
 pembangunan bahagian belakang
Tutorial Python
Pandas dan PySpark bergabung tenaga untuk mencapai kedua-dua fungsi dan kelajuan!
pembangunan bahagian belakang
Tutorial Python
Pandas dan PySpark bergabung tenaga untuk mencapai kedua-dua fungsi dan kelajuan!
Pandas dan PySpark bergabung tenaga untuk mencapai kedua-dua fungsi dan kelajuan!

Ahli sains data atau pengamal data yang menggunakan Python untuk pemprosesan data tidak asing dengan panda pakej sains data Terdapat juga pengguna panda berat seperti Yun Duojun Baris pertama kod yang ditulis pada permulaan projek kebanyakannya mengimport panda sebagai pd. Panda boleh dikatakan yyd untuk pemprosesan data! Dan kelemahannya juga sangat jelas Panda hanya boleh diproses pada satu mesin, dan ia tidak boleh menskala secara linear dengan jumlah data. Sebagai contoh, jika panda cuba membaca set data yang lebih besar daripada memori tersedia mesin, ia akan gagal kerana memori tidak mencukupi.
Selain itu, panda sangat lambat dalam memproses data yang besar Walaupun terdapat perpustakaan lain seperti Dask atau Vaex untuk mengoptimumkan dan meningkatkan kelajuan pemprosesan data, ia adalah sekeping kek di hadapan Spark, rangka kerja dewa. pemprosesan data besar.
Nasib baik, dalam versi Spark 3.2 baharu, API Pandas baharu telah muncul, yang menyepadukan kebanyakan fungsi panda ke dalam PySpark Menggunakan antara muka panda, anda boleh menggunakan Spark, kerana Spark mempunyai API Pandas menggunakan Spark di latar belakang, supaya ia dapat mencapai kesan kerjasama yang kuat, yang boleh dikatakan sangat berkuasa dan sangat mudah.
Semuanya bermula di Spark + AI Summit 2019. Koala ialah projek sumber terbuka yang menggunakan Panda di atas Spark. Pada mulanya, ia hanya meliputi sebahagian kecil daripada fungsi Panda, tetapi saiznya beransur-ansur berkembang. Kini, dalam versi Spark 3.2 baharu, Koala telah digabungkan menjadi PySpark.
Spark kini menyepadukan API Pandas, supaya anda boleh menjalankan Pandas pada Spark. Kita hanya perlu menukar satu baris kod:
import pyspark.pandas as ps
Daripada ini kita boleh mendapat banyak kelebihan:
- Jika kita biasa menggunakan Python dan Panda, tetapi tidak biasa dengan Spark, kita boleh meninggalkan kerumitan Mula menggunakan PySpark dengan segera untuk proses pembelajaran anda.
- Satu pangkalan kod boleh digunakan untuk semua perkara: data kecil dan besar, mesin tunggal dan teragih.
- Anda boleh menjalankan kod Pandas dengan lebih pantas pada rangka kerja yang diedarkan Spark.
Perkara terakhir amat perlu diberi perhatian.
Di satu pihak, pengkomputeran teragih boleh digunakan pada kod dalam Panda. Dan dengan enjin Spark, kod anda akan menjadi lebih pantas walaupun pada satu mesin! Graf di bawah menunjukkan perbandingan prestasi antara menjalankan Spark pada mesin dengan memori 96 vCPU dan 384 GiB dan memanggil panda sahaja untuk menganalisis set data CSV 130GB.
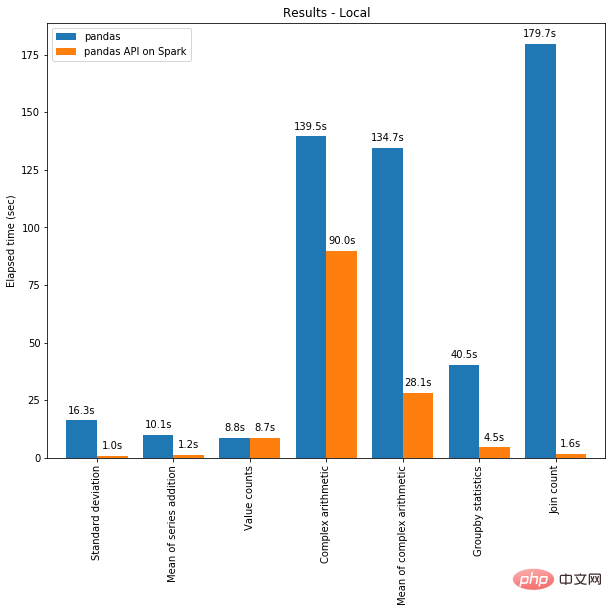
Berbilang rangkaian dan Spark SQL Catalyst Optimizer kedua-duanya membantu mengoptimumkan prestasi. Sebagai contoh, operasi kiraan Sertai adalah 4x lebih pantas dengan penjanaan kod merentas seluruh peringkat: 5.9 saat tanpa penjanaan kod dan 1.6 saat dengan penjanaan kod.
Spark mempunyai kelebihan yang ketara terutamanya dalam operasi rantaian. Pengoptimum pertanyaan Catalyst mengiktiraf penapis untuk menapis data secara bijak dan boleh menggunakan cantuman berasaskan cakera, manakala Pandas lebih suka memuatkan semua data ke dalam memori pada setiap langkah.
Tidak sabar untuk mencuba cara menulis beberapa kod menggunakan API Pandas pada Spark? Jom mulakan sekarang!
Bertukar antara Panda / Pandas-on-Spark / Spark
Perkara pertama yang perlu diketahui ialah apa sebenarnya yang kami gunakan. Apabila menggunakan Panda, gunakan kelas pandas.core.frame.DataFrame. Apabila menggunakan API panda dalam Spark, gunakan pyspark.pandas.frame.DataFrame. Walaupun kedua-duanya serupa, mereka tidak sama. Perbezaan utama ialah yang pertama berada dalam satu mesin, manakala yang kedua diedarkan.
Anda boleh menggunakan Pandas-on-Spark untuk mencipta Dataframe dan menukarnya kepada Panda dan sebaliknya:
# import Pandas-on-Spark import pyspark.pandas as ps # 使用 Pandas-on-Spark 创建一个 DataFrame ps_df = ps.DataFrame(range(10)) # 将 Pandas-on-Spark Dataframe 转换为 Pandas Dataframe pd_df = ps_df.to_pandas() # 将 Pandas Dataframe 转换为 Pandas-on-Spark Dataframe ps_df = ps.from_pandas(pd_df)
Perhatikan bahawa jika anda menggunakan berbilang mesin, anda perlu menggunakan Pandas- on-Spark sebelum menukarnya kepada Pandas Apabila menukar Spark Dataframe kepada Pandas Dataframe, data dipindahkan daripada berbilang mesin kepada satu mesin dan begitu juga sebaliknya (lihat Panduan PySpark [1]).
Anda juga boleh menukar Bingkai Data Pandas-on-Spark kepada Bingkai Data Spark dan begitu juga sebaliknya:
# 使用 Pandas-on-Spark 创建一个 DataFrame ps_df = ps.DataFrame(range(10)) # 将 Pandas-on-Spark Dataframe 转换为 Spark Dataframe spark_df = ps_df.to_spark() # 将 Spark Dataframe 转换为 Pandas-on-Spark Dataframe ps_df_new = spark_df.to_pandas_on_spark()
Bagaimanakah jenis data berubah?
Jenis data pada asasnya adalah sama apabila menggunakan Pandas-on-Spark dan Panda. Apabila menukar Pandas-on-Spark DataFrame kepada Spark DataFrame, jenis data ditukar secara automatik kepada jenis yang sesuai (lihat Panduan PySpark [2])
Contoh berikut menunjukkan cara data ditukar apabila menukar Jenis penukaran daripada PySpark DataFrame kepada panda-on-Spark DataFrame.
>>> sdf = spark.createDataFrame([ ... (1, Decimal(1.0), 1., 1., 1, 1, 1, datetime(2020, 10, 27), "1", True, datetime(2020, 10, 27)), ... ], 'tinyint tinyint, decimal decimal, float float, double double, integer integer, long long, short short, timestamp timestamp, string string, boolean boolean, date date') >>> sdf
DataFrame[tinyint: tinyint, decimal: decimal(10,0), float: float, double: double, integer: int, long: bigint, short: smallint, timestamp: timestamp, string: string, boolean: boolean, date: date]
psdf = sdf.pandas_api() psdf.dtypes
tinyintint8 decimalobject float float32 doublefloat64 integer int32 longint64 short int16 timestampdatetime64[ns] string object booleanbool date object dtype: object
Fungsi Pandas-on-Spark vs Spark
Frame Data dalam Spark dan fungsi yang paling biasa digunakan dalam Pandas-on-Spark. Ambil perhatian bahawa satu-satunya perbezaan sintaks antara Pandas-on-Spark dan Pandas ialah import pyspark.pandas sebagai baris ps.
当你看完如下内容后,你会发现,即使您不熟悉 Spark,也可以通过 Pandas API 轻松使用。
导入库
# 运行Spark
from pyspark.sql import SparkSession
spark = SparkSession.builder
.appName("Spark")
.getOrCreate()
# 在Spark上运行Pandas
import pyspark.pandas as ps读取数据
以 old dog iris 数据集为例。
# SPARK
sdf = spark.read.options(inferSchema='True',
header='True').csv('iris.csv')
# PANDAS-ON-SPARK
pdf = ps.read_csv('iris.csv')选择
# SPARK
sdf.select("sepal_length","sepal_width").show()
# PANDAS-ON-SPARK
pdf[["sepal_length","sepal_width"]].head()删除列
# SPARK
sdf.drop('sepal_length').show()# PANDAS-ON-SPARK
pdf.drop('sepal_length').head()删除重复项
# SPARK sdf.dropDuplicates(["sepal_length","sepal_width"]).show() # PANDAS-ON-SPARK pdf[["sepal_length", "sepal_width"]].drop_duplicates()
筛选
# SPARK sdf.filter( (sdf.flower_type == "Iris-setosa") & (sdf.petal_length > 1.5) ).show() # PANDAS-ON-SPARK pdf.loc[ (pdf.flower_type == "Iris-setosa") & (pdf.petal_length > 1.5) ].head()
计数
# SPARK sdf.filter(sdf.flower_type == "Iris-virginica").count() # PANDAS-ON-SPARK pdf.loc[pdf.flower_type == "Iris-virginica"].count()
唯一值
# SPARK
sdf.select("flower_type").distinct().show()
# PANDAS-ON-SPARK
pdf["flower_type"].unique()排序
# SPARK
sdf.sort("sepal_length", "sepal_width").show()
# PANDAS-ON-SPARK
pdf.sort_values(["sepal_length", "sepal_width"]).head()分组
# SPARK
sdf.groupBy("flower_type").count().show()
# PANDAS-ON-SPARK
pdf.groupby("flower_type").count()替换
# SPARK
sdf.replace("Iris-setosa", "setosa").show()
# PANDAS-ON-SPARK
pdf.replace("Iris-setosa", "setosa").head()连接
#SPARK sdf.union(sdf) # PANDAS-ON-SPARK pdf.append(pdf)
transform 和 apply 函数应用
有许多 API 允许用户针对 pandas-on-Spark DataFrame 应用函数,例如:
DataFrame.transform() DataFrame.apply() DataFrame.pandas_on_spark.transform_batch() DataFrame.pandas_on_spark.apply_batch() Series.pandas_on_spark.transform_batch()
每个 API 都有不同的用途,并且在内部工作方式不同。
transform 和 apply
DataFrame.transform()和DataFrame.apply()之间的主要区别在于,前者需要返回相同长度的输入,而后者不需要。
# transform
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pser):
return pser + 1# 应该总是返回与输入相同的长度。
psdf.transform(pandas_plus)
# apply
psdf = ps.DataFrame({'a': [1,2,3], 'b':[5,6,7]})
def pandas_plus(pser):
return pser[pser % 2 == 1]# 允许任意长度
psdf.apply(pandas_plus)在这种情况下,每个函数采用一个 pandas Series,Spark 上的 pandas API 以分布式方式计算函数,如下所示。
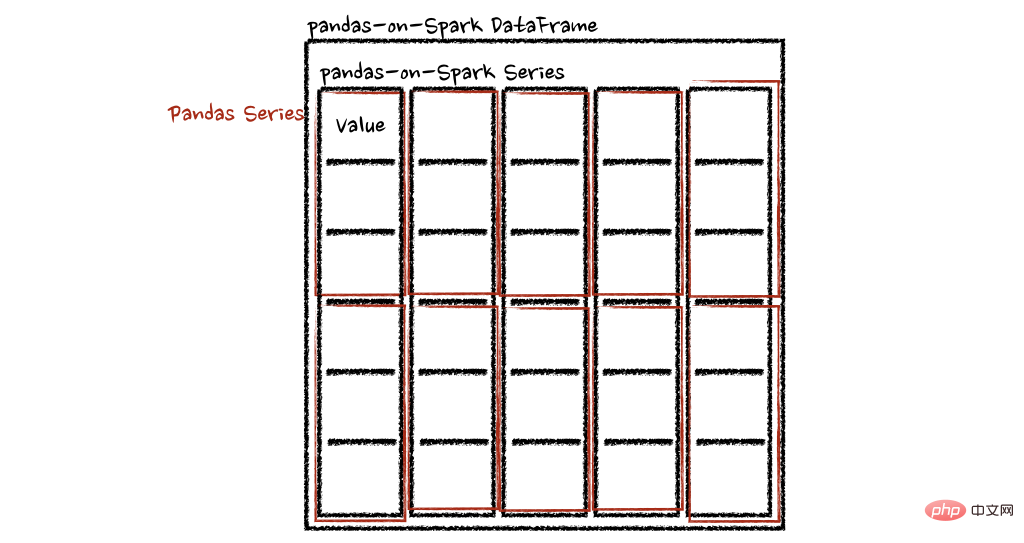
在“列”轴的情况下,该函数将每一行作为一个熊猫系列。
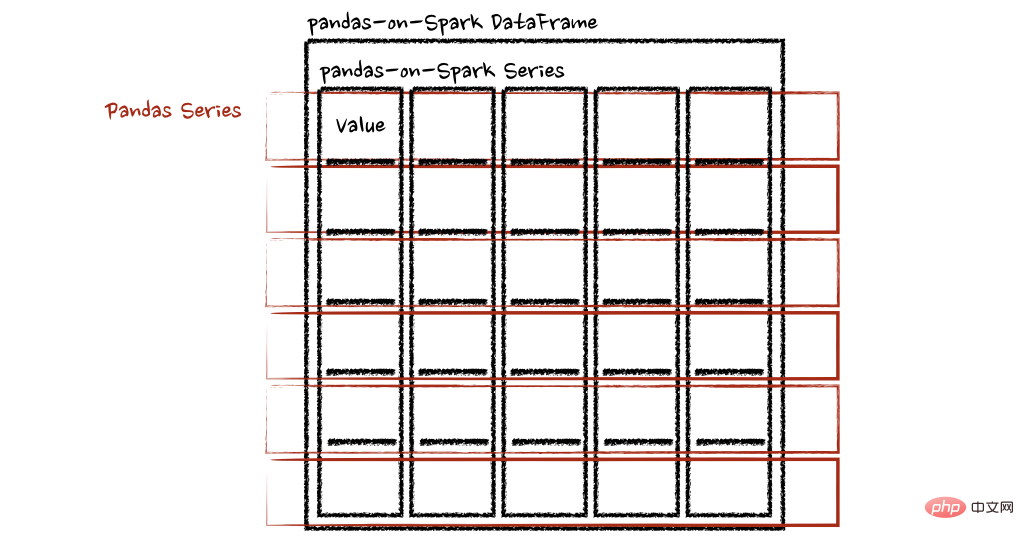
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pser):
return sum(pser)# 允许任意长度
psdf.apply(pandas_plus, axis='columns')上面的示例将每一行的总和计算为pands Series
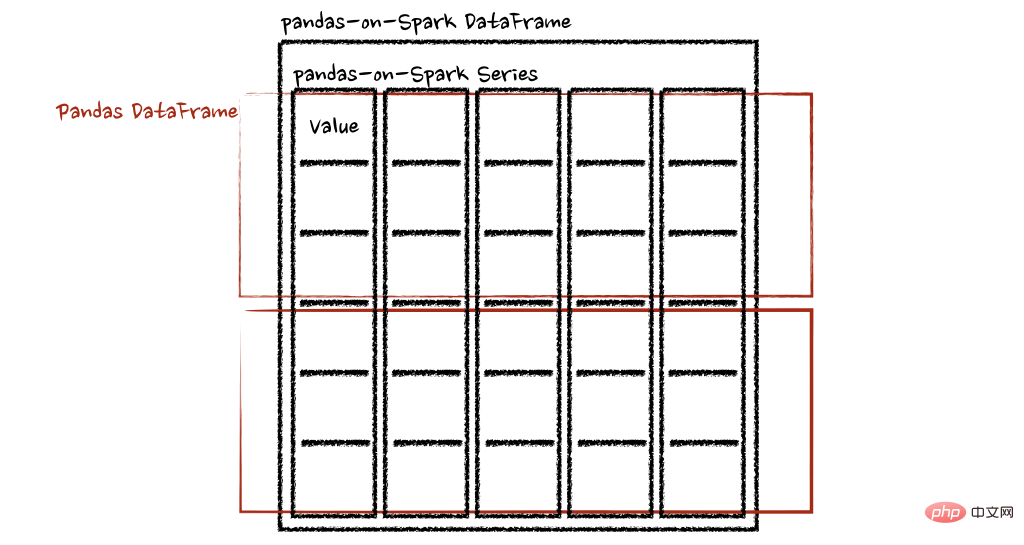
pandas_on_spark.transform_batch和pandas_on_spark.apply_batch
batch 后缀表示 pandas-on-Spark DataFrame 或 Series 中的每个块。API 对 pandas-on-Spark DataFrame 或 Series 进行切片,然后以 pandas DataFrame 或 Series 作为输入和输出应用给定函数。请参阅以下示例:
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pdf):
return pdf + 1# 应该总是返回与输入相同的长度。
psdf.pandas_on_spark.transform_batch(pandas_plus)
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pdf):
return pdf[pdf.a > 1]# 允许任意长度
psdf.pandas_on_spark.apply_batch(pandas_plus)两个示例中的函数都将 pandas DataFrame 作为 pandas-on-Spark DataFrame 的一个块,并输出一个 pandas DataFrame。Spark 上的 Pandas API 将 pandas 数据帧组合为 pandas-on-Spark 数据帧。
在 Spark 上使用 pandas API的注意事项
避免shuffle
某些操作,例如sort_values在并行或分布式环境中比在单台机器上的内存中更难完成,因为它需要将数据发送到其他节点,并通过网络在多个节点之间交换数据。
避免在单个分区上计算
另一种常见情况是在单个分区上进行计算。目前, DataFrame.rank 等一些 API 使用 PySpark 的 Window 而不指定分区规范。这会将所有数据移动到单个机器中的单个分区中,并可能导致严重的性能下降。对于非常大的数据集,应避免使用此类 API。
不要使用重复的列名
不允许使用重复的列名,因为 Spark SQL 通常不允许这样做。Spark 上的 Pandas API 继承了这种行为。例如,见下文:
import pyspark.pandas as ps
psdf = ps.DataFrame({'a': [1, 2], 'b':[3, 4]})
psdf.columns = ["a", "a"]Reference 'a' is ambiguous, could be: a, a.;
此外,强烈建议不要使用区分大小写的列名。Spark 上的 Pandas API 默认不允许它。
import pyspark.pandas as ps
psdf = ps.DataFrame({'a': [1, 2], 'A':[3, 4]})Reference 'a' is ambiguous, could be: a, a.;
但可以在 Spark 配置spark.sql.caseSensitive中打开以启用它,但需要自己承担风险。
from pyspark.sql import SparkSession
builder = SparkSession.builder.appName("pandas-on-spark")
builder = builder.config("spark.sql.caseSensitive", "true")
builder.getOrCreate()
import pyspark.pandas as ps
psdf = ps.DataFrame({'a': [1, 2], 'A':[3, 4]})
psdfaA 013 124
使用默认索引
pandas-on-Spark 用户面临的一个常见问题是默认索引导致性能下降。当索引未知时,Spark 上的 Pandas API 会附加一个默认索引,例如 Spark DataFrame 直接转换为 pandas-on-Spark DataFrame。
如果计划在生产中处理大数据,请通过将默认索引配置为distributed或distributed-sequence来使其确保为分布式。
有关配置默认索引的更多详细信息,请参阅默认索引类型[3]。
在 Spark 上使用 pandas API
尽管 Spark 上的 pandas API 具有大部分与 pandas 等效的 API,但仍有一些 API 尚未实现或明确不受支持。因此尽可能直接在 Spark 上使用 pandas API。
例如,Spark 上的 pandas API 没有实现__iter__(),阻止用户将所有数据从整个集群收集到客户端(驱动程序)端。不幸的是,许多外部 API,例如 min、max、sum 等 Python 的内置函数,都要求给定参数是可迭代的。对于 pandas,它开箱即用,如下所示:
>>> import pandas as pd >>> max(pd.Series([1, 2, 3])) 3 >>> min(pd.Series([1, 2, 3])) 1 >>> sum(pd.Series([1, 2, 3])) 6
Pandas 数据集存在于单台机器中,自然可以在同一台机器内进行本地迭代。但是,pandas-on-Spark 数据集存在于多台机器上,并且它们是以分布式方式计算的。很难在本地迭代,很可能用户在不知情的情况下将整个数据收集到客户端。因此,最好坚持使用 pandas-on-Spark API。上面的例子可以转换如下:
>>> import pyspark.pandas as ps >>> ps.Series([1, 2, 3]).max() 3 >>> ps.Series([1, 2, 3]).min() 1 >>> ps.Series([1, 2, 3]).sum() 6
pandas 用户的另一个常见模式可能是依赖列表推导式或生成器表达式。但是,它还假设数据集在引擎盖下是本地可迭代的。因此,它可以在 pandas 中无缝运行,如下所示:
import pandas as pd data = [] countries = ['London', 'New York', 'Helsinki'] pser = pd.Series([20., 21., 12.], index=countries) for temperature in pser: assert temperature > 0 if temperature > 1000: temperature = None data.append(temperature ** 2) pd.Series(data, index=countries)
London400.0 New York441.0 Helsinki144.0 dtype: float64
但是,对于 Spark 上的 pandas API,它的工作原理与上述相同。上面的示例也可以更改为直接使用 pandas-on-Spark API,如下所示:
import pyspark.pandas as ps import numpy as np countries = ['London', 'New York', 'Helsinki'] psser = ps.Series([20., 21., 12.], index=countries) def square(temperature) -> np.float64: assert temperature > 0 if temperature > 1000: temperature = None return temperature ** 2 psser.apply(square)
London400.0 New York441.0 Helsinki144.0
减少对不同 DataFrame 的操作
Spark 上的 Pandas API 默认不允许对不同 DataFrame(或 Series)进行操作,以防止昂贵的操作。只要有可能,就应该避免这种操作。
写在最后
到目前为止,我们将能够在 Spark 上使用 Pandas。这将会导致Pandas 速度的大大提高,迁移到 Spark 时学习曲线的减少,以及单机计算和分布式计算在同一代码库中的合并。
参考资料
[1]PySpark 指南: https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/pandas_pyspark.html
[2]PySpark 指南: https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/types.html
[3]默认索引类型: https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/options.html#default-index-type
Atas ialah kandungan terperinci Pandas dan PySpark bergabung tenaga untuk mencapai kedua-dua fungsi dan kelajuan!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Menyelesaikan masalah pemasangan panda biasa: tafsiran dan penyelesaian kepada ralat pemasangan
Feb 19, 2024 am 09:19 AM
Menyelesaikan masalah pemasangan panda biasa: tafsiran dan penyelesaian kepada ralat pemasangan
Feb 19, 2024 am 09:19 AM
Tutorial pemasangan Pandas: Analisis ralat pemasangan biasa dan penyelesaiannya, contoh kod khusus diperlukan Pengenalan: Pandas ialah alat analisis data yang berkuasa yang digunakan secara meluas dalam pembersihan data, pemprosesan data dan visualisasi data, jadi ia sangat dihormati dalam bidang sains data. Walau bagaimanapun, disebabkan oleh konfigurasi persekitaran dan isu pergantungan, anda mungkin menghadapi beberapa kesukaran dan ralat semasa memasang panda. Artikel ini akan memberi anda tutorial pemasangan panda dan menganalisis beberapa ralat pemasangan biasa serta penyelesaiannya. 1. Pasang panda
 kaedah pemasangan panda python
Nov 22, 2023 pm 02:33 PM
kaedah pemasangan panda python
Nov 22, 2023 pm 02:33 PM
Python boleh memasang panda dengan menggunakan pip, menggunakan conda, daripada kod sumber, dan menggunakan alat pengurusan pakej bersepadu IDE. Pengenalan terperinci: 1. Gunakan pip dan jalankan arahan pemasangan panda pip dalam terminal atau command prompt untuk memasang panda 2. Gunakan conda dan jalankan arahan pemasangan panda di terminal atau command prompt untuk memasang panda; pemasangan dan banyak lagi.
 Cara membaca fail txt dengan betul menggunakan panda
Jan 19, 2024 am 08:39 AM
Cara membaca fail txt dengan betul menggunakan panda
Jan 19, 2024 am 08:39 AM
Cara menggunakan panda untuk membaca fail txt dengan betul memerlukan contoh kod khusus Pandas ialah perpustakaan analisis data Python yang digunakan secara meluas. Ia boleh digunakan untuk memproses pelbagai jenis data, termasuk fail CSV, fail Excel, pangkalan data SQL, dll. Pada masa yang sama, ia juga boleh digunakan untuk membaca fail teks, seperti fail txt. Walau bagaimanapun, apabila membaca fail txt, kadangkala kami menghadapi beberapa masalah, seperti masalah pengekodan, masalah pembatas, dsb. Artikel ini akan memperkenalkan cara membaca txt dengan betul menggunakan panda
 Baca fail CSV dan lakukan analisis data menggunakan panda
Jan 09, 2024 am 09:26 AM
Baca fail CSV dan lakukan analisis data menggunakan panda
Jan 09, 2024 am 09:26 AM
Pandas ialah alat analisis data yang berkuasa yang boleh membaca dan memproses pelbagai jenis fail data dengan mudah. Antaranya, fail CSV ialah salah satu daripada format fail data yang paling biasa dan biasa digunakan. Artikel ini akan memperkenalkan cara menggunakan Panda untuk membaca fail CSV dan melakukan analisis data serta memberikan contoh kod khusus. 1. Import perpustakaan yang diperlukan Mula-mula, kita perlu mengimport perpustakaan Pandas dan perpustakaan lain yang berkaitan yang mungkin diperlukan, seperti yang ditunjukkan di bawah: importpandasaspd 2. Baca fail CSV menggunakan Pan
 Bagaimana untuk memasang panda dalam python
Dec 04, 2023 pm 02:48 PM
Bagaimana untuk memasang panda dalam python
Dec 04, 2023 pm 02:48 PM
Langkah-langkah untuk memasang panda dalam python: 1. Buka terminal atau command prompt 2. Masukkan arahan "pip install panda" untuk memasang perpustakaan panda; 3. Tunggu pemasangan selesai, dan anda boleh mengimport dan menggunakan perpustakaan panda dalam skrip Python; 4. Gunakan Ia adalah persekitaran maya tertentu Pastikan untuk mengaktifkan persekitaran maya yang sepadan sebelum memasang panda 5. Jika anda menggunakan persekitaran pembangunan bersepadu, anda boleh menambah kod "import panda sebagai pd". import perpustakaan panda.
 Petua praktikal untuk membaca fail txt menggunakan panda
Jan 19, 2024 am 09:49 AM
Petua praktikal untuk membaca fail txt menggunakan panda
Jan 19, 2024 am 09:49 AM
Petua praktikal untuk membaca fail txt menggunakan panda, contoh kod khusus diperlukan Dalam analisis data dan pemprosesan data, fail txt ialah format data biasa. Menggunakan panda untuk membaca fail txt membolehkan pemprosesan data yang cepat dan mudah. Artikel ini akan memperkenalkan beberapa teknik praktikal untuk membantu anda menggunakan panda dengan lebih baik untuk membaca fail txt, bersama-sama dengan contoh kod tertentu. Baca fail txt dengan pembatas Apabila menggunakan panda untuk membaca fail txt dengan pembatas, anda boleh menggunakan read_c
 Mendedahkan kaedah penduaan data yang cekap dalam Pandas: Petua untuk mengalih keluar data pendua dengan cepat
Jan 24, 2024 am 08:12 AM
Mendedahkan kaedah penduaan data yang cekap dalam Pandas: Petua untuk mengalih keluar data pendua dengan cepat
Jan 24, 2024 am 08:12 AM
Rahsia kaedah deduplikasi Pandas: cara yang cepat dan cekap untuk menyahduplikasi data, yang memerlukan contoh kod khusus Dalam proses analisis dan pemprosesan data, duplikasi dalam data sering ditemui. Data pendua mungkin mengelirukan keputusan analisis, jadi penduaan adalah langkah yang sangat penting. Pandas, pustaka pemprosesan data yang berkuasa, menyediakan pelbagai kaedah untuk mencapai penyahduplikasian data Artikel ini akan memperkenalkan beberapa kaedah penyahduplikasian yang biasa digunakan, dan melampirkan contoh kod tertentu. Kes penduaan yang paling biasa berdasarkan satu lajur adalah berdasarkan sama ada nilai lajur tertentu diduakan.
 Panda dengan mudah membaca data daripada pangkalan data SQL
Jan 09, 2024 pm 10:45 PM
Panda dengan mudah membaca data daripada pangkalan data SQL
Jan 09, 2024 pm 10:45 PM
Alat pemprosesan data: Pandas membaca data daripada pangkalan data SQL dan memerlukan contoh kod khusus Memandangkan jumlah data terus berkembang dan kerumitannya meningkat, pemprosesan data telah menjadi bahagian penting dalam masyarakat moden. Dalam proses pemprosesan data, Pandas telah menjadi salah satu alat pilihan untuk ramai penganalisis dan saintis data. Artikel ini akan memperkenalkan cara menggunakan pustaka Pandas untuk membaca data daripada pangkalan data SQL dan menyediakan beberapa contoh kod khusus. Pandas ialah alat pemprosesan dan analisis data yang berkuasa berdasarkan Python
