


Jika anda perlu mengakses berbilang perkhidmatan untuk melengkapkan pemprosesan permintaan, seperti semasa melaksanakan fungsi muat naik fail, mula-mula akses cache Redis, sahkan sama ada pengguna telah log masuk, dan kemudian terima badan dalam mesej HTTP Dan simpan pada cakera, dan akhirnya tulis laluan fail dan maklumat lain ke dalam pangkalan data MySQL Apa yang akan anda lakukan?
Pertama, anda boleh menggunakan API penyekat untuk menulis kod penyegerakan dan hanya mensirikannya langkah demi langkah Walau bagaimanapun, adalah jelas bahawa satu urutan hanya boleh memproses satu permintaan pada masa yang sama. Kami tahu bahawa bilangan utas adalah terhad Bilangan utas yang terhad menjadikannya mustahil untuk mencapai berpuluh-puluh ribu sambungan serentak.
Jadi untuk mencapai keselarasan tinggi, anda boleh memilih rangka kerja tak segerak, menggunakan API tidak menyekat untuk mengganggu logik perniagaan ke dalam berbilang fungsi panggil balik dan mencapai keselarasan tinggi melalui pemultipleksan. Tetapi pada masa ini, kod perniagaan diperlukan untuk memberi terlalu banyak perhatian kepada butiran konkurensi dan perlu mengekalkan banyak keadaan perantaraan Sebaik sahaja ralat berlaku dalam logik kod, ia akan jatuh ke dalam neraka panggilan balik.
Oleh itu, bukan sahaja kadar pepijat akan menjadi sangat tinggi, tetapi kelajuan pembangunan projek juga akan diperlahankan, dan akan terdapat risiko dalam melancarkan produk tepat pada masanya. Jika anda ingin mengambil kira kecekapan pembangunan sambil memastikan keselarasan yang tinggi, coroutine ialah pilihan terbaik. Ia boleh menulis kod secara segerak sambil mengekalkan mekanisme operasi tak segerak Ini bukan sahaja mencapai konkurensi tinggi tetapi juga memendekkan kitaran pembangunan masa hadapan perkhidmatan berprestasi tinggi.
Di sini kita mesti menunjukkan bahawa dari segi konkurensi, menggunakan "coroutine" tidak lebih baik daripada "tidak menyekat + panggil balik", dan sebab kami memilih coroutine adalah kerana model pengaturcaraannya Ia lebih mudah, serupa kepada penyegerakan, yang membolehkan kami menulis kod tak segerak dengan cara segerak. Kaedah "tidak menyekat + panggil balik" ialah ujian hebat kemahiran pengaturcaraan Apabila ralat berlaku, sukar untuk mengesan masalah dan mudah mengalami masalah seperti neraka panggil balik dan koyak tindanan.
Jadi, anda akan mendapati bahawa teknologi untuk menyelesaikan masalah konkurensi tinggi telah berubah, daripada berbilang proses dan berbilang benang kepada tak segerak dan coroutine, mereka semua menyelesaikannya dengan cara yang berbeza. Mari kita lihat bagaimana penyelesaian konkurensi tinggi telah berkembang, apakah masalah yang diselesaikan oleh coroutine dan cara ia harus digunakan.
Kami tahu bahawa hos mempunyai sumber terhad, satu CPU, satu cakera dan satu kad rangkaian Bagaimana ia boleh menyampaikan ratusan permintaan pada masa yang sama masa? Mod berbilang proses ialah penyelesaian asal. Kernel membahagikan masa perlaksanaan CPU kepada banyak kepingan masa (timelices) Contohnya, 1 saat boleh dibahagikan kepada 100 10 milisaat hirisan Setiap hirisan masa kemudiannya diedarkan kepada proses yang berbeza suatu permintaan.
Dengan cara ini, walaupun dari perspektif mikro, sebagai contoh, CPU hanya boleh melaksanakan satu proses dalam 10 milisaat ini, dari perspektif makro, 100 kepingan masa dilaksanakan dalam 1 saat, jadi permintaan dalam proses yang dimiliki setiap kepingan masa juga diperolehi, yang mencapai pelaksanaan serentak permintaan.
Walau bagaimanapun, ruang ingatan setiap proses adalah bebas, jadi menggunakan berbilang proses untuk mencapai konkurensi mempunyai dua kelemahan: satu ialah kos pengurusan kernel yang tinggi, dan satu lagi ialah ketidakupayaan untuk menyegerakkan data melalui memori, yang sangat sukar menyusahkan. Akibatnya, mod berbilang benang muncul Mod berbilang benang menyelesaikan dua masalah ini dengan berkongsi ruang alamat memori.
Walau bagaimanapun, walaupun ruang alamat yang dikongsi boleh berkongsi objek dengan mudah, ia juga membawa kepada masalah, iaitu, apabila mana-mana urutan membuat ralat, semua urutan dalam proses akan ranap bersama-sama. Inilah sebabnya mengapa perkhidmatan seperti Nginx yang menekankan kestabilan bertegas untuk menggunakan mod berbilang proses.
Tetapi sebenarnya, sama ada berdasarkan berbilang proses atau berbilang benang, sukar untuk mencapai keselarasan tinggi, terutamanya atas dua sebab berikut.
Rajah berikut mengambil cakera IO sebagai contoh untuk menerangkan kaedah penukaran antara dua benang menggunakan kaedah menyekat untuk membaca cakera dalam berbilang benang.
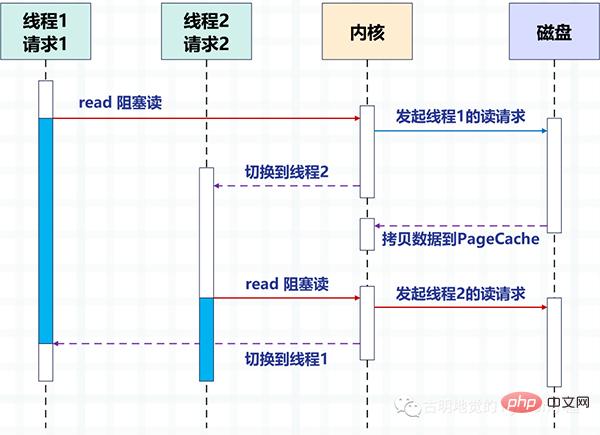
Melalui multi-threading, satu thread memproses satu permintaan untuk mencapai concurrency. Tetapi jelas bahawa bilangan benang yang boleh dibuat oleh sistem pengendalian adalah terhad, kerana lebih banyak benang, lebih banyak sumber diduduki, dan kos menukar antara benang juga agak tinggi, kerana ia melibatkan pertukaran antara mod kernel dan pengguna mod.
Maka persoalannya, bagaimana kita boleh mencapai konkurensi yang tinggi? Jawapannya ialah "Serahkan sahaja kerja penukaran permintaan yang dilaksanakan oleh kernel dalam rajah di atas kepada kod mod pengguna." Pengaturcaraan tak segerak melaksanakan penukaran permintaan melalui kod lapisan aplikasi, mengurangkan kos penukaran dan jejak memori.
Asynchronousization bergantung pada mekanisme pemultipleksan IO, seperti epoll Linux Pada masa yang sama, kaedah penyekatan mesti ditukar kepada kaedah tidak menyekat untuk mengelakkan penggunaan besar yang disebabkan oleh penukaran kernel. Perkhidmatan berprestasi tinggi seperti Nginx dan Redis bergantung pada penyegerakan untuk mencapai berjuta-juta tahap keselarasan.
Rajah berikut menerangkan cara permintaan ditukar selepas bacaan tidak menyekat IO tak segerak digabungkan dengan rangka kerja tak segerak.
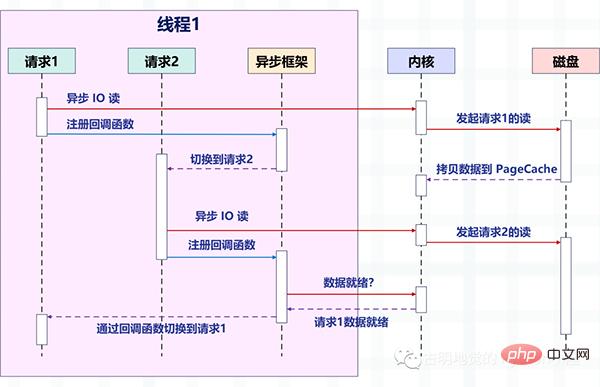
Perhatikan perubahan dalam gambar Sebelum ini, satu utas memproses satu permintaan, tetapi kini satu utas memproses berbilang permintaan + cara panggil balik". Ia bergantung pada pemultipleksan IO yang disediakan oleh sistem pengendalian, seperti epoll Linux dan kqueue BSD.
Operasi baca dan tulis pada masa ini adalah bersamaan dengan acara, dan fungsi panggil balik yang sepadan didaftarkan untuk setiap acara Kemudian urutan tidak akan disekat (kerana operasi baca dan tulis tidak disekat pada masa ini masa), tetapi boleh Melakukan perkara lain, dan kemudian biarkan epoll menguruskan acara ini secara seragam.
Setelah peristiwa berlaku (apabila ia boleh dibaca dan boleh ditulis), epoll akan memberitahu urutan, dan kemudian urutan melaksanakan fungsi panggil balik yang didaftarkan untuk acara tersebut.
Untuk pemahaman yang lebih baik, mari kita ambil Redis sebagai contoh untuk memperkenalkan pemultipleksan IO dan IO yang tidak menyekat.
127.0.0.1:6379> get name "satori"
Pertama sekali, kita boleh menggunakan arahan get untuk mendapatkan nilai yang sepadan dengan kunci. Kemudian persoalannya, apakah yang berlaku kepada pelayan Redis di atas?
Pelayan mesti terlebih dahulu mendengar permintaan pelanggan (bind/listen), kemudian mewujudkan sambungan dengan klien apabila ia tiba (terima), membaca permintaan pelanggan (recv) dari soket, dan menghuraikan permintaan itu (parse), jenis permintaan yang dihuraikan di sini ialah dapatkan, kuncinya ialah "nama", dan kemudian nilai yang sepadan diperolehi mengikut kekunci, dan akhirnya dikembalikan kepada pelanggan, iaitu, menulis data ke soket (hantar).
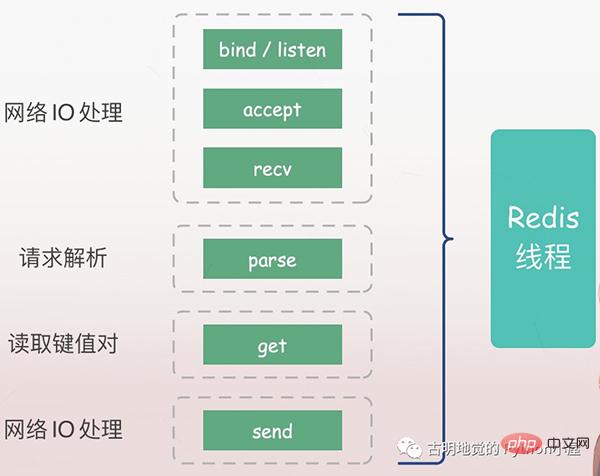
Semua operasi di atas dilaksanakan mengikut urutan oleh urutan utama Redis, tetapi terdapat potensi titik sekatan, iaitu terima dan pulih.
Jika ia menyekat IO, apabila Redis mengesan permintaan sambungan daripada pelanggan tetapi gagal mewujudkan sambungan, utas utama akan sentiasa disekat dalam fungsi terima, menyebabkan pelanggan lain tidak dapat mewujudkan sambungan dengan Redis sambung. Begitu juga, apabila Redis membaca data daripada klien melalui recv, jika data belum sampai, utas utama Redis akan sentiasa disekat dalam langkah recv, jadi ini akan menyebabkan kecekapan Redis menjadi rendah.
Tetapi yang jelas, Redis tidak akan membenarkan ini berlaku, kerana semua situasi di atas adalah semua situasi yang akan dihadapi oleh IO yang menyekat, dan Redis menggunakan IO yang tidak menyekat, iaitu, ia akan Soket ditetapkan kepada mod tidak menyekat. Pertama, dalam model soket, memanggil kaedah socket() akan mengembalikan soket aktif memanggil kaedah bind() untuk mengikat IP dan port, dan kemudian memanggil kaedah listen() untuk menukar soket aktif menjadi soket mendengar; akhirnya, soket mendengar Soket memanggil kaedah accept() untuk menunggu ketibaan sambungan klien Apabila sambungan diwujudkan dengan klien, ia mengembalikan soket yang disambungkan, dan kemudian menggunakan soket yang disambungkan untuk menerima dan menghantar data ke. pelanggan.
Tetapi ambil perhatian: Kami berkata bahawa dalam langkah listen(), soket aktif akan ditukar kepada soket mendengar dan jenis soket mendengar pada masa ini adalah menyekat Jenis soket mendengar Apabila antara muka memanggil kaedah accept(), jika tiada klien untuk disambungkan, ia akan sentiasa berada dalam keadaan disekat, dan utas utama tidak akan dapat melakukan perkara lain pada masa ini. Oleh itu, anda boleh menetapkannya kepada tidak menyekat apabila mendengar() Apabila soket mendengar tanpa menyekat menerima(), jika tiada permintaan sambungan pelanggan tiba, utas utama tidak akan menunggu dengan bodoh , tetapi akan kembali terus dan kemudian melakukannya perkara lain.
Begitu juga, apabila kita mencipta soket bersambung, kita juga boleh menetapkan jenisnya kepada tidak menyekat, kerana jenis menyekat soket bersambung juga akan disekat apabila memanggil send() / recv() Ia akan berada dalam keadaan menyekat Contohnya, apabila pelanggan tidak menghantar data, soket yang disambungkan akan sentiasa disekat dalam langkah rev(). Jika ia adalah jenis soket bersambung yang tidak menyekat, maka apabila recv() dipanggil tetapi tiada data diterima, tidak perlu berada dalam keadaan menyekat, dan anda juga boleh kembali terus untuk melakukan perkara lain.
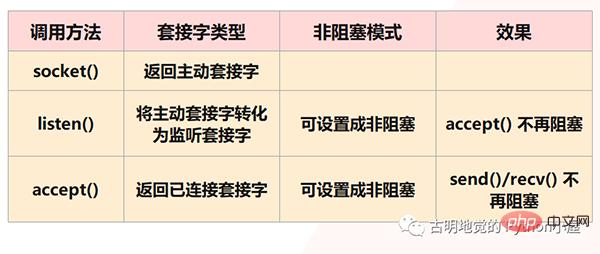
Tetapi terdapat dua perkara yang perlu diperhatikan:
1) Walaupun accept() tidak disekat, utas utama Redis boleh melakukan perkara lain apabila tiada sambungan klien . Tetapi jika pelanggan datang untuk menyambung kemudian, bagaimana Redis tahu? Oleh itu, mesti ada mekanisme yang boleh terus menunggu permintaan sambungan seterusnya pada soket pendengaran dan memberitahu Redis apabila permintaan itu tiba.
2) send() / recv() tidak lagi disekat Proses membaca dan menulis bersamaan dengan IO tidak lagi disekat Kaedah membaca dan menulis akan selesai dan kembali serta-merta, iaitu ia akan membaca seberapa banyak yang boleh dibaca Kita boleh menulis sebanyak yang kita boleh untuk melaksanakan operasi IO, yang jelas lebih selaras dengan usaha kita untuk mencapai prestasi. Tetapi ini juga akan menghadapi masalah, iaitu, apabila kita melakukan operasi baca, kemungkinan hanya sebahagian daripada data telah dibaca, dan data yang tinggal belum dihantar oleh pelanggan Jadi bilakah data ini boleh dibaca? Perkara yang sama berlaku untuk menulis data Apabila penimbal penuh dan data kami belum ditulis lagi, bilakah baki data boleh ditulis? Oleh itu, mesti ada juga mekanisme yang boleh terus memantau soket yang disambungkan semasa utas utama Redis melakukan perkara lain, dan memberitahu Redis apabila terdapat data untuk membaca dan menulis.
Ini akan memastikan bahawa utas Redis tidak akan menunggu di titik penyekatan seperti dalam model IO asas, dan ia juga tidak akan dapat memproses permintaan sambungan pelanggan yang tiba dan data yang boleh dibaca dan boleh ditulis seperti yang dinyatakan di atas mekanisme ialah pemultipleksan IO.
Mekanisme pemultipleksan I/O merujuk kepada benang memproses berbilang strim IO, iaitu pemilihan/pungutan suara/epoll yang sering kita dengar. Kami tidak akan bercakap tentang perbezaan antara ketiga-tiga ini. Mereka semua melakukan perkara yang sama, tetapi terdapat perbezaan dalam prinsip prestasi dan pelaksanaan. pilih disokong oleh semua sistem, manakala epoll hanya disokong oleh Linux.
Ringkasnya, apabila Redis hanya menjalankan satu utas, mekanisme ini membenarkan berbilang soket pendengaran dan soket bersambung wujud dalam kernel pada masa yang sama. Kernel akan sentiasa memantau permintaan sambungan atau permintaan data pada soket ini Setelah permintaan tiba, ia akan diserahkan kepada utas Redis untuk diproses, sekali gus mencapai kesan satu utas Redis memproses berbilang aliran IO.
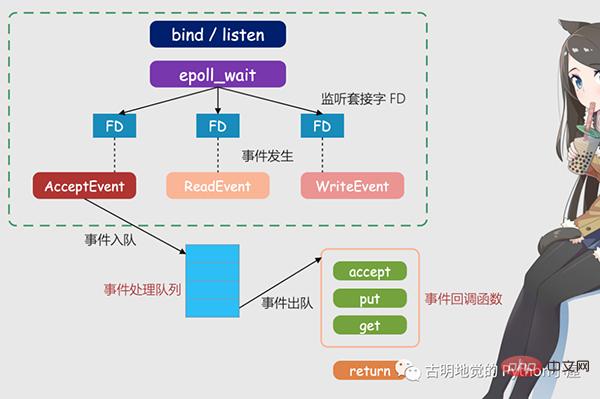
Gambar di atas ialah model Redis IO berdasarkan pemultipleksan. FD dalam gambar ialah soket, yang boleh menjadi soket pendengaran atau soket yang disambungkan, Redis akan menggunakan mekanisme epoll untuk membenarkan kernel membantu memantau soket ini. Pada masa ini, utas Redis atau utas utama tidak akan disekat pada soket tertentu, yang bermaksud bahawa ia tidak akan disekat pada pemprosesan permintaan pelanggan tertentu. Oleh itu, Redis boleh menyambung kepada berbilang pelanggan pada masa yang sama dan memproses permintaan, dengan itu meningkatkan keselarasan.
Tetapi untuk memberitahu urutan Redis apabila permintaan tiba, epoll menyediakan mekanisme panggil balik berasaskan peristiwa, iaitu, memanggil fungsi pemprosesan yang sepadan untuk kejadian yang berbeza.
Jadi bagaimana mekanisme panggil balik berfungsi? Mengambil angka di atas sebagai contoh, pertama, epoll akan mencetuskan peristiwa yang sepadan setelah ia mengesan bahawa permintaan tiba pada FD. Acara ini akan dimasukkan ke dalam baris gilir, dan urutan utama Redis akan terus memproses baris gilir acara Dengan cara ini, Redis tidak perlu terus mengundi sama ada terdapat permintaan, dengan itu mengelakkan pembaziran sumber.
Pada masa yang sama, apabila Redis memproses acara dalam baris gilir acara, ia akan memanggil fungsi pemprosesan yang sepadan, yang melaksanakan panggilan balik berasaskan acara. Oleh kerana Redis telah memproses baris gilir acara, ia boleh bertindak balas kepada permintaan pelanggan tepat pada masanya dan meningkatkan prestasi respons Redis.
Mari kita ambil permintaan sambungan sebenar dan permintaan baca data sebagai contoh untuk menerangkan lebih lanjut. Permintaan sambungan dan permintaan baca data masing-masing sepadan dengan acara Terima dan acara Baca Redis menerima dan dapatkan fungsi panggil balik untuk kedua-dua acara ini Apabila kernel Linux memantau permintaan sambungan atau permintaan baca data, ia akan mencetuskan acara Terima atau acara Baca , kemudian maklumkan utas utama dan panggil semula fungsi terima atau dapatkan berdaftar.
Sama seperti pesakit yang pergi ke hospital untuk berjumpa doktor, setiap pesakit (sama seperti permintaan) perlu diuji, diperiksa suhu, didaftarkan, dan lain-lain sebelum doktor benar-benar boleh mendiagnosis. Jika semua tugas ini dilakukan oleh doktor, kecekapan kerja mereka akan menjadi sangat rendah. Oleh itu, hospital telah menyediakan stesen triage Stesen triage akan sentiasa mengendalikan tugasan pra-diagnosis ini (serupa dengan permintaan mendengar kernel Linux), dan kemudian memindahkannya kepada doktor untuk diagnosis sebenar (bersamaan dengan utas utama Redis) boleh Boleh menjadi sangat cekap.
这里需要再补充一下:我们上面提到的异步 IO 不是真正意义上的异步 IO,而是基于 IO 多路复用实现的异步化。但 IO 多路复用本质上是同步 IO,只是它可以同时监听多个文件描述符,一旦某个描述符的读写操作就绪,就能够通知应用程序进行相应的读写操作。至于真正意义的异步 IO,操作系统也是支持的,但支持的不太理想,所以现在使用的都是 IO 多用复用,并代指异步 IO。
必须要承认的是,编写这种异步化代码能够带来很高的性能收益,Redis、Nginx 已经证明了这一点。
但是这种编程模式,在实际工作中很容易出错,因为所有阻塞函数,都需要通过非阻塞的系统调用加上回调注册的方式拆分成两个函数。说白了就是我们的逻辑不能够直接执行,必须把它们放在一个单独的函数里面,然后这个函数以回调的方式注册给 IO 多路复用。
这种编程模式违反了软件工程的内聚性原则,函数之间同步数据也更复杂。特别是条件分支众多、涉及大量系统调用时,异步化的改造工作会非常困难,尽管它的性能很高。
下面我们用 Python 编写一段代码,实际体验一下这种编程模式,看看它复杂在哪里。
from urllib.parse import urlparse
import socket
from io import BytesIO
# selectors 里面提供了多种"多路复用器"
# 除了 select、poll、epoll 之外
# 还有 kqueue,这个是针对 BSD 平台的
try:
from selectors import (
SelectSelector,
PollSelector,
EpollSelector,
KqueueSelector
)
except ImportError:
pass
# 由于种类比较多,所以提供了DefaultSelector
# 会根据当前的系统种类,自动选择一个合适的多路复用器
from selectors import (
DefaultSelector,
EVENT_READ,# 读事件
EVENT_WRITE,# 写事件
)
class RequestHandler:
"""
向指定的 url 发请求
获取返回的内容
"""
selector = DefaultSelector()
tasks = {"unfinished": 0}
def __init__(self, url):
"""
:param url: http://localhost:9999/v1/index
"""
self.tasks["unfinished"] += 1
url = urlparse(url)
# 根据 url 解析出 域名、端口、查询路径
self.netloc = url.netloc# 域名:端口
self.path = url.path or "/"# 查询路径
# 创建 socket
self.client = socket.socket()
# 设置成非阻塞
self.client.setblocking(False)
# 用于接收数据的缓存
self.buffer = BytesIO()
def get_result(self):
"""
发送请求,进行下载
:return:
"""
# 连接到指定的服务器
# 如果没有 : 说明只有域名没有端口
# 那么默认访问 80 端口
if ":" not in self.netloc:
host, port = self.netloc, 80
else:
host, port = self.netloc.split(":")
# 由于 socket 非阻塞,所以连接可能尚未建立好
try:
self.client.connect((host, int(port)))
except BlockingIOError:
pass
# 我们上面是建立连接,连接建立好就该发请求了
# 但是连接什么时候建立好我们并不知道,只能交给操作系统
# 所以我们需要通过 register 给 socket 注册一个回调函数
# 参数一:socket 的文件描述符
# 参数二:事件
# 参数三:当事件发生时执行的回调函数
self.selector.register(self.client.fileno(),
EVENT_WRITE,
self.send)
# 表示当 self.client 这个 socket 满足可写时
# 就去执行 self.send
# 翻译过来就是连接建立好了,就去发请求
# 可以看到,一个阻塞调用,我们必须拆成两个函数去写
def send(self, key):
"""
连接建立好之后,执行的回调函数
回调需要接收一个参数,这是一个 namedtuple
内部有如下字段:'fileobj', 'fd', 'events', 'data'
key.fd 就是 socket 的文件描述符
key.data 就是给 socket 绑定的回调
:param key:
:return:
"""
payload = (f"GET {self.path} HTTP/1.1rn"
f"Host: {self.netloc}rn"
"Connection: closernrn")
# 执行此函数,说明事件已经触发
# 我们要将绑定的回调函数取消
self.selector.unregister(key.fd)
# 发送请求
self.client.send(payload.encode("utf-8"))
# 请求发送之后就要接收了,但是啥时候能接收呢?
# 还是要交给操作系统,所以仍然需要注册回调
self.selector.register(self.client.fileno(),
EVENT_READ,
self.recv)
# 表示当 self.client 这个 socket 满足可读时
# 就去执行 self.recv
# 翻译过来就是数据返回了,就去接收数据
def recv(self, key):
"""
数据返回时执行的回调函数
:param key:
:return:
"""
# 接收数据,但是只收了 1024 个字节
# 如果实际返回的数据超过了 1024 个字节怎么办?
data = self.client.recv(1024)
# 很简单,只要数据没收完,那么数据到来时就会可读
# 那么会再次调用此函数,直到数据接收完为止
# 注意:此时是非阻塞的,数据有多少就收多少
# 没有接收的数据,会等到下一次再接收
# 所以这里不能写 while True
if data:
# 如果有数据,那么写入到 buffer 中
self.buffer.write(data)
else:
# 否则说明数据读完了,那么将注册的回调取消
self.selector.unregister(key.fd)
# 此时就拿到了所有的数据
all_data = self.buffer.getvalue()
# 按照 rnrn 进行分隔得到列表
# 第一个元素是响应头,第二个元素是响应体
result = all_data.split(b"rnrn")[1]
print(f"result: {result.decode('utf-8')}")
self.client.close()
self.tasks["unfinished"] -= 1
@classmethod
def run_until_complete(cls):
# 基于 IO 多路复用创建事件循环
# 驱动内核不断轮询 socket,检测事件是否发生
# 当事件发生时,调用相应的回调函数
while cls.tasks["unfinished"]:
# 轮询,返回事件已经就绪的 socket
ready = cls.selector.select()
# 这个 key 就是回调里面的 key
for key, mask in ready:
# 拿到回调函数并调用,这一步需要我们手动完成
callback = key.data
callback(key)
# 因此当事件发生时,调用绑定的回调,就是这么实现的
# 整个过程就是给 socket 绑定一个事件 + 回调
# 事件循环不停地轮询检测,一旦事件发生就会告知我们
# 但是调用回调不是内核自动完成的,而是由我们手动完成的
# "非阻塞 + 回调 + 基于 IO 多路复用的事件循环"
# 所有框架基本都是这个套路一个简单的 url 获取,居然要写这么多代码,而它的好处就是性能高,因为不用把时间浪费在建立连接、等待数据上面。只要有事件发生,就会执行相应的回调,极大地提高了 CPU 利用率。而且这是单线程,也没有线程切换带来的开销。
那么下面测试一下吧。
import time
start = time.perf_counter()
for _ in range(10):
# 这里面只是注册了回调,但还没有真正执行
RequestHandler(url="https://localhost:9999/index").get_result()
# 创建事件循环,驱动执行
RequestHandler.run_until_complete()
end = time.perf_counter()
print(f"总耗时: {end - start}")我用 FastAPI 编写了一个服务,为了更好地看到现象,服务里面刻意 sleep 了 1 秒。然后发送十次请求,看看效果如何。
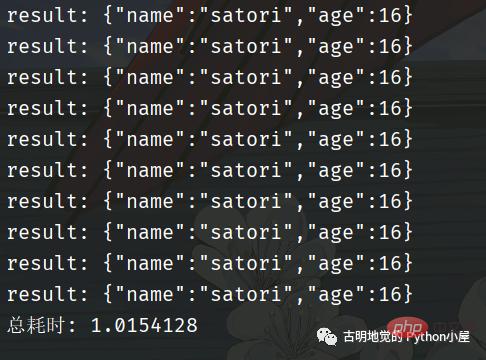
总共耗时 1 秒钟,我们再采用同步的方式进行编写,看看效果如何。
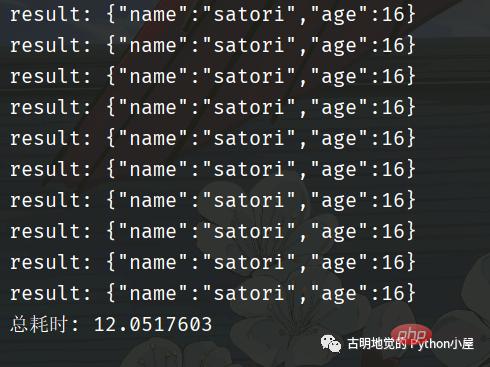
可以看到回调的这种写法性能非常高,但是它和我们传统的同步代码的写法大相径庭。如果是同步代码,那么会先建立连接、然后发送数据、再接收数据,这显然更符合我们人类的思维,逻辑自上而下,非常自然。
但是回调的方式,就让人很不适应,我们在建立完连接之后,不能直接发送数据,必须将发送数据的逻辑放在一个单独的函数(方法)中,然后再将这个函数以回调的方式注册进去。
同理,在发送完数据之后,也不能立刻接收。同样要将接收数据的逻辑放在一个单独的函数中,然后再以回调的方式注册进去。
所以好端端的自上而下的逻辑,因为回调而被分割的四分五裂,这种代码在编写和维护的时候是非常痛苦的。
比如回调可能会层层嵌套,容易陷入回调地狱,如果某一个回调执行出错了怎么办?代码的可读性差导致不好排查,即便排查到了也难处理。
另外,如果多个回调需要共享一个变量该怎么办?因为回调是通过事件循环调用的,在注册回调的时候很难把变量传过去。简单的做法是把该变量设置为全局变量,或者说多个回调都是某个类的成员函数,然后把共享的变量作为一个属性绑定在 self 上面。但当逻辑复杂时,就很容易导致全局变量满天飞的问题。
所以这种模式就使得开发人员在编写业务逻辑的同时,还要关注并发细节。
因此使用回调的方式编写异步化代码,虽然并发量能上去,但是对开发者很不友好;而使用同步的方式编写同步代码,虽然很容易理解,可并发量却又上不去。那么问题来了,有没有一种办法,能够让我们在享受异步化带来的高并发的同时,又能以同步的方式去编写代码呢?也就是我们能不能以同步的方式去编写异步化的代码呢?
答案是可以的,使用「协程」便可以办到。协程在异步化之上包了一层外衣,兼顾了开发效率与运行效率。
协程与异步编程相似的地方在于,它们必须使用非阻塞的系统调用与内核交互,把切换请求的权力牢牢掌握在用户态的代码中。但不同的地方在于,协程把异步化中的两段函数,封装为一个阻塞的协程函数。
这个函数执行时,会使调用它的协程无感知地放弃执行权,由协程框架切换到其他就绪的协程继续执行。当这个函数的结果满足后,协程框架再选择合适的时机,切换回它所在的协程继续执行。我们还是以读取磁盘文件为例,看一张协程的示意图:
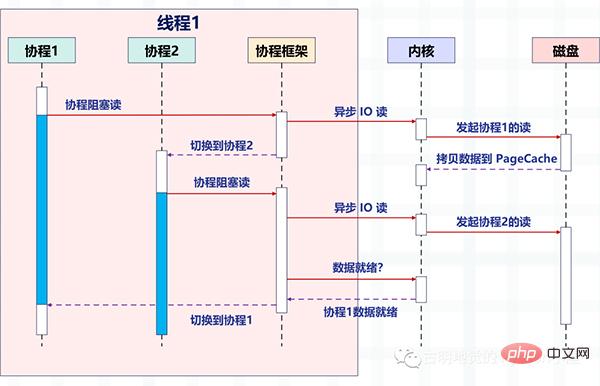
看起来非常棒,所以异步化是通过回调函数来完成请求切换的,业务逻辑与并发实现关联在一起,很容易出错。而协程不需要什么「回调函数」,它允许用户调用「阻塞的」协程方法,用同步编程方式写业务逻辑。
再回到之前的那个 socket 发请求的例子,我们用协程的方式重写一遍,看看它和基于回调的异步化编程有什么区别?
import time
from urllib.parse import urlparse
import asyncio
async def download(url):
url = urlparse(url)
# 域名:端口
netloc = url.netloc
if ":" not in netloc:
host, port = netloc, 80
else:
host, port = netloc.split(":")
path = url.path or "/"
# 创建连接
reader, writer = await asyncio.open_connection(host, port)
# 发送数据
payload = (f"GET {path} HTTP/1.1rn"
f"Host: {netloc}rn"
"Connection: closernrn")
writer.write(payload.encode("utf-8"))
await writer.drain()
# 接收数据
result = (await reader.read()).split(b"rnrn")[1]
writer.close()
print(f"result: {result.decode('utf-8')}")
# 以上就是发送请求相关的逻辑
# 我们看到代码是自上而下的,没有涉及到任何的回调
# 完全就像写同步代码一样
async def main():
# 发送 10 个请求
await asyncio.gather(
*[download("http://localhost:9999/index")
for _ in range(10)]
)
start = time.perf_counter()
# 同样需要创建基于 IO 多路复用的事件循环
# 协程会被丢进事件循环中,依靠事件循环驱动执行
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
end = time.perf_counter()
print(f"总耗时: {end - start}")代码逻辑很好理解,和我们平时编写的同步代码没有太大的区别,那么它的效率如何呢?
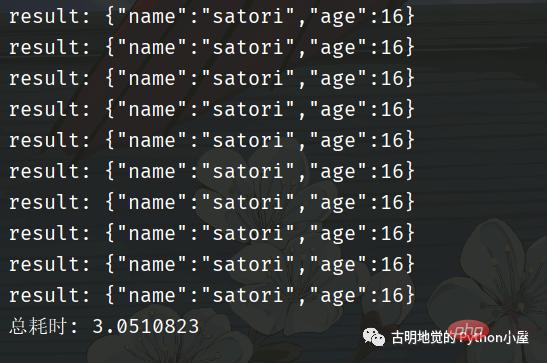
我们看到用了 3 秒钟,比同步的方式快,但是比异步化的方式要慢。因为一开始就说过,协程并不比异步化的方式快,但我们之所以选择它,是因为它的编程模型更简单,能够让我们以同步的方式编写异步的代码。如果是基于回调方式的异步化,虽然性能很高(比如 Redis、Nginx),但对开发者是一个挑战。
回到上面那个协程的例子中,我们一共发了 10 个请求,并在可能阻塞的地方加上了 await。意思就是,在执行某个协程 await 后面的代码时如果阻塞了,那么该协程会主动将执行权交给事件循环,然后事件循环再选择其它的协程执行。并且协程本质上也是个单线程,虽然协程可以有多个,但是背后的线程只有一个。
那么问题来了,协程的切换是如何完成的呢?
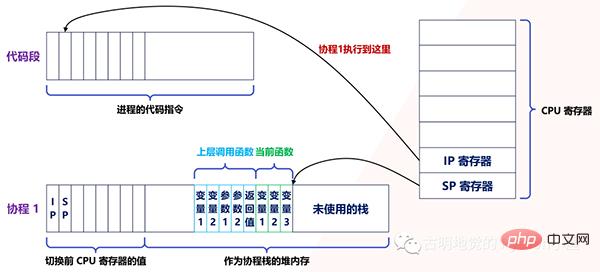
实际上,用户态的代码切换协程,与内核切换线程的原理是一样的。内核通过管理 CPU 的寄存器来切换线程,我们以最重要的栈寄存器和指令寄存器为例,看看协程切换时如何切换程序指令与内存。
每个线程有独立的栈,而栈既保留了变量的值,也保留了函数的调用关系、参数和返回值,CPU 中的栈寄存器 SP 指向了当前线程的栈,而指令寄存器 IP 保存着下一条要执行的指令地址。
因此,从线程 1 切换到线程 2 时,首先要把 SP、IP 寄存器的值为线程 1 保存下来,再从内存中找出线程 2 上一次切换前保存好的寄存器的值,并写入 CPU 的寄存器,这样就完成了线程切换(其他寄存器也需要管理、替换,原理与此相同,不再赘述)。
协程的切换与此相同,只是把内核的工作转移到协程框架来实现而已,下图是协程切换前的状态:
当遇到阻塞时会进行协程切换,从协程 1 切换到协程 2 后的状态如下图所示:
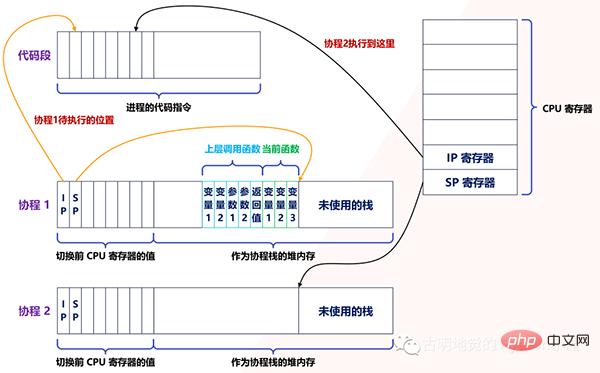
创建协程时,会从进程的堆中分配一段内存作为协程的栈。线程的栈有 8MB,而协程栈的大小通常只有几十 KB。而且,C 库内存池也不会为协程预分配内存,它感知不到协程的存在。这样,更低的内存占用空间为高并发提供了保证,毕竟十万并发请求,就意味着 10 万个协程。
另外栈缩小后,就尽量不要使用递归函数,也不能在栈中申请过多的内存,这是实现高并发必须付出的代价。当然啦,如果能像 Go 一样,协程栈可以自由伸缩的话,就不用担心了。
由此可见,协程就是用户态的线程。然而,为了保证所有切换都在用户态进行,协程必须重新封装所有的阻塞系统调用,否则一旦协程触发了线程切换,会导致这个线程进入休眠状态,进而其上的所有协程都得不到执行。
Sebagai contoh, fungsi tidur biasa akan membuatkan benang semasa tidur, dan kernel akan membangunkan benang Selepas transformasi coroutine, tidur hanya akan membuatkan coroutine semasa tidur, dan rangka kerja coroutine akan membangunkan coroutine selepas itu. masa yang ditentukan, jadi dalam Kami tidak boleh menulis time.sleep dalam coroutine Python, tetapi harus menulis asyncio.sleep. Untuk contoh lain, kunci mutex antara benang dilaksanakan menggunakan semafor, dan semafor juga boleh menyebabkan benang tidur Selepas kunci mutex diubah menjadi coroutine, rangka kerja juga akan menyelaraskan dan menyegerakkan pelaksanaan setiap coroutine.
Jadi prestasi tinggi coroutine adalah berdasarkan fakta bahawa penukaran mesti dilengkapkan dengan kod mod pengguna Ini memerlukan ekosistem coroutine lengkap dan merangkumi komponen biasa sebanyak mungkin.
Mari kita ambil Python sebagai contoh Saya sering melihat orang menulis permintaan.masuk async def untuk menghantar permintaan. Ini adalah salah. Panggilan asas kepada requests.get ialah soket yang disekat secara serentak, yang akan menyebabkan utas tersekat Setelah benang tersekat, ia akan menyebabkan semua coroutine disekat, yang bersamaan dengan bersiri. Jadi tidak ada gunanya meletakkannya di dalam async def, cara yang betul ialah menggunakan aiohttp atau httpx. Oleh itu, jika anda ingin menggunakan coroutine, anda perlu merangkum semula panggilan sistem yang mendasarinya. Jika tiada cara lain, masukkannya ke dalam kumpulan benang untuk dijalankan.
Contoh lain ialah SDK pelanggan yang disediakan secara rasmi oleh MySQL Ia menggunakan soket penyekat untuk akses rangkaian, yang akan menyebabkan rangkaian tidak berfungsi. Anda mesti menggunakan soket tidak menyekat untuk mengubah SDK menjadi fungsi coroutine digunakan dalam coroutine.
Sudah tentu, tidak semua fungsi boleh diubah dengan coroutine, seperti bacaan IO tak segerak daripada cakera. Walaupun ia tidak menyekat, ia tidak boleh menggunakan PageCache, yang mengurangkan daya pemprosesan sistem. Jika anda menggunakan IO cache untuk membaca fail, penyekatan mungkin berlaku apabila PageCache tidak dipukul. Pada masa ini, jika anda mempunyai keperluan prestasi yang lebih tinggi, anda perlu menggabungkan benang dengan coroutine, membuang operasi yang berpotensi menyekat ke dalam kumpulan benang untuk pelaksanaan dan bekerjasama dengan coroutine melalui model pengeluar/pengguna.
Malah, dalam menghadapi sistem berbilang teras, coroutine dan thread juga perlu bekerjasama. Oleh kerana pembawa coroutine ialah utas, dan utas hanya boleh menggunakan satu CPU pada satu masa, dengan membuka lebih banyak utas dan mengedarkan semua coroutine antara utas ini, sumber CPU boleh digunakan sepenuhnya. Jika anda mempunyai pengalaman menggunakan bahasa Go, anda harus mengetahui perkara ini dengan baik.
Selain itu, untuk membolehkan coroutine mendapat lebih banyak masa CPU, anda juga boleh menetapkan keutamaan utas Contohnya, dalam Linux, tetapkan keutamaan utas kepada -20, dan anda boleh dapatkan ia setiap kali masa yang lebih panjang. Di samping itu, cache CPU juga mempunyai kesan ke atas prestasi program Untuk mengurangkan bahagian kegagalan cache CPU, benang juga boleh diikat pada CPU untuk meningkatkan kebarangkalian memukul cache CPU apabila coroutine dilaksanakan.
Walaupun telah dikatakan di sini bahawa rangka kerja coroutine menjadualkan coroutine, anda akan mendapati bahawa banyak perpustakaan coroutine hanya menyediakan kaedah asas seperti mencipta, menggantung, dan menyambung semula pelaksanaan, dan tidak mempunyai kewujudan coroutine rangka kerja. Kod perniagaan menjadualkan coroutine dengan sendirinya. Ini kerana perpustakaan coroutine am ini (seperti asyncio) tidak direka khusus untuk pelayan Penubuhan sambungan rangkaian pelanggan dalam pelayan boleh memacu penciptaan coroutine dan ditamatkan dengan tamat permintaan.
Apabila syarat larian coroutine tidak dipenuhi, rangka kerja pemultipleksan akan menggantungnya dan memilih coroutine lain untuk dilaksanakan mengikut dasar keutamaan. Oleh itu, apabila menggunakan coroutine untuk melaksanakan perkhidmatan konkurensi tinggi pada bahagian pelayan, anda bukan sahaja memilih perpustakaan coroutine, tetapi juga mencari rangka kerja coroutine (seperti Tornado) yang menggabungkan pemultipleksan IO daripada ekosistemnya, yang boleh mempercepatkan pembangunan.
Secara umum, coroutine ialah model konkurensi ringan, yang agak tinggi. Tetapi dalam erti kata yang sempit, coroutine adalah untuk memanggil fungsi yang boleh dijeda dan ditukar. Sebagai contoh, apa yang kita gunakan async def untuk mentakrifkan ialah fungsi coroutine, yang pada asasnya ialah fungsi Apabila memanggil fungsi coroutine, kita akan mendapat coroutine.
Lempar coroutine ke dalam gelung peristiwa dan gelung peristiwa memacu pelaksanaan Setelah disekat, hak pelaksanaan diserahkan secara aktif kepada gelung peristiwa dan gelung peristiwa mendorong coroutine lain untuk dilaksanakan. Jadi hanya terdapat satu utas dari awal hingga akhir, dan coroutine hanya disimulasikan dalam mod pengguna dengan merujuk kepada struktur benang.
Jadi apabila memanggil fungsi biasa, semua logik kod dalaman akan dilaksanakan sehingga semuanya selesai semasa memanggil fungsi coroutine dan penyekatan berlaku secara dalaman, ia akan bertukar kepada coroutine lain.
Walau bagaimanapun, terdapat prasyarat penting untuk menukar apabila coroutine disekat, iaitu, penyekatan ini tidak boleh melibatkan sebarang panggilan sistem, seperti masa.tidur, soket segerak, dsb. Ini semua memerlukan penyertaan kernel, dan sebaik sahaja kernel mengambil bahagian, penyekatan yang disebabkan bukan semudah menyekat coroutine tertentu (OS tidak mengetahui coroutine), tetapi akan menyebabkan benang disekat. Sebaik sahaja benang disekat, semua coroutine di atasnya akan disekat Memandangkan coroutine menggunakan benang sebagai pembawa, pelaksanaan sebenar mestilah benang Jika setiap coroutine menyekat benang, maka ia tidak bersamaan dengan rentetan.
Jadi, jika anda ingin menggunakan coroutine, anda mesti merangkum semula panggilan sistem yang disekat
@app.get(r"/index1") async def index1(): time.sleep(30) return "index1" @app.get(r"/index2") async def index2(): return "index2"
这是一个基于 FastAPI 编写的服务,我们只看视图函数。如果我们先访问 /index1,然后访问 /index2,那么必须等到 30 秒之后,/index2 才会响应。因为这是一个单线程,/index1 里面的 time.sleep 会触发系统调用,使得整个线程都进入阻塞,线程一旦阻塞了,所有的协程就都别想执行了。
如果将上面的例子改一下:
@app.get(r"/index1") async def index(): await asyncio.sleep(30) return "index1" @app.get(r"/index2") async def index(): return "index2"
访问 /index1 依旧会进行 30 秒的休眠,但此时再访问 /index2 的话则是立刻返回。原因是 asyncio.sleep(30) 重新封装了阻塞的系统调用,此时的休眠是在用户态完成的,没有经过内核。换句话说,此时只会导致协程休眠,不会导致线程休眠,那么当访问 /index2 的时候,对应的协程会立刻执行,然后返回结果。
同理我们在发网络请求的时候,也不能使用 requests.get,因为它会导致线程阻塞。当然,还有一些数据库的驱动,例如 pymysql, psycopg2 等等,这些阻塞的都是线程。为此,在开发协程项目时,我们应该使用 aiohttp, asyncmy, asyncpg 等等。
为什么早期 Python 的协程都没有人用,原因就是协程想要运行,必须基于协程库 asyncio,但问题是 asyncio 只支持发送 TCP 请求(对于协程库而言足够了)。如果你想通过网络连接到某个组件(比如数据库、Redis),只能手动发 TCP 请求,而且这些组件对发送的数据还有格式要求,返回的数据也要手动解析,可以想象这是多么麻烦的事情。
如果想解决这一点,那么必须基于 asyncio 重新封装一个 SDK。所以同步 SDK 和协程 SDK 最大的区别就是,一个是基于同步阻塞的 socket,一个是基于 asyncio。比如 redis 和 aioredis,连接的都是 Redis,只是在 TCP 层面发送数据的方式不同,至于其它方面则是类似的。
而早期,还没有出现这些协程 SDK,自己封装的话又是一个庞大的工程,所以 Python 的协程用起来就很艰难,因为达不到期望的效果。不像 Go 在语言层面上就支持协程,一个 go 关键字就搞定了。而且 Python 里面一处异步、处处异步,如果某处的阻塞切换不了,那么协程也就没有意义了。
但现在 Python 已经进化到 3.10 了,协程相关的生态也越来越完善,感谢这些开源的作者们。发送网络请求、连接数据库、编写 web 服务等等,都有协程化的 SDK 和框架,现在完全可以开发以协程为主导的项目了。
本次我们从高并发的应用场景入手,分析了协程出现的背景和实现原理,以及它的应用范围。你会发现,协程融合了多线程与异步化编程的优点,既保证了开发效率,也提升了运行效率。有限的硬件资源下,多线程通过微观上时间片的切换,实现了同时服务上百个用户的能力。多线程的开发成本虽然低,但内存消耗大,切换次数过多,无法实现高并发。
异步编程方式通过非阻塞系统调用和多路复用,把原本属于内核的请求切换能力,放在用户态的代码中执行。这样,不仅减少了每个请求的内存消耗,也降低了切换请求的成本,最终实现了高并发。然而,异步编程违反了代码的内聚性,还需要业务代码关注并发细节,开发成本很高。
协程参考内核通过 CPU 寄存器切换线程的方法,在用户态代码中实现了协程的切换,既降低了切换请求的成本,也使得协程中的业务代码不用关注自己何时被挂起,何时被执行。相比异步编程中要维护一堆数据结构表示中间状态,协程直接用代码表示状态,大大提升了开发效率。但是在协程中调用的所有 API,都需要做非阻塞的协程化改造。优秀的协程生态下,常用服务都有对应的协程 SDK,方便业务代码使用。开发高并发服务时,与 IO 多路复用结合的协程框架可以与这些 SDK 配合,自动挂起、切换协程,进一步提升开发效率。
最后,协程并不是完全与线程无关。因为线程可以帮助协程充分使用多核 CPU 的计算力(Python 除外),而且遇到无法协程化、会导致内核切换的阻塞函数,或者计算太密集从而长时间占用 CPU 的任务,还是要放在独立的线程中,以防止它影响别的协程执行。
Jadi apabila menggunakan coroutine, sebaiknya gunakan kumpulan benang Jika beberapa sekatan mesti melalui kernel dan tidak boleh dicoroutinekan, kemudian buang ke dalam kumpulan benang dan selesaikan penukaran pada tahap benang . Walaupun memulakan beberapa utas akan menduduki sumber, dan penukaran benang akan membawa overhead, untuk menukar melalui penyekatan kernel, ini tidak dapat dielakkan, dan kami hanya boleh meletakkan harapan kami pada utas sudah tentu, untuk tugas yang terlalu CPU-; intensif, Anda juga boleh mempertimbangkan untuk membuangnya ke dalam kolam benang. Sesetengah orang mungkin ingin tahu, jika anda boleh menggunakan berbilang teras, maka adalah munasabah untuk membuangnya ke dalam kumpulan benang, tetapi berbilang benang Python tidak boleh menggunakan berbilang teras, mengapa anda melakukan ini? Alasannya mudah. Jika hanya terdapat satu utas, maka tugas intensif CPU sedemikian akan menduduki sumber CPU untuk masa yang lama, menyebabkan tugas lain tidak dapat dilaksanakan. Apabila multi-threading dihidupkan, walaupun masih ada satu teras, GIL akan menyebabkan penukaran benang, jadi tidak akan ada situasi seperti "raja Chu mempunyai pinggang yang ramping, dan harem mati kelaparan". CPU boleh diagihkan secara sama rata, membolehkan semua tugasan dilaksanakan.
Atas ialah kandungan terperinci Penuh dengan maklumat berguna! Pengenalan menyeluruh tentang cara coroutine Python dilaksanakan! Jika anda memahaminya, anda hebat!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



