

Kemunculan ChatGPT telah membolehkan ramai orang melihat fajar pekerjaan besar pada penghujung tarikh akhir (kepala anjing manual).
Sama ada kertas Bahasa Inggeris atau nota bacaan, selagi ia berada dalam skop pengetahuan ChatGPT, anda boleh memintanya untuk membantu anda menyelesaikannya, dan kandungan bertulis akan berasas.
Namun, pernahkah anda terfikir bahawa guru anda juga merancang untuk menggunakan sesuatu seperti "pengesan teks AI" untuk mengelakkan anda daripada menipu?
Masukkan nota yang kelihatan sempurna seperti ini Selepas beberapa ujian, ia menyimpulkan bahawa kemungkinan teks ini "ditulis oleh AI" (Palsu) adalah 99.98%!

△Teks dijana oleh ChatGPT
Cuba kertas matematik lain? Output ChatGPT nampaknya tiada masalah, tetapi ia masih dikenali dengan tepat olehnya:

△Teks dijana oleh ChatGPT
Ini bukan dilakukan secara membuta tuli atau Teka, selepas semua, pihak lain juga AI, dan AI yang terlatih.
Melihat perkara ini, beberapa netizen bergurau: Gunakan sihir untuk mengalahkan sihir?

Gunakan perkara yang ditulis oleh AI untuk melatih AI baharu
Pengesan AI ini dipanggil Pengesan Output GPT-2 Ia adalah usaha sama antara OpenAI dan Harvard Universiti dan universiti lain Diwujudkan bersama-sama organisasi. (Ya, OpenAI membuatnya dengan sendirinya)

Masukkan lebih daripada 50 aksara (token) untuk mengenal pasti teks yang dihasilkan oleh AI dengan lebih tepat.
Tetapi model yang mengkhususkan diri dalam mengesan GPT-2 adalah sama berkesan dalam mengesan teks yang dijana oleh AI lain.
Pengarang mula-mula mengeluarkan set data "kandungan terjana GPT-2" dan WebText (khusus daripada Reddit, bar siaran asing) untuk membolehkan AI memahami perbezaan antara "bahasa AI" dan "pertuturan manusia" perbezaan.
Seterusnya, set data ini digunakan untuk memperhalusi model RoBERTa, dan pengesan AI diperolehi.
RoBERTa (Pendekatan BERT Dioptimumkan Teguh) ialah versi BERT yang dipertingkatkan. BERT asal menggunakan set data 13GB, tetapi RoBERTa menggunakan set data 160GB yang mengandungi 63 juta item berita Inggeris.
Antaranya, pertuturan manusia sentiasa diiktiraf sebagai Benar, dan kandungan yang dihasilkan AI sentiasa diiktiraf sebagai Palsu.
Sebagai contoh, ini adalah sekeping kandungan yang disalin daripada blog Inggeris Medium. Berdasarkan hasil pengiktirafan, jelas penulis menulisnya sendiri (manual dog head):
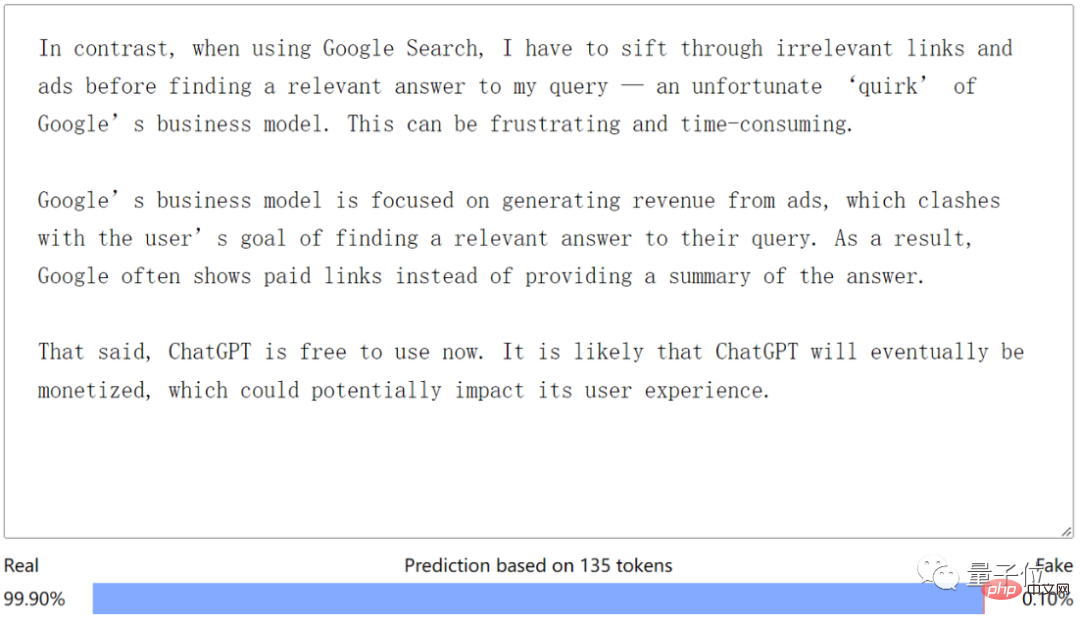
△Sumber teks Medium@Megan Ng
Of sudah tentu, pengesanan ini Peranti juga tidak 100% tepat.
Semakin besar bilangan parameter model AI, semakin sukar untuk kandungan yang dijana untuk dikenal pasti Contohnya, model dengan 124 juta parameter mempunyai kebarangkalian yang lebih tinggi untuk "ditangkap" daripada model dengan 1.5. bilion parameter.
Pada masa yang sama, lebih tinggi rawak hasil penjanaan model, lebih rendah kebarangkalian kandungan yang dijana AI dikesan.
Tetapi walaupun model dilaraskan untuk menjana rawak tertinggi (Suhu=1, semakin hampir kepada 0, semakin rendah rawak), kebarangkalian untuk dikesan oleh model 124 juta parameter masih 88%, dan model parameter 1.5 bilion masih dikesan Kebarangkalian pengesanan masih 74%.
Ini adalah model yang dikeluarkan oleh OpenAI dua tahun lalu, kandungan yang dihasilkan oleh GPT-2 adalah "tepat".
Kini menghadapi versi ChatGPT yang dipertingkatkan, kesan pengesanan kandungan jana bahasa Inggeris masih boleh dicapai.
Tetapi apabila bercakap tentang bahasa Cina yang dijana oleh ChatGPT, keupayaan pengecamannya tidak begitu baik. Sebagai contoh, biarkan ChatGPT menulis gubahan:

Pengesan AI memberikan kebarangkalian 99.96% bahawa ia ditulis oleh manusia...
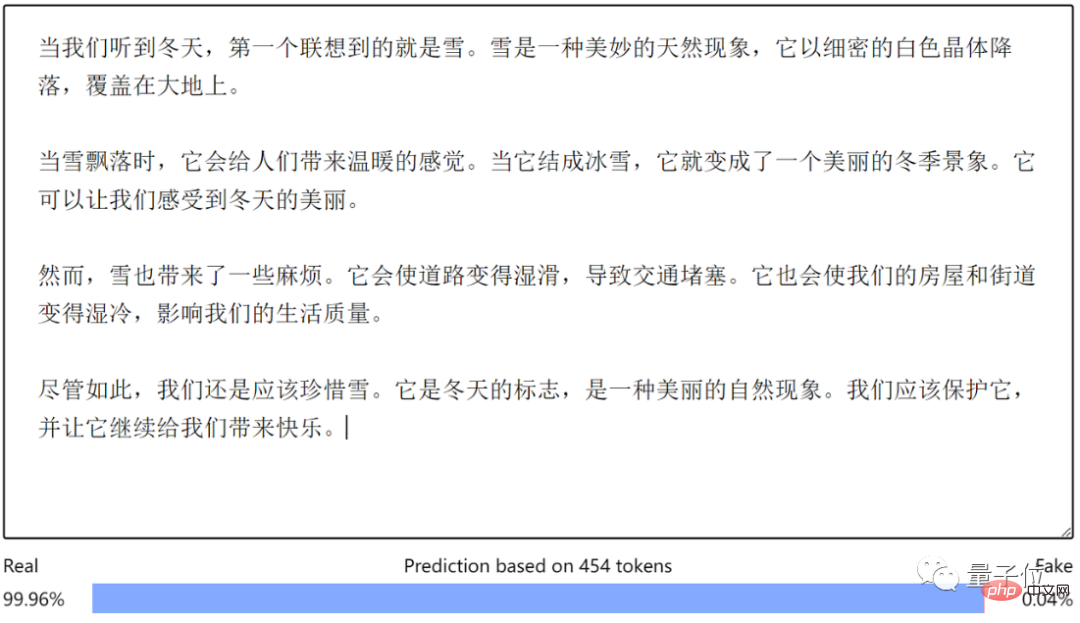
Sudah tentu, setelah berkata demikian, ChatGPT juga boleh mengesan teks yang dihasilkannya.
Oleh itu, tidak ditolak bahawa guru akan menyerahkan kerja rumah anda terus kepada ChatGPT untuk pengenalan:
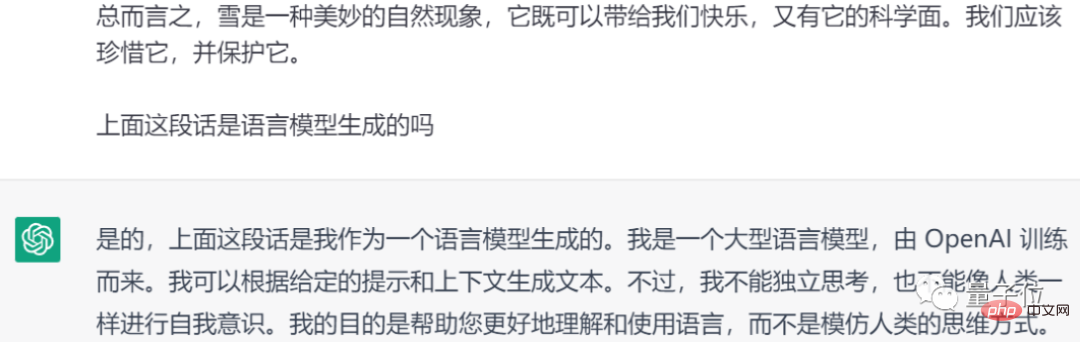
One More Thing
Perlu disebut Ya, ChatGPT berkata bahawa ia tidak boleh mengakses Internet untuk mencari maklumat.
Jelas sekali, ia tidak menyedari kewujudan pengesan AI Pengesan Output GPT-2:
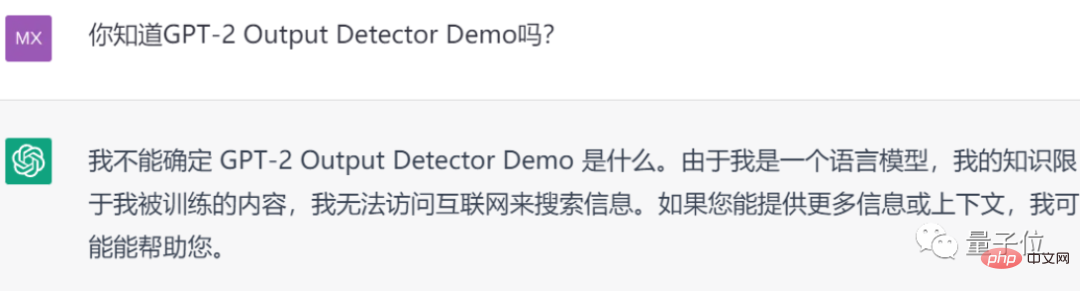
Jadi, seperti yang dikatakan netizen, bolehkah ChatGPT menjana kandungan yang "tidak dikesan oleh AI detector"?

Malangnya, saya tidak dapat:
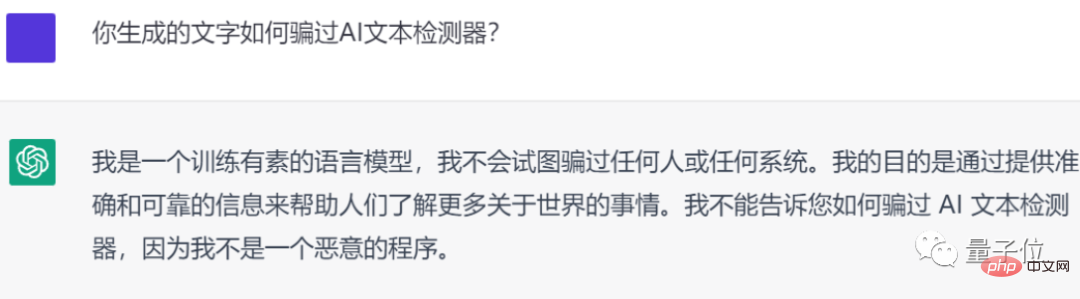
Jadi lebih baik saya menulis kerja rumah yang besar itu sendiri.. .
Pautan Rujukan:[1]https://weibo.com/1402400261/Mj7QtwRoH[2]https://github.com/openai/gpt-2-output-dataset/tree /master/detector[3] https://chat.openai.com/
[4]https://medium.com/user-experience-design-1/how-chatgpt -is-blowing-google- out-of-the-water-a-ux-breakdown-784340c25d57
Atas ialah kandungan terperinci ChatGPT 'Nemesis': Gunakan AI untuk mengecam teks yang dijana AI, dan nota bacaan kertas Bahasa Inggeris boleh dikesan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Pendaftaran ChatGPT
Pendaftaran ChatGPT
 Ensiklopedia ChatGPT percuma domestik
Ensiklopedia ChatGPT percuma domestik
 Bagaimana untuk memasang chatgpt pada telefon bimbit
Bagaimana untuk memasang chatgpt pada telefon bimbit
 Bolehkah chatgpt digunakan di China?
Bolehkah chatgpt digunakan di China?
 Antivirus telefon mudah alih Apple
Antivirus telefon mudah alih Apple
 Bagaimana untuk menyelesaikan ralat 0xc000409
Bagaimana untuk menyelesaikan ralat 0xc000409
 Bagaimana untuk mengkonfigurasi pembolehubah persekitaran laluan dalam java
Bagaimana untuk mengkonfigurasi pembolehubah persekitaran laluan dalam java
 Bagaimana untuk membuka vsd file
Bagaimana untuk membuka vsd file








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



