

HuggingGPT: Alat ajaib untuk tugas AI

Pengenalan
Kecerdasan Am Buatan (AGI) boleh dianggap sebagai sistem kecerdasan buatan yang mampu memahami, memproses dan bertindak balas terhadap tugas intelektual seperti manusia. Ini adalah tugas yang mencabar yang memerlukan pemahaman yang mendalam tentang bagaimana otak manusia berfungsi supaya kita boleh menirunya. Walau bagaimanapun, kemunculan ChatGPT telah menimbulkan minat yang besar daripada komuniti penyelidik dalam membangunkan sistem tersebut. Microsoft telah mengeluarkan sistem dipacu AI utama yang dipanggil HuggingGPT (Microsoft Jarvis).
Sebelum kita menyelami perkara baharu dalam HuggingGPT dan butiran yang berkaitan tentang cara ia berfungsi, mari kita fahami dahulu isu dengan ChatGPT dan sebab ia menghadapi kesukaran menyelesaikan tugasan AI yang kompleks. Model bahasa besar seperti ChatGPT pandai mentafsir data teks dan mengendalikan tugas umum. Walau bagaimanapun, mereka sering bergelut dengan tugas tertentu dan boleh bertindak balas dengan tidak masuk akal. Anda mungkin telah menemui jawapan palsu daripada ChatGPT semasa menyelesaikan masalah matematik yang rumit. Sebaliknya, kami mempunyai model AI peringkat pakar seperti Stable Diffusion dan DALL-E, yang mempunyai pemahaman yang lebih mendalam tentang bidang subjek masing-masing tetapi bergelut dengan pelbagai tugas yang lebih luas. Melainkan kami mewujudkan hubungan antara LLM dan model AI profesional, kami tidak dapat mengeksploitasi sepenuhnya potensi LLM untuk menyelesaikan tugas AI yang mencabar. Inilah yang dilakukan oleh HuggingGPT, ia menggabungkan kelebihan kedua-duanya untuk mencipta sistem AI yang lebih berkesan, tepat dan serba boleh.
Apakah itu HuggingGPT?
Menurut kertas baru-baru ini yang diterbitkan oleh Microsoft, HuggingGPT memanfaatkan kuasa LLM, menggunakannya sebagai pengawal untuk menyambungkannya dengan pelbagai model AI dalam komuniti pembelajaran mesin (HuggingFace), membolehkannya digunakan Alat luaran untuk meningkatkan produktiviti. HuggingFace ialah tapak web yang menyediakan banyak alat dan sumber kepada pembangun dan penyelidik. Ia juga mempunyai pelbagai jenis model profesional dan berketepatan tinggi. HuggingGPT menggunakan model ini untuk tugas AI yang kompleks dalam domain dan mod yang berbeza, mencapai hasil yang mengagumkan. Ia mempunyai keupayaan berbilang modal yang sama seperti OPenAI GPT-4 apabila ia berkaitan dengan teks dan imej. Walau bagaimanapun, ia juga menghubungkan anda ke Internet, dan anda boleh menyediakan pautan web luaran untuk bertanya soalan mengenainya.
Andaikan anda mahu model melakukan bacaan audio teks yang ditulis pada imej. HuggingGPT akan melaksanakan tugas ini secara bersiri menggunakan model yang paling sesuai. Pertama, ia akan mengeksport teks daripada imej dan menggunakan hasilnya untuk penjanaan audio. Butiran respons boleh dilihat dalam imej di bawah. Sungguh menakjubkan!

Analisis kualitatif kerjasama multimodal mod video dan audio
Bagaimanakah HuggingGPT berfungsi?
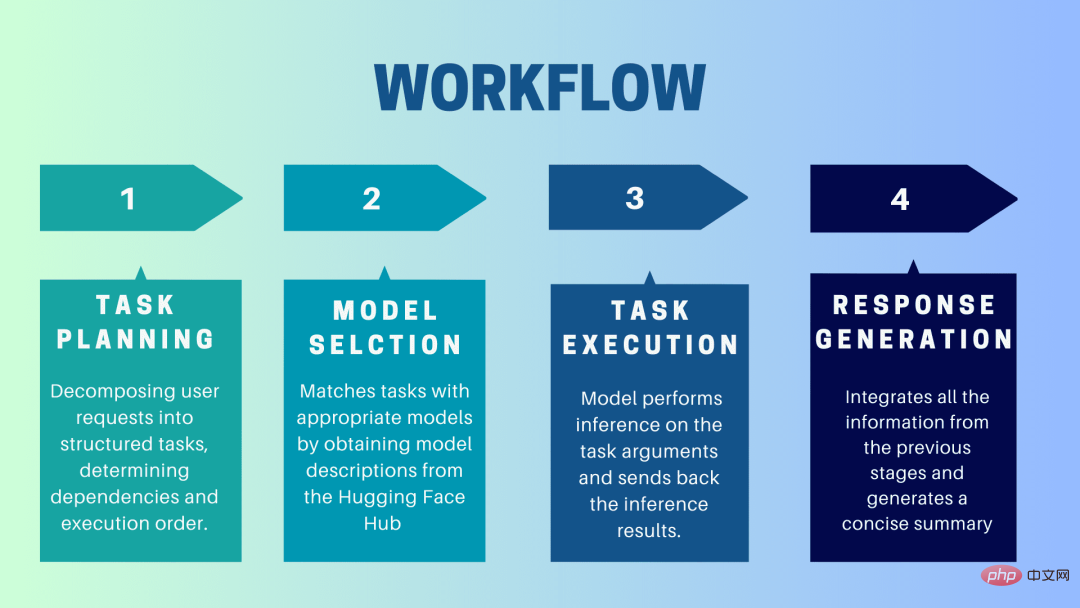
HuggingGPT ialah sistem kerjasama yang menggunakan LLM sebagai antara muka untuk menghantar permintaan pengguna kepada model pakar. Proses lengkap daripada gesaan pengguna kepada model sehingga respons diterima boleh diuraikan kepada langkah-langkah diskret berikut:
1 Perancangan tugas
Pada peringkat ini, HuggingGPT menggunakan ChatGPT untuk memahami gesaan pengguna, Kemudian pecahkan pertanyaan kepada tugasan kecil yang boleh diambil tindakan. Ia juga mengenal pasti kebergantungan tugas ini dan mentakrifkan susunan tugasan tersebut dilaksanakan. HuggingGPT mempunyai empat slot untuk penghuraian tugas, iaitu jenis tugasan, ID tugasan, kebergantungan tugas dan parameter tugas. Sembang antara HuggingGPT dan pengguna direkodkan dan dipaparkan pada skrin yang menunjukkan sejarah sumber.
2. Pemilihan model
Berdasarkan persekitaran pengguna dan model yang tersedia, HuggingGPT menggunakan mekanisme peruntukan model tugas kontekstual untuk memilih model yang paling sesuai untuk tugasan tertentu. Mengikut mekanisme ini, pemilihan model dianggap sebagai soalan aneka pilihan, yang pada mulanya menapis model berdasarkan jenis tugasan. Selepas itu, model telah disenaraikan berdasarkan bilangan muat turun, kerana ia dianggap sebagai ukuran kualiti model yang boleh dipercayai. Model Top-K dipilih berdasarkan kedudukan ini. K di sini hanyalah pemalar yang mencerminkan bilangan model, sebagai contoh, jika ia ditetapkan kepada 3, maka ia akan memilih 3 model dengan paling banyak muat turun.
3. Pelaksanaan tugasan
Di sini, tugasan diberikan kepada model tertentu, yang melakukan inferens padanya dan mengembalikan hasilnya. Untuk menjadikan proses ini lebih cekap, HuggingGPT boleh menjalankan model yang berbeza secara serentak, selagi mereka tidak memerlukan sumber yang sama. Contohnya, jika diberi gesaan untuk menjana gambar kucing dan anjing, model yang berbeza boleh dijalankan secara selari untuk melaksanakan tugas ini. Walau bagaimanapun, kadangkala model mungkin memerlukan sumber yang sama, itulah sebabnya HuggingGPT mengekalkan atribut
4. Hasilkan respons
Langkah terakhir ialah menjana respons kepada pengguna. Pertama, ia menyepadukan semua maklumat dan hasil penaakulan daripada peringkat sebelumnya. Maklumat dipersembahkan dalam format berstruktur. Contohnya, jika gesaan adalah untuk mengesan bilangan singa dalam imej, ia akan melukis kotak sempadan yang sesuai dengan kebarangkalian pengesanan. LLM (ChatGPT) kemudian mengambil format ini dan menjadikannya dalam bahasa mesra manusia.
Sediakan HuggingGPT
HuggingGPT dibina pada seni bina GPT-3.5 Hugging Face yang terkini, iaitu model rangkaian saraf dalam yang boleh menjana teks bahasa semula jadi. Berikut ialah langkah bagaimana untuk menyediakannya pada mesin tempatan anda:
Keperluan Sistem
Konfigurasi lalai memerlukan Ubuntu 16.04 LTS, sekurang-kurangnya 24GB VRAM, sekurang-kurangnya 12GB (minimum), 16GB (standard) atau 80GB (penuh) RAM, dan sekurang-kurangnya 284GB ruang cakera. Selain itu, 42GB ruang diperlukan untuk damo-vilab/text-to-video-ms-1.7b, 126GB untuk ControlNet, 66GB untuk stable-diffusion-v1-5 dan 50GB untuk sumber lain. Untuk konfigurasi "lite", hanya Ubuntu 16.04 LTS diperlukan.
Langkah untuk bermula
Mula-mula, gantikan OpenAI Key dan Hugging Face Token dalam fail server/configs/config.default.yaml dengan kunci anda. Sebagai alternatif, anda boleh meletakkannya dalam pembolehubah persekitaran OPENAI_API_KEY dan HUGGINGFACE_ACCESS_TOKEN masing-masing
Jalankan arahan berikut:
Untuk Pelayan:
- Sediakan persekitaran Python dan pasang kebergantungan yang diperlukan.
<code># 设置环境cd serverconda create -n jarvis pythnotallow=3.8conda activate jarvisconda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidiapip install -r requirements.txt</code>
- Muat turun model yang diperlukan.
<code># 下载模型。确保`git-lfs`已经安装。cd modelsbash download.sh # required when `inference_mode` is `local` or `hybrid`.</code>
- Jalankan pelayan
<code># 运行服务器cd ..python models_server.py --config configs/config.default.yaml # required when `inference_mode` is `local` or `hybrid`python awesome_chat.py --config configs/config.default.yaml --mode server # for text-davinci-003</code>
Kini anda boleh mengakses perkhidmatan Jarvis dengan menghantar permintaan HTTP ke titik akhir API Web. Hantar permintaan kepada:
- /hugginggpt endpoint dan gunakan kaedah POST untuk mengakses perkhidmatan lengkap.
- /tasks endpoint, gunakan kaedah POST untuk mengakses hasil perantaraan fasa 1.
- /hasil titik akhir, gunakan kaedah POST untuk mengakses keputusan perantaraan peringkat 1-3.
Permintaan ini hendaklah dalam format JSON dan harus mengandungi senarai maklumat yang dimasukkan bagi pihak pengguna.
Untuk Web:
- Selepas melancarkan aplikasi awesome_chat.py dalam mod pelayan, pasang nod js dan npm pada komputer anda.
- Navigasi ke direktori web dan pasang kebergantungan berikut:
<code>cd webnpm installnpm run dev</code>
- Tetapkan http://{LAN_IP_of_the_server}:{port}/ to web/src/config/ HUGGINGGPT_BASE_URL untuk index.ts, sekiranya anda menjalankan klien web pada mesin lain.
- Jika anda ingin menggunakan fungsi penjanaan video, sila susun ffmpeg secara manual dengan H.264.
<code># 可选:安装 ffmpeg# 这个命令需要在没有错误的情况下执行。LD_LIBRARY_PATH=/usr/local/lib /usr/local/bin/ffmpeg -i input.mp4 -vcodec libx264 output.mp4</code>
- Klik dua kali ikon tetapan untuk bertukar kembali ke ChatGPT.
Untuk CLI:
Menyediakan Jarvis menggunakan CLI adalah sangat mudah. Jalankan sahaja arahan yang dinyatakan di bawah:
<code>cd serverpython awesome_chat.py --config configs/config.default.yaml --mode cli</code>
Untuk Gradio:
Demo gradio juga dihoskan pada Ruang Wajah Memeluk. Anda boleh mencuba selepas memasukkan OPENAI_API_KEY dan HUGGINGFACE_ACCESS_TOKEN.
Untuk menjalankannya secara setempat:
- Pasang kebergantungan yang diperlukan, klon repositori projek daripada Hugging Face Space dan navigasi ke direktori projek
- gunakan Perintah berikut untuk memulakan pelayan model dan kemudian mulakan demo Gradio:
<code>python models_server.py --config configs/config.gradio.yamlpython run_gradio_demo.py --config configs/config.gradio.yaml</code>
- Akses demo melalui http://localhost:7860 dalam penyemak imbas anda dan mengujinya dengan memasukkan pelbagai input
- Sebagai pilihan, anda juga boleh menjalankan demo sebagai imej Docker dengan menjalankan arahan berikut:
<code>docker run -it -p 7860:7860 --platform=linux/amd64 registry.hf.space/microsoft-hugginggpt:latest python app.py</code>
Nota: Jika anda mempunyai sebarang soalan, sila rujuk Github Repo rasmi (https: //github.com/microsoft/JARVIS).
Fikiran Akhir
HuggingGPT juga mempunyai batasan tertentu yang perlu ditekankan di sini. Sebagai contoh, kecekapan sistem adalah halangan utama, dan HuggingGPT memerlukan berbilang interaksi dengan LLM pada semua peringkat yang dinyatakan sebelum ini. Interaksi ini boleh mengakibatkan pengalaman pengguna yang terdegradasi dan peningkatan kependaman. Begitu juga, panjang konteks maksimum dihadkan oleh bilangan token yang dibenarkan. Isu lain ialah kebolehpercayaan sistem, kerana LLM mungkin salah tafsir gesaan dan menghasilkan urutan tugas yang salah, yang seterusnya menjejaskan keseluruhan proses. Walau bagaimanapun, ia mempunyai potensi besar untuk menyelesaikan tugas AI yang kompleks dan merupakan kemajuan yang baik untuk AGI. Mari kita nantikan hala tuju penyelidikan ini akan membawa masa depan AI!
Atas ialah kandungan terperinci HuggingGPT: Alat ajaib untuk tugas AI. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Perintah shutdown CentOS adalah penutupan, dan sintaks adalah tutup [pilihan] [maklumat]. Pilihan termasuk: -h menghentikan sistem dengan segera; -P mematikan kuasa selepas penutupan; -r mulakan semula; -T Waktu Menunggu. Masa boleh ditentukan sebagai segera (sekarang), minit (minit), atau masa tertentu (HH: mm). Maklumat tambahan boleh dipaparkan dalam mesej sistem.
 Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Dasar sandaran dan pemulihan Gitlab di bawah sistem CentOS untuk memastikan keselamatan data dan pemulihan, Gitlab pada CentOS menyediakan pelbagai kaedah sandaran. Artikel ini akan memperkenalkan beberapa kaedah sandaran biasa, parameter konfigurasi dan proses pemulihan secara terperinci untuk membantu anda menubuhkan strategi sandaran dan pemulihan GitLab lengkap. 1. Backup Manual Gunakan Gitlab-Rakegitlab: Backup: Buat Perintah untuk Melaksanakan Backup Manual. Perintah ini menyokong maklumat utama seperti repositori Gitlab, pangkalan data, pengguna, kumpulan pengguna, kunci, dan kebenaran. Fail sandaran lalai disimpan dalam direktori/var/opt/gitlab/sandaran. Anda boleh mengubah suai /etc /gitlab
 Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Panduan Lengkap untuk Memeriksa Konfigurasi HDFS Dalam Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk memeriksa konfigurasi dan menjalankan status HDFS secara berkesan pada sistem CentOS. Langkah -langkah berikut akan membantu anda memahami sepenuhnya persediaan dan operasi HDFS. Sahkan Pembolehubah Alam Sekitar Hadoop: Pertama, pastikan pembolehubah persekitaran Hadoop ditetapkan dengan betul. Di terminal, laksanakan arahan berikut untuk mengesahkan bahawa Hadoop dipasang dan dikonfigurasi dengan betul: Hadoopversion Semak fail konfigurasi HDFS: Fail konfigurasi teras HDFS terletak di/etc/hadoop/conf/direktori, di mana core-site.xml dan hdfs-site.xml adalah kritikal. gunakan
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
Memasang MySQL pada CentOS melibatkan langkah -langkah berikut: Menambah sumber MySQL YUM yang sesuai. Jalankan YUM Pasang Perintah MySQL-Server untuk memasang pelayan MySQL. Gunakan perintah mysql_secure_installation untuk membuat tetapan keselamatan, seperti menetapkan kata laluan pengguna root. Sesuaikan fail konfigurasi MySQL seperti yang diperlukan. Tune parameter MySQL dan mengoptimumkan pangkalan data untuk prestasi.
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 CentOS8 memulakan semula SSH
Apr 14, 2025 pm 09:00 PM
CentOS8 memulakan semula SSH
Apr 14, 2025 pm 09:00 PM
Perintah untuk memulakan semula perkhidmatan SSH ialah: Sistem Restart SSHD. Langkah -langkah terperinci: 1. Akses terminal dan sambungkan ke pelayan; 2. Masukkan arahan: SistemCtl Restart SSHD; 3. Sahkan Status Perkhidmatan: Status Sistem SSHD.
 Cara Melihat Log Gitlab Di Bawah Centos
Apr 14, 2025 pm 06:18 PM
Cara Melihat Log Gitlab Di Bawah Centos
Apr 14, 2025 pm 06:18 PM
Panduan Lengkap untuk Melihat Log Gitlab Di bawah Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk melihat pelbagai log Gitlab dalam sistem CentOS, termasuk log utama, log pengecualian, dan log lain yang berkaitan. Sila ambil perhatian bahawa laluan fail log mungkin berbeza -beza bergantung pada versi GitLab dan kaedah pemasangan. Jika laluan berikut tidak wujud, sila semak fail Direktori Pemasangan dan Konfigurasi GitLab. 1. Lihat log Gitlab utama Gunakan arahan berikut untuk melihat fail log utama aplikasi GitLabRails: Perintah: Sudocat/var/Log/Gitlab/Gitlab-Rails/Production.log Perintah ini akan memaparkan produk
