
 Peranti teknologi
AI
Pasukan Zhu Jun memperoleh sumber terbuka model penyebaran pelbagai mod berskala besar pertama berdasarkan Transformer di Universiti Tsinghua, dan ia telah siap sepenuhnya selepas penulisan semula teks dan imej.
Peranti teknologi
AI
Pasukan Zhu Jun memperoleh sumber terbuka model penyebaran pelbagai mod berskala besar pertama berdasarkan Transformer di Universiti Tsinghua, dan ia telah siap sepenuhnya selepas penulisan semula teks dan imej.
Pasukan Zhu Jun memperoleh sumber terbuka model penyebaran pelbagai mod berskala besar pertama berdasarkan Transformer di Universiti Tsinghua, dan ia telah siap sepenuhnya selepas penulisan semula teks dan imej.

Dilaporkan bahawa GPT-4 akan dikeluarkan minggu ini, dan pelbagai mod akan menjadi salah satu sorotannya. Model bahasa besar semasa menjadi antara muka universal untuk memahami pelbagai modaliti dan boleh memberikan teks balasan berdasarkan maklumat modal yang berbeza Walau bagaimanapun, kandungan yang dihasilkan oleh model bahasa besar hanya terhad kepada teks. Sebaliknya, model resapan semasa DALL・E 2, Imagen, Stable Diffusion, dsb. telah mencetuskan revolusi dalam penciptaan visual, tetapi model ini hanya menyokong satu fungsi silang mod dari teks ke imej dan masih jauh. daripada model generatif sejagat. Model besar multi-modal akan dapat membuka keupayaan pelbagai modaliti dan merealisasikan penukaran antara mana-mana modaliti, yang dianggap sebagai hala tuju pembangunan masa depan model generatif sejagat.
Pasukan TSAIL yang diketuai oleh Profesor Zhu Jun dari Jabatan Sains Komputer di Universiti Tsinghua baru-baru ini menerbitkan kertas kerja "Satu Transformer Sesuai Semua Pengagihan dalam Resapan Pelbagai Modal pada Skala", yang yang pertama menerbitkan multi-modal Beberapa kerja penerokaan pada model generatif telah membolehkan transformasi bersama antara mod arbitrari.

Pautan kertas: https://ml.cs. tsinghua.edu.cn/diffusion/unidiffuser.pdf
Kod sumber terbuka: https://github.com/thu-ml/unidiffuser
Pengarang pertama kertas kerja ini, Bao Fan, kini merupakan pelajar kedoktoran. Beliau adalah pencadang Analytic-DPM sebelum ini hanya satu) untuk kerja cemerlangnya dalam model penyebaran yang memenangi anugerah yang disiapkan secara bebas oleh unit tanah besar).
Selain itu, Machine Heart sebelum ini telah melaporkan algoritma pantas DPM-Solver yang dicadangkan oleh pasukan TSAIL, yang masih merupakan algoritma penjanaan terpantas untuk model resapan. Model besar berbilang modal ialah paparan tertumpu pengumpulan algoritma dan prinsip mendalam jangka panjang pasukan model probabilistik dalam. Kolaborator dalam kerja ini termasuk Li Chongxuan dari Sekolah Kecerdasan Buatan Hillhouse Universiti Renmin, Cao Yue dari Institut Penyelidikan Zhiyuan Beijing dan lain-lain.
 Perlu diingat bahawa kertas dan kod projek ini adalah sumber terbuka.
Perlu diingat bahawa kertas dan kod projek ini adalah sumber terbuka.
Paparan kesan
Rajah 8 di bawah menunjukkan kesan UniDiffuser pada penjanaan bersama imej dan teks:
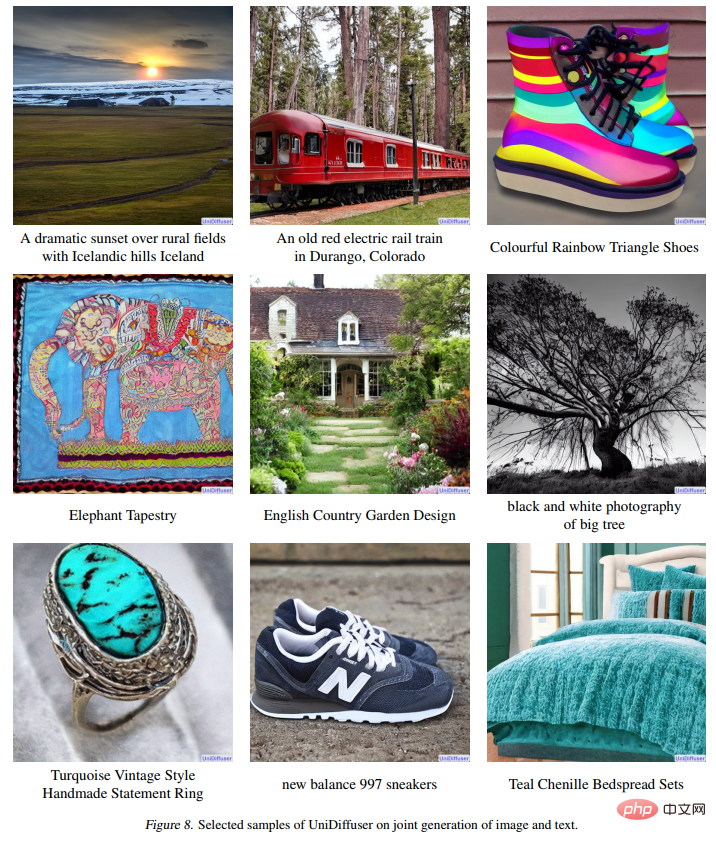 Rajah 9 di bawah menunjukkan kesan UniDiffuser pada teks-ke-gambar:
Rajah 9 di bawah menunjukkan kesan UniDiffuser pada teks-ke-gambar:
 Rajah 10 berikut menunjukkan kesan UniDiffuser pada imej-ke-teks:
Rajah 10 berikut menunjukkan kesan UniDiffuser pada imej-ke-teks:
 Rajah berikut 11 Menunjukkan kesan UniDiffuser pada penjanaan imej tanpa syarat:
Rajah berikut 11 Menunjukkan kesan UniDiffuser pada penjanaan imej tanpa syarat:
Rajah 12 di bawah menunjukkan kesan UniDiffuser pada penulisan semula imej:

Rajah 15 berikut menunjukkan bahawa UniDiffuser boleh melompat ke sana ke mari antara dua mod grafik dan teks:

seperti yang ditunjukkan dalam Rajah 16 di bawah UniDiffuser boleh menginterpolasi dua imej sebenar:
Tinjauan Keseluruhan Kaedah
Pasukan penyelidik membahagikan reka bentuk model generatif umum kepada dua sub-masalah:
- Rangka kerja pemodelan kebarangkalian: Adakah mungkin untuk mencari rangka kerja pemodelan kebarangkalian yang boleh memodelkan semua pengedaran antara mod pada masa yang sama, seperti pengedaran tepi antara imej dan teks , pengedaran bersyarat, pengedaran bersama, dan lain-lain?
- Seni bina rangkaian: Bolehkah seni bina rangkaian bersatu direka bentuk untuk menyokong pelbagai modaliti input?
Rangka kerja pemodelan kebarangkalian
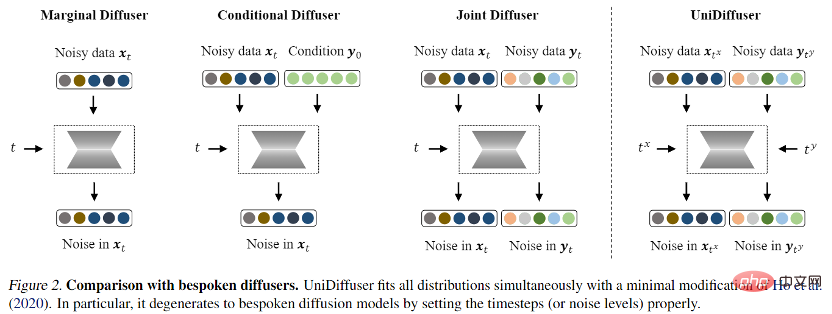
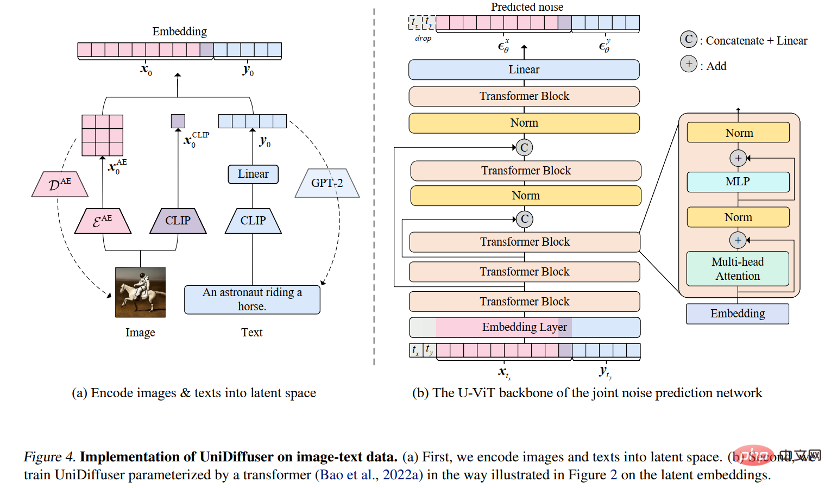
Untuk rangka kerja pemodelan kebarangkalian, pasukan penyelidik mencadangkan UniDiffuser, sebuah A rangka kerja pemodelan kebarangkalian untuk model resapan. UniDiffuser boleh memodelkan semua pengedaran dalam data berbilang mod secara eksplisit, termasuk pengedaran marginal, pengedaran bersyarat dan pengedaran bersama. Pasukan penyelidik mendapati bahawa pembelajaran model resapan tentang pengedaran berbeza boleh disatukan ke dalam satu perspektif: mula-mula menambah saiz hingar tertentu pada data dua modaliti, dan kemudian meramalkan hingar pada data dua modaliti. Jumlah hingar pada dua data modal menentukan pengedaran khusus. Sebagai contoh, menetapkan saiz hingar teks kepada 0 sepadan dengan taburan bersyarat bagi gambar rajah Vincentian, menetapkan saiz bunyi teks kepada nilai maksimum sepadan dengan taburan penjanaan imej tanpa syarat; teks dengan nilai yang sama sepadan dengan pengedaran penjanaan imej tanpa syarat. Mengikut perspektif bersatu ini, UniDiffuser hanya perlu membuat sedikit pengubahsuaian pada algoritma latihan model penyebaran asal untuk mempelajari semua pengedaran di atas pada masa yang sama - seperti yang ditunjukkan dalam rajah di bawah, UniDiffuser menambah hingar pada semua mod pada masa yang sama bukannya mod tunggal, masukkan magnitud hingar yang sepadan dengan semua mod, dan hingar yang diramalkan pada semua mod.
Mengambil mod bimodal sebagai contoh, fungsi objektif latihan terakhir adalah seperti berikut:
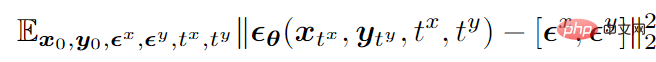
di mana

mewakili data ,

mewakili bunyi Gaussian standard yang ditambahkan pada dua mod,

mewakili saiz (iaitu, masa) bunyi yang ditambahkan oleh kedua-dua mod dan kedua-duanya diambil secara bebas daripada {1,2,…,T} ,
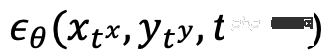
ialah rangkaian ramalan hingar yang meramalkan hingar pada dua modaliti secara serentak.
Selepas latihan, UniDiffuser dapat mencapai penjanaan tanpa syarat, bersyarat dan bersama dengan menetapkan dua modaliti kepada rangkaian ramalan hingar pada masa yang sesuai. Sebagai contoh, menetapkan masa teks kepada 0 boleh mencapai penjanaan teks ke imej; penjanaan bersama imej dan teks.
Algoritma latihan dan pensampelan UniDiffuser disenaraikan di bawah. Dapat dilihat bahawa algoritma ini hanya mempunyai perubahan kecil berbanding model penyebaran asal dan mudah untuk dilaksanakan.

Selain itu, kerana UniDiffuser memodelkan kedua-dua pengagihan bersyarat dan tanpa syarat, UniDiffuser secara semula jadi menyokong bimbingan tanpa pengelas . Rajah 3 di bawah menunjukkan kesan penjanaan bersyarat UniDiffuser dan penjanaan bersama di bawah skala bimbingan yang berbeza:

Seni Bina Rangkaian
Berkenaan dengan seni bina rangkaian, pasukan penyelidik mencadangkan untuk menggunakan seni bina berasaskan pengubah untuk parameter rangkaian ramalan hingar. Khususnya, pasukan penyelidik mengguna pakai seni bina U-ViT yang dicadangkan baru-baru ini. U-ViT menganggap semua input sebagai token dan menambah sambungan berbentuk U antara blok pengubah. Pasukan penyelidik juga menggunakan strategi Resapan Stabil untuk menukar data modaliti berbeza kepada ruang terpendam dan kemudian memodelkan model resapan. Perlu diingat bahawa seni bina U-ViT juga berasal dari pasukan penyelidikan ini dan telah bersumberkan terbuka di https://github.com/baoff/U-ViT.
Hasil eksperimen
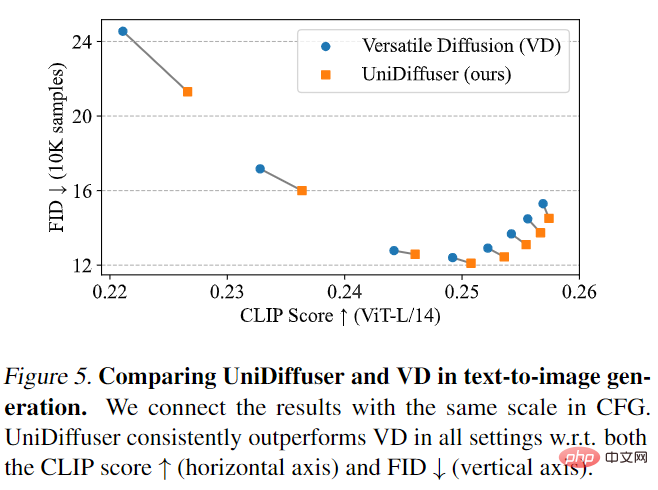
UniDiffuser terlebih dahulu berbanding dengan Versatile Diffusion. Resapan Serbaguna ialah model penyebaran pelbagai mod yang lalu berdasarkan rangka kerja berbilang tugas. Pertama, UniDiffuser dan Versatile Diffusion dibandingkan pada kesan teks-ke-imej. Seperti yang ditunjukkan dalam Rajah 5 di bawah, UniDiffuser adalah lebih baik daripada Resapan Serbaguna dalam kedua-dua Skor CLIP dan metrik FID di bawah skala panduan tanpa pengelas yang berbeza.
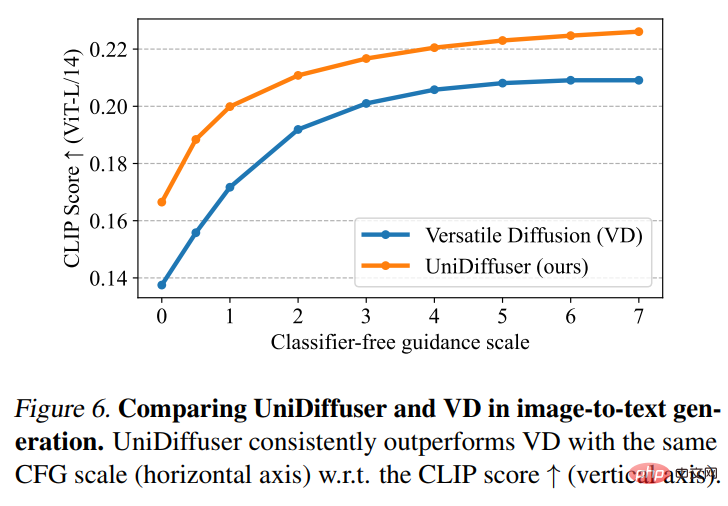
Kemudian UniDiffuser dan Versatile Diffusion melakukan perbandingan gambar-ke-teks. Seperti yang ditunjukkan dalam Rajah 6 di bawah, UniDiffuser mempunyai Skor CLIP yang lebih baik pada imej-ke-teks.
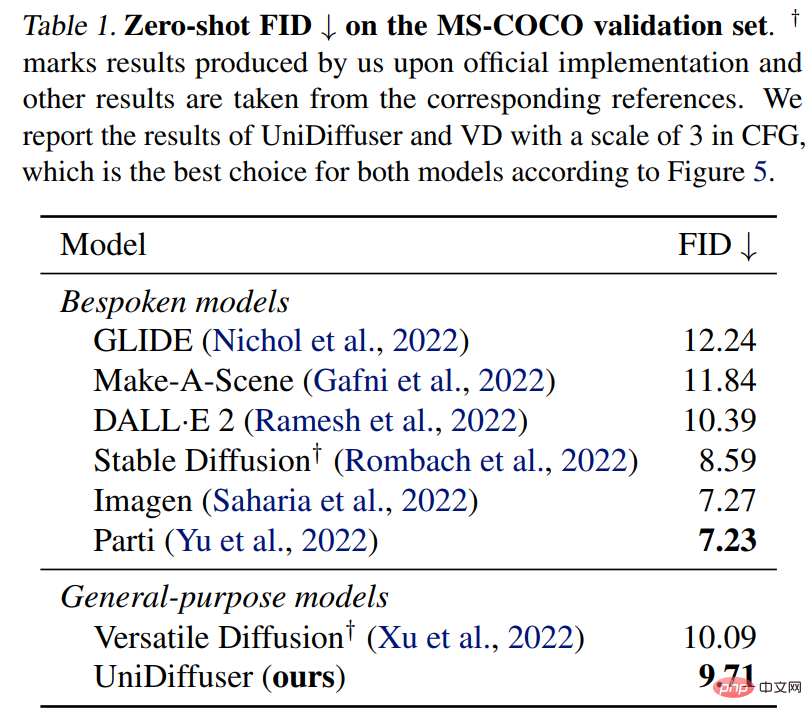
UniDiffuser juga dibandingkan dengan model teks-ke-graf khusus untuk FID tangkapan sifar pada MS-COCO. Seperti yang ditunjukkan dalam Jadual 1 di bawah, UniDiffuser boleh mencapai hasil yang setanding dengan model teks-ke-graf khusus.
Atas ialah kandungan terperinci Pasukan Zhu Jun memperoleh sumber terbuka model penyebaran pelbagai mod berskala besar pertama berdasarkan Transformer di Universiti Tsinghua, dan ia telah siap sepenuhnya selepas penulisan semula teks dan imej.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Di barisan hadapan teknologi perisian, kumpulan UIUC Zhang Lingming, bersama penyelidik dari organisasi BigCode, baru-baru ini mengumumkan model kod besar StarCoder2-15B-Instruct. Pencapaian inovatif ini mencapai kejayaan ketara dalam tugas penjanaan kod, berjaya mengatasi CodeLlama-70B-Instruct dan mencapai bahagian atas senarai prestasi penjanaan kod. Keunikan StarCoder2-15B-Instruct terletak pada strategi penjajaran diri yang tulen Keseluruhan proses latihan adalah terbuka, telus, dan sepenuhnya autonomi dan boleh dikawal. Model ini menjana beribu-ribu arahan melalui StarCoder2-15B sebagai tindak balas kepada penalaan halus model asas StarCoder-15B tanpa bergantung pada anotasi manual yang mahal.
 Yolov10: Penjelasan terperinci, penggunaan dan aplikasi semuanya di satu tempat!
Jun 07, 2024 pm 12:05 PM
Yolov10: Penjelasan terperinci, penggunaan dan aplikasi semuanya di satu tempat!
Jun 07, 2024 pm 12:05 PM
1. Pengenalan Sejak beberapa tahun kebelakangan ini, YOLO telah menjadi paradigma dominan dalam bidang pengesanan objek masa nyata kerana keseimbangannya yang berkesan antara kos pengiraan dan prestasi pengesanan. Penyelidik telah meneroka reka bentuk seni bina YOLO, matlamat pengoptimuman, strategi pengembangan data, dsb., dan telah mencapai kemajuan yang ketara. Pada masa yang sama, bergantung pada penindasan bukan maksimum (NMS) untuk pemprosesan pasca menghalang penggunaan YOLO dari hujung ke hujung dan memberi kesan buruk kepada kependaman inferens. Dalam YOLO, reka bentuk pelbagai komponen tidak mempunyai pemeriksaan yang komprehensif dan teliti, mengakibatkan lebihan pengiraan yang ketara dan mengehadkan keupayaan model. Ia menawarkan kecekapan suboptimum, dan potensi yang agak besar untuk peningkatan prestasi. Dalam kerja ini, matlamatnya adalah untuk meningkatkan lagi sempadan kecekapan prestasi YOLO daripada kedua-dua pasca pemprosesan dan seni bina model. sampai habis
 Universiti Tsinghua mengambil alih dan YOLOv10 keluar: prestasi telah bertambah baik dan ia berada dalam senarai panas GitHub
Jun 06, 2024 pm 12:20 PM
Universiti Tsinghua mengambil alih dan YOLOv10 keluar: prestasi telah bertambah baik dan ia berada dalam senarai panas GitHub
Jun 06, 2024 pm 12:20 PM
Siri penanda aras YOLO sistem pengesanan sasaran sekali lagi menerima peningkatan besar. Sejak pengeluaran YOLOv9 pada Februari tahun ini, baton siri YOLO (YouOnlyLookOnce) telah diserahkan kepada penyelidik di Universiti Tsinghua. Hujung minggu lalu, berita pelancaran YOLOv10 menarik perhatian komuniti AI. Ia dianggap sebagai rangka kerja terobosan dalam bidang penglihatan komputer dan terkenal dengan keupayaan pengesanan objek hujung ke hujung masa nyata, meneruskan legasi siri YOLO dengan menyediakan penyelesaian berkuasa yang menggabungkan kecekapan dan ketepatan. Alamat kertas: https://arxiv.org/pdf/2405.14458 Alamat projek: https://github.com/THU-MIG/yo
 Laporan teknikal Google Gemini 1.5: Buktikan soalan Olimpik Matematik dengan mudah, versi Flash adalah 5 kali lebih pantas daripada GPT-4 Turbo
Jun 13, 2024 pm 01:52 PM
Laporan teknikal Google Gemini 1.5: Buktikan soalan Olimpik Matematik dengan mudah, versi Flash adalah 5 kali lebih pantas daripada GPT-4 Turbo
Jun 13, 2024 pm 01:52 PM
Pada bulan Februari tahun ini, Google melancarkan model besar berbilang modal Gemini 1.5, yang telah meningkatkan prestasi dan kelajuan dengan sangat baik melalui pengoptimuman kejuruteraan dan infrastruktur, seni bina MoE dan strategi lain. Dengan konteks yang lebih panjang, keupayaan penaakulan yang lebih kukuh dan pengendalian kandungan merentas modal yang lebih baik. Jumaat ini, Google DeepMind secara rasmi mengeluarkan laporan teknikal Gemini 1.5, yang merangkumi versi Flash dan peningkatan terkini yang lain Dokumen itu sepanjang 153 halaman. Pautan laporan teknikal: https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf Dalam laporan ini, Google memperkenalkan Gemini1
 Bagaimana untuk menilai keberkesanan kos sokongan komersial untuk rangka kerja Java
Jun 05, 2024 pm 05:25 PM
Bagaimana untuk menilai keberkesanan kos sokongan komersial untuk rangka kerja Java
Jun 05, 2024 pm 05:25 PM
Menilai kos/prestasi sokongan komersial untuk rangka kerja Java melibatkan langkah-langkah berikut: Tentukan tahap jaminan yang diperlukan dan jaminan perjanjian tahap perkhidmatan (SLA). Pengalaman dan kepakaran pasukan sokongan penyelidikan. Pertimbangkan perkhidmatan tambahan seperti peningkatan, penyelesaian masalah dan pengoptimuman prestasi. Timbang kos sokongan perniagaan terhadap pengurangan risiko dan peningkatan kecekapan.
 Semakan! Ringkaskan secara menyeluruh peranan penting model asas dalam mempromosikan pemanduan autonomi
Jun 11, 2024 pm 05:29 PM
Semakan! Ringkaskan secara menyeluruh peranan penting model asas dalam mempromosikan pemanduan autonomi
Jun 11, 2024 pm 05:29 PM
Ditulis di atas & pemahaman peribadi pengarang: Baru-baru ini, dengan perkembangan dan penemuan teknologi pembelajaran mendalam, model asas berskala besar (Model Asas) telah mencapai hasil yang ketara dalam bidang pemprosesan bahasa semula jadi dan penglihatan komputer. Aplikasi model asas dalam pemanduan autonomi juga mempunyai prospek pembangunan yang hebat, yang boleh meningkatkan pemahaman dan penaakulan senario. Melalui pra-latihan tentang bahasa yang kaya dan data visual, model asas boleh memahami dan mentafsir pelbagai elemen dalam senario pemanduan autonomi dan melakukan penaakulan, menyediakan arahan bahasa dan tindakan untuk memacu membuat keputusan dan perancangan. Model asas boleh ditambah data dengan pemahaman senario pemanduan untuk menyediakan ciri-ciri yang jarang berlaku dalam pengedaran ekor panjang yang tidak mungkin ditemui semasa pemanduan rutin dan pengumpulan data.
 Bagaimanakah keluk pembelajaran rangka kerja PHP berbanding rangka kerja bahasa lain?
Jun 06, 2024 pm 12:41 PM
Bagaimanakah keluk pembelajaran rangka kerja PHP berbanding rangka kerja bahasa lain?
Jun 06, 2024 pm 12:41 PM
Keluk pembelajaran rangka kerja PHP bergantung pada kecekapan bahasa, kerumitan rangka kerja, kualiti dokumentasi dan sokongan komuniti. Keluk pembelajaran rangka kerja PHP adalah lebih tinggi jika dibandingkan dengan rangka kerja Python dan lebih rendah jika dibandingkan dengan rangka kerja Ruby. Berbanding dengan rangka kerja Java, rangka kerja PHP mempunyai keluk pembelajaran yang sederhana tetapi masa yang lebih singkat untuk bermula.
 Bagaimanakah pilihan rangka kerja PHP yang ringan mempengaruhi prestasi aplikasi?
Jun 06, 2024 am 10:53 AM
Bagaimanakah pilihan rangka kerja PHP yang ringan mempengaruhi prestasi aplikasi?
Jun 06, 2024 am 10:53 AM
Rangka kerja PHP yang ringan meningkatkan prestasi aplikasi melalui saiz kecil dan penggunaan sumber yang rendah. Ciri-cirinya termasuk: saiz kecil, permulaan pantas, penggunaan memori yang rendah, kelajuan dan daya tindak balas yang dipertingkatkan, dan penggunaan sumber yang dikurangkan: SlimFramework mencipta API REST, hanya 500KB, responsif yang tinggi dan daya pemprosesan yang tinggi.
