

100 bilion neuron, setiap neuron mempunyai kira-kira 8,000 sinaps Struktur kompleks otak memberi inspirasi kepada penyelidikan kecerdasan buatan.
Pada masa ini, seni bina kebanyakan model pembelajaran mendalam ialah rangkaian saraf tiruan yang diilhamkan oleh neuron otak biologi.
AI Generatif meletup, dan anda dapat melihat bahawa algoritma pembelajaran mendalam sedang menjana , keupayaan untuk meringkaskan, menterjemah dan mengklasifikasikan teks semakin berkuasa.
Walau bagaimanapun, model bahasa ini masih tidak dapat menandingi keupayaan bahasa manusia.
Teori pengekodan ramalan memberikan penjelasan awal untuk perbezaan ini:
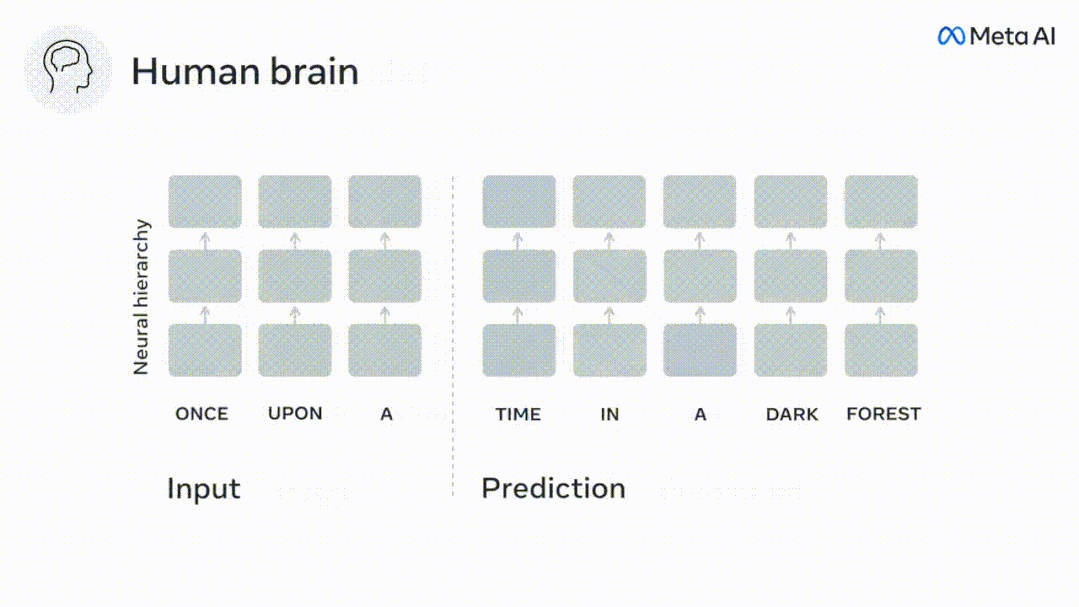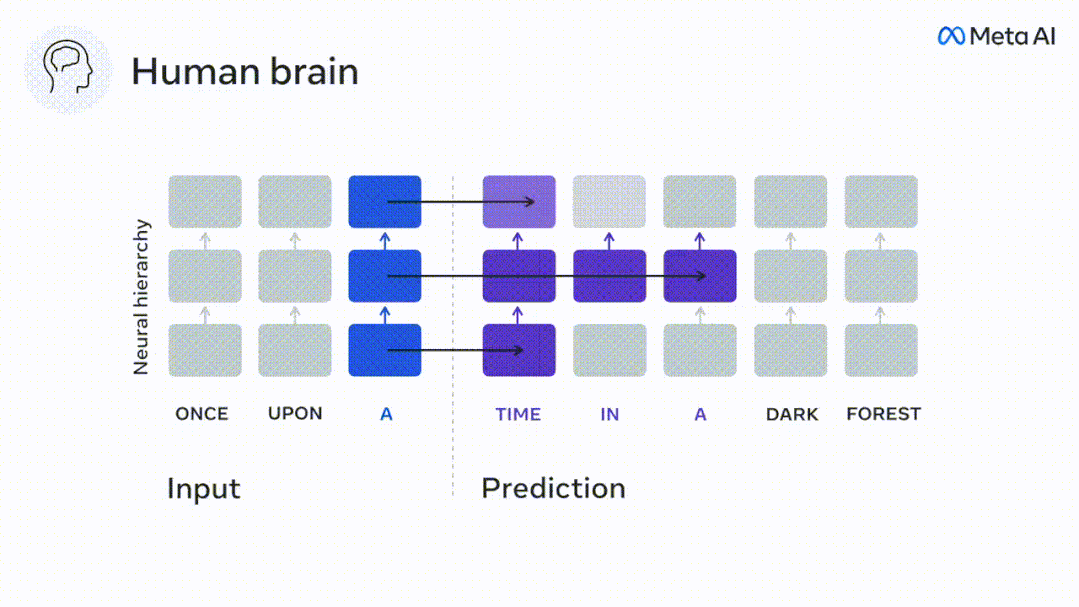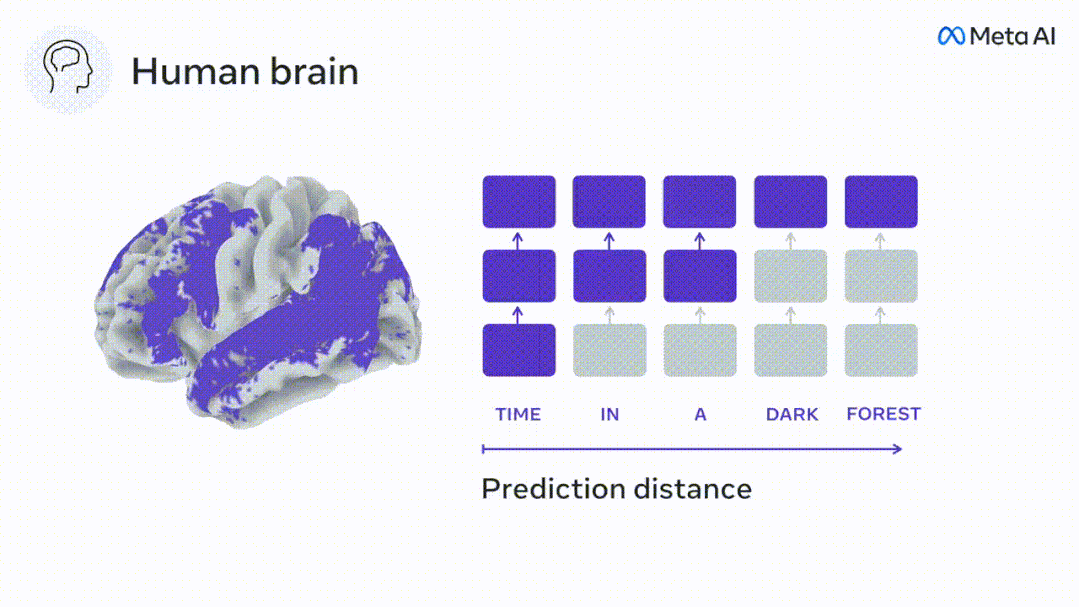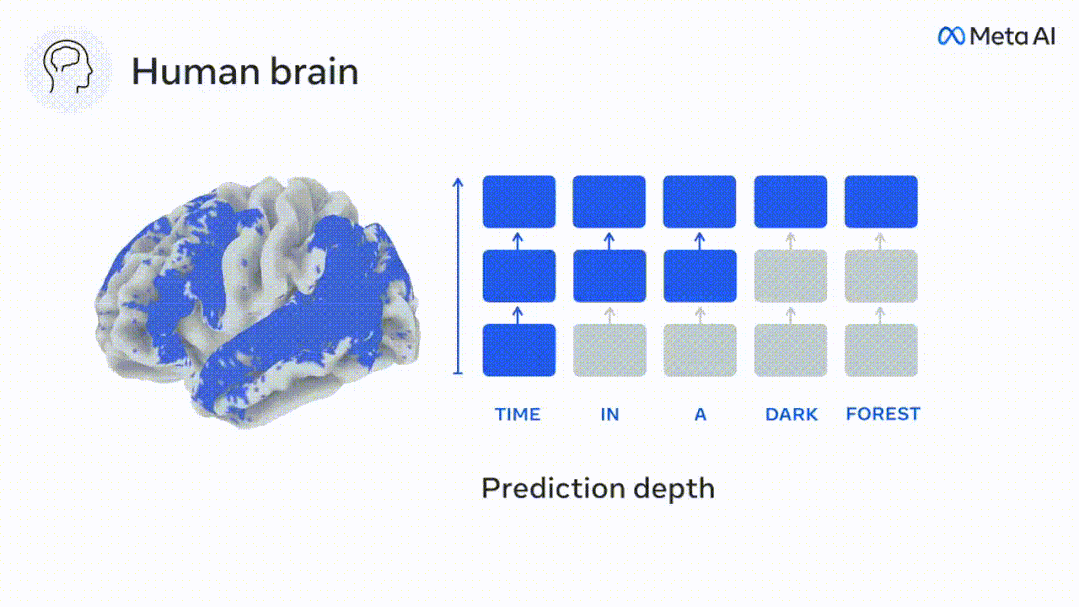
Walaupun model bahasa boleh meramalkan perkataan berdekatan, otak manusia sentiasa meramalkan lapisan perwakilan merentas pelbagai skala masa.
Untuk menguji hipotesis ini, saintis di Meta AI menganalisis isyarat pengimejan resonans magnetik berfungsi otak daripada 304 orang yang mendengar cerpen itu.
Disimpulkan bahawa pengekodan ramalan hierarki memainkan peranan penting dalam pemprosesan bahasa.
Sementara itu, penyelidikan menggambarkan bagaimana sinergi antara neurosains dan kecerdasan buatan boleh mendedahkan asas pengiraan kognisi manusia.
Penyelidikan terkini telah diterbitkan dalam sub-jurnal Nature Nature Human Behavior.

Alamat kertas: https://www.php.cn/link/7eab47bf3a57db8e440e5a788467c37f
Perlu dinyatakan bahawa GPT-2 telah digunakan semasa percubaan Mungkin penyelidikan ini boleh memberi inspirasi kepada model OpenAI yang belum dibuka pada masa hadapan.
Bukankah ChatGPT akan menjadi lebih kuat pada masa itu? Pengekodan Ramalan Otak Berlapis
Dalam masa kurang daripada 3 tahun, pembelajaran mendalam telah mencapai kemajuan yang ketara dalam penjanaan teks dan terjemahan Terima kasih kepada seorang yang terlatih algoritma: meramal perkataan berdasarkan konteks berdekatan.
Terutamanya, pengaktifan daripada model ini telah ditunjukkan untuk memetakan secara linear kepada tindak balas otak terhadap pertuturan dan teks.
Tambahan pula, pemetaan ini bergantung terutamanya pada keupayaan algoritma untuk meramal perkataan akan datang, dengan itu mencadangkan bahawa matlamat ini mencukupi untuk mereka menumpu kepada pengiraan seperti otak.
Walau bagaimanapun, jurang masih wujud antara algoritma ini dan otak: walaupun terdapat sejumlah besar data latihan, model bahasa semasa gagal pada penjanaan cerita panjang, ringkasan dan Cabaran dengan perbualan yang koheren dan pencarian maklumat.
Oleh kerana algoritma tidak dapat menangkap beberapa struktur sintaksis dan sifat semantik, dan pemahaman bahasa itu juga sangat cetek.
Sebagai contoh, algoritma cenderung untuk salah menetapkan kata kerja kepada subjek dalam frasa bersarang.
「kunci yang dipegang lelaki itu ADA di sini」
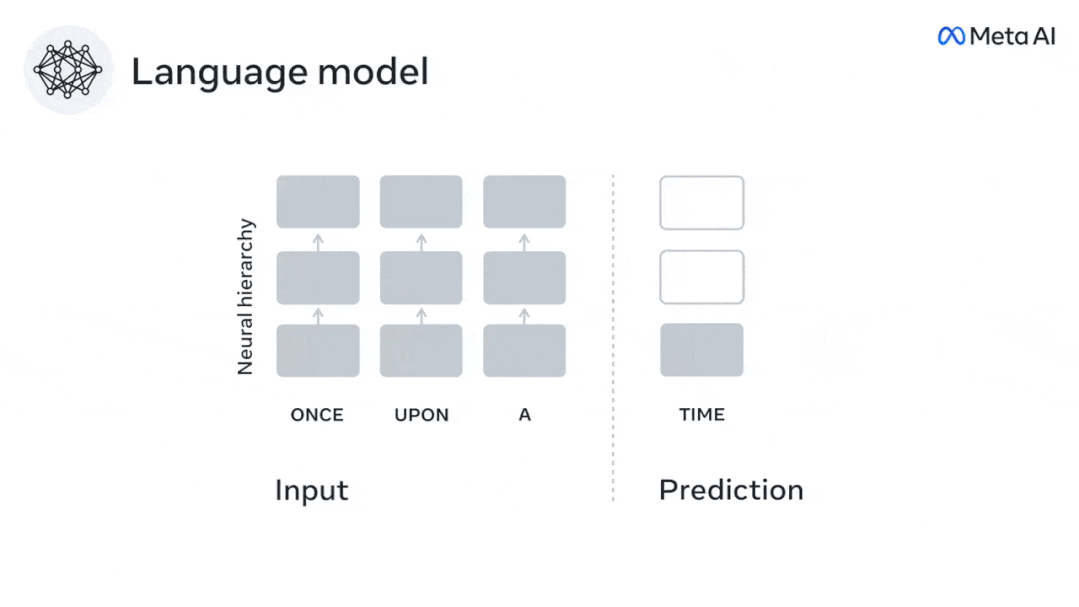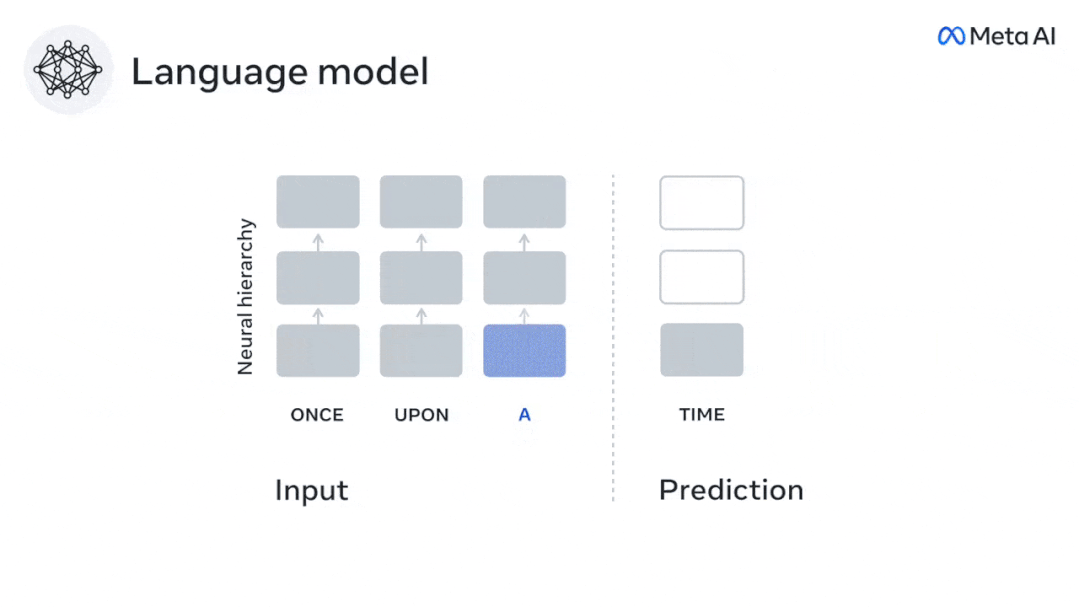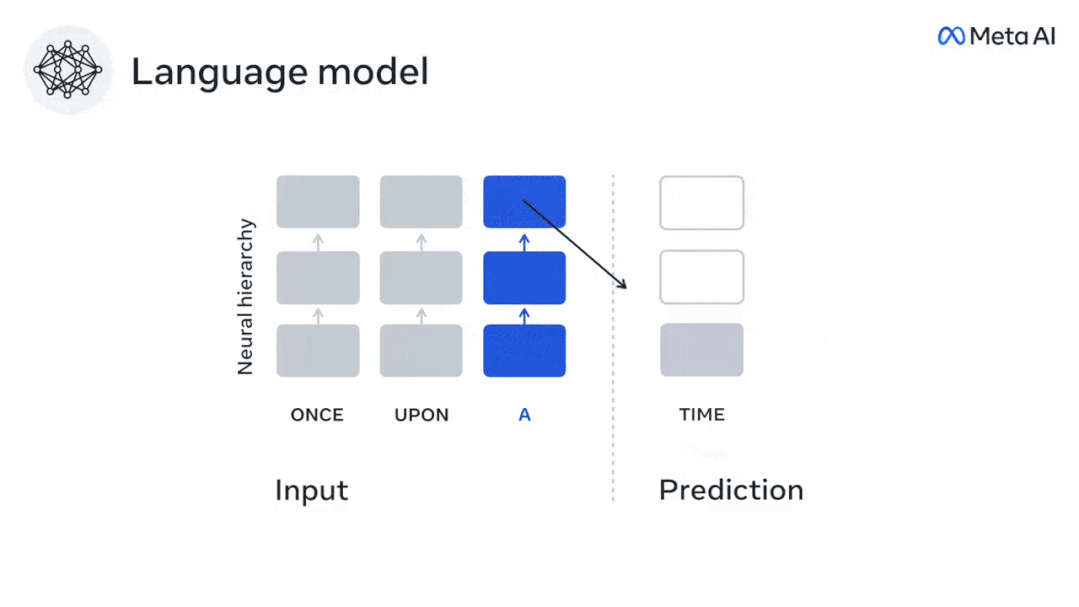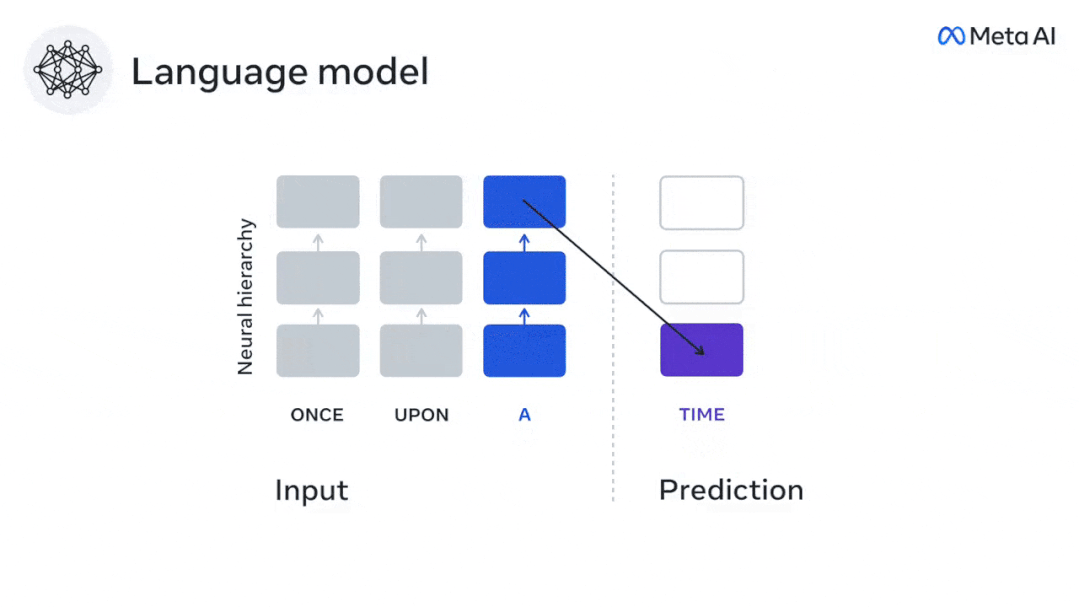
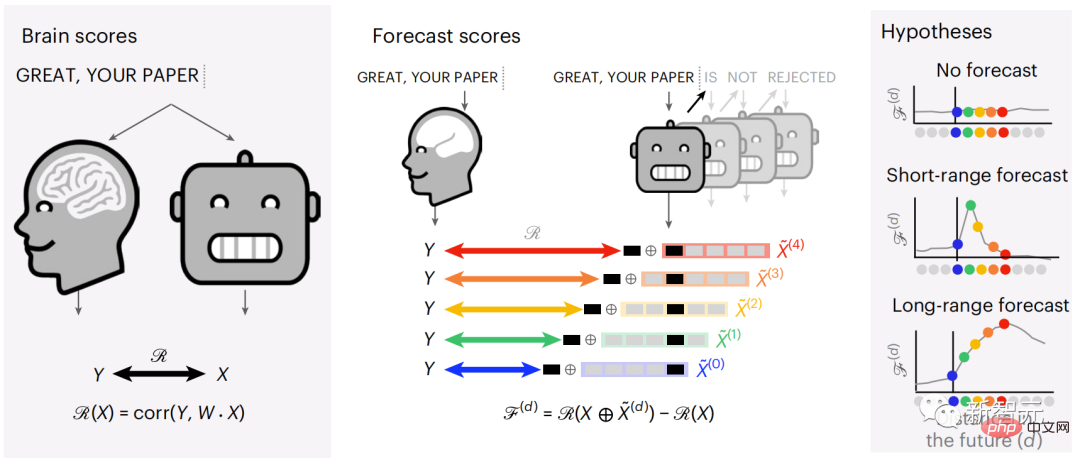
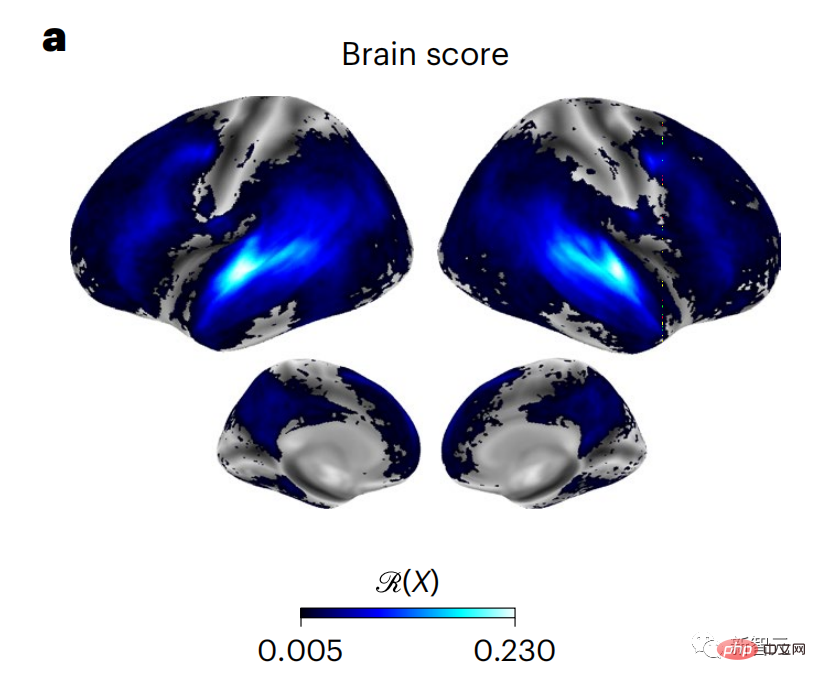
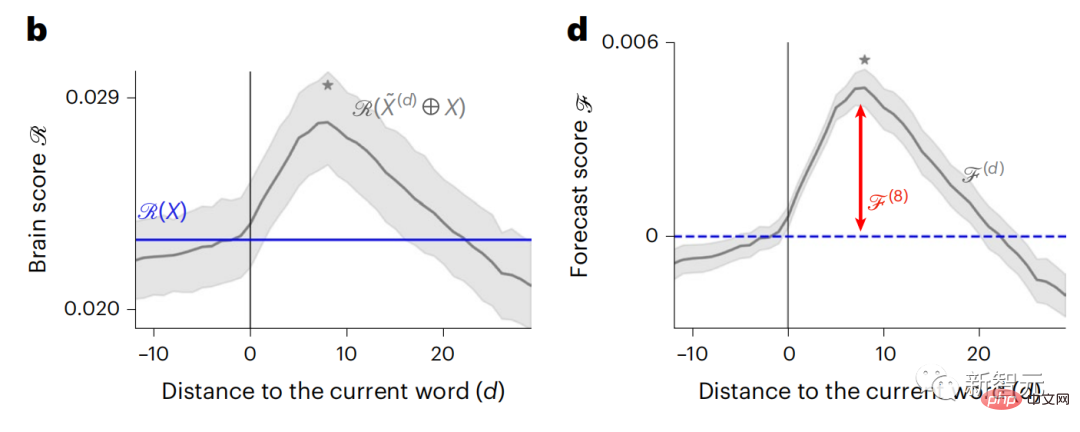
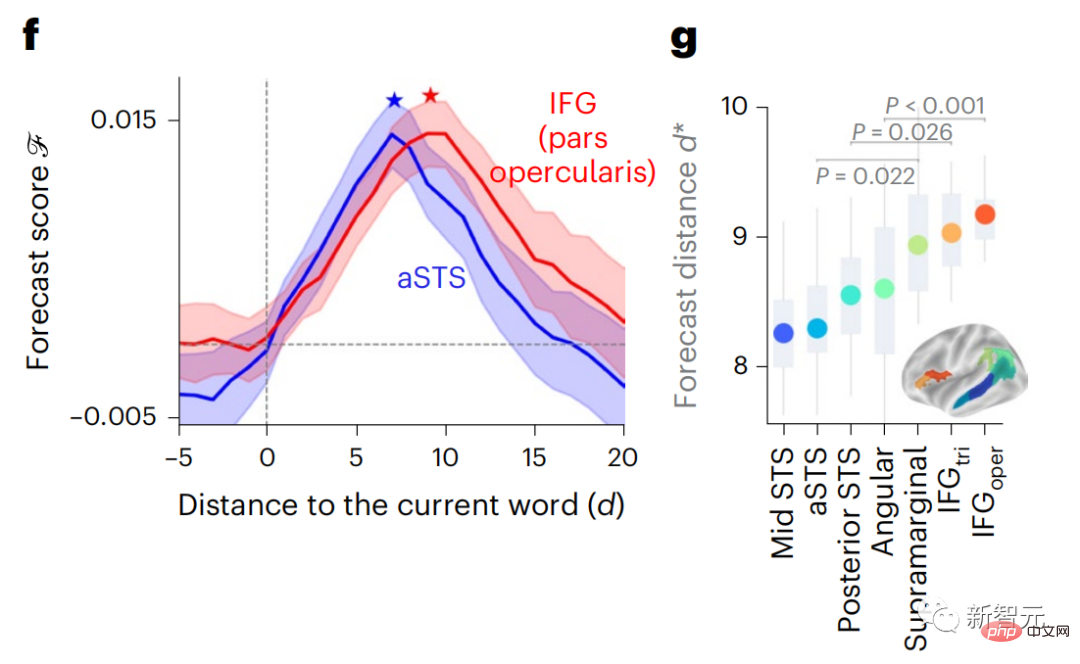
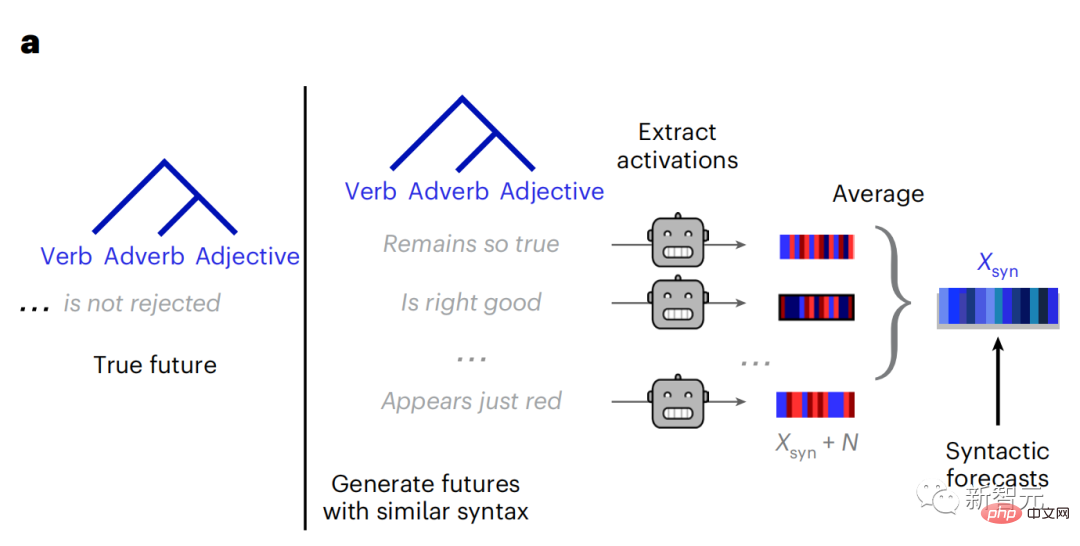
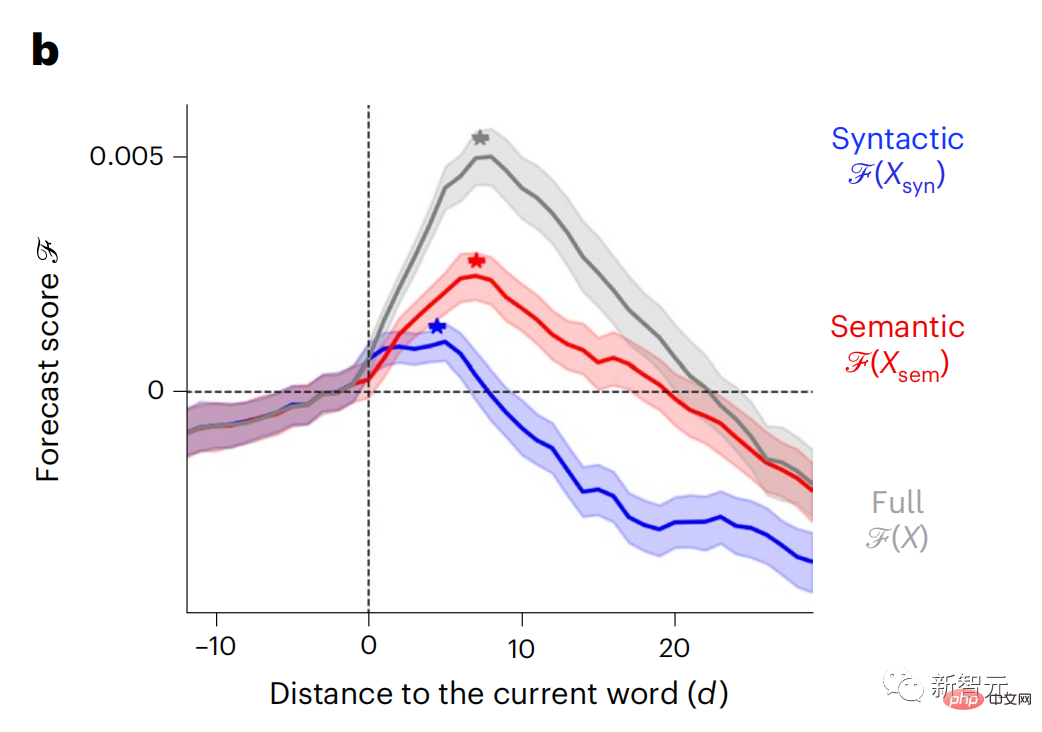
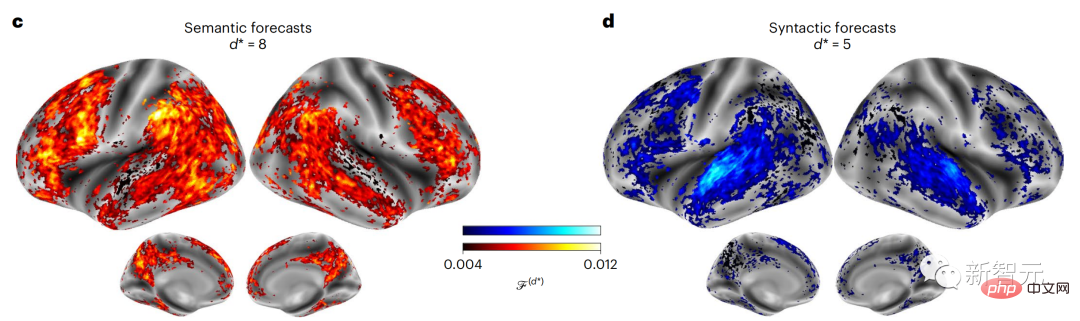
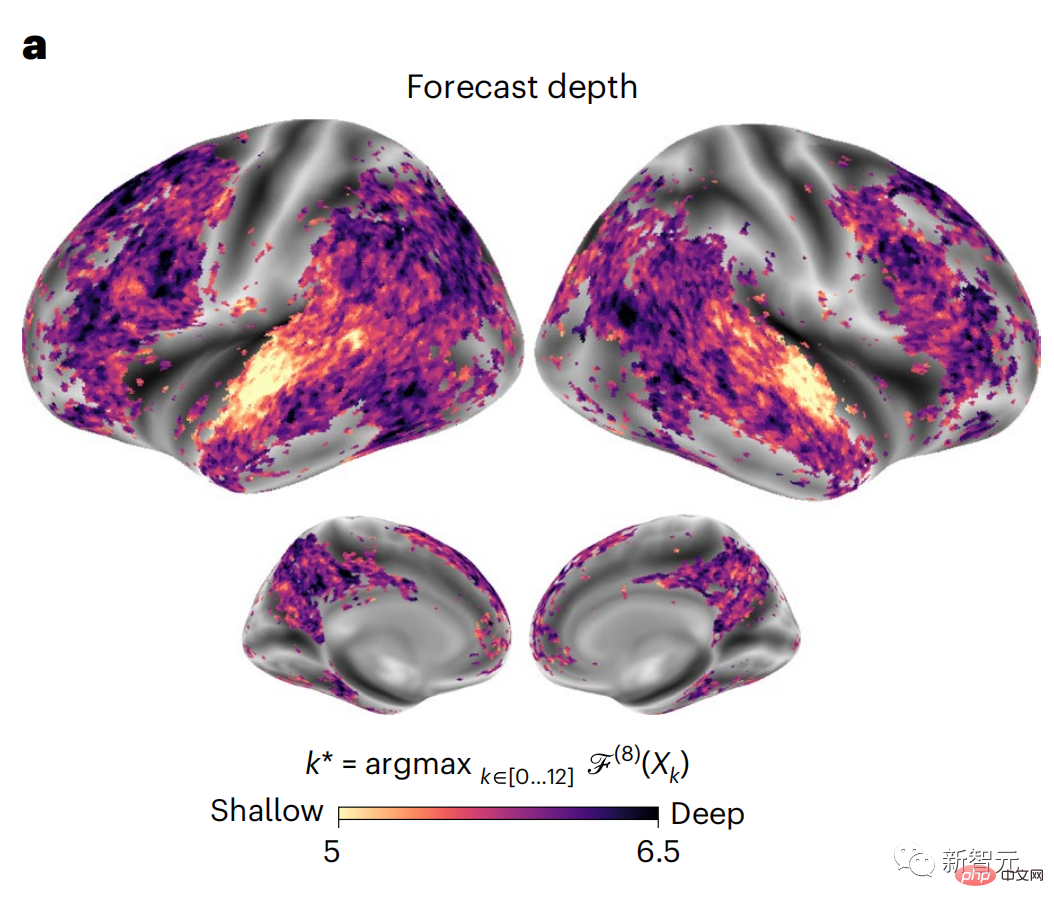
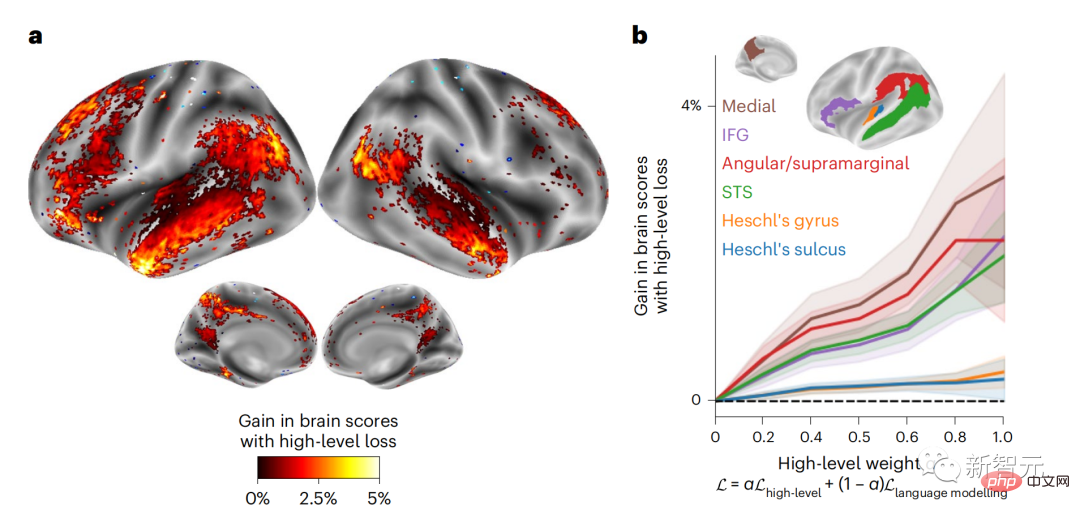
Begitu juga apabila teks Apabila menjana ramalan yang dioptimumkan hanya untuk perkataan seterusnya, model bahasa dalam boleh menjana urutan yang hambar, tidak koheren atau terperangkap dalam gelung yang berulang tanpa henti. Pada masa ini, teori pengekodan ramalan memberikan penjelasan yang berpotensi untuk kecacatan ini: Sementara model bahasa dalam digunakan terutamanya untuk Meramalkan perkataan seterusnya, tetapi rangka kerja ini menunjukkan bahawa otak manusia boleh meramalkan pada skala masa berbilang dan tahap perwakilan kortikal. Penyelidikan sebelum ini telah menunjukkan ramalan pertuturan dalam otak, iaitu perkataan atau fonem, dengan fMRI ( fMRI), electroencephalography, magnetoencephalography dan electrocorticography telah dikaitkan. Model yang dilatih untuk meramal perkataan atau fonem seterusnya boleh mengurangkan outputnya kepada satu nombor, kebarangkalian simbol seterusnya. Walau bagaimanapun, sifat dan skala masa bagi perwakilan ramalan sebahagian besarnya tidak diketahui. Dalam kajian ini, penyelidik mengekstrak isyarat fMRI sebanyak 304 orang dan membiarkan setiap orang mendengarnya selama kira-kira 26 minit cerpen (Y), dan masukkan kandungan yang sama untuk mengaktifkan algoritma bahasa (X). Kemudian, persamaan antara X dan Y dikira dengan "skor otak", iaitu pekali korelasi Pearson (R) selepas pemetaan linear terbaik W . Untuk menguji sama ada menambah perwakilan perkataan yang diramalkan meningkatkan korelasi ini, pengaktifan rangkaian (segi empat tepat hitam ) disambungkan ke tetingkap ramalan (segi empat tepat berwarna ~X), dan kemudian menggunakan PCA untuk mengurangkan dimensi tetingkap ramalan kepada dimensi X. Akhir sekali F mengukur keuntungan skor otak yang diperoleh dengan meningkatkan pengaktifan tetingkap ramalan ini oleh algoritma bahasa. Kami mengulangi analisis ini (d) dengan tingkap jarak yang berbeza. Didapati pemetaan otak ini boleh diperbaiki dengan menambah algoritma ini dengan ramalan yang menjangkau skala masa berbilang iaitu ramalan jarak jauh dan ramalan hierarki. Akhir sekali, keputusan percubaan mendapati bahawa ramalan ini disusun secara hierarki: korteks hadapan meramalkan tahap yang lebih tinggi, skop yang lebih besar dan lebih banyak ramalan daripada korteks temporal perwakilan. Peta model bahasa mendalam ke aktiviti otak Penyelidik secara kuantitatif mengkaji persamaan antara model bahasa dalam dan otak apabila kandungan input adalah sama. Menggunakan dataset Naratif, fMRI (pengimejan resonans magnetik berfungsi) daripada 304 orang yang mendengar cerpen telah dianalisis. Lakukan regresi rabung linear bebas pada keputusan untuk setiap voxel dan setiap individu eksperimen untuk meramalkan isyarat fMRI yang terhasil daripada pengaktifan beberapa model bahasa dalam. Menggunakan data yang disimpan, "skor otak" yang sepadan telah dikira, iaitu, korelasi antara isyarat fMRI dan hasil ramalan regresi rabung yang diperoleh dengan memasukkan model bahasa yang ditentukan rangsangan seks. Untuk kejelasan, fokus dahulu pada pengaktifan lapisan kelapan GPT-2, rangkaian neural dalam penyebab 12 lapisan yang dikuasakan oleh HuggingFace2, iaitu Aktiviti otak yang paling meramalkan. Selaras dengan kajian terdahulu, pengaktifan GPT-2 dipetakan dengan tepat kepada set teragih kawasan otak dua hala, dengan skor otak memuncak dalam korteks pendengaran dan kawasan temporal anterior dan superior. Pasukan Meta kemudiannya menguji Adakah peningkatan rangsangan model bahasa dengan keupayaan ramalan jarak jauh membawa kepada skor otak yang lebih tinggi. Untuk setiap perkataan, penyelidik menyambungkan pengaktifan model untuk perkataan semasa kepada "tetingkap ramalan" yang terdiri daripada perkataan masa hadapan. Parameter perwakilan tetingkap ramalan termasuk d, yang mewakili jarak antara perkataan semasa dan perkataan masa hadapan yang terakhir dalam tetingkap, dan w, yang mewakili bilangan perkataan bercantum. Untuk setiap d, bandingkan markah otak dengan dan tanpa perwakilan ramalan dan hitung "skor ramalan". Keputusan menunjukkan bahawa skor ramalan adalah tertinggi apabila d=8, dan nilai puncak muncul di kawasan otak yang berkaitan dengan pemprosesan bahasa. d=8 sepadan dengan 3.15 saat audio, iaitu masa dua imbasan fMRI berturut-turut. Skor ramalan diedarkan secara dua hala dalam otak, kecuali dalam gyri frontal dan supramarginal inferior. Melalui analisis tambahan, pasukan juga memperoleh keputusan berikut: (1) Setiap perkataan masa depan dengan jarak 0 hingga 10 daripada perkataan semasa mempunyai signifikan sumbangan kepada hasil ramalan ; (2) Perwakilan ramalan paling baik ditangkap dengan saiz tetingkap sekitar 8 perkataan; keputusan keputusan yang serupa, tetapi dengan markah yang lebih rendah. Rangka masa yang diramalkan berbeza-beza mengikut tahap otak Anatomi & kajian telah menunjukkan bahawa korteks serebrum adalah hierarki. Adakah tetingkap masa ramalan adalah sama untuk tahap korteks yang berbeza? Para penyelidik menganggarkan skor ramalan puncak setiap voxel dan menyatakan jarak yang sepadan sebagai d. Keputusan menunjukkan bahawa d yang sepadan dengan puncak yang diramalkan di kawasan prefrontal adalah lebih besar daripada di kawasan lobus temporal secara purata (Rajah 2e), dan d gyrus temporal inferior Ia lebih besar daripada sulcus temporal superior. Variasi jarak ramalan terbaik sepanjang paksi temporal-parietal-frontal pada asasnya simetri di kedua-dua hemisfera otak . Untuk setiap perkataan dan konteks sebelumnya, sepuluh adalah menjana kemungkinan perkataan masa hadapan yang sepadan dengan sintaks perkataan masa hadapan yang sebenar. Untuk setiap perkataan masa hadapan yang mungkin, pengaktifan GPT-2 yang sepadan diekstrak dan dipuratakan. Pendekatan ini dapat menguraikan pengaktifan model bahasa tertentu kepada komponen sintaksis dan semantik, dengan itu mengira skor ramalan masing-masing. Keputusan menunjukkan bahawa ramalan semantik adalah jarak jauh (d = 8), melibatkan rangkaian teragih, di hadapan Puncak dicapai dalam lobus dan lobus parietal, manakala ramalan sintaksis adalah lebih pendek (d = 5) dan tertumpu di kawasan hadapan temporal dan kiri yang unggul. Keputusan ini mendedahkan pelbagai peringkat ramalan dalam otak, di mana korteks temporal unggul terutamanya meramalkan perwakilan jangka pendek, cetek dan sintaksis, manakala kawasan hadapan dan parietal yang lebih rendah terutamanya meramalkan jangka panjang, perwakilan kontekstual, peringkat tinggi dan sintaksis. Latar belakang yang diramalkan menjadi lebih kompleks di sepanjang tahap otak Masih seperti sebelum ini kaedah mengira skor ramalan, tetapi mengubah penggunaan lapisan GPT-2 untuk menentukan k bagi setiap voxel, kedalaman di mana skor ramalan dimaksimumkan. Keputusan kami menunjukkan bahawa kedalaman ramalan optimum berbeza-beza mengikut hierarki kortikal yang dijangkakan, dengan model terbaik untuk korteks bersekutu mempunyai ramalan yang lebih mendalam daripada kawasan bahasa peringkat rendah . Perbezaan antara wilayah, walaupun kecil secara purata, sangat ketara pada individu yang berbeza. Secara amnya, latar belakang ramalan jangka panjang korteks hadapan adalah lebih kompleks daripada latar belakang ramalan jangka pendek kawasan otak peringkat rendah Tahap lebih tinggi. Laraskan GPT-2 kepada struktur pengekodan ramalan Laraskan perkataan semasa dan masa hadapan GPT-2 The representasi boleh digabungkan untuk mendapatkan model aktiviti otak yang lebih baik, terutamanya di kawasan hadapan. Bolehkah penalaan halus GPT-2 untuk meramalkan perwakilan pada jarak yang lebih jauh, dengan latar belakang yang lebih kaya dan pada tahap yang lebih tinggi meningkatkan pemetaan otak di kawasan ini? Dalam pelarasan, bukan sahaja pemodelan bahasa digunakan, tetapi juga sasaran peringkat tinggi dan jarak jauh digunakan Sasaran peringkat tinggi di sini ialah GPT pra-latihan -Lapisan 8 daripada 2 model. Hasilnya menunjukkan bahawa penalaan halus GPT-2 dengan pasangan pemodelan peringkat tinggi dan jarak jauh terbaik meningkatkan tindak balas lobus hadapan, manakala kawasan pendengaran dan peringkat bawah kawasan otak tidak mendapat manfaat yang ketara daripada penyasaran peringkat tinggi tersebut, seterusnya mencerminkan peranan kawasan hadapan dalam meramalkan perwakilan bahasa jarak jauh, kontekstual dan peringkat tinggi. Rujukan: https:/ / www.php.cn/link/7eab47bf3a57db8e440e5a788467c37f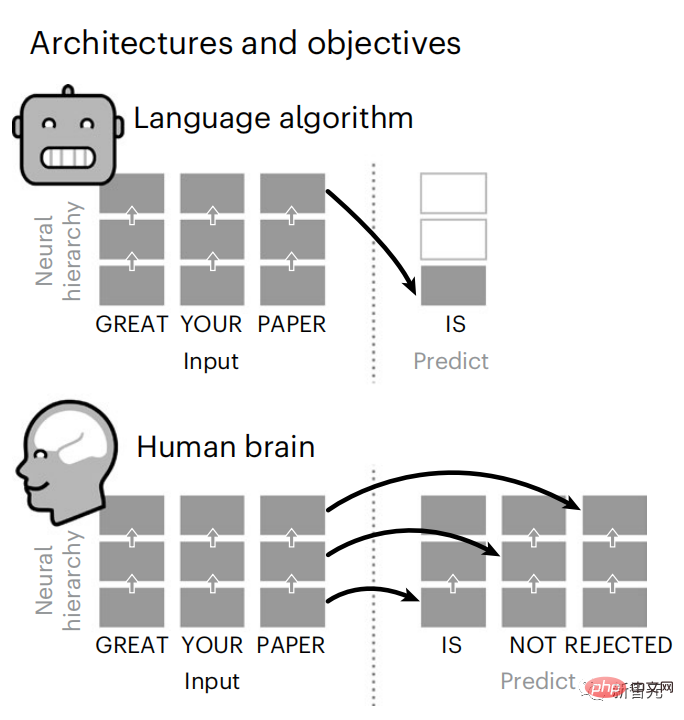
Hasil eksperimen
Atas ialah kandungan terperinci Ramalan hierarki otak menjadikan model besar lebih cekap!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Ciri-ciri bahasa delima
Ciri-ciri bahasa delima
 Apa yang perlu dilakukan jika halaman web tidak boleh diakses
Apa yang perlu dilakukan jika halaman web tidak boleh diakses
 Bagaimana untuk menambah gaya css ke html
Bagaimana untuk menambah gaya css ke html
 Mengapa telefon saya tidak dimatikan tetapi apabila seseorang menghubungi saya, telefon itu menggesa saya untuk mematikannya?
Mengapa telefon saya tidak dimatikan tetapi apabila seseorang menghubungi saya, telefon itu menggesa saya untuk mematikannya?
 Proses terperinci menaik taraf sistem win7 kepada sistem win10
Proses terperinci menaik taraf sistem win7 kepada sistem win10
 Bagaimana untuk membuka fail format csv
Bagaimana untuk membuka fail format csv
 Perbezaan antara benang dan proses
Perbezaan antara benang dan proses
 Padamkan maklumat exif
Padamkan maklumat exif








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



