

Bolehkah anda menjana pemandangan dinamik 3D dengan hanya memasukkan baris teks?
Ya, beberapa penyelidik telah melakukannya. Dapat dilihat bahawa kesan generasi sekarang masih di peringkat awal dan hanya boleh menghasilkan beberapa objek mudah. Walau bagaimanapun, kaedah "satu langkah" ini masih menarik perhatian sebilangan besar penyelidik:

Dalam artikel terbaru Dalam kertas itu, penyelidik dari Meta mencadangkan buat kali pertama MAV3D (Make-A-Video3D), kaedah yang boleh menjana adegan dinamik tiga dimensi daripada penerangan teks.

Secara khusus, kaedah ini menggunakan Medan Sinaran Neural dinamik 4D (NeRF) untuk mengoptimumkan ketekalan penampilan pemandangan, ketumpatan dan gerakan dengan menanyakan model berasaskan resapan teks-ke-video (T2V). Output video dinamik yang dijana oleh teks yang disediakan boleh dilihat dari mana-mana sudut atau sudut kamera dan boleh disintesis ke dalam mana-mana persekitaran 3D.
MAV3D tidak memerlukan sebarang data 3D atau 4D, model T2V hanya dilatih pada pasangan imej teks dan video tidak berlabel.

Mari kita lihat kesan MAV3D menjana adegan dinamik 4D daripada teks:

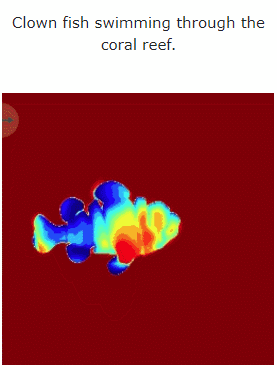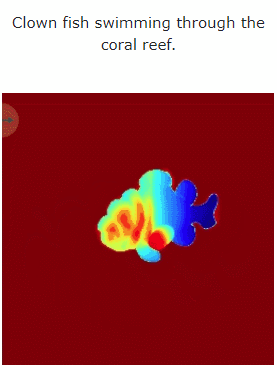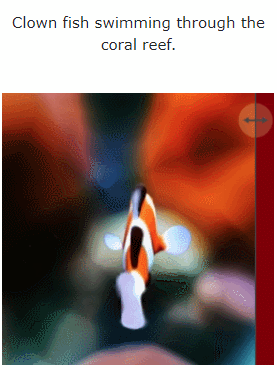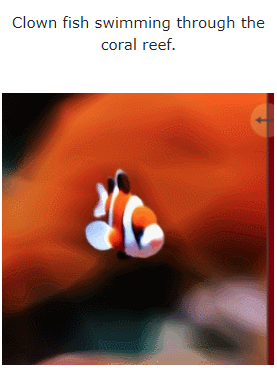
Selain itu, ia juga boleh terus dari imej ke 4D, kesannya adalah seperti berikut:


Para penyelidik membuktikannya melalui eksperimen kuantitatif dan kualitatif yang komprehensif Keberkesanan kaedah, pada garis dasar dalaman yang telah ditetapkan sebelum ini juga telah dipertingkatkan. Dilaporkan bahawa ini adalah kaedah pertama untuk menjana pemandangan dinamik 3D berdasarkan penerangan teks.
Matlamat penyelidikan ini adalah untuk membangunkan kaedah untuk menjana perwakilan adegan 3D dinamik daripada penerangan bahasa semula jadi. Ini amat mencabar kerana tiada teks atau pasangan 3D mahupun data adegan 3D dinamik untuk latihan. Oleh itu, kami memilih untuk bergantung pada model resapan teks-ke-video (T2V) yang telah dilatih sebagai adegan sebelumnya, yang telah belajar untuk memodelkan penampilan dan gerakan adegan yang realistik melalui latihan mengenai imej, teks dan gambar berskala besar. data video.
Daripada tahap yang lebih tinggi, diberikan gesaan teks p, kami boleh memuatkan perwakilan 4D yang menyerupai penampilan pemandangan yang sepadan dengan gesaan pada sebarang titik dalam ruang dan masa. Tanpa data latihan berpasangan, kajian tidak boleh menyelia secara langsung output 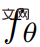 walau bagaimanapun, memandangkan urutan pose kamera
walau bagaimanapun, memandangkan urutan pose kamera 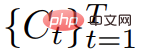 boleh memaparkan jujukan imej daripada
boleh memaparkan jujukan imej daripada 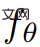
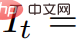
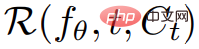 dan susunkannya ke dalam video V. Gesaan teks p dan video V kemudiannya dihantar ke model resapan T2V beku dan pra-latihan, yang menjaringkan ketulenan dan penjajaran segera video dan menggunakan SDS (Pensampelan Penyulingan Skor) untuk mengira arah kemas kini parameter pemandangan θ .
dan susunkannya ke dalam video V. Gesaan teks p dan video V kemudiannya dihantar ke model resapan T2V beku dan pra-latihan, yang menjaringkan ketulenan dan penjajaran segera video dan menggunakan SDS (Pensampelan Penyulingan Skor) untuk mengira arah kemas kini parameter pemandangan θ .
Saluran paip di atas boleh dikira sebagai lanjutan DreamFusion, menambah dimensi temporal pada model pemandangan dan menggunakan model T2V dan bukannya teks-ke-imej (T2I ) model untuk penyeliaan. Walau bagaimanapun, untuk mencapai penjanaan teks-ke-4D yang berkualiti tinggi memerlukan lebih banyak inovasi:
Lihat gambar di bawah untuk mendapatkan arahan khusus:
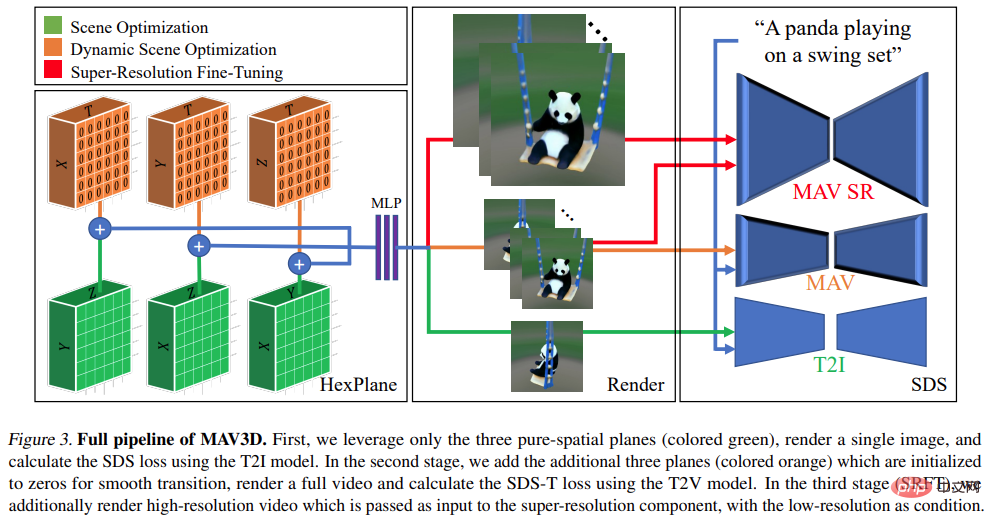
Dalam percubaan, penyelidik menilai keupayaan MAV3D untuk menjana pemandangan dinamik daripada huraian teks. Pertama, penyelidik menilai keberkesanan kaedah pada tugas Text-To-4D. Dilaporkan bahawa MAV3D adalah penyelesaian pertama untuk tugas ini, jadi penyelidikan membangunkan tiga kaedah alternatif sebagai garis dasar. Kedua, kami menilai versi ringkas model subtugas T2V dan Text-To-3D dan membandingkannya dengan garis dasar sedia ada dalam literatur. Ketiga, kajian ablasi komprehensif mewajarkan reka bentuk kaedah. Keempat, eksperimen menerangkan proses menukar NeRF dinamik kepada jejaring dinamik, akhirnya memanjangkan model kepada tugas Imej-ke-4D.
Metrik
Kaji untuk menilai video yang dijana menggunakan CLIP R-Precision, yang mengukur teks dan menghasilkan ketekalan adegan antara . Metrik yang dilaporkan ialah ketepatan mendapatkan semula gesaan input daripada bingkai yang diberikan. Kami menggunakan varian ViT-B/32 CLIP dan bingkai yang diekstrak dalam paparan dan langkah masa yang berbeza, dan juga menggunakan empat metrik kualitatif dengan meminta penilai manusia untuk pilihan mereka merentas dua video yang dijana, masing-masing ialah: (i) kualiti video; ii) kesetiaan kepada gesaan teks; (iii) jumlah aktiviti; Kami menilai semua garis dasar dan ablasi yang digunakan dalam pembahagian gesaan teks.
Rajah 1 dan 2 adalah contoh. Untuk visualisasi yang lebih terperinci, lihat make-a-video3d.github.io.

Keputusan
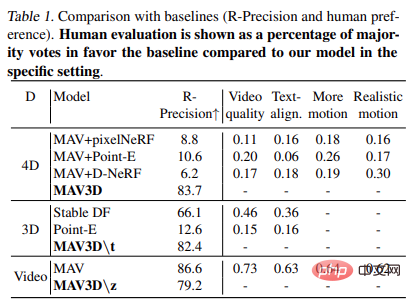
Jadual 1 menunjukkan Perbandingan kepada garis dasar (R - ketepatan dan keutamaan manusia). Ulasan manusia dibentangkan sebagai peratusan undian yang memihak kepada majoriti garis dasar berbanding model dalam persekitaran tertentu.
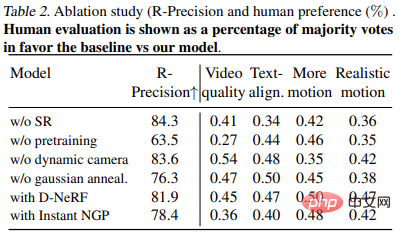
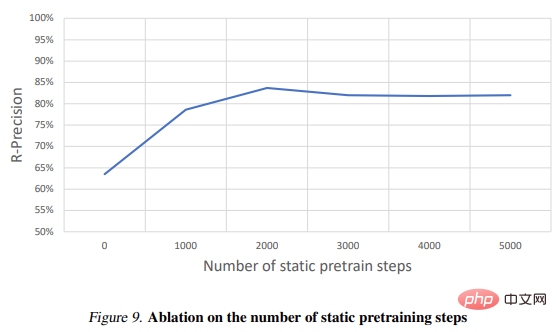
Jadual 2 menunjukkan keputusan eksperimen ablasi:
Reparan masa nyata
Aplikasi seperti realiti maya dan permainan yang menggunakan enjin grafik tradisional memerlukan format standard, Seperti mesh tekstur. Model HexPlane boleh ditukar dengan mudah menjadi jerat animasi seperti yang ditunjukkan di bawah. Pertama, jejaring mudah diekstrak daripada medan kelegapan yang dijana pada setiap kali t menggunakan algoritma kiub kawad, diikuti dengan pengekstrakan jejaring (untuk kecekapan) dan penyingkiran komponen kecil bersambung yang bising. Algoritma XATLAS digunakan untuk memetakan bucu mesh ke atlas tekstur, dengan tekstur dimulakan menggunakan warna HexPlane dipuratakan dalam sfera kecil yang berpusat pada setiap bucu. Akhir sekali, tekstur dioptimumkan lagi untuk lebih sepadan dengan beberapa contoh bingkai yang diberikan oleh HexPlane menggunakan jerat yang boleh dibezakan. Ini akan menghasilkan koleksi jejaring tekstur yang boleh dimainkan semula dalam mana-mana enjin 3D di luar rak.
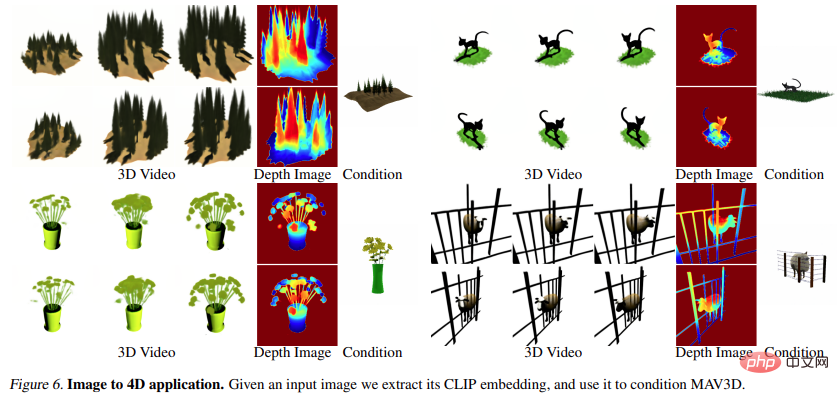
Imej ke 4D
Rajah 6 dan Rajah 10 menunjukkan bahawa kaedah tersebut mampu menjana daripada input yang diberikan imej Kedalaman dan gerakan untuk menjana aset 4D.



Untuk butiran penyelidikan lanjut, sila rujuk kertas asal.
Atas ialah kandungan terperinci Baris teks menghasilkan pemandangan dinamik 3D: Model 'satu langkah' Meta agak berkuasa. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



