
 pembangunan bahagian belakang
Tutorial Python
Cara menggunakan perpustakaan log loguru dalam Python
pembangunan bahagian belakang
Tutorial Python
Cara menggunakan perpustakaan log loguru dalam Python
Cara menggunakan perpustakaan log loguru dalam Python

1. Gambaran Keseluruhan Pustaka log
dalampythonlogging agak seperti log4j untuk digunakan, tetapi konfigurasi biasanya lebih rumit dan tidak mudah untuk membina pelayan log. Penggantian pustaka standard logging ialah loguru, yang lebih mudah digunakan. loguru
Format output lalai ialah: masa, tahap, modul, nombor baris dan kandungan log. loguru Tidak perlu membuat loguru secara manual, ia boleh digunakan di luar kotak, yang lebih mudah digunakan daripada logger selain itu, output log mempunyai fungsi warna dan warna terbina dalam dan kawalan bukan warna adalah sangat mudah dan lebih mesra pengguna. logging
ialah perpustakaan bukan standard dan perlu dipasang terlebih dahulu Perintahnya ialah: **loguru****. **Selepas pemasangan, contoh penggunaan paling mudah adalah seperti berikut: pip3 install loguru
from loguru import logger logger.debug('hello, this debug loguru') logger.info('hello, this is info loguru') logger.warning('hello, this is warning loguru') logger.error('hello, this is error loguru') logger.critical('hello, this is critical loguru')
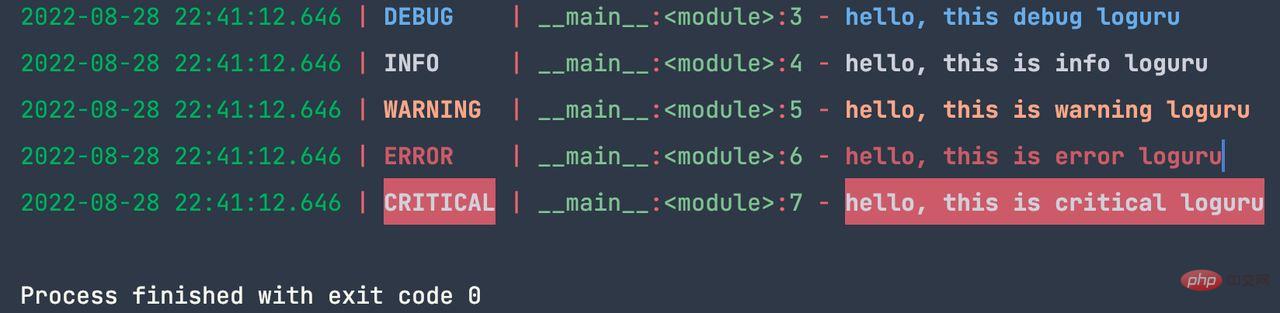
from loguru import logger logger.add('myloguru.log') logger.debug('hello, this debug loguru') logger.info('hello, this is info loguru') logger.warning('hello, this is warning loguru') logger.error('hello, this is error loguru') logger.critical('hello, this is critical loguru')
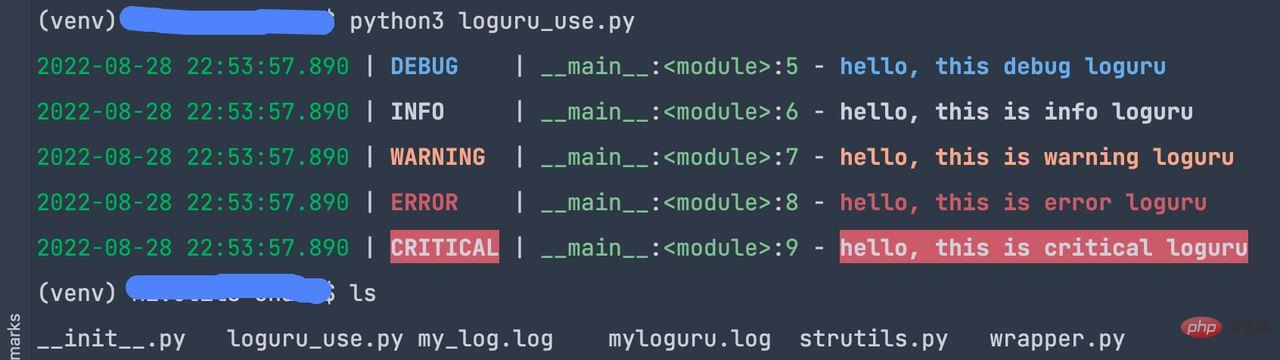
Format lalai ialah masa, tahap, nama + modul dan log Kandungan, di mana nama + modul berkod keras, ialah pembolehubah loguru bagi fail semasa Sebaiknya jangan ubah suai pembolehubah ini. __name__
. Seperti berikut: logger.configure
import sys
from loguru import logger
logger.configure(handlers=[
{
"sink": sys.stderr,
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |<lvl>{level:8}</>| {name} : {module}:{line:4} | <cyan>mymodule</> | - <lvl>{message}</>",
"colorize": True
},
])
logger.debug('this is debug')
logger.info('this is info')
logger.warning('this is warning')
logger.error('this is error')
logger.critical('this is critical')Output kod di atas ialah:: menunjukkan pemegang keluaran log atau destinasi,
handlersmenunjukkan output ke terminal baris arahan.sys.stderrbermaksud output ke terminal
"sink": sys.stderrbermaksud pemformatan log.
"format":bermaksud memaparkan warna mengikut tahap log. 8 bermakna lebar output ialah 8 aksara.<lvl>{level:8}</>
"colorize":**: Menunjukkan warna paparan.True

Nama modul dikodkan keras di sini dan agak menyusahkan untuk sediakan setiap log dengan cara ini. Berikut menerangkan cara menentukan nama modul yang berbeza.2.2. Menulis fail Log secara amnya perlu diteruskan sebagai tambahan kepada terminal baris arahan, ia juga perlu ditulis ke fail. Pustaka log standard boleh mengkonfigurasi logger melalui fail konfigurasi, dan ia juga boleh dilaksanakan dalam kod, tetapi prosesnya agak rumit. Loguru adalah agak mudah Mari kita lihat bagaimana untuk melaksanakan fungsi ini dalam kod. Kod log adalah seperti berikut:
import sys
from loguru import logger
logger.configure(handlers=[
{
"sink": sys.stderr,
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |<lvl>{level:8}</>| {name} : {module}:{line:4} | <cyan>mymodule</> | - <lvl>{message}</>",
"colorize": True
},
{
"sink": 'first.log',
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |{level:8}| {name} : {module}:{line:4} | mymodule | - {message}",
"colorize": False
},
])
logger.debug('this is debug')
logger.info('this is info')
logger.warning('this is warning')
logger.error('this is error')
logger.critical('this is critical')Satu-satunya perbezaan daripada 2.1 ialahDi atas hanya menetapkan format log melaluimenambah
logger.configurebaharu dan menulisnya pada fail log. Penggunaannya sangat mudah.handler
, tetapi nama modul tidak berubah Dalam pembangunan projek sebenar, modul yang berbeza perlu menentukan nama modul yang berbeza semasa menulis log. Oleh itu, nama modul perlu diparameterkan untuk menjadikannya lebih praktikal. Kod sampel adalah seperti berikut: logger.configure
import sys
from loguru import logger
logger.configure(handlers=[
{
"sink": sys.stderr,
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |<lvl>{level:8}</>| {name} : {module}:{line:4} | <cyan>{extra[module_name]}</> | - <lvl>{message}</>",
"colorize": True
},
{
"sink": 'first.log',
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |{level:8}| {name} : {module}:{line:4} | {extra[module_name]} | - {message}",
"colorize": False
},
])
log = logger.bind(module_name='my-loguru')
log.debug("this is hello, module is my-loguru")
log2 = logger.bind(module_name='my-loguru2')
log2.info("this is hello, module is my-loguru2")Output kod di atas adalah seperti berikut:Parameterisasi
Fungsi menyesuaikan nama modul dalam loguru sedikit berbeza daripada perpustakaan pengelogan standard. Melalui kaedah bind, fungsi log standardlogger.bind(module_name='my-loguru')dilaksanakan melalui kaedah bind. bind mengembalikan objek log di mana output log boleh dilakukan, supaya format log untuk modul berbeza boleh dilaksanakan.module_nameboleh dilaksanakan dengan mudah. Selain itu, log berstruktur boleh dilaksanakan dengan mudah melalui
logging.bind和logger.configure

Simpan dalam format json berstruktur Mudah, cuma tetapkan parameter loguru. Kodnya adalah seperti berikut: serialize=True
from loguru import logger logger.add('json.log', serialize=True, encoding='utf-8') logger.debug('this is debug message') logger.info('this is info message') logger.error('this is error message')

Fail log menyokong tiga tetapan: Gelung, simpan, mampat. Persediaan juga agak mudah. Terutamanya format mampatan sangat kaya dengan sokongan Format mampatan biasa disokong, seperti: loguru, "gz", "bz2", "xz", "lzma", "tar", "tar.gz", "tar.bz2" , "tar.xz". Kod sampel adalah seperti berikut: "zip"
from loguru import logger
logger.add("file_1.log", rotation="500 MB") # 自动循环过大的文件
logger.add("file_2.log", rotation="12:00") # 每天中午创建新文件
logger.add("file_3.log", rotation="1 week") # 一旦文件太旧进行循环
logger.add("file_X.log", retention="10 days") # 定期清理
logger.add("file_Y.log", compression="zip") # 压缩节省空间2.5.并发安全
loguru默认是线程安全的,但不是多进程安全的,如果使用了多进程安全,需要添加参数enqueue=True,样例代码如下:
logger.add("somefile.log", enqueue=True)
loguru另外还支持协程,有兴趣可以自行研究。
3.高级用法
3.1.接管标准日志logging
更换日志系统或者设计一套日志系统,比较难的是兼容现有的代码,尤其是第三方库,因为不能因为日志系统的切换,而要去修改这些库的代码,也没有必要。好在loguru可以方便的接管标准的日志系统。
样例代码如下:
import logging
import logging.handlers
import sys
from loguru import logger
handler = logging.handlers.SysLogHandler(address=('localhost', 514))
logger.add(handler)
class LoguruHandler(logging.Handler):
def emit(self, record):
try:
level = logger.level(record.levelname).name
except ValueError:
level = record.levelno
frame, depth = logging.currentframe(), 2
while frame.f_code.co_filename == logging.__file__:
frame = frame.f_back
depth += 1
logger.opt(depth=depth, exception=record.exc_info).log(level, record.getMessage())
logging.basicConfig(handlers=[LoguruHandler()], level=0, format='%(asctime)s %(filename)s %(levelname)s %(message)s',
datefmt='%Y-%M-%D %H:%M:%S')
logger.configure(handlers=[
{
"sink": sys.stderr,
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |<lvl>{level:8}</>| {name} : {module}:{line:4} | [ModuleA] | - <lvl>{message}</>",
"colorize": True
},
])
log = logging.getLogger('root')
# 使用标注日志系统输出
log.info('hello wrold, that is from logging')
log.debug('debug hello world, that is from logging')
log.error('error hello world, that is from logging')
log.warning('warning hello world, that is from logging')
# 使用loguru系统输出
logger.info('hello world, that is from loguru')输出为:

3.2.输出日志到网络服务器
如果有需要,不同进程的日志,可以输出到同一个日志服务器上,便于日志的统一管理。我们可以利用自定义或者第三方库进行日志服务器和客户端的设置。下面介绍两种日志服务器的用法。
3.2.1.自定义日志服务器
日志客户端段代码如下:
# client.py
import pickle
import socket
import struct
import time
from loguru import logger
class SocketHandler:
def __init__(self, host, port):
self.sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.sock.connect((host, port))
def write(self, message):
record = message.record
data = pickle.dumps(record)
slen = struct.pack(">L", len(data))
self.sock.send(slen + data)
logger.configure(handlers=[{"sink": SocketHandler('localhost', 9999)}])
while True:
time.sleep(1)
logger.info("Sending info message from the client")
logger.debug("Sending debug message from the client")
logger.error("Sending error message from the client")日志服务器代码如下:
# server.py
import pickle
import socketserver
import struct
from loguru import logger
class LoggingStreamHandler(socketserver.StreamRequestHandler):
def handle(self):
while True:
chunk = self.connection.recv(4)
if len(chunk) < 4:
break
slen = struct.unpack('>L', chunk)[0]
chunk = self.connection.recv(slen)
while len(chunk) < slen:
chunk = chunk + self.connection.recv(slen - len(chunk))
record = pickle.loads(chunk)
level, message = record["level"].no, record["message"]
logger.patch(lambda record: record.update(record)).log(level, message)
server = socketserver.TCPServer(('localhost', 9999), LoggingStreamHandler)
server.serve_forever()运行结果如下:
3.2.2.第三方库日志服务器
日志客户端代码如下:
# client.py
import zmq
from zmq.log.handlers import PUBHandler
from loguru import logger
socket = zmq.Context().socket(zmq.PUB)
socket.connect("tcp://127.0.0.1:12345")
handler = PUBHandler(socket)logger.add(handler)
logger.info("Logging from client")日志服务器代码如下:
# server.py
import sys
import zmq
from loguru import logger
socket = zmq.Context().socket(zmq.SUB)
socket.bind("tcp://127.0.0.1:12345")
socket.subscribe("")
logger.configure(handlers=[{"sink": sys.stderr, "format": "{message}"}])
while True:
_, message = socket.recv_multipart()
logger.info(message.decode("utf8").strip())3.3.与pytest结合
官方帮助中有一个讲解loguru与pytest结合的例子,讲得有点含糊不是很清楚。简单的来说,pytest有个fixture,可以捕捉被测方法中的logging日志打印,从而验证打印是否触发。
下面就详细讲述如何使用loguru与pytest结合的代码,如下:
import pytest
from _pytest.logging import LogCaptureFixture
from loguru import logger
def some_func(i, j):
logger.info('Oh no!')
logger.info('haha')
return i + j
@pytest.fixture
def caplog(caplog: LogCaptureFixture):
handler_id = logger.add(caplog.handler, format="{message}")
yield caplog
logger.remove(handler_id)
def test_some_func_logs_warning(caplog):
assert some_func(-1, 3) == 2
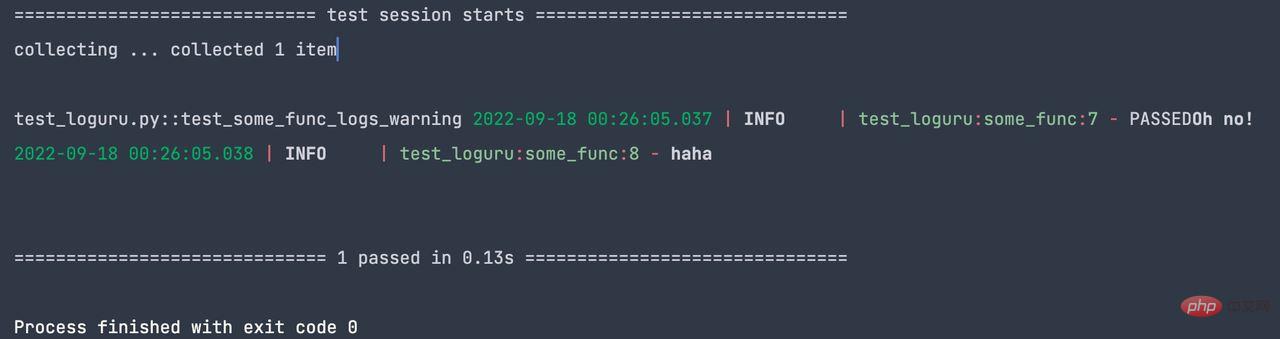
assert "Oh no!" in caplog.text测试输出如下:
Atas ialah kandungan terperinci Cara menggunakan perpustakaan log loguru dalam Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Hadidb: Pangkalan data yang ringan dan berskala mendatar di Python
Apr 08, 2025 pm 06:12 PM
Hadidb: Pangkalan data yang ringan dan berskala mendatar di Python
Apr 08, 2025 pm 06:12 PM
Hadidb: Pangkalan data Python yang ringan, tinggi, Hadidb (Hadidb) adalah pangkalan data ringan yang ditulis dalam Python, dengan tahap skalabilitas yang tinggi. Pasang HadIdb menggunakan pemasangan PIP: Pengurusan Pengguna PipInstallHadidB Buat Pengguna: CreateUser () Kaedah untuk membuat pengguna baru. Kaedah pengesahan () mengesahkan identiti pengguna. dariHadidb.OperationImportuserer_Obj = user ("admin", "admin") user_obj.
 Kaedah Navicat untuk melihat kata laluan pangkalan data MongoDB
Apr 08, 2025 pm 09:39 PM
Kaedah Navicat untuk melihat kata laluan pangkalan data MongoDB
Apr 08, 2025 pm 09:39 PM
Tidak mustahil untuk melihat kata laluan MongoDB secara langsung melalui Navicat kerana ia disimpan sebagai nilai hash. Cara mendapatkan kata laluan yang hilang: 1. Tetapkan semula kata laluan; 2. Periksa fail konfigurasi (mungkin mengandungi nilai hash); 3. Semak Kod (boleh kata laluan Hardcode).
 Rancangan Python 2 jam: Pendekatan yang realistik
Apr 11, 2025 am 12:04 AM
Rancangan Python 2 jam: Pendekatan yang realistik
Apr 11, 2025 am 12:04 AM
Anda boleh mempelajari konsep pengaturcaraan asas dan kemahiran Python dalam masa 2 jam. 1. Belajar Pembolehubah dan Jenis Data, 2.
 Bagaimana untuk mengoptimumkan prestasi MySQL untuk aplikasi beban tinggi?
Apr 08, 2025 pm 06:03 PM
Bagaimana untuk mengoptimumkan prestasi MySQL untuk aplikasi beban tinggi?
Apr 08, 2025 pm 06:03 PM
Panduan Pengoptimuman Prestasi Pangkalan Data MySQL Dalam aplikasi yang berintensifkan sumber, pangkalan data MySQL memainkan peranan penting dan bertanggungjawab untuk menguruskan urus niaga besar-besaran. Walau bagaimanapun, apabila skala aplikasi berkembang, kemunculan prestasi pangkalan data sering menjadi kekangan. Artikel ini akan meneroka satu siri strategi pengoptimuman prestasi MySQL yang berkesan untuk memastikan aplikasi anda tetap cekap dan responsif di bawah beban tinggi. Kami akan menggabungkan kes-kes sebenar untuk menerangkan teknologi utama yang mendalam seperti pengindeksan, pengoptimuman pertanyaan, reka bentuk pangkalan data dan caching. 1. Reka bentuk seni bina pangkalan data dan seni bina pangkalan data yang dioptimumkan adalah asas pengoptimuman prestasi MySQL. Berikut adalah beberapa prinsip teras: Memilih jenis data yang betul dan memilih jenis data terkecil yang memenuhi keperluan bukan sahaja dapat menjimatkan ruang penyimpanan, tetapi juga meningkatkan kelajuan pemprosesan data.
 Python: meneroka aplikasi utamanya
Apr 10, 2025 am 09:41 AM
Python: meneroka aplikasi utamanya
Apr 10, 2025 am 09:41 AM
Python digunakan secara meluas dalam bidang pembangunan web, sains data, pembelajaran mesin, automasi dan skrip. 1) Dalam pembangunan web, kerangka Django dan Flask memudahkan proses pembangunan. 2) Dalam bidang sains data dan pembelajaran mesin, numpy, panda, scikit-learn dan perpustakaan tensorflow memberikan sokongan yang kuat. 3) Dari segi automasi dan skrip, Python sesuai untuk tugas -tugas seperti ujian automatik dan pengurusan sistem.
 Cara Menggunakan AWS Glue Crawler dengan Amazon Athena
Apr 09, 2025 pm 03:09 PM
Cara Menggunakan AWS Glue Crawler dengan Amazon Athena
Apr 09, 2025 pm 03:09 PM
Sebagai profesional data, anda perlu memproses sejumlah besar data dari pelbagai sumber. Ini boleh menimbulkan cabaran kepada pengurusan data dan analisis. Nasib baik, dua perkhidmatan AWS dapat membantu: AWS Glue dan Amazon Athena.
 Bolehkah mysql menyambung ke pelayan SQL
Apr 08, 2025 pm 05:54 PM
Bolehkah mysql menyambung ke pelayan SQL
Apr 08, 2025 pm 05:54 PM
Tidak, MySQL tidak dapat menyambung terus ke SQL Server. Tetapi anda boleh menggunakan kaedah berikut untuk melaksanakan interaksi data: Gunakan middleware: data eksport dari MySQL ke format pertengahan, dan kemudian mengimportnya ke SQL Server melalui middleware. Menggunakan Pangkalan Data Pangkalan Data: Alat perniagaan menyediakan antara muka yang lebih mesra dan ciri -ciri canggih, pada dasarnya masih dilaksanakan melalui middleware.
 Cara memulakan pelayan dengan redis
Apr 10, 2025 pm 08:12 PM
Cara memulakan pelayan dengan redis
Apr 10, 2025 pm 08:12 PM
Langkah -langkah untuk memulakan pelayan Redis termasuk: Pasang Redis mengikut sistem operasi. Mulakan perkhidmatan Redis melalui Redis-server (Linux/macOS) atau redis-server.exe (Windows). Gunakan redis-cli ping (linux/macOS) atau redis-cli.exe ping (windows) perintah untuk memeriksa status perkhidmatan. Gunakan klien Redis, seperti redis-cli, python, atau node.js untuk mengakses pelayan.
