
 Peranti teknologi
AI
Google sedang mengoptimumkan model resapan Telefon mudah alih Samsung menjalankan Stable Diffusion dan menghasilkan imej dalam masa 12 saat.
Peranti teknologi
AI
Google sedang mengoptimumkan model resapan Telefon mudah alih Samsung menjalankan Stable Diffusion dan menghasilkan imej dalam masa 12 saat.
Google sedang mengoptimumkan model resapan Telefon mudah alih Samsung menjalankan Stable Diffusion dan menghasilkan imej dalam masa 12 saat.

Stable Diffusion terkenal dalam bidang penjanaan imej seperti ChatGPT dalam model besar perbualan. Ia mampu mencipta imej realistik bagi mana-mana teks input yang diberikan dalam berpuluh-puluh saat. Oleh kerana Stable Diffusion mempunyai lebih daripada 1 bilion parameter, dan disebabkan oleh pengkomputeran dan sumber memori yang terhad pada peranti, model ini dijalankan terutamanya dalam awan.
Tanpa reka bentuk dan pelaksanaan yang teliti, menjalankan model ini pada peranti boleh mengakibatkan peningkatan kependaman disebabkan oleh proses penyahnodahan berulang dan penggunaan memori yang berlebihan.
Cara menjalankan Stable Diffusion pada peranti telah membangkitkan minat penyelidikan semua orang Sebelum ini, seorang penyelidik membangunkan aplikasi yang menggunakan Stable Diffusion untuk menjana imej pada iPhone 14 Pro menggunakan lebih kurang 2GiB memori aplikasi.
Apple juga telah membuat beberapa pengoptimuman untuk ini. Mereka boleh menjana imej dengan resolusi 512x512 dalam setengah minit pada iPhone, iPad, Mac dan peranti lain. Qualcomm mengikuti rapat di belakang, menjalankan Stable Diffusion v1.5 pada telefon Android, menjana imej dengan resolusi 512x512 dalam masa kurang daripada 15 saat.
Baru-baru ini, dalam kertas kerja yang diterbitkan oleh Google "Speed As All You Need: On-Device Acceleration of Large Diffusion Models via GPU-Aware Optimizations", mereka melaksanakan dipacu GPU. Stable Diffusion 1.4 dijalankan pada peranti, mencapai prestasi kependaman inferens SOTA (pada Samsung S23 Ultra, ia hanya mengambil masa 11.5 saat untuk menjana imej 512 × 512 melalui 20 lelaran). Tambahan pula, kajian ini tidak khusus untuk satu peranti sebaliknya, ia adalah pendekatan umum yang boleh digunakan untuk menambah baik semua model resapan yang berpotensi.
Penyelidikan ini membuka banyak kemungkinan untuk menjalankan AI generatif secara setempat pada telefon anda tanpa sambungan data atau pelayan awan. Stable Diffusion hanya dikeluarkan pada musim luruh lepas, dan ia sudah boleh dipalamkan ke peranti dan dijalankan hari ini, yang menunjukkan betapa pantas medan ini berkembang.

Alamat kertas: https://arxiv.org/pdf/2304.11267.pdf
Untuk mencapai kelajuan penjanaan ini, Google telah mengemukakan beberapa cadangan pengoptimuman. Mari kita lihat cara Google mengoptimumkan.
Pengenalan kaedah
Penyelidikan ini bertujuan untuk mencadangkan kaedah pengoptimuman untuk meningkatkan kelajuan gambar rajah Vincentian model resapan berskala besar cadangan pengoptimuman juga Sesuai untuk model penyebaran besar yang lain.
Pertama, mari kita lihat komponen utama Resapan Stabil, termasuk: penyusun teks, penjanaan hingar, rangkaian neural denoising dan penyahkod imej (penyahkod imej, seperti yang ditunjukkan dalam Rajah 1 di bawah .
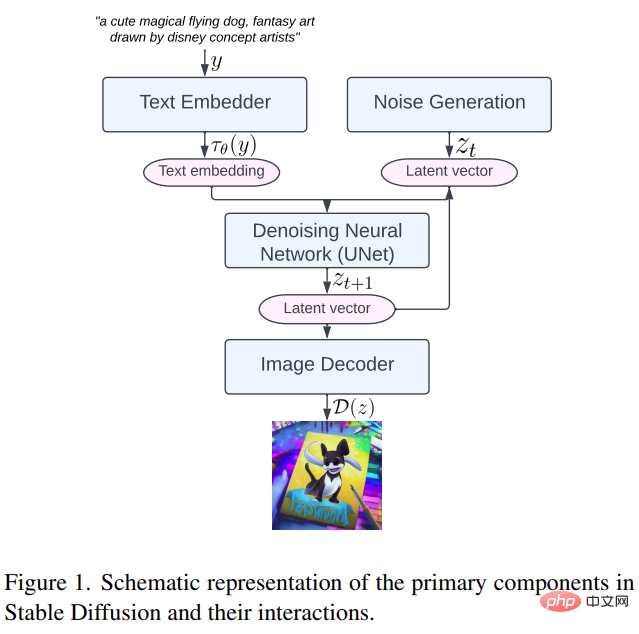
Kemudian mari kita lihat dengan lebih dekat tiga kaedah yang dicadangkan dalam kajian ini
Inti khusus: Norma Kumpulan dan GELU
Kaedah Normalisasi Kumpulan (GN) Prinsip kerjanya ialah membahagikan saluran peta ciri kepada lebih kecil kumpulan dan menormalkan setiap kumpulan secara bebas, sekali gus menjadikan GN kurang bergantung pada saiz kelompok dan lebih sesuai untuk pelbagai saiz kelompok dan seni bina rangkaian . kernel yang boleh melakukan semua operasi ini dalam satu arahan GPU tanpa sebarang Tensor perantaraan
Unit linear ralat Gaussian (GELU) ialah fungsi pengaktifan model yang biasa digunakan yang mengandungi sejumlah besar angka. pengiraan, seperti pendaraban, penambahan, dan fungsi ralat Gaussian Lorek khusus untuk menyepadukan pengiraan berangka ini dan operasi pembahagian dan pendaraban yang disertakan supaya ia boleh dilakukan dalam satu panggilan cat AI untuk meningkatkan kecekapan modul perhatian<.>Pengubah teks-ke-imej dalam Stable Diffusion membantu memodelkan pengagihan bersyarat, yang penting untuk tugas penjanaan teks-ke-imej. Walau bagaimanapun, mekanisme kendiri/perhatian silang menghadapi kesukaran dalam memproses urutan panjang disebabkan oleh kerumitan ingatan dan kerumitan masa. Berdasarkan ini, kajian ini mencadangkan dua kaedah pengoptimuman untuk mengurangkan kesesakan pengiraan. Di satu pihak, untuk mengelakkan daripada melaksanakan keseluruhan pengiraan softmax pada matriks yang besar, kajian ini menggunakan shader GPU untuk mengurangkan operasi pengiraan, yang mengurangkan jejak memori dan keseluruhannya dengan ketara. kependaman tensor perantaraan Kaedah khusus ditunjukkan dalam Rajah 2 di bawah. 
Sebaliknya, penyelidikan ini menggunakan FlashAttention [7], algoritma perhatian tepat yang menyedari IO, yang menjadikan Memori Lebar Jalur tinggi (HBM) memerlukan akses yang lebih sedikit daripada mekanisme perhatian standard, meningkatkan kecekapan keseluruhan.
Konvolusi Winograd
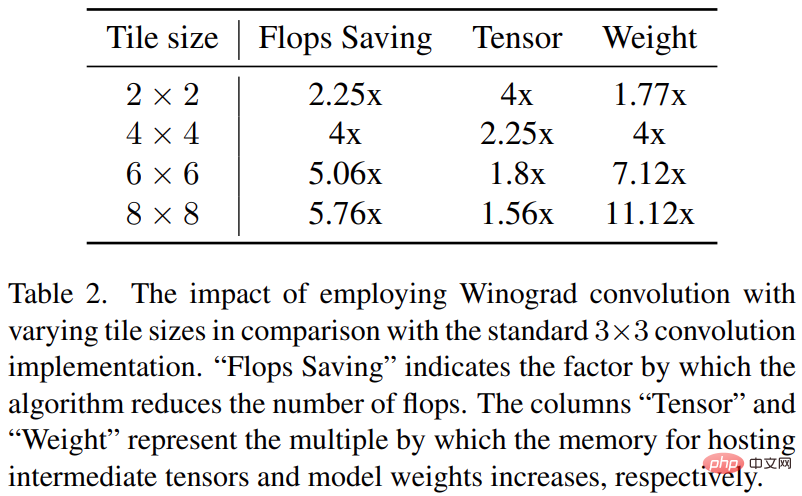
Konvolusi Winograd menukarkan operasi konvolusi kepada siri pendaraban matriks. Kaedah ini boleh mengurangkan banyak operasi pendaraban dan meningkatkan kecekapan pengiraan. Walau bagaimanapun, ini juga meningkatkan penggunaan memori dan ralat berangka, terutamanya apabila menggunakan jubin yang lebih besar.
Tulang belakang Resapan Stabil sangat bergantung pada lapisan konvolusi 3×3, terutamanya dalam penyahkod imej, di mana ia menyumbang 90%. Kajian ini menyediakan analisis mendalam tentang fenomena ini untuk meneroka potensi manfaat menggunakan Winograd dengan saiz jubin yang berbeza pada lilitan kernel 3 × 3. Penyelidikan telah mendapati bahawa saiz jubin 4 × 4 adalah optimum kerana ia memberikan keseimbangan terbaik antara kecekapan pengiraan dan penggunaan memori.
Kajian telah ditanda aras pada pelbagai peranti: Samsung S23 Ultra (Adreno 740) dan iPhone 14 Pro Max (A16). Keputusan penanda aras ditunjukkan dalam Jadual 1 di bawah:
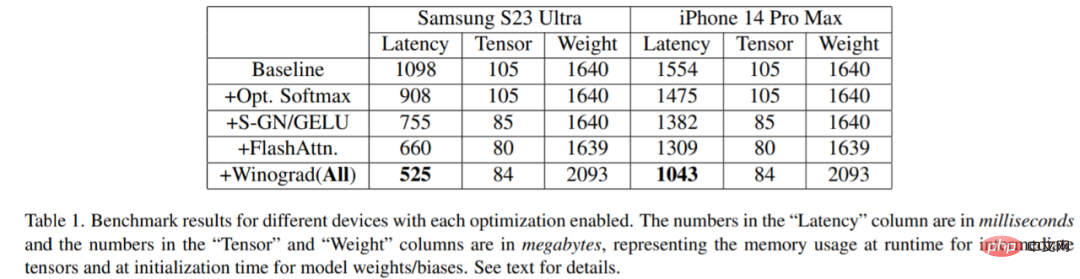
Adalah jelas bahawa kependaman berkurangan secara beransur-ansur apabila setiap pengoptimuman diaktifkan (Boleh difahamkan masa untuk menjana imej semakin berkurangan). Khususnya, berbanding garis dasar: pengurangan kependaman 52.2% pada Samsung S23 Ultra; 32.9% pengurangan kependaman pada iPhone 14 Pro Max. Di samping itu, kajian ini juga menilai kependaman hujung ke hujung Samsung S23 Ultra, menjana imej 512 × 512 piksel dalam 20 langkah lelaran denoising, mencapai keputusan SOTA dalam masa kurang daripada 12 saat.
Peranti kecil boleh menjalankan model AI generatif mereka sendiri. Apakah maksud ini untuk masa hadapan? Kita boleh mengharapkan gelombang.
Atas ialah kandungan terperinci Google sedang mengoptimumkan model resapan Telefon mudah alih Samsung menjalankan Stable Diffusion dan menghasilkan imej dalam masa 12 saat.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Cara Mengulas DeepSeek
Feb 19, 2025 pm 05:42 PM
Cara Mengulas DeepSeek
Feb 19, 2025 pm 05:42 PM
DeepSeek adalah alat pengambilan maklumat yang kuat. .
 Cara Mencari DeepSeek
Feb 19, 2025 pm 05:39 PM
Cara Mencari DeepSeek
Feb 19, 2025 pm 05:39 PM
DeepSeek adalah enjin carian proprietari yang hanya mencari dalam pangkalan data atau sistem tertentu, lebih cepat dan lebih tepat. Apabila menggunakannya, pengguna dinasihatkan untuk membaca dokumen itu, cuba strategi carian yang berbeza, dapatkan bantuan dan maklum balas mengenai pengalaman pengguna untuk memanfaatkan kelebihan mereka.
 Sesame Open Door Exchange Web Pautan Pautan Gerbang Perdagangan Laman Web Pendaftaran Terkini
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange Web Pautan Pautan Gerbang Perdagangan Laman Web Pendaftaran Terkini
Feb 28, 2025 am 11:06 AM
Artikel ini memperkenalkan proses pendaftaran versi web Web Open Exchange (GATE.IO) dan aplikasi Perdagangan Gate secara terperinci. Sama ada pendaftaran web atau pendaftaran aplikasi, anda perlu melawat laman web rasmi atau App Store untuk memuat turun aplikasi tulen, kemudian isi nama pengguna, kata laluan, e -mel, nombor telefon bimbit dan maklumat lain, dan lengkap e -mel atau pengesahan telefon bimbit.
 Mengapa pautan Bybit Exchange tidak dimuat turun dan dipasang secara langsung?
Feb 21, 2025 pm 10:57 PM
Mengapa pautan Bybit Exchange tidak dimuat turun dan dipasang secara langsung?
Feb 21, 2025 pm 10:57 PM
Mengapa pautan Bybit Exchange tidak dimuat turun dan dipasang secara langsung? Bybit adalah pertukaran cryptocurrency yang menyediakan perkhidmatan perdagangan kepada pengguna. Aplikasi mudah alih Exchange tidak boleh dimuat turun terus melalui AppStore atau GooglePlay untuk sebab -sebab berikut: 1. Aplikasi pertukaran cryptocurrency sering tidak memenuhi keperluan ini kerana ia melibatkan perkhidmatan kewangan dan memerlukan peraturan dan standard keselamatan tertentu. 2. Undang -undang dan Peraturan Pematuhan di banyak negara, aktiviti yang berkaitan dengan urus niaga cryptocurrency dikawal atau terhad. Untuk mematuhi peraturan ini, aplikasi bybit hanya boleh digunakan melalui laman web rasmi atau saluran yang diberi kuasa lain
 Platform Perdagangan Pintu Terbuka Sesame Muat turun Versi Mudah Alih Platform Perdagangan Platform Perdagangan Alamat Muat Turun
Feb 28, 2025 am 10:51 AM
Platform Perdagangan Pintu Terbuka Sesame Muat turun Versi Mudah Alih Platform Perdagangan Platform Perdagangan Alamat Muat Turun
Feb 28, 2025 am 10:51 AM
Adalah penting untuk memilih saluran rasmi untuk memuat turun aplikasi dan memastikan keselamatan akaun anda.
 WEB OPEN DOOR EXCHANGE WEB PAGE LOGIN VERSI VERSI UNTUK GATEIO Laman Web Rasmi Pintu Masuk
Mar 04, 2025 pm 11:48 PM
WEB OPEN DOOR EXCHANGE WEB PAGE LOGIN VERSI VERSI UNTUK GATEIO Laman Web Rasmi Pintu Masuk
Mar 04, 2025 pm 11:48 PM
Pengenalan terperinci kepada operasi log masuk versi Web Open Exchange, termasuk langkah masuk dan proses pemulihan kata laluan.
 Portal Log Masuk Versi Rasmi Binance Binance
Feb 21, 2025 pm 05:42 PM
Portal Log Masuk Versi Rasmi Binance Binance
Feb 21, 2025 pm 05:42 PM
Untuk mengakses versi Login Laman Web Binance yang terkini, ikuti langkah mudah ini. Pergi ke laman web rasmi dan klik butang "Login" di sudut kanan atas. Pilih kaedah log masuk anda yang sedia ada. Masukkan nombor mudah alih berdaftar atau e -mel dan kata laluan anda dan pengesahan lengkap (seperti kod pengesahan mudah alih atau Google Authenticator). Selepas pengesahan yang berjaya, anda boleh mengakses Portal Log masuk laman web rasmi Binance.
 Top 10 Disyorkan untuk App Perdagangan Aset Digital Crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 Disyorkan untuk App Perdagangan Aset Digital Crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Artikel ini mencadangkan sepuluh platform perdagangan cryptocurrency teratas yang memberi perhatian kepada, termasuk Binance, OKX, Gate.io, Bitflyer, Kucoin, Bybit, Coinbase Pro, Kraken, BYDFI dan Xbit yang desentralisasi. Platform ini mempunyai kelebihan mereka sendiri dari segi kuantiti mata wang transaksi, jenis urus niaga, keselamatan, pematuhan, dan ciri khas. Memilih platform yang sesuai memerlukan pertimbangan yang komprehensif berdasarkan pengalaman perdagangan anda sendiri, toleransi risiko dan keutamaan pelaburan. Semoga artikel ini membantu anda mencari saman terbaik untuk diri sendiri
