
 Peranti teknologi
AI
Merumuskan tiga tahun yang lalu, MIT mengeluarkan kertas ulasan tentang pemecut AI
Peranti teknologi
AI
Merumuskan tiga tahun yang lalu, MIT mengeluarkan kertas ulasan tentang pemecut AI
Merumuskan tiga tahun yang lalu, MIT mengeluarkan kertas ulasan tentang pemecut AI

Sepanjang tahun lalu, kedua-dua syarikat pemula dan syarikat yang ditubuhkan lambat untuk mengumumkan, melancarkan dan menggunakan pemecut kecerdasan buatan (AI) dan pembelajaran mesin (ML). Tetapi ia tidak munasabah, dan bagi kebanyakan syarikat yang menerbitkan laporan pemecut, mereka menghabiskan masa tiga hingga empat tahun untuk menyelidik, menganalisis, mereka bentuk, mengesahkan dan menimbang reka bentuk pemecut dan membina tindanan teknologi untuk memprogramkan pemecut. Bagi syarikat yang telah mengeluarkan versi pemecut mereka yang dinaik taraf, kitaran pembangunan masih sekurang-kurangnya dua hingga tiga tahun, walaupun mereka melaporkan bahawa ia lebih pendek. Tumpuan pemecut ini masih pada mempercepatkan model rangkaian saraf dalam (DNN) Senario aplikasi terdiri daripada pengecaman pertuturan terbenam kuasa yang sangat rendah dan klasifikasi imej pusat data Persaingan dalam pasaran biasa dan kawasan aplikasi berterusan, iaitu Bahagian penting peralihan daripada pengkomputeran tradisional moden kepada penyelesaian pembelajaran mesin untuk syarikat industri dan teknologi.
Ekosistem AI menghimpunkan komponen pengkomputeran tepi, pengkomputeran berprestasi tinggi tradisional (HPC) dan analisis data berprestasi tinggi (HPDA) yang mesti berfungsi bersama untuk menjadi Empower yang berkesan pembuat keputusan, kakitangan barisan hadapan dan penganalisis. Rajah 1 menunjukkan gambaran keseluruhan seni bina bagi penyelesaian AI hujung ke hujung ini dan komponennya.
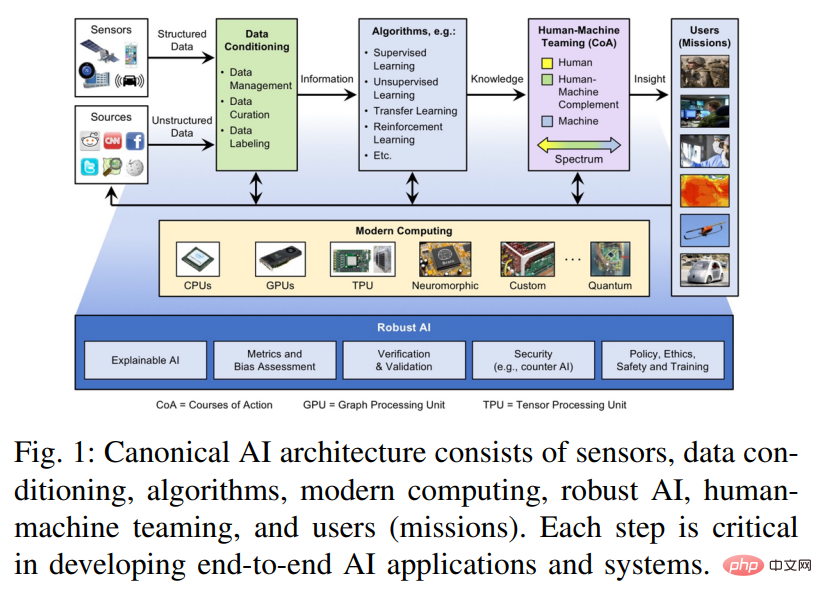
Data asal perlu dipilih susun terlebih dahulu, di mana data digabungkan, diagregatkan, berstruktur, terkumpul dan ditukar menjadi maklumat. Maklumat yang dijana oleh langkah perbalahan data berfungsi sebagai input kepada algoritma yang diselia atau tidak diselia seperti rangkaian saraf yang mengekstrak corak, mengisi data yang hilang atau mencari persamaan antara set data dan membuat ramalan, dengan itu menukar maklumat input kepada Pengetahuan yang boleh diambil tindakan. Pengetahuan yang boleh diambil tindakan ini akan dipindahkan kepada manusia dan digunakan dalam proses membuat keputusan semasa fasa kerjasama manusia-mesin. Peringkat kerjasama manusia-mesin menyediakan pengguna dengan cerapan yang berguna dan penting, mengubah pengetahuan menjadi kecerdasan atau cerapan yang boleh diambil tindakan.
Menyokong sistem ini ialah sistem pengkomputeran moden. Aliran Undang-undang Moore telah tamat, tetapi pada masa yang sama terdapat banyak undang-undang dan aliran berkaitan yang dicadangkan, seperti Undang-undang Denard (ketumpatan kuasa), kekerapan jam, kiraan teras, arahan setiap kitaran jam dan arahan setiap Joule (Hukum Koomey). Daripada aliran sistem-on-a-cip (SoC) yang mula-mula muncul dalam aplikasi automotif, robotik dan telefon pintar, inovasi terus berkembang melalui pembangunan dan penyepaduan pemecut teras, kaedah atau fungsi yang biasa digunakan. Pemecut ini menawarkan keseimbangan yang berbeza antara prestasi dan fleksibiliti berfungsi, termasuk ledakan inovasi dalam pemproses dan pemecut pembelajaran mendalam. Dengan membaca sejumlah besar kertas kerja yang berkaitan, artikel ini meneroka kelebihan relatif teknologi ini, kerana ia amat penting apabila menggunakan kecerdasan buatan pada sistem terbenam dan pusat data yang mempunyai keperluan yang melampau pada saiz, berat dan kuasa.
Artikel ini adalah kemas kini kertas kerja IEEE-HPEC dari tiga tahun yang lalu. Seperti tahun-tahun lepas, artikel ini terus memfokuskan pada pemecut dan pemproses untuk rangkaian saraf dalam (DNN) dan rangkaian saraf konvolusi (CNN), yang sangat intensif dari segi pengiraan. Artikel ini memfokuskan pada pembangunan pemecut dan pemproses dalam inferens, kerana banyak aplikasi tepi AI/ML sangat bergantung pada inferens. Artikel ini menangani semua jenis ketepatan berangka yang disokong oleh pemecut, tetapi bagi kebanyakan pemecut prestasi inferens terbaik mereka ialah int8 atau fp16/bf16 (titik terapung IEEE 16-bit atau apungan otak 16-bit Google).

Pautan kertas: https://arxiv.org/pdf/2210.04055.pdf
Pada masa ini, terdapat banyak kertas kerja membincangkan pemecut AI. Sebagai contoh, kertas pertama dalam siri tinjauan ini membincangkan prestasi puncak FPGA untuk model AI tertentu Tinjauan sebelumnya telah merangkumi FPGA secara mendalam dan oleh itu tidak lagi disertakan dalam tinjauan ini. Usaha dan artikel tinjauan berterusan ini bertujuan untuk mengumpulkan senarai komprehensif pemecut AI, termasuk keupayaan pengiraan, kecekapan tenaga dan kecekapan pengiraan mereka menggunakan pemecut dalam aplikasi terbenam dan pusat data. Pada masa yang sama, artikel itu terutamanya membandingkan pemecut rangkaian saraf untuk penderia kerajaan dan industri serta aplikasi pemprosesan data. Beberapa pemecut dan pemproses yang disertakan dalam kertas dari tahun-tahun sebelumnya telah dikecualikan daripada tinjauan tahun ini kerana ia mungkin telah digantikan oleh pemecut baharu daripada syarikat yang sama, tidak lagi diselenggara atau tidak lagi berkaitan dengan topik .
Tinjauan Pemproses
Banyak kemajuan terkini dalam kecerdasan buatan sebahagiannya disebabkan oleh peningkatan dalam prestasi perkakasan, yang membolehkan algoritma pembelajaran mesin yang memerlukan kuasa pengkomputeran yang besar, terutamanya rangkaian seperti DNN. Tinjauan untuk artikel ini mengumpulkan pelbagai maklumat daripada bahan yang tersedia untuk umum, termasuk pelbagai kertas penyelidikan, jurnal teknikal, penanda aras terbitan syarikat, dsb. Walaupun terdapat cara lain untuk mendapatkan maklumat tentang syarikat dan syarikat pemula (termasuk yang berada dalam tempoh senyap), artikel ini meninggalkan maklumat ini pada masa tinjauan ini dan data akan dimasukkan dalam tinjauan apabila ia diketahui umum. Metrik utama daripada data awam ini ditunjukkan dalam carta di bawah, yang menggambarkan prestasi puncak pemproses terkini berbanding keupayaan penggunaan kuasa (sehingga Julai 2022).
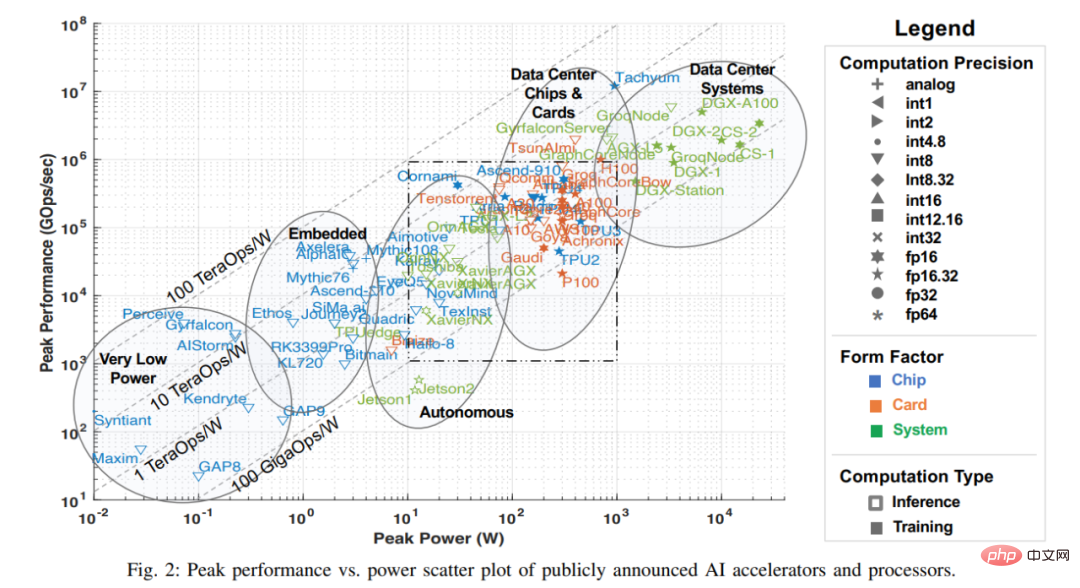
Nota: Kotak bertitik dalam Rajah 2 sepadan dengan Rajah 3 di bawah ialah versi besar bagi kotak bertitik.
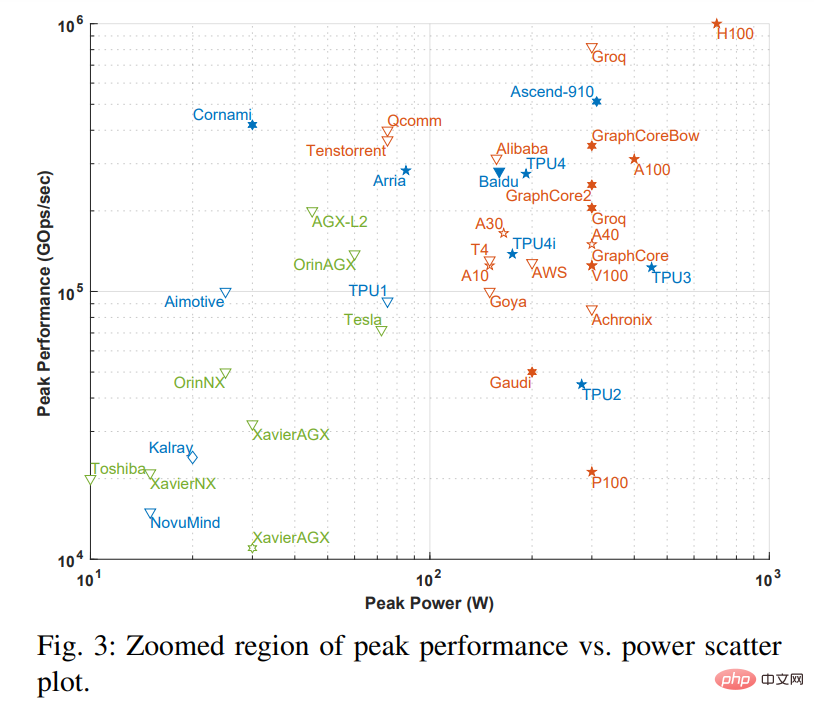
Paksi-x dalam rajah mewakili kuasa puncak, dan paksi-y mewakili operasi gigabit puncak sesaat (GOps /s), kedua-duanya adalah skala logaritma. Ketepatan pengiraan kuasa pemprosesan diwakili oleh geometri yang berbeza, antara int1 hingga int32 dan dari fp16 hingga fp64. Terdapat dua jenis ketepatan yang dipaparkan. Bahagian kiri mewakili ketepatan operasi pendaraban, dan bahagian kanan mewakili ketepatan operasi pengumpulan/tambahan (seperti fp16.32 mewakili pendaraban fp16 dan pengumpulan/tambahan fp32). Gunakan warna dan bentuk untuk membezakan antara pelbagai jenis sistem dan kuasa puncak. Biru mewakili cip tunggal; oren mewakili kad; hijau mewakili sistem keseluruhan (sistem desktop dan pelayan nod tunggal). Penyiasatan ini terhad kepada papan induk tunggal, sistem memori tunggal. Geometri terbuka dalam rajah mewakili prestasi tertinggi pemecut yang hanya melakukan inferens, manakala geometri pepejal mewakili prestasi pemecut yang melakukan kedua-dua latihan dan inferens.
Dalam tinjauan ini, artikel ini bermula dengan plot berselerak data tinjauan sepanjang tiga tahun yang lalu. Artikel ini meringkaskan beberapa metadata penting untuk pemecut, kad dan sistem keseluruhan dalam Jadual 1 di bawah, termasuk label untuk setiap titik dalam Rajah 2, dengan banyak mata diambil daripada tinjauan tahun lepas. Kebanyakan lajur dan entri dalam Jadual 1 adalah tepat dan jelas. Tetapi dua item teknologi mungkin tidak: Aliran Data dan PIM. Pemproses jenis aliran data ialah pemproses yang disesuaikan untuk inferens dan latihan rangkaian saraf. Oleh kerana latihan rangkaian saraf dan pengiraan inferens dibina sepenuhnya secara deterministik, ia sesuai untuk pemprosesan aliran data, di mana pengiraan, akses memori dan komunikasi antara ALU secara eksplisit/statik diprogramkan atau diletakkan dan dihalakan ke perkakasan pengiraan. Pemecut Pemproses dalam Memori (PIM) menyepadukan elemen pemprosesan dengan teknologi memori. Antara pemecut PIM ini adalah yang berasaskan teknologi pengkomputeran analog yang menambah litar memori kilat dengan fungsi tambah ganda analog di tempat. Anda boleh merujuk kepada bahan pemecut Mythic dan Gyrfalcon untuk mendapatkan butiran lanjut tentang teknologi inovatif ini.
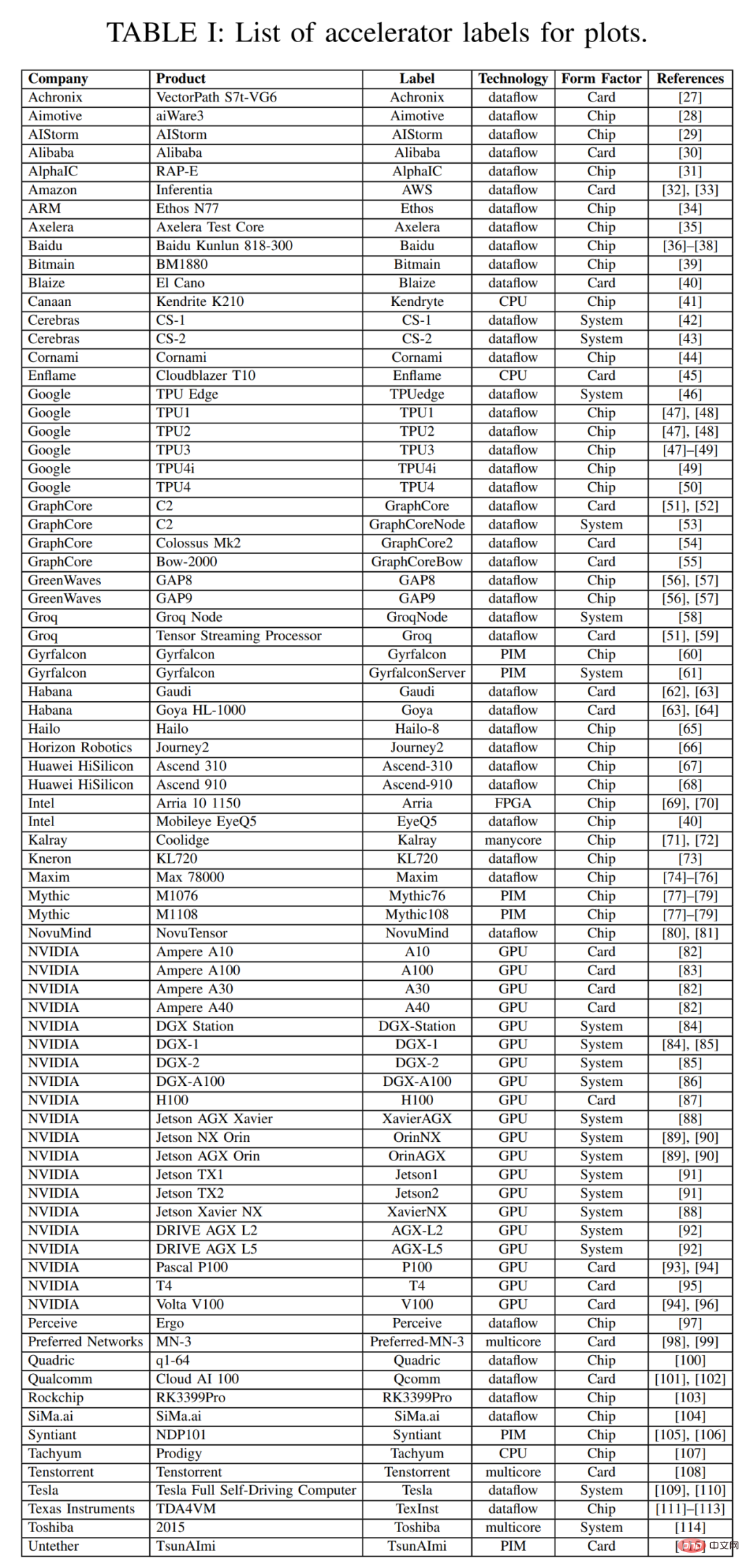
Artikel ini mengelaskan pemecut secara munasabah mengikut aplikasi yang dijangkakan. Rajah 1 menggunakan bujur untuk mengenal pasti lima jenis pemecut, sepadan dengan prestasi dan penggunaan kuasa. : Pemprosesan suara dengan penggunaan kuasa yang sangat rendah dan sensor yang sangat kecil, dron kecil dan sistem bantuan pemandu, cip dan kad pusat data;
Prestasi, fungsi dan penunjuk lain bagi kebanyakan pemecut tidak berubah Anda boleh merujuk kepada kertas kerja dalam tempoh dua tahun yang lalu untuk mendapatkan maklumat yang berkaitan. Berikut adalah pemecut yang tidak disertakan dalam artikel lepas.
Pemula sistem terbenam Belanda Acelera mendakwa bahawa mereka menghasilkan cip ujian terbenam dengan keupayaan reka bentuk digital dan analog, dan cip ujian ini adalah untuk menguji skop keupayaan reka bentuk digital. Mereka berharap untuk menambah elemen reka bentuk analog (dan mungkin kilat) dalam kerja masa hadapan.
Maxim Integrated telah mengeluarkan sistem pada cip (SoC) yang dipanggil MAX78000 untuk aplikasi kuasa ultra rendah. Ia termasuk teras CPU ARM, teras CPU RISC-V dan pemecut AI. Teras ARM digunakan untuk prototaip pantas dan penggunaan semula kod, manakala teras RISC-V dioptimumkan untuk penggunaan kuasa terendah. AI accelerator mempunyai 64 pemproses selari yang menyokong operasi integer 1-bit, 2-bit, 4-bit dan 8-bit. SoC beroperasi pada kuasa maksimum 30mW, menjadikannya sesuai untuk aplikasi berkuasa bateri berkependaman rendah.
Tachyum baru-baru ini mengeluarkan pemproses semua-dalam-satu yang dipanggil Prodigy Setiap teras Prodigy menyepadukan fungsi CPU dan GPU Ia direka untuk aplikasi pembelajaran mesin dan 128 teras berprestasi tinggi ., kekerapan operasi ialah 5.7GHz.
NVIDIA mengeluarkan GPU generasi seterusnya yang dipanggil Hopper (H100) pada Mac 2022. Hopper menyepadukan lebih banyak Pemproses Berbilang Simetri (teras SIMD dan Tensor), 50% lebih lebar jalur memori, dan tika kad mezanin SXM dengan kuasa 700W. (Kuasa kad PCIe ialah 450W)
Sejak beberapa tahun lalu NVIDIA telah mengeluarkan satu siri platform sistem untuk GPU seni bina Ampere yang digunakan dalam automotif, robotik dan aplikasi terbenam lain. Untuk aplikasi automotif, platform DRIVE AGX menambah dua sistem baharu: DRIVE AGX L2 membolehkan pemanduan autonomi Tahap 2 dalam julat kuasa 45W, dan DRIVE AGX L5 membolehkan pemanduan autonomi Tahap 5 dalam julat kuasa 800W. Jetson AGX Orin dan Jetson NX Orin juga menggunakan GPU seni bina Ampere untuk robotik, automasi kilang dan banyak lagi, dan mereka mempunyai kuasa puncak maksimum 60W dan 25W.
Graphcore mengeluarkan cip pemecut generasi kedua CG200, yang digunakan pada kad PCIe dan mempunyai kuasa puncak kira-kira 300W. Tahun lepas, Graphcore turut melancarkan Bow accelerator, pemproses wafer-to-wafer pertama yang direka bentuk dengan kerjasama TSMC. Pemecut itu sendiri adalah sama dengan CG200 yang dinyatakan di atas, tetapi ia dipasangkan dengan mati kedua yang sangat meningkatkan kuasa dan pengagihan jam merentas keseluruhan cip CG200. Ini mewakili peningkatan prestasi sebanyak 40% dan peningkatan prestasi setiap watt sebanyak 16%.
Pada Jun 2021, Google mengumumkan butiran pemecut TPU4i inferens tulen generasi keempatnya. Hampir setahun kemudian, Google telah berkongsi butiran pemecut latihan generasi ke-4nya, TPUv4. Walaupun pengumuman rasmi mempunyai sedikit butiran, mereka berkongsi kuasa puncak dan angka prestasi yang berkaitan. Seperti versi TPU sebelumnya, TPU4 tersedia melalui Google Compute Cloud dan digunakan untuk operasi dalaman.
Berikut ialah pengenalan kepada pemecut yang tidak muncul dalam Rajah 2. Setiap versi mengeluarkan beberapa hasil penanda aras, tetapi ada yang kurang prestasi puncak dan ada yang tidak menerbitkan prestasi puncak, sebagai mengikuti.
SambaNova mengeluarkan beberapa hasil penanda aras bagi teknologi pemecut AI yang boleh dikonfigurasikan semula pada tahun lepas ia juga mengeluarkan beberapa teknologi berkaitan dan menerbitkan kertas aplikasi dengan kerjasama Argonne National Laboratory tidak memberikan sebarang butiran dan hanya boleh menganggarkan prestasi puncak atau penggunaan kuasa penyelesaiannya daripada sumber yang tersedia secara umum.
Pada bulan Mei tahun ini, Intel Habana Labs mengumumkan pelancaran pemecut inferens Goya generasi kedua dan pemecut latihan Gaudi, masing-masing dinamakan Greco dan Gaudi2. Kedua-duanya berprestasi beberapa kali lebih baik daripada versi sebelumnya. Greco ialah kad PCIe lebar tunggal 75w, manakala Gaudi2 juga merupakan kad PCIe dua kali ganda 650w (mungkin pada slot PCIe 5.0). Habana menerbitkan beberapa perbandingan penanda aras Gaudi2 terhadap GPU Nvidia A100, tetapi tidak mendedahkan angka prestasi puncak untuk kedua-dua pemecut.
Esperanto telah menghasilkan beberapa cip demo untuk dinilai oleh Samsung dan rakan kongsi lain. Cip ini ialah pemproses RISC-V 1000-teras dengan pemecut tensor AI bagi setiap teras. Esperanto telah mengeluarkan beberapa angka prestasi, tetapi mereka tidak mendedahkan kuasa puncak atau prestasi puncak.
Pada Hari AI Tesla, Tesla memperkenalkan pemecut Dojo tersuai mereka dan beberapa butiran sistem. Cip mereka menampilkan prestasi puncak 22.6 TF FP32, tetapi penggunaan kuasa puncak bagi setiap cip belum diumumkan, mungkin butiran tersebut akan didedahkan kemudian.
Teknologi Centaur tahun lepas melancarkan CPU x86 dengan pemecut AI bersepadu, yang mempunyai unit SIMD lebar 4096-bait dan prestasi yang sangat kompetitif. Tetapi syarikat induk Centaur, VIA Technologies, nampaknya telah menamatkan pembangunan pemproses CNS selepas menjual pasukan kejuruteraan pemproses yang berpangkalan di A.S. kepada Intel.
Beberapa Pemerhatian dan Trend
Terdapat beberapa pemerhatian yang patut dinyatakan dalam Rajah 2, seperti berikut.
Int8 kekal sebagai ketepatan angka lalai untuk aplikasi inferens terbenam, autonomi dan pusat data. Ketepatan ini mencukupi untuk kebanyakan aplikasi AI/ML yang menggunakan nombor rasional. Juga sesetengah pemecut menggunakan fp16 atau bf16. Latihan model menggunakan perwakilan integer.
Tiada ciri tambahan selain daripada pemecut untuk pembelajaran mesin telah ditemui dalam cip kuasa yang sangat rendah. Dalam cip kuasa ultra rendah dan kategori terbenam, adalah perkara biasa untuk mengeluarkan penyelesaian sistem pada cip (SoC), selalunya termasuk teras CPU berkuasa rendah, penukar analog-ke-digital (ADC) audio dan video, enjin kriptografi. , antara muka rangkaian, dsb. Ciri tambahan SoC ini tidak mengubah metrik prestasi puncak, tetapi ia mempunyai kesan langsung pada kuasa puncak yang dilaporkan oleh cip, jadi itu penting apabila membandingkannya.
Bahagian terbenam tidak banyak berubah, bermakna prestasi pengkomputeran dan kuasa puncak adalah mencukupi untuk memenuhi keperluan aplikasi dalam bidang ini.
Beberapa syarikat, termasuk Texas Instruments, telah mengeluarkan pemecut AI sejak beberapa tahun lalu. Dan NVIDIA juga telah mengeluarkan beberapa sistem yang berprestasi lebih baik untuk aplikasi automotif dan robotik, seperti yang dinyatakan sebelum ini. Di pusat data, spesifikasi PCIe v5 sangat dinanti-nantikan untuk menembusi had kuasa 300W PCIe v4.
Akhir sekali, bukan sahaja sistem latihan mewah mengeluarkan nombor prestasi yang mengagumkan, tetapi syarikat-syarikat ini juga mengeluarkan teknologi interkoneksi berskala tinggi untuk menyambung beribu-ribu kad bersama-sama. Ini amat penting untuk pemecut aliran data seperti Cerebras, GraphCore, Groq, Tesla Dojo dan SambaNova, yang diprogramkan melalui pengaturcaraan eksplisit/statik atau letak-dan-laluan pada perkakasan pengiraan. Dengan cara ini ia membolehkan pemecut ini sesuai dengan model yang sangat besar seperti transformer.
Sila rujuk artikel asal untuk butiran lanjut.
Atas ialah kandungan terperinci Merumuskan tiga tahun yang lalu, MIT mengeluarkan kertas ulasan tentang pemecut AI. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Bytedance Cutting melancarkan keahlian super SVIP: 499 yuan untuk langganan tahunan berterusan, menyediakan pelbagai fungsi AI
Jun 28, 2024 am 03:51 AM
Bytedance Cutting melancarkan keahlian super SVIP: 499 yuan untuk langganan tahunan berterusan, menyediakan pelbagai fungsi AI
Jun 28, 2024 am 03:51 AM
Laman web ini melaporkan pada 27 Jun bahawa Jianying ialah perisian penyuntingan video yang dibangunkan oleh FaceMeng Technology, anak syarikat ByteDance Ia bergantung pada platform Douyin dan pada asasnya menghasilkan kandungan video pendek untuk pengguna platform tersebut Windows , MacOS dan sistem pengendalian lain. Jianying secara rasmi mengumumkan peningkatan sistem keahliannya dan melancarkan SVIP baharu, yang merangkumi pelbagai teknologi hitam AI, seperti terjemahan pintar, penonjolan pintar, pembungkusan pintar, sintesis manusia digital, dsb. Dari segi harga, yuran bulanan untuk keratan SVIP ialah 79 yuan, yuran tahunan ialah 599 yuan (nota di laman web ini: bersamaan dengan 49.9 yuan sebulan), langganan bulanan berterusan ialah 59 yuan sebulan, dan langganan tahunan berterusan ialah 499 yuan setahun (bersamaan dengan 41.6 yuan sebulan) . Di samping itu, pegawai yang dipotong juga menyatakan bahawa untuk meningkatkan pengalaman pengguna, mereka yang telah melanggan VIP asal
 Pembantu pengekodan AI yang ditambah konteks menggunakan Rag dan Sem-Rag
Jun 10, 2024 am 11:08 AM
Pembantu pengekodan AI yang ditambah konteks menggunakan Rag dan Sem-Rag
Jun 10, 2024 am 11:08 AM
Tingkatkan produktiviti, kecekapan dan ketepatan pembangun dengan menggabungkan penjanaan dipertingkatkan semula dan memori semantik ke dalam pembantu pengekodan AI. Diterjemah daripada EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, pengarang JanakiramMSV. Walaupun pembantu pengaturcaraan AI asas secara semulajadi membantu, mereka sering gagal memberikan cadangan kod yang paling relevan dan betul kerana mereka bergantung pada pemahaman umum bahasa perisian dan corak penulisan perisian yang paling biasa. Kod yang dijana oleh pembantu pengekodan ini sesuai untuk menyelesaikan masalah yang mereka bertanggungjawab untuk menyelesaikannya, tetapi selalunya tidak mematuhi piawaian pengekodan, konvensyen dan gaya pasukan individu. Ini selalunya menghasilkan cadangan yang perlu diubah suai atau diperhalusi agar kod itu diterima ke dalam aplikasi
 Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Model Bahasa Besar (LLM) dilatih pada pangkalan data teks yang besar, di mana mereka memperoleh sejumlah besar pengetahuan dunia sebenar. Pengetahuan ini dibenamkan ke dalam parameter mereka dan kemudiannya boleh digunakan apabila diperlukan. Pengetahuan tentang model ini "diperbaharui" pada akhir latihan. Pada akhir pra-latihan, model sebenarnya berhenti belajar. Selaraskan atau perhalusi model untuk mempelajari cara memanfaatkan pengetahuan ini dan bertindak balas dengan lebih semula jadi kepada soalan pengguna. Tetapi kadangkala pengetahuan model tidak mencukupi, dan walaupun model boleh mengakses kandungan luaran melalui RAG, ia dianggap berfaedah untuk menyesuaikan model kepada domain baharu melalui penalaan halus. Penalaan halus ini dilakukan menggunakan input daripada anotasi manusia atau ciptaan LLM lain, di mana model menemui pengetahuan dunia sebenar tambahan dan menyepadukannya
 Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Untuk mengetahui lebih lanjut tentang AIGC, sila layari: 51CTOAI.x Komuniti https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou berbeza daripada bank soalan tradisional yang boleh dilihat di mana-mana sahaja di Internet memerlukan pemikiran di luar kotak. Model Bahasa Besar (LLM) semakin penting dalam bidang sains data, kecerdasan buatan generatif (GenAI) dan kecerdasan buatan. Algoritma kompleks ini meningkatkan kemahiran manusia dan memacu kecekapan dan inovasi dalam banyak industri, menjadi kunci kepada syarikat untuk kekal berdaya saing. LLM mempunyai pelbagai aplikasi Ia boleh digunakan dalam bidang seperti pemprosesan bahasa semula jadi, penjanaan teks, pengecaman pertuturan dan sistem pengesyoran. Dengan belajar daripada sejumlah besar data, LLM dapat menjana teks
 Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) set data memainkan peranan penting dalam mempromosikan penyelidikan pemprosesan bahasa semula jadi (NLP). Set data QA berkualiti tinggi bukan sahaja boleh digunakan untuk memperhalusi model, tetapi juga menilai dengan berkesan keupayaan model bahasa besar (LLM), terutamanya keupayaan untuk memahami dan menaakul tentang pengetahuan saintifik. Walaupun pada masa ini terdapat banyak set data QA saintifik yang meliputi bidang perubatan, kimia, biologi dan bidang lain, set data ini masih mempunyai beberapa kekurangan. Pertama, borang data adalah agak mudah, kebanyakannya adalah soalan aneka pilihan. Ia mudah dinilai, tetapi mengehadkan julat pemilihan jawapan model dan tidak dapat menguji sepenuhnya keupayaan model untuk menjawab soalan saintifik. Sebaliknya, Soal Jawab terbuka
 Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Pembelajaran mesin ialah cabang penting kecerdasan buatan yang memberikan komputer keupayaan untuk belajar daripada data dan meningkatkan keupayaan mereka tanpa diprogramkan secara eksplisit. Pembelajaran mesin mempunyai pelbagai aplikasi dalam pelbagai bidang, daripada pengecaman imej dan pemprosesan bahasa semula jadi kepada sistem pengesyoran dan pengesanan penipuan, dan ia mengubah cara hidup kita. Terdapat banyak kaedah dan teori yang berbeza dalam bidang pembelajaran mesin, antaranya lima kaedah yang paling berpengaruh dipanggil "Lima Sekolah Pembelajaran Mesin". Lima sekolah utama ialah sekolah simbolik, sekolah sambungan, sekolah evolusi, sekolah Bayesian dan sekolah analogi. 1. Simbolisme, juga dikenali sebagai simbolisme, menekankan penggunaan simbol untuk penaakulan logik dan ekspresi pengetahuan. Aliran pemikiran ini percaya bahawa pembelajaran adalah proses penolakan terbalik, melalui sedia ada
 Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama
Jul 17, 2024 pm 06:37 PM
Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama
Jul 17, 2024 pm 06:37 PM
Editor |. KX Dalam bidang penyelidikan dan pembangunan ubat, meramalkan pertalian pengikatan protein dan ligan dengan tepat dan berkesan adalah penting untuk pemeriksaan dan pengoptimuman ubat. Walau bagaimanapun, kajian semasa tidak mengambil kira peranan penting maklumat permukaan molekul dalam interaksi protein-ligan. Berdasarkan ini, penyelidik dari Universiti Xiamen mencadangkan rangka kerja pengekstrakan ciri berbilang mod (MFE) novel, yang buat pertama kalinya menggabungkan maklumat mengenai permukaan protein, struktur dan jujukan 3D, dan menggunakan mekanisme perhatian silang untuk membandingkan ciri modaliti yang berbeza penjajaran. Keputusan eksperimen menunjukkan bahawa kaedah ini mencapai prestasi terkini dalam meramalkan pertalian mengikat protein-ligan. Tambahan pula, kajian ablasi menunjukkan keberkesanan dan keperluan maklumat permukaan protein dan penjajaran ciri multimodal dalam rangka kerja ini. Penyelidikan berkaitan bermula dengan "S
 Meletakkan pasaran seperti AI, GlobalFoundries memperoleh teknologi gallium nitrida Tagore Technology dan pasukan berkaitan
Jul 15, 2024 pm 12:21 PM
Meletakkan pasaran seperti AI, GlobalFoundries memperoleh teknologi gallium nitrida Tagore Technology dan pasukan berkaitan
Jul 15, 2024 pm 12:21 PM
Menurut berita dari laman web ini pada 5 Julai, GlobalFoundries mengeluarkan kenyataan akhbar pada 1 Julai tahun ini, mengumumkan pemerolehan teknologi power gallium nitride (GaN) Tagore Technology dan portfolio harta intelek, dengan harapan dapat mengembangkan bahagian pasarannya dalam kereta dan Internet of Things dan kawasan aplikasi pusat data kecerdasan buatan untuk meneroka kecekapan yang lebih tinggi dan prestasi yang lebih baik. Memandangkan teknologi seperti AI generatif terus berkembang dalam dunia digital, galium nitrida (GaN) telah menjadi penyelesaian utama untuk pengurusan kuasa yang mampan dan cekap, terutamanya dalam pusat data. Laman web ini memetik pengumuman rasmi bahawa semasa pengambilalihan ini, pasukan kejuruteraan Tagore Technology akan menyertai GLOBALFOUNDRIES untuk membangunkan lagi teknologi gallium nitride. G
