

Secara amnya, kami menggunakan plot serakan untuk visualisasi kelompok, tetapi plot serakan tidak sesuai untuk menggambarkan beberapa algoritma pengelompokan, jadi dalam artikel ini, kami memperkenalkan cara menggunakan dendrogram ( Dendrogram) untuk menggambarkan hasil pengelompokan kami.
Dendrogram ialah gambar rajah yang menunjukkan hubungan hierarki antara objek, kumpulan atau pembolehubah. Dendrogram terdiri daripada cawangan yang disambungkan pada nod atau kelompok yang mewakili kumpulan pemerhatian dengan ciri yang serupa. Ketinggian cawangan atau jarak antara nod menunjukkan betapa berbeza atau serupa kumpulan itu. Iaitu, semakin panjang cawangan atau semakin jauh jarak antara nod, semakin kurang persamaan kumpulan tersebut. Semakin pendek cawangan atau semakin kecil jarak antara nod, semakin serupa kumpulan itu.
Dendogram berguna untuk menggambarkan struktur data yang kompleks dan mengenal pasti subkumpulan atau gugusan data dengan ciri yang serupa. Ia biasanya digunakan dalam biologi, genetik, ekologi, sains sosial dan bidang lain di mana data boleh dikumpulkan berdasarkan persamaan atau korelasi.
Latar Belakang:
Perkataan "dendrogram" berasal daripada perkataan Yunani "dendron" (pokok) dan "gramma" (lukisan). Pada tahun 1901, ahli matematik dan statistik British Karl Pearson menggunakan gambar rajah pokok untuk menunjukkan hubungan antara spesies tumbuhan yang berbeza. Dia memanggil graf ini sebagai "graf kluster." Ini boleh dianggap sebagai penggunaan pertama dendrogram.
Kami akan menggunakan harga saham sebenar beberapa syarikat untuk pengelompokan. Untuk akses mudah, data dikumpul menggunakan API percuma yang disediakan oleh Alpha Vantage. Alpha Vantage menyediakan API percuma dan API premium melalui API memerlukan kunci, sila rujuk tapak webnya.
import pandas as pd
import requests
companies={'Apple':'AAPL','Amazon':'AMZN','Facebook':'META','Tesla':'TSLA','Alphabet (Google)':'GOOGL','Shell':'SHEL','Suncor Energy':'SU',
'Exxon Mobil Corp':'XOM','Lululemon':'LULU','Walmart':'WMT','Carters':'CRI','Childrens Place':'PLCE','TJX Companies':'TJX',
'Victorias Secret':'VSCO','MACYs':'M','Wayfair':'W','Dollar Tree':'DLTR','CVS Caremark':'CVS','Walgreen':'WBA','Curaleaf':'CURLF'}Dua puluh syarikat telah dipilih merentas teknologi, runcit, minyak dan gas serta industri lain.
import time
all_data={}
for key,value in companies.items():
# Replace YOUR_API_KEY with your Alpha Vantage API key
url = f'https://www.alphavantage.co/query?function=TIME_SERIES_DAILY_ADJUSTED&symbol={value}&apikey=<YOUR_API_KEY>&outputsize=full'
response = requests.get(url)
data = response.json()
time.sleep(15)
if 'Time Series (Daily)' in data and data['Time Series (Daily)']:
df = pd.DataFrame.from_dict(data['Time Series (Daily)'], orient='index')
print(f'Received data for {key}')
else:
print("Time series data is empty or not available.")
df.rename(columns = {'1. open':key}, inplace = True)
all_data[key]=df[key]Kod di atas menetapkan jeda 15 saat antara panggilan API untuk memastikan ia tidak disekat terlalu kerap.
# find common dates among all data frames common_dates = None for df_key, df in all_data.items(): if common_dates is None: common_dates = set(df.index) else: common_dates = common_dates.intersection(df.index) common_dates = sorted(list(common_dates)) # create new data frame with common dates as index df_combined = pd.DataFrame(index=common_dates) # reindex each data frame with common dates and concatenate horizontally for df_key, df in all_data.items(): df_combined = pd.concat([df_combined, df.reindex(common_dates)], axis=1)
Integrate data di atas ke dalam DF yang kita perlukan, yang boleh digunakan terus di bawah
Hierarchical clustering clustering) ialah pengelompokan algoritma yang digunakan dalam pembelajaran mesin dan analisis data. Ia menggunakan hierarki kelompok bersarang untuk mengumpulkan objek yang serupa ke dalam kelompok berdasarkan persamaan. Algoritma boleh sama ada aglomeratif, yang bermula dengan objek tunggal dan menggabungkannya menjadi gugusan, atau pembahagi, yang bermula dengan gugusan besar dan membahagikannya secara rekursif kepada gugusan yang lebih kecil.
Perlu diambil perhatian bahawa bukan semua kaedah pengelompokan ialah kaedah pengelompokan hierarki dan dendrogram hanya boleh digunakan pada beberapa algoritma pengelompokan.
Algoritma Pengelompokan Kami akan menggunakan pengelompokan hierarki yang disediakan dalam modul scipy.
import numpy as np
import scipy.cluster.hierarchy as sch
import matplotlib.pyplot as plt
# Convert correlation matrix to distance matrix
dist_mat = 1 - df_combined.corr()
# Perform top-down clustering
clustering = sch.linkage(dist_mat, method='complete')
cuts = sch.cut_tree(clustering, n_clusters=[3, 4])
# Plot dendrogram
plt.figure(figsize=(10, 5))
sch.dendrogram(clustering, labels=list(df_combined.columns), leaf_rotation=90)
plt.title('Dendrogram of Company Correlations (Top-Down Clustering)')
plt.xlabel('Companies')
plt.ylabel('Distance')
plt.show()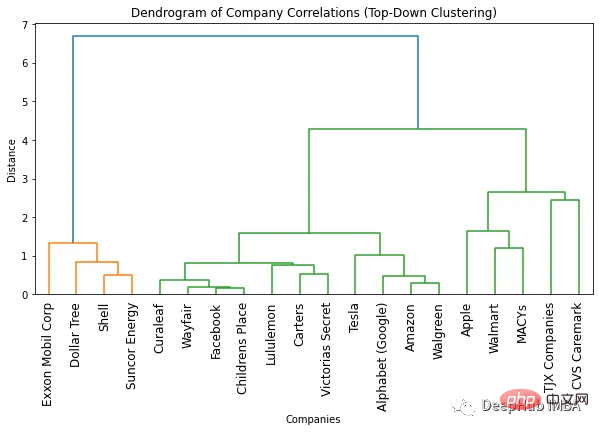
Cara paling mudah untuk mencari bilangan gugusan yang optimum adalah dengan melihat bilangan warna yang digunakan dalam dendrogram yang terhasil. Bilangan gugusan optimum adalah kurang satu daripada bilangan warna. Jadi mengikut dendrogram di atas, bilangan gugusan optimum ialah dua.
Cara lain untuk mencari bilangan gugusan yang optimum ialah dengan mengenal pasti titik di mana jarak antara gugusan tiba-tiba berubah. Ini dipanggil "titik lutut" atau "titik siku" dan boleh digunakan untuk menentukan bilangan gugusan yang paling baik menangkap variasi dalam data. Kita boleh lihat dalam rajah di atas bahawa perubahan jarak maksimum antara bilangan kluster yang berbeza berlaku antara 1 dan 2 kluster. Jadi sekali lagi, bilangan kluster yang optimum ialah dua.
Satu kelebihan menggunakan dendrogram ialah objek boleh dikelompokkan ke dalam sebarang bilangan gugusan dengan melihat dendrogram. Sebagai contoh, jika anda perlu mencari dua kluster, anda boleh melihat garis menegak atas pada dendrogram dan memutuskan kluster. Sebagai contoh, dalam contoh ini, jika dua kluster diperlukan, maka terdapat empat syarikat dalam kluster pertama dan 16 syarikat dalam kluster kedua. Jika kita memerlukan tiga kluster, kita boleh membahagikan kluster kedua kepada 11 dan 5 syarikat. Jika anda memerlukan lebih banyak lagi, anda boleh mengikuti contoh ini.
import numpy as np
import scipy.cluster.hierarchy as sch
import matplotlib.pyplot as plt
# Convert correlation matrix to distance matrix
dist_mat = 1 - df_combined.corr()
# Perform bottom-up clustering
clustering = sch.linkage(dist_mat, method='ward')
# Plot dendrogram
plt.figure(figsize=(10, 5))
sch.dendrogram(clustering, labels=list(df_combined.columns), leaf_rotation=90)
plt.title('Dendrogram of Company Correlations (Bottom-Up Clustering)')
plt.xlabel('Companies')
plt.ylabel('Distance')
plt.show()
Kami adalah pengelompokan bawah ke atas Dendrogram yang diperolehi oleh kelas adalah serupa dengan pengelompokan atas ke bawah. Bilangan gugusan optimum masih ada dua (berdasarkan bilangan warna dan kaedah "titik infleksi"). Tetapi jika kita memerlukan lebih banyak kluster, beberapa perbezaan halus akan diperhatikan. Ini adalah perkara biasa kerana kaedah yang digunakan adalah berbeza, menyebabkan sedikit perbezaan dalam keputusan.
Dendogram ialah alat yang berguna untuk menggambarkan struktur data yang kompleks dan mengenal pasti subkumpulan atau gugusan data dengan ciri yang serupa. Dalam artikel ini, kami menggunakan kaedah pengelompokan hierarki untuk menunjukkan cara mencipta dendrogram dan cara menentukan bilangan gugusan yang optimum. Untuk gambar rajah pepohon data kami membantu dalam memahami perhubungan antara syarikat yang berbeza, tetapi ia juga boleh digunakan dalam pelbagai bidang lain untuk memahami struktur hierarki data.
Atas ialah kandungan terperinci Visualisasi kelompok menggunakan dendrogram. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah alat pembangunan bahasa Cina visual PHP?
Apakah alat pembangunan bahasa Cina visual PHP?
 Apa yang perlu dilakukan jika kod skrin biru 0x0000007e berlaku
Apa yang perlu dilakukan jika kod skrin biru 0x0000007e berlaku
 Semak sama ada port dibuka dalam linux
Semak sama ada port dibuka dalam linux
 Bagaimana untuk memusatkan teks div secara menegak
Bagaimana untuk memusatkan teks div secara menegak
 Pengenalan kepada kekunci pintasan tangkapan skrin dalam sistem Windows 7
Pengenalan kepada kekunci pintasan tangkapan skrin dalam sistem Windows 7
 Bagaimana untuk berpakaian Douyin Xiaohuoren
Bagaimana untuk berpakaian Douyin Xiaohuoren
 Pesanan yang disyorkan untuk mempelajari bahasa c++ dan c
Pesanan yang disyorkan untuk mempelajari bahasa c++ dan c
 Adakah kadar inflasi mempunyai kesan ke atas mata wang digital?
Adakah kadar inflasi mempunyai kesan ke atas mata wang digital?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



