

Dalam beberapa tahun kebelakangan ini, latihan pelbagai mod berskala besar berdasarkan Transformer telah membawa kepada peningkatan dalam teknologi terkini dalam pelbagai bidang, termasuk penglihatan, bahasa dan audio. Terutamanya dalam penglihatan komputer dan pemahaman bahasa imej, satu model besar yang telah dilatih boleh mengatasi model pakar untuk tugas tertentu.
Walau bagaimanapun, model berbilang mod yang besar selalunya menggunakan modaliti atau pengekod dan penyahkod khusus set data, dan mengakibatkan protokol terlibat dengan sewajarnya. Sebagai contoh, model sedemikian sering melibatkan peringkat latihan yang berbeza bahagian model yang berbeza pada set data masing-masing, dengan prapemprosesan khusus set data, atau pemindahan bahagian yang berbeza mengikut cara khusus tugasan. Corak dan komponen khusus tugas ini boleh membawa kepada kerumitan dan cabaran kejuruteraan tambahan apabila memperkenalkan kerugian pra-latihan baharu atau tugas hiliran.
Oleh itu, membangunkan model hujung ke hujung tunggal yang boleh mengendalikan sebarang modaliti atau gabungan modaliti akan menjadi langkah penting ke arah pembelajaran pelbagai mod. Dalam artikel ini, penyelidik dari Google Research (pasukan Google Brain) dan Zurich akan memberi tumpuan terutamanya pada imej dan teks.

Alamat kertas: https://arxiv.org/pdf/2212.08045.pdf
Banyak penyatuan utama mempercepatkan proses pembelajaran multimodal. Pertama, telah terbukti bahawa seni bina Transformer boleh berfungsi sebagai tulang belakang umum dan berprestasi baik pada teks, visual, audio dan domain lain. Kedua, banyak kertas kerja meneroka pemetaan modaliti yang berbeza ke dalam satu ruang pembenaman dikongsi untuk memudahkan antara muka input/output, atau untuk membangunkan satu antara muka untuk berbilang tugas. Ketiga, perwakilan alternatif modaliti membenarkan penggunaan dalam satu domain seni bina saraf atau prosedur latihan yang direka dalam domain lain. Sebagai contoh, [54] dan [26,48] masing-masing mewakili teks dan audio, yang diproses dengan menjadikan bentuk ini sebagai imej (spektrogram dalam kes audio).
Artikel ini akan meneroka pembelajaran pelbagai mod teks dan imej menggunakan model berasaskan piksel semata-mata. Model ini ialah Transformer visual yang berasingan yang memproses input visual atau teks, atau kedua-duanya bersama-sama, semuanya dipaparkan sebagai imej RGB. Semua modaliti menggunakan parameter model yang sama, termasuk pemprosesan ciri peringkat rendah, iaitu, tiada lilitan awal khusus modaliti, algoritma tokenisasi atau jadual benam input. Model ini dilatih dengan hanya satu tugas: pembelajaran kontrastif, seperti yang dipopularkan oleh CLIP dan ALIGN. Oleh itu model itu dipanggil CLIP-Pixel Sahaja (CLIPPO).
Mengenai tugas utama CLIP yang direka untuk klasifikasi imej dan pengambilan teks/imej, CLIPPO juga berprestasi serupa dengan CLIP walaupun tidak mempunyai modaliti menara tertentu (persamaan dalam 1- Dalam 2%) . Anehnya, CLIPPO boleh melaksanakan tugas pemahaman bahasa yang kompleks tanpa memerlukan sebarang pemodelan bahasa kiri ke kanan, pemodelan bahasa bertopeng atau kehilangan tahap perkataan yang jelas. Terutamanya pada penanda aras GLUE, CLIPPO mengatasi garis dasar NLP klasik seperti perhatian ELMO+BiLSTM+Selain itu, CLIPPO juga mengatasi model bahasa topeng berasaskan piksel dan menghampiri skor BERT.
Menariknya, CLIPPO juga mencapai prestasi yang baik pada VQA apabila hanya memaparkan imej dan teks bersama-sama, walaupun tidak pernah dipralatih pada data sedemikian. Kelebihan segera model berasaskan piksel berbanding model bahasa konvensional ialah tiada perbendaharaan kata yang telah ditetapkan diperlukan. Hasilnya, prestasi perolehan semula berbilang bahasa dipertingkatkan berbanding model setara menggunakan tokenizer klasik. Akhirnya, kajian juga mendapati bahawa dalam beberapa kes jurang modal yang diperhatikan sebelum ini telah dikurangkan apabila melatih CLIPPO.
CLIP telah muncul sebagai paradigma yang berkuasa dan boleh skala untuk melatih model penglihatan serba boleh pada set data. Khususnya, pendekatan ini bergantung pada pasangan imej/alt-teks, yang boleh dikumpulkan secara automatik daripada web pada skala. Akibatnya, perihalan teks selalunya bising dan mungkin terdiri daripada kata kunci tunggal, set kata kunci atau perihalan yang berpotensi panjang. Menggunakan data ini, dua pengekod dilatih bersama, iaitu pengekod teks yang membenamkan teks alt dan pengekod imej yang membenamkan imej yang sepadan dalam ruang terpendam yang dikongsi. Kedua-dua pengekod dilatih menggunakan kehilangan kontrastif yang menggalakkan pembenaman imej dan teks alt yang sepadan menjadi serupa sambil berbeza daripada pembenaman semua imej dan teks alt lain.
Setelah dilatih, pasangan pengekod sebegini boleh digunakan dalam pelbagai cara: ia boleh mengklasifikasikan set tetap konsep visual mengikut penerangan teks (pengkelasan tangkapan sifar boleh digunakan untuk mendapatkan semula sesuatu); imej perihalan teks, dan sebaliknya, pengekod visual boleh dipindahkan ke tugas hiliran dengan cara yang diawasi dengan menala halus pada set data berlabel atau dengan melatih kepala pada perwakilan pengekod imej beku. Pada dasarnya, pengekod teks boleh digunakan sebagai pembenaman teks bebas Walau bagaimanapun, dilaporkan bahawa tiada siapa yang telah menjalankan penyelidikan mendalam tentang aplikasi ini Beberapa kajian menyebut teks alt berkualiti rendah, menyebabkan prestasi pemodelan bahasa yang lemah pengekod teks.
Kerja sebelum ini telah menunjukkan bahawa pengekod imej dan teks boleh dilaksanakan dengan model pengubah kongsi (juga dipanggil model menara tunggal, atau 1T-CLIP), di mana imej dibenamkan menggunakan pembenaman tampalan , Teks bertoken dibenamkan menggunakan pembenaman perkataan yang berasingan. Kecuali untuk pembenaman khusus modaliti, semua parameter model dikongsi antara kedua-dua modaliti. Walaupun jenis perkongsian ini biasanya mengakibatkan kemerosotan prestasi pada tugas imej/imej ke bahasa, ia juga mengurangkan bilangan parameter model sebanyak separuh.
CLIPPO mengambil idea ini selangkah lebih jauh: input teks dipaparkan pada imej kosong dan kemudian diproses sepenuhnya sebagai imej, termasuk pembenaman tampalan awal (lihat Rajah 1). Melalui latihan perbandingan dengan kerja terdahulu, model pengubah visual tunggal dijana yang boleh memahami imej dan teks melalui antara muka visual tunggal, dan menyediakan penyelesaian yang boleh digunakan untuk menyelesaikan tugas pemahaman imej, bahasa imej dan bahasa tulen.
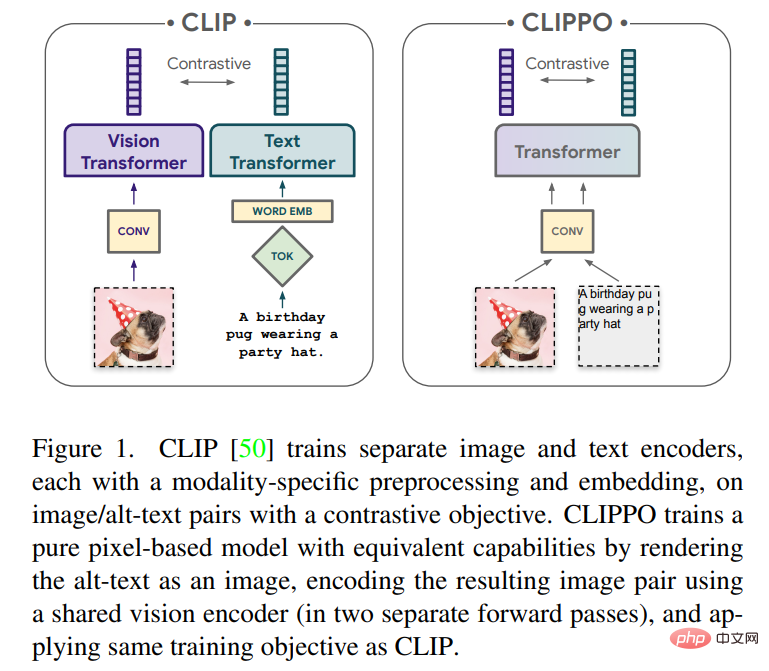
Selain kepelbagaian pelbagai mod, CLIPPO mengurangkan kesukaran biasa dalam pemprosesan teks, iaitu membangunkan tokenizer dan perbendaharaan kata yang sesuai. Ini amat menarik dalam konteks tetapan berbilang bahasa yang besar, di mana pengekod teks perlu mengendalikan berpuluh-puluh bahasa.
Dapat didapati bahawa CLIPPO terlatih pada pasangan imej/alt-teks berprestasi setanding dengan 1T-CLIP pada tanda aras imej awam dan bahasa imej, dan pada penanda aras GLUE dengan Baseline yang berkuasa pertandingan model bahasa. Walau bagaimanapun, memandangkan teks alt mempunyai kualiti yang lebih rendah dan secara amnya bukan ayat yang gramatis, pembelajaran pemahaman bahasa daripada teks alt sahaja pada asasnya terhad. Oleh itu, latihan kontras berasaskan bahasa boleh ditambah pada pra-latihan kontras imej/alt-teks. Khususnya, pasangan ayat berturut-turut yang dijadikan sampel daripada korpus teks, pasangan ayat yang diterjemahkan dalam bahasa yang berbeza, pasangan ayat pasca terjemahan dan pasangan ayat dengan perkataan yang hilang perlu diambil kira.
Pemahaman visual dan visual-bahasa
Pengelasan dan pengambilan imej. Jadual 1 menunjukkan prestasi CLIPPO, dan dapat dilihat bahawa CLIPPO dan 1T-CLIP menghasilkan penurunan mutlak 2-3 mata peratusan berbanding CLIP*.
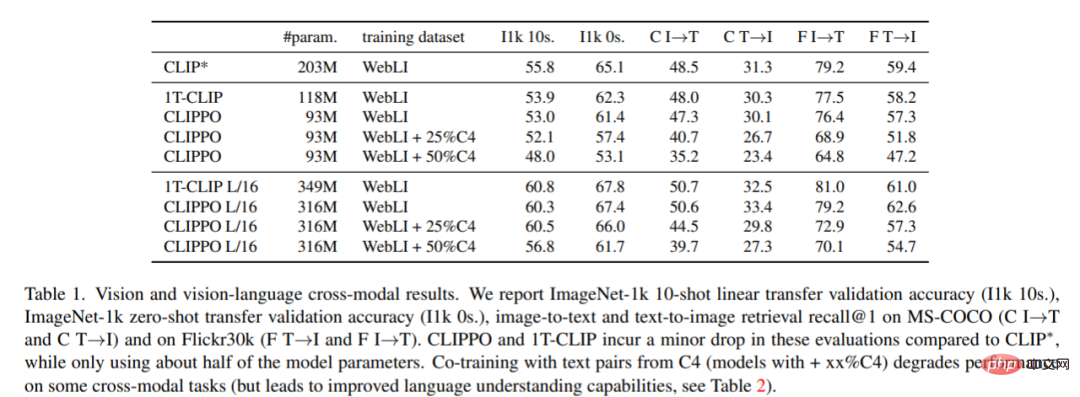
VQA. Skor VQAv2 model dan garis dasar dilaporkan dalam Rajah 2. Dapat dilihat bahawa CLIPPO mengatasi CLIP∗, 1T-CLIP, dan ViT-B/16, mencapai skor 66.3.
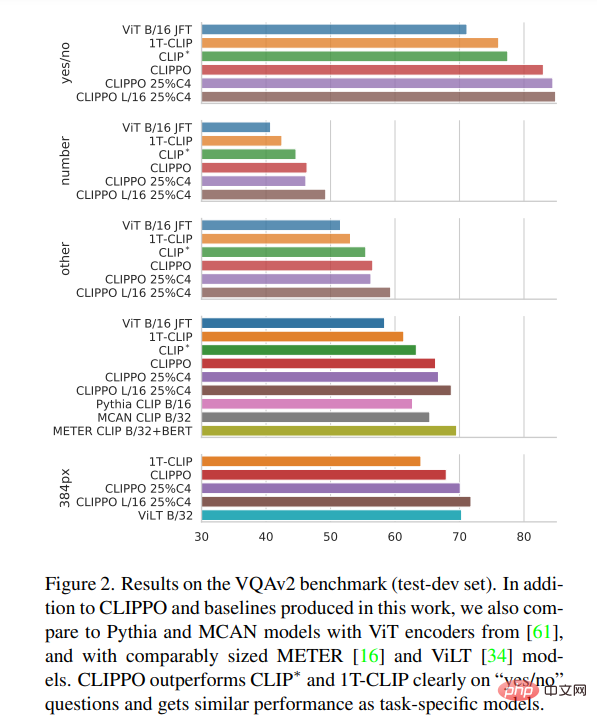
Penglihatan berbilang bahasa - pemahaman bahasa
Rajah 3 menunjukkan bahawa Prestasi perolehan semula CLIPPO yang setanding dengan garis dasar ini dicapai. Dalam kes mT5, menggunakan data tambahan boleh meningkatkan prestasi dengan memanfaatkan parameter dan data tambahan ini dalam konteks berbilang bahasa akan menjadi hala tuju masa depan yang menarik untuk CLIPPO.
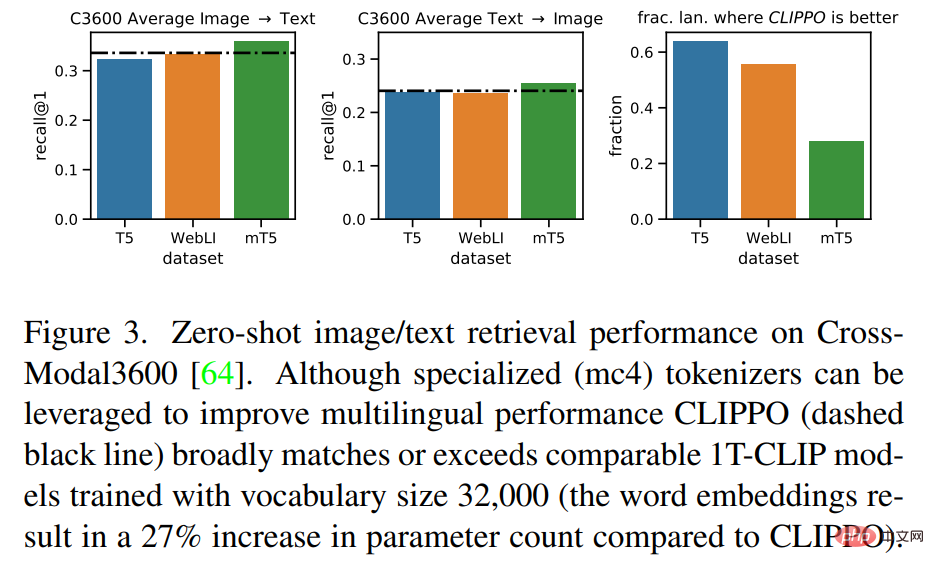
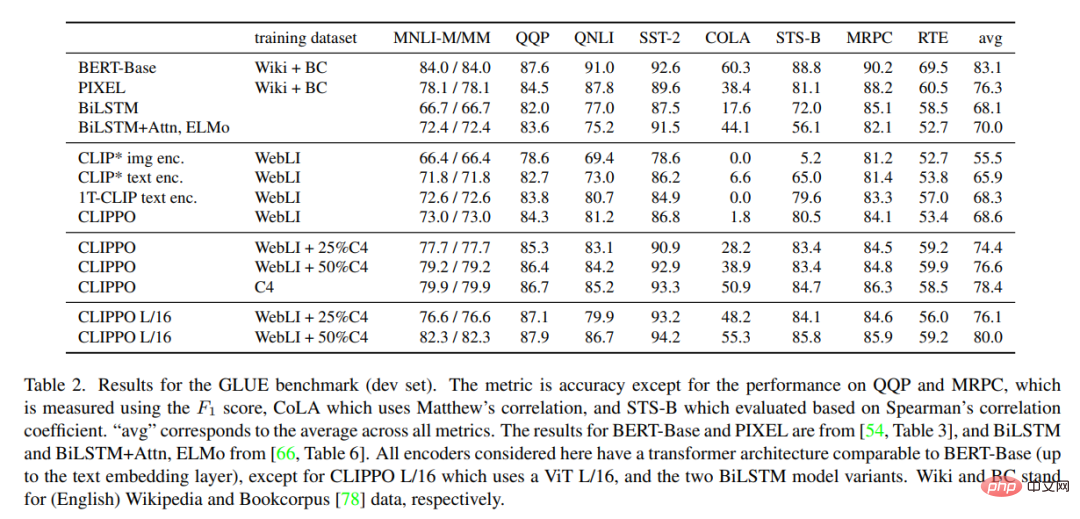
Jadual 2 menunjukkan hasil penanda aras GLUE untuk CLIPPO dan garis dasar. Dapat diperhatikan bahawa CLIPPO yang dilatih di WebLI adalah berdaya saing dengan garis dasar BiLSTM+Attn+ELMo yang mempunyai pembenaman perkataan mendalam yang dilatih pada korpus bahasa yang besar. Tambahan pula, kita dapat melihat bahawa CLIPPO dan 1T-CLIP mengatasi pengekod bahasa yang dilatih menggunakan pra-latihan penglihatan bahasa kontrastif standard.
Untuk butiran penyelidikan lanjut, sila rujuk kertas asal.
Atas ialah kandungan terperinci Parameter dibelah dua dan sebaik CLIP Transformer visual menyedari penyatuan imej dan teks bermula dari piksel.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk membuka akaun dengan mata wang u
Bagaimana untuk membuka akaun dengan mata wang u
 Perkara yang perlu dilakukan jika folder dokumen muncul apabila komputer dihidupkan
Perkara yang perlu dilakukan jika folder dokumen muncul apabila komputer dihidupkan
 Sebab pemuatan css gagal
Sebab pemuatan css gagal
 penggunaan sisipan oracle
penggunaan sisipan oracle
 kaedah pemadaman fail hiberfil
kaedah pemadaman fail hiberfil
 Bagaimana untuk menyelesaikan 400badrequest
Bagaimana untuk menyelesaikan 400badrequest
 sublime menjalankan kod js
sublime menjalankan kod js
 Apakah perbezaan antara telefon bimbit 4g dan 5g?
Apakah perbezaan antara telefon bimbit 4g dan 5g?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



