

Evolusi teknikal model besar masa nyata untuk cadangan Weibo


1. Semakan peta jalan teknikal
1 > Perniagaan pengesyoran yang pasukan ini bertanggungjawab dalam APP Weibo terutamanya termasuk:
① Kandungan semua lajur tab di bawah pengesyoran halaman utama, produk aliran maklumat secara amnya Tab pertama mempunyai bahagian lalu lintas yang lebih tinggi
② Aliran maklumat yang meluncur ke bawah daripada carian hangat ini juga , termasuk tab aliran maklumat lain ini pada halaman, seperti saluran video, dll.;
③ Cari atau klik video yang disyorkan dalam keseluruhan APP untuk memasuki adegan video yang mengasyikkan.
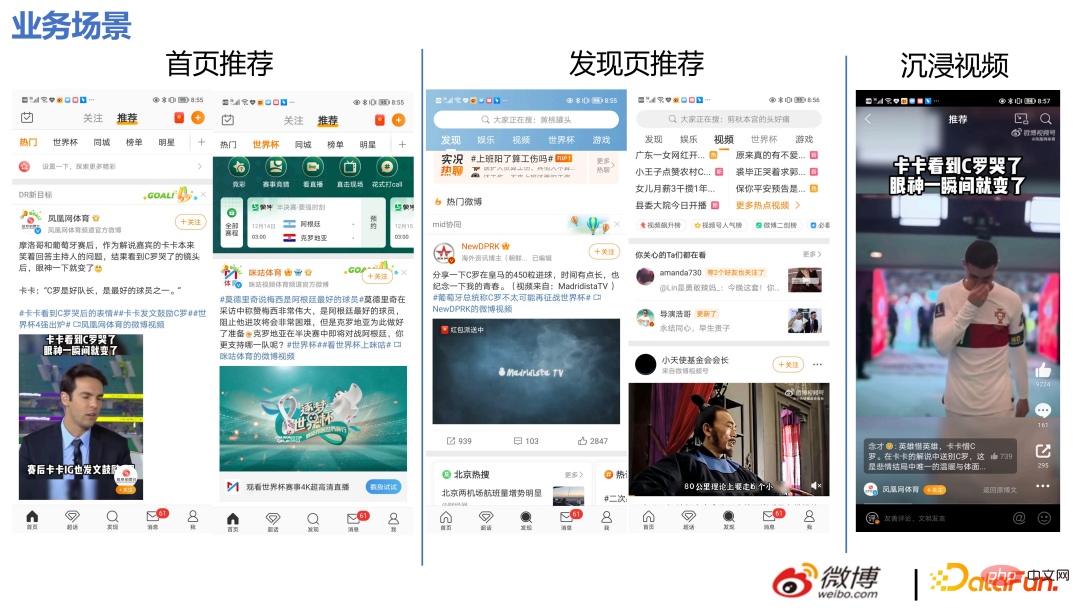 Perniagaan kami mempunyai ciri-ciri berikut:
Perniagaan kami mempunyai ciri-ciri berikut:
(1) Pertama
Pertama, dari perspektif pelaksanaan yang disyorkan: ① Terdapat banyak senario perniagaan.
② Pengguna di UI Weibo mempunyai pelbagai operasi dan maklum balas Kandungan boleh dilihat dengan mengklik pada halaman teks atau digunakan dalam strim pelbagai. Contohnya, klik untuk masuk ke halaman peribadi blogger, klik untuk masuk ke halaman teks, klik pada gambar, klik pada video, ke hadapan komen dan suka, dll.
③ Terdapat banyak jenis bahan yang boleh diedarkan, seperti gambar panjang, gambar (satu gambar atau beberapa gambar), dan video (mendatar atau menegak ) yang boleh diedarkan pada video halaman utama), artikel, dsb.
(2) Dari perspektif kedudukan produk:
① Perkhidmatan tempat panas : Perubahan trafik Weibo sangat besar sebelum dan selepas titik panas berlaku. Pengguna boleh menggunakan kandungan panas dalam pengesyoran, yang merupakan keperluan syarikat untuk produk yang disyorkan.
② Bina perhubungan: Saya berharap dapat mengumpul beberapa perhubungan sosial dalam Weibo yang disyorkan.
2. Pemilihan Teknologi
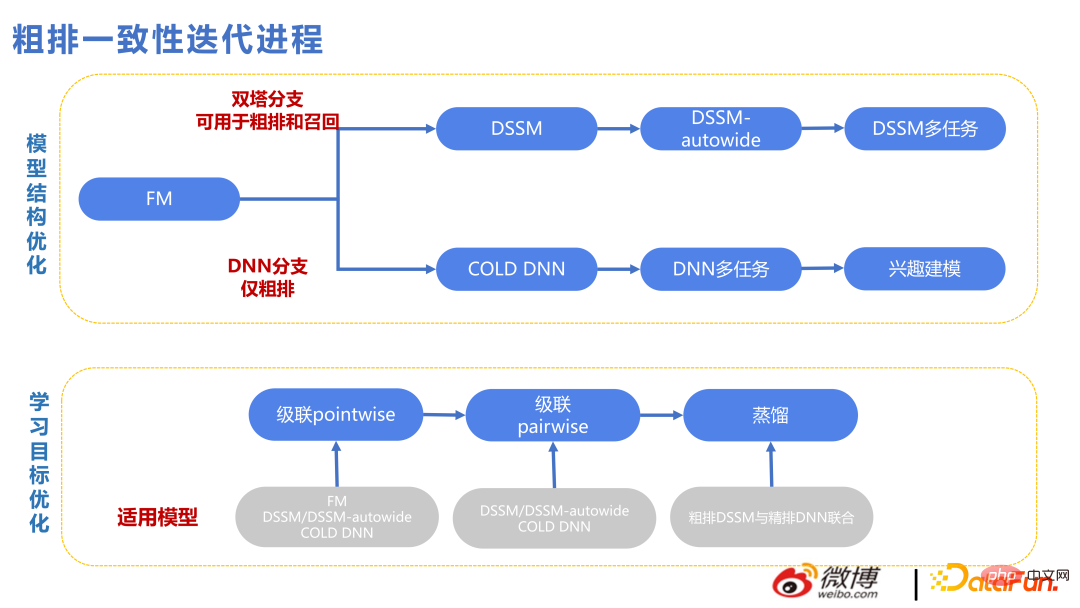
Angka berikut menunjukkan kemajuan teknologi kami dalam beberapa tahun kebelakangan ini.
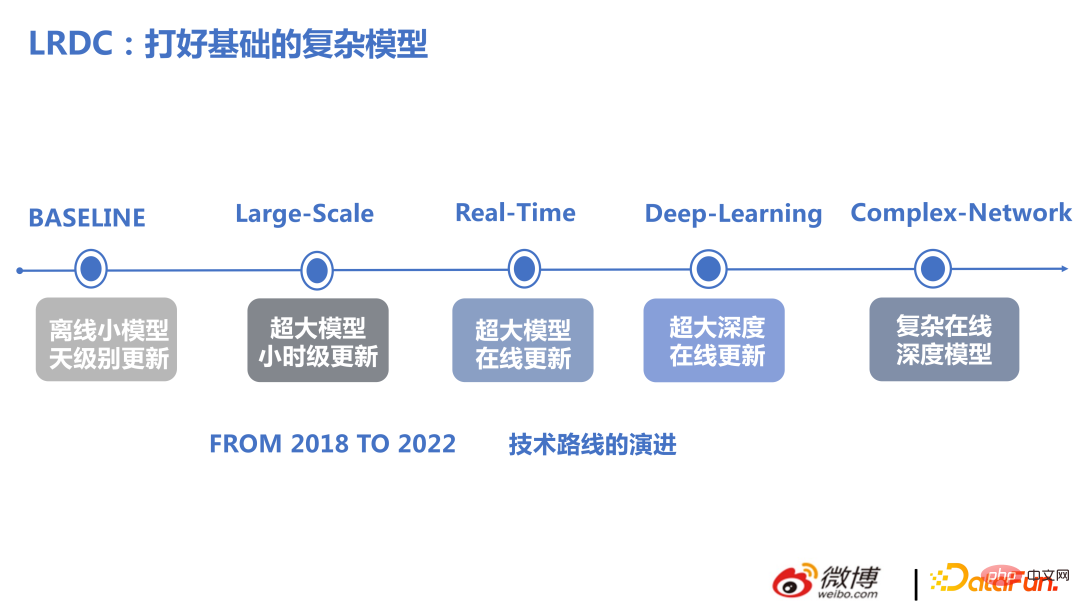
Evolusi teknologi pasukan kami dari 2018 hingga 2022 terutamanya dalam dua aspek: berskala besar dan masa nyata. Atas dasar ini, buat struktur kompleks untuk mencapai hasil dua kali ganda dengan separuh usaha.
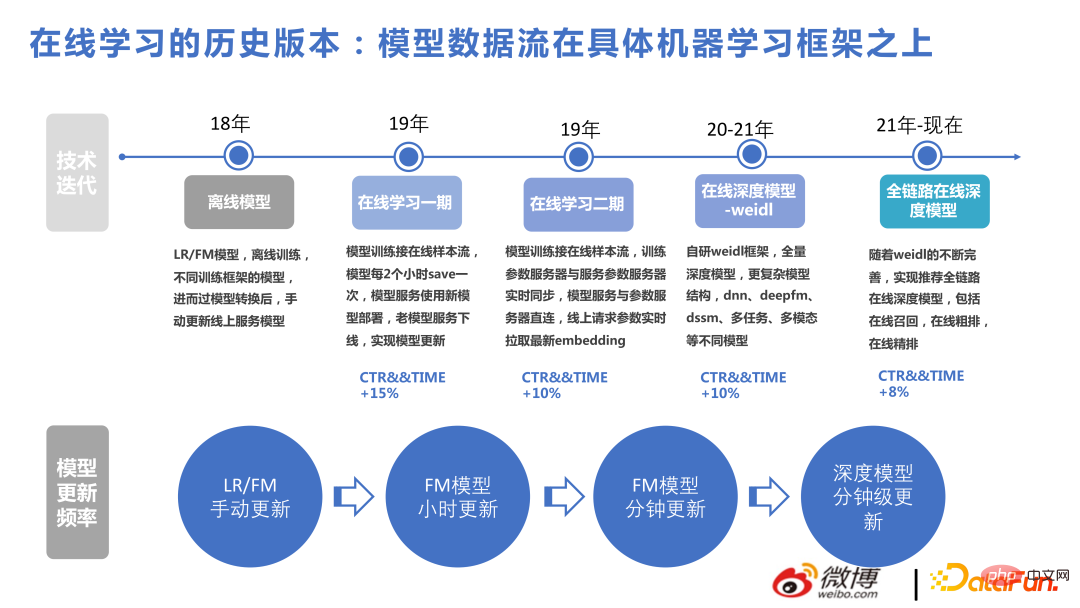
Berikut ialah pengenalan ringkas kepada platform pembelajaran dalam talian Weidl kami.
Proses utama ialah: Sampel penyambungan tingkah laku pengguna digunakan untuk pembelajaran mengikut model, dan kemudian pengesyoran diberikan kepada pengguna untuk mendapatkan maklum balas secara keseluruhan reka bentuk menggunakan prinsip keutamaan aliran data untuk mencapai fleksibiliti yang lebih baik. Tidak kira kaedah yang digunakan untuk melatih KERNEL, bahagian kemas kini masa nyata antara storan model luar talian dan PS dalam talian masih wujud. Sama ada model latihan LR atau FM tulisan tangan, Tensorflow, atau DeepRec, adalah mungkin Storan model yang sepadan ialah satu set aliran data yang dibina oleh kami sendiri, dan format model juga dibuat oleh kami sendiri, dengan itu memastikan berbilang itu. Bahagian belakang boleh dimuat turun daripada Latihan model boleh dikemas kini dalam talian dalam masa kurang daripada satu minit dan parameter baharu boleh digunakan pada kali seterusnya pengguna memanggilnya. Di bawah prinsip reka bentuk ini, Backend boleh ditukar dengan mudah.
Weidl ialah platform pembelajaran mesin yang dibangunkan sendiri oleh Weibo yang boleh memanggil pengendali pelbagai rangka kerja pembelajaran mendalam Anda juga boleh menggunakan mod Bridge dan bukannya menggantikan ia dengan sendiri Ia juga sangat mudah untuk mengira pengendali. Sebagai contoh, apabila kami menggunakan Tensorflow sebelum ini, kami akan melakukan beberapa peruntukan memori dan pengoptimuman operator pada tf Kami akan bertukar kepada DeepRec pada separuh kedua 2022. Selepas mengetahui lebih lanjut tentang DeepRec, kami akan mendapati bahawa beberapa titik pengoptimuman prestasi sebelumnya. berdasarkan tf adalah serupa dengan DeepRec.
Angka berikut menyenaraikan beberapa versi yang telah dibuat oleh pasukan kami selama bertahun-tahun untuk membantu anda memahami sumbangan setiap perkara teknikal dalam perniagaan kami berdasarkan model FM menyelesaikan masalah pengesyoran masa nyata berskala besar, dan kemudian mencipta struktur kompleks berdasarkan kedalaman. Berdasarkan keputusannya, penggunaan model tidak mendalam sebelum ini untuk menyelesaikan masalah masa nyata dalam talian juga telah membawa manfaat yang besar.
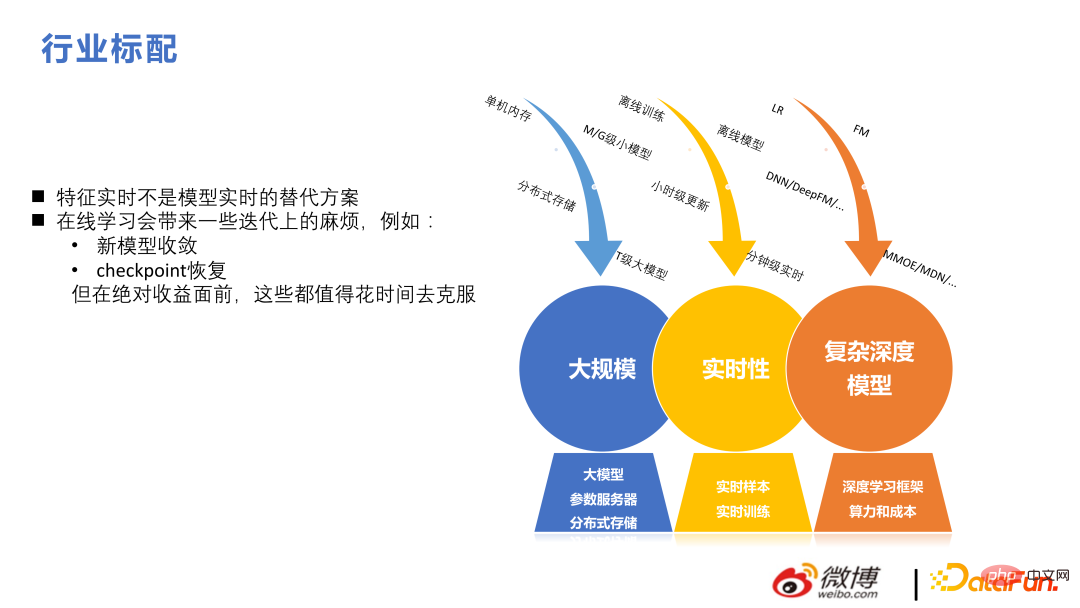
Pengesyoran aliran maklumat berbeza daripada pengesyoran aliran maklumat pada dasarnya berskala besar Seni bina dalam masa nyata. Terdapat juga beberapa kesukaran dan perbezaan dalam bidang ini Sebagai contoh, ciri masa nyata bukanlah alternatif kepada model masa nyata Untuk sistem pengesyoran, apa yang dipelajari oleh model adalah lebih penting Tetapi sebelum keuntungan mutlak boleh dibuat, ia boleh diatasi dengan masa.
2. Lelaran teknologi terkini bagi model besar
Bab ini akan memperkenalkan model lelaran perniagaan dari aspek matlamat, struktur dan ciri.
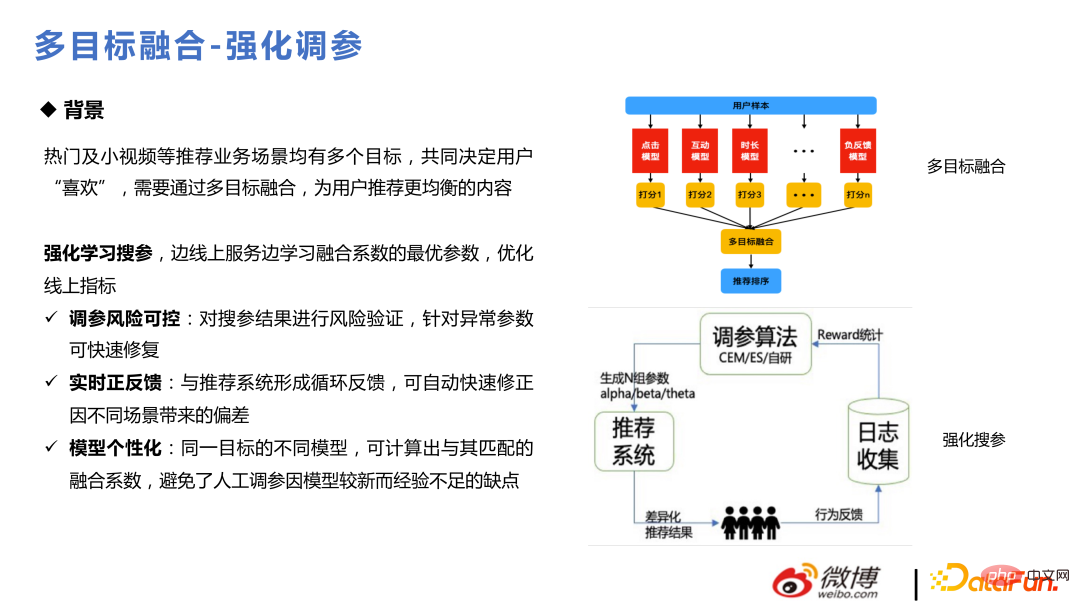
1. Gabungan pelbagai objektif
Terdapat banyak operasi pengguna dalam adegan Weibo, dan pengguna akan menyatakan kecintaan mereka terhadap item tersebut. Terdapat banyak jenis gelagat, seperti interaksi klik, tempoh, lungsur turun, dsb. Setiap matlamat mesti dimodelkan dan dianggarkan, dan akhirnya penyepaduan dan kedudukan keseluruhan adalah sangat penting untuk perniagaan pengesyoran. Apabila ia mula-mula dilakukan, ia dilakukan melalui static fusion dan offline parameter search Kemudiannya, ia ditukar kepada dynamic parameter search melalui kaedah pembelajaran pengukuhan skor gabungan melalui tunggu model.

Pendekatan teras untuk mengukuhkan pelarasan parameter ialah , bahagikan trafik dalam talian kepada beberapa kumpulan trafik kecil, gunakan beberapa parameter dalam talian semasa untuk menjana beberapa parameter baharu, lihat reaksi pengguna terhadap parameter ini, kumpulkan maklum balas dan ulangi. Bahagian teras ialah pengiraan ganjaran, yang menggunakan CEM dan ES. Kemudian, algoritma yang dibangunkan sendiri telah digunakan untuk menyesuaikan diri dengan keperluan perniagaannya sendiri. Oleh kerana pembelajaran dalam talian berubah dengan sangat cepat, masalah besar akan timbul jika parameter tidak boleh berubah dengan sewajarnya parameter gabungan mesti mencerminkan perubahan dalam keutamaan pengguna untuk sesuatu.
Berikut ialah beberapa helah kecil dalam pengoptimuman model Pengguna menggunakannya secara kitaran setiap hari perlu untuk mematuhi pengedaran terdahulu, menjalankan analisis terdahulu terlebih dahulu, dan kemudian melakukan gabungan pembezaan mekanisme pengesanan anomali untuk memastikan bahawa parameter gabungan boleh dikemas kini secara konsisten dan berulang.
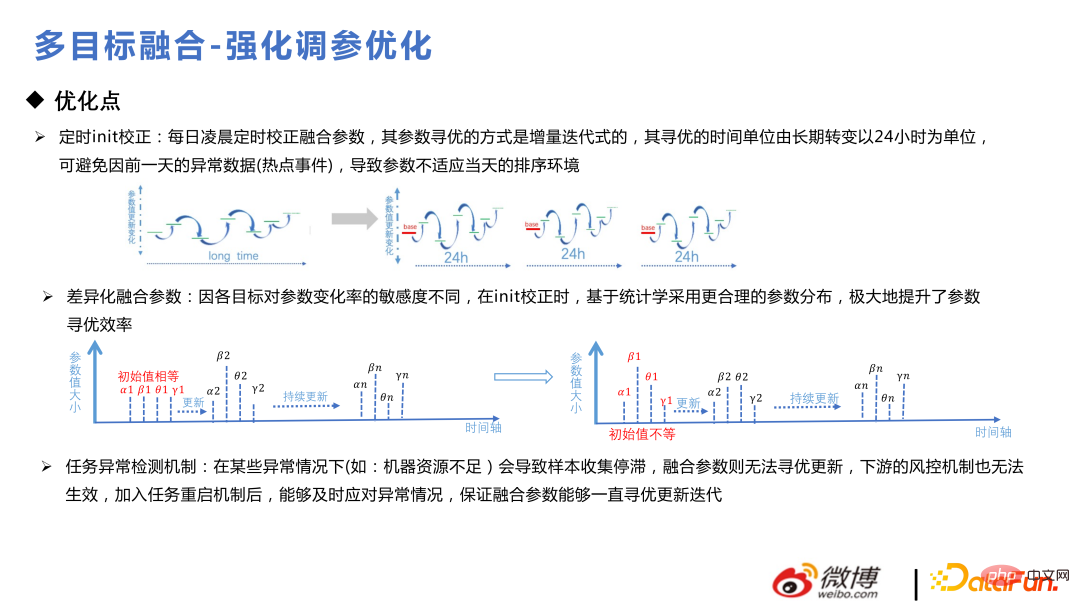
Aditive fusion dipilih sebagai formula gabungan pada mulanya tidak begitu banyak matlamat perniagaan Apabila bilangan matlamat bertambah, didapati bahawa gabungan aditif menyusahkan untuk menyokong penambahan lebih banyak matlamat dan akan melemahkan kepentingan setiap sub-matlamat Formula gabungan berganda digunakan kemudian. Kesannya ditunjukkan dalam ppt:

Selepas versi penuh dinaik taraf kepada berbilang tugasan, di sini Versi ini dioptimumkan untuk melaksanakan gabungan sasaran melalui model. Melalui gabungan model, banyak perkara bukan linear boleh ditangkap dengan lebih baik dan mempunyai kuasa ekspresif yang lebih baik Dengan cara ini, gabungan diperibadikan juga boleh dicapai, dan perkara yang digabungkan akan berbeza untuk setiap pengguna.
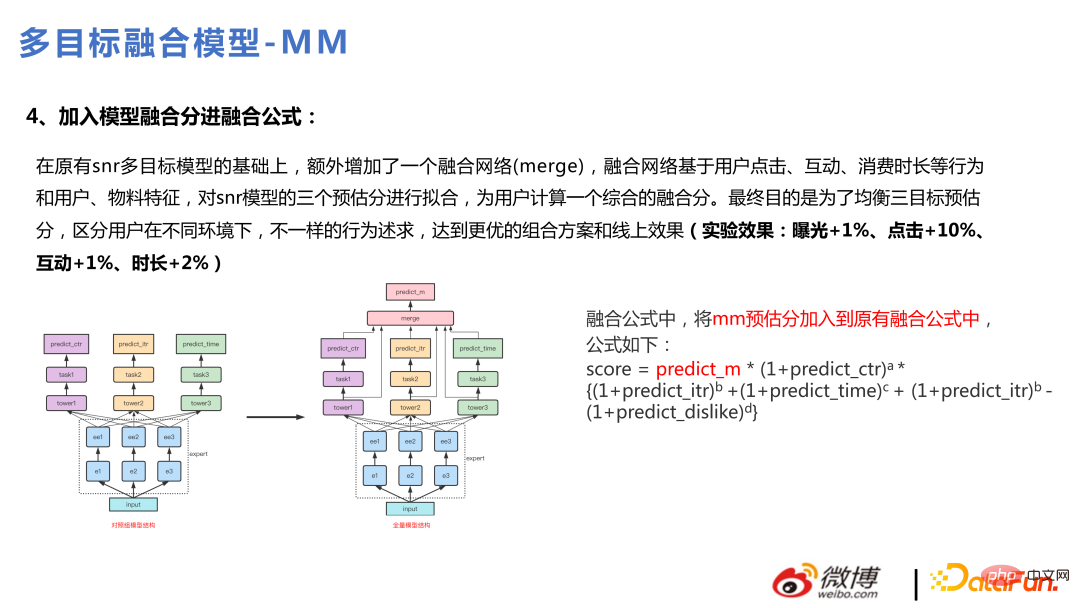
2. menjadi popular pada tahun 2020, sistem pengesyoran selalunya perlu memfokuskan pada berbilang matlamat pada masa yang sama Contohnya, terdapat tujuh matlamat dalam senario perniagaan kami: klik, tempoh, interaksi, penyiapan, maklum balas negatif, memasuki halaman utama, muat semula tarik ke bawah. , dsb. Melatih model untuk setiap sasaran menggunakan lebih banyak sumber dan menyusahkan. Lebih-lebih lagi, beberapa sasaran jarang dan ada yang agak padat Jika model dibina secara berasingan, sasaran yang jarang itu secara amnya tidak mudah dipelajari dengan baik dapat menyelesaikan masalah pembelajaran sasaran yang jarang.

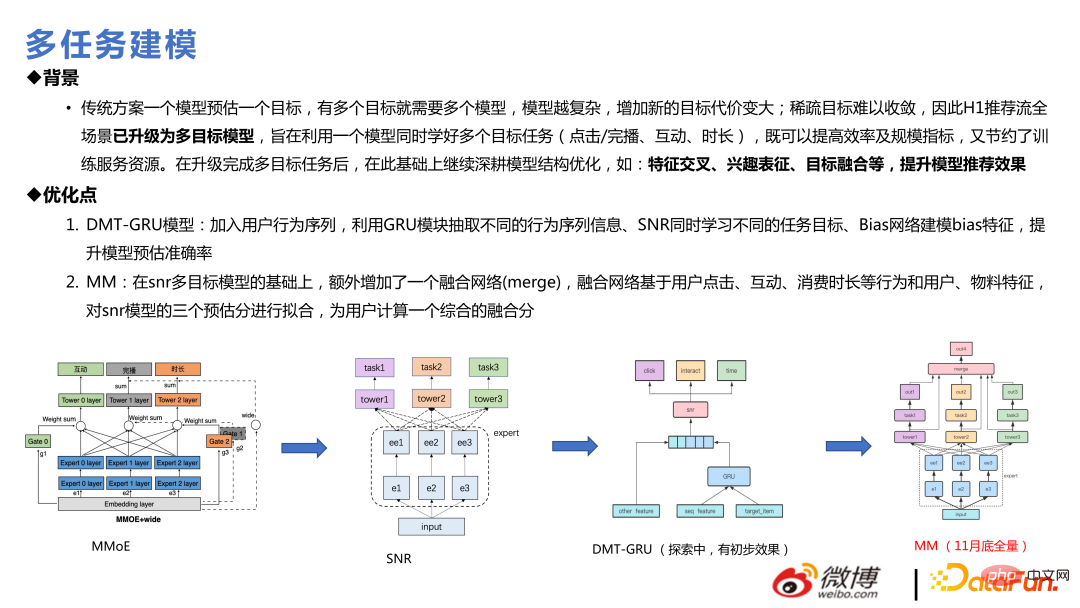
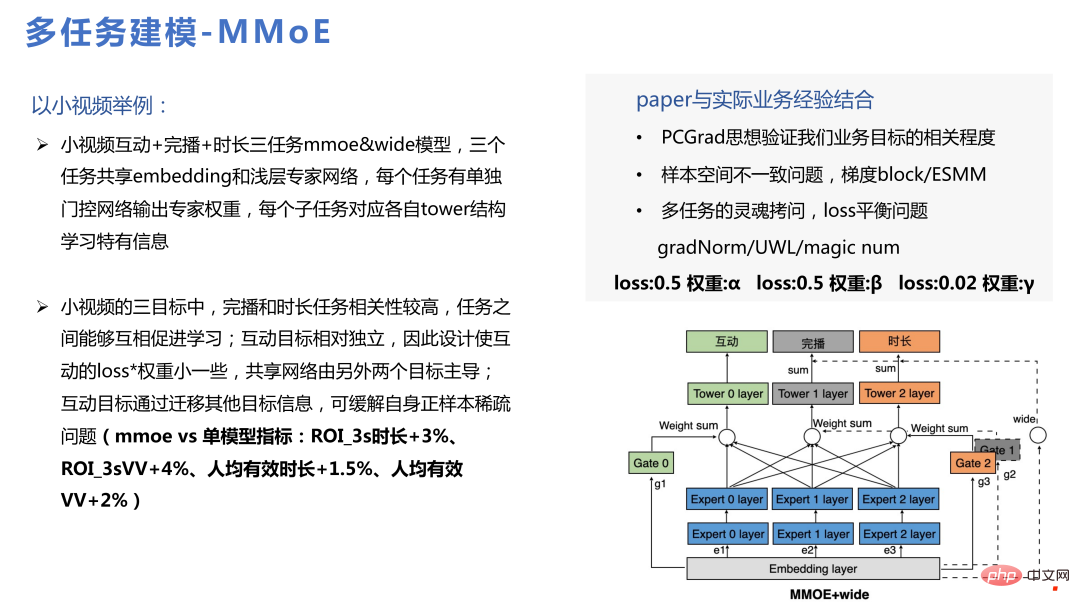
3. Teknologi berbilang senario
Kami bertanggungjawab terhadap banyak senario pengesyoran, jadi adalah wajar untuk memikirkan menggunakan beberapa teknologi berbilang senario. Multi-tasking bermakna bahawa beberapa sasaran agak jarang Berbilang adegan adalah besar dan kecil Konvergensi adegan kecil tidak begitu baik kerana jumlah data tidak mencukupi, manakala penumpuan adegan besar adalah lebih baik jika kedua-dua adegan itu lebih kurang sama, akan ada jurang di tengah-tengahnya. Sebahagian daripadanya melibatkan pemindahan ilmu yang akan menguntungkan perniagaan Ini juga menjadi trend hangat baru-baru ini dan mempunyai banyak persamaan teknikal dengan multitasking.
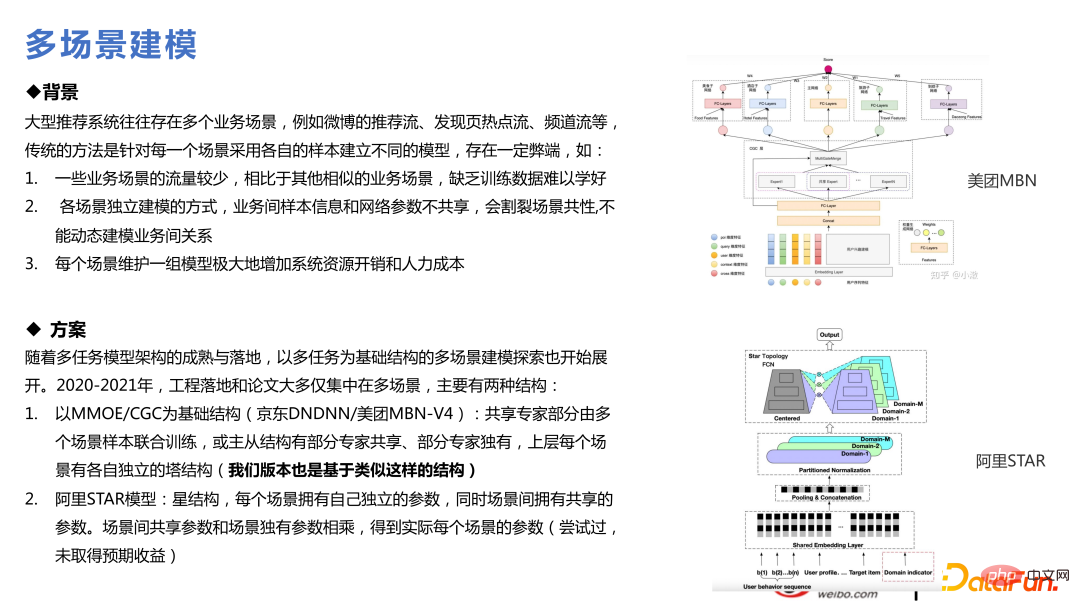
Berdasarkan setiap model berbilang tugas, model berbilang senario boleh dibuat, berbanding kepadaDalam struktur berbilang tugas, apa yang ditambah ialah lapisan Slot-gate dalam rajah di bawah Pembenaman yang sama menyatakan fungsi yang berbeza untuk senario yang berbeza melalui Slot-gate. Output melalui Slot-gate boleh dibahagikan kepada tiga bahagian: menyambung ke rangkaian pakar, menyambung ke tugas sasaran, atau menyambung ke ciri.
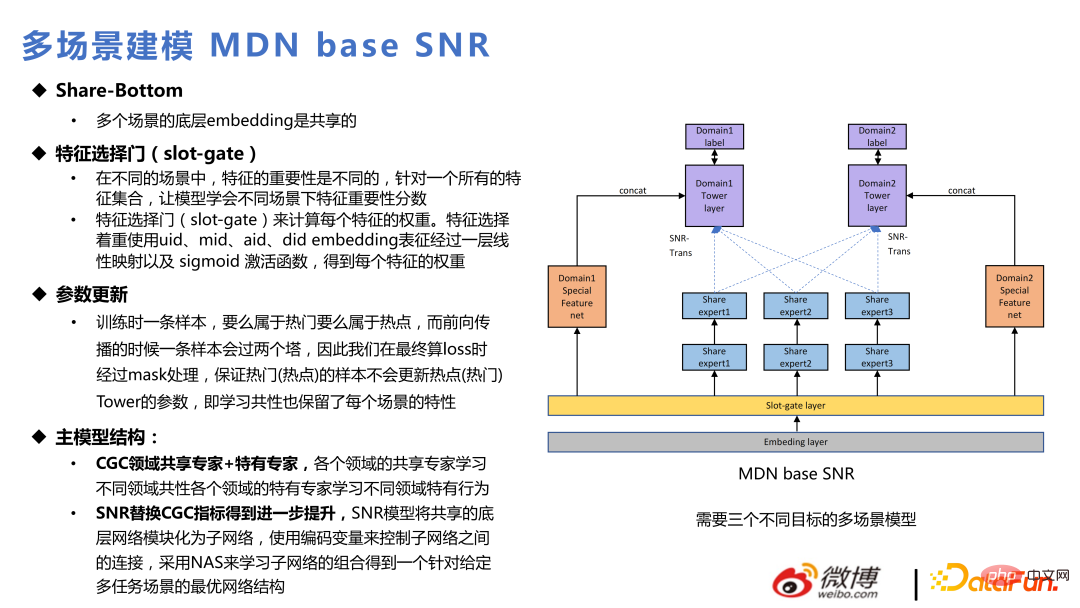
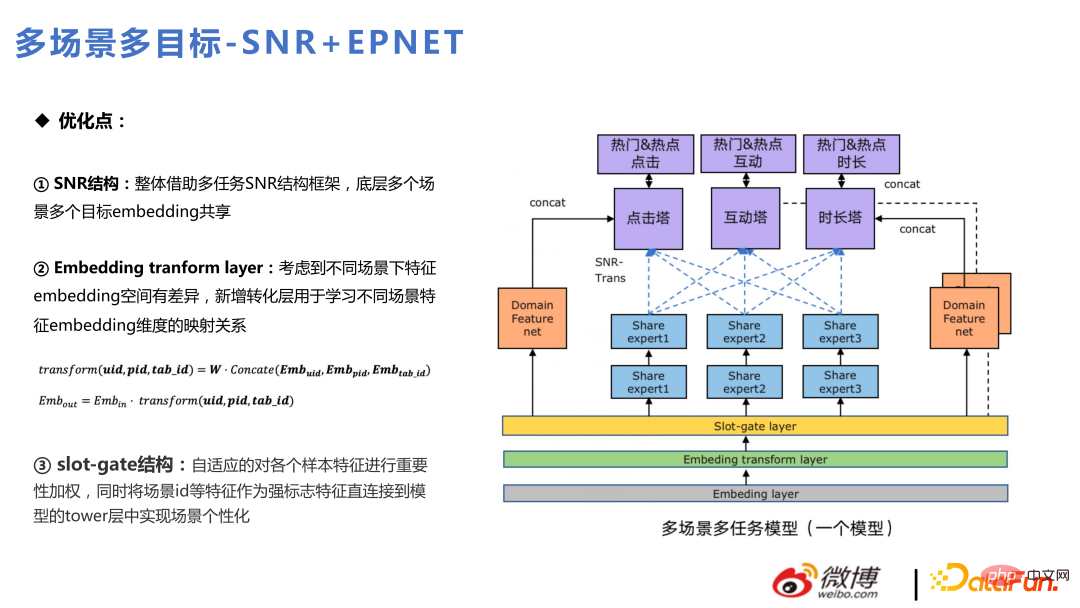
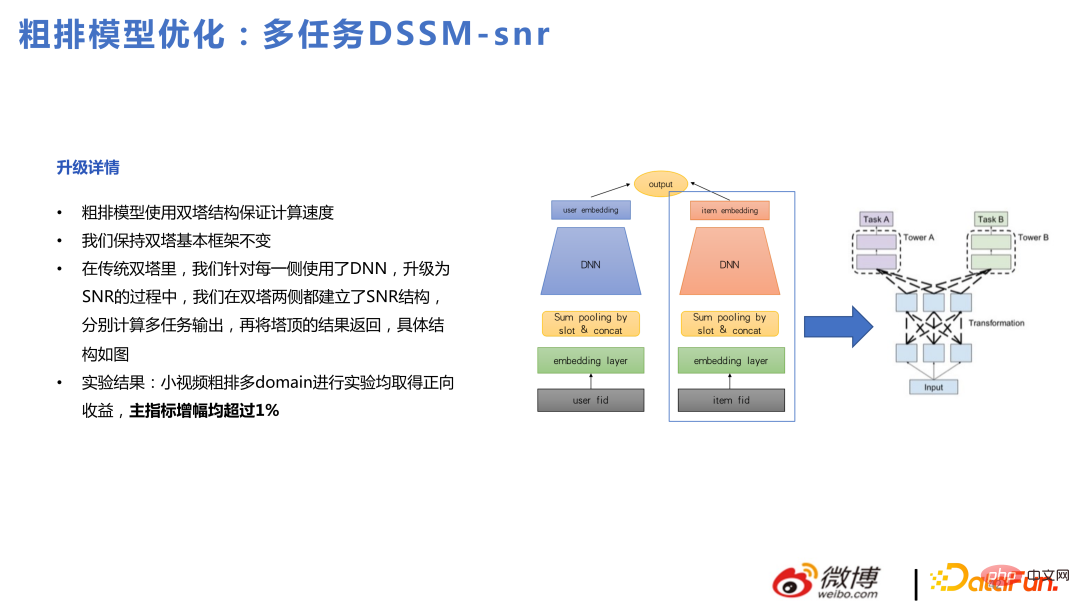
Model utama terutamanya menggunakan SNR untuk menggantikan CGC, yang konsisten dengan lelaran berbilang tugas. Berikut ialah aplikasi semasa berbilang tugas dan berbilang senario yang digabungkan bersama dalam dua senario perniagaan dalaman: hangat dan popular. Antaranya, pengesyoran halaman utama ialah strim popular dan pengesyoran halaman penemuan ialah strim hangat.
Struktur keseluruhan adalah serupa dengan SNR, dengan tiga menara sasaran klik, interaksi dan tempoh. Antaranya, ketiga-tiga menara sasaran ini dibahagikan kepada enam sasaran untuk dua adegan popular dan popular. Di samping itu, lapisan Transformasi Benam ditambahkan Berbeza daripada Gerbang-Slot, Gerbang-Slot adalah untuk mencari kepentingan ciri, manakala lapisan transformasi Benamkan adalah untuk mempertimbangkan perbezaan dalam membenamkan ruang dalam senario yang berbeza untuk melaksanakan pemetaan benam. Sesetengah ciri mempunyai dimensi berbeza dalam dua adegan dan diubah melalui lapisan transformasi Benam.
4. Perwakilan minat
Faedah. Pencirian ialah teknologi yang telah banyak disebut dalam beberapa tahun kebelakangan ini Daripada DIN Alibaba kepada SIM dan DMT, ia telah menjadi arus perdana pemodelan jujukan tingkah laku pengguna dalam industri.
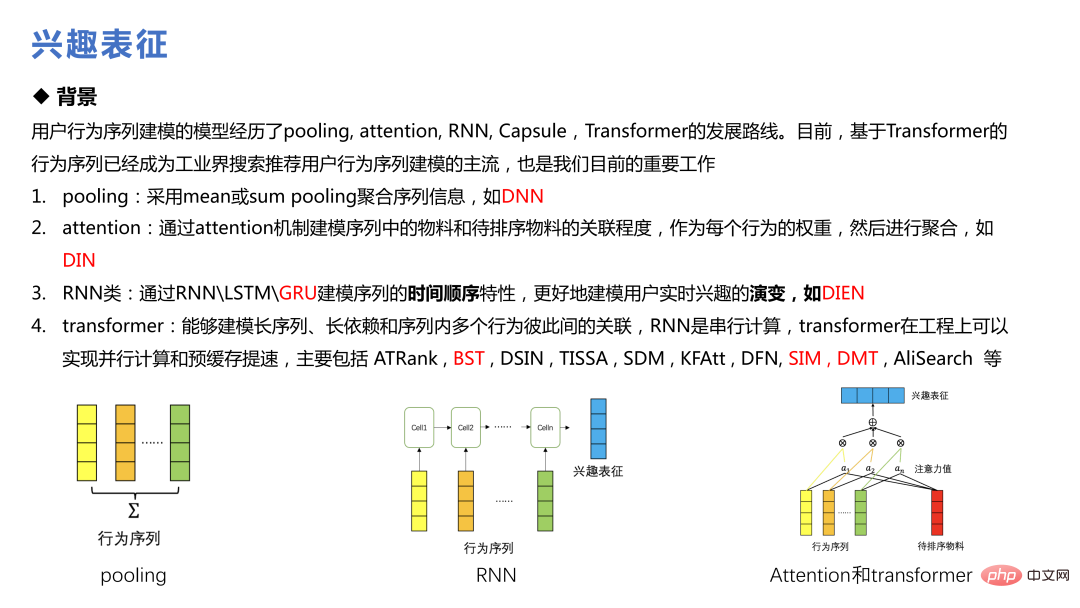
DIN digunakan pada mulanya untuk membina berbilang jujukan tingkah laku untuk tingkah laku yang berbeza. Mekanisme perhatian diperkenalkan untuk memberikan pemberat yang berbeza kepada bahan yang berbeza dalam tingkah laku, dan unit pengaktifan tempatan digunakan untuk mempelajari pengagihan berat jujukan pengguna dan bahan yang diisih calon semasa, merealisasikan penyelesaian kedudukan halus yang popular dan mencapai perniagaan tertentu faedah.
Inti DMT ialah menggunakan Transformer pada berbilang tugas Pasukan kami menggunakan model DMT yang dipermudah, mengalih keluar modul bias, menggantikan MMoE dengan SNR dan pergi ke dalam talian Akhirnya, keputusan perniagaan tertentu telah dicapai.
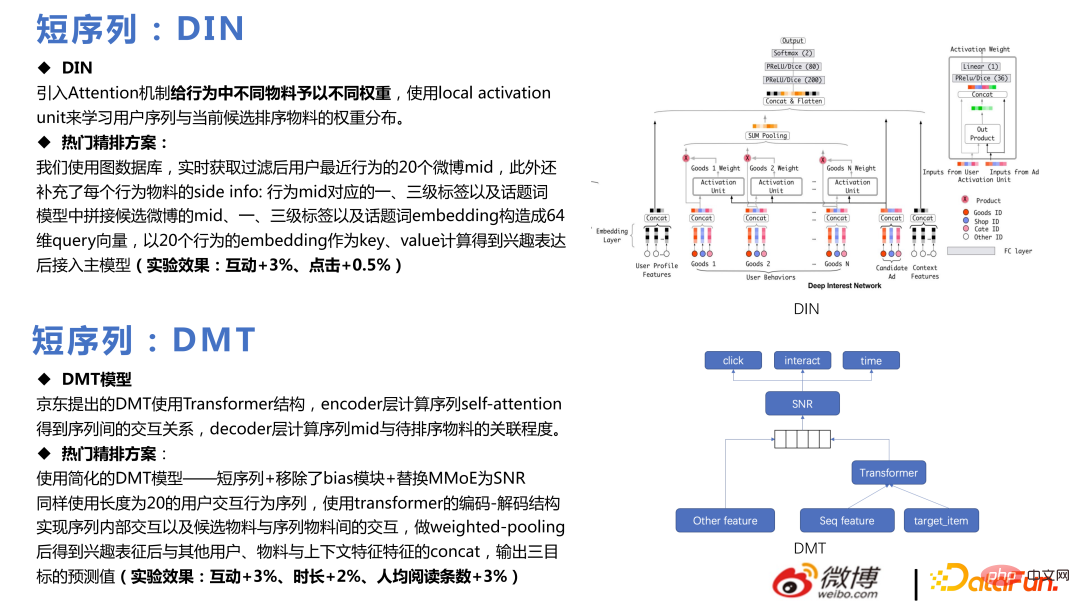
Berbilang DIN mengembangkan berbilang jujukan dan menggunakan pertengahan, teg, authorid, dsb. bahan calon sebagai pertanyaan . Selepas secara berasingan memberi perhatian kepada setiap urutan untuk mendapatkan perwakilan minat, ciri-ciri lain disambungkan ke dalam model pemeringkatan berbilang tugas.
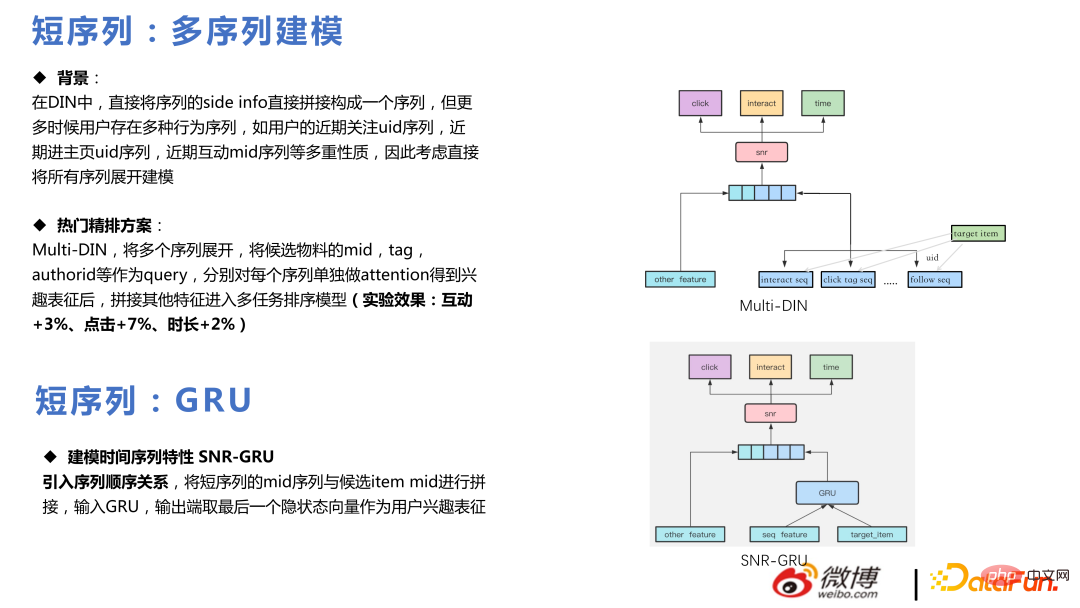
Pada masa yang sama, kami juga menjalankan eksperimen dan mendapati bahawa kami boleh membuat urutan lebih panjang, seperti klik , tempoh, dan urutan interaksi dsb., kesannya adalah lebih baik jika setiap jujukan dikembangkan daripada 20 kepada 50, yang konsisten dengan kesimpulan dalam kertas, tetapi jujukan yang lebih panjang memerlukan lebih banyak kos kuasa pengkomputeran.
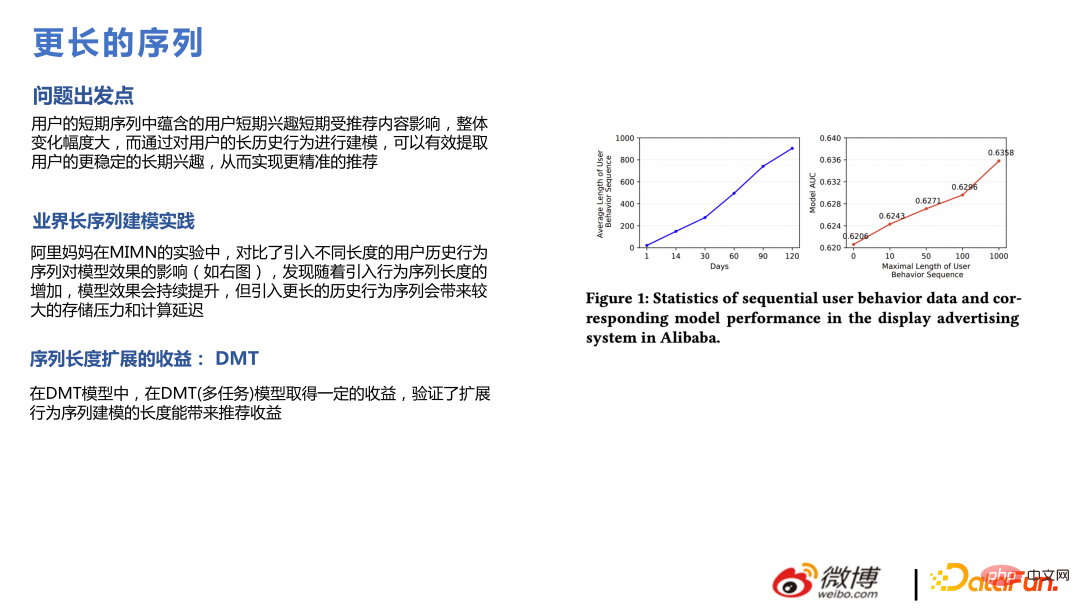
Pemodelan jujukan ultra panjang kitaran hayat pengguna adalah berbeza daripada pemodelan jujukan panjang sebelumnya Data tidak boleh ditarik dengan meminta ciri , tetapi untuk membina ciri jujukan tingkah laku panjang pengguna di luar talian atau untuk mencari ciri yang sepadan melalui beberapa kaedah carian dan kemudian menjana pembenaman atau memodelkan model utama dan model jujukan ultra-panjang secara berasingan, dan akhirnya membentuk pembenaman dan menghantarnya ke; tengah model utama.
Dalam perniagaan Weibo, nilai urutan yang sangat panjang tidaklah begitu hebat, kerana tumpuan semua orang berubah dengan cepat di Internet, seperti carian panas, Ia secara beransur-ansur hilang dalam masa satu atau dua hari, dan kandungan dari tujuh hari yang lalu dalam aliran maklumat diedarkan kurang. Oleh itu, jujukan tingkah laku pengguna yang terlalu panjang akan melemahkan anggaran nilai keutamaan pengguna untuk item tersebut ke tahap tertentu. Tetapi untuk pengguna frekuensi rendah atau kembali, kesimpulan ini berbeza pada tahap tertentu.
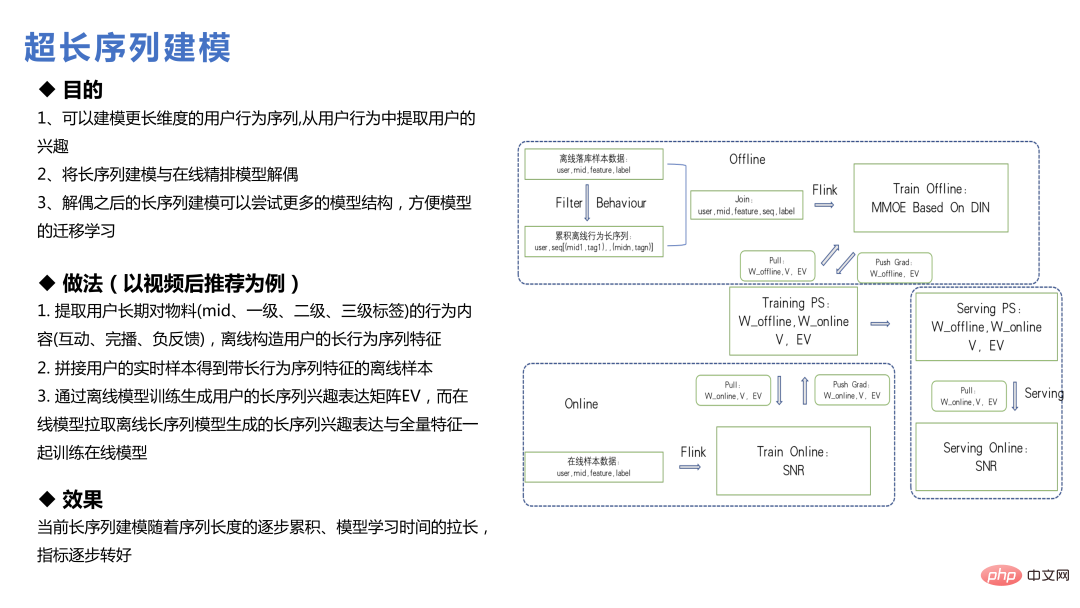
5 Ciri-ciri
Gunakan bersaiz besar. Model berskala besar juga akan menghadapi beberapa masalah pada tahap ciri. Sebagai contoh, beberapa ciri secara teorinya dianggap membantu model, tetapi kesan selepas menambahkannya tidak dapat memenuhi jangkaan Ini juga realiti yang dihadapi oleh perniagaan pengesyoran. Oleh kerana skala model adalah sangat besar, banyak maklumat kelas id telah ditambahkan pada model, yang telah memberikan ekspresi yang baik kepada beberapa pilihan pengguna Menambah beberapa ciri statistik pada masa ini mungkin tidak begitu mudah untuk digunakan. Mari kita bercakap tentang pasukan ini Ciri-ciri yang agak mudah untuk digunakan dalam amalan.
Pertama sekali, kesan ciri padanan adalah agak baik Pengguna boleh mencipta beberapa data statistik yang lebih terperinci untuk satu bahan, satu jenis kandungan dan a blogger tunggal boleh membawa beberapa faedah.
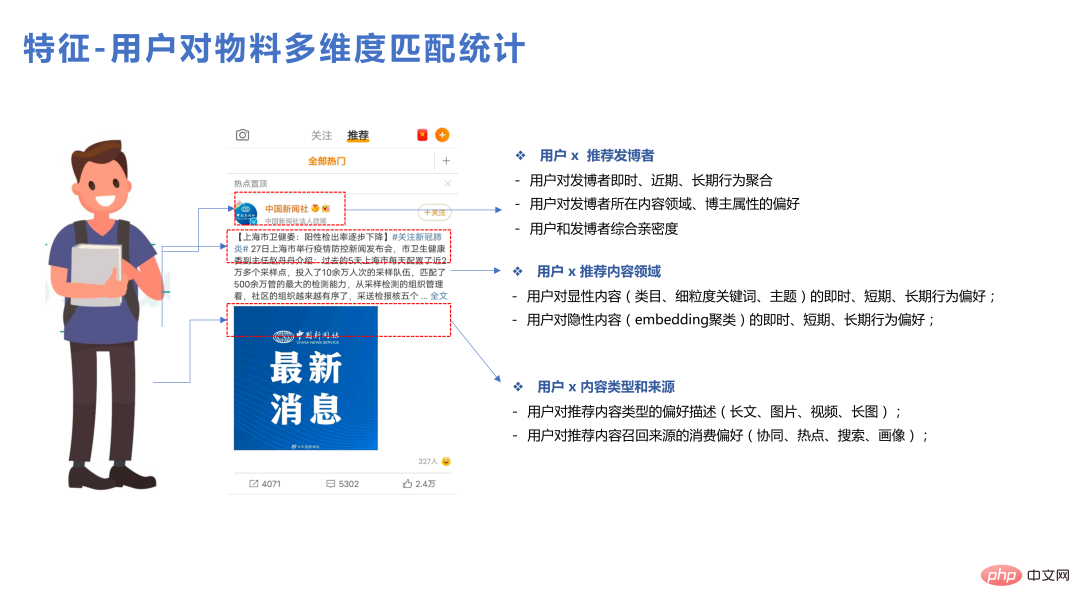
Selain itu, ciri berbilang modal juga lebih bernilai, kerana keseluruhan model pengesyoran adalah berdasarkan tingkah laku pengguna, dan terdapat beberapa rendah- kekerapan dan yang tidak popular. Tingkah laku pengguna item tidak mencukupi dalam keseluruhan sistem Pada masa ini, memperkenalkan lebih banyak pengetahuan terdahulu boleh membawa lebih banyak faedah. Multimodaliti memperkenalkan kumpulan semantik melalui pengenalan NLP dan teknologi lain, yang membantu kedua-dua frekuensi rendah dan permulaan sejuk.
Pasukan ini telah melakukan dua jenis kaedah untuk memperkenalkan ciri berbilang modal: jenis pertama ialah menyepadukan benam berbilang modal ke dalam model pengesyoran, membekukan kecerunan benam asas ini dan kemudian beralih ke bahagian atas Kemas kini MLP; kaedah lain ialah menggunakan berbilang modaliti untuk melaksanakan pengelompokan sebelum memasuki model pengesyoran, dan membuang ID kluster ke dalam model yang disyorkan untuk latihan Ini adalah cara yang lebih mudah untuk memperkenalkan maklumat kepada model pengesyoran maklumat semantik tertentu juga akan hilang.
Dua kaedah di atas telah banyak dicuba dalam perniagaan kami Kaedah pertama akan meningkatkan kerumitan model dan memerlukan banyak transformasi spatial, mencari kepentingan ciri, dll., tetapi ia boleh Membawa manfaat yang baik. ; kaedah kedua menggunakan ID kluster untuk belajar, kerumitan adalah di luar model, perkhidmatan dalam talian agak mudah, kesannya boleh mencapai kira-kira 90%, dan anda juga boleh melakukan beberapa statistik pada ID kluster Ciri-ciri seksual, digabungkan, berfungsi dengan baik.
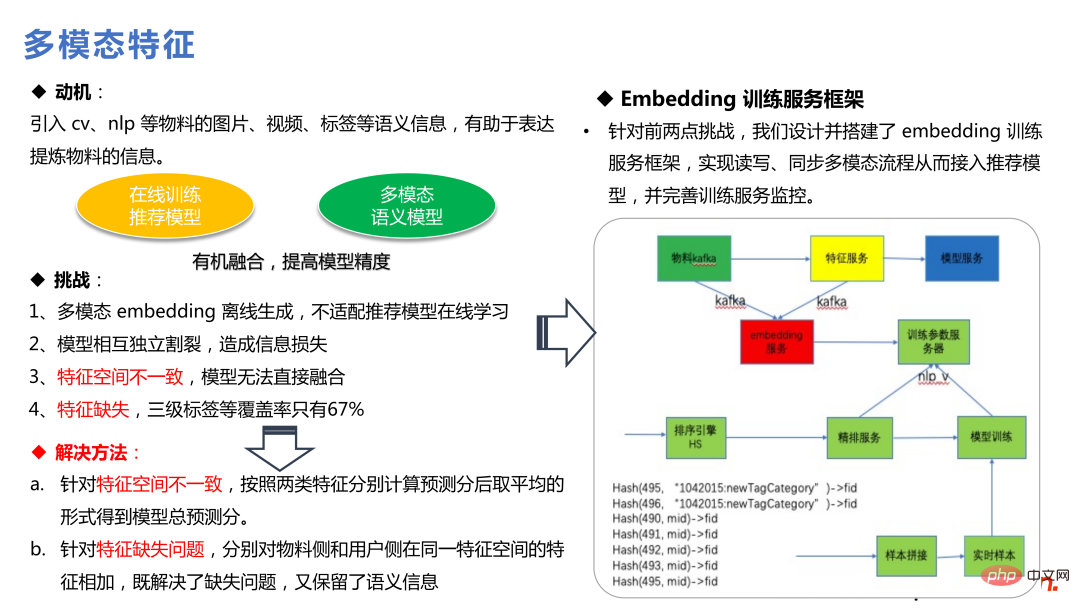
Selepas menambah ciri berbilang modal, faedah terbesar ialah bahan dedahan rendah berkualiti tinggi, yang boleh menyelesaikan sejuk mulakan soalan. Mengesyorkan bahan dengan pendedahan yang agak sedikit, yang model tidak dapat belajar sepenuhnya, akan sangat bergantung pada badan berbilang modal untuk membawa lebih banyak maklumat, yang juga bernilai positif kepada ekologi perniagaan.

Motivasi Co-action adalah untuk mencuba persimpangan deepfm, wide deep dan ciri lain Kaedah ini tidak membuahkan hasil dan ia disyaki disebabkan oleh konflik antara ciri silang dan pembenaman kongsi separa DNN. Tindakan bersama adalah bersamaan dengan menambah storan dan membuka ruang storan yang berasingan untuk bersilang Ini meningkatkan ruang ekspresi dan juga memperoleh keuntungan yang baik dalam perniagaan.

3. Kekonsistenan ungkapan pautan
Bahagian ini adalah mengenai pengisihan dan ingatan secara kasar. Untuk perniagaan pengesyoran, walaupun kuasa pengkomputeran tidak dapat menyokong pengisihan berjuta-juta set calon, dan ia dibahagikan kepada ingatan semula, pengisihan kasar dan pengisihan halus, logiknya adalah isu yang sama. Sebagai contoh, seperti yang ditunjukkan dalam rajah di bawah, pengisihan kasar akan dipotong, dan kandungan akhir untuk pengisihan halus hanya akan menjadi kira-kira 1,000 Jika ungkapan pengisihan kasar dan pengisihan halus berbeza dengan ketara, semasa proses penyisihan, pengisihan halus. skor mungkin akan lebih tinggi pada masa hadapan. Ciri dan struktur model pengisihan halus dan pengisihan kasar secara amnya serupa dengan rangka kerja penarikan balik, yang merupakan struktur anggaran perolehan vektor kemudian, dan ia adalah wajar untuk perbezaan ekspresi dengan pengisihan halus model untuk muncul. Jika konsistensi boleh dipertingkatkan, penunjuk perniagaan juga akan meningkat kerana kedua-dua pihak boleh menangkap trend perubahan yang sama.
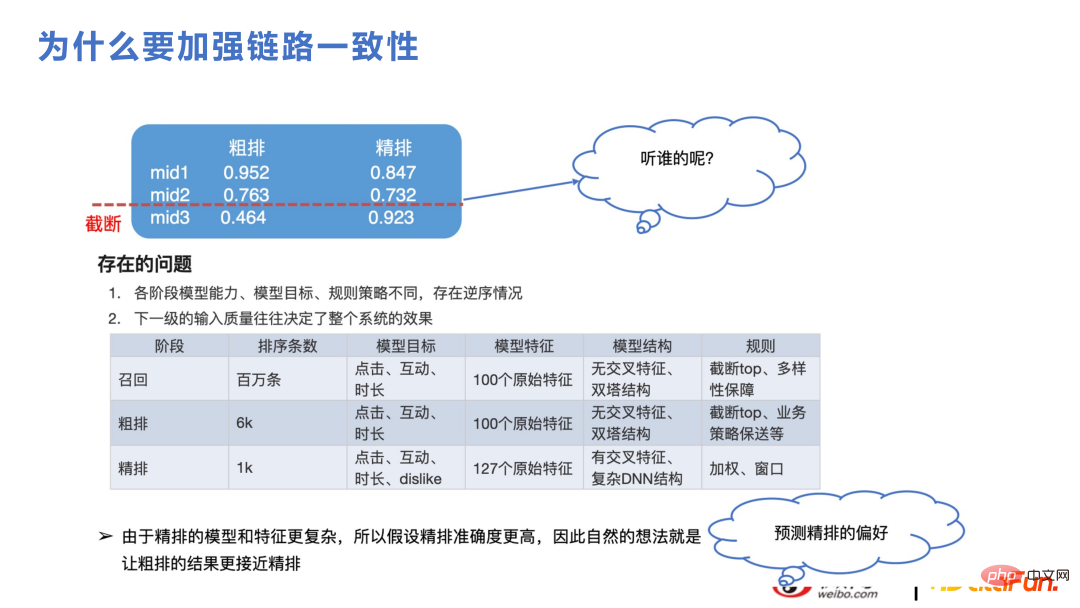
Rajah berikut menunjukkan konteks teknikal proses lelaran konsistensi kasar di atas ialah Barisan teknikal Menara Berkembar, di bawah ialah talian teknikal DNN. Memandangkan ciri-ciri Menara Berkembar berinteraksi agak lewat, banyak cara untuk ciri-ciri Menara Berkembar bersilang telah ditambah. Walau bagaimanapun, siling kaedah pengambilan vektor agak terlalu rendah, jadi bermula dari 2022, akan ada cawangan DNN untuk penyisihan kasar, yang akan memberi tekanan yang lebih besar pada seni bina kejuruteraan, seperti penapisan ciri, pemangkasan rangkaian, pengoptimuman prestasi , dsb., dan Bilangan item yang dijaringkan pada satu masa juga akan dikurangkan daripada sebelumnya, tetapi markahnya lebih baik, jadi bilangan item yang lebih kecil boleh diterima.
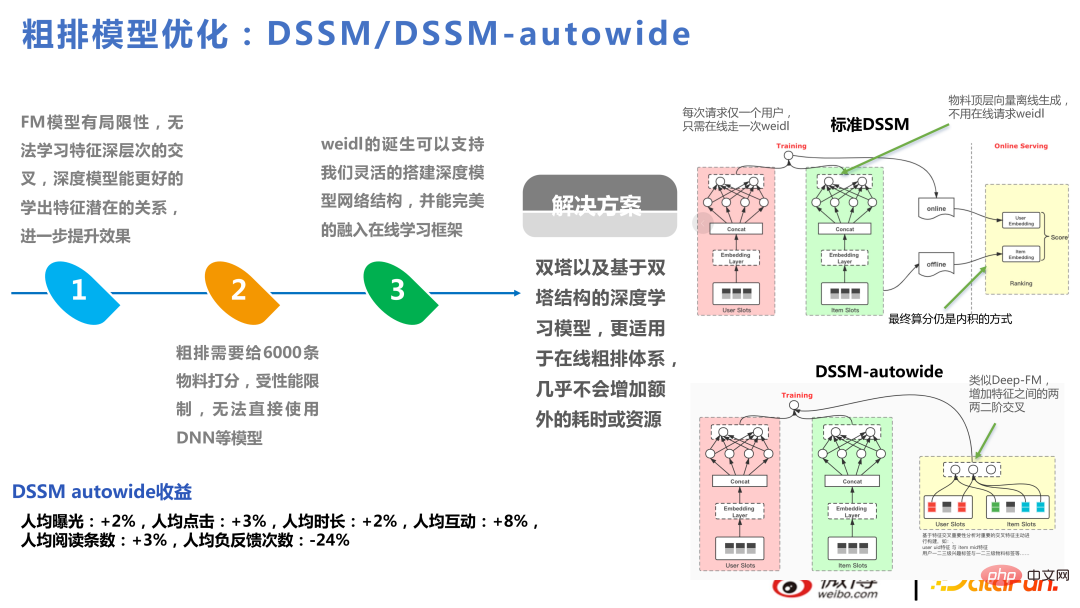
DSSM-autowide ialah crossover serupa dengan Deep-FM berdasarkan Menara Berkembar, dengan Terdapat peningkatan dalam penunjuk perniagaan, tetapi untuk projek seterusnya, menggunakan kaedah silang silang baharu, peningkatan itu tidak begitu ketara.
Oleh itu, kami merasakan manfaat yang boleh kami perolehi berdasarkan menara berkembar adalah agak terhad. Kami juga mencuba model berbilang tugas kasar berdasarkan menara berkembar, tetapi kami masih tidak dapat mengatasi masalah menara berkembar.
Berdasarkan masalah di atas, pasukan kami mengoptimumkan model kasar, menggunakan DNN dan tahap Model bersama ialah Stacking seni bina.
Model lata boleh ditapis terlebih dahulu dengan menara berkembar, dan kemudian ditapis dan dipotong kepada model DNN untuk pengisihan kasar, yang bersamaan dengan melakukan pengisihan kasar dan pengisihan halus di dalam pengisihan kasar . Selepas bertukar kepada model DNN, ia boleh menyokong struktur yang lebih kompleks dan lebih cepat menyesuaikan diri dengan perubahan dalam minat pengguna.
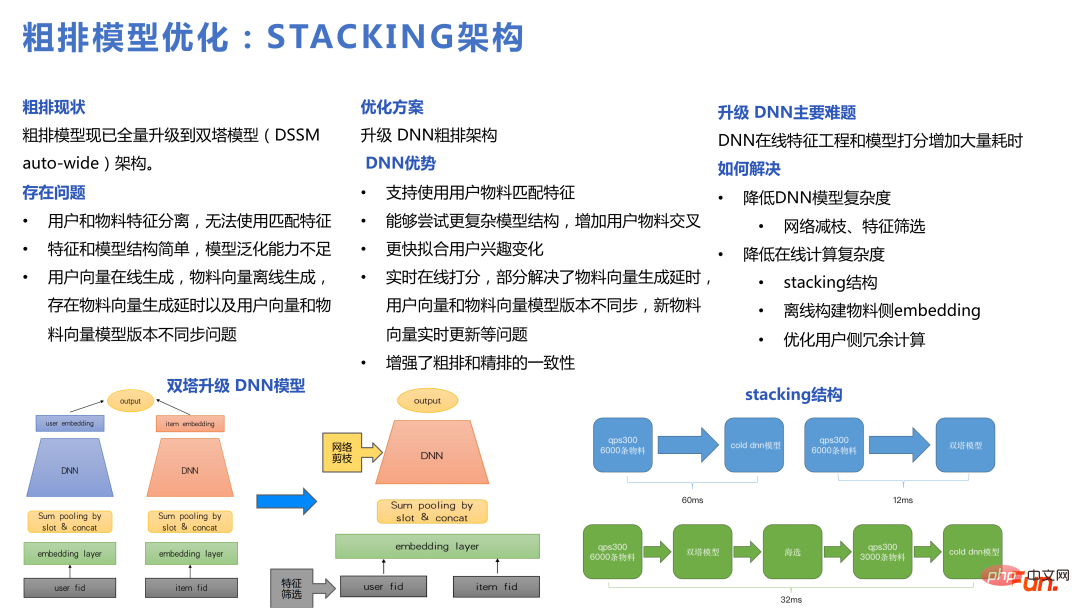
Lata memainkan peranan penting dalam rangka kerja Tanpa model lata, ia tidak mungkin menjadi Set calon yang kecil dipilih daripada set calon yang agak besar untuk digunakan oleh DNN kasar. Perkara yang lebih penting dalam lata ialah cara membina sampel Anda boleh lihat rajah di bawah. Daripada perpustakaan bahan peringkat juta, kami mengingati beribu-ribu pengisihan kasar dan pengisihan halus dalam 1,000 Akhirnya, kira-kira 20 item telah didedahkan, dan bilangan tindakan pengguna adalah dalam satu digit Proses keseluruhan adalah daripada yang lebih besar perpustakaan kepada pengguna proses corong tingkah laku. Apabila melakukan lata, titik teras ialah setiap bahagian mesti diambil sampel untuk membentuk beberapa pasangan yang sukar dan pasangan yang agak mudah untuk dipelajari daripada model lata.
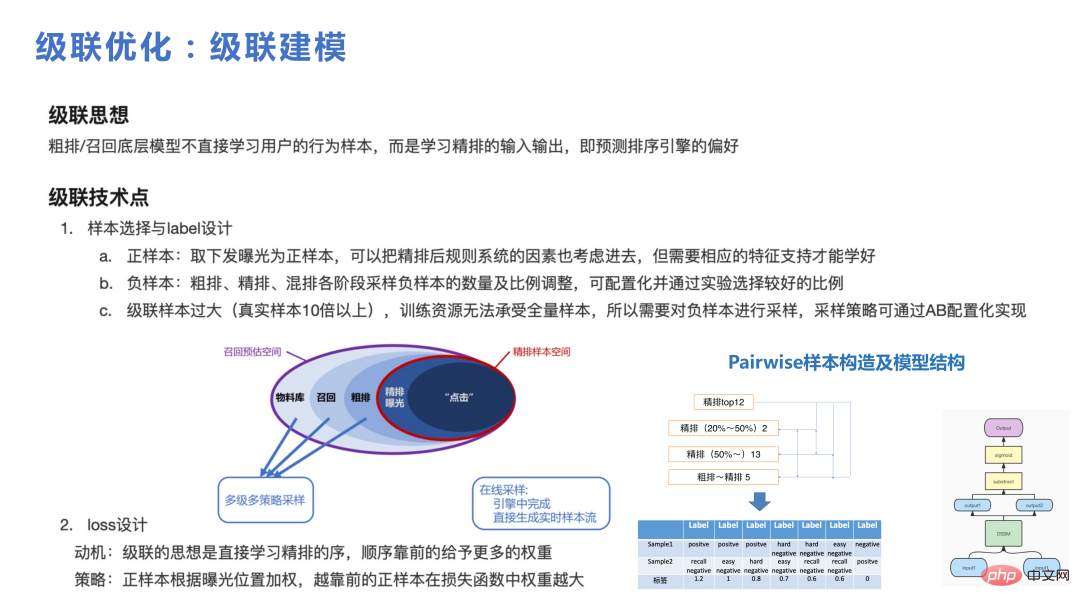
Rajah berikut menunjukkan faedah yang dibawa oleh pengoptimuman lata dan pensampelan negatif global, iaitu tidak disertakan di sini Berikan pengenalan terperinci. Berikut memperkenalkan inferens sebab yang popular baru-baru ini. Motivasi kami untuk menggunakan inferens kausal ialah jika kami menolak sesuatu yang semua orang suka, kesan klik pengguna akan menjadi baik, tetapi pengguna itu sendiri Terdapat juga beberapa minat yang agak khusus Kami mengesyorkan bahan khusus ini kepada pengguna, dan pengguna juga lebih menyukainya. Kedua-dua perkara ini adalah sama untuk pengguna, tetapi untuk platform, lebih banyak perkara khusus yang boleh diperkenalkan adalah lebih diperibadikan, dan jenis pertama lebih mudah diperolehi oleh model adalah untuk menyelesaikan masalah ini . Kaedah khusus ialah mengumpulkan pasangan sampel berpasangan Untuk bahan yang diklik oleh pengguna dan mempunyai populariti yang rendah, dan bahan yang sangat popular tetapi tidak diklik pengguna, gunakan kaedah Bayesian digunakan untuk melatih model kerugian. Dalam amalan kami, adalah lebih mudah untuk memperoleh faedah dengan melakukan inferens sebab dalam peringkat pengisihan dan ingatan kasar berbanding dalam pengisihan halus. Sebabnya ialah model penarafan halus agak rumit sudah mempunyai keupayaan pemperibadian yang baik Walau bagaimanapun, walaupun kedudukan kasar dan penarikan semula menggunakan DNN, ia juga merupakan DNN yang dipotong . Keupayaan pemperibadian agak lemah Kesan penggunaan inferens sebab di tempat pasti lebih jelas daripada menggunakannya di tempat yang mempunyai keupayaan pemperibadian yang kuat. 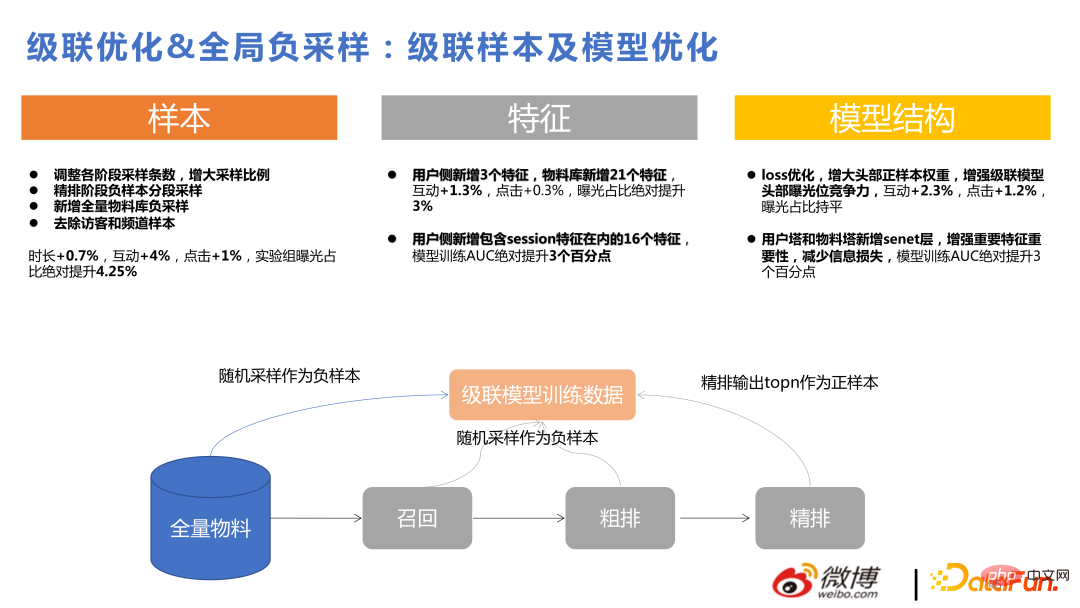
4 Perkara teknikal lain
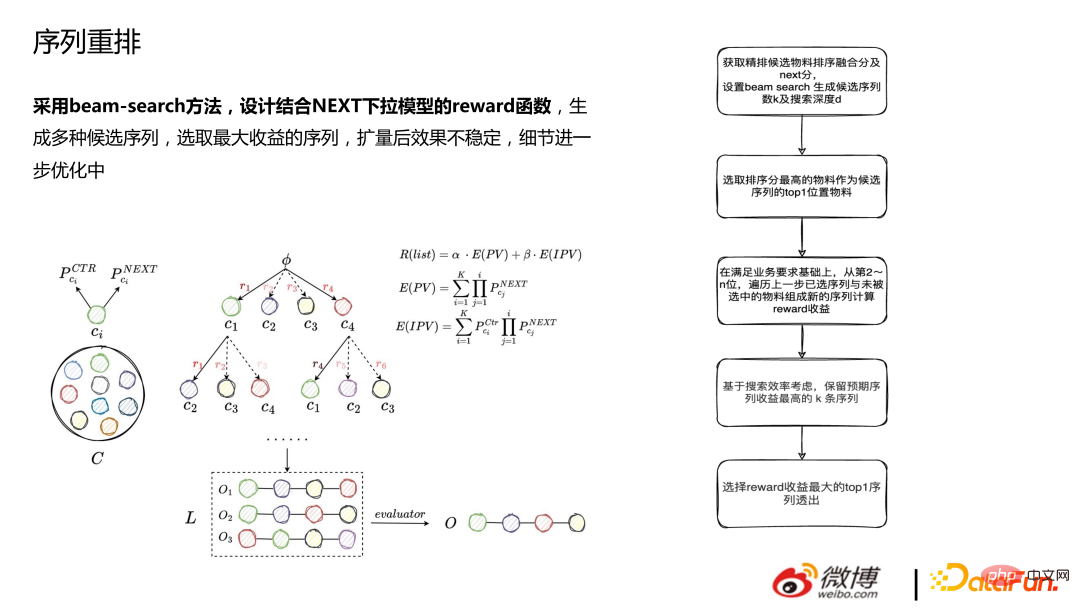
1 Penyusunan Semula
Penyusunan semula menggunakan kaedah carian pancaran untuk mereka bentuk fungsi ganjaran digabungkan dengan model lungsur turun SETERUSNYA untuk menjana pelbagai jujukan calon dan memilih jujukan yang paling hebat keuntungan. Selepas pengembangan Kesannya tidak stabil dan butiran sedang dioptimumkan lagi.
2 🎜>Teknologi graf terutamanya merangkumi dua bahagian: pangkalan data graf dan pembenaman graf. Untuk cadangan, lebih mudah dan lebih murah untuk menggunakan pangkalan data graf. Pembenaman graf merujuk kepada proses berjalan rawak nod kelas berjalan, memetakan data graf (biasanya matriks tumpat berdimensi tinggi) ke dalam vektor tumpat berdimensi rendah. Pembenaman graf perlu menangkap struktur topologi graf, hubungan antara bucu dan maklumat lain (seperti subgraf, tepi, dll.), yang tidak akan diperkenalkan di sini.
Algoritma berdasarkan jalan rawak, struktur graf, pembelajaran perbandingan graf dan algoritma lain boleh digunakan dalam cadangan untuk menjadikan pengguna dan catatan blog, Mengingat kembali interaksi/perhatian antara pengguna dan pengarang. Kaedah arus perdana adalah untuk membenamkan imej, teks, pengguna, dsb., dan menambahkan ciri pada model Terdapat juga beberapa percubaan yang lebih canggih, seperti membina rangkaian hujung ke hujung secara terus dan menggunakan GNN untuk cadangan. 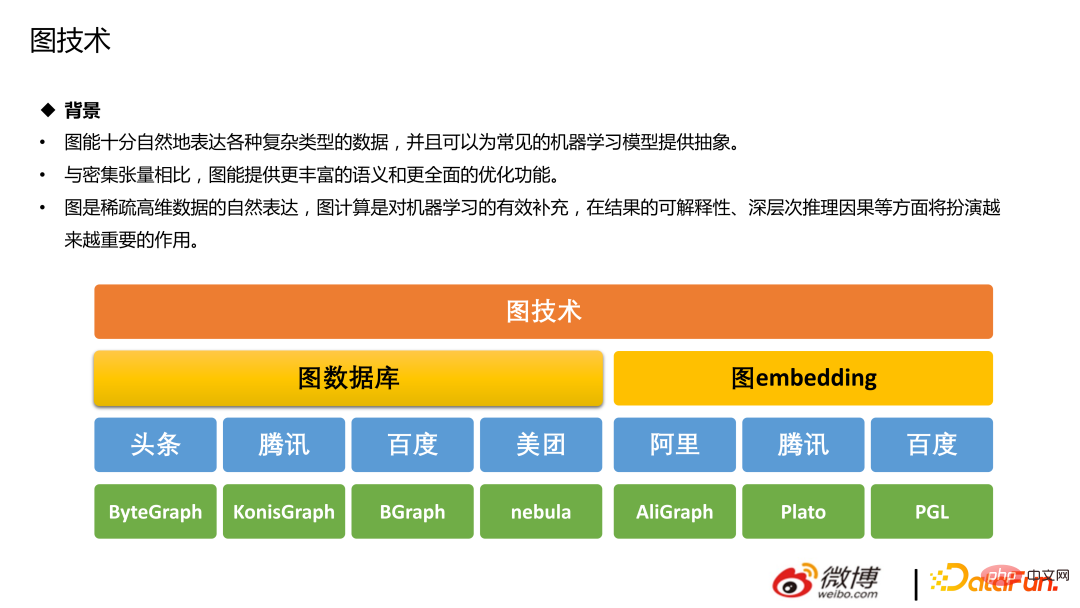
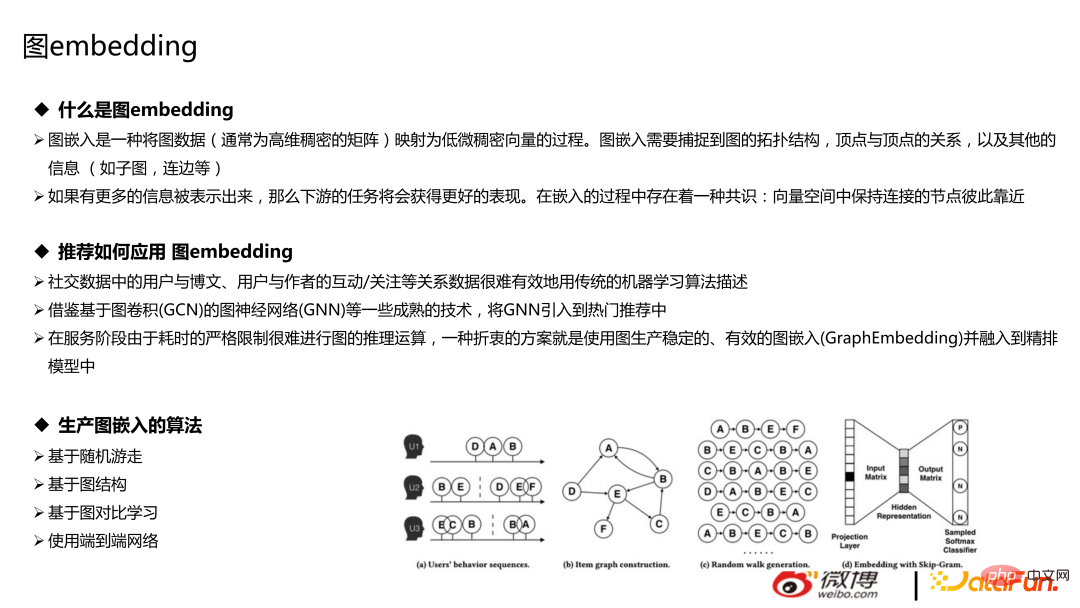 Gambar di bawah ialah model hujung ke hujung semasa ia. Tiada versi arus perdana dalam talian.
Gambar di bawah ialah model hujung ke hujung semasa ia. Tiada versi arus perdana dalam talian.
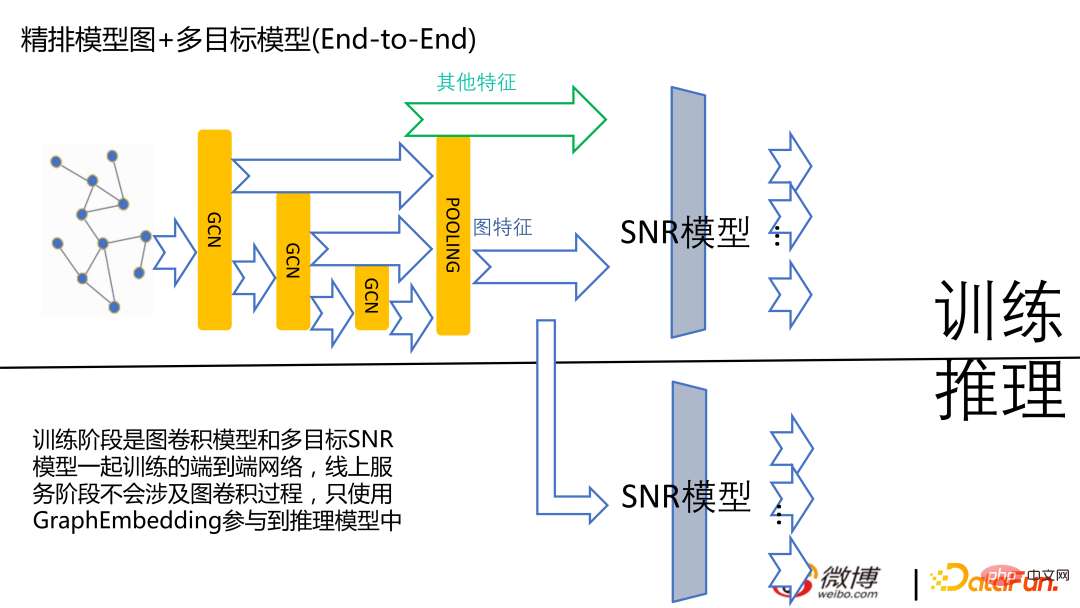 Gambar berikut adalah berdasarkan rangkaian graf untuk menjana pembenaman, dan gambar di yang betul adalah berdasarkan domain akaun Persamaan yang dikira. Untuk Weibo, adalah menguntungkan untuk mengira pembenaman berdasarkan hubungan perhatian.
Gambar berikut adalah berdasarkan rangkaian graf untuk menjana pembenaman, dan gambar di yang betul adalah berdasarkan domain akaun Persamaan yang dikira. Untuk Weibo, adalah menguntungkan untuk mengira pembenaman berdasarkan hubungan perhatian.
5. Sesi Soal Jawab
S1: Terdapat banyak item dalam aliran maklumat yang disyorkan, tetapi hanya menyemak imbas tanpa mengklik bukan? Melalui masa tinggal Item pada halaman senarai?
J1: Ya, apabila ia berkaitan dengan perniagaan aliran maklumat, tempoh ialah penunjuk pengoptimuman yang lebih penting. Tidak mudah untuk mengoptimumkan secara langsung tempoh pengguna kekal pada APP secara keseluruhan hari ini apabila menggunakan penunjuk pengoptimuman tempoh Perkara yang lebih dioptimumkan ialah tempoh mereka kekal pada item. Jika tempoh tidak dianggap sebagai matlamat pengoptimuman, lebih mudah untuk mempromosikan banyak kandungan penggunaan cetek.
S2: Adakah terdapat isu konsistensi dalam kemas kini masa nyata model jika kegagalan berlaku semasa latihan? Bagaimana untuk menangani isu konsistensi model?
A2: Pada masa ini, untuk pembelajaran dan latihan yang disyorkan, jika ia adalah CPU, terdapat lebih banyak asynchronous, dan orang ramai tidak cenderung melakukannya dengan pusingan global , dsb. Selepas pusingan tamat, kumpulkan mereka bersama-sama, kemas kini mereka pada PS, dan kemudian mulakan pusingan seterusnya Kerana isu prestasi, orang pada dasarnya tidak akan melakukan ini. Tidak kira sama ada pembelajaran masa nyata atau dalam talian, konsistensi yang kukuh tidak boleh dicapai.
Jika kegagalan lebih berlaku semasa latihan anda, jika anda melakukan latihan penstriman, ia akan direkodkan pada aliran data, seperti kafka atau flink, untuk dirakam semasa anda Di mana sahaja rancangan dilatih, ps anda juga mempunyai rekod latihan terakhir anda, yang serupa dengan perbezaan global.
S3: Adakah menggunakan pengisihan halus untuk panggil semula mengurangkan had lelaran model panggil balik?
A3: Had atas lelaran boleh difahamkan sebagai siling penarikan balik maka saya faham bahawa siling penarikan semula pastinya tidak melebihi kedudukan yang baik. jika kuasa pengkomputeran kini tidak terhingga , maka menggunakan pengisihan halus untuk menjaringkan 5 juta bahan ialah cara terbaik untuk mengendalikan perniagaan. Apabila penarikan balik bukanlah pelaburan yang besar, kami cuba mencari untuknya bahagian terbaik semakan Sebagai contoh, biarkan dia memilih 15 teratas daripada 6,000 dalam panggilan balik dan 15 teratas daripada 5 juta, yang mana. Modul penarikan semula berfungsi dengan lebih baik. Jika semua orang memahami perkara ini, maka mengingati susunan pengisihan halus tidak akan mengurangkan lelaran dalam talian, tetapi akan bergerak ke arah had atas. Walau bagaimanapun, ini juga pendapat kami Bergantung pada orientasi perniagaan anda sendiri, kesimpulannya mungkin tidak boleh digunakan secara universal.
Atas ialah kandungan terperinci Evolusi teknikal model besar masa nyata untuk cadangan Weibo. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Apl model besar Tencent Yuanbao berada dalam talian! Hunyuan dinaik taraf untuk mencipta pembantu AI serba boleh yang boleh dibawa ke mana-mana
Jun 09, 2024 pm 10:38 PM
Apl model besar Tencent Yuanbao berada dalam talian! Hunyuan dinaik taraf untuk mencipta pembantu AI serba boleh yang boleh dibawa ke mana-mana
Jun 09, 2024 pm 10:38 PM
Pada 30 Mei, Tencent mengumumkan peningkatan menyeluruh model Hunyuannya Apl "Tencent Yuanbao" berdasarkan model Hunyuan telah dilancarkan secara rasmi dan boleh dimuat turun dari kedai aplikasi Apple dan Android. Berbanding dengan versi applet Hunyuan dalam peringkat ujian sebelumnya, Tencent Yuanbao menyediakan keupayaan teras seperti carian AI, ringkasan AI, dan penulisan AI untuk senario kecekapan kerja untuk senario kehidupan harian, permainan Yuanbao juga lebih kaya dan menyediakan pelbagai ciri , dan kaedah permainan baharu seperti mencipta ejen peribadi ditambah. "Tencent tidak akan berusaha untuk menjadi yang pertama membuat model besar, Liu Yuhong, naib presiden Tencent Cloud dan orang yang bertanggungjawab bagi model besar Tencent Hunyuan, berkata: "Pada tahun lalu, kami terus mempromosikan keupayaan untuk Model besar Tencent Hunyuan Dalam teknologi Poland yang kaya dan besar dalam senario perniagaan sambil mendapatkan cerapan tentang keperluan sebenar pengguna
 Model besar Bytedance Beanbao dikeluarkan, perkhidmatan AI tindanan penuh Volcano Engine membantu perusahaan mengubah dengan bijak
Jun 05, 2024 pm 07:59 PM
Model besar Bytedance Beanbao dikeluarkan, perkhidmatan AI tindanan penuh Volcano Engine membantu perusahaan mengubah dengan bijak
Jun 05, 2024 pm 07:59 PM
Tan Dai, Presiden Volcano Engine, berkata syarikat yang ingin melaksanakan model besar dengan baik menghadapi tiga cabaran utama: kesan model, kos inferens dan kesukaran pelaksanaan: mereka mesti mempunyai sokongan model besar asas yang baik untuk menyelesaikan masalah yang kompleks, dan mereka juga mesti mempunyai inferens kos rendah. Perkhidmatan membolehkan model besar digunakan secara meluas, dan lebih banyak alat, platform dan aplikasi diperlukan untuk membantu syarikat melaksanakan senario. ——Tan Dai, Presiden Huoshan Engine 01. Model pundi kacang besar membuat kemunculan sulungnya dan banyak digunakan Menggilap kesan model adalah cabaran paling kritikal untuk pelaksanaan AI. Tan Dai menegaskan bahawa hanya melalui penggunaan meluas model yang baik boleh digilap. Pada masa ini, model Doubao memproses 120 bilion token teks dan menjana 30 juta imej setiap hari. Untuk membantu perusahaan melaksanakan senario model berskala besar, model berskala besar beanbao yang dibangunkan secara bebas oleh ByteDance akan dilancarkan melalui gunung berapi
 Artikel ini akan membawa anda memahami SHAP: penjelasan model untuk pembelajaran mesin
Jun 01, 2024 am 10:58 AM
Artikel ini akan membawa anda memahami SHAP: penjelasan model untuk pembelajaran mesin
Jun 01, 2024 am 10:58 AM
Dalam bidang pembelajaran mesin dan sains data, kebolehtafsiran model sentiasa menjadi tumpuan penyelidik dan pengamal. Dengan aplikasi meluas model yang kompleks seperti kaedah pembelajaran mendalam dan ensemble, memahami proses membuat keputusan model menjadi sangat penting. AI|XAI yang boleh dijelaskan membantu membina kepercayaan dan keyakinan dalam model pembelajaran mesin dengan meningkatkan ketelusan model. Meningkatkan ketelusan model boleh dicapai melalui kaedah seperti penggunaan meluas pelbagai model yang kompleks, serta proses membuat keputusan yang digunakan untuk menerangkan model. Kaedah ini termasuk analisis kepentingan ciri, anggaran selang ramalan model, algoritma kebolehtafsiran tempatan, dsb. Analisis kepentingan ciri boleh menerangkan proses membuat keputusan model dengan menilai tahap pengaruh model ke atas ciri input. Anggaran selang ramalan model
 Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Cabaran biasa yang dihadapi oleh algoritma pembelajaran mesin dalam C++ termasuk pengurusan memori, multi-threading, pengoptimuman prestasi dan kebolehselenggaraan. Penyelesaian termasuk menggunakan penunjuk pintar, perpustakaan benang moden, arahan SIMD dan perpustakaan pihak ketiga, serta mengikuti garis panduan gaya pengekodan dan menggunakan alat automasi. Kes praktikal menunjukkan cara menggunakan perpustakaan Eigen untuk melaksanakan algoritma regresi linear, mengurus memori dengan berkesan dan menggunakan operasi matriks berprestasi tinggi.
 Amalan lanjutan graf pengetahuan industri
Jun 13, 2024 am 11:59 AM
Amalan lanjutan graf pengetahuan industri
Jun 13, 2024 am 11:59 AM
1. Latar Belakang Pengenalan Pertama, mari kita perkenalkan sejarah pembangunan Teknologi Yunwen. Syarikat Teknologi Yunwen...2023 ialah tempoh apabila model besar berleluasa Banyak syarikat percaya bahawa kepentingan graf telah dikurangkan dengan ketara selepas model besar, dan sistem maklumat pratetap yang dikaji sebelum ini tidak lagi penting. Walau bagaimanapun, dengan promosi RAG dan kelaziman tadbir urus data, kami mendapati bahawa tadbir urus data yang lebih cekap dan data berkualiti tinggi adalah prasyarat penting untuk meningkatkan keberkesanan model besar yang diswastakan Oleh itu, semakin banyak syarikat mula memberi perhatian kepada kandungan berkaitan pembinaan pengetahuan. Ini juga menggalakkan pembinaan dan pemprosesan pengetahuan ke peringkat yang lebih tinggi, di mana terdapat banyak teknik dan kaedah yang boleh diterokai. Dapat dilihat bahawa kemunculan teknologi baru tidak mengalahkan semua teknologi lama, tetapi mungkin juga mengintegrasikan teknologi baru dan lama.
 Xiaomi Byte bergabung tenaga! Model besar akses Xiao Ai ke Doubao: sudah dipasang pada telefon mudah alih dan SU7
Jun 13, 2024 pm 05:11 PM
Xiaomi Byte bergabung tenaga! Model besar akses Xiao Ai ke Doubao: sudah dipasang pada telefon mudah alih dan SU7
Jun 13, 2024 pm 05:11 PM
Menurut berita pada 13 Jun, menurut akaun awam “Volcano Engine” Byte, pembantu kecerdasan buatan Xiaomi “Xiao Ai” telah mencapai kerjasama dengan Volcano Engine Kedua-dua pihak akan mencapai pengalaman interaktif AI yang lebih pintar berdasarkan model besar beanbao . Dilaporkan bahawa model beanbao berskala besar yang dicipta oleh ByteDance boleh memproses sehingga 120 bilion token teks dengan cekap dan menjana 30 juta keping kandungan setiap hari. Xiaomi menggunakan model besar Doubao untuk meningkatkan keupayaan pembelajaran dan penaakulan modelnya sendiri dan mencipta "Xiao Ai Classmate", yang bukan sahaja memahami keperluan pengguna dengan lebih tepat, tetapi juga menyediakan kelajuan tindak balas yang lebih pantas dan perkhidmatan kandungan yang lebih komprehensif. Contohnya, apabila pengguna bertanya tentang konsep saintifik yang kompleks, &ldq
 AI yang boleh dijelaskan: Menerangkan model AI/ML yang kompleks
Jun 03, 2024 pm 10:08 PM
AI yang boleh dijelaskan: Menerangkan model AI/ML yang kompleks
Jun 03, 2024 pm 10:08 PM
Penterjemah |. Disemak oleh Li Rui |. Chonglou Model kecerdasan buatan (AI) dan pembelajaran mesin (ML) semakin kompleks hari ini, dan output yang dihasilkan oleh model ini adalah kotak hitam – tidak dapat dijelaskan kepada pihak berkepentingan. AI Boleh Dijelaskan (XAI) bertujuan untuk menyelesaikan masalah ini dengan membolehkan pihak berkepentingan memahami cara model ini berfungsi, memastikan mereka memahami cara model ini sebenarnya membuat keputusan, dan memastikan ketelusan dalam sistem AI, Amanah dan akauntabiliti untuk menyelesaikan masalah ini. Artikel ini meneroka pelbagai teknik kecerdasan buatan (XAI) yang boleh dijelaskan untuk menggambarkan prinsip asasnya. Beberapa sebab mengapa AI boleh dijelaskan adalah penting Kepercayaan dan ketelusan: Untuk sistem AI diterima secara meluas dan dipercayai, pengguna perlu memahami cara keputusan dibuat
 Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) set data memainkan peranan penting dalam mempromosikan penyelidikan pemprosesan bahasa semula jadi (NLP). Set data QA berkualiti tinggi bukan sahaja boleh digunakan untuk memperhalusi model, tetapi juga menilai dengan berkesan keupayaan model bahasa besar (LLM), terutamanya keupayaan untuk memahami dan menaakul tentang pengetahuan saintifik. Walaupun pada masa ini terdapat banyak set data QA saintifik yang meliputi bidang perubatan, kimia, biologi dan bidang lain, set data ini masih mempunyai beberapa kekurangan. Pertama, borang data adalah agak mudah, kebanyakannya adalah soalan aneka pilihan. Ia mudah dinilai, tetapi mengehadkan julat pemilihan jawapan model dan tidak dapat menguji sepenuhnya keupayaan model untuk menjawab soalan saintifik. Sebaliknya, Soal Jawab terbuka
