
 pembangunan bahagian belakang
Tutorial Python
Bagaimana untuk memanipulasi data teks menggunakan Python?
pembangunan bahagian belakang
Tutorial Python
Bagaimana untuk memanipulasi data teks menggunakan Python?
Bagaimana untuk memanipulasi data teks menggunakan Python?

Gunakan python untuk memproses data teks
Tujuan percubaan
Kenal dengan struktur data asas python, serta input dan output fail .
Data eksperimen
Menggunakan data penilaian dan tugasan penilaian persidangan pembelajaran mesin xx dalam xxxx Data termasuk set latihan dan set ujian lulus Data latihan yang diberikan, ramalkan sama ada hubungan dalam set ujian adalah contoh positif atau negatif, dan berikan 1 atau 0 pada akhir setiap sampel.
Data diterangkan seperti berikut Lajur pertama ialah jenis hubungan, lajur kedua dan ketiga ialah nama orang, lajur keempat ialah tajuk, lajur kelima ialah sama ada hubungan itu positif. atau contoh negatif, 1 ialah contoh positif, 0 ialah contoh negatif; lajur keenam mewakili set latihan.
| 事件 | 人物1 | 人物2 | 标题 | 关系(0 or 1) | 训练集 |
|---|
Set ujian diterangkan dalam rajah di bawah Format pada dasarnya serupa dengan set latihan Satu-satunya perbezaan ialah lajur kelima tidak mempunyai tanda yang berkaitan dengan contoh positif atau negatif.
| 关系 | 人物1 | 人物2 | 事件 |
|---|
Kandungan percubaan
Proses data set latihan, hanya meninggalkan lima lajur pertama dan teks output dinamakan exp1_1.txt.
Kelaskan 19 jenis perhubungan berdasarkan data yang diperoleh dalam langkah pertama Teks yang dijana disimpan dalam folder exp1_train Mengikut susunan kategori perhubungan yang muncul, data kategori perhubungan pertama ialah disimpan dalam 1 .txt, kategori hubungan kedua disimpan dalam 2.txt sehingga 19.txt.
Set ujian mengelaskan setiap sampel mengikut kategori hubungan dalam susunan 19 kategori set latihan, iaitu, data jenis hubungan yang sama dimasukkan ke dalam fail teks, dan fail ujian 19 kategori juga dijana Formatnya masih sama Selaras dengan fail ujian. Disimpan dalam folder exp1_test, fail setiap kategori masih dinamakan 1_test.txt, 2_test.txt... Pada masa yang sama, kedudukan setiap sampel dalam set ujian asal direkodkan dan sepadan dengan 19 fail ujian satu oleh seorang. Sebagai contoh, baris setiap sampel jenis pertama "perpecahan khabar angin" dalam teks asal direkodkan dalam fail indeks dan disimpan dalam fail index1.txt, index2.txt...
Idea Soalan Penyelesaian
1 Soalan pertama adalah untuk menguji pengetahuan kami tentang operasi dan senarai Kesukaran utama adalah untuk membaca fail baru selepas memprosesnya mengikut keperluan, kami akan menjana fail txt. Mari kita lihat pelaksanaan kod khusus:
import os
# 创建一个列表用来存储新的内容
list = []
with open("task1.trainSentence.new", "r",encoding='xxx') as file_input: # 打开.new文件,xxx根据自己的编码格式填写
with open("exp1_1.txt", "w", encoding='xxx') as file_output: # 打开exp1_1.txt,xxx根据自己的编码格式填写文件如果没有就创建一个
for Line in file_input: # 遍历每一行的文件
arr = Line.split('\t') # 以\t为分隔符读取
if arr[0] not in list: # if the word is not in the list
list.append(arr[0]) # add the word to the list
file_output.write(arr[0]+"\t"+arr[1]+"\t"+arr[2]+"\t"+arr[3]+"\t"+arr[4]+"\n") # write the line to the file
file_input.close() #关闭.new文件
file_output.close() #关闭创建的txt文件2. Soalan kedua masih meneliti operasi fail Berdasarkan fail yang dihasilkan dalam soalan 1, peristiwa dikelaskan mengikut jenis yang sama acara untuk melihat sama ada ia boleh dikumpulkan dengan cekap untuk menyelesaikan, mari kita lihat
pelaksanaan kod
import os
file_1 = open("exp1_1.txt", encoding='xxx') # 打开文件,xxx根据自己的编码格式填写
os.mkdir("exp1_train") # 创建目录
os.chdir("exp1_train") # 修改进程的工作目录(使用该目录)
a = file.readline() # 按行读取exp1_1.txt文件
arr = a.split("\t") # 按\t间隔符作为分割
b = 1 #设置分组文件的序列
file_2 = open("{}.txt".format(b), "w", encoding="xxx") # 打开文件,xxx根据自己的编码格式填写
for line in file_1: # 按行读取文件
arr_1 = line.split("\t") # 按\t间隔符作为分割
if arr[0] != arr_1[0]: # 如果读取文件的第一列内容与存入新文件的第一列类型不同
file_2.close() # 关掉该文件
b += 1 # 文件序列加一
f_2 = open("{}.txt".format(b), "w", encoding="xxx") # 创建新文件,以另一种类型分类,xxx根据自己的编码格式填写
arr = line.split("\t") # 按\t间隔符作为分割
f_2.write(arr[0]+"\t"+arr[1]+"\t"+arr[2]+"\t"+arr[3]+"t"+arr[4]+"\t""\n") # 将相同类型的文件写入
f_1.close() # 关闭题目一创建的exp1_1.txt文件
f_2.close() # 关闭创建的最后一个类型的文件3 kategori set latihan mengikut perhubungan antara watak, kita boleh merentasi data melalui kamus, mencari perhubungan, meletakkan kandungan dengan perhubungan yang sama ke dalam folder, dan mencipta yang baharu jika ia berbeza.
import os
with open("exp1_1.txt", encoding='xxx') as file_in1: # 打开文件,xxx根据自己的编码格式填写
i = 1 # 类型序列
arr2 = {} # 创建字典
for line in file_in1: # 按行遍历
arr3 = line[0:2] # 读取关系
if arr3 not in arr2.keys():
arr2[arr3] = i
i += 1 # 类型+1
file_in = open("task1.test.new") # 打开文件task1.test.new
os.mkdir("exp1_test") # 创建目录
os.chdir("exp1_test") # 修改进程的工作目录(使用该目录)
for line in file_in:
arr = line[0:2]
with open("{}_test.txt".format(arr2[arr]), "a", encoding='xxx') as file_out:
arr = line.split('\t')
file_out.write(line)
i = 1
file_in.seek(0)
os.mkdir("exp1_index")
os.chdir("exp1_index")
for line in file_in:
arr = line[0:2]
with open("index{}.txt".format(arr2[arr]), "a", encoding='xxx') as file_out:
arr = line.split('\t')
line = line[0:-1]
file_out.write(line + '\t' + "{}".format(i) + "\n")
i += 1Gunakan python untuk memproses data berangka
Tujuan percubaan
Kenal dengan struktur data asas python, serta input dan output fail.
Data eksperimen
Pertandingan xx Tianchi dalam xxx juga merupakan data Cabaran Data Besar ke-x universiti China. Data termasuk dua jadual, iaitu jadual tingkah laku pengguna mars_tianchi_user_actions.csv dan jadual artis lagu mars_tianchi_songs.csv. Pertandingan ini membuka sampel data artis lagu, serta rekod sejarah tingkah laku pengguna yang berkaitan dengan artis ini dalam tempoh 6 bulan (20150301-20150831). Peserta perlu meramalkan data main balik artis untuk 2 bulan akan datang, iaitu 60 hari (20150901-20151030).

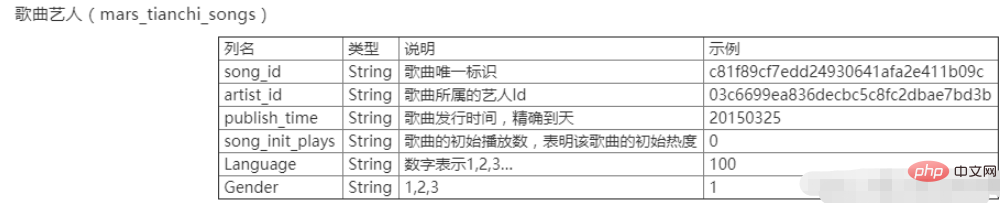

Kandungan percubaan
-
Proses data artis lagu mars_tianchi_songs dan kira bilangan artis dan bilangan lagu untuk setiap artis. Format fail output ialah exp2_1.csv Lajur pertama ialah ID artis dan lajur kedua ialah bilangan lagu oleh artis. Baris terakhir mengeluarkan bilangan artis.
Gabungkan jadual tingkah laku pengguna dan jadual artis lagu ke dalam satu jadual besar menggunakan song_id lagu sebagai persatuan. Nama lajur pertama hingga kelima bagi setiap lajur adalah konsisten dengan nama lajur jadual tingkah laku pengguna, dan nama lajur keenam hingga kesepuluh ialah nama lajur lajur kedua hingga keenam dalam jadual artis lagu. Nama fail output ialah exp2_2.csv.
Mengikut statistik artis, volum main balik semua lagu setiap artis setiap hari dikira Fail output ialah exp2_3.csv. Setiap lajur dinamakan id artis, tarikh Ds dan jumlah kelantangan main balik lagu. Nota: Hanya bilangan lagu yang dimainkan dikira di sini, bukan bilangan muat turun dan koleksi.
Idea penyelesaian masalah: (menggunakan perpustakaan panda)
1.
(1) Gunakan .drop_duplicates() untuk memadamkan nilai pendua
(2) Gunakan .loc[:,‘artist_id’].value_counts() untuk mengetahui bilangan kali penyanyi itu mengulangi, iaitu bilangan lagu bagi setiap penyanyi
( 3) Gunakan .loc[:,‘ songs_id’].value_counts() Ketahui jika tiada lagu pendua
import pandas as pd data = pd.read_csv(r"C:\mars_tianchi_songs.csv") # 读取数据 Newdata = data.drop_duplicates(subset=['artist_id']) # 删除重复值 artist_sum = Newdata['artist_id'].count() #artistChongFu_count = data.duplicated(subset=['artist_id']).count() artistChongFu_count = data.loc[:,'artist_id'].value_counts() 重复次数,即每个歌手的歌曲数目 songChongFu_count = data.loc[:,'songs_id'].value_counts() # 没有重复(歌手) artistChongFu_count.loc['artist_sum'] = artist_sum # 没有重复(歌曲)artistChongFu_count.to_csv('exp2_1.csv') # 输出文件格式为exp2_1.csv
Gunakan merge() untuk menggabungkan dua jadual
import pandas as pd import os data = pd.read_csv(r"C:\mars_tianchi_songs.csv") data_two = pd.read_csv(r"C:\mars_tianchi_user_actions.csv") num=pd.merge(data_two, data) num.to_csv('exp2_2.csv')
Gunakan groupby( )[].sum() untuk penambahan berulang
import pandas as pd data =pd.read_csv('exp2_2.csv') DataCHongfu = data.groupby(['artist_id','Ds'])['gmt_create'].sum()#重复项相加DataCHongfu.to_csv('exp2_3.csv')
Atas ialah kandungan terperinci Bagaimana untuk memanipulasi data teks menggunakan Python?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Adakah Mysql perlu membayar
Apr 08, 2025 pm 05:36 PM
Adakah Mysql perlu membayar
Apr 08, 2025 pm 05:36 PM
MySQL mempunyai versi komuniti percuma dan versi perusahaan berbayar. Versi komuniti boleh digunakan dan diubahsuai secara percuma, tetapi sokongannya terhad dan sesuai untuk aplikasi dengan keperluan kestabilan yang rendah dan keupayaan teknikal yang kuat. Edisi Enterprise menyediakan sokongan komersil yang komprehensif untuk aplikasi yang memerlukan pangkalan data yang stabil, boleh dipercayai, berprestasi tinggi dan bersedia membayar sokongan. Faktor yang dipertimbangkan apabila memilih versi termasuk kritikal aplikasi, belanjawan, dan kemahiran teknikal. Tidak ada pilihan yang sempurna, hanya pilihan yang paling sesuai, dan anda perlu memilih dengan teliti mengikut keadaan tertentu.
 Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Artikel ini memperkenalkan operasi pangkalan data MySQL. Pertama, anda perlu memasang klien MySQL, seperti MySqlworkbench atau Command Line Client. 1. Gunakan perintah MySQL-Uroot-P untuk menyambung ke pelayan dan log masuk dengan kata laluan akaun root; 2. Gunakan CreateTatabase untuk membuat pangkalan data, dan gunakan Pilih pangkalan data; 3. Gunakan createtable untuk membuat jadual, menentukan medan dan jenis data; 4. Gunakan InsertInto untuk memasukkan data, data pertanyaan, kemas kini data dengan kemas kini, dan padam data dengan padam. Hanya dengan menguasai langkah -langkah ini, belajar menangani masalah biasa dan mengoptimumkan prestasi pangkalan data anda boleh menggunakan MySQL dengan cekap.
 Kaedah Navicat untuk melihat kata laluan pangkalan data MongoDB
Apr 08, 2025 pm 09:39 PM
Kaedah Navicat untuk melihat kata laluan pangkalan data MongoDB
Apr 08, 2025 pm 09:39 PM
Tidak mustahil untuk melihat kata laluan MongoDB secara langsung melalui Navicat kerana ia disimpan sebagai nilai hash. Cara mendapatkan kata laluan yang hilang: 1. Tetapkan semula kata laluan; 2. Periksa fail konfigurasi (mungkin mengandungi nilai hash); 3. Semak Kod (boleh kata laluan Hardcode).
 Adakah mysql memerlukan internet
Apr 08, 2025 pm 02:18 PM
Adakah mysql memerlukan internet
Apr 08, 2025 pm 02:18 PM
MySQL boleh berjalan tanpa sambungan rangkaian untuk penyimpanan dan pengurusan data asas. Walau bagaimanapun, sambungan rangkaian diperlukan untuk interaksi dengan sistem lain, akses jauh, atau menggunakan ciri -ciri canggih seperti replikasi dan clustering. Di samping itu, langkah -langkah keselamatan (seperti firewall), pengoptimuman prestasi (pilih sambungan rangkaian yang betul), dan sandaran data adalah penting untuk menyambung ke Internet.
 Bagaimana untuk mengoptimumkan prestasi MySQL untuk aplikasi beban tinggi?
Apr 08, 2025 pm 06:03 PM
Bagaimana untuk mengoptimumkan prestasi MySQL untuk aplikasi beban tinggi?
Apr 08, 2025 pm 06:03 PM
Panduan Pengoptimuman Prestasi Pangkalan Data MySQL Dalam aplikasi yang berintensifkan sumber, pangkalan data MySQL memainkan peranan penting dan bertanggungjawab untuk menguruskan urus niaga besar-besaran. Walau bagaimanapun, apabila skala aplikasi berkembang, kemunculan prestasi pangkalan data sering menjadi kekangan. Artikel ini akan meneroka satu siri strategi pengoptimuman prestasi MySQL yang berkesan untuk memastikan aplikasi anda tetap cekap dan responsif di bawah beban tinggi. Kami akan menggabungkan kes-kes sebenar untuk menerangkan teknologi utama yang mendalam seperti pengindeksan, pengoptimuman pertanyaan, reka bentuk pangkalan data dan caching. 1. Reka bentuk seni bina pangkalan data dan seni bina pangkalan data yang dioptimumkan adalah asas pengoptimuman prestasi MySQL. Berikut adalah beberapa prinsip teras: Memilih jenis data yang betul dan memilih jenis data terkecil yang memenuhi keperluan bukan sahaja dapat menjimatkan ruang penyimpanan, tetapi juga meningkatkan kelajuan pemprosesan data.
 Hadidb: Pangkalan data yang ringan dan berskala mendatar di Python
Apr 08, 2025 pm 06:12 PM
Hadidb: Pangkalan data yang ringan dan berskala mendatar di Python
Apr 08, 2025 pm 06:12 PM
Hadidb: Pangkalan data Python yang ringan, tinggi, Hadidb (Hadidb) adalah pangkalan data ringan yang ditulis dalam Python, dengan tahap skalabilitas yang tinggi. Pasang HadIdb menggunakan pemasangan PIP: Pengurusan Pengguna PipInstallHadidB Buat Pengguna: CreateUser () Kaedah untuk membuat pengguna baru. Kaedah pengesahan () mengesahkan identiti pengguna. dariHadidb.OperationImportuserer_Obj = user ("admin", "admin") user_obj.
 Bolehkah Mysql Workbench menyambung ke Mariadb
Apr 08, 2025 pm 02:33 PM
Bolehkah Mysql Workbench menyambung ke Mariadb
Apr 08, 2025 pm 02:33 PM
MySQL Workbench boleh menyambung ke MariaDB, dengan syarat bahawa konfigurasi adalah betul. Mula -mula pilih "MariaDB" sebagai jenis penyambung. Dalam konfigurasi sambungan, tetapkan host, port, pengguna, kata laluan, dan pangkalan data dengan betul. Apabila menguji sambungan, periksa bahawa perkhidmatan MariaDB dimulakan, sama ada nama pengguna dan kata laluan betul, sama ada nombor port betul, sama ada firewall membenarkan sambungan, dan sama ada pangkalan data itu wujud. Dalam penggunaan lanjutan, gunakan teknologi penyatuan sambungan untuk mengoptimumkan prestasi. Kesilapan biasa termasuk kebenaran yang tidak mencukupi, masalah sambungan rangkaian, dan lain -lain. Apabila kesilapan debugging, dengan teliti menganalisis maklumat ralat dan gunakan alat penyahpepijatan. Mengoptimumkan konfigurasi rangkaian dapat meningkatkan prestasi
 Adakah mysql memerlukan pelayan
Apr 08, 2025 pm 02:12 PM
Adakah mysql memerlukan pelayan
Apr 08, 2025 pm 02:12 PM
Untuk persekitaran pengeluaran, pelayan biasanya diperlukan untuk menjalankan MySQL, atas alasan termasuk prestasi, kebolehpercayaan, keselamatan, dan skalabilitas. Pelayan biasanya mempunyai perkakasan yang lebih kuat, konfigurasi berlebihan dan langkah keselamatan yang lebih ketat. Untuk aplikasi kecil, rendah, MySQL boleh dijalankan pada mesin tempatan, tetapi penggunaan sumber, risiko keselamatan dan kos penyelenggaraan perlu dipertimbangkan dengan teliti. Untuk kebolehpercayaan dan keselamatan yang lebih besar, MySQL harus digunakan di awan atau pelayan lain. Memilih konfigurasi pelayan yang sesuai memerlukan penilaian berdasarkan beban aplikasi dan jumlah data.
