
 pembangunan bahagian belakang
Tutorial Python
Bagaimana untuk melaksanakan timbunan terbina dalam python
pembangunan bahagian belakang
Tutorial Python
Bagaimana untuk melaksanakan timbunan terbina dalam python
Bagaimana untuk melaksanakan timbunan terbina dalam python

1 Pengenalan
Timbunan, juga dikenali sebagai baris gilir keutamaan, ialah pokok binari yang lengkap dan nilai setiap nod induk hanya akan kurang daripada atau sama dengan Semua nod anak (nilai). Ia menggunakan tatasusunan untuk melaksanakan: pengiraan bermula dari sifar, dan untuk semua k , terdapat heap[k] . Untuk tujuan perbandingan, unsur yang tidak wujud dianggap sebagai tidak terhingga. Ciri timbunan yang paling menarik ialah unsur terkecil sentiasa berada di nod akar: timbunan[0].
Timbunan Python secara amnya ialah timbunan minimum, yang berbeza daripada kandungan dalam kebanyakan buku teks kiri ke kanan, yang berbeza daripada kandungan dalam banyak buku teks Senarai sangat serupa, jadi untuk membuat timbunan, anda boleh menggunakan senarai untuk memulakannya sebagai [], atau anda boleh menukar senarai menjadi timbunan melalui fungsi heapify(. ). Berikut adalah operasi yang berkaitan pada timbunan dalam python Ia boleh dilihat daripada ini bahawa python sememangnya menganggap timbunan sebagai senarai.
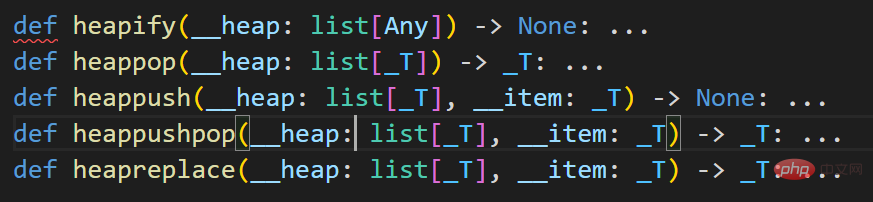
2. Operasi berkaitan timbunan
heapq.heappush(timbunan, item)
Tambah nilai item ke timbunan dan simpannya Ketidakbolehubahan timbunan. Ia secara automatik akan menukar elemen berkaitan mengikut ciri timbunan minimum dalam Python supaya elemen nod akar timbunan tidak pernah lebih besar daripada unsur nod anak.
Data asal ialah timbunan
1 2 3 4 5 6 7 |
|
Proses operasi adalah seperti berikut:
1 keadaan awal
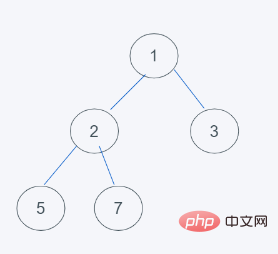
2. Selepas menambah 2 elemen
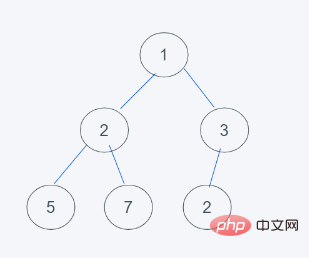
3 timbunan, ia ditukar dengan 3
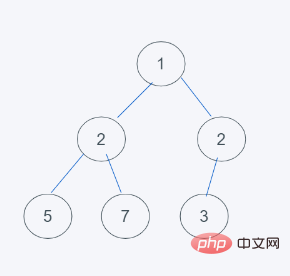
4 Selaras dengan ciri timbunan minimum, pertukaran itu berakhir, jadi hasilnya adalah [1, 2, 3, 5. , 7, 3]
Asal Terdapat data yang tiada dalam timbunan
1 2 3 4 5 6 7 |
|
Ia boleh dilihat apabila melakukan operasi tolak, jika elemen itu tidak dalam timbunan, elemen ditambah secara lalai mengikut kaedah tambah senarai
heapq.heappop( heap)
Memunculkan dan mengembalikan elemen terkecil timbunan, mengekalkan timbunan tidak berubah . Jika timbunan kosong, buang IndexError. Menggunakan heap[0] , adalah mungkin untuk mengakses elemen terkecil sahaja tanpa memunculkannya.
Data asal ialah timbunan
1 2 3 4 5 6 7 |
|
Proses operasi adalah seperti berikut:
Keadaan awal
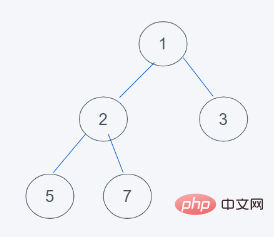
2 Elemen atas timbunan dipadamkan dan elemen terakhir dialihkan ke bahagian atas timbunan
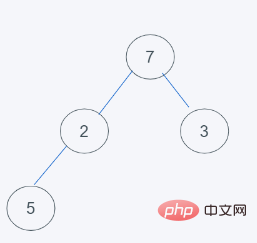
3. Elemen ditukar mengikut ciri timbunan minimum python, kerana 7>2, tukar 7 dan 2
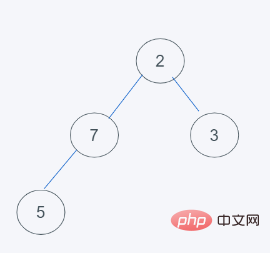
4 timbunan minimum. Sejak 7>5, tukar 7 dan 5
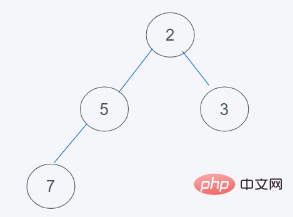
5 ]
Data asal bukan timbunan
1 2 3 4 5 6 7 |
|
Proses operasi adalah seperti berikut:
1 nyatakan jelas tidak menepati sifat timbunan
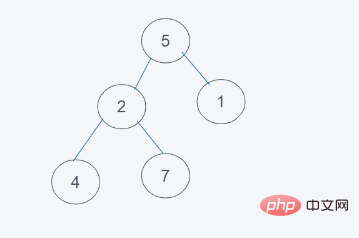
2 Keluarkan paling banyak Untuk elemen di atas (elemen pertama), susun semula elemen yang tinggal dalam timbunan
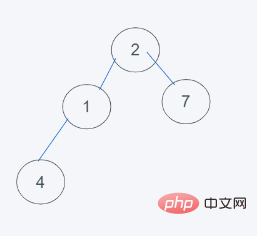
3 Mengikut ciri timbunan minimum python, 2>1 menukar 2 dengan 1
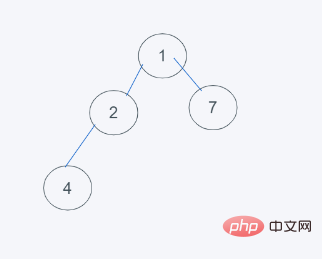
4 keperluan timbunan, hasilnya ialah [1, 2, 7, 4]
heapq.heappushpop(timbunan, item)
Masukkan item ke dalam timbunan, kemudian keluarkan dan kembalikan unsur terkecil timbunan. Operasi gabungan ini berjalan dengan lebih cekap daripada memanggil heappush() dahulu dan kemudian heappop(). Perlu diingatkan bahawa elemen yang timbul mesti berada di bahagian atas atau hujung timbunan Maksudnya, apabila elemen dimasukkan dan elemen terkecil dibandingkan, elemen atas timbunan sentiasa dibandingkan adalah lebih besar daripada atau sama dengan elemen atas timbunan, Timbunan tidak akan berubah Apabila elemen yang dimasukkan lebih kecil daripada elemen atas timbunan, timbunan akan diproses mengikut ciri timbunan minimum timbunan ular sawa.
Data asal ialah timbunan
1 2 3 4 5 6 7 8 9 |
|
Proses operasi adalah seperti berikut
1. Keadaan awal
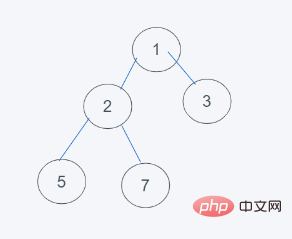
2. Sisipkan elemen 2
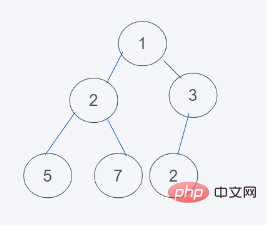
3.删除最小元素,刚好是堆顶元素1,并使用末尾元素2代替
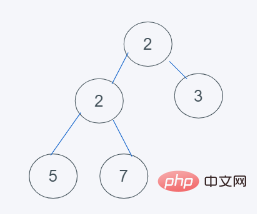
4.符合要求,即结果为[2, 2, 3, 5, 7]
原有数据不是堆
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
对于插入元素6的操作过程如下
1.初始状态
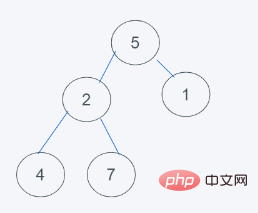
2.插入元素6之后
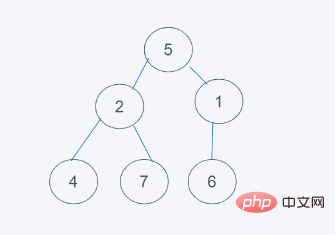
3.发现元素6大于堆顶元素5,弹出堆顶元素5,由堆尾元素6替换
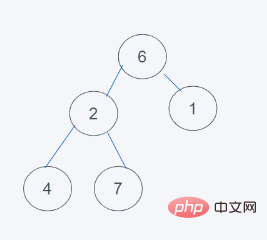
4.依据python的最小堆特性,元素6>元素1且元素6>元素2,但元素2>元素1, 交换6与1
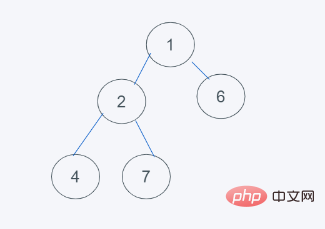
5.符合要求,则结果为[1, 2, 6, 4, 7]
由结果可以看出,当插入元素小于堆顶元素时,则堆不会发生改变,当插入元素大于堆顶元素时,则堆依据python堆的最小堆特性处理。
heapq.heapify(x)
将列表转换为堆。
1 2 3 4 5 6 7 8 9 |
|
会自动将列表依据python最小堆特性进行重新排列。
heapq.heapreplace(heap, item)
弹出并返回最小的元素,并且添加一个新元素item,这个单步骤操作比heappop()加heappush() 更高效。适用于堆元素数量固定的情况。
返回的值可能会比添加的 item 更大。 如果不希望如此,可考虑改用heappushpop()。 它的 push/pop 组合会返回两个值中较小的一个,将较大的值留在堆中。
1 2 3 4 5 6 7 8 9 10 11 |
|
原有数据是堆
对于插入元素6的操作过程如下:
1.初始状态
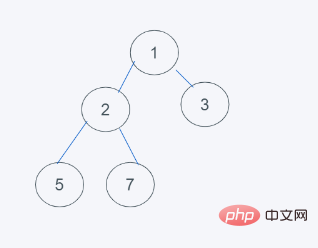
2.弹出最小元素,只能弹出堆顶或者堆尾的元素,很明显,最小元素是1,弹出1,插入元素是6,代替堆顶元素
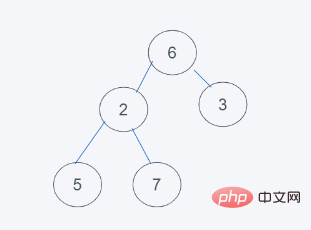
3.依据python堆的最小堆特性,6>2,交换6与2
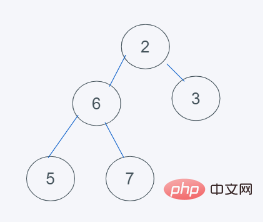
4.依据python堆的最小堆特性,6>5,交换6与5
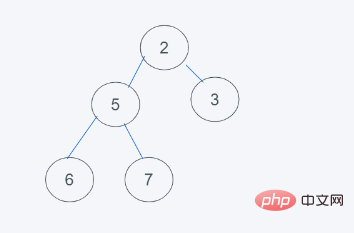
5.符合要求,则结果为[2, 5, 3, 6 ,7]
原有数据不是堆
对于插入元素6的操作过程如下:
1.初始状态
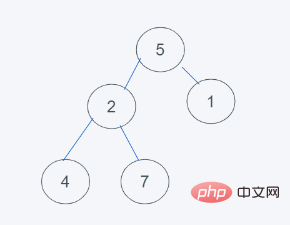
2.对于数据不为堆的情况下,默认移除第一个元素,这里就是元素5,然后插入元素6到堆顶
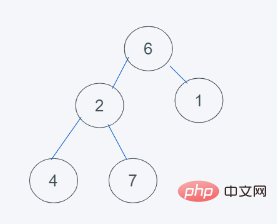
3.依据python的最小堆特性,元素6>1,交换元素6与1
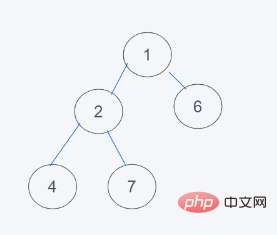
4.符合要求,即结果为[1, 2, 6, 4, 7
heapq.merge(*iterables, key=None, reverse=False)
将多个已排序的输入合并为一个已排序的输出(例如,合并来自多个日志文件的带时间戳的条目)。 返回已排序值的 iterator。注意需要是已排序完成的可迭代对象(默认为从小到大排序),当reverse为True时,则为从大到小排序。
heapq.nlargest(n, iterable, key=None)
从 iterable 所定义的数据集中返回前 n 个最大元素组成的列表。 如果提供了 key 则其应指定一个单参数的函数,用于从 iterable 的每个元素中提取比较键 (例如 key=str.lower)。
等价于: sorted(iterable, key=key, reverse=True)[:n]。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
|
由上述结构可见,heapq.nlargest与sorted(iterable, key=key, reverse=False)[:n]功能是类似的,但是性能方面还是sorted较为快速。
heapq.nsmallest(n, iterable, key=None)
从 iterable 所定义的数据集中返回前 n 个最小元素组成的列表。 如果提供了 key 则其应指定一个单参数的函数,用于从 iterable 的每个元素中提取比较键 (例如 key=str.lower)。 等价于: sorted(iterable, key=key)[:n]。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
由上述结果可见,sorted的性能比后面两个函数都要好,但如果只是返回最大的或者最小的一个元素,则使用max和min最好。
3.堆排序
由于在python中堆的特性是最小堆,堆顶的元素始终是最小的,可以将序列转换成堆之后,再使用pop弹出堆顶元素来实现从小到大排序。具体实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
4.堆中元素可以是元组形式,主要用于任务优先级
1 2 3 4 5 6 7 8 9 10 11 12 |
|
上述操作流程如下:
1.当进行第一次push(5, ‘write code’)时

2.当进行第二次push(7, ‘release product’)时,符合堆的要求
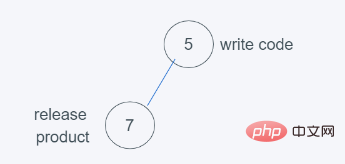
3.当进行第三次push(1, ‘write spec’)时,
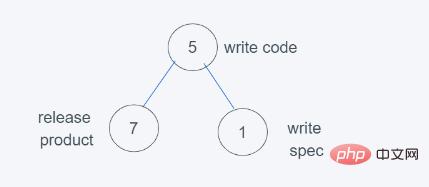
4.依据python的堆的最小堆特性,5>1 ,交换5和1
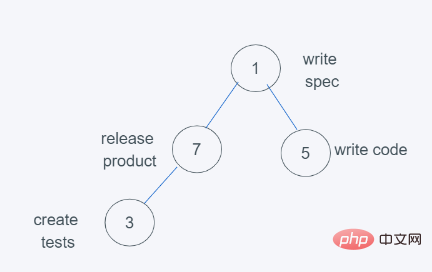
5.当进行最后依次push(3, ‘create tests’)时
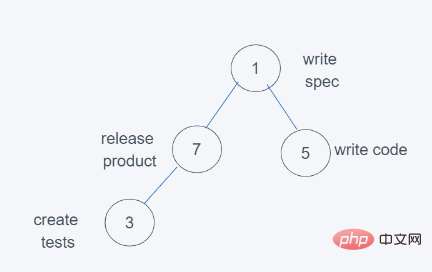
6.依据python堆的最小堆特性,7>3,交换7与3
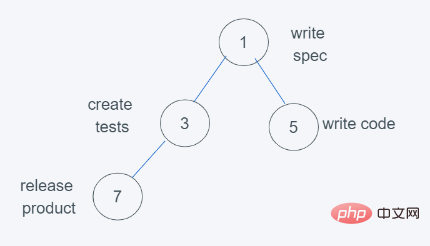
7.符合要求,因此结果为[(1, ‘write spec’), (3, ‘create tests’), (5, ‘write code’), (7, ‘release product’)],弹出元素则是堆顶元素,数字越小,优先级越大。
Atas ialah kandungan terperinci Bagaimana untuk melaksanakan timbunan terbina dalam python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.
Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Bagaimana cara menukar fail XML ke PDF di telefon anda?
Apr 02, 2025 pm 10:12 PM
Bagaimana cara menukar fail XML ke PDF di telefon anda?
Apr 02, 2025 pm 10:12 PM
Tidak mustahil untuk menyelesaikan penukaran XML ke PDF secara langsung di telefon anda dengan satu aplikasi. Ia perlu menggunakan perkhidmatan awan, yang boleh dicapai melalui dua langkah: 1. Tukar XML ke PDF di awan, 2. Akses atau muat turun fail PDF yang ditukar pada telefon bimbit.
 Adakah kelajuan penukaran cepat apabila menukar XML ke PDF pada telefon bimbit?
Apr 02, 2025 pm 10:09 PM
Adakah kelajuan penukaran cepat apabila menukar XML ke PDF pada telefon bimbit?
Apr 02, 2025 pm 10:09 PM
Kelajuan XML mudah alih ke PDF bergantung kepada faktor -faktor berikut: kerumitan struktur XML. Kaedah Penukaran Konfigurasi Perkakasan Mudah Alih (Perpustakaan, Algoritma) Kaedah Pengoptimuman Kualiti Kod (Pilih perpustakaan yang cekap, mengoptimumkan algoritma, data cache, dan menggunakan pelbagai threading). Secara keseluruhannya, tidak ada jawapan mutlak dan ia perlu dioptimumkan mengikut keadaan tertentu.
 Apakah fungsi jumlah bahasa C?
Apr 03, 2025 pm 02:21 PM
Apakah fungsi jumlah bahasa C?
Apr 03, 2025 pm 02:21 PM
Tiada fungsi jumlah terbina dalam dalam bahasa C, jadi ia perlu ditulis sendiri. Jumlah boleh dicapai dengan melintasi unsur -unsur array dan terkumpul: Versi gelung: SUM dikira menggunakan panjang gelung dan panjang. Versi Pointer: Gunakan petunjuk untuk menunjuk kepada unsur-unsur array, dan penjumlahan yang cekap dicapai melalui penunjuk diri sendiri. Secara dinamik memperuntukkan versi Array: Perlawanan secara dinamik dan uruskan memori sendiri, memastikan memori yang diperuntukkan dibebaskan untuk mengelakkan kebocoran ingatan.
 Adakah terdapat aplikasi mudah alih yang boleh menukar XML ke PDF?
Apr 02, 2025 pm 08:54 PM
Adakah terdapat aplikasi mudah alih yang boleh menukar XML ke PDF?
Apr 02, 2025 pm 08:54 PM
Permohonan yang menukarkan XML terus ke PDF tidak dapat dijumpai kerana mereka adalah dua format yang berbeza. XML digunakan untuk menyimpan data, manakala PDF digunakan untuk memaparkan dokumen. Untuk melengkapkan transformasi, anda boleh menggunakan bahasa pengaturcaraan dan perpustakaan seperti Python dan ReportLab untuk menghuraikan data XML dan menghasilkan dokumen PDF.
 Cara menukar XML ke dalam gambar
Apr 03, 2025 am 07:39 AM
Cara menukar XML ke dalam gambar
Apr 03, 2025 am 07:39 AM
XML boleh ditukar kepada imej dengan menggunakan perpustakaan penukar XSLT atau imej. XSLT Converter: Gunakan pemproses XSLT dan stylesheet untuk menukar XML ke imej. Perpustakaan Imej: Gunakan perpustakaan seperti PIL atau ImageMagick untuk membuat imej dari data XML, seperti bentuk lukisan dan teks.
 Apakah proses menukar XML ke dalam imej?
Apr 02, 2025 pm 08:24 PM
Apakah proses menukar XML ke dalam imej?
Apr 02, 2025 pm 08:24 PM
Untuk menukar imej XML, anda perlu menentukan struktur data XML terlebih dahulu, kemudian pilih perpustakaan grafik yang sesuai (seperti matplotlib Python) dan kaedah, pilih strategi visualisasi berdasarkan struktur data, pertimbangkan volum data dan format imej, lakukan pemprosesan batch atau gunakan perpustakaan yang cekap, dan akhirnya simpan sebagai PNG, JPEG, atau SVG mengikut keperluan.
 Adakah terdapat aplikasi mudah alih yang boleh menukar XML ke PDF?
Apr 02, 2025 pm 09:45 PM
Adakah terdapat aplikasi mudah alih yang boleh menukar XML ke PDF?
Apr 02, 2025 pm 09:45 PM
Tiada aplikasi yang boleh menukar semua fail XML ke dalam PDF kerana struktur XML adalah fleksibel dan pelbagai. Inti XML ke PDF adalah untuk menukar struktur data ke dalam susun atur halaman, yang memerlukan parsing XML dan menjana PDF. Kaedah umum termasuk parsing XML menggunakan perpustakaan python seperti ElementTree dan menjana PDF menggunakan perpustakaan ReportLab. Untuk XML yang kompleks, mungkin perlu menggunakan struktur transformasi XSLT. Apabila mengoptimumkan prestasi, pertimbangkan untuk menggunakan multithreaded atau multiprocesses dan pilih perpustakaan yang sesuai.
 Bagaimana cara mengawal saiz XML ditukar kepada imej?
Apr 02, 2025 pm 07:24 PM
Bagaimana cara mengawal saiz XML ditukar kepada imej?
Apr 02, 2025 pm 07:24 PM
Untuk menjana imej melalui XML, anda perlu menggunakan perpustakaan graf (seperti bantal dan JFreechart) sebagai jambatan untuk menjana imej berdasarkan metadata (saiz, warna) dalam XML. Kunci untuk mengawal saiz imej adalah untuk menyesuaikan nilai & lt; lebar & gt; dan & lt; ketinggian & gt; Tag dalam XML. Walau bagaimanapun, dalam aplikasi praktikal, kerumitan struktur XML, kehalusan lukisan graf, kelajuan penjanaan imej dan penggunaan memori, dan pemilihan format imej semuanya mempunyai kesan ke atas saiz imej yang dihasilkan. Oleh itu, perlu mempunyai pemahaman yang mendalam tentang struktur XML, mahir dalam perpustakaan grafik, dan mempertimbangkan faktor -faktor seperti algoritma pengoptimuman dan pemilihan format imej.
