

目录
作者:Andreas Blattmann 、 Robin Rombach 等
在中语频模型应用于真实世界问题并生成了高分辨率的长视频。他们关注两个相关的视频生成问题,一是高分辨率真实世不界的视频生成问题。其在自动驾驶环境中作为模拟引擎具有巨大潜力;二是文本指导视频生成,生成,生于创意内容生成。
为此,研究者提出了视频潜在扩散模型(Video LDM型(Video了计算密集型任务 —— 高分辨率视频生成。 DM许利用大规模图像数据集。
DM预训练空间层,从而将 LDM 图像生成器转换为视频生成器(下图左)。最后以类似方式微调 LDM 的解码器以实现像素空间中的时间一致性(下图右)。>>视频版 Resapan Stabil:英伟达做到最高 1280×2048、最长 4.7 秒。
论文 2:MiniGPT-4:Meningkatkan Pemahaman Bahasa Visi-bahasa
作者:朱德尧、陈军、沈晓倩、李祥、Mohamed H. Elhoseiny
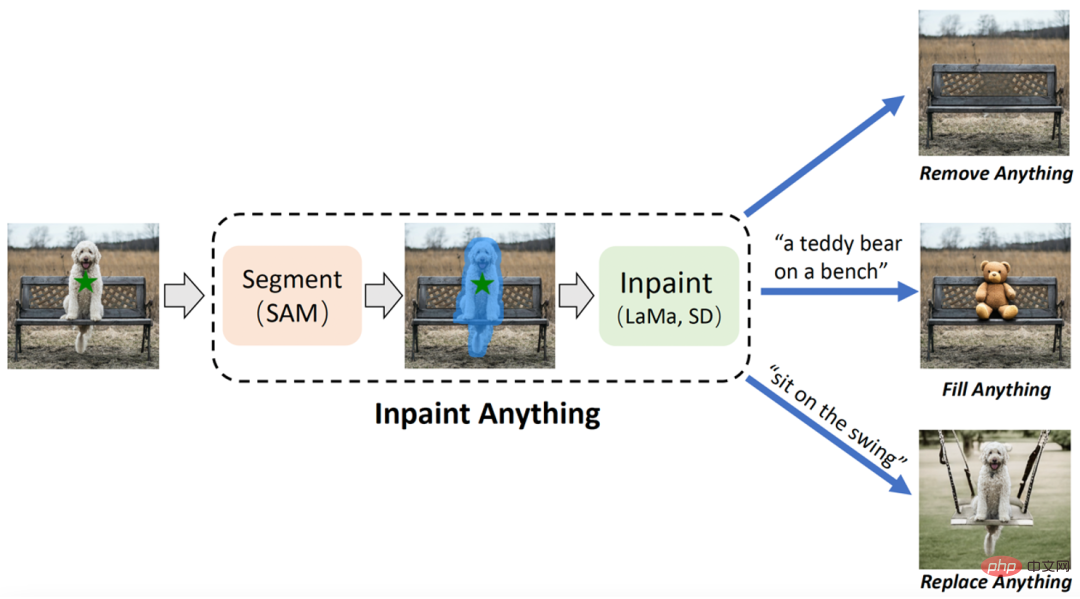
Contoh tunjuk cara: mencipta tapak web daripada lakaran. Cadangan: Hampir 10,000 Bintang dalam 3 hari, pengalaman sempurna keupayaan pengecaman imej GPT-4, lihat MiniGPT-4 Berbual dengan gambar dan bina laman web dengan lakaran. Kertas 3: Perbualan OpenAssistant - Mendemokrasikan Penjajaran Model Bahasa Besar Abstrak: Untuk mendemokrasikan penyelidikan penjajaran berskala besar, penyelidik dari institusi seperti LAION AI (data sumber terbuka yang digunakan oleh Stable diffusion disediakan oleh institusi ini. ) Sejumlah besar input dan maklum balas berasaskan teks dikumpul untuk mencipta OpenAssistant Conversations, set data yang pelbagai dan unik yang direka khusus untuk melatih model bahasa atau aplikasi AI lain. Data data ini ialah korpus perbualan pembantu beranotasi manusia yang dijana manusia yang merangkumi pelbagai topik dan gaya penulisan, yang terdiri daripada 161,443 mesej yang diedarkan di 66,497 pokok perbualan , dalam 35 bahasa berbeza . Korpus itu adalah hasil usaha penyumberan ramai global yang melibatkan lebih daripada 13,500 sukarelawan. Ia adalah alat yang tidak ternilai untuk mana-mana pembangun yang ingin mencipta model arahan SOTA. Dan keseluruhan set data boleh diakses secara bebas oleh sesiapa sahaja. Di samping itu, untuk membuktikan keberkesanan set data OpenAssistant Conversations, kajian itu juga mencadangkan pembantu OpenAssistant berasaskan sembang, yang boleh memahami tugas, berinteraksi dengan sistem pihak ketiga dan secara dinamik mendapatkan semula maklumat. Ini boleh dikatakan model penyelarasan arahan berskala besar sumber terbuka sepenuhnya yang pertama yang dilatih pada data manusia. Hasilnya menunjukkan bahawa balasan OpenAssistant lebih popular daripada GPT-3.5-turbo (ChatGPT). Data Perbualan OpenAssistant dikumpul menggunakan antara muka apl web, termasuk 5 langkah: gesaan, tanda gesaan, tambah mesej balasan Untuk penggerak atau pembantu, menandakan respons dan jawapan pembantu pangkat. Disyorkan: ChatGPT, alternatif sumber terbuka terbesar di dunia. Kertas 4: Inpaint Anything: Segmen Anything Meets Image Inpainting Abstrak: Pasukan penyelidik dari Universiti Sains dan Teknologi China dan Institut Teknologi Timur mencadangkan model "Inpaint Anything" (IA) berdasarkan SAM (Segment Anything Model) . Berbeza daripada model pembaikan imej tradisional, model IA tidak memerlukan operasi terperinci untuk menjana topeng dan menyokong penandaan objek terpilih dengan satu klik IA boleh mengalih keluar segala-galanya (Buang Apa-apa), mengisi segala-galanya (Isi Apa-apa) dan menggantikan segala-galanya Apa-apa sahaja) merangkumi pelbagai senario aplikasi pembaikan imej biasa termasuk penyingkiran sasaran, pengisian sasaran, penggantian latar belakang, dsb. IA mempunyai tiga fungsi utama: (i) Buang Apa-apa: Pengguna hanya perlu mengklik pada objek yang ingin dialih keluar, dan IA akan mengalih keluar objek tanpa meninggalkan kesan, mencapai "magic" Eliminate" yang cekap; (ii) Isi Apa-apa: Pada masa yang sama, pengguna boleh memberitahu IA selanjutnya apa yang mereka mahu isikan objek melalui gesaan teks (Text Prompt), dan IA kemudiannya akan memacu Model AIGC (Kandungan Dijana AI) yang dibenamkan (seperti sebagai Stable Diffusion [2]) menjana objek isi kandungan yang sepadan untuk mencapai "penciptaan kandungan" sesuka hati (iii) Gantikan Apa-apa: Pengguna juga boleh mengklik untuk memilih objek yang perlu dikekalkan dan memberitahu IA menggunakan gesaan teks Jika anda ingin menggantikan latar belakang objek dengan sesuatu, anda boleh menggantikan latar belakang objek dengan kandungan yang ditentukan untuk mencapai "transformasi persekitaran" yang jelas. Rangka kerja keseluruhan IA ditunjukkan dalam rajah di bawah: Cadangan: Tidak perlu tanda halus, klik pada objek untuk mengeluarkan objek Pengisian kandungan dan penggantian pemandangan. Pengarang : Feng Liang, Bichen Wu, et al Alamat kertas: https://arxiv.org/pdf/2210.04150.pdf Disyorkan: Meta/UTAustin mencadangkan model pembahagian kelas terbuka baharu. Kertas 6: Plan4MC: Pembelajaran Pengukuhan Kemahiran dan Perancangan untuk Tugas Minecraft Dunia Terbuka Pengarang: Haoqi Yuan, Chi Zhang, et al Alamat kertas: https://arxiv.org/abs/2303.16563 Gunakan ChatGPT dan pembelajaran pengukuhan untuk bermain Minecraft, Plan4MC mengatasi 24 tugas yang kompleks. Abstrak: Pemeringkat perenggan ialah topik yang sangat penting dan mencabar dalam bidang pencarian maklumat, dan telah menarik banyak minat perhatian dari kalangan akademia dan industri. Keberkesanan model pemeringkatan perenggan boleh meningkatkan kepuasan pengguna enjin carian dan membantu aplikasi berkaitan pencarian maklumat seperti sistem soal jawab, pemahaman bacaan, dsb. Dalam konteks ini, beberapa set data penanda aras seperti MS-MARCO, DuReader_retrieval, dsb. telah dibina untuk menyokong kerja penyelidikan yang berkaitan tentang pengisihan perenggan. Walau bagaimanapun, kebanyakan set data yang biasa digunakan memfokuskan pada adegan bahasa Inggeris Untuk adegan bahasa Cina, set data sedia ada mempunyai had dalam skala data, anotasi pengguna yang terperinci dan penyelesaian kepada masalah contoh negatif palsu. Berdasarkan latar belakang ini, kajian ini membina set data penanda aras kedudukan perenggan bahasa Cina baharu berdasarkan log carian sebenar: T2Ranking. T2Ranking terdiri daripada lebih 300,000 pertanyaan sebenar dan 2 juta perenggan Internet, dan termasuk anotasi perkaitan terperinci 4 peringkat yang disediakan oleh anotor profesional. Data semasa dan beberapa model asas telah diterbitkan di Github, dan kerja penyelidikan yang berkaitan telah diterima oleh SIGIR 2023 sebagai kertas Sumber. Disyorkan: 300,000 pertanyaan sebenar, 2 juta perenggan Internet, set data penanda aras kedudukan perenggan Cina dikeluarkan. Heart of Machine bekerjasama dengan Stesen Radio Mingguan ArXiv yang dimulakan oleh Chu Hang, Luo Ruotian dan Mei Hongyuan, dan memilih artikel ini berdasarkan 7 Kertas Lagi kertas penting minggu ini, termasuk 10 kertas terpilih dalam medan NLP, CV dan ML, dan pengenalan abstrak kepada kertas kerja dalam format audio disediakan seperti berikut: 10 kertas minggu ini Kertas NLP yang dipilih ialah: 1 Sistem Dialog Berasaskan Tugasan oleh HLTPR@RWTH untuk DSTC9 dan DSTC10 (dari Hermann Ney) 2. Meneroka Pertukaran: Model Bahasa Besar Bersatu lwn Model Ditala Halus Tempatan untuk Tugasan NLI Radiologi Sangat Spesifik (dari Wei Liu, Dinggang Shen) 3 Mengenai Kemantapan Analisis Sentimen Berasaskan Aspek: Model Pemikiran Semula, Data dan Latihan (daripada Tat-Seng Chua) 4 Burung kakak tua yang Mencari Burung kakak tua Stochastic : LLM Mudah Diperhalusi dan Sukar Dikesan dengan LLM lain (dari Rachid Guerraoui) 5 Model Bahasa Besar. ( daripada Kai-Wei Chang, Song-Chun Zhu, Jianfeng Gao) 6 MER 2023: Pembelajaran Berbilang Label, Kemantapan Modaliti dan Pembelajaran Separuh Selia. (dari Meng Wang, Erik Cambria, Guoying Zhao) 7 GeneGPT: Mengajar Model Bahasa Besar untuk Menggunakan API Web NCBI (dari Zhiyong Lu) 8 . Tinjauan tentang Ringkasan Teks Bioperubatan dengan Model Bahasa Pra-terlatih (daripada Sophia Ananiadou) 9 . (daripada Sophia Ananiadou ) 10 Model Bahasa Membolehkan Sistem Mudah untuk Menjana Pandangan Berstruktur Data Tasik (daripada Christopher Ré) Ini 10 kertas kerja terpilih minggu ini ialah: 1 NeuralField-LDM: Scene Generation with Hierarchical Latent Diffusion Models (daripada Antonio Torralba) 2. dalam Penjanaan Imej Sedikit Tangkapan . (daripada Shuicheng Yan) 4. Grafik Hiper Situasi Pembelajaran untuk Menjawab Soalan Video. (dari Mubarak Shah) 5. Penjanaan Video Melangkaui Satu Klip. (dari Ming-Hsuan Yang) 6. Penyelesaian Berpusatkan Data kepada Dehazing Tidak Homogen melalui Pengubah Penglihatan. (dari Huan Liu) 7. Aliran Optik Neuromorfik dan Pelaksanaan Masa Nyata dengan Kamera Acara. (daripada Luca Benini, Davide Scaramuzza) 8. Penyusupan Tempatan Berpandukan Bahasa untuk Pengambilan Imej Interaktif. (daripada Lei Zhang) 9. LipsFormer: Memperkenalkan Kesinambungan Lipschitz kepada Pengubah Penglihatan. (daripada Lei Zhang) 10. UVA: Ke arah Avatar Volumetrik Bersatu untuk Sintesis Pandangan, rendering Pose, Geometri dan Pengeditan Tekstur. (dari Dacheng Tao) 本周 10 篇 ML 精选论文是: 1. Merapatkan Teori dan Amalan RL dengan Horizon Berkesan. (daripada Stuart Russell) 2. Ke arah model lengkung kuasa turbin angin dipacu data yang telus dan mantap. (daripada Klaus-Robert Müller) 3. Pembelajaran Berterusan Dunia Terbuka: Menyatukan Pengesanan Kebaharuan dan Pembelajaran Berterusan. (daripada Bing Liu) 4. Pembelajaran dalam ruang terpendam meningkatkan ketepatan ramalan pengendali saraf dalam. (daripada George Em Karniadakis) 5. Decouple Graph Neural Networks: Latih Berbilang GNN Mudah Serentak Daripada Satu. (daripada Xuelong Li) 6. Pengitlakan dan Had Ralat Anggaran untuk Rangkaian Neural berasaskan Model. (daripada Yonina C. Eldar) 7. RAFT: Penalaan Halus Berperingkat Ganjaran untuk Penjajaran Model Asas Generatif. (daripada Tong Zhang) 8. Kaedah Pengoptimuman Konsensus Adaptif untuk GAN. (daripada Pawan Kumar) 9. Kadar pembelajaran dinamik berasaskan sudut untuk keturunan kecerunan. (dari Pawan Kumar) 10. AGNN: Rangkaian Neural Teratur Graf Bergantian untuk Mengurangkan Kelicinan Terlalu Banyak. (dari Wenzhong Guo)

Disyorkan: 
Stesen Radio Mingguan ArXiv
Atas ialah kandungan terperinci MiniGPT-4 melihat gambar dan sembang, dan juga boleh melakar dan membina tapak web versi video Stable Diffusion ada di sini. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



