

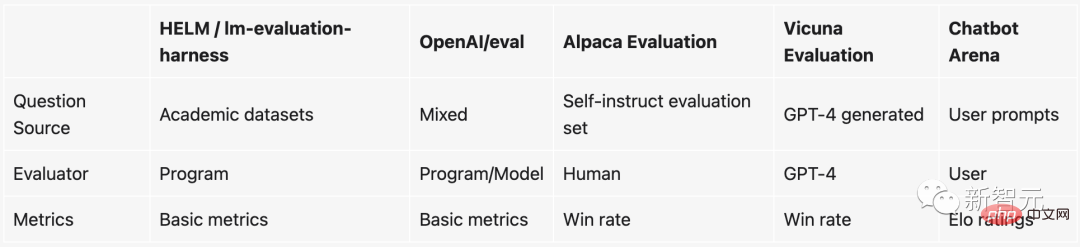
Baru-baru ini, penyelidik dari LMSYS Org (diketuai oleh UC Berkeley) telah membuat satu lagi berita besar - pertandingan ranking versi model bahasa yang besar!
Seperti namanya, "Pertandingan Kedudukan LLM" adalah untuk membenarkan sekumpulan model bahasa besar secara rawak melakukan pertempuran dan meletakkan mereka mengikut markah Elo mereka.
Kemudian, kita boleh mengetahui sepintas lalu sama ada chatbot tertentu adalah "Raja Mulut Kuat" atau "Raja Terkuat".
Perkara utama: Pasukan ini juga merancang untuk membawa masuk semua model "sumber tertutup" ini dari negara dalam dan luar negara Anda akan tahu sama ada ia adalah keldai atau kuda! (GPT-3.5 sudah berada di arena tanpa nama sekarang)

Arena chatbot tanpa nama kelihatan seperti ini:
Jelas sekali, Model B menjawab dengan betul dan memenangi pusingan; >
Alamat projek: https://arena.lmsys.org/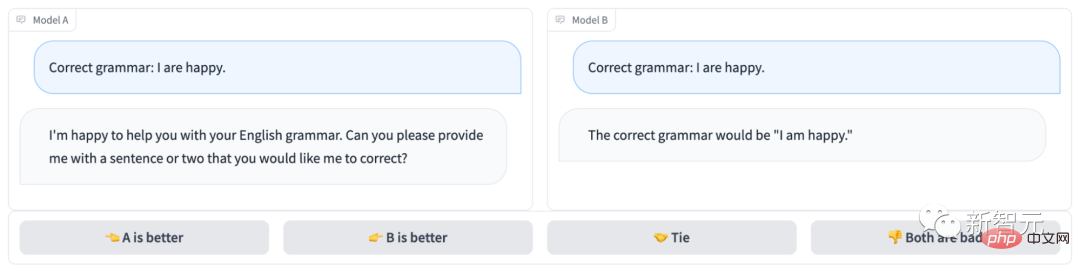
Dalam kedudukan semasa , Vicuna dengan 13 bilion parameter menduduki tempat pertama dengan 1169 mata, Koala dengan 13 bilion parameter menduduki tempat kedua, dan Pembantu Terbuka LAION menduduki tempat ketiga.
ChatGLM yang dicadangkan oleh Universiti Tsinghua, walaupun hanya mempunyai 6 bilion parameter, masih memecah masuk ke lima teratas, hanya 23 mata di belakang Alpaca dengan 13 bilion parameter.Sebagai perbandingan, LLaMa asal Meta hanya menduduki tempat kelapan (kedua dari yang terakhir), manakala StableLM Stability AI hanya memperoleh 800+ mata, menduduki tempat pertama dari yang terakhir.
Pasukan menyatakan bahawa mereka bukan sahaja akan mengemas kini senarai kedudukan secara kerap, tetapi juga mengoptimumkan algoritma dan mekanisme, serta memberikan kedudukan yang lebih terperinci berdasarkan jenis tugas yang berbeza.
Pada masa ini, semua kod penilaian dan analisis data telah diterbitkan.

Dalam penilaian ini, pasukan memilih 9 chatbots sumber terbuka yang terkenal pada masa ini.
Setiap kali berlaku pertempuran 1v1, sistem akan secara rawak menarik dua pemain PK. Pengguna perlu berbual dengan kedua-dua robot pada masa yang sama dan kemudian memutuskan chatbot yang lebih baik.Seperti yang anda lihat, terdapat 4 pilihan di bahagian bawah halaman, kiri (A) lebih baik, kanan (B) lebih baik, sama baik, atau kedua-duanya adalah teruk.
Selepas pengguna menyerahkan undian, sistem akan memaparkan nama model. Pada masa ini, pengguna boleh terus bersembang atau memilih model baharu untuk memulakan semula pusingan pertempuran.
Walau bagaimanapun, apabila menganalisis, pasukan hanya akan menggunakan keputusan undian apabila model itu tanpa nama. Selepas hampir seminggu pengumpulan data, pasukan itu mengumpul sejumlah 4.7k undi tanpa nama yang sah.
Sebelum bermula, pasukan terlebih dahulu memahami kemungkinan kedudukan setiap model berdasarkan keputusan ujian penanda aras.
Kemudian, pensampelan seragam digunakan untuk mendapatkan liputan keseluruhan ranking yang lebih baik.
Pada akhir kelayakan, pasukan memperkenalkan model fastchat-t5-3b baharu.
Operasi di atas akhirnya membawa kepada frekuensi model yang tidak seragam. 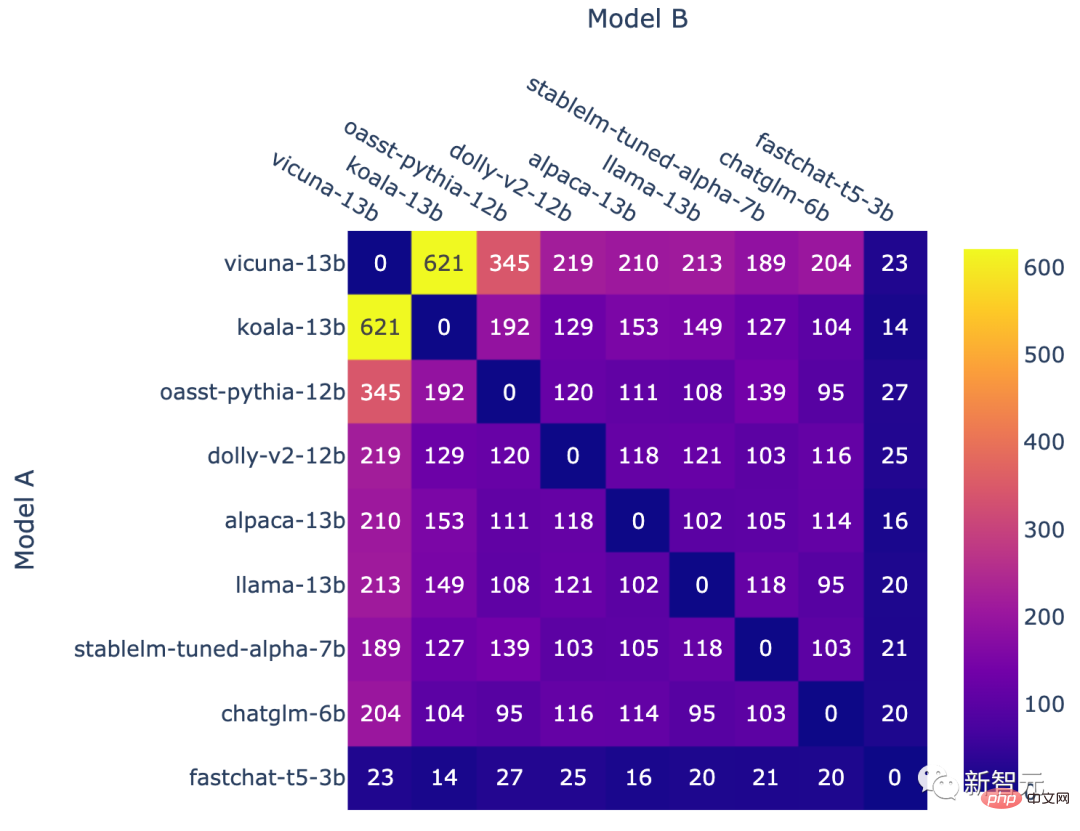
Bilangan pertempuran untuk setiap kombinasi model
Daripada data statistik, kebanyakan pengguna menggunakan bahasa Inggeris, dengan kedudukan bahasa Cina kedua.
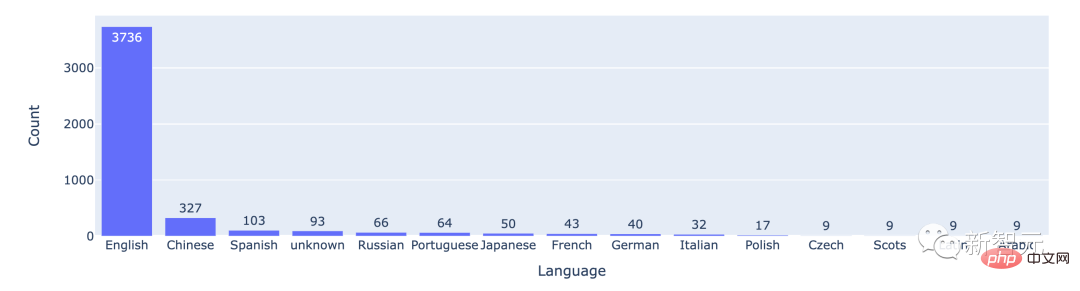
Bilangan permainan yang dimainkan dalam 15 bahasa teratas
Sejak populariti ChatGPT, model bahasa besar sumber terbuka yang telah diperhalusi mengikut arahan telah bermunculan seperti cendawan selepas hujan musim bunga. Boleh dikatakan LLM sumber terbuka baharu dikeluarkan hampir setiap minggu.
Tetapi masalahnya adalah sangat sukar untuk menilai model bahasa yang besar ini.
Secara khusus, perkara yang digunakan pada masa ini untuk mengukur kualiti model pada asasnya berdasarkan beberapa penanda aras akademik, seperti membina set data ujian pada tugas NLP tertentu, dan kemudian Lihat ketepatan pada set data ujian.
Walau bagaimanapun, penanda aras akademik ini (seperti HELM) tidak mudah digunakan pada model besar dan chatbot. Sebabnya ialah:
1. Memandangkan menilai sama ada chatbot pandai bersembang adalah sangat subjektif, sukar untuk mengukurnya dengan kaedah sedia ada.
2. Model besar ini mengimbas hampir semua data di Internet semasa latihan, jadi sukar untuk memastikan set data ujian tidak dilihat. Malah melangkah lebih jauh, menggunakan set ujian untuk terus "melatih khas" model akan menghasilkan prestasi yang lebih baik.
3 Secara teori, kita boleh berbual dengan chatbot tentang apa sahaja, tetapi banyak topik atau tugasan tidak wujud dalam penanda aras sedia ada.
Jika anda tidak mahu menggunakan penanda aras ini, sebenarnya ada cara lain - bayar seseorang untuk melakukannya ia.
Malah, inilah yang OpenAI lakukan. Tetapi kaedah ini jelas lambat, dan yang lebih penting, terlalu mahal...
Untuk menyelesaikan masalah perit ini, pasukan dari UC Berkeley, UCSD, dan CMU mencipta mekanisme A baharu yang menyeronokkan dan praktikal - Arena Chatbot.
Sebagai perbandingan, sistem garis dasar berasaskan pertempuran mempunyai kelebihan berikut:
Apabila data yang mencukupi tidak dapat dikumpul untuk semua pasangan model yang berpotensi, sistem seharusnya dapat menskalakan kepada seberapa banyak model yang mungkin.
Sistem seharusnya dapat menilai model baharu menggunakan bilangan percubaan yang agak kecil.
Sistem harus menyediakan susunan unik untuk semua model. Memandangkan mana-mana dua model, kita sepatutnya dapat memberitahu yang mana satu kedudukan lebih tinggi atau jika ia terikat.
Sistem penilaian Elo ialah kaedah mengira tahap kemahiran relatif pemain dan digunakan secara meluas dalam permainan kompetitif dan pelbagai sukan di kalangan. Antaranya, semakin tinggi skor Elo, semakin kuat pemain itu.
Contohnya, dalam League of Legends, Dota 2, Chicken Fighting, dsb., inilah mekanisme yang digunakan oleh sistem untuk menyusun kedudukan pemain.
Sebagai contoh, apabila anda bermain banyak perlawanan berperingkat dalam League of Legends, skor tersembunyi akan muncul. Skor tersembunyi ini bukan sahaja menentukan kedudukan anda, tetapi juga menentukan bahawa lawan yang anda hadapi semasa bermain ranking pada asasnya adalah tahap yang sama.
Selain itu, nilai skor Elo ini adalah mutlak. Dalam erti kata lain, apabila chatbot baharu ditambahkan pada masa hadapan, kita masih boleh menilai secara langsung bot chat mana yang lebih berkuasa melalui skor Elo.
Secara khusus, jika rating pemain A ialah Ra dan rating pemain B ialah Rb, formula tepat untuk kebarangkalian kemenangan pemain A (menggunakan lengkung logistik asas 10) ialah:

Kemudian, rating pemain akan dikemas kini secara linear selepas setiap pertempuran.
Andaikan pemain A (dinilai Ra) dijangka mendapat mata Ea, tetapi sebenarnya mendapat mata Sa. Formula untuk mengemas kini rating pemain ini ialah:
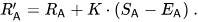
Selain itu, pengarang juga menunjukkan kedudukan Kadar kemenangan head-to-head bagi setiap model dalam ranking dan ramalan kadar kemenangan head-to-head yang dianggarkan menggunakan skor Elo.
Keputusan menunjukkan bahawa markah Elo sememangnya boleh diramalkan dengan agak tepat
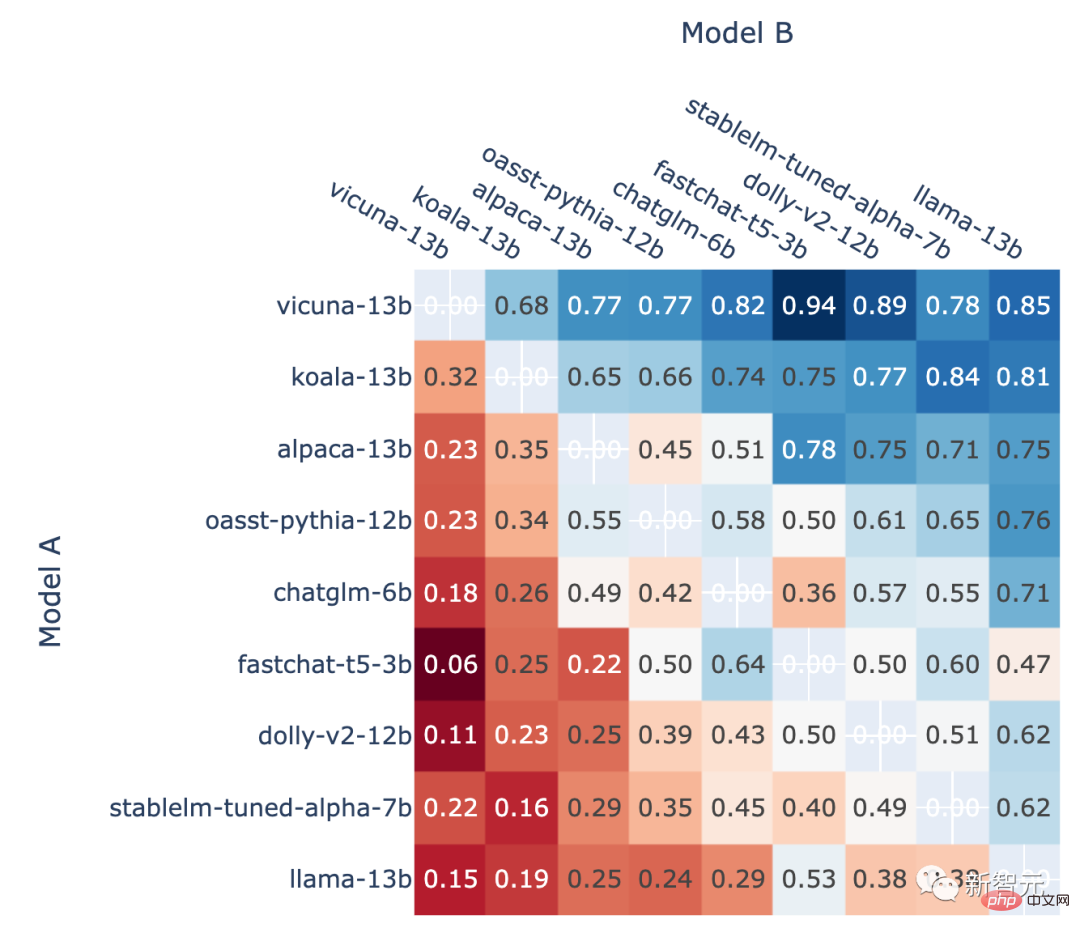
Semua bukan - Perkadaran Model A yang menang dalam pertarungan seri A vs. B
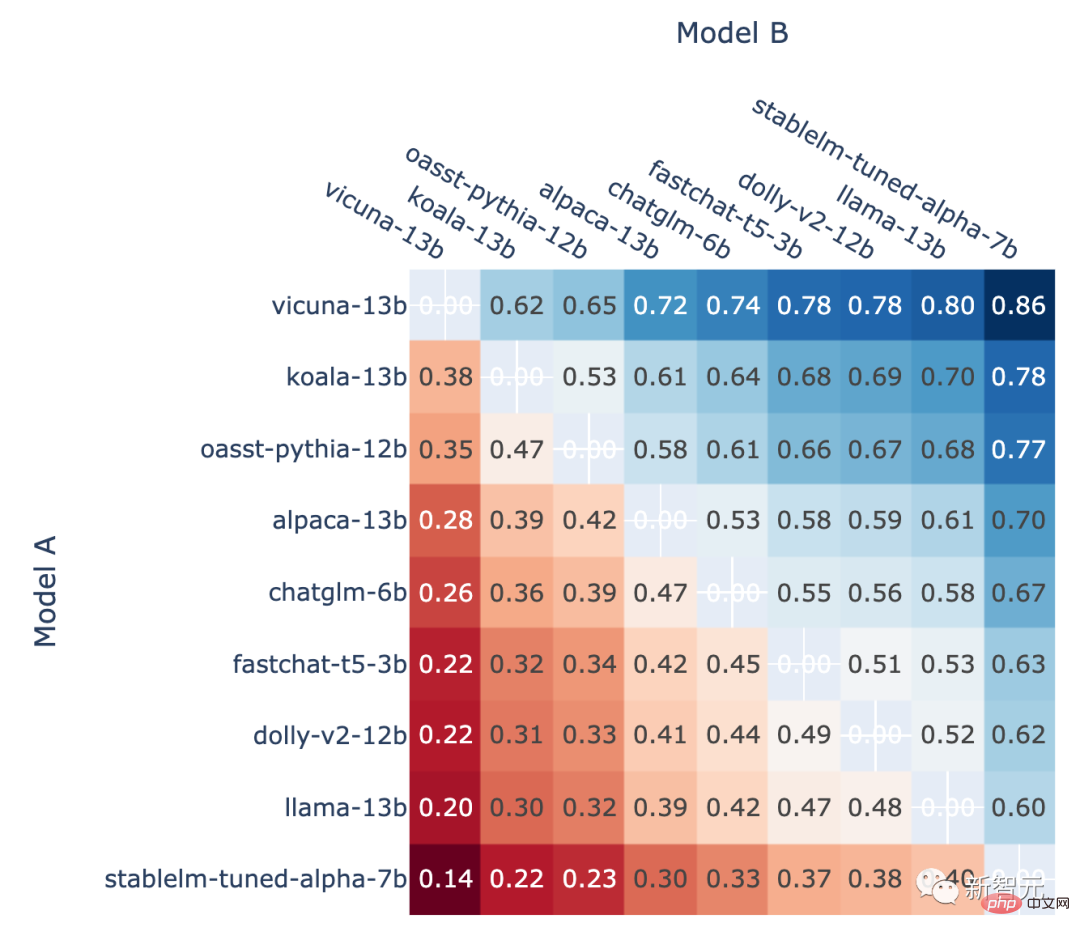
Dalam A vs. B battle , kadar kemenangan model A yang diramalkan menggunakan skor Elo
"Chatbot Arena" dikeluarkan oleh bekas Little Alpaca agensi pengarang LMSYS Org.
Institusi ini diasaskan oleh UC Berkeley Ph.D. Lianmin Zheng dan profesor bersekutu UCSD Hao Zhang, dengan matlamat menjadikannya boleh diakses oleh semua orang dengan membangunkan set data terbuka, model, sistem dan alat penilaian Dapatkan model besar.
Lianmin Zheng ialah seorang profesor di Jabatan Pelajar EECS, Universiti California, Berkeley PhD, minat penyelidikannya termasuk sistem pembelajaran mesin, penyusun dan sistem teragih.
Hao Zhang kini merupakan penyelidik pasca doktoral di Universiti California, Berkeley. Beliau akan berkhidmat sebagai penolong profesor di Institut Sains Data UC San Diego Halıcıoğlu dan Jabatan Sains Komputer bermula pada musim gugur 2023.
Atas ialah kandungan terperinci UC Berkeley mengeluarkan ranking model bahasa besar! Vicuna memenangi kejuaraan dan Tsinghua ChatGLM berada di antara 5 teratas. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk mengaktifkan sistem versi profesional win7
Bagaimana untuk mengaktifkan sistem versi profesional win7
 Bagaimana untuk menyelesaikan 0xc000035
Bagaimana untuk menyelesaikan 0xc000035
 Bagaimana untuk berdagang syiling VV
Bagaimana untuk berdagang syiling VV
 Bagaimana untuk mendapatkan masa semasa dalam JAVA
Bagaimana untuk mendapatkan masa semasa dalam JAVA
 Telekom cdma
Telekom cdma
 sistem Hongmeng
sistem Hongmeng
 proses paparan linux
proses paparan linux
 Bagaimana untuk menukar format wav
Bagaimana untuk menukar format wav
 Bagaimana untuk membuka dua akaun WeChat pada telefon mudah alih Huawei
Bagaimana untuk membuka dua akaun WeChat pada telefon mudah alih Huawei








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



