
 Peranti teknologi
AI
DAMO-YOLO: rangka kerja pengesanan sasaran yang cekap yang mengambil kira kelajuan dan ketepatan
Peranti teknologi
AI
DAMO-YOLO: rangka kerja pengesanan sasaran yang cekap yang mengambil kira kelajuan dan ketepatan
DAMO-YOLO: rangka kerja pengesanan sasaran yang cekap yang mengambil kira kelajuan dan ketepatan


1 Pengenalan kepada pengesanan sasaran
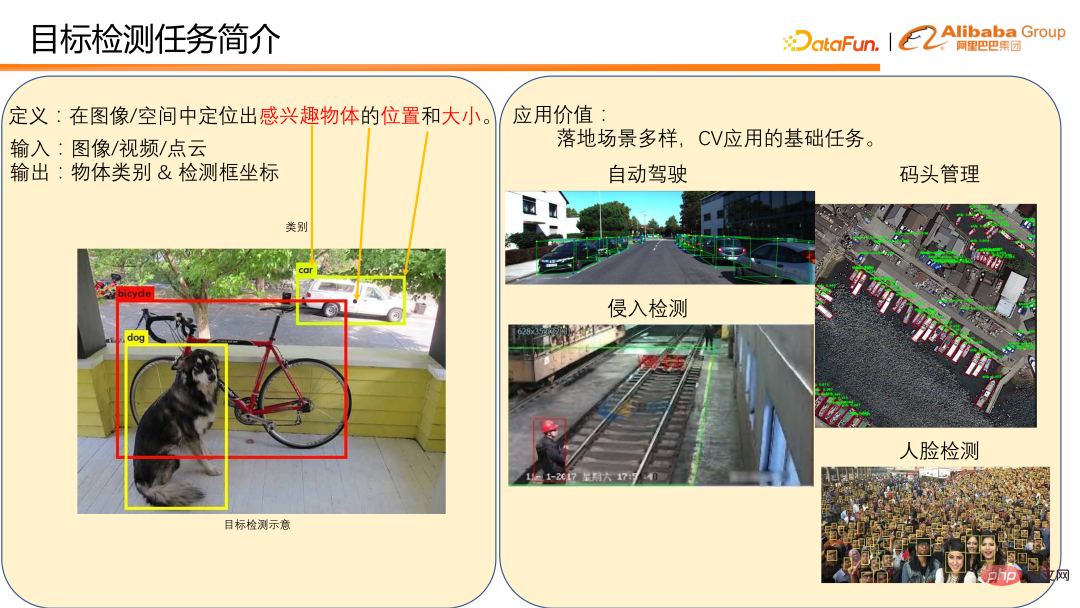
Takrifan pengesanan sasaran adalah untuk mencari objek yang menarik dalam imej/ lokasi dan saiz ruang.
Secara amnya, masukkan imej, video atau awan titik dan keluarkan kategori objek dan koordinat bingkai pengesanan. Gambar di sebelah kiri bawah adalah contoh pengesanan objek pada imej. Terdapat banyak senario aplikasi untuk pengesanan sasaran, seperti pengesanan kenderaan dan pejalan kaki dalam senario pemanduan autonomi, dan pengesanan berlabuh dalam pengurusan dok. Kedua-dua ini adalah aplikasi langsung kepada pengesanan objek. Pengesanan sasaran juga merupakan tugas asas untuk banyak aplikasi CV, seperti pengesanan pencerobohan dan pengecaman muka yang digunakan di kilang ini memerlukan pengesanan pejalan kaki dan pengesanan muka sebagai asas untuk menyelesaikan tugas pengesanan. Dapat dilihat bahawa pengesanan sasaran mempunyai banyak aplikasi penting dalam kehidupan seharian, dan kedudukannya dalam pelaksanaan CV juga sangat penting, jadi ini adalah bidang yang mempunyai persaingan yang sengit.
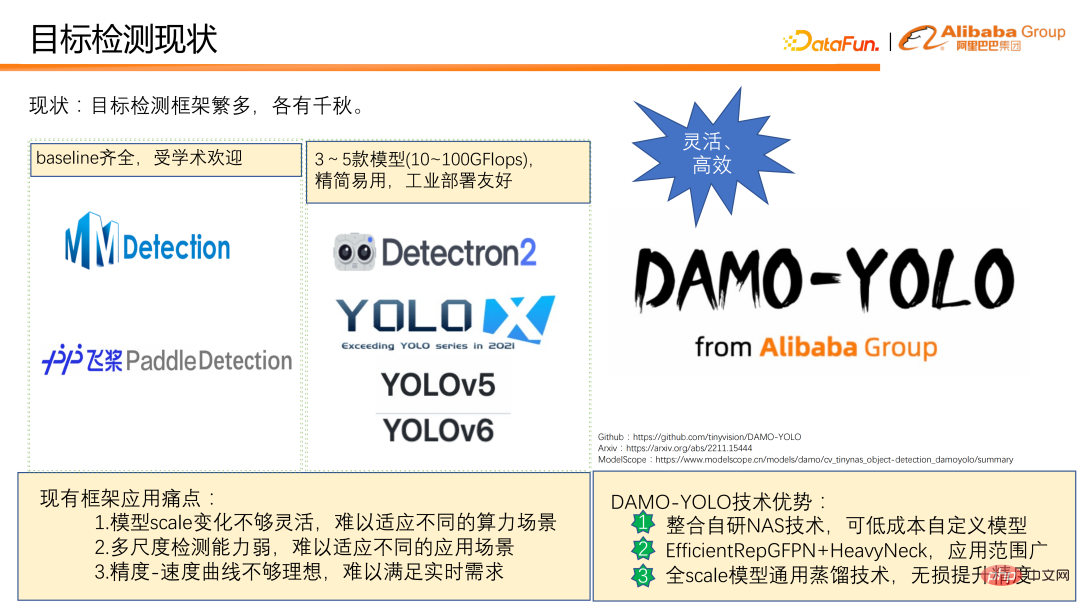
Pada masa ini terdapat banyak rangka kerja pengesanan sasaran dengan ciri tersendiri. Berdasarkan pengalaman terkumpul kami dalam penggunaan sebenar, kami mendapati bahawa rangka kerja pengesanan semasa masih mempunyai titik kesakitan berikut dalam aplikasi praktikal:
① Perubahan skala model yang tidak mencukupi Fleksibel dan sukar untuk menyesuaikan diri dengan senario kuasa pengkomputeran yang berbeza. Sebagai contoh, rangka kerja pengesanan siri YOLO secara amnya hanya menyediakan jumlah pengiraan 3-5 model, antara sedozen hingga lebih daripada seratus Flop, menjadikannya sukar untuk menampung senario kuasa pengkomputeran yang berbeza.
② Keupayaan pengesanan berbilang skala adalah lemah, terutamanya prestasi pengesanan objek kecil adalah lemah, yang menjadikan senario aplikasi model sangat terhad. Sebagai contoh, dalam senario pengesanan dron, keputusan mereka selalunya tidak ideal.
③ Keluk kelajuan/ketepatan tidak cukup ideal, dan kelajuan serta ketepatan sukar untuk serasi pada masa yang sama.
Sebagai tindak balas kepada situasi di atas, kami mereka bentuk dan sumber terbuka DAMO-YOLO. DAMO-YOLO tertumpu terutamanya pada pelaksanaan perindustrian. Berbanding dengan rangka kerja pengesanan sasaran lain, ia mempunyai tiga kelebihan teknikal yang jelas:
① Ia menyepadukan teknologi NAS yang dibangunkan sendiri dan boleh menyesuaikan model pada kos rendah, membolehkan pengguna menggunakan cip sepenuhnya. kuasa pengkomputeran.
② Menggabungkan paradigma reka bentuk model RepGFPN yang Cekap dan HeavyNeck boleh meningkatkan keupayaan pengesanan berbilang skala model dan meluaskan skop aplikasi model.
③ Mencadangkan teknologi penyulingan universal berskala penuh yang tanpa rasa sakit boleh meningkatkan ketepatan model kecil, sederhana dan besar.
Di bawah ini kami akan menganalisis lagi DAMO-YOLO daripada nilai 3 kelebihan teknikal.
2. Nilai teknikal DAMO-YOLO
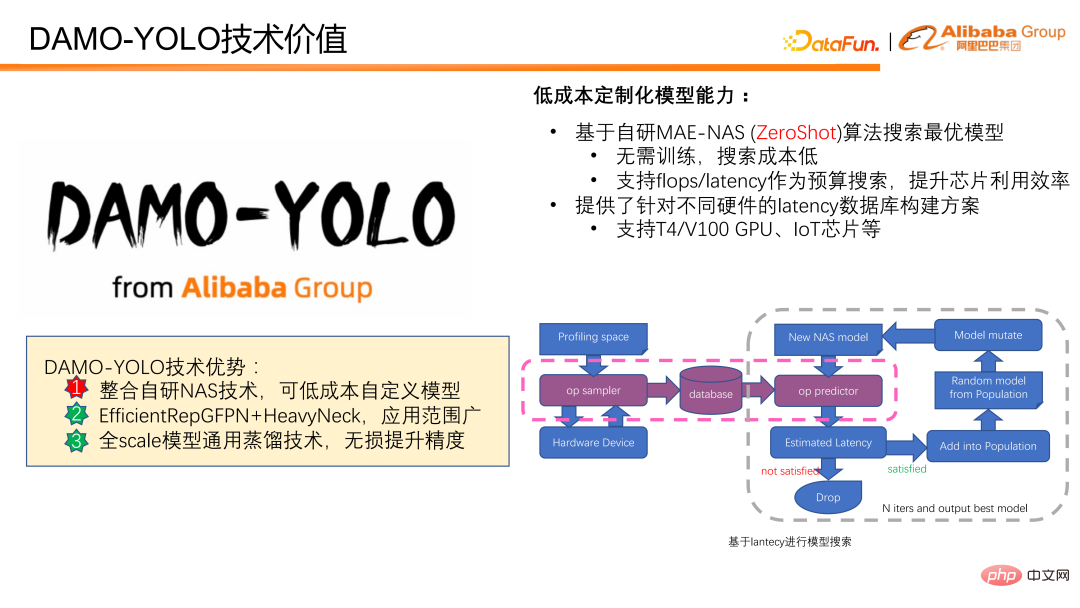
DAMO-YOLO merealisasikan penyesuaian model kos rendah berdasarkan sendiri Algoritma MAE-NAS yang dibangunkan. Model boleh disesuaikan pada kos rendah berdasarkan kependaman atau belanjawan FLOPS. Ia tidak memerlukan latihan model atau penyertaan data sebenar untuk menyediakan skor penilaian model, dan kos carian model adalah rendah. Menyasarkan FLOPS boleh menggunakan sepenuhnya kuasa pengkomputeran cip. Mencari dengan kelewatan kerana belanjawan sangat sesuai untuk pelbagai senario yang mempunyai keperluan ketat mengenai kelewatan. Kami juga menyediakan penyelesaian pembinaan pangkalan data yang menyokong senario kelewatan perkakasan yang berbeza, menjadikannya lebih mudah untuk semua orang mencari menggunakan kelewatan sebagai sasaran.
Rajah berikut menunjukkan cara menggunakan kelewatan masa untuk carian model. Mula-mula, sampel cip sasaran atau peranti sasaran untuk mendapatkan kelewatan semua pengendali yang mungkin, dan kemudian meramalkan kelewatan model berdasarkan data kelewatan. Jika magnitud model yang diramalkan memenuhi sasaran pratetap, model akan memasukkan kemas kini model seterusnya dan pengiraan markah. Akhirnya, selepas pengemaskinian berulang, model optimum yang memenuhi kekangan kelewatan diperolehi.
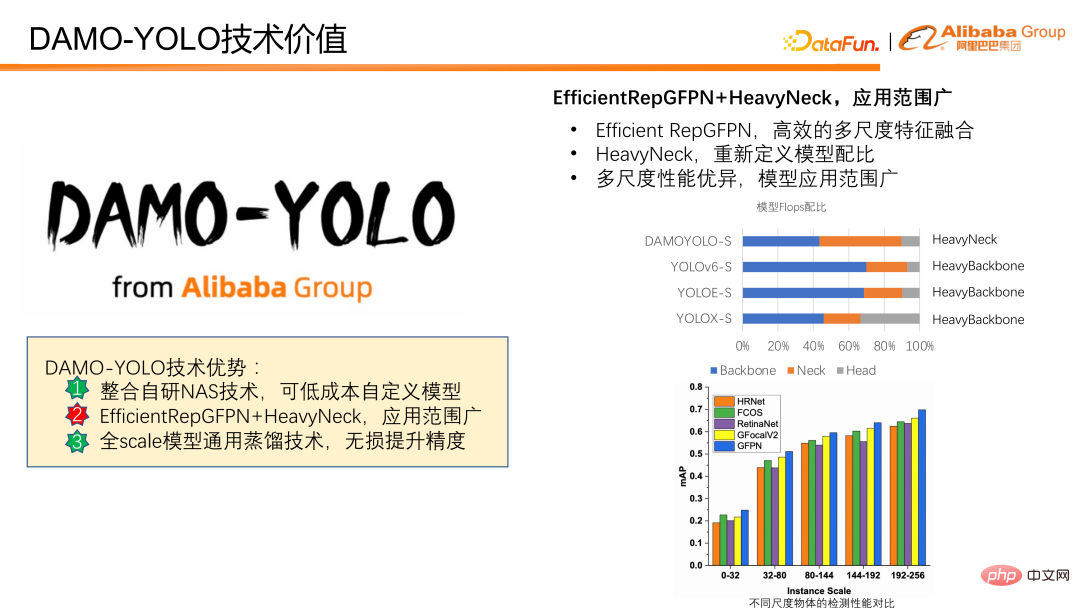
Seterusnya, kami akan memperkenalkan cara untuk meningkatkan keupayaan pengesanan berbilang skala model . DAMO-YOLO menggabungkan RepGFPN Cekap yang dicadangkan dan HeavyNeck yang inovatif, yang meningkatkan keupayaan pengesanan pelbagai skala dengan ketara. RepGFPN yang cekap boleh melengkapkan gabungan ciri berbilang skala dengan cekap. Paradigma HeavyNeck merujuk kepada memperuntukkan sejumlah besar FLOPS model kepada lapisan gabungan ciri. Seperti jadual nisbah FLOPS model. Mengambil DAMO-YOLO-S sebagai contoh, jumlah pengiraan leher merangkumi hampir separuh daripada keseluruhan model Ini berbeza dengan ketara daripada model lain yang meletakkan jumlah pengiraan pada tulang belakang.
Akhir sekali, model penyulingan diperkenalkan. Penyulingan merujuk kepada pemindahan pengetahuan model besar kepada model kecil, meningkatkan prestasi model kecil tanpa menanggung beban penaakulan. Penyulingan model ialah alat yang berkuasa untuk meningkatkan kecekapan model pengesanan, tetapi penerokaan dalam akademik dan industri kebanyakannya terhad kepada model besar, dan terdapat kekurangan penyelesaian penyulingan untuk model kecil. DAMO-YOLO menyediakan satu set penyulingan yang biasa kepada model semua skala. Penyelesaian ini bukan sahaja boleh mencapai peningkatan yang ketara dalam model skala penuh, tetapi juga mempunyai kekukuhan yang tinggi Ia juga menggunakan pemberat dinamik tanpa perlu melaraskan parameter, dan penyulingan boleh dilengkapkan dengan skrip satu klik. Di samping itu, skim ini juga teguh kepada penyulingan heterogen, yang sangat penting untuk model tersuai kos rendah yang dinyatakan di atas. Dalam model NAS, persamaan struktur antara model kecil dan model besar yang diperoleh dengan mencari tidak dijamin. Sekiranya terdapat penyulingan heterogen yang teguh, kelebihan NAS dan penyulingan boleh dieksploitasi sepenuhnya. Rajah di bawah menunjukkan prestasi kami pada penyulingan Ia boleh dilihat bahawa tidak kira pada model T, model S atau model M, terdapat peningkatan yang stabil selepas penyulingan.

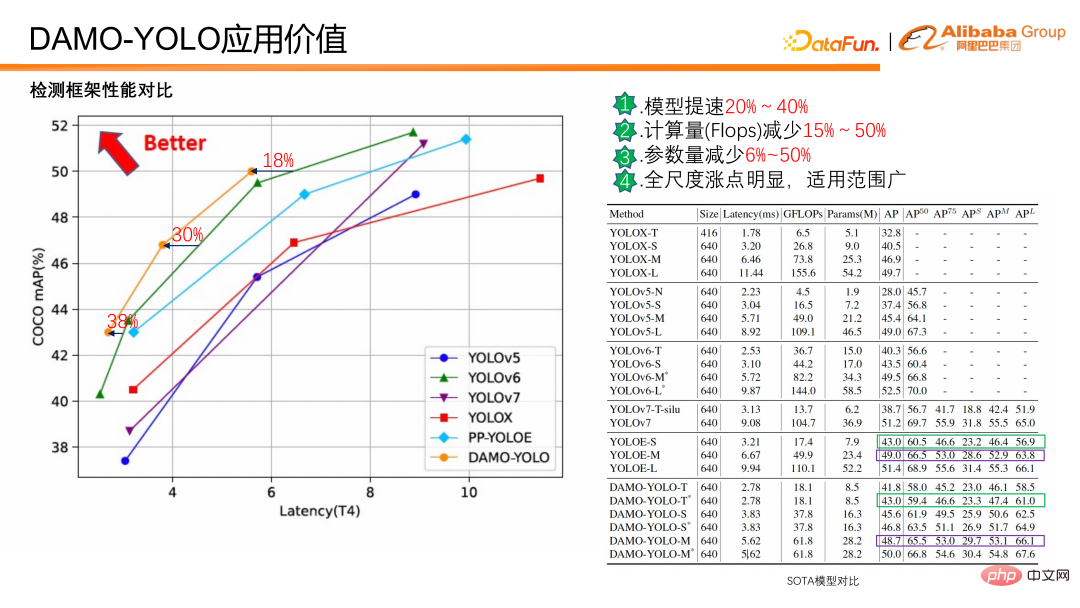
DAMO-YOLO Berbanding dengan SOTA semasa, model ini 20%-40% lebih pantas dengan ketepatan yang sama, jumlah pengiraan dikurangkan sebanyak 15%- 50%, dan parameter dikurangkan sebanyak 6% -50%, keseluruhan skala mempunyai titik peningkatan yang jelas, dan ia mempunyai pelbagai aplikasi. Di samping itu, terdapat penambahbaikan yang jelas pada kedua-dua objek kecil dan besar.
Daripada perbandingan data di atas, kita dapat melihat bahawa DAMO-YOLO adalah pantas, mempunyai Flop yang rendah, dan mempunyai rangkaian aplikasi yang luas; juga menyesuaikan model untuk kuasa pengkomputeran dan meningkatkan kecekapan Penggunaan cip.
Model yang berkaitan telah dilancarkan pada ModelScope dan latihan boleh dilakukan melalui konfigurasi tiga hingga lima baris kod Anda boleh mengalami penggunaan anda mempunyai sebarang pertanyaan semasa penggunaan atau Komen dialu-alukan di ruangan komen.
Seterusnya, fokus pada 3 kelebihan teknikal DAMO-YOLO dan perkenalkan prinsip di sebalik ia, untuk membantu semua orang memahami dan menggunakan DAMO-YOLO dengan lebih baik.
4 Pengenalan kepada prinsip DAMO-YOLO Pertama, teknologi utama keupayaan penyesuaian model kos rendah, MAE-NAS. , diperkenalkan. Idea asasnya ialah menganggap rangkaian dalam sebagai sistem maklumat dengan ruang keadaan berterusan dan mencari entropi yang boleh memaksimumkan sistem maklumat.
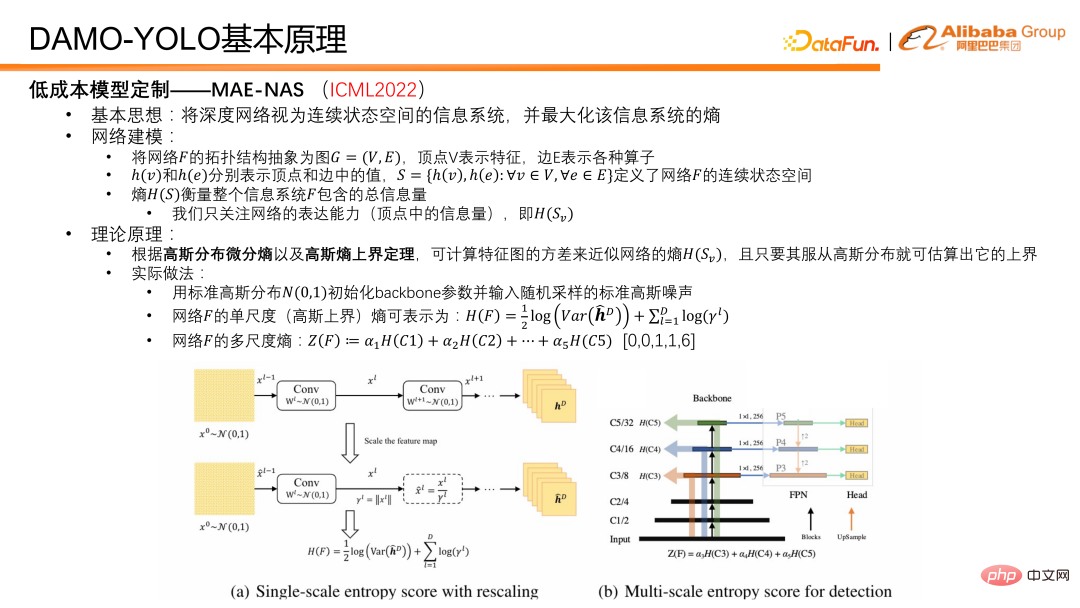
Idea pemodelan rangkaian adalah seperti berikut: abstrak struktur topologi rangkaian F ke dalam graf G=(V,E), di mana puncak V mewakili ciri dan tepi E mewakili pelbagai operator . Atas dasar ini, h(v) dan h(e) boleh digunakan untuk mewakili nilai masing-masing dalam bucu dan tepi, dan set S sedemikian boleh dijana, yang mentakrifkan ruang keadaan berterusan rangkaian, dan entropi daripada set S boleh mewakili Jumlah keseluruhan maklumat dalam rangkaian atau sistem maklumat F. Jumlah maklumat bucu mengukur keupayaan ekspresif rangkaian, dan jumlah maklumat tepi juga merupakan entropi tepi, yang mengukur kerumitan rangkaian. Untuk tugas pengesanan objek DAMO-YOLO, kebimbangan utama kami adalah untuk memaksimumkan keupayaan ekspresif rangkaian. Dalam aplikasi praktikal, hanya entropi ciri rangkaian yang berkenaan. Menurut entropi pembezaan taburan Gaussian dan teorem sempadan atas entropi Gaussian, kami menggunakan varians peta ciri untuk menganggarkan sempadan atas entropi ciri rangkaian.
Dalam operasi sebenar, kami mula-mula memulakan pemberat tulang belakang rangkaian dengan taburan Gaussian standard dan menggunakan imej hingar Gaussian standard sebagai input. Selepas bunyi Gaussian dimasukkan ke dalam rangkaian untuk hantaran ke hadapan, beberapa ciri boleh diperolehi. Kemudian entropi skala tunggal, iaitu, varians setiap ciri skala dikira, dan kemudian entropi berskala berbilang diperoleh dengan pemberat. Dalam proses pemberat, pekali priori digunakan untuk mengimbangi keupayaan ekspresif ciri pada skala yang berbeza Parameter ini biasanya ditetapkan kepada [0,0,1,1,6]. Sebab mengapa ini ditetapkan adalah seperti berikut: Dalam model pengesanan, ciri umum dibahagikan kepada lima peringkat, iaitu, lima resolusi berbeza, dari 1/2 hingga 1/32. Untuk mengekalkan penggunaan ciri yang cekap, kami hanya menggunakan tiga peringkat terakhir. Jadi sebenarnya, dua peringkat pertama tidak mengambil bahagian dalam ramalan model, jadi mereka adalah 0 dan 0. Untuk tiga yang lain, kami telah menjalankan eksperimen yang meluas dan mendapati bahawa 1, 1, dan 6 adalah nisbah model yang lebih baik.
Berdasarkan prinsip teras di atas, kita boleh menggunakan entropi pelbagai skala bagi rangkaian sebagai proksi prestasi, Menggunakan algoritma penulenan sebagai rangka kerja asas untuk mencari struktur rangkaian, ini membentuk MAE-NAS yang lengkap. NAS mempunyai banyak kelebihan. Pertama sekali, ia menyokong berbilang sekatan belanjawan inferens, dan boleh menggunakan FLOPS, jumlah parameter, kependaman dan nombor lapisan rangkaian untuk menjalankan carian model. Kedua, ia juga menyokong sejumlah besar variasi dalam struktur rangkaian berbutir halus. Oleh kerana algoritma evolusi digunakan di sini untuk melakukan carian rangkaian, lebih banyak variasi struktur rangkaian disokong, lebih tinggi tahap penyesuaian dan fleksibiliti semasa carian. Di samping itu, untuk memudahkan pengguna menyesuaikan proses carian, kami menyediakan tutorial rasmi. Akhir sekali, dan yang paling penting, MAE-NAS adalah sifar pendek, iaitu cariannya tidak memerlukan sebarang penyertaan data sebenar dan tidak memerlukan sebarang latihan model sebenar. Ia mencari berpuluh-puluh minit pada CPU dan boleh menghasilkan hasil rangkaian yang optimum di bawah kekangan semasa.
Dalam DAMO-YOLO, kami menggunakan MAE-NAS untuk mencari rangkaian tulang belakang model T/S/M dengan kelewatan yang berbeza sebagai sasaran carian; infrastruktur dibungkus, model kecil menggunakan ResStyle, dan model besar menggunakan CSPStyle.
Seperti yang dapat dilihat daripada jadual di bawah, CSP-Darknet ialah rangkaian yang direka secara manual menggunakan struktur CSP, dan juga telah mencapai beberapa keputusan dalam YOLO v 5 /V6 Pelbagai aplikasi. Kami menggunakan MAE-NAS untuk menjana struktur asas, dan selepas membungkusnya dengan CSP, kami mendapati model itu telah dipertingkatkan dengan ketara dalam kelajuan dan ketepatan. Di samping itu, pada model kecil, anda boleh melihat borang MAE-ResNet, yang mempunyai ketepatan yang lebih tinggi. Terdapat kelebihan yang jelas dalam menggunakan struktur CPS pada model besar, yang boleh mencapai 48.7.

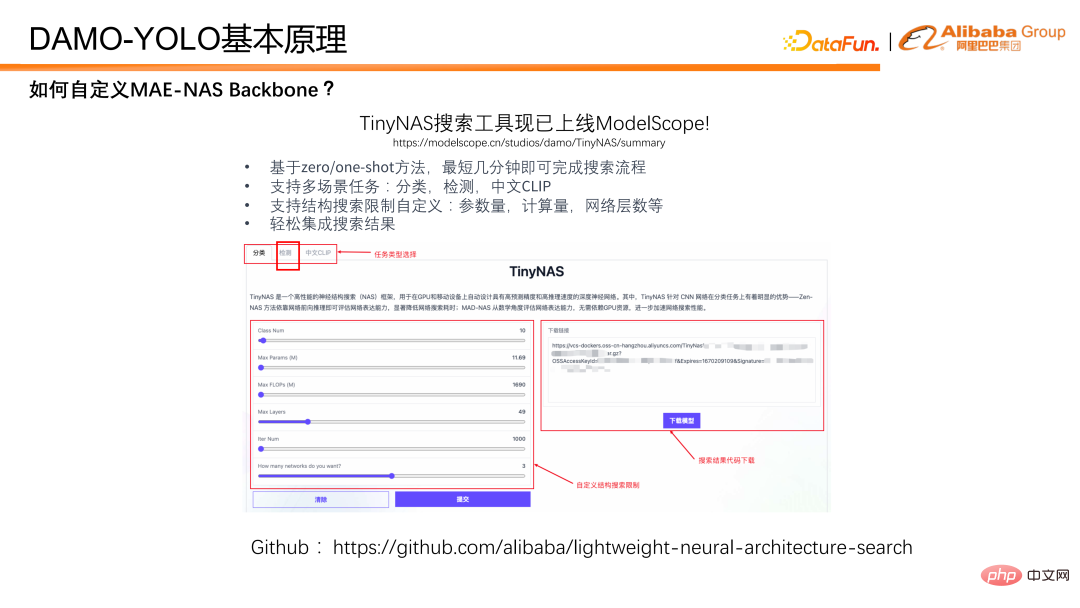
Bagaimana cara menggunakan MAE-NAS untuk carian tulang belakang? Di sini kami memperkenalkan kotak alat TinyNAS kami, yang sudah dalam talian dalam ModelScope Anda boleh mendapatkan model yang diingini dengan mudah melalui konfigurasi visual pada halaman web. Pada masa yang sama, MAE-NAS juga telah menjadi sumber terbuka di github. Pelajar yang berminat boleh mencari model yang dikehendaki dengan lebih bebas berdasarkan kod sumber terbuka.
Seterusnya, kami akan memperkenalkan cara DAMO-YOLO meningkatkan keupayaan pengesanan berbilang skala Ia bergantung pada gabungan ciri skala yang berbeza pada rangkaian. Dalam rangkaian pengesanan sebelumnya, kedalaman ciri pada skala berbeza sangat berbeza. Sebagai contoh, ciri resolusi besar digunakan untuk mengesan objek kecil, tetapi kedalaman cirinya adalah cetek, yang akan menjejaskan prestasi pengesanan objek kecil.
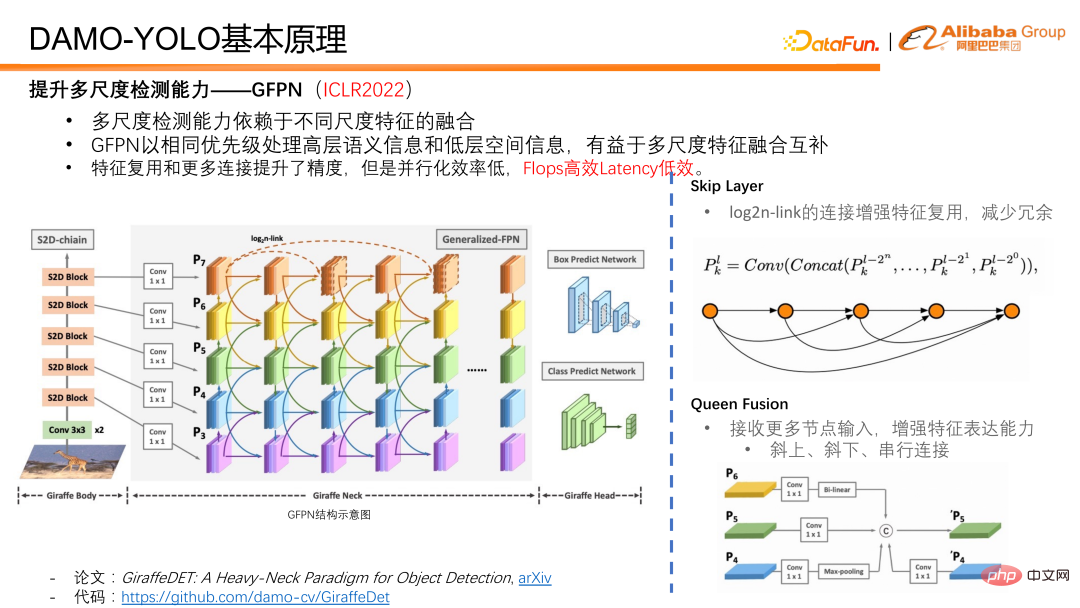
Karya yang kami cadangkan di ICLR2022 - GFPN, memproses maklumat semantik peringkat tinggi dan maklumat spatial peringkat rendah dengan keutamaan yang sama, dan sangat mesra kepada gabungan dan pelengkap ciri berbilang skala. Dalam reka bentuk GFPN, kami mula-mula memperkenalkan lapisan langkau untuk membolehkan GFPN direka bentuk dengan lebih mendalam. Kami menggunakan pautan log2n untuk menggunakan semula ciri dan mengurangkan lebihan.
Ratu gabungan adalah untuk meningkatkan gabungan interaktif ciri skala yang berbeza dan ciri kedalaman yang berbeza. Selain menerima ciri skala berbeza secara menyerong di atas dan di bawahnya, setiap nod dalam gabungan Queen juga menerima ciri skala berbeza pada kedalaman ciri yang sama, yang meningkatkan jumlah maklumat semasa gabungan ciri dan mempromosikan maklumat berbilang skala pada kedalaman yang sama. gabungan pada.
Walaupun penggunaan semula ciri GFPN dan reka bentuk sambungan unik membawa peningkatan dalam ketepatan model. Memandangkan lapisan langkau kami dan gabungan Queen kami membawa operasi gabungan pada nod ciri berbilang skala, serta operasi pensampelan naik dan pensampelan rendah, ia sangat meningkatkan inferens yang memakan masa dan menyukarkan untuk memenuhi keperluan pelaksanaan industri. Jadi sebenarnya, GFPN adalah FLOPS yang cekap, tetapi melambatkan struktur yang tidak cekap. Memandangkan beberapa kecacatan GFPN, kami menganalisis dan mengaitkan sebabnya seperti berikut:
① Pertama sekali, ciri skala yang berbeza sebenarnya berkongsi bilangan saluran , dan terdapat banyak Ciri adalah berlebihan dan konfigurasi rangkaian tidak cukup fleksibel.
② Kedua, terdapat sambungan pensampelan naik dan pensampelan bawah dalam ciri Queen, dan penggunaan masa pengendali pensampelan naik dan turun dipertingkatkan dengan ketara.
③ Ketiga, apabila nod disusun, sambungan bersiri pada kedalaman ciri yang sama mengurangkan kecekapan selari GPU, dan setiap timbunan membawa Pertumbuhan laluan bersiri telah ketara.
Untuk menangani masalah ini, kami telah membuat pengoptimuman yang sepadan dan mencadangkan RepGFPN yang Cekap.
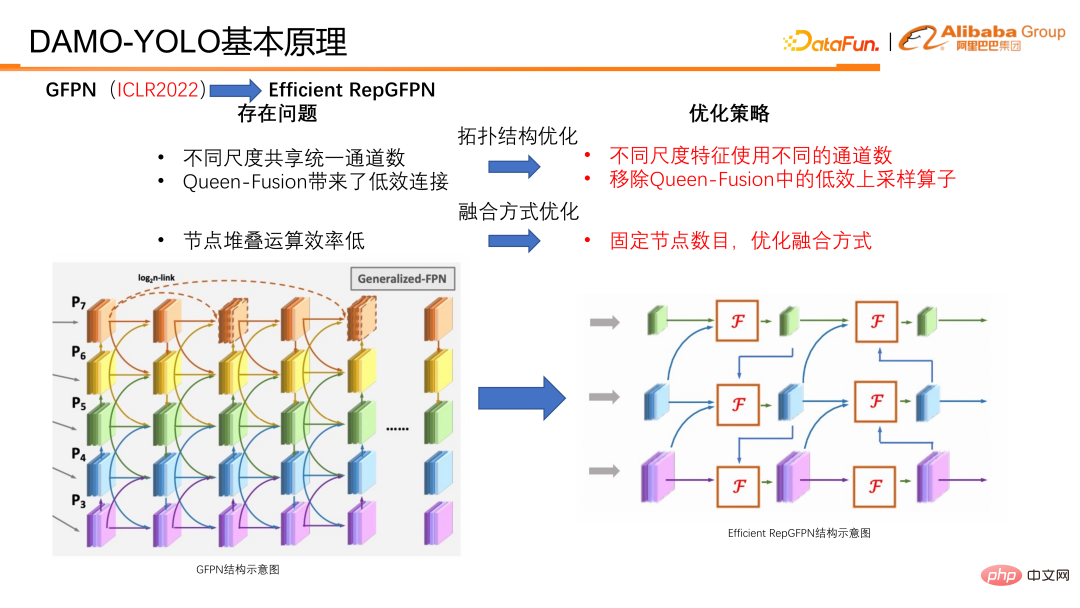
Semasa pengoptimuman, ia terbahagi kepada dua kategori, satu ialah pengoptimuman topologi struktur , kategori lain ialah pengoptimuman kaedah gabungan.
Dari segi pengoptimuman topologi, Efficient RepGFPN menggunakan nombor saluran yang berbeza untuk ciri skala yang berbeza, supaya ia boleh mengawal ciri peringkat tinggi dan ciri peringkat rendah secara fleksibel di bawah kekangan pengiraan ringan kebolehan ekspresif. Dalam kes FLOPS dan anggaran kelewatan, konfigurasi fleksibel boleh mencapai ketepatan dan kecekapan kelajuan yang terbaik. Di samping itu, kami juga menjalankan analisis kecekapan pada sambungan dalam gabungan ratu dan mendapati bahawa pengendali pensampelan naik mempunyai beban yang besar, tetapi peningkatan ketepatan adalah kecil, yang jauh lebih rendah daripada faedah pengendali pensampelan turun. Jadi kami mengalih keluar sambungan upsampling dalam gabungan ratu. Seperti yang boleh dilihat dalam jadual, kutu menyerong ke bawah sebenarnya adalah pensampelan atas, dan kutu menyerong ke atas adalah pensampelan ke bawah represent Tujuannya adalah untuk menambah sampel ciri resolusi kecil, menyambungkannya kepada ciri resolusi besar, dan menggabungkannya menjadi ciri resolusi besar. Kesimpulan terakhir ialah pengendali pensampelan turun mempunyai pulangan yang lebih tinggi, manakala pengendali pensampelan naik mempunyai pulangan yang sangat rendah, jadi kami mengalih keluar sambungan pensampelan dalam ciri Ratu untuk meningkatkan kecekapan keseluruhan GFPN.
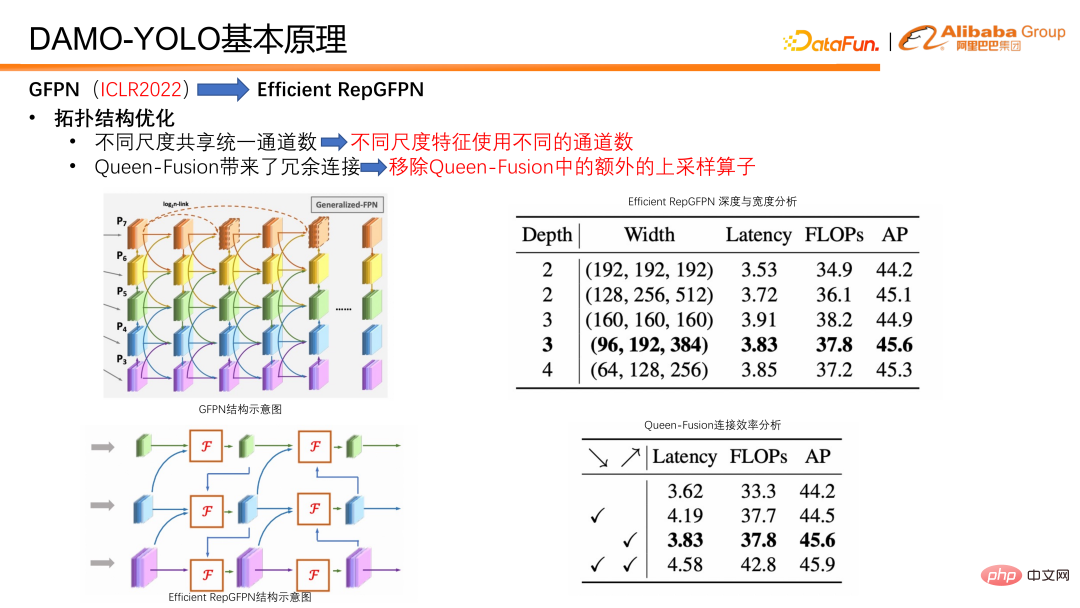
Kami juga telah membuat beberapa pengoptimuman dari segi kaedah penyepaduan. Pertama, bilangan nod gabungan ditetapkan, supaya hanya dua gabungan dilakukan dalam setiap model, bukannya terus menyusun gabungan untuk mencipta GFPN yang lebih mendalam seperti sebelumnya. Ini mengelakkan kecekapan selari yang disebabkan oleh pertumbuhan berterusan pautan bersiri. Selain itu, kami direka khas blok gabungan untuk gabungan ciri. Dalam fusion block, kami memperkenalkan teknologi seperti mekanisme parameterisasi berat dan sambungan pengagregatan berbilang lapisan untuk meningkatkan lagi kesan gabungan.
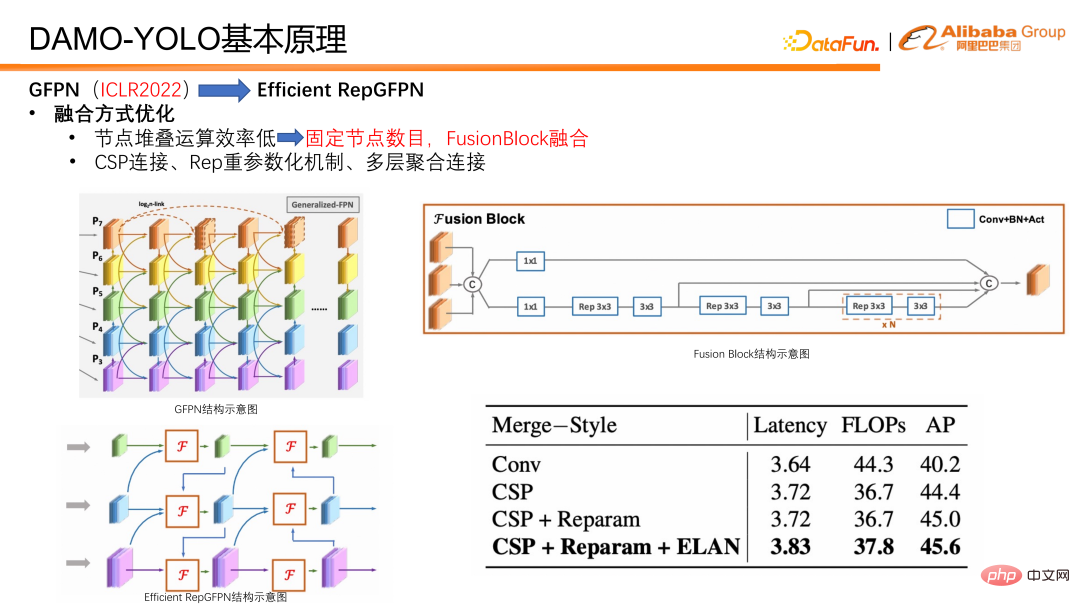
Selain Leher, Kepala kepala pengesan juga merupakan bahagian penting dalam pengesanan model. Ia mengambil keluaran ciri oleh Neck sebagai input dan bertanggungjawab untuk mengeluarkan keputusan regresi dan klasifikasi. Kami mereka bentuk eksperimen untuk mengesahkan pertukaran antara RepGFPN Cekap dan Ketua, dan mendapati bahawa apabila kependaman model dikawal ketat, lebih mendalam RepGFPN Cekap, lebih baik. Oleh itu, dalam reka bentuk rangkaian, amaun pengiraan terutamanya diperuntukkan kepada RepGFPN Cekap, manakala hanya satu lapisan unjuran linear dikhaskan di bahagian Ketua untuk tugas klasifikasi dan regresi. Kami memanggil Ketua yang hanya mempunyai satu lapisan klasifikasi dan satu lapisan regresi lapisan pemetaan bukan linear ZeroHead. Corak reka bentuk yang memperuntukkan beban pengiraan ini terutamanya kepada Leher dipanggil paradigma HeavyNeck.
Struktur model akhir DAMO-YOLO ditunjukkan dalam rajah di bawah.
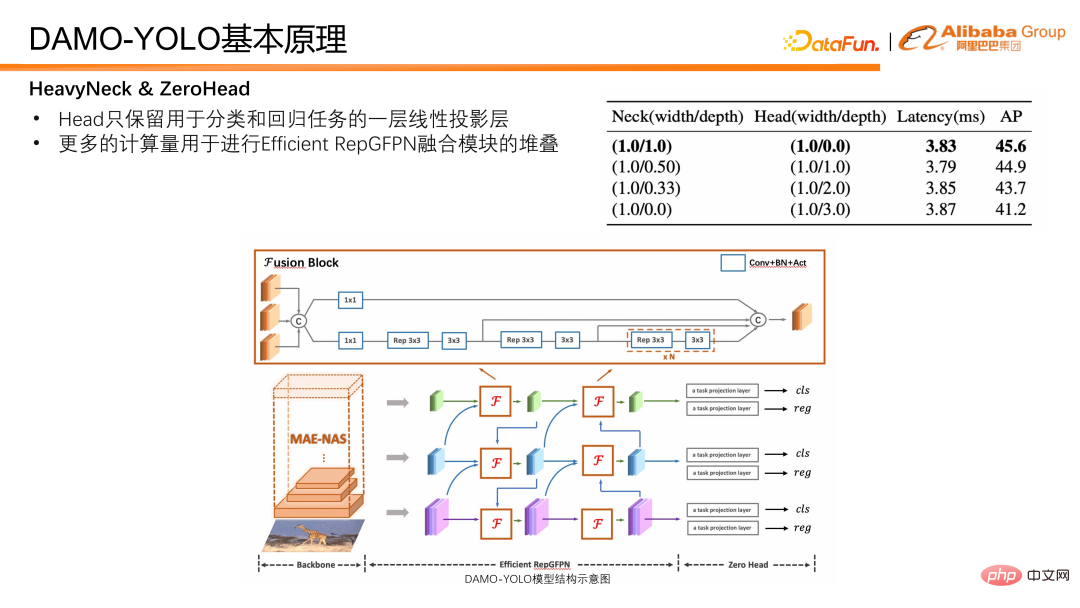
Di atas ialah beberapa pendapat tentang dalam reka bentuk model. Akhir sekali, mari kita perkenalkan skim penyulingan.
DAMO-YOLO mengambil ciri keluaran RepGFPN Cekap untuk penyulingan. Ciri pelajar akan terlebih dahulu melalui modul penjajaran untuk menjajarkan nombor salurannya kepada guru. Untuk menghapuskan bias model itu sendiri, ciri pelajar dan guru akan dinormalisasi oleh BN yang tidak berat sebelah, dan kemudian pengiraan kehilangan penyulingan akan dilakukan. Semasa penyulingan, kami mendapati bahawa kehilangan yang berlebihan akan menghalang penumpuan cawangan klasifikasi pelajar itu sendiri. Jadi kami memilih untuk menggunakan berat dinamik yang mereput dengan latihan. Daripada keputusan eksperimen, berat penyulingan seragam dinamik adalah teguh kepada model T/S/M.
Rantai penyulingan DAMO-YOLO ialah, L penyulingan M, M penyulingan S. Perlu dinyatakan bahawa apabila M menyuling S, M menggunakan pembungkusan CSP, manakala S menggunakan pembungkusan Res Secara struktur, M dan S adalah isomer. Walau bagaimanapun, apabila menggunakan skim penyulingan DAMO-YOLO, M menyuling S, terdapat juga peningkatan sebanyak 1.2 mata selepas penyulingan, menunjukkan bahawa skim penyulingan kami juga teguh kepada isomerisme. Jadi secara ringkasnya, skim penyulingan DAMO-YOLO mempunyai parameter percuma, menyokong rangkaian penuh model, dan heterogen dan teguh.
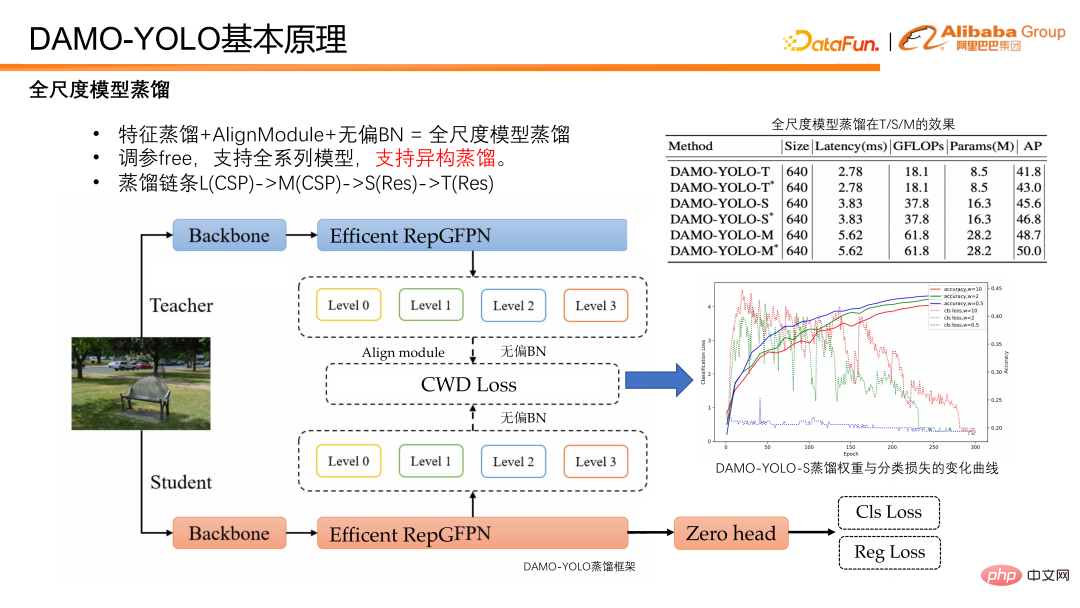
Akhir sekali mari kita ringkaskan DAMO-YOLO . DAMO-YOLO menggabungkan teknologi MAE-NAS untuk membolehkan penyesuaian model kos rendah dan menggunakan sepenuhnya kuasa pengkomputeran cip Digabungkan dengan paradigma RepGFPN dan HeavyNeck yang Cekap, ia meningkatkan keupayaan pengesanan berbilang skala dan mempunyai pelbagai aplikasi model. skim penyulingan skala, ia boleh meningkatkan lagi kecekapan model.

Model DAMO-YOLO telah dilancarkan pada ModelScope dan sumber terbuka pada github. Semua orang dialu-alukan untuk mencubanya .
5. Pelan Pembangunan DAMO-YOLO
DAMO-YOLO baru sahaja dikeluarkan, dan masih banyak lagi. perkara yang perlu diperbaiki dan diperbaiki tempat Pengoptimuman. Kami merancang untuk menambah baik alatan penggunaan dan menyokong ModelScope dalam jangka pendek. Selain itu, lebih banyak contoh aplikasi akan disediakan berdasarkan penyelesaian juara pertandingan dalam kumpulan, seperti pengesanan sasaran kecil UAV dan pengesanan sasaran berputar. Ia juga merancang untuk melancarkan lebih banyak model contoh, termasuk model Nano untuk peranti dan model Besar untuk awan. Akhir kata, saya berharap semua orang akan memberi perhatian dan memberikan maklum balas yang positif.

Atas ialah kandungan terperinci DAMO-YOLO: rangka kerja pengesanan sasaran yang cekap yang mengambil kira kelajuan dan ketepatan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 CLIP-BEVFormer: Selia secara eksplisit struktur BEVFormer untuk meningkatkan prestasi pengesanan ekor panjang
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Selia secara eksplisit struktur BEVFormer untuk meningkatkan prestasi pengesanan ekor panjang
Mar 26, 2024 pm 12:41 PM
Ditulis di atas & pemahaman peribadi penulis: Pada masa ini, dalam keseluruhan sistem pemanduan autonomi, modul persepsi memainkan peranan penting Hanya selepas kenderaan pemanduan autonomi yang memandu di jalan raya memperoleh keputusan persepsi yang tepat melalui modul persepsi boleh Peraturan hiliran dan. modul kawalan dalam sistem pemanduan autonomi membuat pertimbangan dan keputusan tingkah laku yang tepat pada masanya dan betul. Pada masa ini, kereta dengan fungsi pemanduan autonomi biasanya dilengkapi dengan pelbagai penderia maklumat data termasuk penderia kamera pandangan sekeliling, penderia lidar dan penderia radar gelombang milimeter untuk mengumpul maklumat dalam modaliti yang berbeza untuk mencapai tugas persepsi yang tepat. Algoritma persepsi BEV berdasarkan penglihatan tulen digemari oleh industri kerana kos perkakasannya yang rendah dan penggunaan mudah, dan hasil keluarannya boleh digunakan dengan mudah untuk pelbagai tugas hiliran.
 Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Cabaran biasa yang dihadapi oleh algoritma pembelajaran mesin dalam C++ termasuk pengurusan memori, multi-threading, pengoptimuman prestasi dan kebolehselenggaraan. Penyelesaian termasuk menggunakan penunjuk pintar, perpustakaan benang moden, arahan SIMD dan perpustakaan pihak ketiga, serta mengikuti garis panduan gaya pengekodan dan menggunakan alat automasi. Kes praktikal menunjukkan cara menggunakan perpustakaan Eigen untuk melaksanakan algoritma regresi linear, mengurus memori dengan berkesan dan menggunakan operasi matriks berprestasi tinggi.
 Terokai prinsip asas dan pemilihan algoritma bagi fungsi isihan C++
Apr 02, 2024 pm 05:36 PM
Terokai prinsip asas dan pemilihan algoritma bagi fungsi isihan C++
Apr 02, 2024 pm 05:36 PM
Lapisan bawah fungsi C++ sort menggunakan isihan gabungan, kerumitannya ialah O(nlogn), dan menyediakan pilihan algoritma pengisihan yang berbeza, termasuk isihan pantas, isihan timbunan dan isihan stabil.
 Bolehkah kecerdasan buatan meramalkan jenayah? Terokai keupayaan CrimeGPT
Mar 22, 2024 pm 10:10 PM
Bolehkah kecerdasan buatan meramalkan jenayah? Terokai keupayaan CrimeGPT
Mar 22, 2024 pm 10:10 PM
Konvergensi kecerdasan buatan (AI) dan penguatkuasaan undang-undang membuka kemungkinan baharu untuk pencegahan dan pengesanan jenayah. Keupayaan ramalan kecerdasan buatan digunakan secara meluas dalam sistem seperti CrimeGPT (Teknologi Ramalan Jenayah) untuk meramal aktiviti jenayah. Artikel ini meneroka potensi kecerdasan buatan dalam ramalan jenayah, aplikasi semasanya, cabaran yang dihadapinya dan kemungkinan implikasi etika teknologi tersebut. Kecerdasan Buatan dan Ramalan Jenayah: Asas CrimeGPT menggunakan algoritma pembelajaran mesin untuk menganalisis set data yang besar, mengenal pasti corak yang boleh meramalkan di mana dan bila jenayah mungkin berlaku. Set data ini termasuk statistik jenayah sejarah, maklumat demografi, penunjuk ekonomi, corak cuaca dan banyak lagi. Dengan mengenal pasti trend yang mungkin terlepas oleh penganalisis manusia, kecerdasan buatan boleh memperkasakan agensi penguatkuasaan undang-undang
 Algoritma pengesanan yang dipertingkatkan: untuk pengesanan sasaran dalam imej penderiaan jauh optik resolusi tinggi
Jun 06, 2024 pm 12:33 PM
Algoritma pengesanan yang dipertingkatkan: untuk pengesanan sasaran dalam imej penderiaan jauh optik resolusi tinggi
Jun 06, 2024 pm 12:33 PM
01Garis prospek Pada masa ini, sukar untuk mencapai keseimbangan yang sesuai antara kecekapan pengesanan dan hasil pengesanan. Kami telah membangunkan algoritma YOLOv5 yang dipertingkatkan untuk pengesanan sasaran dalam imej penderiaan jauh optik resolusi tinggi, menggunakan piramid ciri berbilang lapisan, strategi kepala pengesanan berbilang dan modul perhatian hibrid untuk meningkatkan kesan rangkaian pengesanan sasaran dalam imej penderiaan jauh optik. Menurut set data SIMD, peta algoritma baharu adalah 2.2% lebih baik daripada YOLOv5 dan 8.48% lebih baik daripada YOLOX, mencapai keseimbangan yang lebih baik antara hasil pengesanan dan kelajuan. 02 Latar Belakang & Motivasi Dengan perkembangan pesat teknologi penderiaan jauh, imej penderiaan jauh optik resolusi tinggi telah digunakan untuk menggambarkan banyak objek di permukaan bumi, termasuk pesawat, kereta, bangunan, dll. Pengesanan objek dalam tafsiran imej penderiaan jauh
 Amalkan dan fikirkan platform model besar berbilang modal Jiuzhang Yunji DataCanvas
Oct 20, 2023 am 08:45 AM
Amalkan dan fikirkan platform model besar berbilang modal Jiuzhang Yunji DataCanvas
Oct 20, 2023 am 08:45 AM
1. Perkembangan sejarah model besar pelbagai mod Gambar di atas adalah bengkel kecerdasan buatan pertama yang diadakan di Kolej Dartmouth di Amerika Syarikat pada tahun 1956. Persidangan ini juga dianggap telah memulakan pembangunan kecerdasan buatan perintis logik simbolik (kecuali ahli neurobiologi Peter Milner di tengah-tengah barisan hadapan). Walau bagaimanapun, teori logik simbolik ini tidak dapat direalisasikan untuk masa yang lama, malah memulakan musim sejuk AI pertama pada 1980-an dan 1990-an. Sehingga pelaksanaan model bahasa besar baru-baru ini, kami mendapati bahawa rangkaian saraf benar-benar membawa pemikiran logik ini. Kerja ahli neurobiologi Peter Milner memberi inspirasi kepada pembangunan rangkaian saraf tiruan yang seterusnya, dan atas sebab inilah dia dijemput untuk mengambil bahagian. dalam projek ini.
 Aplikasi algoritma dalam pembinaan 58 platform potret
May 09, 2024 am 09:01 AM
Aplikasi algoritma dalam pembinaan 58 platform potret
May 09, 2024 am 09:01 AM
1. Latar Belakang Pembinaan 58 Portrait Platform Pertama sekali, saya ingin berkongsi dengan anda latar belakang pembinaan 58 Portrait Platform. 1. Pemikiran tradisional platform pemprofilan tradisional tidak lagi mencukupi Membina platform pemprofilan pengguna bergantung pada keupayaan pemodelan gudang data untuk menyepadukan data daripada pelbagai barisan perniagaan untuk membina potret pengguna yang tepat untuk memahami tingkah laku, minat pengguna dan keperluan, dan menyediakan keupayaan sampingan, akhirnya, ia juga perlu mempunyai keupayaan platform data untuk menyimpan, bertanya dan berkongsi data profil pengguna dan menyediakan perkhidmatan profil dengan cekap. Perbezaan utama antara platform pemprofilan perniagaan binaan sendiri dan platform pemprofilan pejabat pertengahan ialah platform pemprofilan binaan sendiri menyediakan satu barisan perniagaan dan boleh disesuaikan atas permintaan platform pertengahan pejabat berkhidmat berbilang barisan perniagaan, mempunyai kompleks pemodelan, dan menyediakan lebih banyak keupayaan umum. 2.58 Potret pengguna latar belakang pembinaan potret di platform tengah 58
 Tambah SOTA dalam masa nyata dan meroket! FastOcc: Inferens yang lebih pantas dan algoritma Occ mesra penggunaan sudah tersedia!
Mar 14, 2024 pm 11:50 PM
Tambah SOTA dalam masa nyata dan meroket! FastOcc: Inferens yang lebih pantas dan algoritma Occ mesra penggunaan sudah tersedia!
Mar 14, 2024 pm 11:50 PM
Ditulis di atas & Pemahaman peribadi penulis ialah dalam sistem pemanduan autonomi, tugas persepsi adalah komponen penting dalam keseluruhan sistem pemanduan autonomi. Matlamat utama tugas persepsi adalah untuk membolehkan kenderaan autonomi memahami dan melihat elemen persekitaran sekeliling, seperti kenderaan yang memandu di jalan raya, pejalan kaki di tepi jalan, halangan yang dihadapi semasa memandu, tanda lalu lintas di jalan raya, dan sebagainya, dengan itu membantu hiliran. modul Membuat keputusan dan tindakan yang betul dan munasabah. Kenderaan dengan keupayaan pemanduan autonomi biasanya dilengkapi dengan pelbagai jenis penderia pengumpulan maklumat, seperti penderia kamera pandangan sekeliling, penderia lidar, penderia radar gelombang milimeter, dsb., untuk memastikan kenderaan autonomi itu dapat melihat dan memahami persekitaran sekeliling dengan tepat. elemen , membolehkan kenderaan autonomi membuat keputusan yang betul semasa pemanduan autonomi. kepala
