
 Peranti teknologi
AI
Pokok evolusi model bahasa besar, ini adalah panduan 'makan' yang sangat terperinci untuk ChatGPT
Peranti teknologi
AI
Pokok evolusi model bahasa besar, ini adalah panduan 'makan' yang sangat terperinci untuk ChatGPT
Pokok evolusi model bahasa besar, ini adalah panduan 'makan' yang sangat terperinci untuk ChatGPT

Dalam proses penerokaan sebenar, pengamal mungkin bergelut untuk mencari model AI yang sesuai untuk aplikasi mereka: Patutkah mereka memilih LLM atau memperhalusi model? Jika menggunakan LLM, yang manakah harus saya pilih?
Baru-baru ini, sarjana dari Amazon, Texas A&M University, Rice University dan institusi lain telah membincangkan proses pembangunan model bahasa seperti ChatGPT, dan artikel mereka juga telah dipuji oleh Yann LeCun Retweet .
Kertas: https://arxiv.org/abs/2304.13712
Sumber berkaitan: https://github.com/Mooler0410/LLMsPracticalGuide

Artikel ini akan bermula dari perspektif aplikasi praktikal dan membincangkan tugasan yang sesuai untuk LLM dan isu praktikal seperti model, data dan tugasan yang perlu dipertimbangkan semasa memilih model.
1 Pengenalan
Dalam beberapa tahun kebelakangan ini, perkembangan pesat model bahasa besar (LLM) telah mencetuskan revolusi dalam bidang pemprosesan bahasa semula jadi (NLP). Model ini sangat berkuasa dan berjanji untuk menyelesaikan pelbagai jenis tugasan NLP – daripada pemahaman bahasa semula jadi (NLU) kepada tugas penjanaan, malah membuka jalan kepada kecerdasan am buatan (AGI). Walau bagaimanapun, untuk menggunakan model ini dengan berkesan dan cekap, kita perlu mempunyai pemahaman praktikal tentang keupayaan dan batasannya, serta pemahaman tentang data dan tugas yang terlibat dalam NLP.
Kertas kerja ini memfokuskan kepada pelbagai aspek aplikasi praktikal LLM dalam tugasan NLP hiliran untuk memberi panduan kepada pengamal dan pengguna akhir. Matlamat panduan ini adalah untuk memberi pembaca nasihat praktikal dan berguna sama ada untuk menggunakan LLM untuk tugasan tertentu dan cara memilih LLM yang paling sesuai - ini akan mengambil kira banyak faktor, seperti saiz model, keperluan pengiraan, dan domain tertentu. Sama ada terdapat model pra-latihan, dsb. Artikel ini juga memperkenalkan dan menerangkan LLM daripada perspektif aplikasi praktikal, yang boleh membantu pengamal dan pengguna akhir berjaya memanfaatkan kuasa LLM untuk menyelesaikan tugas NLP mereka sendiri.
Struktur artikel ini ialah: Artikel ini mula-mula akan memperkenalkan secara ringkas LLM, di mana seni bina gaya GPT dan gaya BERT yang paling penting akan dibincangkan. Kemudian kami akan memberikan pengenalan yang mendalam kepada faktor utama yang mempengaruhi prestasi model dari segi data, termasuk data pra-latihan, data latihan/penalaan data dan data ujian. Dalam bahagian terakhir dan paling penting, artikel ini akan menyelidiki pelbagai tugasan NLP khusus, memperkenalkan sama ada LLM sesuai untuk tugasan intensif pengetahuan, tugasan NLU tradisional, dan tugas penjanaan Selain itu, ia juga akan menerangkan keupayaan dan cabaran baharu itu model ini terus memperoleh senario aplikasi dunia sebenar. Kami menyediakan contoh terperinci untuk menyerlahkan kegunaan dan batasan LLM dalam amalan.
Untuk menganalisis keupayaan model bahasa yang besar, artikel ini akan membandingkannya dengan model yang diperhalusi. Kami belum mempunyai piawaian yang diterima secara meluas untuk definisi LLM dan model yang diperhalusi. Untuk membuat perbezaan yang praktikal dan berkesan, takrifan yang diberikan dalam artikel ini adalah seperti berikut: LLM merujuk kepada model bahasa besar yang dipralatih pada set data berskala besar dan tidak melaraskan data untuk tugasan tertentu; model biasanya lebih kecil, dan ia telah dilatih terlebih dahulu Kemudian, penalaan halus selanjutnya akan dilakukan pada set data khusus tugasan yang lebih kecil untuk mengoptimumkan prestasi mereka pada tugasan ini.
Artikel ini meringkaskan panduan praktikal tentang menggunakan LLM dalam:
- Pemahaman bahasa semula jadi. Apabila data sebenar tidak berada dalam julat pengedaran data latihan atau terdapat sedikit data latihan, keupayaan generalisasi LLM yang sangat baik boleh digunakan.
- Penjanaan bahasa semula jadi. Gunakan kuasa LLM untuk mencipta teks yang koheren, kontekstual dan berkualiti tinggi untuk pelbagai aplikasi.
- Tugas berintensif pengetahuan. Manfaatkan pengetahuan luas yang disimpan dalam LLM untuk mengendalikan tugas yang memerlukan kepakaran khusus atau pengetahuan dunia umum.
- Keupayaan menaakul. Memahami dan menggunakan keupayaan penaakulan LLM untuk meningkatkan pembuatan keputusan dan penyelesaian masalah dalam pelbagai situasi.
2 Panduan Praktikal untuk Model
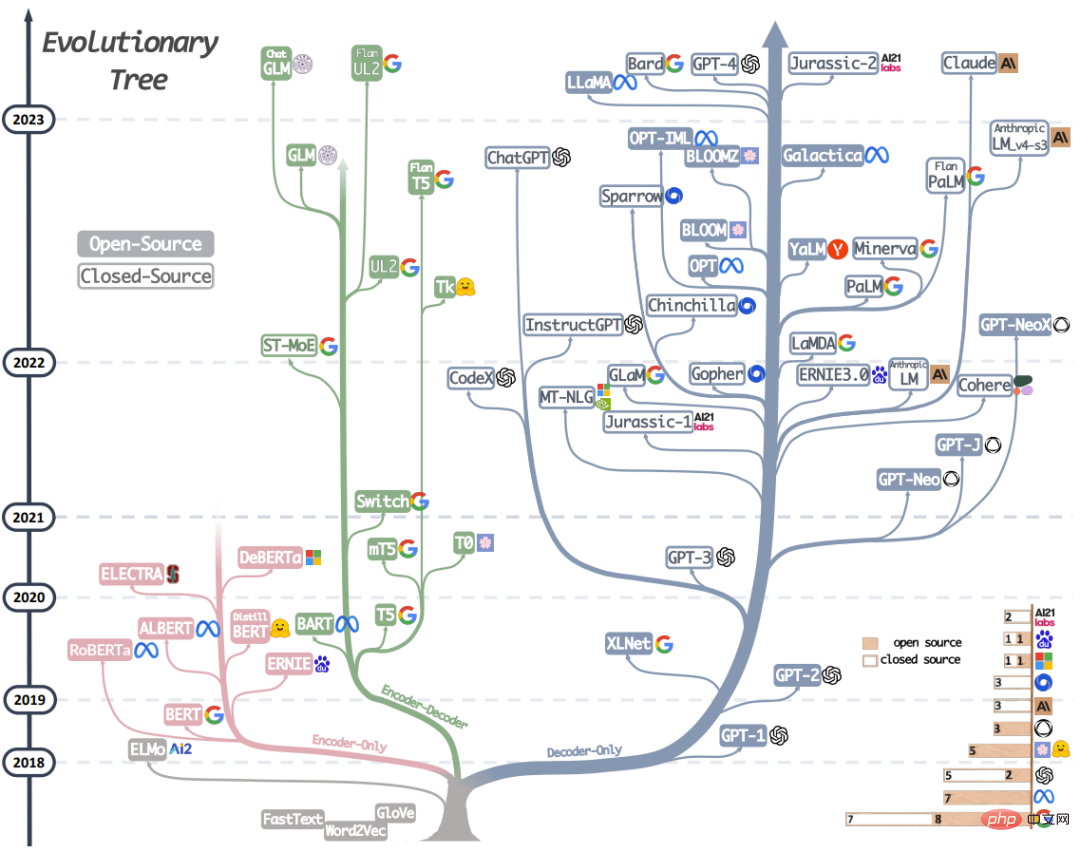
Rajah 1 : Pokok evolusi LLM moden ini mengesan perkembangan model bahasa dalam beberapa tahun kebelakangan ini, menonjolkan beberapa model yang paling terkenal. Model pada cawangan yang sama lebih berkait rapat. Model berasaskan pengubah tidak diwakili dalam warna kelabu: model penyahkod sahaja ialah cawangan biru, model pengekod sahaja ialah cawangan merah jambu, dan model penyahkod pengekod ialah cawangan hijau. Kedudukan menegak model pada garis masa menunjukkan apabila ia dikeluarkan. Petak pepejal mewakili model sumber terbuka, dan petak kosong mewakili model sumber tertutup. Carta bar bertindan di penjuru kanan sebelah bawah merujuk kepada bilangan model untuk setiap syarikat dan institusi.
Bahagian ini akan memperkenalkan secara ringkas LLM berprestasi terbaik semasa. Model ini mempunyai strategi latihan, seni bina model dan kes penggunaan yang berbeza. Untuk memahami gambaran keseluruhan LLM dengan lebih jelas, kita boleh membahagikannya kepada dua kategori yang luas: model bahasa pengekod-penyahkod atau pengekod sahaja dan model bahasa penyahkod sahaja. Rajah 1 menunjukkan evolusi model bahasa secara terperinci. Berdasarkan pokok evolusi ini, kita boleh melihat beberapa kesimpulan yang menarik:
a) Model penyahkod sahaja secara beransur-ansur menjadi model dominan dalam pembangunan LLM. Pada peringkat awal pembangunan LLM, model penyahkod sahaja tidak begitu popular seperti model pengekod sahaja dan penyahkod pengekod. Tetapi selepas 2021, kemunculan GPT-3 mengubah gambaran industri, dan hanya model penyahkod mengalami perkembangan yang meletup. Pada masa yang sama, BERT juga membawa pertumbuhan letupan awal kepada model pengekod sahaja, tetapi selepas itu, model pengekod sahaja beransur-ansur hilang dari pandangan.
b) OpenAI terus mengekalkan kedudukan utamanya dalam hala tuju LLM, sekarang dan mungkin pada masa hadapan. Syarikat dan institusi lain sedang mengejar untuk membangunkan model yang setanding dengan GPT-3 dan GPT-4. Kedudukan utama OpenAI mungkin dikaitkan dengan pelaburan berterusannya dalam teknologi, walaupun teknologi itu tidak diiktiraf secara meluas pada awalnya.
c) Meta telah membuat sumbangan cemerlang dalam LLM sumber terbuka dan mempromosikan penyelidikan LLM. Meta menonjol sebagai salah satu syarikat komersil yang paling murah hati apabila melibatkan sumbangannya kepada komuniti sumber terbuka, terutamanya yang berkaitan dengan LLM, kerana ia bersumber terbuka semua LLM yang dibangunkannya.
d) Pembangunan LLM mempunyai trend sumber tertutup. Pada peringkat awal pembangunan LLM (sebelum 2020), sebahagian besar model adalah sumber terbuka. Walau bagaimanapun, dengan pelancaran GPT-3, syarikat semakin memilih untuk menutup sumber model mereka, seperti PaLM, LaMDA dan GPT-4. Oleh itu, semakin sukar bagi penyelidik akademik untuk menjalankan eksperimen latihan LLM. Ini mempunyai akibat bahawa penyelidikan berasaskan API mungkin menjadi pendekatan yang dominan dalam akademik.
e) Model pengekod-penyahkod masih mempunyai prospek pembangunan, kerana syarikat dan institusi masih aktif meneroka jenis seni bina ini, dan kebanyakan model adalah sumber terbuka. Google telah membuat sumbangan besar kepada penyahkod pengekod sumber terbuka. Walau bagaimanapun, disebabkan fleksibiliti dan kepelbagaian model penyahkod sahaja, peluang Google untuk berjaya kelihatan lebih tipis dengan meneruskan ke arah ini.
Jadual 1 meringkaskan secara ringkas ciri-ciri pelbagai LLM perwakilan.
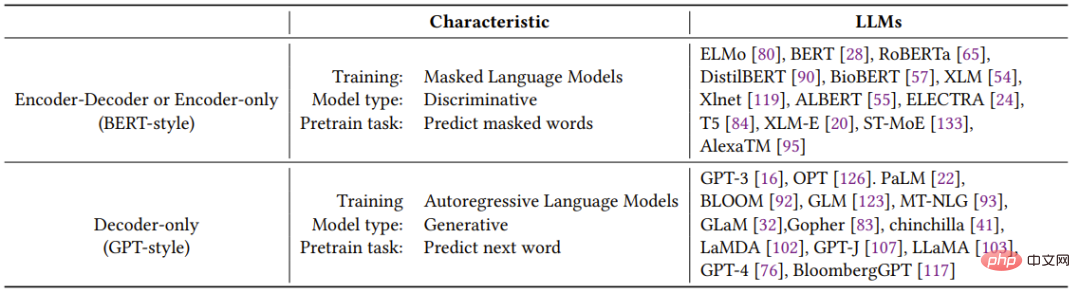
Jadual 1: Ciri-ciri model bahasa besar
2.1 Model bahasa gaya BERT: pengekod - penyahkod atau hanya pengekod
Pembangunan pembelajaran bahasa semula jadi tanpa pengawasan telah mencapai kemajuan besar sejak kebelakangan ini kerana data bahasa semula jadi mudah diperoleh dan paradigma latihan tanpa pengawasan boleh digunakan untuk menggunakan set data yang sangat besar dengan lebih baik. Pendekatan biasa adalah untuk meramalkan perkataan tersumbat dalam ayat berdasarkan konteks. Paradigma latihan ini dipanggil Model Bahasa Bertopeng. Kaedah latihan ini membolehkan model memperoleh pemahaman yang lebih mendalam tentang hubungan antara perkataan dan konteksnya. Model ini dilatih pada korpora teks besar, menggunakan teknik seperti seni bina Transformer, dan telah mencapai prestasi terkini pada banyak tugas NLP, seperti analisis sentimen dan pengiktirafan entiti yang dinamakan. Model bahasa bertopeng yang terkenal termasuk BERT, RoBERTa dan T5. Disebabkan prestasinya yang berjaya dalam pelbagai tugas, model bahasa bertopeng telah menjadi alat penting dalam bidang pemprosesan bahasa semula jadi.
2.2 Model bahasa gaya GPT: penyahkod sahaja
Walaupun seni bina model bahasa umumnya bersifat agnostik tugas , Walau bagaimanapun, kaedah ini memerlukan penalaan halus berdasarkan set data untuk tugas hiliran tertentu. Penyelidik telah mendapati bahawa meningkatkan saiz model bahasa boleh meningkatkan prestasinya dengan ketara dengan sedikit atau sifar sampel. Model yang paling berjaya dalam meningkatkan prestasi dengan sampel yang sedikit dan sifar ialah model bahasa autoregresif, yang dilatih untuk menjana perkataan seterusnya berdasarkan perkataan sebelumnya dalam urutan tertentu. Model ini telah digunakan secara meluas dalam tugas hiliran seperti penjanaan teks dan menjawab soalan. Model bahasa autoregresif termasuk GPT-3, OPT, PaLM dan BLOOM. GPT-3 revolusioner menunjukkan buat kali pertama bahawa pembelajaran melalui pembayang dan konteks boleh memberikan hasil yang munasabah dengan sedikit/sifar sampel, dan dengan itu menunjukkan keunggulan model bahasa autoregresif.
Terdapat juga model yang dioptimumkan untuk tugasan tertentu, seperti CodeX untuk penjanaan kod dan BloombergGPT untuk bidang kewangan. Satu kejayaan besar baru-baru ini ialah ChatGPT, model GPT-3 yang dioptimumkan untuk tugas perbualan yang menghasilkan perbualan yang lebih interaktif, koheren dan kontekstual untuk pelbagai aplikasi dunia sebenar.
3 Panduan Praktikal untuk Data
Bahagian ini akan memperkenalkan peranan kritikal data dalam memilih model yang betul untuk tugas hiliran. Kesan data terhadap keberkesanan model bermula dalam fasa pra-latihan dan berterusan melalui fasa latihan dan inferens.
Key Point 1
(1) Apabila tugas hiliran akan menggunakan data di luar pengedaran, seperti menggunakan sampel lawan atau perubahan domain data Pada kali ini, keupayaan generalisasi LLM adalah lebih baik daripada model yang diperhalusi.
(2) Apabila terdapat data berlabel terhad, LLM adalah lebih baik daripada model yang diperhalusi apabila terdapat data berlabel yang banyak, kedua-duanya adalah pilihan yang munasabah, bergantung pada keperluan tugas tertentu .
(3) Adalah disyorkan untuk memilih model yang domain datanya digunakan untuk pra-latihan adalah serupa dengan domain data tugas hiliran.
4 Garis Panduan Praktikal untuk Tugasan NLP
Bahagian ini akan membincangkan secara terperinci sama ada LLM berguna dalam pelbagai tugasan NLP hiliran dan keupayaan model yang sepadan. Rajah 2 ialah rajah aliran keputusan yang meringkaskan semua perbincangan. Apabila berhadapan dengan tugas tertentu, keputusan pantas boleh dibuat berdasarkan proses ini.
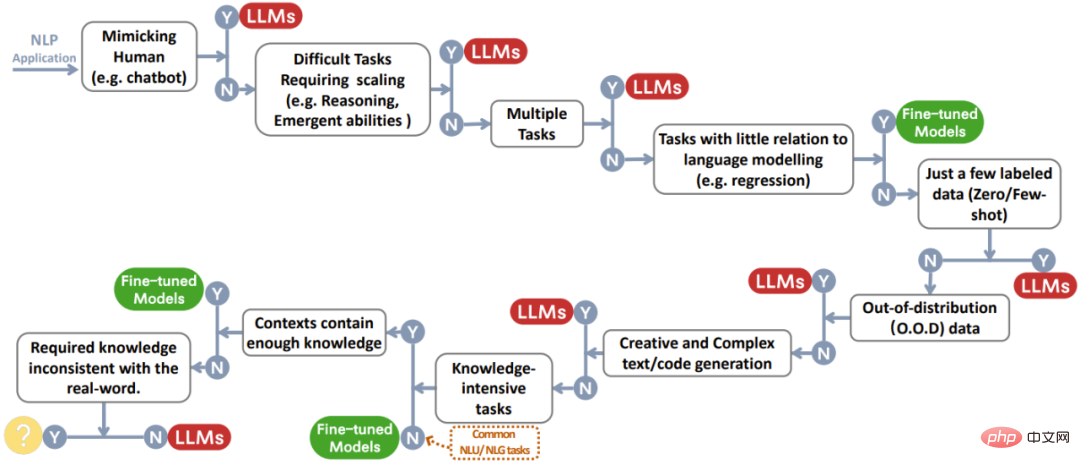
Rajah 2: Proses membuat keputusan pengguna apabila memilih LLM atau model yang diperhalusi untuk aplikasi NLP. Carta aliran keputusan ini membantu pengguna menilai sama ada tugasan NLP hiliran di tangan memenuhi kriteria tertentu dan menentukan sama ada LLM atau model yang diperhalusi paling sesuai untuk aplikasi mereka berdasarkan hasil penilaian. Dalam proses membuat keputusan dalam rajah, Y menunjukkan bahawa syarat dipenuhi, dan N menunjukkan bahawa syarat tidak dipenuhi. Bulatan kuning di sebelah Y untuk keadaan terakhir menunjukkan bahawa pada masa ini tiada model yang sesuai untuk jenis aplikasi ini.
4.1 Tugas NLU Tradisional
Tugas NLU Tradisional Mereka ialah beberapa tugas asas dalam bidang NLP, termasuk klasifikasi teks, pengecaman entiti bernama (NER), ramalan entailment, dsb. Kebanyakan tugas ini boleh digunakan sebagai langkah perantaraan dalam sistem AI yang lebih besar, seperti menggunakan NER untuk pembinaan graf pengetahuan.
Tidak terpakai untuk LLM: Untuk kebanyakan tugas pemahaman bahasa semula jadi, seperti dalam GLUE dan SuperGLUE, jika tugasan itu sudah mempunyai banyak data beranotasi baik dan hanya sedikit data dalam set ujian berada di luar pengedaran , maka prestasi model yang diperhalusi masih lebih baik. Jurang antara model kecil yang diperhalusi dan LLM juga berbeza apabila tugas dan set data berbeza-beza.
Sesuai untuk LLM: Walau bagaimanapun, terdapat beberapa tugasan NLU yang lebih sesuai untuk dikendalikan oleh LLM. Dua tugas perwakilan ialah masalah klasifikasi teks kompleks dan penaakulan bahasa semula jadi yang bertentangan.
Titik 2
Untuk tugasan pemahaman bahasa semula jadi tradisional, model penalaan halus biasanya merupakan pilihan yang lebih baik daripada LLM, tetapi jika tugas itu Kuat keupayaan generalisasi diperlukan, maka LLM boleh membantu.
4.2 Tugas Penjanaan
Matlamat penjanaan bahasa semula jadi adalah untuk mencipta urutan Simbol yang koheren, bermakna dan kontekstual, yang secara kasarnya merangkumi dua kategori tugasan yang luas. Kategori tugasan pertama memfokuskan pada menukar teks input kepada jujukan simbol baharu Contohnya termasuk ringkasan perenggan dan terjemahan mesin. Kategori tugasan kedua ialah "generasi terbuka", di mana matlamatnya adalah untuk menjana teks atau simbol dari awal supaya ia sepadan dengan penerangan input dengan tepat, seperti menulis e-mel, menulis artikel baharu, mencipta cerita fiksyen dan menulis kod.
Berlaku untuk LLM: Tugas penjanaan memerlukan model untuk memahami kandungan atau keperluan input sepenuhnya dan juga memerlukan tahap kreativiti tertentu. Inilah yang LLM cemerlang.
LLM tidak berkenaan: Pada kebanyakan tugas terjemahan dengan sumber yang banyak dan tugas terjemahan dengan sedikit sumber, model yang diperhalusi berprestasi lebih baik, seperti DeltaLM+Zcode. Untuk terjemahan mesin dengan sumber yang kaya, model yang diperhalusi sedikit mengatasi prestasi LLM. Untuk terjemahan mesin dengan sumber yang sangat sedikit, seperti terjemahan Inggeris-Kazakh, model yang diperhalusi mengatasi prestasi LLM dengan ketara.
Titik 3
Berkat keupayaan dan kreativiti penjanaan yang kukuh, LLM mempunyai kelebihan dalam kebanyakan tugas generasi.
4.3 Tugas berintensif pengetahuan
Tugas NLP berintensif pengetahuan merujuk kepada tugasan yang sangat bergantung pada pengetahuan latar belakang dan kepakaran dalam bidang khusus Kategori tugasan pengetahuan atau pengetahuan umum dunia sebenar. Tugasan ini memerlukan lebih daripada pengecaman corak atau analisis sintaksis. Mereka sangat bergantung pada ingatan dan penggunaan pengetahuan yang sesuai yang berkaitan dengan entiti, peristiwa dan akal fikiran tertentu dalam dunia sebenar kita.
Berlaku untuk LLM: Secara umumnya, jika terdapat berbilion-bilion token dan parameter latihan, jumlah pengetahuan dunia sebenar yang terkandung dalam LLM boleh jauh melebihi model yang diperhalusi.
Tidak berkenaan dengan LLM: Sesetengah tugasan lain memerlukan pengetahuan yang berbeza daripada apa yang dipelajari oleh LLM. Pengetahuan yang diperlukan bukanlah apa yang LLM pelajari tentang dunia sebenar. Dalam tugas sedemikian, LLM tidak mempunyai kelebihan yang jelas.
Key Point 4
(1) Terima kasih kepada pengetahuan dunia sebenar yang besar, LLM pandai mengendalikan tugas berintensif pengetahuan. (2) LLM akan menghadapi kesukaran apabila keperluan pengetahuan tidak sepadan dengan pengetahuan yang dipelajari atau apabila tugas hanya memerlukan pengetahuan kontekstual, model penalaan halus boleh mencapai prestasi yang sama seperti LLM.
4.4 Keupayaan untuk mengembangkan skala
Memperluas skala LLM (seperti parameter, pengiraan latihan, dsb. ) boleh sangat membantu dalam model bahasa pra-latihan. Dengan meningkatkan saiz model, keupayaan model untuk mengendalikan pelbagai tugas sering dipertingkatkan. Dicerminkan pada penunjuk tertentu, prestasi model menunjukkan hubungan undang-undang kuasa dengan saiz model. Sebagai contoh, kehilangan entropi silang yang digunakan untuk mengukur prestasi pemodelan bahasa berkurangan secara linear dengan pertumbuhan eksponen dalam saiz model, yang juga dikenali sebagai "undang-undang skala." Untuk beberapa keupayaan utama, seperti penaakulan, meningkatkan model secara beransur-ansur boleh meningkatkan keupayaan ini daripada tahap yang sangat rendah kepada tahap yang boleh digunakan, malah hampir dengan tahap manusia. Subseksyen ini akan memperkenalkan penggunaan LLM dari segi kesan skala terhadap keupayaan dan tingkah laku LLM.
LLM menggunakan kes dalam penaakulan: Penaakulan melibatkan pemahaman maklumat, membuat inferens dan membuat keputusan, dan merupakan keupayaan teras kecerdasan manusia. Untuk NLP, penaakulan adalah sangat mencabar. Banyak tugas penaakulan sedia ada boleh dibahagikan kepada dua kategori: penaakulan akal dan penaakulan aritmetik. Pembesaran model boleh meningkatkan keupayaan penaakulan aritmetik LLM. Penaakulan akal memerlukan LLM bukan sahaja mengingati pengetahuan fakta tetapi juga melakukan beberapa langkah penaakulan tentang fakta. Keupayaan penaakulan akal secara beransur-ansur bertambah baik apabila saiz model bertambah. LLM berprestasi lebih baik daripada model yang diperhalusi pada kebanyakan set data.
Kes penggunaan LLM dalam keupayaan muncul: Meningkatkan saiz model juga boleh memberikan model beberapa keupayaan yang belum pernah terjadi sebelumnya dan hebat yang melangkaui peraturan undang-undang kuasa. Kebolehan ini dipanggil "kebolehan muncul." Seperti yang ditakrifkan dalam makalah "Keupayaan Muncul Model Bahasa Besar": Keupayaan munculan LLM merujuk kepada keupayaan yang tidak dimiliki oleh model berskala kecil tetapi muncul dalam model berskala besar. (Untuk tafsiran lanjut kertas ini, sila rujuk "Karya Baru oleh Jeff Dean dan Lain-lain: Melihat Model Bahasa dari Sudut Berbeza, Tidak Dapat Menemui Jika Skalanya Tidak Cukup") Ini bermakna kita tidak boleh membuat kesimpulan dan meramalkan keupayaan ini berdasarkan peningkatan prestasi model berskala kecil; Pada beberapa tugas, apabila saiz model melebihi tahap tertentu, ia mungkin tiba-tiba mencapai prestasi cemerlang. Keupayaan yang timbul selalunya tidak dapat diramalkan dan tidak dijangka, yang boleh mengakibatkan keupayaan model untuk mengendalikan tugas yang timbul secara rawak atau tidak dijangka.
LLM tidak berkenaan dan kemunculan pemahaman: Walaupun dalam kebanyakan kes, model lebih besar dan berprestasi lebih baik, terdapat pengecualian.
Pada sesetengah tugasan, apabila skala LLM meningkat, prestasi model akan mula menurun. Ini juga dikenali sebagai Fenomena Penskalaan Songsang. Selain itu, pengkaji turut memerhati satu lagi fenomena menarik berkaitan skala iaitu Fenomena berbentuk U. Seperti namanya, fenomena ini bermakna apabila model LLM semakin besar, prestasinya pada tugas tertentu pada mulanya akan bertambah baik, kemudian mula menurun, dan kemudian bertambah baik semula.
Untuk memajukan penyelidikan dalam bidang ini, kita mesti memperoleh pemahaman yang lebih mendalam tentang keupayaan kemunculan, fenomena penskalaan balas dan fenomena berbentuk U.
Key Point 5
(1) Apabila saiz model meningkat secara eksponen, penaakulan aritmetik dan keupayaan penaakulan akal bagi LLM juga akan meningkat . (2) Apabila skala LLM meningkat, keupayaan yang muncul boleh menemui kegunaan baharu secara kebetulan, seperti keupayaan pemprosesan perkataan dan keupayaan logik. (3) Keupayaan model tidak selalu meningkat mengikut skala, dan pemahaman kita tentang hubungan antara keupayaan model dan skala bahasa yang besar masih terhad.
4.5 Pelbagai Tugasan
Untuk lebih memahami kekuatan dan kelemahan LLM, di bawah kita akan bercakap tentang yang tidak disebutkan di atas tugas-tugas lain yang terlibat.
Tidak berkenaan dengan LLM: LLM selalunya menghadapi kesukaran dalam tugasan ini jika matlamat model berbeza daripada data latihan.
Sesuai untuk LLM: LLM amat sesuai untuk tugasan tertentu. Untuk memberi beberapa contoh, LLM sangat pandai meniru manusia juga boleh digunakan untuk menilai kualiti tugasan NLG tertentu seperti rumusan dan penterjemahan Beberapa keupayaan LLM juga boleh membawa manfaat selain daripada peningkatan prestasi, seperti kebolehtafsiran.
Key Point 6
(1) Untuk tugasan yang jauh daripada sasaran dan data pra-latihan LLM, model penalaan halus dan domain- model tertentu masih Ada tempat untuknya. (2) LLM pandai meniru manusia, anotasi data dan penjanaan. Ia juga boleh digunakan untuk penilaian kualiti tugas NLP dan mempunyai faedah seperti kebolehtafsiran.
4.6 "tugas" dunia nyata
Bahagian ini akhirnya membincangkan penggunaan LLM dan model penalaan halus dalam aplikasi "tugas" ” dunia sebenar pada. Istilah "tugas" digunakan secara longgar di sini kerana, tidak seperti tetapan akademik, tetapan dunia sebenar sering kekurangan definisi yang terbentuk dengan baik. Banyak keperluan untuk model tidak boleh dianggap sebagai tugas NLP. Cabaran dunia sebenar yang dihadapi oleh model datang daripada tiga aspek berikut:
- Input bising/tidak berstruktur. Input dunia sebenar datang daripada orang dunia sebenar, yang kebanyakannya bukan pakar. Mereka tidak memahami cara berinteraksi dengan model dengan betul dan mungkin tidak dapat menggunakan teks dengan lancar. Oleh itu, data input dunia sebenar boleh menjadi kucar-kacir, dengan ralat ejaan, teks sehari-hari dan campur aduk berbilang bahasa, tidak seperti data berformat yang ditakrifkan dengan baik yang digunakan untuk pra-latihan atau penalaan halus.
- Tugas yang belum diformalkan oleh akademia. Tugasan dalam senario dunia sebenar selalunya tidak ditakrifkan dengan baik oleh ahli akademik, dan kepelbagaian itu melangkaui takrifan senario penyelidikan akademik. Pengguna sering membuat pertanyaan atau permintaan yang tidak sesuai dengan kategori yang dipratentukan, dan kadangkala satu pertanyaan merangkumi berbilang tugas.
- Ikuti arahan pengguna. Permintaan pengguna mungkin mengandungi berbilang niat tersirat (seperti keperluan khusus untuk format output), atau mungkin tidak jelas perkara yang pengguna jangkakan untuk meramalkan tanpa soalan susulan. Model perlu memahami niat pengguna dan memberikan output yang konsisten dengan niat tersebut.
Pada asasnya, teka-teki dunia sebenar daripada permintaan pengguna ini disebabkan oleh penyelewengan daripada pengedaran mana-mana set data NLP yang direka untuk tugas tertentu. Set data NLP awam tidak menggambarkan cara model ini digunakan.
Titik 7
Berbanding dengan penalaan halus model, LLM lebih sesuai untuk memproses senario dunia sebenar. Walau bagaimanapun, menilai keberkesanan model dalam dunia sebenar masih menjadi persoalan terbuka.
5 Aspek lain
Walaupun LLM sesuai untuk pelbagai tugas hiliran, terdapat faktor lain yang perlu dipertimbangkan, seperti kecekapan dan kebolehpercayaan. Isu yang terlibat dalam kecekapan termasuk kos latihan LLM, kependaman inferens dan strategi penalaan untuk penggunaan parameter yang cekap. Dari segi kebolehpercayaan, kekukuhan dan keupayaan penentukuran LLM, keadilan dan berat sebelah, potensi korelasi ralat dan cabaran keselamatan perlu dipertimbangkan. Perkara Utama 8(1) Jika tugas itu sensitif kos atau mempunyai keperluan kependaman yang ketat, maka model penalaan halus tempatan yang ringan harus diutamakan. Apabila menggunakan dan menghantar model anda, pertimbangkan untuk menala untuk menggunakan parameter dengan cekap. (2) Pendekatan sifar pukulan LLM menghalangnya daripada mempelajari pintasan daripada set data khusus tugasan, yang biasa digunakan untuk model yang diperhalusi. Namun begitu, LLM masih mempamerkan masalah pembelajaran pintasan tertentu. (3) Memandangkan masalah pengeluaran dan halusinasi yang berpotensi berbahaya atau berat sebelah LLM boleh membawa kepada akibat yang serius, isu keselamatan yang berkaitan dengan LLM harus mendapat perhatian yang paling besar. Kaedah seperti maklum balas manusia menjanjikan untuk mengurangkan masalah ini.
6 Ringkasan dan Cabaran Masa Depan
Panduan praktikal ini memberikan cerapan tentang LLM dan amalan terbaik untuk menggunakan LLM pada pelbagai tugasan NLP. Semoga ini akan membantu penyelidik dan pengamal memanfaatkan potensi LLM dan memacu inovasi dalam teknologi bahasa.
Sudah tentu, LLM masih mempunyai beberapa cabaran yang perlu diselesaikan:
- Nilai model pada set data dunia sebenar. Walaupun model pembelajaran mendalam sedia ada dinilai terutamanya pada set data akademik standard seperti ImageNet, set data akademik standard adalah terhad dan tidak menggambarkan prestasi model dengan tepat dalam dunia sebenar. Apabila model maju, adalah perlu untuk menilai mereka pada data yang lebih pelbagai, kompleks dan realistik yang mencerminkan keperluan sebenar. Menilai model pada set data akademik dan dunia nyata membolehkan model diuji dengan lebih teliti dan membolehkan kami memahami dengan lebih baik keberkesanannya dalam aplikasi dunia sebenar. Ini memastikan bahawa model mempunyai keupayaan untuk menyelesaikan masalah dunia sebenar dan memberikan penyelesaian yang praktikal dan boleh digunakan.
- Penjajaran Model. Adalah penting untuk memastikan model yang semakin berkuasa dan automatik diselaraskan dengan nilai dan keutamaan manusia. Kita perlu memikirkan cara untuk memastikan model berkelakuan seperti yang diharapkan dan tidak mengoptimumkan model untuk hasil yang kita tidak mahu. Adalah penting untuk mengintegrasikan teknik yang tepat dari permulaan proses pembangunan model. Ketelusan dan kebolehtafsiran model juga penting dalam menilai dan memastikan ketepatan. Di samping itu, melihat masa depan, terdapat cabaran yang lebih sukar yang muncul: pelaksanaan sistem manusia super yang tepat. Walaupun tugas ini pada masa ini melebihi keperluan kami, adalah penting untuk mempertimbangkan dan bersedia untuk sistem termaju seperti Hezhun, kerana ia mungkin menimbulkan kerumitan unik dan isu etika.
- Penjajaran Keselamatan. Walaupun penting untuk membincangkan risiko wujud yang ditimbulkan oleh AI, kami memerlukan penyelidikan praktikal untuk memastikan AI lanjutan boleh dibangunkan dengan selamat. Ini termasuk teknik untuk kebolehtafsiran, penyeliaan dan tadbir urus boleh skala, dan pengesahan formal sifat model. Dalam pembinaan model, keselamatan tidak boleh dilihat sebagai tambahan tetapi sebagai sebahagian daripada keseluruhannya.
- Ramalkan prestasi model apabila saiznya berubah. Apabila saiz dan kerumitan model meningkat dengan ketara, adalah sukar untuk meramalkan prestasi model tersebut. Teknik harus dibangunkan untuk meramalkan prestasi model dengan lebih baik semasa mereka meningkatkan atau menggunakan seni bina baharu, yang akan membolehkan kami menggunakan sumber dengan lebih cekap dan mempercepatkan pembangunan. Terdapat beberapa kemungkinan: melatih model "benih" yang lebih kecil dan meramalkan pertumbuhannya melalui ekstrapolasi, mensimulasikan kesan menskalakan atau melaraskan model, dan mengulang pada bangku ujian model pada saiz yang berbeza untuk membina undang-undang skala . Ini memberi kita gambaran tentang prestasi model sebelum kita membinanya.
Atas ialah kandungan terperinci Pokok evolusi model bahasa besar, ini adalah panduan 'makan' yang sangat terperinci untuk ChatGPT. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1385
1385
 52
52

 ChatGPT kini membenarkan pengguna percuma menjana imej dengan menggunakan DALL-E 3 dengan had harian
Aug 09, 2024 pm 09:37 PM
ChatGPT kini membenarkan pengguna percuma menjana imej dengan menggunakan DALL-E 3 dengan had harian
Aug 09, 2024 pm 09:37 PM
DALL-E 3 telah diperkenalkan secara rasmi pada September 2023 sebagai model yang jauh lebih baik daripada pendahulunya. Ia dianggap sebagai salah satu penjana imej AI terbaik setakat ini, mampu mencipta imej dengan perincian yang rumit. Walau bagaimanapun, semasa pelancaran, ia adalah tidak termasuk
 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas secara rasmi memasuki era robot elektrik! Semalam, Atlas hidraulik hanya "menangis" menarik diri daripada peringkat sejarah Hari ini, Boston Dynamics mengumumkan bahawa Atlas elektrik sedang berfungsi. Nampaknya dalam bidang robot humanoid komersial, Boston Dynamics berazam untuk bersaing dengan Tesla. Selepas video baharu itu dikeluarkan, ia telah pun ditonton oleh lebih sejuta orang dalam masa sepuluh jam sahaja. Orang lama pergi dan peranan baru muncul. Ini adalah keperluan sejarah. Tidak dinafikan bahawa tahun ini adalah tahun letupan robot humanoid. Netizen mengulas: Kemajuan robot telah menjadikan majlis pembukaan tahun ini kelihatan seperti manusia, dan tahap kebebasan adalah jauh lebih besar daripada manusia Tetapi adakah ini benar-benar bukan filem seram? Pada permulaan video, Atlas berbaring dengan tenang di atas tanah, seolah-olah terlentang. Apa yang berikut adalah rahang-jatuh
 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Video terbaru robot Tesla Optimus dikeluarkan, dan ia sudah boleh berfungsi di kilang. Pada kelajuan biasa, ia mengisih bateri (bateri 4680 Tesla) seperti ini: Pegawai itu juga mengeluarkan rupanya pada kelajuan 20x - pada "stesen kerja" kecil, memilih dan memilih dan memilih: Kali ini ia dikeluarkan Salah satu sorotan video itu ialah Optimus menyelesaikan kerja ini di kilang, sepenuhnya secara autonomi, tanpa campur tangan manusia sepanjang proses. Dan dari perspektif Optimus, ia juga boleh mengambil dan meletakkan bateri yang bengkok, memfokuskan pada pembetulan ralat automatik: Berkenaan tangan Optimus, saintis NVIDIA Jim Fan memberikan penilaian yang tinggi: Tangan Optimus adalah robot lima jari di dunia paling cerdik. Tangannya bukan sahaja boleh disentuh
 FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
Pengesanan objek ialah masalah yang agak matang dalam sistem pemanduan autonomi, antaranya pengesanan pejalan kaki adalah salah satu algoritma terawal untuk digunakan. Penyelidikan yang sangat komprehensif telah dijalankan dalam kebanyakan kertas kerja. Walau bagaimanapun, persepsi jarak menggunakan kamera fisheye untuk pandangan sekeliling agak kurang dikaji. Disebabkan herotan jejari yang besar, perwakilan kotak sempadan standard sukar dilaksanakan dalam kamera fisheye. Untuk mengurangkan perihalan di atas, kami meneroka kotak sempadan lanjutan, elips dan reka bentuk poligon am ke dalam perwakilan kutub/sudut dan mentakrifkan metrik mIOU pembahagian contoh untuk menganalisis perwakilan ini. Model fisheyeDetNet yang dicadangkan dengan bentuk poligon mengatasi model lain dan pada masa yang sama mencapai 49.5% mAP pada set data kamera fisheye Valeo untuk pemanduan autonomi
 Yang terbaru dari Universiti Oxford! Mickey: Padanan imej 2D dalam SOTA 3D! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Yang terbaru dari Universiti Oxford! Mickey: Padanan imej 2D dalam SOTA 3D! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Pautan projek ditulis di hadapan: https://nianticlabs.github.io/mickey/ Memandangkan dua gambar, pose kamera di antara mereka boleh dianggarkan dengan mewujudkan kesesuaian antara gambar. Biasanya, surat-menyurat ini adalah 2D hingga 2D, dan anggaran pose kami adalah skala-tak tentu. Sesetengah aplikasi, seperti realiti tambahan segera pada bila-bila masa, di mana-mana sahaja, memerlukan anggaran pose metrik skala, jadi mereka bergantung pada penganggar kedalaman luaran untuk memulihkan skala. Makalah ini mencadangkan MicKey, proses pemadanan titik utama yang mampu meramalkan korespondensi metrik dalam ruang kamera 3D. Dengan mempelajari padanan koordinat 3D merentas imej, kami dapat membuat kesimpulan relatif metrik
 Satu kad menjalankan Llama 70B lebih pantas daripada dua kad, Microsoft hanya meletakkan FP6 ke dalam A100 |
Apr 29, 2024 pm 04:55 PM
Satu kad menjalankan Llama 70B lebih pantas daripada dua kad, Microsoft hanya meletakkan FP6 ke dalam A100 |
Apr 29, 2024 pm 04:55 PM
FP8 dan ketepatan pengiraan titik terapung yang lebih rendah bukan lagi "paten" H100! Lao Huang mahu semua orang menggunakan INT8/INT4, dan pasukan Microsoft DeepSpeed memaksa diri mereka menjalankan FP6 pada A100 tanpa sokongan rasmi daripada Nvidia. Keputusan ujian menunjukkan bahawa kaedah baharu TC-FPx FP6 kuantisasi pada A100 adalah hampir atau kadangkala lebih pantas daripada INT4, dan mempunyai ketepatan yang lebih tinggi daripada yang terakhir. Selain itu, terdapat juga sokongan model besar hujung ke hujung, yang telah bersumberkan terbuka dan disepadukan ke dalam rangka kerja inferens pembelajaran mendalam seperti DeepSpeed. Keputusan ini juga mempunyai kesan serta-merta pada mempercepatkan model besar - di bawah rangka kerja ini, menggunakan satu kad untuk menjalankan Llama, daya pemprosesan adalah 2.65 kali lebih tinggi daripada dua kad. satu
