
 Peranti teknologi
AI
Byte mencadangkan model pensampelan semula imej tidak simetri, dengan prestasi anti-mampatan terkemuka SOTA pada JPEG dan WebP
Peranti teknologi
AI
Byte mencadangkan model pensampelan semula imej tidak simetri, dengan prestasi anti-mampatan terkemuka SOTA pada JPEG dan WebP
Byte mencadangkan model pensampelan semula imej tidak simetri, dengan prestasi anti-mampatan terkemuka SOTA pada JPEG dan WebP

Tugas Penskalaan Semula Imej (LR) bersama-sama mengoptimumkan operasi pensampelan turun dan naikkan imej Dengan mengurangkan dan memulihkan resolusi imej, ia boleh digunakan untuk menjimatkan ruang storan atau lebar jalur penghantaran. Dalam aplikasi praktikal, seperti pengedaran berbilang peringkat perkhidmatan atlas, imej resolusi rendah yang diperoleh melalui pensampelan rendah selalunya tertakluk kepada pemampatan lossy, dan pemampatan lossy selalunya membawa kepada penurunan ketara dalam prestasi algoritma sedia ada.
Baru-baru ini, ByteDance - Volcano Engine Multimedia Laboratory mencuba pengoptimuman prestasi pensampelan semula imej di bawah pemampatan lossy buat kali pertama, mereka bentuk rangka kerja Pensampelan Semula boleh balik asimetrik , berdasarkan dua pemerhatian di bawah rangka kerja ini, model pensampelan semula imej anti-mampatan SAIN selanjutnya dicadangkan. Kajian ini mengasingkan satu set modul rangkaian boleh balik kepada dua bahagian: pensampelan semula dan simulasi mampatan, menggunakan taburan Gaussian bercampur untuk memodelkan kehilangan maklumat bersama yang disebabkan oleh kemerosotan resolusi dan herotan mampatan, dan menggabungkannya dengan operator JPEG yang boleh dibezakan untuk hujung ke- menamatkan latihan , yang meningkatkan keteguhan kepada algoritma pemampatan biasa.
Pada masa ini untuk penyelidikan pensampelan semula imej, kaedah SOTA adalah berdasarkan Rangkaian Boleh Terbalik untuk membina fungsi bijektif (fungsi bijektif), dan operasi positifnya menukarkan resolusi tinggi (HR) Imej adalah ditukar kepada imej resolusi rendah (LR) dan satu siri pembolehubah tersembunyi yang mematuhi taburan normal piawai.
Disebabkan oleh ciri-ciri rangkaian boleh balik, pengendali pensampelan turun dan pensampelan naik mengekalkan tahap simetri yang tinggi, yang menyukarkan imej LR termampat untuk melepasi pengendali pensampelan yang telah dipelajari kepada memulihkan. Untuk meningkatkan keteguhan kepada mampatan lossy, kajian ini mencadangkan model pensampelan semula imej tahan mampatan SAIN (Self-Asimetri berdasarkan rangka kerja boleh balik asimetri Iterbalik Nkerja).
Inovasi teras model SAIN adalah seperti berikut:
- Mencadangkan rangka kerja pensampelan semula imej boleh balik asimetri Ia menyelesaikan masalah kemerosotan prestasi disebabkan oleh simetri yang ketat dalam kaedah sebelumnya; mencadangkan modul boleh terbalik yang dipertingkatkan (E-InvBlock), yang meningkatkan keupayaan pemasangan model sambil berkongsi sejumlah besar parameter dan operasi, sambil memodelkan sebelum dan selepas pemampatan kedua-dua set imej LR membolehkan model melakukan pemulihan mampatan dan pensampelan melalui operasi songsang.
- Bina taburan Gaussian bercampur yang boleh dipelajari, modelkan kehilangan maklumat bersama yang disebabkan oleh pengurangan resolusi dan pemampatan lossy, dan secara langsung mengoptimumkan parameter pengedaran melalui teknik penparameteran semula, yang lebih konsisten dengan pembolehubah tersembunyi taburan sebenar.
Model SAIN telah disahkan untuk prestasi di bawah pemampatan JPEG dan WebP, dan prestasinya pada berbilang set data awam adalah jauh mendahului model SOTA yang berkaitan telah dipilih untuk Lisan AAI 2023.

- Alamat kertas: https://arxiv.org/abs/2303.02353
- Pautan kod: https://github.com/yang-jin-hai/SAIN
Pensampelan Semula Asimetri rangka kerja
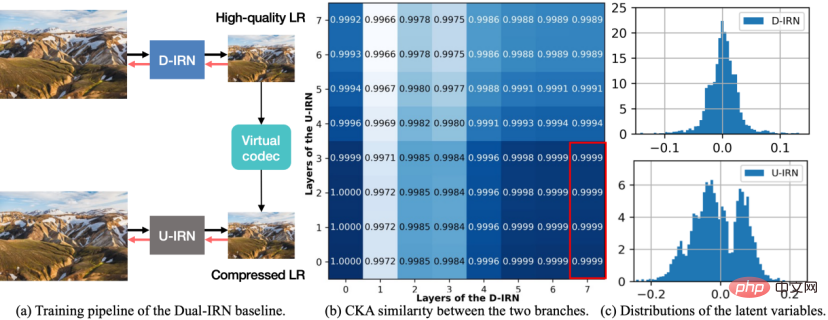
Rajah 1 Rajah model Dwi-IRN.
Untuk meningkatkan prestasi anti-mampatan, penyelidikan ini mula-mula mereka bentuk rangka kerja pensampelan semula imej boleh balik asimetri, mencadangkan skema garis dasar model Dual-IRN, dan dianalisis secara mendalam Selepas kekurangan skim ini, model SAIN telah dicadangkan untuk pengoptimuman selanjutnya. Seperti yang ditunjukkan dalam rajah di atas, model Dwi-IRN mengandungi dua cawangan, di mana D-IRN dan U-IRN ialah dua set rangkaian boleh balik yang mempelajari bijection antara imej HR dan imej LR pra-mampatan/pasca-mampatan. .
Semasa fasa latihan, model Dwi-IRN melepasi kecerunan antara dua cawangan melalui pengendali JPEG yang boleh dibezakan. Dalam fasa ujian, model menggunakan D-IRN untuk menurunkan sampel untuk mendapatkan imej LR berkualiti tinggi Selepas pemampatan sebenar dalam persekitaran sebenar, model kemudian menggunakan U-IRN dengan pemampatan sedar untuk melengkapkan pemulihan mampatan dan peningkatan.
Rangka kerja asimetri sedemikian membolehkan operator pensampelan naik dan turun untuk mengelakkan perhubungan boleh balik yang ketat Selesaikan punca algoritma pemampatan yang memusnahkan simetri proses pensampelan naik dan turun 🎜> ialah berbanding dengan penyelesaian simetri SOTA, prestasi anti-mampatan bertambah baik.
Selepas itu, penyelidik menjalankan analisis lanjut ke atas model Dwi-IRN dan memerhatikan dua fenomena berikut:
- Pertama , ukur persamaan CKA ciri lapisan tengah bagi dua cabang D-IRN dan U-IRN. Seperti yang ditunjukkan dalam (b) di atas, ciri output lapisan terakhir D-IRN (iaitu, imej LR berkualiti tinggi yang dijana oleh rangkaian) sangat serupa dengan ciri output lapisan cetek U-IRN, menunjukkan tingkah laku cetek U-IRN lebih dekat dengan simulasi kehilangan pensampelan, manakala tingkah laku dalam lebih dekat dengan simulasi kehilangan mampatan.
- Kedua, kira taburan sebenar pembolehubah tersembunyi di lapisan tengah dua cawangan D-IRN dan U-IRN. Seperti yang ditunjukkan dalam (c) (d) di atas, pembolehubah pendam D-IRN tanpa penderiaan termampat memenuhi andaian taburan normal unimodal secara keseluruhan, manakala pembolehubah terpendam U-IRN dengan penderiaan termampat menunjukkan bentuk berbilang modal. menunjukkan bahawa bentuk kehilangan maklumat yang disebabkan oleh pemampatan lossy adalah lebih kompleks.
Berdasarkan analisis di atas, penyelidik mengoptimumkan model dari banyak aspek Model SAIN yang terhasil bukan sahaja mengurangkan bilangan parameter rangkaian sebanyak hampir separuh, tetapi juga mencapai lebih jauh penambahbaikan.
Butiran model SAIN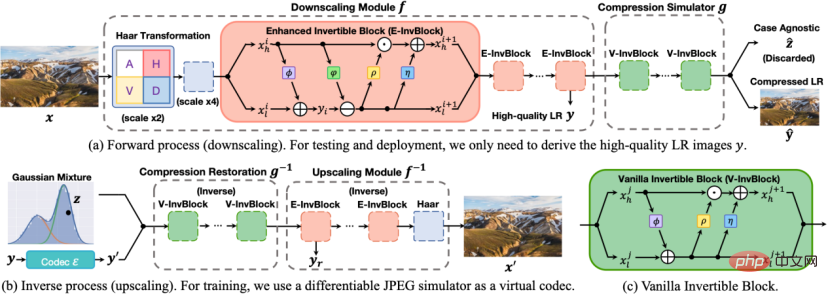
Rajah 2 rajah model SAIN.
Seni bina model SAIN ditunjukkan dalam rajah di atas, dan empat penambahbaikan utama berikut telah dibuat:
1. Rangka kerja keseluruhan . Berdasarkan persamaan ciri lapisan tengah, satu set modul rangkaian boleh balik dipisahkan kepada dua bahagian: pensampelan semula dan simulasi mampatan, membentuk seni bina asimetri diri untuk mengelak daripada menggunakan dua set lengkap rangkaian boleh balik. Dalam fasa ujian, gunakan transformasi ke hadapan
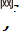
untuk mendapatkan imej LR berkualiti tinggi, mula-mula gunakan transformasi songsang
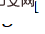
lakukan pemulihan mampatan, dan kemudian gunakan transformasi songsang
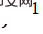
untuk pensampelan semula.
Struktur rangkaian . E-InvBlock dicadangkan berdasarkan andaian bahawa kehilangan mampatan boleh dipulihkan dengan bantuan maklumat frekuensi tinggi Satu transformasi tambahan ditambahkan pada modul, supaya dua set imej LR sebelum dan selepas pemampatan boleh dimodelkan dengan cekap semasa berkongsi. sejumlah besar operasi.
3. Berdasarkan taburan sebenar pembolehubah terpendam, adalah dicadangkan untuk menggunakan taburan Gaussian campuran yang boleh dipelajari untuk memodelkan kehilangan maklumat bersama yang disebabkan oleh pensampelan rendah dan mampatan lossy, dan mengoptimumkan parameter taburan hujung ke hujung melalui teknik penparameteran semula.
4. Fungsi kehilangan berbilang direka untuk mengekang kebolehbalikan rangkaian dan meningkatkan ketepatan pembinaan semula Pada masa yang sama, operasi mampatan sebenar diperkenalkan ke dalam fungsi kehilangan untuk meningkatkan keteguhan kepada skim mampatan sebenar. Evaluasi Eksperimen dan Kesan
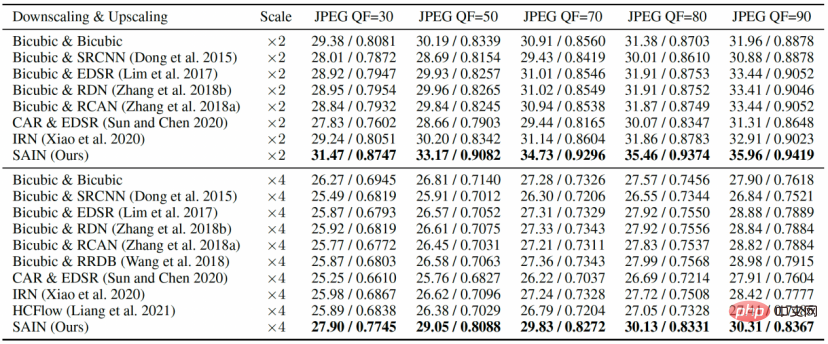
Set data penilaian ialah set pengesahan DIV2K dan empat set ujian standard Set5, Set14, BSD100 dan Urban100.
Penunjuk penilaian kuantitatif ialah:
- PSNR: Nisbah Isyarat-ke-Bunyi Puncak, nisbah isyarat-ke-bunyi puncak, mencerminkan ralat kuasa dua min antara imej yang dibina semula dan imej asal, lebih tinggi lebih baik; 🎜> SSIM: Pengukuran Imej Keserupaan Struktur, yang mengukur persamaan struktur antara imej yang dibina semula dan imej asal Lebih tinggi lebih baik.
SAIN masih mengekalkan prestasi optimum.
Jadual 1 Percubaan perbandingan, membandingkan kualiti mampatan JPEG (QF) berbeza pada set data DIV2K Kualiti pembinaan semula (PSNR/SSIM).
Rajah 3 Percubaan perbandingan, membandingkan JPEG QF berbeza pada empat set ujian standard kualiti pembinaan semula ( PSNR).
Dalam hasil visualisasi dalam Rajah 4, dapat dilihat dengan jelas bahawa imej HR yang dipulihkan oleh SAIN adalahlebih jelas dan tepat .

Rajah 4 Perbandingan hasil visualisasi kaedah berbeza di bawah pemampatan JPEG (pembesaran ×4).
Dalam eksperimen ablasi dalam Jadual 2, penyelidik juga membandingkan beberapa calon lain untuk latihan digabungkan dengan pemampatan sebenar. Calon ini lebih tahan terhadap mampatan daripada model sedia ada simetri sepenuhnya (IRN), tetapi masih lebih rendah daripada model SAIN dari segi bilangan parameter dan ketepatan.
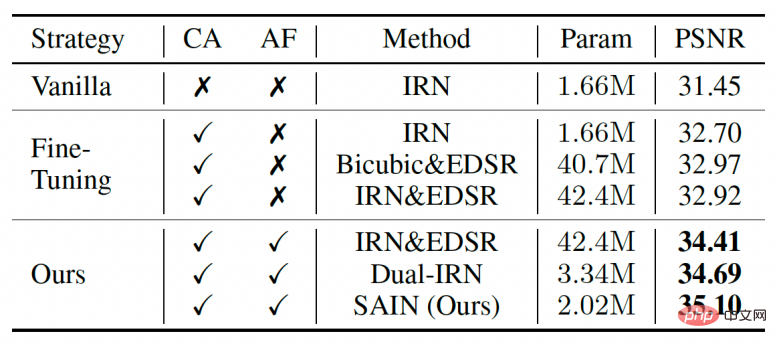
Jadual 2 Eksperimen ablasi untuk keseluruhan rangka kerja dan strategi latihan.
Dalam hasil visualisasi dalam Rajah 5, penyelidik membandingkan hasil pembinaan semula model pensampelan semula imej yang berbeza di bawah herotan mampatan WebP. Ia boleh didapati bahawa model SAIN juga menunjukkan skor pembinaan semula tertinggi di bawah skema pemampatan WebP dan boleh memulihkan butiran imej dengan jelas dan tepat, membuktikan keserasianSAIN dengan skema pemampatan yang berbeza.
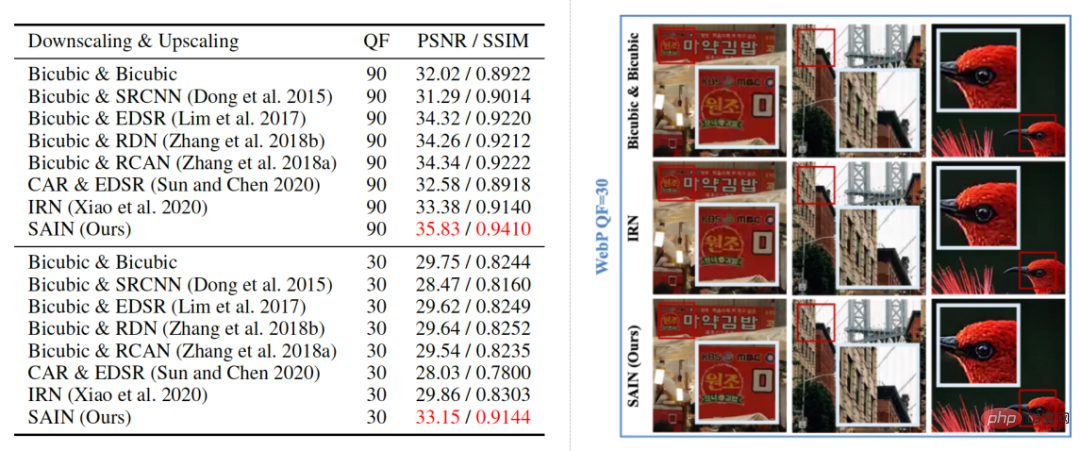
Rajah 5 Perbandingan kualitatif dan kuantitatif kaedah berbeza di bawah pemampatan WebP (pembesaran ×2).
Selain itu, kajian itu juga menjalankan eksperimen ablasi ke atas taburan Gaussian bercampur, E-InvBlock dan fungsi kehilangan, membuktikan bahawa penambahbaikan ini memberi impak positif kepada keputusan .Ringkasan dan Tinjauan
Makmal Multimedia Enjin Gunung Berapi mencadangkan model berdasarkan rangka kerja boleh balik asimetri untuk pensampelan semula imej anti-mampatan: SAIN. Model ini terdiri daripada dua bahagian: pensampelan semula dan simulasi mampatan Ia menggunakan taburan Gaussian campuran untuk memodelkan kehilangan maklumat bersama yang disebabkan oleh pengurangan resolusi dan herotan mampatan Ia digabungkan dengan pengendali JPEG yang boleh dibezakan untuk latihan hujung ke hujung -InvBlock dicadangkan untuk mempertingkatkan model Keupayaan pemasangan sangat meningkatkan keteguhan kepada algoritma pemampatan biasa.Makmal Multimedia Enjin Gunung Berapi ialah pasukan penyelidikan di bawah ByteDance Ia komited untuk meneroka teknologi termaju dalam bidang multimedia dan mengambil bahagian dalam kerja penyeragaman antarabangsa Banyak algoritma inovatif serta penyelesaian perisian dan perkakasannya telah meluas digunakan dalam Douyin, Douyin, dsb. Perniagaan multimedia untuk produk seperti Xigua Video, dan menyediakan perkhidmatan teknikal kepada pelanggan peringkat perusahaan Volcano Engine. Sejak penubuhan makmal, banyak kertas kerja telah dipilih ke dalam persidangan antarabangsa terkemuka dan jurnal perdana, dan telah memenangi beberapa kejohanan pertandingan teknikal antarabangsa, anugerah inovasi industri dan anugerah kertas terbaik. Pada masa hadapan, pasukan penyelidik akan terus mengoptimumkan prestasi model pensampelan semula imej di bawah pemampatan lossy, dan seterusnya meneroka senario aplikasi yang lebih kompleks seperti pensampelan semula video anti-mampatan dan sewenang-wenangnya persampelan semula pembesaran.
Atas ialah kandungan terperinci Byte mencadangkan model pensampelan semula imej tidak simetri, dengan prestasi anti-mampatan terkemuka SOTA pada JPEG dan WebP. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Di barisan hadapan teknologi perisian, kumpulan UIUC Zhang Lingming, bersama penyelidik dari organisasi BigCode, baru-baru ini mengumumkan model kod besar StarCoder2-15B-Instruct. Pencapaian inovatif ini mencapai kejayaan ketara dalam tugas penjanaan kod, berjaya mengatasi CodeLlama-70B-Instruct dan mencapai bahagian atas senarai prestasi penjanaan kod. Keunikan StarCoder2-15B-Instruct terletak pada strategi penjajaran diri yang tulen Keseluruhan proses latihan adalah terbuka, telus, dan sepenuhnya autonomi dan boleh dikawal. Model ini menjana beribu-ribu arahan melalui StarCoder2-15B sebagai tindak balas kepada penalaan halus model asas StarCoder-15B tanpa bergantung pada anotasi manual yang mahal.
 Yolov10: Penjelasan terperinci, penggunaan dan aplikasi semuanya di satu tempat!
Jun 07, 2024 pm 12:05 PM
Yolov10: Penjelasan terperinci, penggunaan dan aplikasi semuanya di satu tempat!
Jun 07, 2024 pm 12:05 PM
1. Pengenalan Sejak beberapa tahun kebelakangan ini, YOLO telah menjadi paradigma dominan dalam bidang pengesanan objek masa nyata kerana keseimbangannya yang berkesan antara kos pengiraan dan prestasi pengesanan. Penyelidik telah meneroka reka bentuk seni bina YOLO, matlamat pengoptimuman, strategi pengembangan data, dsb., dan telah mencapai kemajuan yang ketara. Pada masa yang sama, bergantung pada penindasan bukan maksimum (NMS) untuk pemprosesan pasca menghalang penggunaan YOLO dari hujung ke hujung dan memberi kesan buruk kepada kependaman inferens. Dalam YOLO, reka bentuk pelbagai komponen tidak mempunyai pemeriksaan yang komprehensif dan teliti, mengakibatkan lebihan pengiraan yang ketara dan mengehadkan keupayaan model. Ia menawarkan kecekapan suboptimum, dan potensi yang agak besar untuk peningkatan prestasi. Dalam kerja ini, matlamatnya adalah untuk meningkatkan lagi sempadan kecekapan prestasi YOLO daripada kedua-dua pasca pemprosesan dan seni bina model. sampai habis
 Universiti Tsinghua mengambil alih dan YOLOv10 keluar: prestasi telah bertambah baik dan ia berada dalam senarai panas GitHub
Jun 06, 2024 pm 12:20 PM
Universiti Tsinghua mengambil alih dan YOLOv10 keluar: prestasi telah bertambah baik dan ia berada dalam senarai panas GitHub
Jun 06, 2024 pm 12:20 PM
Siri penanda aras YOLO sistem pengesanan sasaran sekali lagi menerima peningkatan besar. Sejak pengeluaran YOLOv9 pada Februari tahun ini, baton siri YOLO (YouOnlyLookOnce) telah diserahkan kepada penyelidik di Universiti Tsinghua. Hujung minggu lalu, berita pelancaran YOLOv10 menarik perhatian komuniti AI. Ia dianggap sebagai rangka kerja terobosan dalam bidang penglihatan komputer dan terkenal dengan keupayaan pengesanan objek hujung ke hujung masa nyata, meneruskan legasi siri YOLO dengan menyediakan penyelesaian berkuasa yang menggabungkan kecekapan dan ketepatan. Alamat kertas: https://arxiv.org/pdf/2405.14458 Alamat projek: https://github.com/THU-MIG/yo
 Laporan teknikal Google Gemini 1.5: Buktikan soalan Olimpik Matematik dengan mudah, versi Flash adalah 5 kali lebih pantas daripada GPT-4 Turbo
Jun 13, 2024 pm 01:52 PM
Laporan teknikal Google Gemini 1.5: Buktikan soalan Olimpik Matematik dengan mudah, versi Flash adalah 5 kali lebih pantas daripada GPT-4 Turbo
Jun 13, 2024 pm 01:52 PM
Pada bulan Februari tahun ini, Google melancarkan model besar berbilang modal Gemini 1.5, yang telah meningkatkan prestasi dan kelajuan dengan sangat baik melalui pengoptimuman kejuruteraan dan infrastruktur, seni bina MoE dan strategi lain. Dengan konteks yang lebih panjang, keupayaan penaakulan yang lebih kukuh dan pengendalian kandungan merentas modal yang lebih baik. Jumaat ini, Google DeepMind secara rasmi mengeluarkan laporan teknikal Gemini 1.5, yang merangkumi versi Flash dan peningkatan terkini yang lain Dokumen itu sepanjang 153 halaman. Pautan laporan teknikal: https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf Dalam laporan ini, Google memperkenalkan Gemini1
 Bagaimana untuk menilai keberkesanan kos sokongan komersial untuk rangka kerja Java
Jun 05, 2024 pm 05:25 PM
Bagaimana untuk menilai keberkesanan kos sokongan komersial untuk rangka kerja Java
Jun 05, 2024 pm 05:25 PM
Menilai kos/prestasi sokongan komersial untuk rangka kerja Java melibatkan langkah-langkah berikut: Tentukan tahap jaminan yang diperlukan dan jaminan perjanjian tahap perkhidmatan (SLA). Pengalaman dan kepakaran pasukan sokongan penyelidikan. Pertimbangkan perkhidmatan tambahan seperti peningkatan, penyelesaian masalah dan pengoptimuman prestasi. Timbang kos sokongan perniagaan terhadap pengurangan risiko dan peningkatan kecekapan.
 Semakan! Ringkaskan secara menyeluruh peranan penting model asas dalam mempromosikan pemanduan autonomi
Jun 11, 2024 pm 05:29 PM
Semakan! Ringkaskan secara menyeluruh peranan penting model asas dalam mempromosikan pemanduan autonomi
Jun 11, 2024 pm 05:29 PM
Ditulis di atas & pemahaman peribadi pengarang: Baru-baru ini, dengan perkembangan dan penemuan teknologi pembelajaran mendalam, model asas berskala besar (Model Asas) telah mencapai hasil yang ketara dalam bidang pemprosesan bahasa semula jadi dan penglihatan komputer. Aplikasi model asas dalam pemanduan autonomi juga mempunyai prospek pembangunan yang hebat, yang boleh meningkatkan pemahaman dan penaakulan senario. Melalui pra-latihan tentang bahasa yang kaya dan data visual, model asas boleh memahami dan mentafsir pelbagai elemen dalam senario pemanduan autonomi dan melakukan penaakulan, menyediakan arahan bahasa dan tindakan untuk memacu membuat keputusan dan perancangan. Model asas boleh ditambah data dengan pemahaman senario pemanduan untuk menyediakan ciri-ciri yang jarang berlaku dalam pengedaran ekor panjang yang tidak mungkin ditemui semasa pemanduan rutin dan pengumpulan data.
 Bagaimanakah keluk pembelajaran rangka kerja PHP berbanding rangka kerja bahasa lain?
Jun 06, 2024 pm 12:41 PM
Bagaimanakah keluk pembelajaran rangka kerja PHP berbanding rangka kerja bahasa lain?
Jun 06, 2024 pm 12:41 PM
Keluk pembelajaran rangka kerja PHP bergantung pada kecekapan bahasa, kerumitan rangka kerja, kualiti dokumentasi dan sokongan komuniti. Keluk pembelajaran rangka kerja PHP adalah lebih tinggi jika dibandingkan dengan rangka kerja Python dan lebih rendah jika dibandingkan dengan rangka kerja Ruby. Berbanding dengan rangka kerja Java, rangka kerja PHP mempunyai keluk pembelajaran yang sederhana tetapi masa yang lebih singkat untuk bermula.
 Adakah set data yang berbeza mempunyai undang-undang penskalaan yang berbeza? Dan anda boleh meramalkannya dengan algoritma pemampatan
Jun 07, 2024 pm 05:51 PM
Adakah set data yang berbeza mempunyai undang-undang penskalaan yang berbeza? Dan anda boleh meramalkannya dengan algoritma pemampatan
Jun 07, 2024 pm 05:51 PM
Secara umumnya, lebih banyak pengiraan yang diperlukan untuk melatih rangkaian saraf, lebih baik prestasinya. Apabila menskalakan pengiraan, keputusan mesti dibuat: meningkatkan bilangan parameter model atau meningkatkan saiz set data—dua faktor yang mesti ditimbang dalam belanjawan pengiraan tetap. Kelebihan menambah bilangan parameter model ialah ia boleh meningkatkan kerumitan dan keupayaan ekspresi model, dengan itu lebih sesuai dengan data latihan. Walau bagaimanapun, terlalu banyak parameter boleh menyebabkan pemasangan berlebihan, menjadikan model berprestasi buruk pada data yang tidak kelihatan. Sebaliknya, mengembangkan saiz set data boleh meningkatkan keupayaan generalisasi model dan mengurangkan masalah overfitting. Biar kami memberitahu anda: Selagi anda memperuntukkan parameter dan data dengan sewajarnya, anda boleh memaksimumkan prestasi dalam belanjawan pengkomputeran tetap. Banyak kajian terdahulu telah meneroka Scalingl model bahasa saraf.
