
 Peranti teknologi
AI
ChatGPT: Gabungan model berkuasa, mekanisme perhatian dan pembelajaran pengukuhan
Peranti teknologi
AI
ChatGPT: Gabungan model berkuasa, mekanisme perhatian dan pembelajaran pengukuhan
ChatGPT: Gabungan model berkuasa, mekanisme perhatian dan pembelajaran pengukuhan

Artikel ini terutamanya memperkenalkan model pembelajaran mesin yang memperkasakan ChatGPT Ia akan bermula dengan pengenalan model bahasa berskala besar, menyelidiki mekanisme perhatian diri yang revolusioner yang membolehkan GPT-3 dilatih, dan kemudian menyelidiki peneguhan. belajar daripada maklum balas manusia ialah teknologi baharu yang menjadikan ChatGPT cemerlang.
Model Bahasa Besar
ChatGPT ialah sejenis model pemprosesan bahasa semula jadi pembelajaran mesin untuk inferens, dipanggil model bahasa besar (LLM). LLM mencerna sejumlah besar data teks dan membuat kesimpulan hubungan antara perkataan dalam teks. Sejak beberapa tahun kebelakangan ini, model ini terus berkembang seiring dengan kemajuan kuasa pengkomputeran. Apabila saiz set data input dan ruang parameter bertambah, keupayaan LLM juga meningkat.
Latihan paling asas bagi model bahasa melibatkan meramalkan perkataan dalam urutan perkataan. Selalunya, ini diperhatikan untuk ramalan token seterusnya dan model bahasa penyamaran.
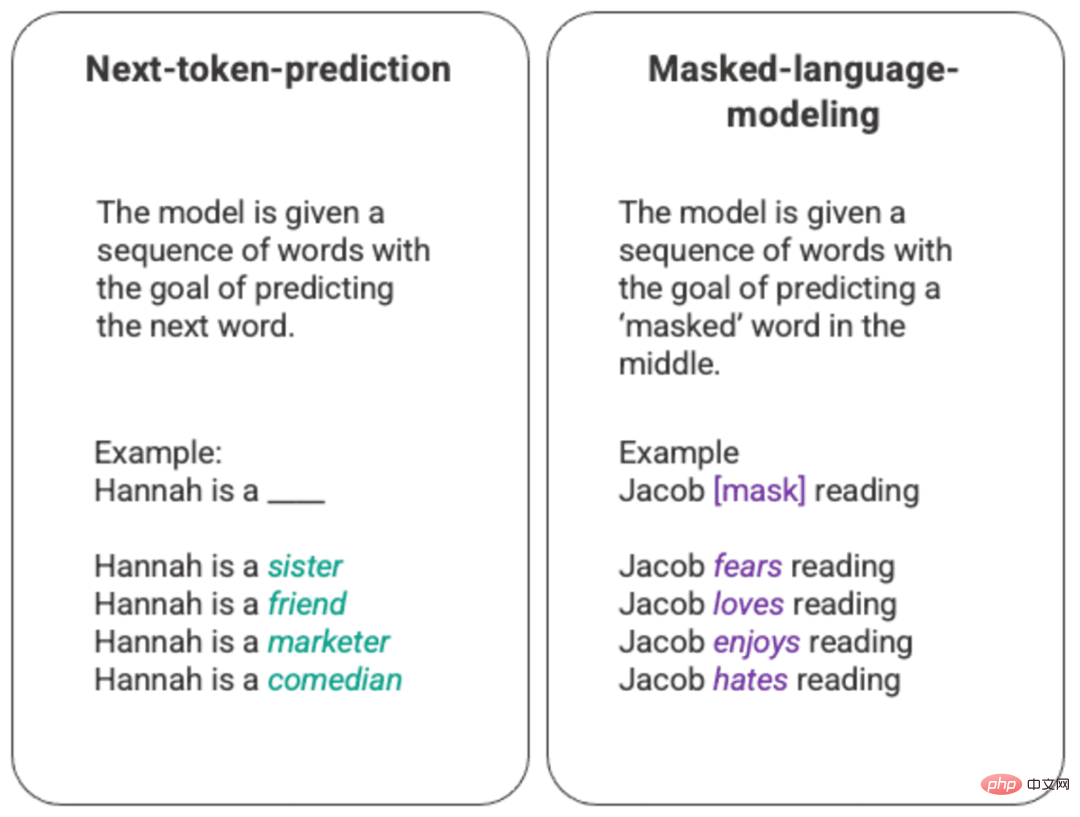
Contoh arbitrari ramalan token seterusnya yang dihasilkan dan model bahasa bertopeng
Dalam teknik pemeringkatan asas ini, biasanya melalui model long short memory (LSTM) ), yang mengisi kekosongan dengan perkataan yang berkemungkinan besar secara statistik memandangkan persekitaran dan konteks. Struktur pemodelan berjujukan ini mempunyai dua batasan utama.
- Model gagal memberi lebih berat kepada beberapa perkataan sekeliling daripada yang lain. Dalam contoh di atas, walaupun "membaca" mungkin paling kerap dikaitkan dengan "benci", dalam pangkalan data "Jacob" mungkin seorang pembaca yang gemar dan model harus menghargai "Jacob" lebih daripada "Jacob" Read" dan pilih "cinta" atas "kebencian".
- Data input diproses secara individu dan secara berurutan, bukannya secara keseluruhan korpus. Ini bermakna apabila melatih LSTM, tetingkap konteks ditetapkan dan hanya melangkaui satu input untuk beberapa langkah dalam jujukan. Ini mengehadkan kerumitan hubungan antara perkataan dan makna yang boleh dilukis.
Untuk menangani masalah ini, pada tahun 2017, pasukan di Google Brain memperkenalkan penukar. Tidak seperti LSTM, pengubah boleh memproses semua data input secara serentak. Dengan menggunakan mekanisme perhatian kendiri, model boleh menetapkan pemberat yang berbeza kepada bahagian data input yang berbeza berbanding mana-mana kedudukan dalam jujukan bahasa. Ciri ini membolehkan penambahbaikan berskala besar dalam menyuntik makna ke dalam LLM dan keupayaan untuk mengendalikan set data yang lebih besar.
GPT dan Perhatian Diri
Model Generative Pretrained Transformer (GPT) pertama kali dilancarkan oleh OpenAI pada 2018 dan dinamakan GPT -1 . Model ini terus berkembang dalam GPT-2 pada 2019, GPT-3 pada 2020, dan yang terbaru, InstructGPT dan ChatGPT pada 2022. Sebelum memasukkan maklum balas manusia ke dalam sistem, kemajuan terbesar dalam evolusi model GPT didorong oleh pencapaian dalam kecekapan pengiraan, yang membolehkan GPT-3 melatih lebih banyak data daripada GPT-2, memberikannya lebih banyak pangkalan pengetahuan yang pelbagai dan keupayaan untuk melaksanakan pelbagai tugasan yang lebih luas.

Perbandingan GPT-2 (kiri) dan GPT-3 (kanan).
Semua model GPT menggunakan struktur pengubah, yang bermaksud mereka mempunyai pengekod untuk memproses urutan input dan penyahkod untuk menjana jujukan output. Kedua-dua pengekod dan penyahkod menampilkan mekanisme perhatian kendiri berbilang kepala, membolehkan model menimbang pelbagai bahagian jujukan secara berbeza untuk membuat kesimpulan makna dan konteks. Selain itu, pengekod menggunakan model bahasa bertopeng untuk memahami hubungan antara perkataan dan menghasilkan respons yang lebih mudah difahami.
Mekanisme perhatian diri yang mendorong GPT berfungsi dengan menukar token (serpihan teks, yang boleh menjadi perkataan, ayat atau kumpulan teks lain) kepada vektor yang mewakili kepentingan token dalam urutan input. Untuk melakukan ini, model ini:
- 1. Buat vektor
query,keydanvalueuntuk setiap token dalam jujukan input. - 2 Kira persamaan antara vektor
querydalam langkah 1 dankeyvektor antara satu sama lain dengan mengambil hasil darab titik kedua-dua vektor. - 3. Hasilkan pemberat normal dengan memasukkan output langkah 2 ke dalam fungsi
softmax. - 4 Dengan mendarab berat yang dihasilkan dalam langkah 3 dengan vektor
valuesetiap teg, vektor akhir dihasilkan yang mewakili kepentingan teg dalam jujukan.
Mekanisme perhatian "multi-head" yang digunakan oleh GPT ialah evolusi perhatian diri. Daripada melaksanakan langkah 1-4 sekaligus, model ini mengulangi mekanisme ini beberapa kali secara selari, setiap kali menghasilkan unjuran linear baharu bagi vektor query, key dan value. Dengan memanjangkan perhatian diri dengan cara ini, model ini dapat memahami sub-makna dan hubungan yang lebih kompleks dalam data input.

Tangkapan skrin dijana daripada ChatGPT.
Walaupun GPT-3 memperkenalkan kemajuan ketara dalam pemprosesan bahasa semula jadi, ia terhad dalam keupayaannya untuk menyelaraskan dengan niat pengguna. Sebagai contoh, GPT-3 mungkin menghasilkan output berikut:
- Tidak membantu, bermakna mereka tidak mengikut arahan eksplisit daripada pengguna.
- Mengandungi ilusi yang mencerminkan fakta yang tidak wujud atau tidak betul.
- Kekurangan kebolehtafsiran menyukarkan manusia untuk memahami cara model itu mencapai keputusan atau ramalan tertentu.
- Mengandungi kandungan berbahaya atau menyinggung perasaan dan kandungan berbahaya atau berat sebelah yang menyebarkan maklumat salah.
Kaedah latihan yang inovatif diperkenalkan dalam ChatGPT untuk mengimbangi beberapa masalah yang wujud dalam LLM standard.
ChatGPT
ChatGPT ialah terbitan InstructGPT yang memperkenalkan pendekatan baru untuk memasukkan maklum balas manusia ke dalam proses latihan untuk menjadikan model Output disepadukan dengan lebih baik dengan niat pengguna. Pembelajaran pengukuhan daripada maklum balas manusia (RLHF) diterangkan secara mendalam dalam kertas kerja openAI 2022 "Melatih model bahasa untuk mengikuti arahan dengan maklum balas manusia" dan diterangkan secara ringkas di bawah.
Langkah 1: Model Penyeliaan Penalaan Halus (SFT)
Pembangunan pertama melibatkan penalaan halus model GPT-3, menggunakan 40 kontraktor untuk mencipta set data latihan yang diselia di mana input mempunyai output yang diketahui untuk dipelajari oleh model. Input atau gesaan dikumpulkan daripada input pengguna sebenar kepada API terbuka. Penanda kemudian menulis respons yang sesuai kepada gesaan, mencipta output yang diketahui untuk setiap input. Model GPT-3 kemudiannya diperhalusi menggunakan set data diselia baharu ini untuk mencipta GPT-3.5, juga dikenali sebagai model SFT.
Untuk memaksimumkan kepelbagaian set data gesaan, hanya 200 gesaan boleh datang daripada mana-mana ID pengguna tertentu dan sebarang gesaan yang berkongsi awalan biasa yang panjang dialih keluar. Akhirnya, semua petua yang mengandungi maklumat pengenalan peribadi (PII) telah dialih keluar.
Selepas mengagregatkan maklumat segera daripada OpenAI API, pelabel juga diminta membuat sampel maklumat segera untuk mengisi kategori tersebut dengan data sampel sebenar yang sangat sedikit. Kategori untuk diikuti termasuk:
- Petua Umum: Sebarang pertanyaan rawak.
- Petua Kecil: Arahan yang mengandungi berbilang pasangan pertanyaan/jawapan.
- Petua berasaskan pengguna: sepadan dengan kes penggunaan khusus yang diminta untuk API OpenAI.
Apabila menjana respons, penanda dikehendaki melakukan yang terbaik untuk membuat kesimpulan tentang arahan pengguna. Dokumen ini menerangkan tiga cara utama di mana gesaan boleh meminta maklumat.
- Langsung: "Beritahu saya tentang..."
- Beberapa perkataan: Beri contoh dua cerita ini, tulis cerita lain tentang topik yang sama.
- Sambungan: Berikan permulaan cerita dan selesaikannya.
Kompilasi gesaan daripada OpenAI API dan gesaan tulisan tangan daripada pelabel, menghasilkan 13,000 sampel input/output untuk digunakan dalam model yang diselia.
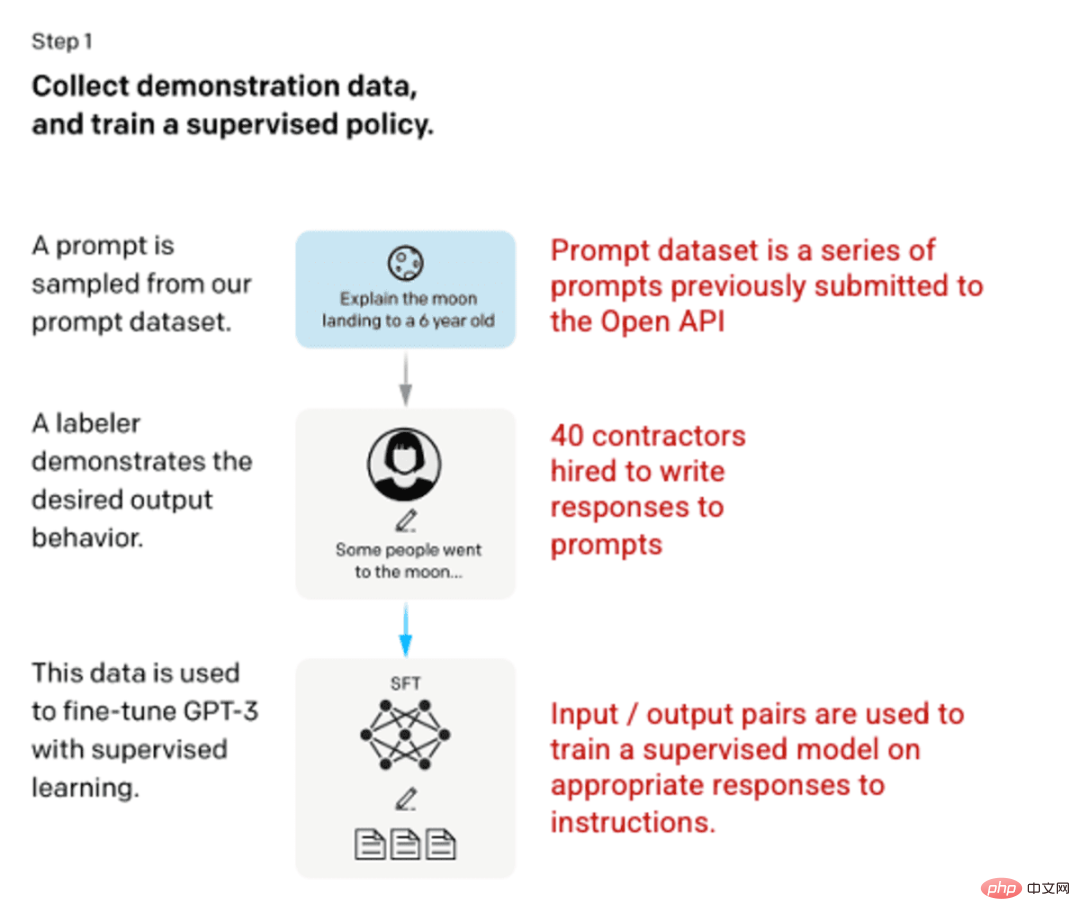
Gambar (kiri) disisipkan daripada "Melatih model bahasa untuk mengikut arahan dengan maklum balas manusia" OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155. pdf. (Kanan) Konteks tambahan ditambah dengan warna merah.
Langkah 2: Model Ganjaran
Selepas melatih model SFT dalam langkah 1, model menghasilkan gesaan yang lebih baik untuk pengguna , respons yang konsisten. Penambahbaikan seterusnya datang dalam bentuk model ganjaran latihan, di mana input kepada model adalah urutan isyarat dan tindak balas, dan output adalah nilai berskala yang dipanggil ganjaran. Model ganjaran diperlukan untuk memanfaatkan Pembelajaran Pengukuhan, di mana model belajar untuk menghasilkan output yang memaksimumkan ganjarannya (lihat langkah 3).
Untuk melatih model ganjaran, pelabel menyediakan 4 hingga 9 output model SFT kepada gesaan input tunggal. Mereka diminta untuk menilai keluaran ini daripada yang terbaik kepada yang terburuk, mencipta kombinasi berperingkat keluaran seperti ini:

Contoh gabungan berperingkat respons.
Memasukkan setiap gabungan dalam model sebagai titik data yang berasingan membawa kepada overfitting (ketidakupayaan untuk mengekstrapolasi melebihi data yang dilihat). Untuk menyelesaikan masalah ini, model dibina menggunakan setiap set kedudukan sebagai kumpulan titik data yang berasingan.
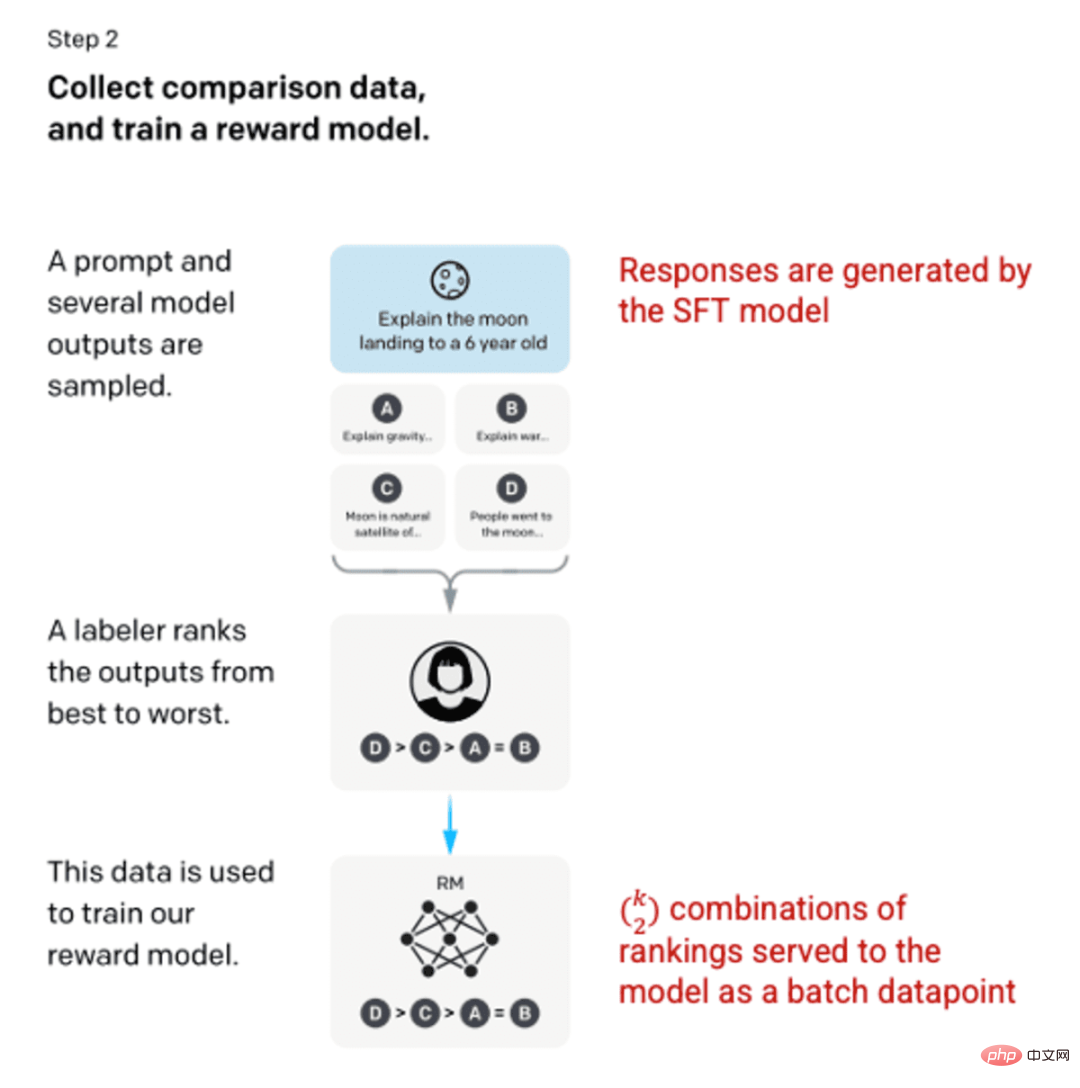
Gambar (kiri) disisipkan daripada "Melatih model bahasa untuk mengikut arahan dengan maklum balas manusia" OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155. pdf. (Kanan) Konteks tambahan ditambah dengan warna merah.
Langkah 3: Model Pembelajaran Pengukuhan
Pada peringkat akhir, gesaan rawak dibentangkan kepada model dan respons dikembalikan. Respons dijana menggunakan "dasar" yang dipelajari oleh model dalam langkah 2. Dasar ini mewakili strategi yang telah dipelajari oleh mesin untuk mencapai matlamatnya dalam kes ini, memaksimumkan ganjarannya. Berdasarkan model ganjaran yang dibangunkan dalam langkah 2, nilai ganjaran berskala kemudian ditentukan untuk pasangan isyarat dan tindak balas. Ganjaran kemudiannya dimasukkan semula ke dalam model untuk membangunkan strategi.
Pada 2017, Schulman et al memperkenalkan pengoptimuman dasar proksimal (PPO), kaedah untuk mengemas kini dasar model apabila setiap respons dijana. PPO menggabungkan penalti Kullback-Leibler (KL) dalam model SFT. Perbezaan KL mengukur persamaan dua fungsi pengedaran dan menghukum jarak yang melampau. Dalam kes ini, menggunakan penalti KL boleh mengurangkan jarak tindak balas daripada output model SFT yang dilatih dalam langkah 1 untuk mengelakkan terlalu mengoptimumkan model ganjaran dan menyimpang terlalu banyak daripada set data niat manusia.
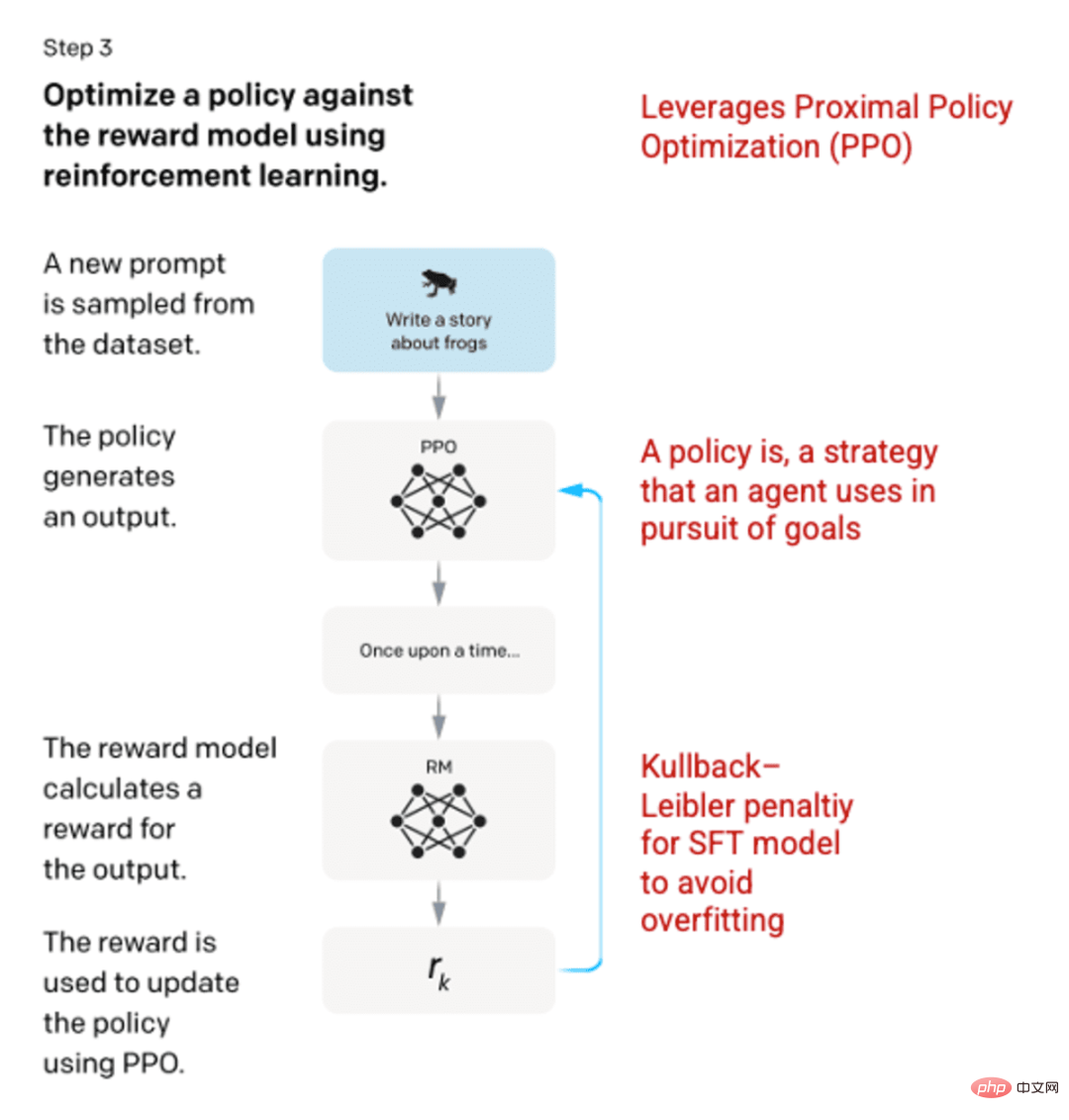
Gambar (kiri) disisipkan daripada "Melatih model bahasa untuk mengikut arahan dengan maklum balas manusia" OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155. pdf. (Kanan) Konteks tambahan ditambah dengan warna merah.
Langkah 2 dan 3 proses boleh diulang berulang kali, walaupun ini belum lagi dilakukan secara meluas dalam amalan.

Tangkapan skrin dijana daripada ChatGPT.
Penilaian model
Penilaian model dilakukan dengan menempah set ujian yang model tidak pernah lihat semasa latihan. Pada set ujian, satu siri penilaian dijalankan untuk menentukan sama ada model berprestasi lebih baik daripada pendahulunya, GPT-3.
Kebergunaan: Keupayaan model untuk membuat kesimpulan dan mengikut arahan pengguna. Pelabel lebih suka output InstructGPT daripada GPT-3 85±3% sepanjang masa.
Keaslian: Kecenderungan model untuk berhalusinasi. Apabila dinilai menggunakan set data TruthfulQA, output yang dihasilkan oleh model PPO menunjukkan peningkatan kecil dalam kedua-dua realisme dan bermaklumat.
Ketidakmudaratan: Keupayaan model untuk mengelakkan kandungan yang tidak sesuai, menghina dan memfitnah. Ketidakmudaratan diuji menggunakan set data RealToxicityPrompts. Ujian dijalankan di bawah tiga keadaan.
- Arahan memberikan respons yang hormat: membawa kepada pengurangan ketara dalam tindak balas berbahaya.
- Arahan memberikan reaksi tanpa sebarang tetapan berkenaan penghormatan: Tiada perubahan ketara dalam bahaya.
- Panduan menyediakan tindak balas yang berbahaya: tindak balas sebenarnya jauh lebih berbahaya daripada model GPT-3.
Untuk mendapatkan maklumat lanjut tentang kaedah yang digunakan untuk mencipta ChatGPT dan InstructGPT, sila baca kertas asal "Melatih model bahasa untuk mengikuti arahan dengan maklum balas manusia" yang diterbitkan oleh OpenAI, 2022 https:// arxiv .org/pdf/2203.02155.pdf.
Tangkapan skrin dijana daripada ChatGPT.
Atas ialah kandungan terperinci ChatGPT: Gabungan model berkuasa, mekanisme perhatian dan pembelajaran pengukuhan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 ChatGPT kini membenarkan pengguna percuma menjana imej dengan menggunakan DALL-E 3 dengan had harian
Aug 09, 2024 pm 09:37 PM
ChatGPT kini membenarkan pengguna percuma menjana imej dengan menggunakan DALL-E 3 dengan had harian
Aug 09, 2024 pm 09:37 PM
DALL-E 3 telah diperkenalkan secara rasmi pada September 2023 sebagai model yang jauh lebih baik daripada pendahulunya. Ia dianggap sebagai salah satu penjana imej AI terbaik setakat ini, mampu mencipta imej dengan perincian yang rumit. Walau bagaimanapun, semasa pelancaran, ia adalah tidak termasuk
 Artikel ini akan membawa anda memahami SHAP: penjelasan model untuk pembelajaran mesin
Jun 01, 2024 am 10:58 AM
Artikel ini akan membawa anda memahami SHAP: penjelasan model untuk pembelajaran mesin
Jun 01, 2024 am 10:58 AM
Dalam bidang pembelajaran mesin dan sains data, kebolehtafsiran model sentiasa menjadi tumpuan penyelidik dan pengamal. Dengan aplikasi meluas model yang kompleks seperti kaedah pembelajaran mendalam dan ensemble, memahami proses membuat keputusan model menjadi sangat penting. AI|XAI yang boleh dijelaskan membantu membina kepercayaan dan keyakinan dalam model pembelajaran mesin dengan meningkatkan ketelusan model. Meningkatkan ketelusan model boleh dicapai melalui kaedah seperti penggunaan meluas pelbagai model yang kompleks, serta proses membuat keputusan yang digunakan untuk menerangkan model. Kaedah ini termasuk analisis kepentingan ciri, anggaran selang ramalan model, algoritma kebolehtafsiran tempatan, dsb. Analisis kepentingan ciri boleh menerangkan proses membuat keputusan model dengan menilai tahap pengaruh model ke atas ciri input. Anggaran selang ramalan model
 Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Cabaran biasa yang dihadapi oleh algoritma pembelajaran mesin dalam C++ termasuk pengurusan memori, multi-threading, pengoptimuman prestasi dan kebolehselenggaraan. Penyelesaian termasuk menggunakan penunjuk pintar, perpustakaan benang moden, arahan SIMD dan perpustakaan pihak ketiga, serta mengikuti garis panduan gaya pengekodan dan menggunakan alat automasi. Kes praktikal menunjukkan cara menggunakan perpustakaan Eigen untuk melaksanakan algoritma regresi linear, mengurus memori dengan berkesan dan menggunakan operasi matriks berprestasi tinggi.
 AI yang boleh dijelaskan: Menerangkan model AI/ML yang kompleks
Jun 03, 2024 pm 10:08 PM
AI yang boleh dijelaskan: Menerangkan model AI/ML yang kompleks
Jun 03, 2024 pm 10:08 PM
Penterjemah |. Disemak oleh Li Rui |. Chonglou Model kecerdasan buatan (AI) dan pembelajaran mesin (ML) semakin kompleks hari ini, dan output yang dihasilkan oleh model ini adalah kotak hitam – tidak dapat dijelaskan kepada pihak berkepentingan. AI Boleh Dijelaskan (XAI) bertujuan untuk menyelesaikan masalah ini dengan membolehkan pihak berkepentingan memahami cara model ini berfungsi, memastikan mereka memahami cara model ini sebenarnya membuat keputusan, dan memastikan ketelusan dalam sistem AI, Amanah dan akauntabiliti untuk menyelesaikan masalah ini. Artikel ini meneroka pelbagai teknik kecerdasan buatan (XAI) yang boleh dijelaskan untuk menggambarkan prinsip asasnya. Beberapa sebab mengapa AI boleh dijelaskan adalah penting Kepercayaan dan ketelusan: Untuk sistem AI diterima secara meluas dan dipercayai, pengguna perlu memahami cara keputusan dibuat
 Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Pembelajaran mesin ialah cabang penting kecerdasan buatan yang memberikan komputer keupayaan untuk belajar daripada data dan meningkatkan keupayaan mereka tanpa diprogramkan secara eksplisit. Pembelajaran mesin mempunyai pelbagai aplikasi dalam pelbagai bidang, daripada pengecaman imej dan pemprosesan bahasa semula jadi kepada sistem pengesyoran dan pengesanan penipuan, dan ia mengubah cara hidup kita. Terdapat banyak kaedah dan teori yang berbeza dalam bidang pembelajaran mesin, antaranya lima kaedah yang paling berpengaruh dipanggil "Lima Sekolah Pembelajaran Mesin". Lima sekolah utama ialah sekolah simbolik, sekolah sambungan, sekolah evolusi, sekolah Bayesian dan sekolah analogi. 1. Simbolisme, juga dikenali sebagai simbolisme, menekankan penggunaan simbol untuk penaakulan logik dan ekspresi pengetahuan. Aliran pemikiran ini percaya bahawa pembelajaran adalah proses penolakan terbalik, melalui sedia ada
 Adakah Flash Attention stabil? Meta dan Harvard mendapati bahawa sisihan berat model mereka berubah-ubah mengikut urutan magnitud
May 30, 2024 pm 01:24 PM
Adakah Flash Attention stabil? Meta dan Harvard mendapati bahawa sisihan berat model mereka berubah-ubah mengikut urutan magnitud
May 30, 2024 pm 01:24 PM
MetaFAIR bekerjasama dengan Harvard untuk menyediakan rangka kerja penyelidikan baharu untuk mengoptimumkan bias data yang dijana apabila pembelajaran mesin berskala besar dilakukan. Adalah diketahui bahawa latihan model bahasa besar sering mengambil masa berbulan-bulan dan menggunakan ratusan atau bahkan ribuan GPU. Mengambil model LLaMA270B sebagai contoh, latihannya memerlukan sejumlah 1,720,320 jam GPU. Melatih model besar memberikan cabaran sistemik yang unik disebabkan oleh skala dan kerumitan beban kerja ini. Baru-baru ini, banyak institusi telah melaporkan ketidakstabilan dalam proses latihan apabila melatih model AI generatif SOTA Mereka biasanya muncul dalam bentuk lonjakan kerugian Contohnya, model PaLM Google mengalami sehingga 20 lonjakan kerugian semasa proses latihan. Bias berangka adalah punca ketidaktepatan latihan ini,
 Pembelajaran Mesin dalam C++: Panduan untuk Melaksanakan Algoritma Pembelajaran Mesin Biasa dalam C++
Jun 03, 2024 pm 07:33 PM
Pembelajaran Mesin dalam C++: Panduan untuk Melaksanakan Algoritma Pembelajaran Mesin Biasa dalam C++
Jun 03, 2024 pm 07:33 PM
Dalam C++, pelaksanaan algoritma pembelajaran mesin termasuk: Regresi linear: digunakan untuk meramalkan pembolehubah berterusan Langkah-langkah termasuk memuatkan data, mengira berat dan berat sebelah, mengemas kini parameter dan ramalan. Regresi logistik: digunakan untuk meramalkan pembolehubah diskret Proses ini serupa dengan regresi linear, tetapi menggunakan fungsi sigmoid untuk ramalan. Mesin Vektor Sokongan: Algoritma klasifikasi dan regresi yang berkuasa yang melibatkan pengkomputeran vektor sokongan dan label ramalan.
 SearchGPT: Open AI mengambil alih Google dengan enjin carian AInya sendiri
Jul 30, 2024 am 09:58 AM
SearchGPT: Open AI mengambil alih Google dengan enjin carian AInya sendiri
Jul 30, 2024 am 09:58 AM
Open AI akhirnya membuat cariannya. Syarikat San Francisco baru-baru ini telah mengumumkan alat AI baharu dengan keupayaan carian. Pertama kali dilaporkan oleh The Information pada Februari tahun ini, alat baharu ini dipanggil SearchGPT dan menampilkan c
