
 Peranti teknologi
AI
Resapan Lembut: Rangka kerja baharu Google menjadualkan, mempelajari dan membuat sampel dengan betul daripada proses resapan sejagat
Peranti teknologi
AI
Resapan Lembut: Rangka kerja baharu Google menjadualkan, mempelajari dan membuat sampel dengan betul daripada proses resapan sejagat
Resapan Lembut: Rangka kerja baharu Google menjadualkan, mempelajari dan membuat sampel dengan betul daripada proses resapan sejagat

Kami tahu bahawa model berasaskan skor dan model kebarangkalian penyebaran resapan (DDPM) ialah dua kelas model generatif berkuasa yang menjana sampel dengan menyongsangkan proses resapan. Kedua-dua jenis model ini telah disatukan menjadi satu rangka kerja dalam makalah "Pemodelan generatif berasaskan skor melalui persamaan pembezaan stokastik" oleh Yang Song dan penyelidik lain, dan dikenali secara meluas sebagai model resapan.
Pada masa ini, model resapan telah mencapai kejayaan besar dalam beberapa siri aplikasi termasuk imej, audio, penjanaan video dan menyelesaikan masalah songsang. Dalam kertas kerja "Menjelaskan ruang reka bentuk model generatif berasaskan penyebaran", penyelidik seperti Tero Karras menganalisis ruang reka bentuk model resapan dan mengenal pasti tiga peringkat, iaitu i) memilih penjadualan tahap hingar, ii) memilih parameter rangkaian. isasi (setiap parameterisasi menjana fungsi kehilangan yang berbeza), iii) mereka bentuk algoritma pensampelan.
Baru-baru ini, dalam makalah arXiv "Soft Diffusion: Score Matching for General Corruption" yang dikendalikan bersama oleh Google Research dan UT-Austin, beberapa penyelidik percaya bahawa masih terdapat model penyebaran Langkah penting : rasuah. Secara umumnya, rasuah ialah proses menambah hingar amplitud yang berbeza, dan untuk DDMP juga memerlukan penskalaan semula. Walaupun terdapat percubaan untuk menggunakan pengedaran berbeza untuk penyebaran, rangka kerja umum masih kurang. Oleh itu, para penyelidik mencadangkan rangka kerja reka bentuk model penyebaran untuk proses kerosakan yang lebih umum.
Secara khusus, mereka mencadangkan objektif latihan baharu yang dipanggil Padanan Skor Lembut dan kaedah pensampelan baru, Pensampel Momentum. Keputusan teori menunjukkan bahawa untuk proses kerosakan yang memenuhi syarat keteraturan, Soft Score MatchIng dapat mempelajari skor mereka (iaitu, kecerunan kemungkinan) bahawa resapan mesti mengubah mana-mana imej kepada mana-mana imej dengan kemungkinan bukan sifar.
Dalam bahagian eksperimen, penyelidik melatih model pada CelebA dan CIFAR-10 Model yang dilatih pada CelebA mencapai skor SOTA FID model resapan linear - 1.85. Pada masa yang sama, model yang dilatih oleh penyelidik adalah jauh lebih pantas daripada model yang dilatih menggunakan penyebaran denoising Gaussian yang asal.

Alamat kertas: https://arxiv.org/pdf/2209.05442.pdf
Gambaran Keseluruhan Kaedah
Secara umumnya, model resapan menjana imej dengan menyongsangkan proses kerosakan yang meningkatkan bunyi secara beransur-ansur. Para penyelidik menunjukkan cara belajar menyongsangkan resapan yang melibatkan degradasi deterministik linear dan bunyi aditif stokastik.

Secara khusus, penyelidik menunjukkan rangka kerja untuk menggunakan model kerosakan yang lebih umum untuk melatih model resapan, yang terdiri daripada tiga bahagian, masing-masing, untuk objektif latihan baharu. Padanan Skor Lembut, kaedah pensampelan novel Sampel Momentum, dan penjadualan mekanisme kerosakan.
Mula-mula mari kita lihat pada sasaran latihan Padanan Skor Lembut Nama ini diilhamkan oleh penapisan lembut, istilah fotografi yang merujuk kepada penapis yang mengalih keluar butiran halus. Ia mempelajari pecahan proses kerosakan linear konvensional dengan cara yang boleh dibuktikan, juga menggabungkan proses penapisan ke dalam rangkaian, dan melatih model untuk meramalkan imej selepas kerosakan yang sepadan dengan pemerhatian resapan.
Selagi penyebaran memberikan kebarangkalian bukan sifar kepada mana-mana pasangan imej yang bersih dan rosak, objektif latihan ini boleh membuktikan bahawa skor dipelajari. Selain itu, keadaan ini sentiasa berpuas hati apabila terdapat bunyi tambahan dalam kerosakan.
Secara khusus, penyelidik meneroka proses kerosakan dalam bentuk berikut.

Dalam proses itu, penyelidik mendapati bunyi bising mempunyai manfaat empirikal (iaitu keputusan yang lebih baik) dan teori (iaitu untuk mempelajari pecahan). . Ini juga menjadi perbezaan utama daripada Cold Diffusion, kerja serentak yang membalikkan rasuah yang menentukan.
Yang kedua ialah kaedah persampelan Persampelan Momentum. Para penyelidik menunjukkan bahawa pilihan pensampel mempunyai kesan yang signifikan terhadap kualiti sampel yang dihasilkan. Mereka mencadangkan Momentum Sampler untuk menyongsangkan proses kerosakan linear universal. Pensampel menggunakan gabungan cembung rasuah dengan tahap resapan yang berbeza dan diilhamkan oleh kaedah momentum dalam pengoptimuman.
Kaedah persampelan ini diilhamkan oleh rumusan berterusan model resapan yang dicadangkan dalam kertas kerja oleh Yang Song et al. Algoritma untuk Pensampel Momentum ditunjukkan di bawah.

Rajah di bawah secara visual menunjukkan kesan kaedah pensampelan yang berbeza ke atas kualiti sampel yang dijana. Imej yang diambil dengan Naive Sampler di sebelah kiri kelihatan berulang dan kurang terperinci, manakala Momentum Sampler di sebelah kanan meningkatkan kualiti pensampelan dan skor FID dengan ketara.

Perkara terakhir ialah penjadualan. Walaupun jenis degradasi dipratakrifkan (seperti kabur), menentukan jumlah kerosakan pada setiap langkah resapan bukanlah perkara remeh. Para penyelidik mencadangkan alat berprinsip untuk membimbing reka bentuk proses kerosakan. Untuk mencari jadual, mereka meminimumkan jarak Wasserstein antara pengedaran di sepanjang laluan. Secara intuitif, penyelidik mahukan peralihan yang lancar daripada pengedaran yang rosak sepenuhnya kepada pengedaran yang bersih.
Hasil eksperimen
Para penyelidik menilai kaedah yang dicadangkan pada CelebA-64 dan CIFAR-10, yang kedua-duanya adalah garis dasar standard untuk penjanaan imej. Tujuan utama eksperimen adalah untuk memahami peranan jenis kerosakan.
Para penyelidik mula-mula cuba menggunakan bunyi kabur dan amplitud rendah untuk kerosakan. Keputusan menunjukkan bahawa model cadangan mereka mencapai keputusan SOTA pada CelebA, iaitu, skor FID 1.85, mengatasi semua kaedah lain yang hanya menambah hingar dan mungkin menskala semula imej. Di samping itu, skor FID yang diperoleh pada CIFAR-10 ialah 4.64, iaitu kompetitif walaupun tidak mencapai SOTA.

Selain itu, pada set data CIFAR-10 dan CelebA, kaedah penyelidik juga menunjukkan prestasi yang lebih baik pada metrik lain, masa pensampelan. Satu lagi faedah tambahan ialah kelebihan pengiraan yang ketara. Penyahkaburan (hampir tiada hingar) nampaknya merupakan manipulasi yang lebih cekap berbanding kaedah penyahhidratan penjanaan imej.
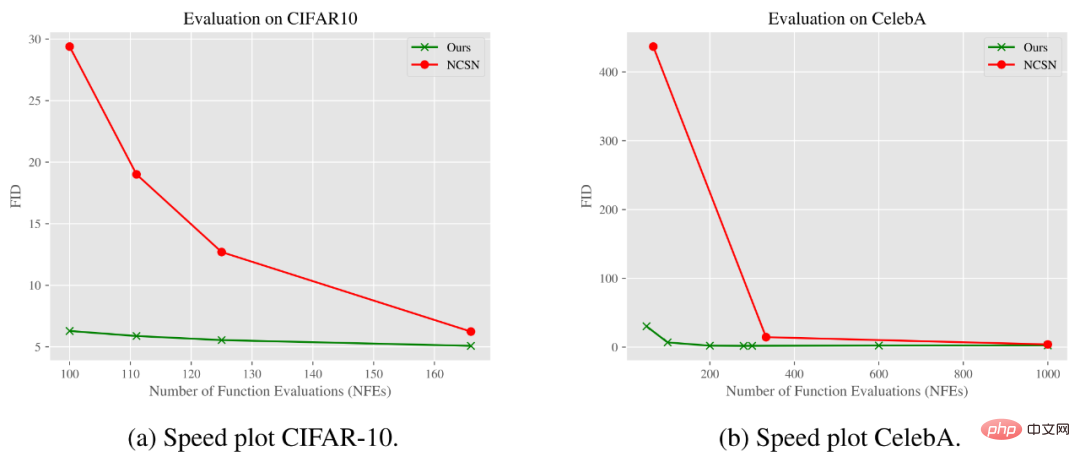
Graf di bawah menunjukkan cara skor FID berubah dengan Bilangan Penilaian Fungsi (NFE). Seperti yang dapat dilihat daripada keputusan, model kami boleh mencapai kualiti yang sama atau lebih baik daripada model penyebaran denoising Gaussian standard menggunakan langkah yang jauh lebih sedikit pada set data CIFAR-10 dan CelebA.
Atas ialah kandungan terperinci Resapan Lembut: Rangka kerja baharu Google menjadualkan, mempelajari dan membuat sampel dengan betul daripada proses resapan sejagat. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1384
1384
 52
52

 Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Perintah shutdown CentOS adalah penutupan, dan sintaks adalah tutup [pilihan] [maklumat]. Pilihan termasuk: -h menghentikan sistem dengan segera; -P mematikan kuasa selepas penutupan; -r mulakan semula; -T Waktu Menunggu. Masa boleh ditentukan sebagai segera (sekarang), minit (minit), atau masa tertentu (HH: mm). Maklumat tambahan boleh dipaparkan dalam mesej sistem.
 Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Dasar sandaran dan pemulihan Gitlab di bawah sistem CentOS untuk memastikan keselamatan data dan pemulihan, Gitlab pada CentOS menyediakan pelbagai kaedah sandaran. Artikel ini akan memperkenalkan beberapa kaedah sandaran biasa, parameter konfigurasi dan proses pemulihan secara terperinci untuk membantu anda menubuhkan strategi sandaran dan pemulihan GitLab lengkap. 1. Backup Manual Gunakan Gitlab-Rakegitlab: Backup: Buat Perintah untuk Melaksanakan Backup Manual. Perintah ini menyokong maklumat utama seperti repositori Gitlab, pangkalan data, pengguna, kumpulan pengguna, kunci, dan kebenaran. Fail sandaran lalai disimpan dalam direktori/var/opt/gitlab/sandaran. Anda boleh mengubah suai /etc /gitlab
 Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Panduan Lengkap untuk Memeriksa Konfigurasi HDFS Dalam Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk memeriksa konfigurasi dan menjalankan status HDFS secara berkesan pada sistem CentOS. Langkah -langkah berikut akan membantu anda memahami sepenuhnya persediaan dan operasi HDFS. Sahkan Pembolehubah Alam Sekitar Hadoop: Pertama, pastikan pembolehubah persekitaran Hadoop ditetapkan dengan betul. Di terminal, laksanakan arahan berikut untuk mengesahkan bahawa Hadoop dipasang dan dikonfigurasi dengan betul: Hadoopversion Semak fail konfigurasi HDFS: Fail konfigurasi teras HDFS terletak di/etc/hadoop/conf/direktori, di mana core-site.xml dan hdfs-site.xml adalah kritikal. gunakan
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
Memasang MySQL pada CentOS melibatkan langkah -langkah berikut: Menambah sumber MySQL YUM yang sesuai. Jalankan YUM Pasang Perintah MySQL-Server untuk memasang pelayan MySQL. Gunakan perintah mysql_secure_installation untuk membuat tetapan keselamatan, seperti menetapkan kata laluan pengguna root. Sesuaikan fail konfigurasi MySQL seperti yang diperlukan. Tune parameter MySQL dan mengoptimumkan pangkalan data untuk prestasi.
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 CentOS8 memulakan semula SSH
Apr 14, 2025 pm 09:00 PM
CentOS8 memulakan semula SSH
Apr 14, 2025 pm 09:00 PM
Perintah untuk memulakan semula perkhidmatan SSH ialah: Sistem Restart SSHD. Langkah -langkah terperinci: 1. Akses terminal dan sambungkan ke pelayan; 2. Masukkan arahan: SistemCtl Restart SSHD; 3. Sahkan Status Perkhidmatan: Status Sistem SSHD.
 Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Latihan yang diedarkan Pytorch pada sistem CentOS memerlukan langkah -langkah berikut: Pemasangan Pytorch: Premisnya ialah Python dan PIP dipasang dalam sistem CentOS. Bergantung pada versi CUDA anda, dapatkan arahan pemasangan yang sesuai dari laman web rasmi Pytorch. Untuk latihan CPU sahaja, anda boleh menggunakan arahan berikut: PipinstallToRchTorchVisionTorchaudio Jika anda memerlukan sokongan GPU, pastikan versi CUDA dan CUDNN yang sama dipasang dan gunakan versi pytorch yang sepadan untuk pemasangan. Konfigurasi Alam Sekitar Teragih: Latihan yang diedarkan biasanya memerlukan pelbagai mesin atau mesin berbilang mesin tunggal. Tempat
