
 Peranti teknologi
AI
Selagi model itu cukup besar dan sampelnya cukup besar, AI boleh menjadi lebih pintar!
Peranti teknologi
AI
Selagi model itu cukup besar dan sampelnya cukup besar, AI boleh menjadi lebih pintar!
Selagi model itu cukup besar dan sampelnya cukup besar, AI boleh menjadi lebih pintar!

Tiada perbezaan dalam mekanisme matematik antara model AI dan otak manusia.
Selagi modelnya cukup besar dan sampelnya cukup besar, AI boleh menjadi lebih pintar!
Kemunculan chatGPT sebenarnya telah membuktikan perkara ini.
1. Butiran asas AI dan otak manusia adalah berdasarkan pernyataan if else
operasi logik, yang merupakan operasi asas yang menjana kecerdasan.
Logik asas bahasa pengaturcaraan ialah if else, yang membahagikan kod kepada dua cabang berdasarkan ungkapan bersyarat.
Atas dasar ini, pengaturcara boleh menulis kod yang sangat kompleks dan melaksanakan pelbagai logik perniagaan.
Logik asas otak manusia juga ialah if else, dua perkataan if else berasal dari bahasa Inggeris, dan kosa kata bahasa Cina yang sepadan ialah if...else...
When the human. otak sedang memikirkan masalah Ia juga merupakan idea yang logik, dan ia tidak berbeza dengan komputer dalam hal ini.
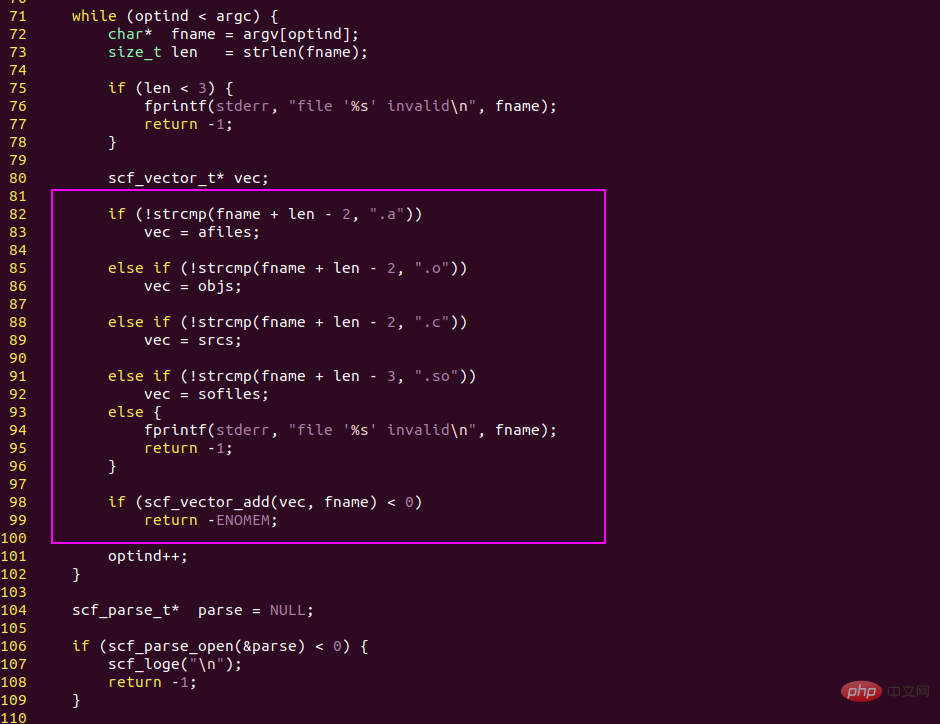
pernyataan if else, teras logik
Pernyataan "if else" model AI ialah fungsi pengaktifan!
Nod pengkomputeran model AI, kita juga boleh memanggilnya sebagai "neuron".
Ia mempunyai vektor input X, matriks berat W, vektor pincang b dan fungsi pengaktifan.
Fungsi pengaktifan sebenarnya ialah pernyataan if else, dan operasi linear WX + b ialah ungkapan bersyarat.
Selepas pengaktifan, kod model AI adalah bersamaan dengan berjalan di cawangan if, dan apabila tidak diaktifkan, ia bersamaan dengan berjalan di cawangan lain.
Keadaan pengaktifan berbeza bagi rangkaian saraf berbilang lapisan sebenarnya adalah pengekodan binari maklumat sampel.
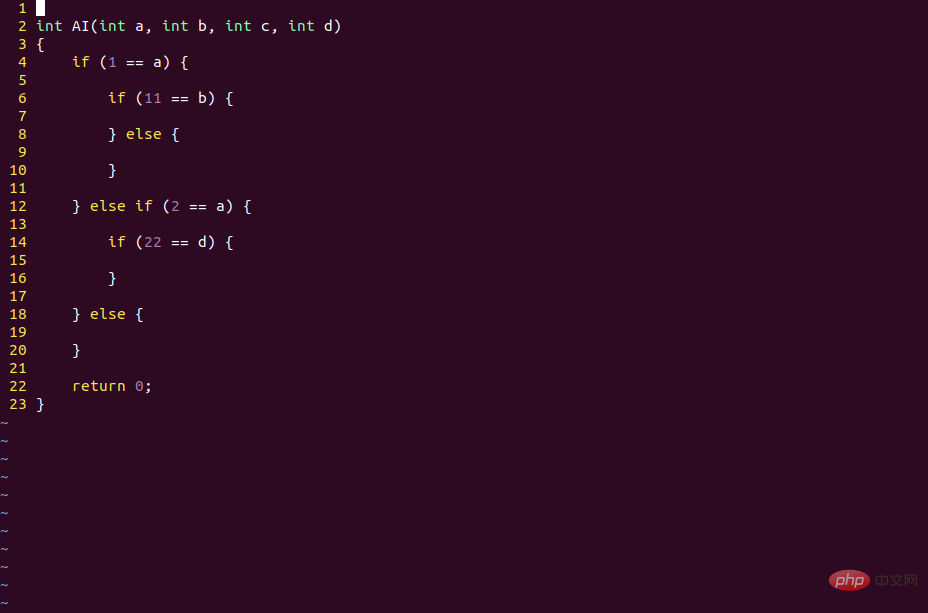
Pembelajaran mendalam juga mengekod maklumat sampel dalam binari
Model AI mengkodkan maklumat sampel secara dinamik dan selari, tidak sama dengan kod CPU Mereka adalah statik dan bersiri, tetapi asas asasnya adalah jika sebaliknya.
Ia tidak sukar untuk dilaksanakan jika di peringkat litar ia boleh dilaksanakan dengan triod.
2. Otak manusia lebih pintar daripada komputer kerana manusia memperoleh lebih banyak maklumat
Otak manusia memperoleh maklumat dari dunia luar setiap saat dan mengemas kini maklumatnya sendiri setiap saat. , tetapi kod program tidak boleh mengemas kini sendiri, itulah sebabnya ramai orang boleh melakukannya tetapi komputer tidak boleh.
Kod otak manusia masih hidup, tetapi kod komputer mati.
Sudah tentu "kod mati" tidak boleh lebih pintar daripada "kod langsung", kerana "kod langsung" boleh mencari pepijat "kod mati" secara aktif.
Mengikut kesinambungan nombor nyata, selagi maklumat yang dikodkan oleh "kod mati" boleh dikira, maka ia akan sentiasa mempunyai titik pepijat yang tidak boleh dikodkan.
Ini boleh disokong secara matematik oleh set ketiga Cantor.
Tidak kira berapa banyak digit perpuluhan ternari yang kami gunakan untuk mengekod nombor nyata dalam selang [0, 1], sentiasa terdapat sekurang-kurangnya satu titik yang tidak boleh dikodkan.
Jadi apabila dua orang bertengkar, mereka sentiasa boleh mencari perkara untuk dihujahkan
Tetapi apabila kod komputer ditulis, ia tidak boleh dikemas kini secara automatik, jadi pengaturcara boleh menghasilkan pelbagai idea. Satu cara untuk menipu CPU.
Sebagai contoh, CPU Intel pada asalnya memerlukan penukaran gerbang tugas apabila menukar proses, tetapi Linux menghasilkan cara untuk menukar direktori halaman dan daftar RSP sahaja.
Dalam pandangan Intel CPU , sistem Linux telah menjalankan proses yang sama, tetapi tidak. Ini dipanggil penukaran lembut proses.
Jadi, selagi litar CPU diperbaiki, maklumat yang dikodkan oleh CPU juga akan diperbaiki.
Maklumat yang dikodkan oleh CPU adalah tetap, maka maklumat yang tidak boleh dikodkan adalah tidak terhad dan boleh digunakan oleh pengaturcara.
Sebab pengaturcara boleh menggunakan maklumat ini adalah kerana otak pengaturcara hidup dan boleh mengemas kini sampel secara dinamik.
3. Kemunculan rangkaian saraf telah mengubah keadaan ini
Rangkaian saraf benar-benar ciptaan yang hebat, ia merealisasikan kemas kini maklumat dinamik pada litar tetap.
Maklumat yang boleh diproses oleh semua program bertulis adalah tetap, termasuk litar CPU dan kod pelbagai sistem.
Tetapi ini tidak berlaku dengan rangkaian saraf Walaupun kodnya ditulis, ia hanya perlu mengemas kini data berat untuk menukar konteks logik model.
Malah, selagi sampel baharu dimasukkan secara berterusan, model AI boleh mengemas kini data berat secara berterusan menggunakan algoritma BP (algoritma keturunan kecerunan) untuk menyesuaikan diri dengan senario perniagaan baharu.
Mengemas kini model AI tidak memerlukan pengubahsuaian kod, tetapi hanya memerlukan pengubahsuaian data, jadi model CNN yang sama boleh mengecam objek yang berbeza jika ia dilatih dengan sampel yang berbeza.
Semasa proses ini, kedua-dua kod rangka kerja aliran tensor dan struktur rangkaian model AI kekal tidak berubah ialah data berat setiap nod.
Secara teorinya, selagi model AI boleh merangkak data melalui rangkaian, ia boleh menjadi lebih pintar.
Adakah ini pada asasnya berbeza daripada orang yang menonton sesuatu melalui penyemak imbas (dengan itu menjadi lebih pintar)? Nampaknya tidak.
4. Asalkan modelnya cukup besar dan sampelnya cukup besar, mungkin ChatGPT benar-benar boleh mencabar otak manusia
Otak manusia mempunyai 15 bilion neuron, dan mata dan telinga manusia berubah sepanjang masa Sudah tentu, model AI juga boleh melakukan ini dengan menyediakannya dengan data baharu.
Mungkin berbanding AI, kelebihan manusia ialah "rantai industri" lebih pendek
Kelahiran bayi hanya memerlukan ibu bapanya, tetapi kelahiran model AI jelas tidak memerlukan satu atau dua program Ahli boleh melakukannya.
Terdapat lebih daripada puluhan ribu orang yang mengeluarkan GPU sahaja.
Program Cuda pada GPU tidak sukar untuk ditulis, tetapi rantaian industri pembuatan GPU terlalu panjang, jauh lebih rendah daripada kelahiran dan pertumbuhan manusia.
Ini mungkin kelemahan sebenar AI berbanding manusia.
Atas ialah kandungan terperinci Selagi model itu cukup besar dan sampelnya cukup besar, AI boleh menjadi lebih pintar!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1386
1386
 52
52

 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 Melebihi DPO secara menyeluruh: Pasukan Chen Danqi mencadangkan pengoptimuman pilihan mudah SimPO, dan turut memperhalusi model sumber terbuka 8B terkuat
Jun 01, 2024 pm 04:41 PM
Melebihi DPO secara menyeluruh: Pasukan Chen Danqi mencadangkan pengoptimuman pilihan mudah SimPO, dan turut memperhalusi model sumber terbuka 8B terkuat
Jun 01, 2024 pm 04:41 PM
Untuk menyelaraskan model bahasa besar (LLM) dengan nilai dan niat manusia, adalah penting untuk mempelajari maklum balas manusia untuk memastikan bahawa ia berguna, jujur dan tidak berbahaya. Dari segi penjajaran LLM, kaedah yang berkesan ialah pembelajaran pengukuhan berdasarkan maklum balas manusia (RLHF). Walaupun keputusan kaedah RLHF adalah cemerlang, terdapat beberapa cabaran pengoptimuman yang terlibat. Ini melibatkan latihan model ganjaran dan kemudian mengoptimumkan model dasar untuk memaksimumkan ganjaran tersebut. Baru-baru ini, beberapa penyelidik telah meneroka algoritma luar talian yang lebih mudah, salah satunya ialah pengoptimuman keutamaan langsung (DPO). DPO mempelajari model dasar secara langsung berdasarkan data keutamaan dengan meparameterkan fungsi ganjaran dalam RLHF, sekali gus menghapuskan keperluan untuk model ganjaran yang jelas. Kaedah ini mudah dan stabil
 Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Di barisan hadapan teknologi perisian, kumpulan UIUC Zhang Lingming, bersama penyelidik dari organisasi BigCode, baru-baru ini mengumumkan model kod besar StarCoder2-15B-Instruct. Pencapaian inovatif ini mencapai kejayaan ketara dalam tugas penjanaan kod, berjaya mengatasi CodeLlama-70B-Instruct dan mencapai bahagian atas senarai prestasi penjanaan kod. Keunikan StarCoder2-15B-Instruct terletak pada strategi penjajaran diri yang tulen Keseluruhan proses latihan adalah terbuka, telus, dan sepenuhnya autonomi dan boleh dikawal. Model ini menjana beribu-ribu arahan melalui StarCoder2-15B sebagai tindak balas kepada penalaan halus model asas StarCoder-15B tanpa bergantung pada anotasi manual yang mahal.
 Yolov10: Penjelasan terperinci, penggunaan dan aplikasi semuanya di satu tempat!
Jun 07, 2024 pm 12:05 PM
Yolov10: Penjelasan terperinci, penggunaan dan aplikasi semuanya di satu tempat!
Jun 07, 2024 pm 12:05 PM
1. Pengenalan Sejak beberapa tahun kebelakangan ini, YOLO telah menjadi paradigma dominan dalam bidang pengesanan objek masa nyata kerana keseimbangannya yang berkesan antara kos pengiraan dan prestasi pengesanan. Penyelidik telah meneroka reka bentuk seni bina YOLO, matlamat pengoptimuman, strategi pengembangan data, dsb., dan telah mencapai kemajuan yang ketara. Pada masa yang sama, bergantung pada penindasan bukan maksimum (NMS) untuk pemprosesan pasca menghalang penggunaan YOLO dari hujung ke hujung dan memberi kesan buruk kepada kependaman inferens. Dalam YOLO, reka bentuk pelbagai komponen tidak mempunyai pemeriksaan yang komprehensif dan teliti, mengakibatkan lebihan pengiraan yang ketara dan mengehadkan keupayaan model. Ia menawarkan kecekapan suboptimum, dan potensi yang agak besar untuk peningkatan prestasi. Dalam kerja ini, matlamatnya adalah untuk meningkatkan lagi sempadan kecekapan prestasi YOLO daripada kedua-dua pasca pemprosesan dan seni bina model. sampai habis
 Universiti Tsinghua mengambil alih dan YOLOv10 keluar: prestasi telah bertambah baik dan ia berada dalam senarai panas GitHub
Jun 06, 2024 pm 12:20 PM
Universiti Tsinghua mengambil alih dan YOLOv10 keluar: prestasi telah bertambah baik dan ia berada dalam senarai panas GitHub
Jun 06, 2024 pm 12:20 PM
Siri penanda aras YOLO sistem pengesanan sasaran sekali lagi menerima peningkatan besar. Sejak pengeluaran YOLOv9 pada Februari tahun ini, baton siri YOLO (YouOnlyLookOnce) telah diserahkan kepada penyelidik di Universiti Tsinghua. Hujung minggu lalu, berita pelancaran YOLOv10 menarik perhatian komuniti AI. Ia dianggap sebagai rangka kerja terobosan dalam bidang penglihatan komputer dan terkenal dengan keupayaan pengesanan objek hujung ke hujung masa nyata, meneruskan legasi siri YOLO dengan menyediakan penyelesaian berkuasa yang menggabungkan kecekapan dan ketepatan. Alamat kertas: https://arxiv.org/pdf/2405.14458 Alamat projek: https://github.com/THU-MIG/yo
 Li Feifei mendedahkan hala tuju keusahawanan 'kecerdasan ruang': visualisasi bertukar menjadi wawasan, melihat menjadi pemahaman, dan pemahaman membawa kepada tindakan
Jun 01, 2024 pm 02:55 PM
Li Feifei mendedahkan hala tuju keusahawanan 'kecerdasan ruang': visualisasi bertukar menjadi wawasan, melihat menjadi pemahaman, dan pemahaman membawa kepada tindakan
Jun 01, 2024 pm 02:55 PM
Stanford Li Feifei memperkenalkan konsep baharu "kecerdasan ruang" buat kali pertama selepas memulakan perniagaannya sendiri. Ini bukan sahaja hala tuju keusahawanannya, tetapi juga "Bintang Utara" yang membimbingnya "bahagian teka-teki utama untuk menyelesaikan masalah kecerdasan buatan." Visualisasi membawa kepada pandangan; melihat membawa kepada pemahaman; Berdasarkan ceramah TED selama 15 minit Li Feifei, ia didedahkan sepenuhnya, bermula dari asal-usul evolusi kehidupan beratus-ratus juta tahun yang lalu, kepada bagaimana manusia tidak berpuas hati dengan apa yang telah diberikan oleh alam semula jadi kepada mereka dan membangunkan kecerdasan buatan, kepada bagaimana untuk membina. kecerdasan ruang dalam langkah seterusnya. Sembilan tahun yang lalu, Li Feifei memperkenalkan ImageNet yang baru dilahirkan kepada dunia di peringkat yang sama - salah satu titik permulaan untuk pusingan ledakan pembelajaran mendalam ini. Dia sendiri juga menggalakkan netizen: Jika anda menonton kedua-dua video, anda akan dapat memahami visi komputer selama 10 tahun yang lalu.
 Menewaskan GPT-4o dalam beberapa saat, menewaskan Llama 3 70B dalam 22B, Mistral AI membuka model kod pertamanya
Jun 01, 2024 pm 06:32 PM
Menewaskan GPT-4o dalam beberapa saat, menewaskan Llama 3 70B dalam 22B, Mistral AI membuka model kod pertamanya
Jun 01, 2024 pm 06:32 PM
Unicorn AI Perancis MistralAI, yang menyasarkan OpenAI, telah membuat langkah baharu: Codestral, model kod besar pertama, telah dilahirkan. Sebagai model AI generatif terbuka yang direka khusus untuk tugas penjanaan kod, Codestral membantu pembangun menulis dan berinteraksi dengan kod dengan berkongsi arahan dan menyelesaikan titik akhir API. Kecekapan Codestral dalam pengekodan dan bahasa Inggeris membolehkan pembangun perisian mereka bentuk aplikasi AI lanjutan. Saiz parameter Codestral ialah 22B, ia mematuhi Lesen Pengeluaran MistralAINon baharu, dan boleh digunakan untuk tujuan penyelidikan dan ujian, tetapi penggunaan komersial adalah dilarang. Pada masa ini, model ini tersedia untuk dimuat turun di HuggingFace. pautan muat turun
 Laporan teknikal Google Gemini 1.5: Buktikan soalan Olimpik Matematik dengan mudah, versi Flash adalah 5 kali lebih pantas daripada GPT-4 Turbo
Jun 13, 2024 pm 01:52 PM
Laporan teknikal Google Gemini 1.5: Buktikan soalan Olimpik Matematik dengan mudah, versi Flash adalah 5 kali lebih pantas daripada GPT-4 Turbo
Jun 13, 2024 pm 01:52 PM
Pada bulan Februari tahun ini, Google melancarkan model besar berbilang modal Gemini 1.5, yang telah meningkatkan prestasi dan kelajuan dengan sangat baik melalui pengoptimuman kejuruteraan dan infrastruktur, seni bina MoE dan strategi lain. Dengan konteks yang lebih panjang, keupayaan penaakulan yang lebih kukuh dan pengendalian kandungan merentas modal yang lebih baik. Jumaat ini, Google DeepMind secara rasmi mengeluarkan laporan teknikal Gemini 1.5, yang merangkumi versi Flash dan peningkatan terkini yang lain Dokumen itu sepanjang 153 halaman. Pautan laporan teknikal: https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf Dalam laporan ini, Google memperkenalkan Gemini1
