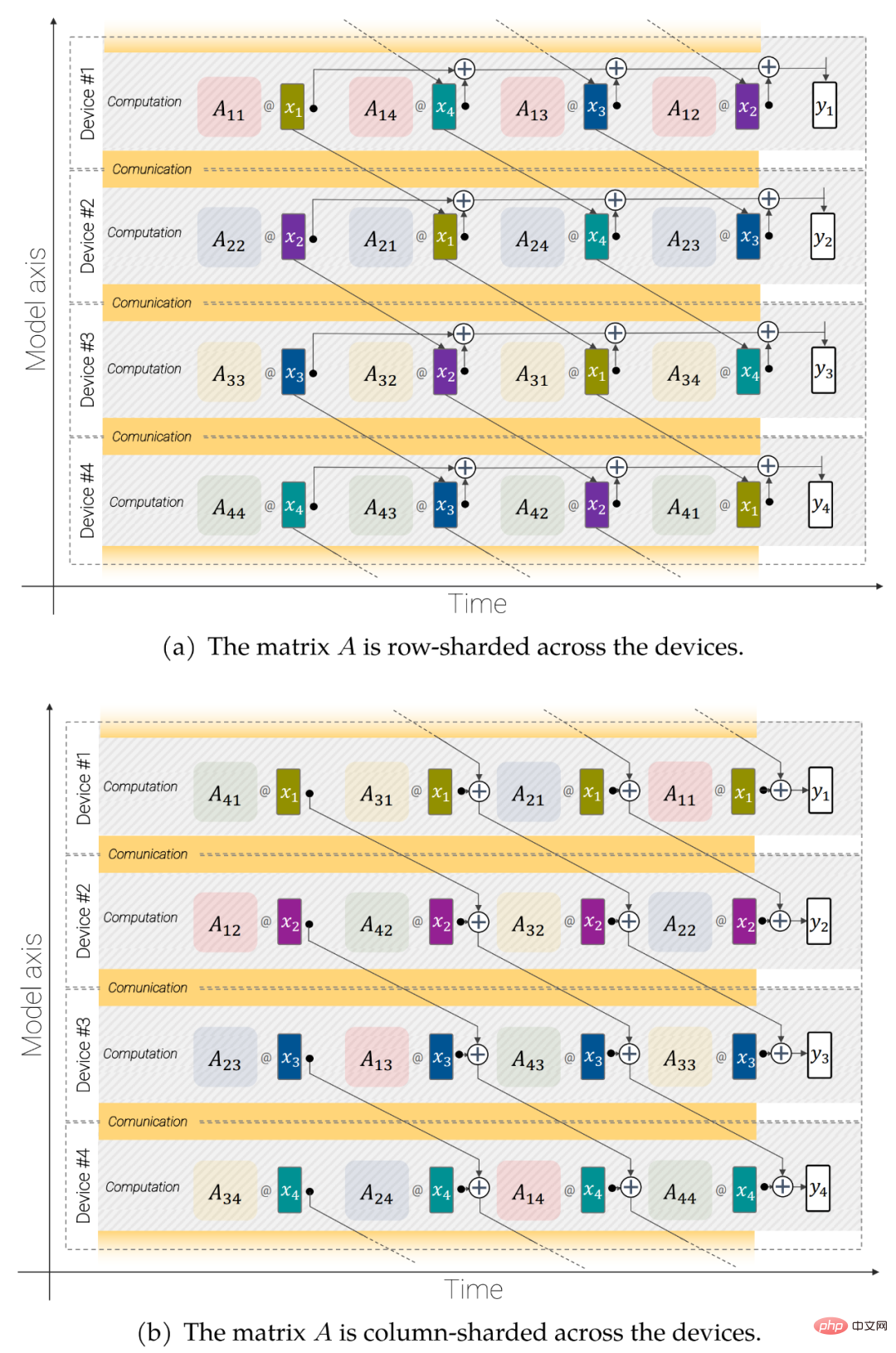
Rajah 3: Operasi linear selari tak segerak (y = Ax): komunikasi bertindih dan pengiraan merentas peranti Model untuk pendaraban matriks selari.
Kendalian linear selari tak segerak. Untuk memaksimumkan daya pengeluaran, pengiraan dan komunikasi mesti dipertimbangkan. Iaitu, jika anda mahu operasi ini setara secara analitik dengan kes yang tidak dipecahkan, anda perlu berkomunikasi sesedikit mungkin, sebaik-baiknya membiarkannya bertindih supaya anda boleh mengekalkan unit pendaraban matriks (di mana kebanyakan kapasiti FLOP berada) ) adalah sentiasa sibuk.
Pecahan parameter. Model adalah data selari dalam paksi pertama. Setiap parameter boleh direplikasi sepenuhnya pada paksi ini, atau setiap peranti boleh disimpan dengan sebahagian daripadanya. Para penyelidik memilih untuk memisahkan beberapa tensor besar daripada parameter model untuk dapat memuatkan model dan saiz kelompok yang lebih besar.
Menggunakan teknik ini, ViT-22B memproses 1.15k token sesaat setiap teras semasa latihan pada TPUv4. Penggunaan model flop (MFU) ViT-22B ialah 54.9%, menunjukkan penggunaan perkakasan yang sangat cekap. Ambil perhatian bahawa PaLM melaporkan MFU sebanyak 46.2%, manakala penyelidik mengukur MFU sebanyak 44.0% untuk ViT-e (keselarian data sahaja) pada perkakasan yang sama.
Hasil eksperimen
Percubaan meneroka keputusan penilaian ViT-22B untuk klasifikasi imej.
Keputusan Jadual 2 menunjukkan bahawa ViT-22B masih mempunyai peningkatan yang ketara dalam pelbagai penunjuk. Tambahan pula, kajian telah menunjukkan bahawa pemeriksaan linear model besar seperti ViT-22B boleh mendekati atau melebihi prestasi penalaan halus penuh model yang lebih kecil dengan resolusi tinggi, yang selalunya lebih murah dan lebih mudah dilakukan.
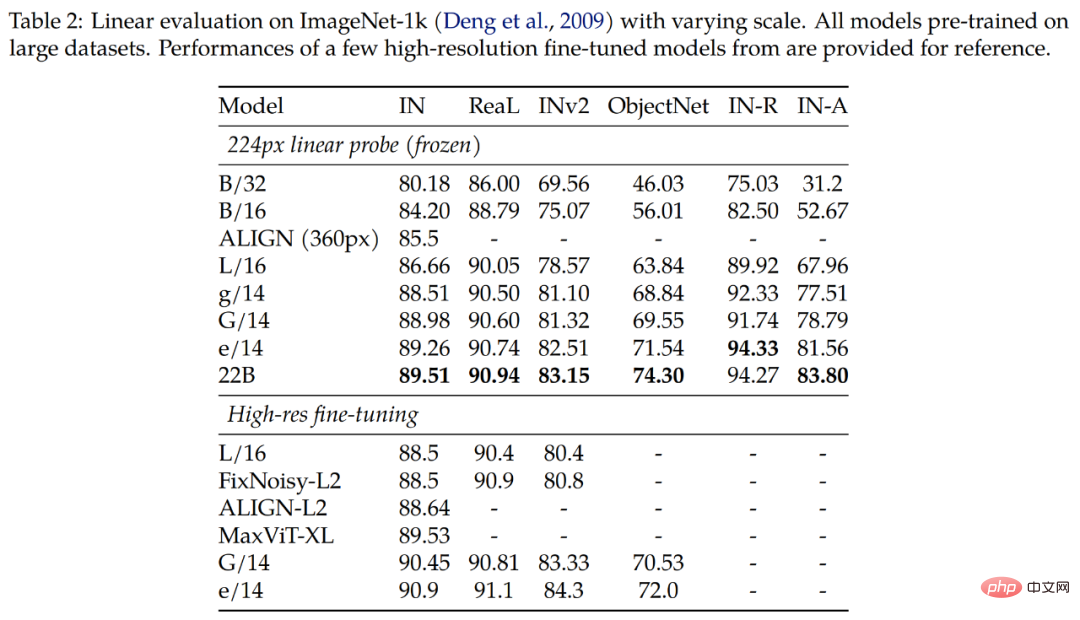
Kajian ini menguji lagi kebolehpisahan linear pada dataset klasifikasi berbutir halus iNaturalist 2017, membandingkan ViT-22B dengan ViT lain varian untuk perbandingan. Kajian itu menguji resolusi input 224px dan 384px. Keputusan ditunjukkan dalam Rajah 4. Kajian mendapati bahawa ViT-22B dengan ketara mengatasi varian ViT lain, terutamanya pada resolusi input standard 224px. Ini menunjukkan bahawa bilangan besar parameter dalam ViT-22B berguna untuk mengekstrak maklumat terperinci daripada imej.
Jadual 3 menunjukkan hasil migrasi sifar pukulan ViT-22B untuk model CLIP, ALIGN, BASIC, CoCa, LiT. Bahagian bawah Jadual 3 membandingkan tiga prestasi model ViT.
ViT-22B mencapai keputusan yang setanding atau lebih baik pada semua set ujian ImageNet. Terutama, keputusan sifar pukulan pada set ujian ObjectNet sangat berkorelasi dengan saiz model ViT. Yang terbesar, ViT-22B, menetapkan SOTA baharu pada set ujian ObjectNet yang mencabar.

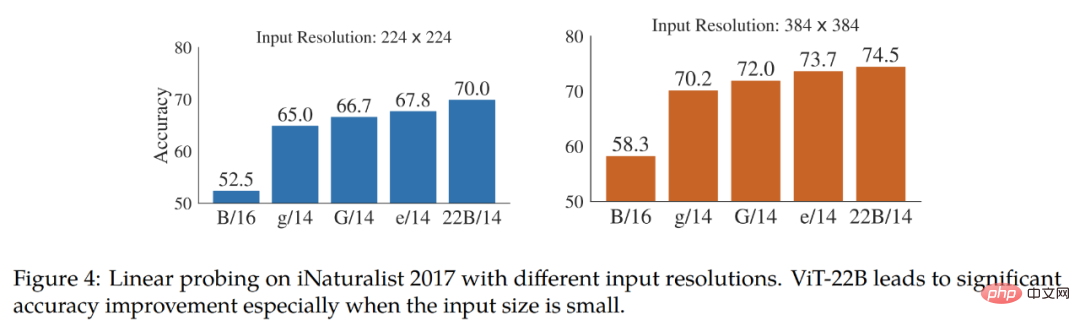
Di luar pengedaran (OOD). Kajian ini membina pemetaan label daripada JFT ke ImageNet, dan daripada ImageNet kepada set data luar pengedaran yang berbeza, iaitu ObjectNet, ImageNet-v2, ImageNet- R, dan ImageNet- A.
Hasil yang disahkan setakat ini ialah, konsisten dengan penambahbaikan pada ImageNet, memanjangkan model meningkatkan prestasi luar pengedaran. Ini berfungsi untuk model yang hanya melihat imej JFT, serta model yang diperhalusi pada ImageNet. Dalam kedua-dua kes, ViT-22B meneruskan trend prestasi OOD yang lebih baik pada model yang lebih besar (Rajah 5, Jadual 11). Di samping itu, para penyelidik juga mengkaji prestasi yang ditangkap oleh model ViT-22B dalam segmentasi semantik dan anggaran kedalaman monokular. kualiti maklumat geometri dan ruang.
Pembahagian semantik. Para penyelidik menilai ViT-22B sebagai tulang belakang segmentasi semantik pada tiga penanda aras: ADE20K, Konteks Pascal dan Pascal VOC. Seperti yang dapat dilihat daripada Jadual 4, penghijrahan tulang belakang ViT-22B berfungsi lebih baik apabila hanya beberapa topeng segmentasi dilihat. 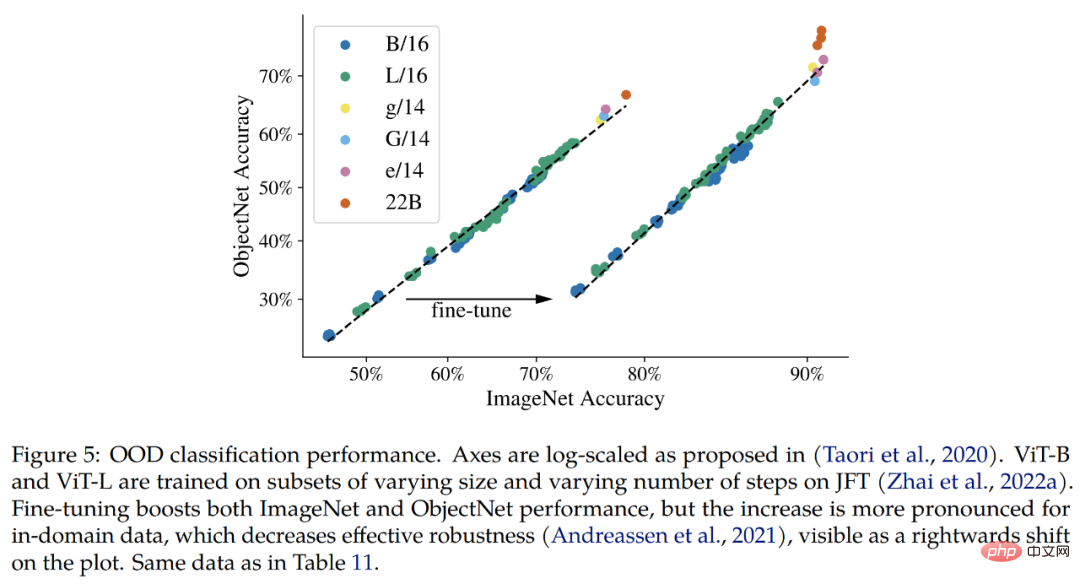
Anggaran kedalaman monokular. Jadual 5 meringkaskan dapatan utama kajian. Seperti yang boleh diperhatikan dari baris atas (dekoder DPT), menggunakan ciri ViT-22B menghasilkan prestasi terbaik (pada semua metrik) berbanding dengan tulang belakang yang berbeza. Dengan membandingkan tulang belakang ViT-22B dengan ViT-e, model yang lebih kecil tetapi dilatih pada data yang sama seperti ViT-22B, kami mendapati bahawa memanjangkan seni bina meningkatkan prestasi.
Selain itu, membandingkan tulang belakang ViT-e dengan ViT-L (seni bina yang serupa dengan ViT-e, tetapi dengan kurang data latihan), kajian mendapati bahawa peningkatan ini juga datang daripada sambungan Data sebelum latihan. Penemuan ini mencadangkan bahawa kedua-dua model yang lebih besar dan set data yang lebih besar membantu meningkatkan prestasi. 
Kajian ini juga diterokai pada set data video. Jadual 6 menunjukkan keputusan klasifikasi video pada set data Kinetics 400 dan Moments in Time, menunjukkan bahawa keputusan kompetitif boleh dicapai menggunakan tulang belakang beku. Kajian ini mula-mula membandingkan dengan ViT-e, yang mempunyai model tulang belakang visual terbesar sebelum ini, yang terdiri daripada 4 bilion parameter, dan juga dilatih pada set data JFT. Kami mendapati bahawa model ViT-22B yang lebih besar bertambah baik sebanyak 1.5 mata pada Kinetics 400 dan 1.3 mata pada Moments in Time.
Akhirnya kajian mendapati terdapat ruang untuk penambahbaikan lanjut dengan penalaan halus menyeluruh dari hujung ke hujung. 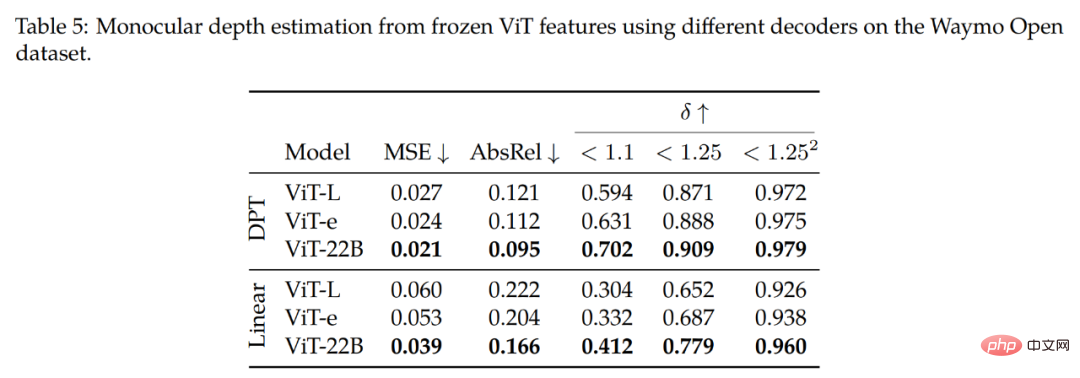
Sila rujuk kertas asal untuk butiran lanjut teknikal.
Atas ialah kandungan terperinci Google mengembangkan parameter model pemindahan visual kepada 22 bilion, dan penyelidik mengambil tindakan kolektif sejak ChatGPT menjadi popular. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1393
1393
 52
1207
24
52
1207
24

 Sesame Open Door Exchange Web Pautan Pautan Gerbang Perdagangan Laman Web Pendaftaran Terkini
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange Web Pautan Pautan Gerbang Perdagangan Laman Web Pendaftaran Terkini
Feb 28, 2025 am 11:06 AM
Artikel ini memperkenalkan proses pendaftaran versi web Web Open Exchange (GATE.IO) dan aplikasi Perdagangan Gate secara terperinci. Sama ada pendaftaran web atau pendaftaran aplikasi, anda perlu melawat laman web rasmi atau App Store untuk memuat turun aplikasi tulen, kemudian isi nama pengguna, kata laluan, e -mel, nombor telefon bimbit dan maklumat lain, dan lengkap e -mel atau pengesahan telefon bimbit.
 Mengapa pautan Bybit Exchange tidak dimuat turun dan dipasang secara langsung?
Feb 21, 2025 pm 10:57 PM
Mengapa pautan Bybit Exchange tidak dimuat turun dan dipasang secara langsung?
Feb 21, 2025 pm 10:57 PM
Mengapa pautan Bybit Exchange tidak dimuat turun dan dipasang secara langsung? Bybit adalah pertukaran cryptocurrency yang menyediakan perkhidmatan perdagangan kepada pengguna. Aplikasi mudah alih Exchange tidak boleh dimuat turun terus melalui AppStore atau GooglePlay untuk sebab -sebab berikut: 1. Aplikasi pertukaran cryptocurrency sering tidak memenuhi keperluan ini kerana ia melibatkan perkhidmatan kewangan dan memerlukan peraturan dan standard keselamatan tertentu. 2. Undang -undang dan Peraturan Pematuhan di banyak negara, aktiviti yang berkaitan dengan urus niaga cryptocurrency dikawal atau terhad. Untuk mematuhi peraturan ini, aplikasi bybit hanya boleh digunakan melalui laman web rasmi atau saluran yang diberi kuasa lain
 WEB OPEN DOOR EXCHANGE WEB PAGE LOGIN VERSI VERSI UNTUK GATEIO Laman Web Rasmi Pintu Masuk
Mar 04, 2025 pm 11:48 PM
WEB OPEN DOOR EXCHANGE WEB PAGE LOGIN VERSI VERSI UNTUK GATEIO Laman Web Rasmi Pintu Masuk
Mar 04, 2025 pm 11:48 PM
Pengenalan terperinci kepada operasi log masuk versi Web Open Exchange, termasuk langkah masuk dan proses pemulihan kata laluan.
 Platform Perdagangan Pintu Terbuka Sesame Muat turun Versi Mudah Alih Platform Perdagangan Platform Perdagangan Alamat Muat Turun
Feb 28, 2025 am 10:51 AM
Platform Perdagangan Pintu Terbuka Sesame Muat turun Versi Mudah Alih Platform Perdagangan Platform Perdagangan Alamat Muat Turun
Feb 28, 2025 am 10:51 AM
Adalah penting untuk memilih saluran rasmi untuk memuat turun aplikasi dan memastikan keselamatan akaun anda.
 Top 10 Disyorkan untuk App Perdagangan Aset Digital Crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 Disyorkan untuk App Perdagangan Aset Digital Crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Artikel ini mencadangkan sepuluh platform perdagangan cryptocurrency teratas yang memberi perhatian kepada, termasuk Binance, OKX, Gate.io, Bitflyer, Kucoin, Bybit, Coinbase Pro, Kraken, BYDFI dan Xbit yang desentralisasi. Platform ini mempunyai kelebihan mereka sendiri dari segi kuantiti mata wang transaksi, jenis urus niaga, keselamatan, pematuhan, dan ciri khas. Memilih platform yang sesuai memerlukan pertimbangan yang komprehensif berdasarkan pengalaman perdagangan anda sendiri, toleransi risiko dan keutamaan pelaburan. Semoga artikel ini membantu anda mencari saman terbaik untuk diri sendiri
 Portal Log Masuk Versi Rasmi Binance Binance
Feb 21, 2025 pm 05:42 PM
Portal Log Masuk Versi Rasmi Binance Binance
Feb 21, 2025 pm 05:42 PM
Untuk mengakses versi Login Laman Web Binance yang terkini, ikuti langkah mudah ini. Pergi ke laman web rasmi dan klik butang "Login" di sudut kanan atas. Pilih kaedah log masuk anda yang sedia ada. Masukkan nombor mudah alih berdaftar atau e -mel dan kata laluan anda dan pengesahan lengkap (seperti kod pengesahan mudah alih atau Google Authenticator). Selepas pengesahan yang berjaya, anda boleh mengakses Portal Log masuk laman web rasmi Binance.
 Bitget Trading Platform Rasmi App Muat turun dan Alamat Pemasangan
Feb 25, 2025 pm 02:42 PM
Bitget Trading Platform Rasmi App Muat turun dan Alamat Pemasangan
Feb 25, 2025 pm 02:42 PM
Panduan ini menyediakan langkah muat turun dan pemasangan terperinci untuk aplikasi Bitget Exchange rasmi, sesuai untuk sistem Android dan iOS. Panduan ini mengintegrasikan maklumat dari pelbagai sumber yang berwibawa, termasuk laman web rasmi, App Store, dan Google Play, dan menekankan pertimbangan semasa muat turun dan pengurusan akaun. Pengguna boleh memuat turun aplikasinya dari saluran rasmi, termasuk App Store, muat turun APK laman web rasmi dan melompat laman web rasmi, dan lengkap pendaftaran, pengesahan identiti dan tetapan keselamatan. Di samping itu, panduan itu merangkumi soalan dan pertimbangan yang sering ditanya, seperti
 Alamat muat turun terbaru Bitget pada tahun 2025: Langkah -langkah untuk mendapatkan aplikasi rasmi
Feb 25, 2025 pm 02:54 PM
Alamat muat turun terbaru Bitget pada tahun 2025: Langkah -langkah untuk mendapatkan aplikasi rasmi
Feb 25, 2025 pm 02:54 PM
Panduan ini menyediakan langkah muat turun dan pemasangan terperinci untuk aplikasi Bitget Exchange rasmi, sesuai untuk sistem Android dan iOS. Panduan ini mengintegrasikan maklumat dari pelbagai sumber yang berwibawa, termasuk laman web rasmi, App Store, dan Google Play, dan menekankan pertimbangan semasa muat turun dan pengurusan akaun. Pengguna boleh memuat turun aplikasinya dari saluran rasmi, termasuk App Store, muat turun APK laman web rasmi dan melompat laman web rasmi, dan lengkap pendaftaran, pengesahan identiti dan tetapan keselamatan. Di samping itu, panduan itu merangkumi soalan dan pertimbangan yang sering ditanya, seperti
