


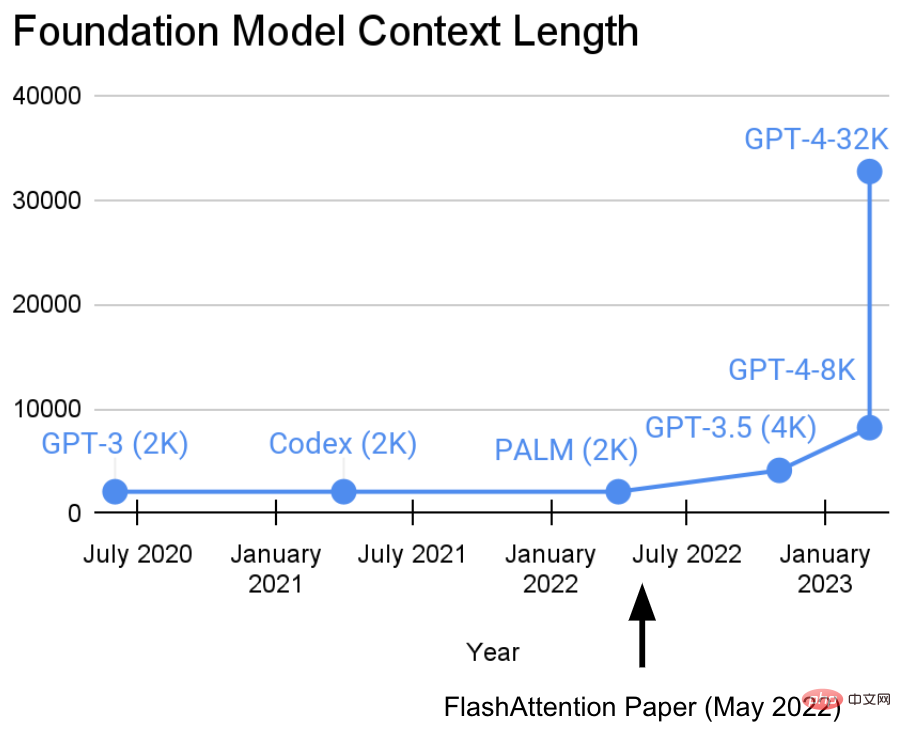
Dalam dua tahun yang lalu, Makmal Penyelidikan Hazy di Universiti Stanford telah terlibat dalam kerja penting: Meningkatkan panjang jujukan .
Mereka mempunyai pandangan: urutan yang lebih panjang akan membawa kepada era baharu model pembelajaran mesin asas - model yang boleh belajar daripada konteks yang lebih panjang dan pelbagai sumber media, kompleks demonstrasi, dsb. untuk belajar.Pada masa ini, penyelidikan ini telah mencapai kemajuan baharu. Tri Dao dan Dan Fu dari makmal Penyelidikan Hazy mengetuai penyelidikan dan promosi algoritma FlashAttention Mereka membuktikan bahawa panjang jujukan 32k adalah mungkin dan akan digunakan secara meluas dalam era model asas semasa (OpenAI, Microsoft, NVIDIA dan syarikat lain. model menggunakan algoritma FlashAttention).
Dalam artikel ini, penulis memperkenalkan kaedah baharu untuk menambah panjang jujukan pada tahap tinggi dan menyediakan "jambatan" kepada set primitif baharu.
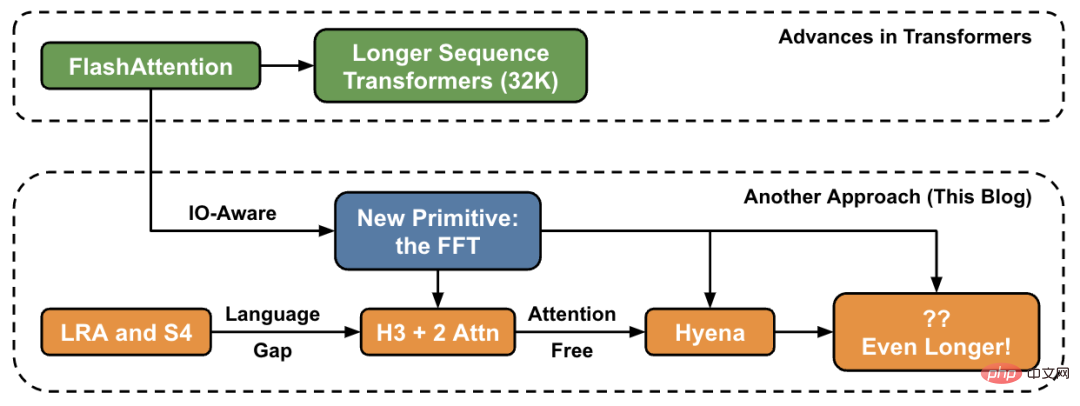
Di makmal Penyelidikan Hazy, kerja ini bermula dengan Hippo, kemudian S4, H3, dan kini Hyena. Model ini berpotensi untuk mengendalikan panjang konteks dalam berjuta-juta malah berbilion-bilion.
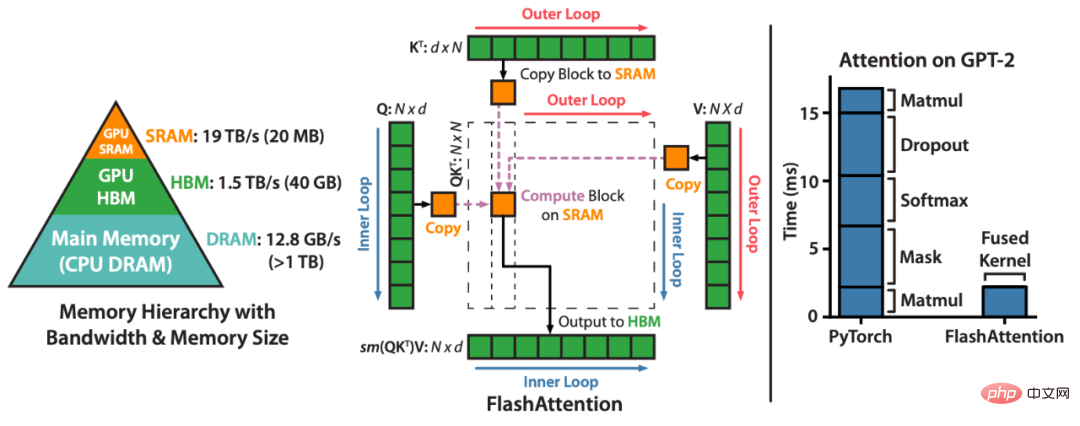
FlashAttention mempercepatkan perhatian dan mengurangkan jejak ingatannya - tanpa sebarang anggaran. "Sejak kami mengeluarkan FlashAttention 6 bulan yang lalu, kami teruja melihat banyak organisasi dan makmal penyelidikan menggunakan FlashAttention untuk mempercepatkan latihan dan inferens mereka," catatan blog itu berbunyi.FlashAttention ialah kaedah yang menyusun semula pengiraan perhatian dan memanfaatkan teknik klasik (jubin, pengiraan semula) untuk mempercepat dan mengurangkan penggunaan memori daripada kuadratik kepada linear dalam algoritma panjang jujukan. Untuk setiap kepala perhatian, untuk mengurangkan bacaan/tulisan memori, FlashAttention menggunakan teknik jubin klasik untuk memuatkan pertanyaan, kunci dan blok nilai daripada GPU HBM (memori utamanya) ke SRAM (cache pantasnya), mengira perhatian dan menulis output kembali kepada HBM. Pengurangan dalam ingatan membaca/menulis menghasilkan kelajuan yang ketara (2-4x) dalam kebanyakan kes.
Penyelidik di Google melancarkan penanda aras Arena Jarak Jauh (LRA) pada tahun 2020 untuk menilai sejauh mana model yang berbeza mengendalikan kebergantungan jarak jauh. LRA mampu menguji pelbagai tugasan yang meliputi pelbagai jenis dan modaliti data yang berbeza, seperti teks, imej dan ungkapan matematik, dengan panjang jujukan sehingga 16K (Laluan-X: Pengelasan imej terbentang ke dalam piksel tanpa sebarang bias generalisasi spatial). Terdapat banyak kerja hebat untuk menskalakan Transformer kepada jujukan yang lebih panjang, tetapi banyak daripadanya seolah-olah mengorbankan ketepatan (seperti yang ditunjukkan dalam imej di bawah). Perhatikan lajur Path-X: semua kaedah Transformer dan variannya berprestasi lebih teruk daripada meneka rawak. Sekarang mari kita mengenali S4, yang dibangunkan oleh Albert Gu. Diilhamkan oleh hasil penanda aras LRA, Albert Gu ingin mengetahui cara untuk memodelkan kebergantungan jarak jauh dengan lebih baik Berdasarkan penyelidikan jangka panjang tentang hubungan antara polinomial ortogon dan model rekursif dan model konvolusi, beliau melancarkan S4—— Model jujukan baharu. berdasarkan model ruang keadaan berstruktur (SSM). Intinya ialah kerumitan masa SSM apabila memanjangkan urutan panjang N hingga 2N ialah Selain itu, apabila Hazy Research mengeluarkan FlashAttention, sudah mungkin untuk meningkatkan panjang jujukan Transformer. Mereka juga mendapati Transformer juga mencapai prestasi unggul pada Path-X (63%) hanya dengan meningkatkan panjang jujukan kepada 16K. Tetapi terdapat jurang dalam kualiti pemodelan bahasa dalam S4 setinggi 5% kebingungan (untuk konteks, ini adalah model 125M dan 6.7 B jurang antara model). Untuk merapatkan jurang ini, penyelidik telah mengkaji bahasa sintetik seperti ingatan bersekutu untuk menentukan sifat yang perlu dimiliki oleh bahasa. Reka bentuk akhir ialah H3 (Hungry Hungry Hippos): lapisan baharu yang menyusun dua SSM dan mendarabkan outputnya dengan get pendaraban. Menggunakan H3, penyelidik di Hazy Research menggantikan hampir semua lapisan perhatian dalam Transformer gaya GPT dan dapat mencapai kebingungan yang lebih tinggi dan Setanding dengan transformer dari segi penilaian hiliran. Tanda Aras Arena Jarak Jauh dan S4
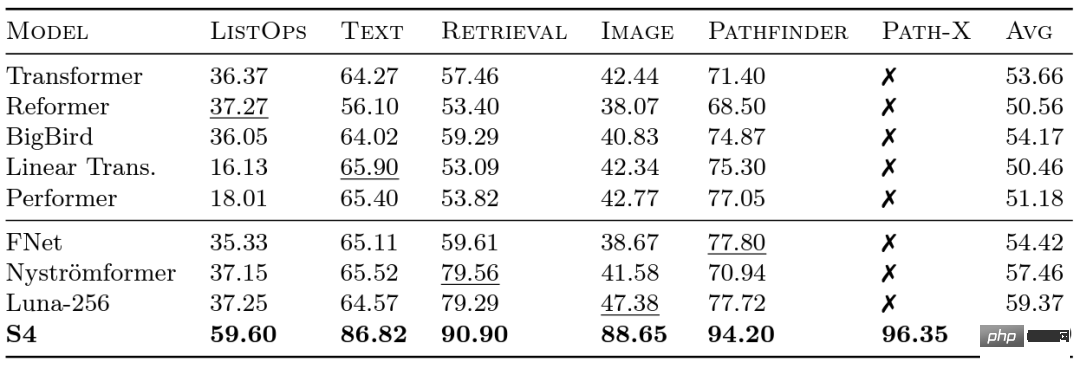
 , tidak seperti perhatian Mekanisme ini juga berkembang pada aras persegi! S4 berjaya memodelkan kebergantungan jarak jauh dalam LRA dan menjadi model pertama yang mencapai prestasi melebihi purata pada Path-X (kini mencapai ketepatan 96.4%!). Sejak keluaran S4, ramai penyelidik telah membangun dan berinovasi atas dasar ini, dengan model baharu seperti model S5 pasukan Scott Linderman, DSS Ankit Gupta (dan makmal Penyelidikan Hazy S4D berikutnya), Hasani dan Lechner's Liquid-S4, dll. Model.
, tidak seperti perhatian Mekanisme ini juga berkembang pada aras persegi! S4 berjaya memodelkan kebergantungan jarak jauh dalam LRA dan menjadi model pertama yang mencapai prestasi melebihi purata pada Path-X (kini mencapai ketepatan 96.4%!). Sejak keluaran S4, ramai penyelidik telah membangun dan berinovasi atas dasar ini, dengan model baharu seperti model S5 pasukan Scott Linderman, DSS Ankit Gupta (dan makmal Penyelidikan Hazy S4D berikutnya), Hasani dan Lechner's Liquid-S4, dll. Model. Kekurangan dalam pemodelan
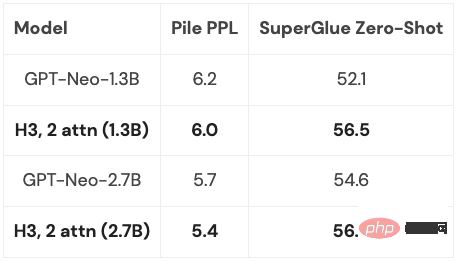
Oleh kerana lapisan H3 dibina pada SSM, kerumitan pengiraannya juga tinggi dari segi panjang jujukan . Berkembang pada kadar  . Dua lapisan perhatian menjadikan kerumitan keseluruhan model masih
. Dua lapisan perhatian menjadikan kerumitan keseluruhan model masih
 Isu ini akan dibincangkan secara terperinci kemudian.
Isu ini akan dibincangkan secara terperinci kemudian.
Sudah tentu, Hazy Research bukan satu-satunya yang mempertimbangkan arah ini: GSS juga mendapati bahawa SSM dengan gating boleh berfungsi dengan baik dengan perhatian dalam pemodelan bahasa (H3 yang diilhamkan ini), Meta mengeluarkan model The Mega, yang juga menggabungkan SSM dan perhatian, model BiGS menggantikan perhatian dalam model gaya BERT, dan RWKV telah mengusahakan pendekatan bergelung sepenuhnya.
Berdasarkan siri kerja terdahulu, penyelidik di Hazy Research mendapat inspirasi untuk membangunkan seni bina baharu: Hyena. Mereka cuba menyingkirkan dua lapisan perhatian terakhir dalam H3 dan mendapatkan model yang tumbuh hampir secara linear untuk panjang jujukan yang lebih panjang. Ternyata dua idea mudah adalah kunci untuk mencari jawapan:
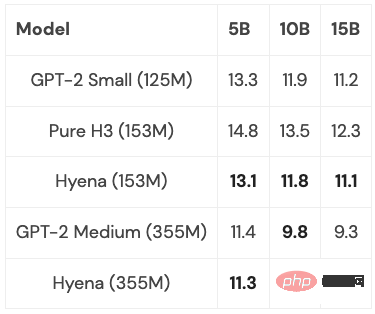
Apa yang masih perlu dipertimbangkan ialah, sejauh manakah model ini boleh digeneralisasikan? Adakah mungkin untuk menskalakannya kepada saiz penuh PILE (400B token)? Apakah yang akan berlaku jika anda menggabungkan idea terbaik H3 dan Hyena, dan sejauh mana ia boleh pergi?
FFT atau pendekatan yang lebih asas?
Dalam semua model ini, operasi asas yang biasa ialah FFT, yang merupakan cara yang cekap untuk mengira lilitan dan hanya mengambil masa O (NlogN). Walau bagaimanapun, FFT kurang disokong pada perkakasan moden dengan seni bina yang dominan ialah unit pendaraban matriks khusus dan GEMM (cth. teras tensor pada GPU NVIDIA).Jurang kecekapan boleh ditutup dengan menulis semula FFT sebagai satu siri operasi pendaraban matriks. Ahli pasukan penyelidik mencapai matlamat ini dengan menggunakan matriks rama-rama untuk meneroka latihan yang jarang. Baru-baru ini, penyelidik Hazy Research telah memanfaatkan sambungan ini untuk membina algoritma lilitan pantas seperti FlashConv dan FlashButterfly, dengan menggunakan penguraian rama-rama untuk mengubah pengiraan FFT kepada satu siri operasi pendaraban matriks.
Tambahan pula, sambungan yang lebih mendalam boleh dibuat dengan menggunakan kerja sebelumnya: termasuk membiarkan matriks ini dipelajari, yang juga mengambil masa yang sama tetapi menambah parameter tambahan. Penyelidik telah mula meneroka sambungan ini pada beberapa set data kecil dan telah mencapai keputusan awal. Kita boleh melihat dengan jelas apa yang boleh ditimbulkan oleh sambungan ini (mis. cara menjadikannya terpakai pada model bahasa):

Ini adalah arah yang menarik, dan perkara yang akan menyusul ialah urutan yang lebih panjang dan lebih panjang serta seni bina baharu yang membolehkan kami menerokai kawasan baharu ini dengan lebih lanjut. Kami perlu memberi perhatian khusus kepada aplikasi yang boleh mendapat manfaat daripada model jujukan panjang, seperti pengimejan resolusi tinggi, format data baharu, model bahasa yang boleh membaca keseluruhan buku, dsb. Bayangkan memberikan keseluruhan buku kepada model bahasa untuk dibaca dan meringkaskan jalan cerita, atau mempunyai model penjanaan kod menjana kod baharu berdasarkan kod yang anda tulis. Terdapat begitu banyak senario yang mungkin, dan semuanya sangat menarik.
Atas ialah kandungan terperinci Mahu memindahkan separuh daripada 'A Dream of Red Mansions' ke dalam kotak input ChatGPT? Jom selesaikan masalah ini dahulu. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk menyelesaikan masalah bahawa pintasan IE tidak boleh dipadamkan
Bagaimana untuk menyelesaikan masalah bahawa pintasan IE tidak boleh dipadamkan
 Akhiran nama fail pengubahsuaian kelompok Linux
Akhiran nama fail pengubahsuaian kelompok Linux
 Tiada pilihan WLAN dalam win11
Tiada pilihan WLAN dalam win11
 WeChat gagal memuatkan data
WeChat gagal memuatkan data
 Sebab utama mengapa komputer menggunakan binari
Sebab utama mengapa komputer menggunakan binari
 Apakah maksud pelayan web?
Apakah maksud pelayan web?
 Cara menggunakan pembuka kunci
Cara menggunakan pembuka kunci
 Bagaimana untuk memulihkan data dari cakera keras mudah alih
Bagaimana untuk memulihkan data dari cakera keras mudah alih








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



