

Beberapa hari yang lalu, komen ketua saintis kecerdasan buatan Meta Yann LeCun tentang ChatGPT dengan cepat merebak ke seluruh industri dan mencetuskan banyak perbincangan.
Pada perhimpunan kecil media dan eksekutif di Zoom, LeCun membuat komen yang mengejutkan: "Setakat teknologi asas, ChatGPT bukanlah inovasi yang hebat
"Walaupun begitu adalah revolusioner di mata umum, kami tahu bahawa ia adalah produk yang disusun dengan baik, tidak lebih daripada itu."
CtGPT, sebagai Robot sembang "trend teratas" dalam beberapa bulan yang lalu, telah menjadi popular di seluruh dunia, malah telah benar-benar mengubah kerjaya sesetengah orang dan status semasa pendidikan sekolah.
Apabila seluruh dunia kagum dengannya, ulasan LeCun terhadap ChatGPT adalah "meremehkan".

Tetapi sebenarnya, tegurannya bukanlah sesuatu yang tidak munasabah.
Banyak syarikat dan makmal penyelidikan mempunyai sistem kecerdasan buatan terdorong data seperti ChatGPT. LeCun berkata OpenAI tidak unik dalam bidang ini.
"Selain Google dan Meta, terdapat enam syarikat permulaan, pada asasnya semuanya dengan teknologi yang hampir serupa."

Kemudian, LeCun mendapat sedikit masam -
"ChatGPT menggunakan seni bina Transformer yang dilatih terlebih dahulu dengan cara yang diselia sendiri, dan supervised Learning adalah perkara yang saya anjurkan sejak sekian lama OpenAI masih belum lahir pada masa itu "
Antaranya, Transformer ialah ciptaan Google. Rangkaian saraf bahasa ini adalah asas kepada model bahasa yang besar seperti GPT-3.
Model bahasa rangkaian saraf pertama telah dicadangkan oleh Yoshua Bengio 20 tahun lalu. Mekanisme perhatian Bengio kemudiannya digunakan oleh Google dalam Transformer, dan sejak itu telah menjadi elemen utama dalam semua model bahasa.
Selain itu, ChatGPT menggunakan teknologi pembelajaran pengukuhan maklum balas manusia (RLHF), yang turut dipelopori oleh Google DeepMind Lab.
Pada pandangan LeCun, ChatGPT lebih merupakan kes kejuruteraan yang berjaya daripada kejayaan saintifik.
Teknologi OpenAI "bukan sesuatu yang inovatif dari segi sains asas, ia hanya direka dengan baik."
"Sudah tentu, saya tidak akan mengkritik mereka untuk itu." >

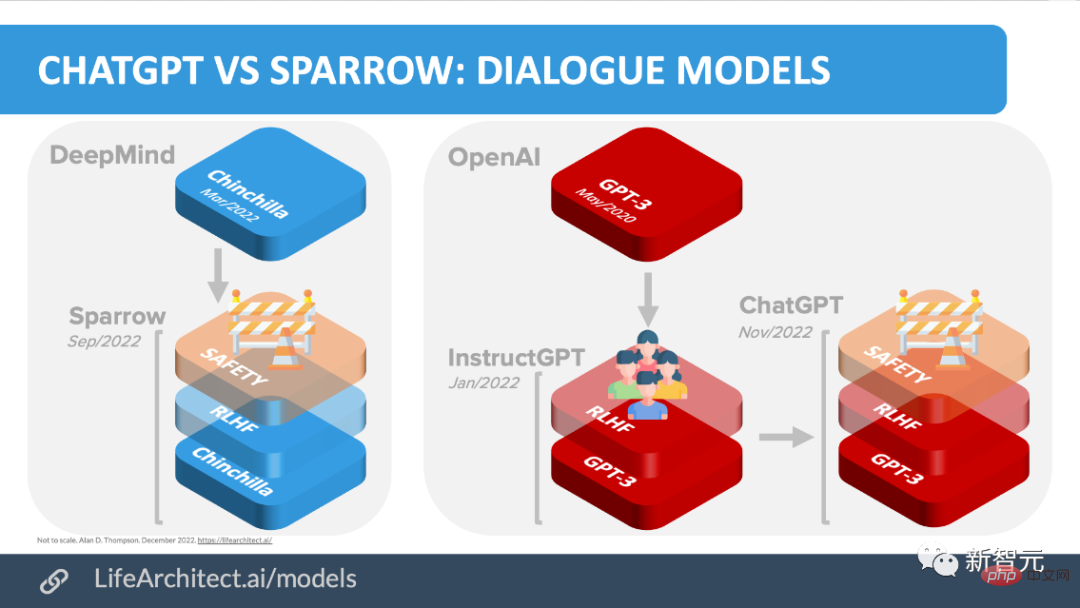
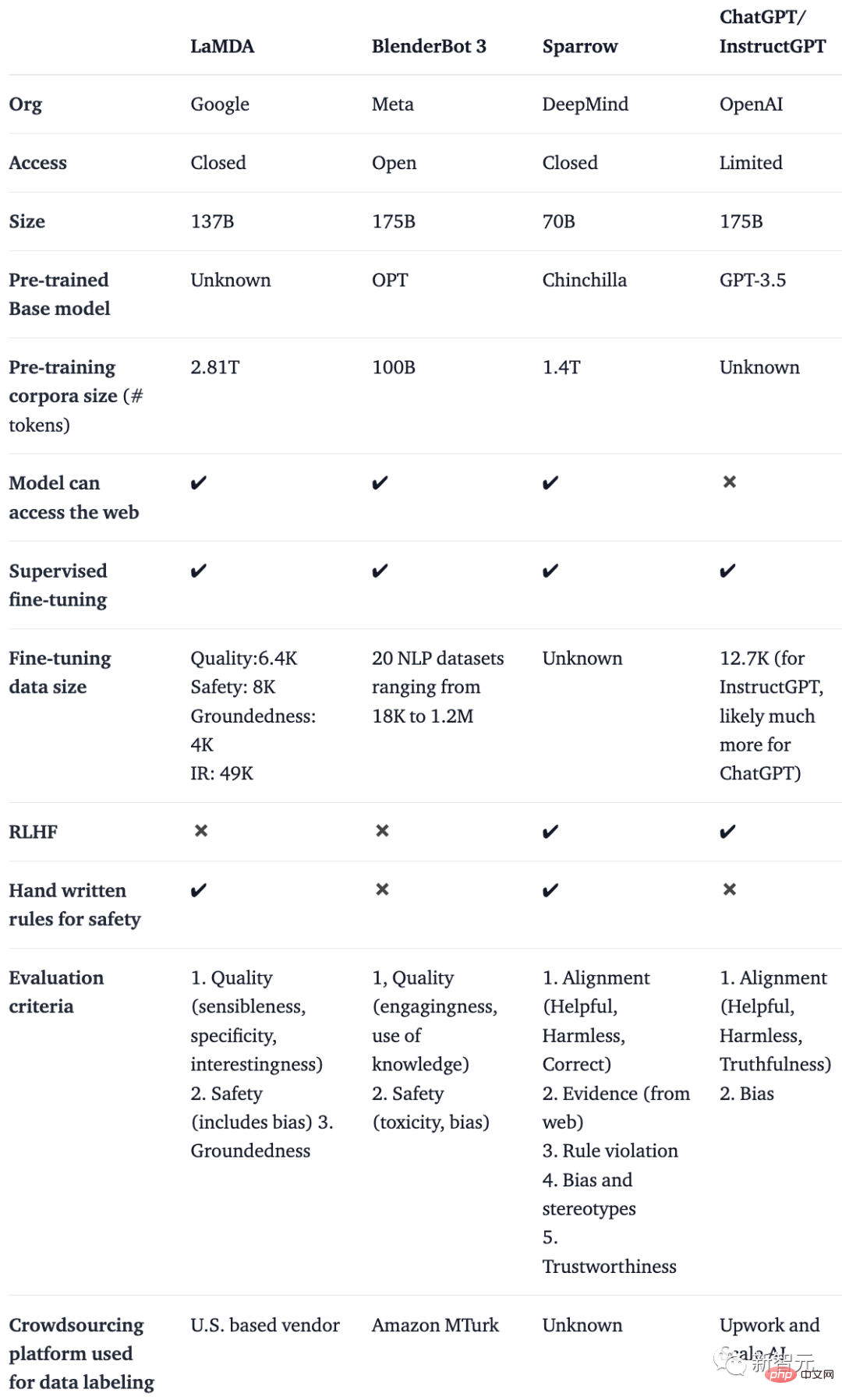
Mereka membuat jadual membandingkan chatbot AI seperti BlenderBot, LaMDA, Sparrow dan InstructGPT berdasarkan butiran seperti akses awam, data latihan, seni bina model dan arah penilaian.
Nota: Oleh kerana ChatGPT tidak didokumenkan, mereka menggunakan butiran InstructGPT, model penalaan halus arahan daripada OpenAI yang boleh dianggap sebagai asas ChatGPT.
LaMDA |
BlenderBot 3 |
Sparrow |
ChatGPT/ InstructGPT |
|
Organisasi |
Meta |
DeepMind |
OpenAI |
|
|
Hak Akses |
Ditutup |
Awam |
Tertutup |
Terhad |
Saiz parameter |
137 bilion |
175 bilion |
70 bilion |
175 bilion |
Model asas |
Tidak diketahui |
PILIH |
Chinchilla |
GPT-3.5 |
Saiz korpus |
2.81 trilion |
100 bilion |
1.4 trilion |
Tidak diketahui |
Rangkaian Akses | ✔️ |
✔️ |
✔️ |
✖️ |
Penyeliaan dan penalaan halus |
✔️ |
✔️ |
✔️ |
✔️ |
Skala data diperhalusi |
Kualiti tinggi: 6.4K Keselamatan: 8K Ciri-ciri Pelaksanaan: 4K IR: 49K |
20 set data NLP antara 18K hingga 1.2M |
Tidak diketahui |
12.7K (ChatGPT mungkin lebih) |
RLHF |
✖️ |
✖️ |
✔️ |
✔️ |
Peraturan Keselamatan Manual |
✔ |
✖️ |
✔ |
✖️ |
Adalah mudah untuk melihat bahawa walaupun terdapat banyak perbezaan dalam data latihan, model asas dan penalaan halus, semua bot sembang ini mempunyai satu persamaan – mengikut arahan.
Sebagai contoh, anda boleh mengarahkan ChatGPT untuk menulis puisi tentang penalaan halus.
Seperti yang anda lihat, ChatGPT sangat "kognitif" dan tidak pernah lupa menyanjung LeCun dan Hinton apabila menulis puisi.
Kemudian dia memuji dengan penuh semangat: "Putar, Putar, anda adalah tarian yang indah."
Biasanya, pemodelan bahasa model asas tidak mencukupi untuk model belajar cara mengikuti arahan pengguna. 
Antaranya, contoh arahan ini terdiri daripada tiga bahagian utama: arahan, input dan output.
Input adalah pilihan, sesetengah tugas hanya memerlukan arahan, seperti binaan terbuka dalam contoh ChatGPT di atas. 
Data IFT biasanya merupakan koleksi arahan yang ditulis oleh manusia dan contoh arahan berpandukan model bahasa.
Semasa proses but, LM digesa dalam tetapan beberapa tangkapan (gambar di atas) dan diarahkan untuk menjana arahan, input dan output baharu.
Dalam setiap pusingan, model digesa untuk memilih daripada sampel tulisan manusia dan model yang dijana. 
Satu hujung ialah set data IFT yang dijana model tulen, seperti Arahan Tidak Semulajadi, dan hujung satu lagi ialah sejumlah besar arahan yang dijana secara buatan, seperti Super-natural arahan.
Di antaranya ialah menggunakan set data benih yang lebih kecil tetapi berkualiti tinggi dan kemudian melakukan kerja berpandu, seperti Arahan Kendiri.
Cara lain untuk menyusun set data untuk IFT ialah memanfaatkan set data NLP sumber khalayak berkualiti tinggi sedia ada pada pelbagai tugas (termasuk gesaan) dan menggabungkannya menggunakan corak bersatu atau templat berbeza Set data ditukar kepada arahan. 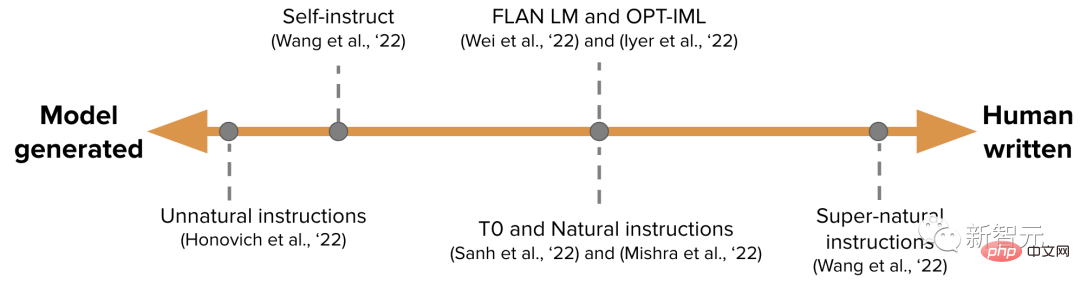
Kertas berkaitan set data arahan semula jadi: https://arxiv.org/abs/2104.08773
Memperhalusi model

Seterusnya, penyelidik melatih model keutamaan pada respons beranotasi ini, mengembalikan ganjaran skalar kepada pengoptimum RL.
Akhir sekali, latih bot sembang melalui pembelajaran pengukuhan untuk mensimulasikan model keutamaan ini. 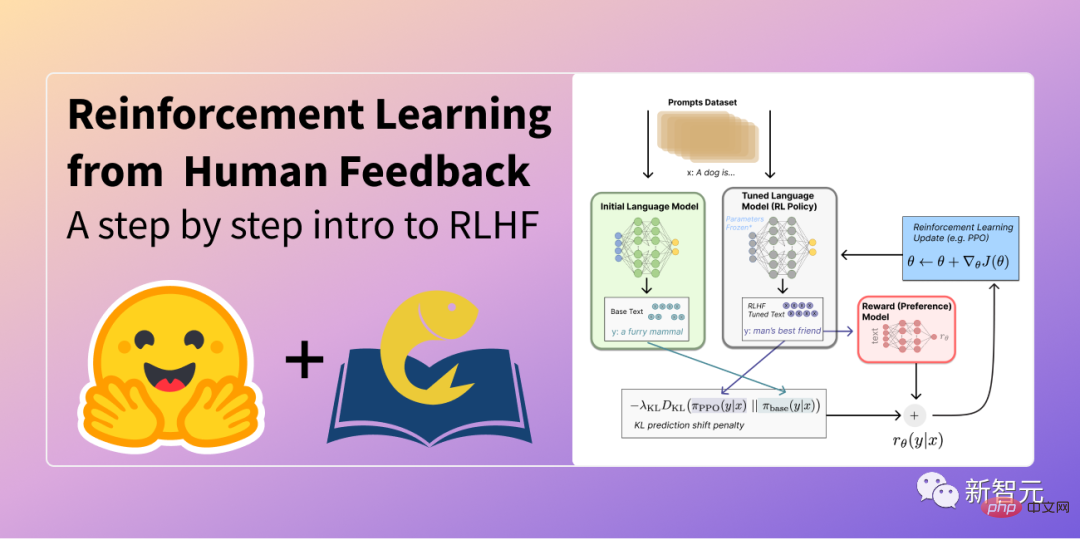
Gesaan Rantaian Pemikiran (CoT) ialah kes khas contoh perintah yang mendorong chatbot untuk menaakul langkah demi langkah untuk menghasilkan output.
Model yang diperhalusi dengan CoT menggunakan set data arahan untuk inferens langkah demi langkah dengan anotasi manusia.
Inilah asal usul gesaan yang terkenal - "mari kita fikir langkah demi langkah". 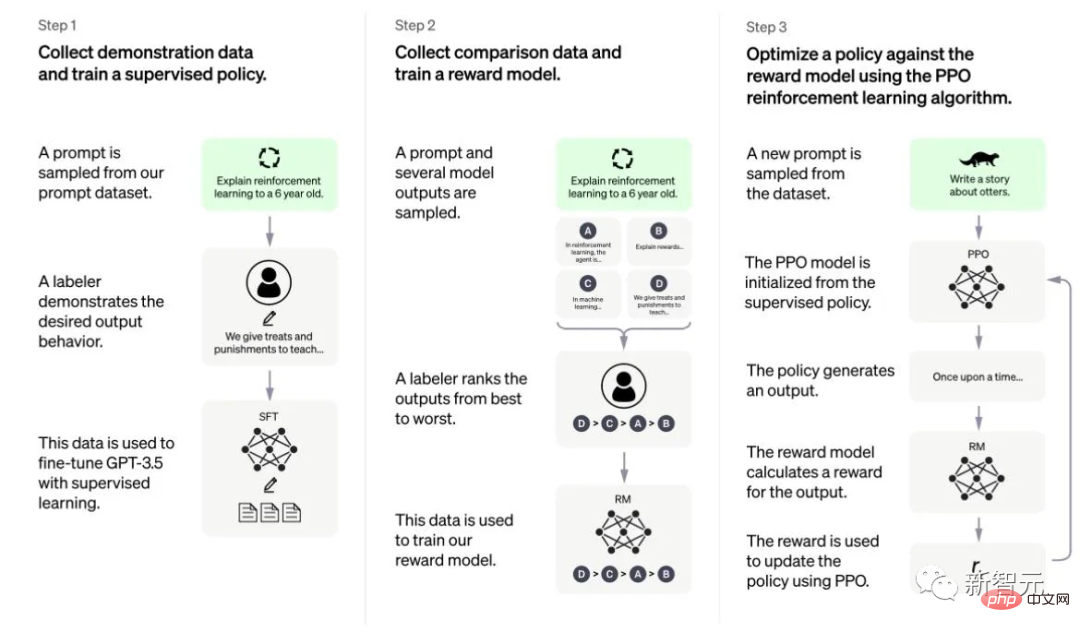
Contoh berikut diambil daripada "Scaling Instruction-Finetuned Language Models". Antaranya, oren menyerlahkan arahan, merah jambu menunjukkan input dan output, dan biru ialah inferens CoT.

Makalah tersebut menunjukkan bahawa model yang diperhalusi dengan CoT berprestasi lebih baik dalam tugas yang melibatkan akal sehat, aritmetik dan penaakulan simbolik.
Selain itu, penalaan halus CoT juga sangat berkesan pada topik sensitif (kadangkala lebih baik daripada RLHF), terutamanya untuk mengelakkan rasuah model - "Maaf, saya tidak dapat menjawab".

Seperti yang baru disebutkan, model bahasa yang diperhalusi arahan tidak boleh sentiasa menghasilkan respons yang berguna dan selamat.
Sebagai contoh, ia akan mengelak dengan memberikan jawapan yang tidak berguna, seperti "Maaf, saya tidak faham" atau mengeluarkan respons yang tidak selamat kepada pengguna yang membangkitkan topik sensitif.
Untuk memperbaik tingkah laku ini, penyelidik memperhalusi model bahasa asas pada data beranotasi manusia berkualiti tinggi melalui bentuk penalaan halus (SFT) yang diselia, dengan itu meningkatkan kegunaan dan tidak berbahaya model tersebut.

SFT dan IFT sangat berkait rapat. IFT boleh dilihat sebagai subset SFT. Dalam literatur terkini, fasa SFT sering digunakan untuk topik keselamatan dan bukannya untuk topik arahan khusus yang diselesaikan selepas IFT.
Pada masa hadapan, klasifikasi dan penerangan mereka harus mempunyai kes penggunaan yang lebih jelas.
Selain itu, LaMDA Google juga diperhalusi pada set data perbualan beranotasi selamat yang mempunyai anotasi keselamatan berdasarkan satu siri peraturan.
Peraturan ini selalunya dipratentukan dan dibangunkan oleh penyelidik serta merangkumi pelbagai topik, termasuk bahaya, diskriminasi, maklumat salah dan banyak lagi.
Masih banyak isu terbuka yang perlu diterokai berkenaan AI chatbots, seperti:
1 pentingkah dari segi pembelajaran daripada maklum balas manusia? Bolehkah kita mendapatkan prestasi RLHF dalam IFT atau SFT dengan latihan data yang lebih berkualiti?
2. Bagaimanakah keselamatan SFT+RLHF dalam Sparrow berbanding dengan hanya SFT dalam LaMDA?
3. Memandangkan kita sudah mempunyai IFT, SFT, CoT dan RLHF, berapa banyak lagi pra-latihan yang diperlukan? Apakah pertukaran? Manakah model asas terbaik (awam dan swasta)?
4 Kini model ini direka bentuk dengan teliti, di mana penyelidik secara khusus mencari mod kegagalan dan mempengaruhi latihan masa hadapan (termasuk petua dan kaedah) berdasarkan isu yang didedahkan. Bagaimanakah kita boleh mendokumenkan dan mengeluarkan semula kesan kaedah ini secara sistematik?
1. Berbanding dengan data latihan, hanya sebahagian kecil digunakan untuk penalaan halus arahan (beberapa ratus pesanan magnitud).
2. Penalaan halus diselia menggunakan anotasi manusia untuk menjadikan output model lebih selamat dan berguna.
3. Penalaan halus CoT meningkatkan prestasi model pada tugasan pemikiran langkah demi langkah dan menghalang model daripada sentiasa melarikan diri daripada isu sensitif.
Rujukan:
https://huggingface.co/blog/dialog-agents
Atas ialah kandungan terperinci Memfokuskan pada persaingan chatbot antara Google, Meta dan OpenAI, ChatGPT menjadikan ketidakpuasan hati LeCun sebagai tumpuan topik. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



