

Penterjemah |. Li Rui
Pengulas |. Baru-baru ini, ramai orang telah menemui watak kejam dalam kalangan rakan mereka yang disayangi dan digeruni, sehinggakan StackOverflow terpaksa mengeluarkannya dari rak dengan tergesa-gesa.
Baru-baru ini, OpenAI mengeluarkan sembang AI ChatGPT dalam masa beberapa hari sahaja, bilangan penggunanya mencecah satu juta, malah pelayan itu terlalu sesak oleh pengguna berdaftar.
Bagaimana artifak ini, yang netizen mengagumi "di luar carian Google", melakukannya? Adakah ia boleh dipercayai?
1. Ulasan acara
Seperti kebanyakan keluaran model bahasa besar (LLM), keluaran ChatGPT telah mencetuskan beberapa kontroversi. Hanya dalam beberapa jam selepas dikeluarkan, model bahasa baharu itu telah menimbulkan kekecohan di Twitter, dengan pengguna memuat naik tangkapan skrin pencapaian mengagumkan ChatGPT atau kegagalan besar.
Walau bagaimanapun, dari perspektif luas model bahasa yang besar, ChatGPT menggambarkan sejarah bidang yang singkat tetapi kaya, yang mewakili sejauh mana telah dicapai dalam beberapa tahun sahaja dan apakah persoalan asas yang masih perlu diselesaikan .
2. Impian pembelajaran tanpa pengawasan
Ini telah berubah dengan kemunculan seni bina Transformer, komponen utama model bahasa yang besar. Model pengubah boleh dilatih menggunakan korpora besar teks tidak berlabel. Mereka menutup bahagian teks secara rawak dan cuba meramal bahagian yang hilang. Dengan berulang kali melakukan operasi ini, Transformer melaraskan parameternya untuk mewakili hubungan antara perkataan yang berbeza dalam urutan besar.
Ini telah terbukti sebagai strategi yang sangat berkesan dan berskala. Korpora latihan yang sangat besar boleh dikumpulkan tanpa memerlukan pelabelan manusia, membolehkan penciptaan dan latihan model Transformer yang semakin besar. Penyelidikan dan eksperimen menunjukkan bahawa apabila model Transformer dan Model Bahasa Besar (LLM) meningkat dalam saiz, model tersebut boleh menjana urutan teks koheren yang lebih panjang. Model Bahasa Besar (LLM) juga menunjukkan keupayaan luar jangka berskala besar.
3. Pembelajaran di bawah seliaan regresi?
Dengan meningkatkan saiz model dan korpus latihannya, saintis telah dapat mengurangkan kekerapan ralat ketara dalam model bahasa yang besar. Tetapi masalah asas tidak hilang, malah model bahasa besar (LLM) terbesar boleh membuat kesilapan bodoh dengan dorongan yang sangat sedikit.
Jika model bahasa besar (LLM) hanya digunakan dalam makmal penyelidikan saintifik untuk menjejak prestasi pada penanda aras, ini mungkin bukan masalah besar. Walau bagaimanapun, apabila minat menggunakan model bahasa besar (LLM) dalam aplikasi dunia nyata semakin meningkat, ia menjadi lebih penting untuk menangani isu ini dan isu lain. Jurutera mesti memastikan bahawa model pembelajaran mesin mereka kekal teguh dalam keadaan yang berbeza-beza dan memenuhi keperluan dan keperluan pengguna.
Untuk menyelesaikan masalah ini, OpenAI menggunakan pembelajaran tetulang daripada teknologi maklum balas manusia (RLHF), yang sebelum ini dibangunkan untuk mengoptimumkan model pembelajaran tetulang. Daripada membiarkan model pembelajaran pengukuhan meneroka secara rawak persekitaran dan tingkah lakunya, Pembelajaran Pengukuhan dengan Maklum Balas Manusia (RLHF) menggunakan maklum balas sekali-sekala daripada penyelia manusia untuk membimbing ejen ke arah yang betul. Faedah Pembelajaran Pengukuhan dengan Maklum Balas Manusia (RLHF) ialah ia menambah baik latihan agen pembelajaran pengukuhan dengan maklum balas manusia yang minimum.
OpenAI kemudiannya menggunakan Pembelajaran Pengukuhan dengan Maklum Balas Manusia (RLHF) kepada InstructGPT, sebuah keluarga model bahasa besar (LLM) yang direka untuk lebih memahami dan bertindak balas terhadap arahan dalam gesaan pengguna. InstructGPT ialah model GPT-3 yang diperhalusi berdasarkan maklum balas manusia.
Ini jelas satu pertukaran. Anotasi manusia boleh menjadi halangan dalam proses latihan berskala. Tetapi dengan mencari keseimbangan yang betul antara pembelajaran tanpa seliaan dan seliaan, OpenAI mampu mencapai faedah penting, termasuk tindak balas yang lebih baik terhadap arahan, pengurangan output berbahaya dan pengoptimuman sumber. Menurut hasil penyelidikan OpenAI, 1.3 bilion parameter InstructionGPT secara amnya mengatasi 175 bilion parameter model GPT-3 dalam arahan berikut.
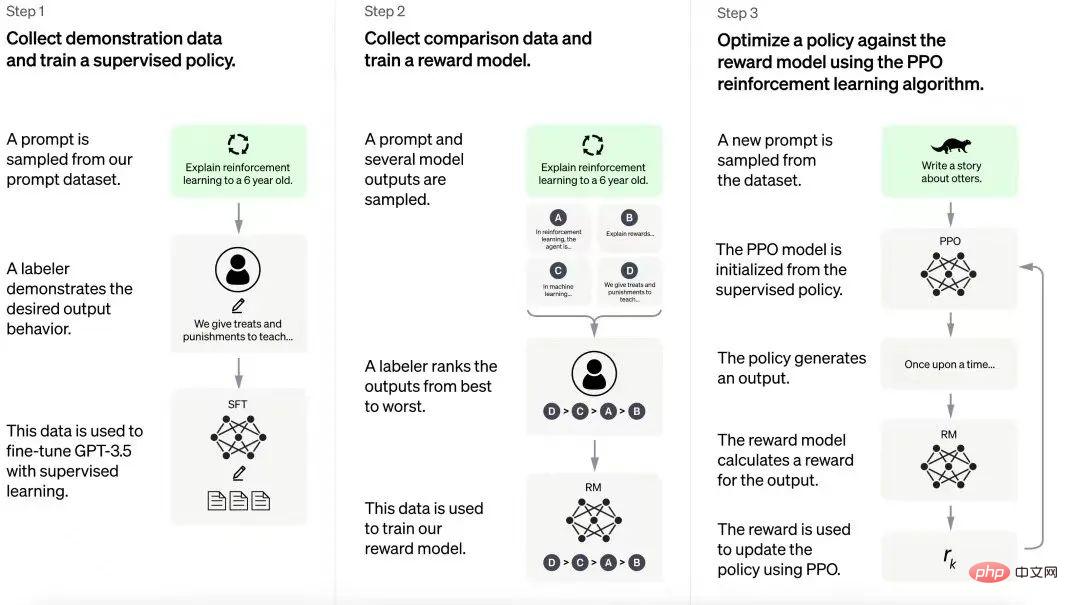 Proses latihan ChatGPT
Proses latihan ChatGPT
ChatGPT dibina berdasarkan pengalaman yang diperoleh daripada model InstructGPT. Anotasi manusia mencipta satu set contoh perbualan yang termasuk gesaan pengguna dan respons model. Data ini digunakan untuk memperhalusi model GPT-3.5 yang ChatGPT dibina. Dalam langkah seterusnya, model yang diperhalusi diberikan gesaan baharu dan diberikan beberapa respons. Anotasi menilai respons ini. Data yang dijana daripada interaksi ini kemudiannya digunakan untuk melatih model ganjaran, yang membantu memperhalusi lagi model bahasa besar (LLM) dalam saluran paip pembelajaran pengukuhan.
OpenAI tidak mendedahkan butiran penuh proses pembelajaran pengukuhan, tetapi orang ramai ingin tahu "kos tidak boleh skala" proses ini, iaitu, berapa banyak tenaga kerja yang diperlukan.
Hasil ChatGPT sangat mengagumkan. Model ini telah menyelesaikan pelbagai tugas, termasuk memberikan maklum balas tentang kod, menulis puisi, menerangkan konsep teknikal dalam nada yang berbeza, dan menjana gesaan untuk model kecerdasan buatan generatif.
Walau bagaimanapun, model ini juga terdedah kepada ralat yang serupa dengan yang dibuat oleh model bahasa besar (LLM), seperti memetik kertas dan buku yang tidak wujud, salah faham fizik intuitif dan gagal dalam komposisi.
Orang ramai tidak terkejut dengan kegagalan ini. ChatGPT tidak berfungsi apa-apa dan ia sepatutnya mengalami masalah yang sama seperti sebelumnya. Walau bagaimanapun, di mana dan sejauh mana ia boleh dipercayai dalam aplikasi dunia nyata Jelas sekali terdapat sesuatu yang berharga di sini, seperti yang boleh dilihat dalam Codex dan GitHubCopilot bahawa Model Bahasa Besar (LLM) boleh Digunakan dengan sangat berkesan.
Apa yang menentukan sama ada ChatGPT berguna di sini ialah jenis alatan dan perlindungan yang dilaksanakan dengannya. Contohnya, ChatGPT boleh menjadi platform yang sangat baik untuk mencipta chatbot untuk perniagaan, seperti rakan digital untuk pengekodan dan reka bentuk grafik. Pertama, jika ia mengikut contoh InstructGPT, anda sepatutnya boleh mendapatkan prestasi model kompleks dengan parameter yang lebih sedikit, yang akan menjadikannya kos efektif. Tambahan pula, jika OpenAI menyediakan alatan yang membolehkan perusahaan melaksanakan penalaan halus pembelajaran pengukuhan mereka sendiri dengan maklum balas manusia (RLHF), ia boleh dioptimumkan lagi untuk aplikasi tertentu, yang dalam kebanyakan kes akan lebih berguna daripada chatbots tentang apa sahaja. Akhir sekali, jika pembangun aplikasi diberi alat untuk menyepadukan ChatGPT dengan senario aplikasi dan memetakan input dan outputnya kepada peristiwa dan tindakan aplikasi tertentu, mereka akan dapat menetapkan pagar yang betul untuk menghalang model daripada beroperasi yang tidak stabil.
Pada asasnya, OpenAI mencipta alat kecerdasan buatan yang berkuasa, tetapi dengan kelemahan yang jelas. Ia kini memerlukan penciptaan ekosistem alat pembangunan yang betul untuk memastikan pasukan produk dapat memanfaatkan kuasa ChatGPT. GPT-3 membuka jalan untuk banyak aplikasi yang tidak dapat diramalkan, jadi ia akan menjadi menarik untuk mengetahui apa yang tersedia oleh ChatGPT.
Pautan asal: https://bdtechtalks.com/2022/12/05/openai-chatgpt/
Atas ialah kandungan terperinci Pengguna melebihi satu juta dalam masa 5 hari, apakah misteri di sebalik ChatGPT?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Pendaftaran ChatGPT
Pendaftaran ChatGPT
 Ensiklopedia ChatGPT percuma domestik
Ensiklopedia ChatGPT percuma domestik
 Bagaimana untuk memasang chatgpt pada telefon bimbit
Bagaimana untuk memasang chatgpt pada telefon bimbit
 Bolehkah chatgpt digunakan di China?
Bolehkah chatgpt digunakan di China?
 Penggunaan fungsi keluar dalam bahasa c
Penggunaan fungsi keluar dalam bahasa c
 python mengkonfigurasi pembolehubah persekitaran
python mengkonfigurasi pembolehubah persekitaran
 Bagaimana untuk menyegarkan cache dns
Bagaimana untuk menyegarkan cache dns
 Cara menggunakan bingkai bingkai
Cara menggunakan bingkai bingkai
 Bagaimana untuk membuka fail nrg
Bagaimana untuk membuka fail nrg








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



