
 Peranti teknologi
AI
Institut Penyelidikan Otak Digital Shanghai mengeluarkan DB1, model membuat keputusan berbilang modal besar pertama di China, yang boleh mencapai keputusan pantas untuk masalah ultra-kompleks
Peranti teknologi
AI
Institut Penyelidikan Otak Digital Shanghai mengeluarkan DB1, model membuat keputusan berbilang modal besar pertama di China, yang boleh mencapai keputusan pantas untuk masalah ultra-kompleks
Institut Penyelidikan Otak Digital Shanghai mengeluarkan DB1, model membuat keputusan berbilang modal besar pertama di China, yang boleh mencapai keputusan pantas untuk masalah ultra-kompleks

Baru-baru ini, Institut Penyelidikan Otak Digital Shanghai (selepas ini dirujuk sebagai "Institut Penyelidikan Otak Digital") melancarkan model membuat keputusan berbilang modal otak digital berskala besar pertama (dirujuk sebagai DB1), memenuhi keperluan domestik. jurang dalam hal ini dan seterusnya mengesahkan Potensi model pra-latihan dalam teks, teks imej, pembelajaran pengukuhan membuat keputusan dan pengoptimuman operasi membuat keputusan. Pada masa ini, kami telah membuka sumber kod DB1 pada Github, pautan projek: https://github.com/Shanghai-Digital-Brain-Laboratory/BDM-DB1.
Sebelum ini, Institut Sains Matematik mencadangkan MADT (https://arxiv.org/abs/2112.02845)/MAT (https://arxiv.org/abs/2205.14953) dan model Badan kecerdasan pelbagai kecerdasan lain, melalui pemodelan jujukan dalam beberapa model luar talian yang besar, menggunakan model Transformer telah mencapai hasil yang luar biasa pada beberapa tugas tunggal/berbilang ejen, dan penyelidikan serta penerokaan ke arah ini diteruskan.
Dalam beberapa tahun kebelakangan ini, dengan peningkatan model pra-latihan yang besar, akademia dan industri terus membuat kemajuan baharu dalam parameter model pra-latihan dan tugasan pelbagai mod . Institut Penyelidikan Digital, yang memberi tumpuan kepada penyelidikan perisikan membuat keputusan, secara inovatif cuba menyalin kejayaan model pra-latihan kepada tugas membuat keputusan dan mencapai kejayaan.
Model besar membuat keputusan berbilang mod DB1
Sebelum ini, DeepMind melancarkan Gato, yang menyatukan tugas membuat keputusan ejen tunggal, perbualan pelbagai pusingan dan gambar- tugas penjanaan teks menjadi satu Berdasarkan masalah autoregresif Transformer, ia telah mencapai prestasi yang baik pada 604 tugasan yang berbeza, menunjukkan bahawa beberapa masalah membuat keputusan pembelajaran pengukuhan mudah boleh diselesaikan melalui ramalan jujukan Ini mengesahkan hala tuju penyelidikan Institut Matematik dalam arah model membuat keputusan yang besar.
Kali ini, DB1 yang dilancarkan oleh Institut Penyelidikan Matematik terutamanya menghasilkan semula dan mengesahkan Gato, dan cuba menjalankannya dari aspek struktur rangkaian dan jumlah parameter, jenis tugas dan bilangan tugasan. Cuba untuk menjadi sedekat mungkin dengan Gato dari segi parameter. Secara umumnya, Institut Penyelidikan Berangka menggunakan struktur yang serupa dengan Gato (bilangan Blok Penyahkod yang sama, saiz lapisan tersembunyi, dll.), tetapi dalam FeedForwardNetwork, kerana fungsi pengaktifan GeGLU akan memperkenalkan tambahan 1/3 daripada bilangan parameter , Institut Sains Matematik mahu Jumlah parameter hampir dengan Gato, dan keadaan lapisan tersembunyi 4 * n_embed dimensi diubah menjadi 2 * n_embed ciri dimensi melalui fungsi pengaktifan GeGLU. Jika tidak, kami berkongsi parameter pembenaman pada sisi pengekodan input dan output dengan pelaksanaan Gato. Berbeza daripada Gato, kami menggunakan penyelesaian PostNorm dalam memilih normalisasi lapisan, dan kami menggunakan pengiraan ketepatan campuran dalam Perhatian untuk meningkatkan kestabilan berangka.
-
-
Jenis tugas dan bilangan tugas: Bilangan tugas percubaan dalam DB1 mencapai 870, iaitu 44.04% lebih tinggi daripada Gato dan >=50 % lebih tinggi daripada Gato Prestasi pakar meningkat sebanyak 2.23%. Dari segi jenis tugas tertentu, DB1 kebanyakannya mewarisi tugas membuat keputusan, imej dan teks Gato, dan bilangan pelbagai tugasan pada asasnya tetap sama. Tetapi dari segi tugas membuat keputusan, DB1 juga telah memperkenalkan lebih daripada 200 tugasan senario kehidupan sebenar, iaitu Masalah Jurujual Perjalanan (TSP) skala 100 dan 200 nod Tugas jenis ini memilih 100-200 lokasi geografi secara rawak nod di semua bandar utama di China representasi) penyelesaian. - Dapat dilihat bahawa prestasi keseluruhan DB1 telah mencapai tahap yang sama dengan Gato, dan telah mula berkembang ke arah badan domain permintaan yang lebih dekat dengan perniagaan sebenar dan boleh diselesaikan dengan baik Masalah NP-hard TSP belum pernah diterokai ke arah ini sebelum ini oleh Gato.
Perbandingan penunjuk DB1 (kanan) dan GATO (kiri)

Pengagihan prestasi pelbagai tugas DB1 pada persekitaran simulasi pembelajaran pengukuhan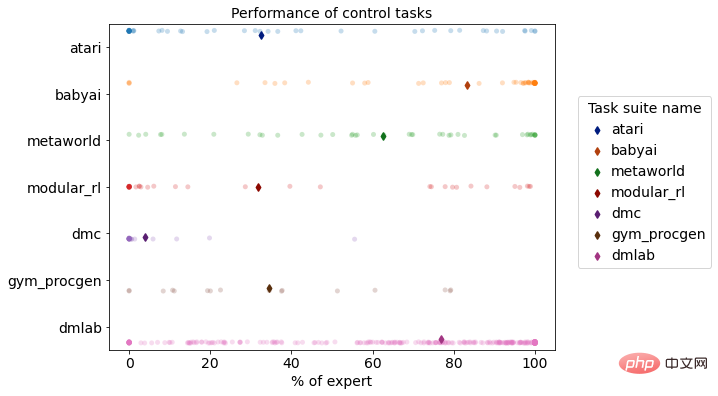
Berbanding dengan algoritma membuat keputusan tradisional, DB1 mempunyai prestasi yang baik dalam keupayaan merentas tugas membuat keputusan dan keupayaan migrasi pantas. Dari segi keupayaan membuat keputusan silang tugas dan kuantiti parameter, ia telah mencapai lonjakan daripada berpuluh juta parameter untuk satu tugas kompleks kepada berbilion parameter untuk pelbagai tugas yang kompleks, dan terus berkembang, serta mempunyai keupayaan untuk menyelesaikannya. masalah dalam persekitaran perniagaan yang kompleks. Keupayaan yang mencukupi untuk menyelesaikan masalah praktikal. Dari segi keupayaan penghijrahan, DB1 telah melengkapkan lonjakan daripada ramalan pintar kepada membuat keputusan yang bijak, dan daripada ejen tunggal kepada berbilang ejen, menebus kelemahan kaedah tradisional dalam migrasi silang tugas, yang memungkinkan untuk membina model besar dalam perusahaan.
Tidak dapat dinafikan bahawa DB1 juga menghadapi banyak kesukaran dalam proses pembangunan Institut Sains Matematik telah melakukan banyak percubaan untuk menyediakan industri dengan latihan model berskala besar dan pelbagai. storan data latihan tugasan Sediakan beberapa laluan penyelesaian standard. Memandangkan parameter model telah mencapai 1 bilion parameter dan skala tugas adalah besar, dan ia perlu dilatih pada lebih daripada 100T (300B+ Token) data pakar, rangka kerja latihan pembelajaran pengukuhan dalam biasa tidak lagi dapat memenuhi keperluan latihan pantas dalam keadaan ini. Untuk tujuan ini, di satu pihak, untuk latihan teragih, Institut Penyelidikan Matematik mempertimbangkan sepenuhnya struktur pengkomputeran pembelajaran tetulang, pengoptimuman operasi dan latihan model besar Dalam persekitaran mesin tunggal dan berbilang kad dan berbilang mesin dan berbilang kad, ia menggunakan sumber perkakasan dengan sebaik mungkin dan bijak mereka bentuk modul Mekanisme komunikasi antara kedua-dua model memaksimumkan kecekapan latihan model dan memendekkan masa latihan 870 tugasan kepada satu minggu. Sebaliknya, untuk pensampelan rawak teragih, pengindeksan, penyimpanan, pemuatan dan prapemprosesan data yang diperlukan dalam proses latihan juga telah menjadi kesesakan yang sepadan Institut Penyelidikan Matematik menggunakan mod pemuatan tertunda apabila memuatkan set data untuk menyelesaikan masalah had memori dan memaksimumkan Gunakan sepenuhnya memori yang tersedia. Di samping itu, selepas prapemprosesan data yang dimuatkan, data yang diproses akan dicache pada cakera keras, supaya data praproses boleh dimuatkan terus kemudian, mengurangkan masa dan kos sumber yang disebabkan oleh prapemprosesan berulang.
Pada masa ini, syarikat dan institusi penyelidikan antarabangsa dan domestik terkemuka seperti OpenAI, Google, Meta, Huawei, Baidu dan DAMO Academy telah menjalankan penyelidikan ke atas model besar berbilang modal dan Terdapat beberapa percubaan pengkomersilan, termasuk mengaplikasikannya dalam produknya sendiri atau menyediakan API model dan penyelesaian industri yang berkaitan. Sebaliknya, Institut Sains Matematik lebih menumpukan pada isu membuat keputusan dan menyokong percubaan aplikasi dalam tugasan membuat keputusan AI permainan, pengoptimuman penyelidikan operasi tugas penyelesaian TSP, tugas kawalan membuat keputusan robot, tugas menyelesaikan pengoptimuman kotak hitam dan berbilang- tugasan dialog bulat.
Prestasi Tugas
Pengoptimuman Penyelidikan Operasi: Penyelesaian Masalah TSP
Mengambil Masalah TSP bahagian Cina dengan bandar sebagai nod
Demonstrasi video tugasan pembelajaran pengukuhan
Model DB1 siap 870 Selepas pembelajaran luar talian tugasan membuat keputusan yang berbeza, keputusan penilaian menunjukkan bahawa 76.67% daripada tugasan mencapai atau melebihi 50% tahap pakar. Berikut ialah demonstrasi kesan daripada beberapa tugasan.
- Senario permainan video: DB1 boleh menerima input imej 2D/3D, dan boleh melengkapkan permainan piksel 2D seperti Atari dan Procgen, dan untuk DMLab DB1 sedemikian juga menunjukkan prestasi yang baik pada tugas input imej 3D yang serupa dengan dunia sebenar.

Atari Breakout

DMLab Teroka Lokasi Objek

Procgen DogBall
- Senario kawalan berterusan: Dalam tugas kawalan berterusan dalam bidang robotik, DB1 juga boleh memodelkan output dasar tindakan berterusan dan menyelesaikannya dengan baik pada tugas simulasi.

Metaworld PlateSlide

ModularRL Cheetah
文本 - 图像任务
- 文本生成:给出主务本描述
- 输入提示:makmal otak digital ialah sebuah syarikat berasaskan shanghai
-
生成结果:makmal otak digital ialah syarikat berasaskan shanghai dan kami sedang mencari syarikat orang yang berkemahiran tinggi dan berpengalaman untuk menyertai pasukan kami di shanghai, china.
kami adalah makmal otak digital dan kami sedang mencari orang yang berkemahiran tinggi dan berpengalaman untuk menyertai pasukan kami di shanghai, china.
ini adalah peluang untuk bekerja untuk sebuah syarikat yang terkenal dan sedang berkembang yang sedang melalui fasa pertumbuhan yang pantas dan mempunyai kesan dalam pasaran.
Ini adalah jawatan tetap sepenuh masa.
Kami sedang mencari jurutera perisian yang berkemahiran tinggi, bermotivasi dan berpengalaman yang boleh memimpin pasukan 5-10 dalam persekitaran yang sangat kompetitif
虽然当前多模态决策预训练模型作住 DB1仍存在一定局限性,诸如:跨域任务采样权重敏感、跨域知识迁移困难、长序列建模困难、专家数据强依赖等。虽然存在众多挆我我,中文我,住我我,住我我了态决策大模型是实现决策智能体从游戏走向更广泛场景,从虚拟走向现实,在现实开放动态环境中进行自主感觉与决策,最终实现更加通用人工智能的是他们最终实现更加通用人工智能的最终实现更加通用人工智能的最终实现更加通用人工智能的最与能的厳中。来,数研院将持续迭代数字大脑决策大模型,通过更大参数量,更有效的娏刁行,接入和支持更多任务,结合离线 / 线训练与微调,实现跨域、跨模态、跨模态、跨他们加,最终在现实应用场景下提供更通用、更高效、更低成本的决策智能决策解决方案。
Atas ialah kandungan terperinci Institut Penyelidikan Otak Digital Shanghai mengeluarkan DB1, model membuat keputusan berbilang modal besar pertama di China, yang boleh mencapai keputusan pantas untuk masalah ultra-kompleks. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Bytedance Cutting melancarkan keahlian super SVIP: 499 yuan untuk langganan tahunan berterusan, menyediakan pelbagai fungsi AI
Jun 28, 2024 am 03:51 AM
Bytedance Cutting melancarkan keahlian super SVIP: 499 yuan untuk langganan tahunan berterusan, menyediakan pelbagai fungsi AI
Jun 28, 2024 am 03:51 AM
Laman web ini melaporkan pada 27 Jun bahawa Jianying ialah perisian penyuntingan video yang dibangunkan oleh FaceMeng Technology, anak syarikat ByteDance Ia bergantung pada platform Douyin dan pada asasnya menghasilkan kandungan video pendek untuk pengguna platform tersebut Windows , MacOS dan sistem pengendalian lain. Jianying secara rasmi mengumumkan peningkatan sistem keahliannya dan melancarkan SVIP baharu, yang merangkumi pelbagai teknologi hitam AI, seperti terjemahan pintar, penonjolan pintar, pembungkusan pintar, sintesis manusia digital, dsb. Dari segi harga, yuran bulanan untuk keratan SVIP ialah 79 yuan, yuran tahunan ialah 599 yuan (nota di laman web ini: bersamaan dengan 49.9 yuan sebulan), langganan bulanan berterusan ialah 59 yuan sebulan, dan langganan tahunan berterusan ialah 499 yuan setahun (bersamaan dengan 41.6 yuan sebulan) . Di samping itu, pegawai yang dipotong juga menyatakan bahawa untuk meningkatkan pengalaman pengguna, mereka yang telah melanggan VIP asal
 Pembantu pengekodan AI yang ditambah konteks menggunakan Rag dan Sem-Rag
Jun 10, 2024 am 11:08 AM
Pembantu pengekodan AI yang ditambah konteks menggunakan Rag dan Sem-Rag
Jun 10, 2024 am 11:08 AM
Tingkatkan produktiviti, kecekapan dan ketepatan pembangun dengan menggabungkan penjanaan dipertingkatkan semula dan memori semantik ke dalam pembantu pengekodan AI. Diterjemah daripada EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, pengarang JanakiramMSV. Walaupun pembantu pengaturcaraan AI asas secara semulajadi membantu, mereka sering gagal memberikan cadangan kod yang paling relevan dan betul kerana mereka bergantung pada pemahaman umum bahasa perisian dan corak penulisan perisian yang paling biasa. Kod yang dijana oleh pembantu pengekodan ini sesuai untuk menyelesaikan masalah yang mereka bertanggungjawab untuk menyelesaikannya, tetapi selalunya tidak mematuhi piawaian pengekodan, konvensyen dan gaya pasukan individu. Ini selalunya menghasilkan cadangan yang perlu diubah suai atau diperhalusi agar kod itu diterima ke dalam aplikasi
 Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Model Bahasa Besar (LLM) dilatih pada pangkalan data teks yang besar, di mana mereka memperoleh sejumlah besar pengetahuan dunia sebenar. Pengetahuan ini dibenamkan ke dalam parameter mereka dan kemudiannya boleh digunakan apabila diperlukan. Pengetahuan tentang model ini "diperbaharui" pada akhir latihan. Pada akhir pra-latihan, model sebenarnya berhenti belajar. Selaraskan atau perhalusi model untuk mempelajari cara memanfaatkan pengetahuan ini dan bertindak balas dengan lebih semula jadi kepada soalan pengguna. Tetapi kadangkala pengetahuan model tidak mencukupi, dan walaupun model boleh mengakses kandungan luaran melalui RAG, ia dianggap berfaedah untuk menyesuaikan model kepada domain baharu melalui penalaan halus. Penalaan halus ini dilakukan menggunakan input daripada anotasi manusia atau ciptaan LLM lain, di mana model menemui pengetahuan dunia sebenar tambahan dan menyepadukannya
 Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Di barisan hadapan teknologi perisian, kumpulan UIUC Zhang Lingming, bersama penyelidik dari organisasi BigCode, baru-baru ini mengumumkan model kod besar StarCoder2-15B-Instruct. Pencapaian inovatif ini mencapai kejayaan ketara dalam tugas penjanaan kod, berjaya mengatasi CodeLlama-70B-Instruct dan mencapai bahagian atas senarai prestasi penjanaan kod. Keunikan StarCoder2-15B-Instruct terletak pada strategi penjajaran diri yang tulen Keseluruhan proses latihan adalah terbuka, telus, dan sepenuhnya autonomi dan boleh dikawal. Model ini menjana beribu-ribu arahan melalui StarCoder2-15B sebagai tindak balas kepada penalaan halus model asas StarCoder-15B tanpa bergantung pada anotasi manual yang mahal.
 Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) set data memainkan peranan penting dalam mempromosikan penyelidikan pemprosesan bahasa semula jadi (NLP). Set data QA berkualiti tinggi bukan sahaja boleh digunakan untuk memperhalusi model, tetapi juga menilai dengan berkesan keupayaan model bahasa besar (LLM), terutamanya keupayaan untuk memahami dan menaakul tentang pengetahuan saintifik. Walaupun pada masa ini terdapat banyak set data QA saintifik yang meliputi bidang perubatan, kimia, biologi dan bidang lain, set data ini masih mempunyai beberapa kekurangan. Pertama, borang data adalah agak mudah, kebanyakannya adalah soalan aneka pilihan. Ia mudah dinilai, tetapi mengehadkan julat pemilihan jawapan model dan tidak dapat menguji sepenuhnya keupayaan model untuk menjawab soalan saintifik. Sebaliknya, Soal Jawab terbuka
 Yolov10: Penjelasan terperinci, penggunaan dan aplikasi semuanya di satu tempat!
Jun 07, 2024 pm 12:05 PM
Yolov10: Penjelasan terperinci, penggunaan dan aplikasi semuanya di satu tempat!
Jun 07, 2024 pm 12:05 PM
1. Pengenalan Sejak beberapa tahun kebelakangan ini, YOLO telah menjadi paradigma dominan dalam bidang pengesanan objek masa nyata kerana keseimbangannya yang berkesan antara kos pengiraan dan prestasi pengesanan. Penyelidik telah meneroka reka bentuk seni bina YOLO, matlamat pengoptimuman, strategi pengembangan data, dsb., dan telah mencapai kemajuan yang ketara. Pada masa yang sama, bergantung pada penindasan bukan maksimum (NMS) untuk pemprosesan pasca menghalang penggunaan YOLO dari hujung ke hujung dan memberi kesan buruk kepada kependaman inferens. Dalam YOLO, reka bentuk pelbagai komponen tidak mempunyai pemeriksaan yang komprehensif dan teliti, mengakibatkan lebihan pengiraan yang ketara dan mengehadkan keupayaan model. Ia menawarkan kecekapan suboptimum, dan potensi yang agak besar untuk peningkatan prestasi. Dalam kerja ini, matlamatnya adalah untuk meningkatkan lagi sempadan kecekapan prestasi YOLO daripada kedua-dua pasca pemprosesan dan seni bina model. sampai habis
 Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama
Jul 17, 2024 pm 06:37 PM
Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama
Jul 17, 2024 pm 06:37 PM
Editor |. KX Dalam bidang penyelidikan dan pembangunan ubat, meramalkan pertalian pengikatan protein dan ligan dengan tepat dan berkesan adalah penting untuk pemeriksaan dan pengoptimuman ubat. Walau bagaimanapun, kajian semasa tidak mengambil kira peranan penting maklumat permukaan molekul dalam interaksi protein-ligan. Berdasarkan ini, penyelidik dari Universiti Xiamen mencadangkan rangka kerja pengekstrakan ciri berbilang mod (MFE) novel, yang buat pertama kalinya menggabungkan maklumat mengenai permukaan protein, struktur dan jujukan 3D, dan menggunakan mekanisme perhatian silang untuk membandingkan ciri modaliti yang berbeza penjajaran. Keputusan eksperimen menunjukkan bahawa kaedah ini mencapai prestasi terkini dalam meramalkan pertalian mengikat protein-ligan. Tambahan pula, kajian ablasi menunjukkan keberkesanan dan keperluan maklumat permukaan protein dan penjajaran ciri multimodal dalam rangka kerja ini. Penyelidikan berkaitan bermula dengan "S
 Meletakkan pasaran seperti AI, GlobalFoundries memperoleh teknologi gallium nitrida Tagore Technology dan pasukan berkaitan
Jul 15, 2024 pm 12:21 PM
Meletakkan pasaran seperti AI, GlobalFoundries memperoleh teknologi gallium nitrida Tagore Technology dan pasukan berkaitan
Jul 15, 2024 pm 12:21 PM
Menurut berita dari laman web ini pada 5 Julai, GlobalFoundries mengeluarkan kenyataan akhbar pada 1 Julai tahun ini, mengumumkan pemerolehan teknologi power gallium nitride (GaN) Tagore Technology dan portfolio harta intelek, dengan harapan dapat mengembangkan bahagian pasarannya dalam kereta dan Internet of Things dan kawasan aplikasi pusat data kecerdasan buatan untuk meneroka kecekapan yang lebih tinggi dan prestasi yang lebih baik. Memandangkan teknologi seperti AI generatif terus berkembang dalam dunia digital, galium nitrida (GaN) telah menjadi penyelesaian utama untuk pengurusan kuasa yang mampan dan cekap, terutamanya dalam pusat data. Laman web ini memetik pengumuman rasmi bahawa semasa pengambilalihan ini, pasukan kejuruteraan Tagore Technology akan menyertai GLOBALFOUNDRIES untuk membangunkan lagi teknologi gallium nitride. G
