
 pembangunan bahagian belakang
Tutorial Python
Bagaimana untuk menggunakan multiprocessing untuk melaksanakan komunikasi antara proses dalam Python?
pembangunan bahagian belakang
Tutorial Python
Bagaimana untuk menggunakan multiprocessing untuk melaksanakan komunikasi antara proses dalam Python?
Bagaimana untuk menggunakan multiprocessing untuk melaksanakan komunikasi antara proses dalam Python?

1. Mengapakah kita harus menguasai komunikasi antara proses
Kecekapan kod berbilang benang Python dihadkan oleh GIL dan tidak boleh dipercepatkan oleh berbilang teras? CPU, manakala berbilang proses Kaedah ini boleh memintas GIL, memanfaatkan pecutan berbilang CPU, dan meningkatkan prestasi program dengan ketara
Tetapi komunikasi antara proses adalah isu yang mesti dipertimbangkan. Proses adalah berbeza daripada utas Proses mempunyai ruang memori bebasnya sendiri dan tidak boleh menggunakan pembolehubah global untuk memindahkan data antara proses.
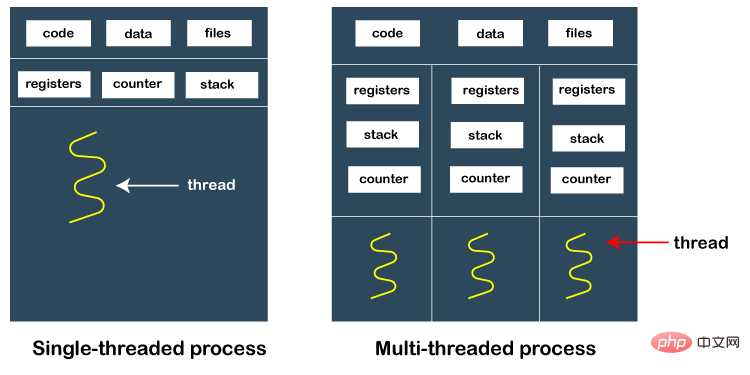
Dalam keperluan projek sebenar, selalunya terdapat pengiraan intensif atau tugas masa nyata, dan kadangkala sejumlah besar data, seperti gambar, objek besar, dsb. . perlu dipindahkan antara proses Jika data dipindahkan melalui siri fail atau antara muka rangkaian, sukar untuk memenuhi keperluan masa nyata Menggunakan redis, atau pakej baris gilir mesej pihak ketiga, rabbitMQ akan merumitkan sistem tersebut.
Modul berbilang pemprosesan Python itu sendiri menyediakan pelbagai kaedah komunikasi antara proses yang sangat cekap seperti mekanisme mesej, mekanisme penyegerakan dan memori kongsi.
Memahami dan menguasai penggunaan pelbagai kaedah komunikasi antara proses python, serta mekanisme keselamatan, boleh membantu meningkatkan prestasi menjalankan program dengan sangat baik.
2. Pengenalan kepada pelbagai kaedah komunikasi antara proses
Kaedah utama komunikasi antara proses diringkaskan seperti berikut
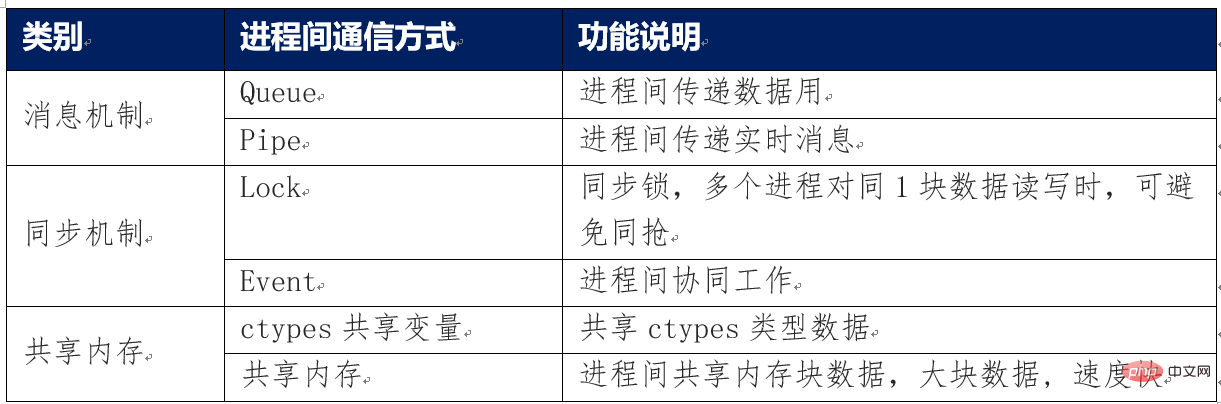
Mengenai antara proses Keselamatan ingatan komunikasi
Keselamatan ingatan bermakna pengecualian pembolehubah yang dikongsi mungkin berlaku antara berbilang proses disebabkan oleh rampasan serentak, pemusnahan tidak sengaja, dsb.
Objek Baris Gilir, Paip, Kunci dan Peristiwa yang disediakan oleh modul Multiprocessing semuanya telah melaksanakan mekanisme keselamatan komunikasi antara proses.
Jika anda menggunakan memori yang dikongsi untuk berkomunikasi, anda perlu menjejak dan memusnahkan pembolehubah memori dikongsi ini sendiri dalam kod, jika tidak, ia mungkin akan ditangkap atau tidak dimusnahkan seperti biasa. Menyebabkan keabnormalan sistem. Melainkan pembangun sangat jelas tentang ciri penggunaan memori kongsi, tidak disyorkan untuk menggunakan memori kongsi ini secara langsung, tetapi menggunakan memori kongsi melalui pengurus Pengurus.
Pengurus Pengurus Memori
Pemprosesan berbilang menyediakan kelas Pengurus pengurus memori, yang boleh menyelesaikan secara seragam isu keselamatan memori komunikasi proses dan boleh menambah pelbagai data dikongsi kepada pengurus, termasuk senarai , dict, Queue, Lock, Event, Shared Memory, dsb., dikesan dan dimusnahkan secara seragam.
3. Komunikasi mekanisme mesej
1) Kaedah Komunikasi Paip
adalah serupa dengan saluran soket ringkas dalam 1, kedua-dua hujungnya boleh menghantar dan menerima mesej.
Kaedah pembinaan objek paip:
parent_conn, child_conn = Pipe(duplex=True/False)
Penerangan parameter
dupleks=Benar, saluran paip ialah komunikasi dua hala
dupleks=Salah, saluran paip adalah komunikasi sehala, hanya child_conn boleh menghantar mesej, dan parent_conn hanya boleh menerima mesej.
Kod contoh:
from multiprocessing import Process, Pipe
def myfunction(conn):
conn.send(['hi!! I am Python'])
conn.close()
if __name__ == '__main__':
parent_conn, child_conn = Pipe()
p = Process(target=myfunction, args=(child_conn,))
p.start()
print (parent_conn.recv() )
p.join()2) Kaedah komunikasi Barisan Gilir Mesej
Kelas Berbilang Pemprosesan diubah suai pada versi gilir python 3.0 mudah untuk melaksanakan pemindahan data antara pengeluar dan pengirim mesej, dan modul Queue Multiprocessing melaksanakan mekanisme keselamatan kunci.
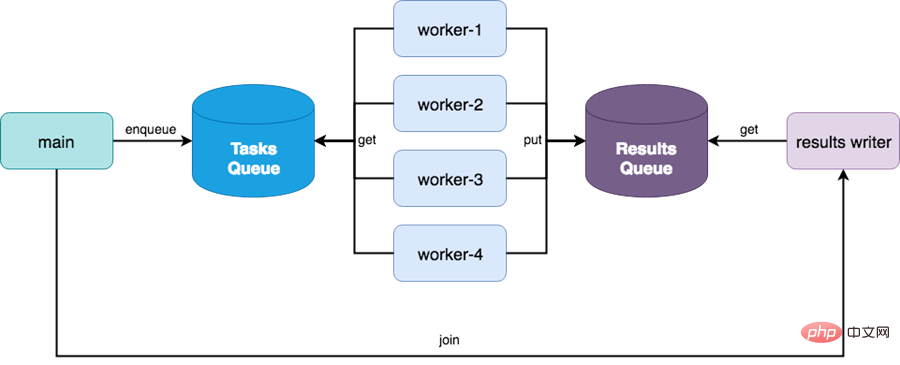
Modul giliran menyediakan sejumlah 3 jenis baris gilir.
(1) Barisan FIFO, masuk dahulu keluar dahulu,
class queue.Queue(maxsize=0)
(2) baris gilir LIFO, lepas masuk dulu keluar, sebenarnya tindanan
class queue.LifoQueue(maxsize=0)
(3 ) Dengan baris gilir keutamaan, nilai masukan keutamaan terendah disenaraikan dahulu
class queue.PriorityQueue(maxsize=0)
Kaedah utama Multiprocessing.Queue class:
| method | Description |
|---|---|
| queue.qsize() | 返回队列长度 |
| queue.full() | 队列满,返回 True, 否则返回False |
| queue.empty() | 队列空,返回 True, 否则返回False |
| queue.put(item) | 将数据写入队列 |
| queue.get() | 将数据抛出队列 , |
| queue.put_nowait(item), queue.get_nowait() | 无等待写入或抛出 |
说明:
put(), get() 是阻塞方法, 而put_notwait(), get_nowait()是非阻塞方法。
Multiprocessing 的Queue类没有提供Task_done, join方法
Queue模块的其它队列类:
(1) SimpleQueue
简洁版的FIFO队列, 适事简单场景使用
(2) JoinableQueue子类
Python 3.5 后新增的 Queue的子类,拥有 task_done(), join() 方法
task_done()表示,最近读出的1个任务已经完成。
join()阻塞队列,直到queue中的所有任务都已完成。
producer – consumer 场景,使用Queue的示例
import multiprocessing
def producer(numbers, q):
for x in numbers:
if x % 2 == 0:
if q.full():
print("queue is full")
break
q.put(x)
print(f"put {x} in queue by producer")
return None
def consumer(q):
while not q.empty():
print(f"take data {q.get()} from queue by consumer")
return None
if __name__ == "__main__":
# 设置1个queue对象,最大长度为5
qu = multiprocessing.Queue(maxsize=5,)
# 创建producer子进程,把queue做为其中1个参数传给它,该进程负责写
p5 = multiprocessing.Process(
name="producer-1",
target=producer,
args=([random.randint(1, 100) for i in range(0, 10)], qu)
)
p5.start()
p5.join()
#创建consumer子进程,把queue做为1个参数传给它,该进程中队列中读
p6 = multiprocessing.Process(
name="consumer-1",
target=consumer,
args=(qu,)
)
p6.start()
p6.join()
print(qu.qsize())4、同步机制通信
(1) 进程间同步锁 – Lock
Multiprocessing也提供了与threading 类似的同步锁机制,确保某个时刻只有1个子进程可以访问某个资源或执行某项任务, 以避免同抢。
例如:多个子进程同时访问数据库表时,如果没有同步锁,用户A修改1条数据后,还未提交,此时,用户B也进行了修改,可以预见,用户A提交的将是B个修改的数据。
添加了同步锁,可以确保同时只有1个子进程能够进行写入数据库与提交操作。
如下面的示例,同时只有1个进程可以执行打印操作。
from multiprocessing import Process, Lock
def f(l, i):
l.acquire()
try:
print('hello world', i)
finally:
l.release()
if __name__ == '__main__':
lock = Lock()
for num in range(10):
Process(target=f, args=(lock, num)).start()(2) 子进程间协调机制 – Event
Event 机制的工作原理:
1个event 对象实例管理着1个 flag标记, 可以用set()方法将其置为true, 用clear()方法将其置为false, 使用wait()将阻塞当前子进程,直至flag被置为true.
这样由1个进程通过event flag 就可以控制、协调各子进程运行。
Event object的使用方法:
1)主函数: 创建1个event 对象, flag = multiprocessing.Event() , 做为参数传给各子进程
2) 子进程A: 不受event影响,通过event 控制其它进程的运行
o 先clear(),将event 置为False, 占用运行权.
o 完成工作后,用set()把flag置为True。
3) 子进程B, C: 受event 影响
o 设置 wait() 状态,暂停运行
o 直到flag重新变为True,恢复运行
主要方法:
set(), clear()设置 True/False,
wait() 使进程等待,直到flag被改为true.
is_set(), Return True if and only if the internal flag is true.
验证进程间通信 – Event
import multiprocessing
import time
import random
def joo_a(q, ev):
print("subprocess joo_a start")
if not ev.is_set():
ev.wait()
q.put(random.randint(1, 100))
print("subprocess joo_a ended")
def joo_b(q, ev):
print("subprocess joo_b start")
ev.clear()
time.sleep(2)
q.put(random.randint(200, 300))
ev.set()
print("subprocess joo_b ended")
def main_event():
qu = multiprocessing.Queue()
ev = multiprocessing.Event()
sub_a = multiprocessing.Process(target=joo_a, args=(qu, ev))
sub_b = multiprocessing.Process(target=joo_b, args=(qu, ev,))
sub_a.start()
sub_b.start()
# ev.set()
sub_a.join()
sub_b.join()
while not qu.empty():
print(qu.get())
if __name__ == "__main__":
main_event()5、共享内存方式通信
(1) 共享变量
子进程之间共存内存变量,要用 multiprocessing.Value(), Array() 来定义变量。 实际上是ctypes 类型,由multiprocessing.sharedctypes模块提供相关功能
注意 使用 share memory 要考虑同抢等问题,释放等问题,需要手工实现。因此在使用共享变量时,建议使用Manager管程来管理这些共享变量。
def func(num):
num.value=10.78 #子进程改变数值的值,主进程跟着改变
if __name__=="__main__":
num = multiprocessing.Value("d", 10.0)
# d表示数值,主进程与子进程可共享这个变量。
p=multiprocessing.Process(target=func,args=(num,))
p.start()
p.join()
print(num.value)进程之间共享数据(数组型):
import multiprocessing
def func(num):
num[2]=9999 #子进程改变数组,主进程跟着改变
if __name__=="__main__":
num=multiprocessing.Array("i",[1,2,3,4,5])
p=multiprocessing.Process(target=func,args=(num,))
p.start()
p.join()
print(num[:])(2) 共享内存 Shared_memory
如果进程间需要共享对象数据,或共享内容,数据较大,multiprocessing 提供了SharedMemory类来实现进程间实时通信,不需要通过发消息,读写磁盘文件来实现,速度更快。
注意:直接使用SharedMemory 存在着同抢、泄露隐患,应通过SharedMemory Manager 管程类来使用, 以确保内存安全。
创建共享内存区:
multiprocessing.shared_memory.SharedMemory(name=none, create=False, size=0)
方法:
父进程创建shared_memory 后,子进程可以使用它,当不再需要后,使用close(), 删除使用unlink()方法
相关属性:
获取内存区内容: shm.buf
获取内存区名称: shm.name
获取内存区字节数: shm.size
示例:
>>> from multiprocessing import shared_memory >>> shm_a = shared_memory.SharedMemory(create=True, size=10) >>> type(shm_a.buf) <class 'memoryview'> >>> buffer = shm_a.buf >>> len(buffer) 10 >>> buffer[:4] = bytearray([22, 33, 44, 55]) # Modify multiple at once >>> buffer[4] = 100 # Modify single byte at a time >>> # Attach to an existing shared memory block >>> shm_b = shared_memory.SharedMemory(shm_a.name) >>> import array >>> array.array('b', shm_b.buf[:5]) # Copy the data into a new array.array array('b', [22, 33, 44, 55, 100]) >>> shm_b.buf[:5] = b'howdy' # Modify via shm_b using bytes >>> bytes(shm_a.buf[:5]) # Access via shm_a b'howdy' >>> shm_b.close() # Close each SharedMemory instance >>> shm_a.close() >>> shm_a.unlink() # Call unlink only once to release the shared memory
3) ShareableList 共享列表
sharedMemory类还提供了1个共享列表类型,这样就更方便了,进程间可以直接共享python强大的列表
构建方法:
multiprocessing.shared_memory.ShareableList(sequence=None, *, name=None)
from multiprocessing import shared_memory >>> a = shared_memory.ShareableList(['howdy', b'HoWdY', -273.154, 100, None, True, 42]) >>> [ type(entry) for entry in a ] [<class 'str'>, <class 'bytes'>, <class 'float'>, <class 'int'>, <class 'NoneType'>, <class 'bool'>, <class 'int'>] >>> a[2] -273.154 >>> a[2] = -78.5 >>> a[2] -78.5 >>> a[2] = 'dry ice' # Changing data types is supported as well >>> a[2] 'dry ice' >>> a[2] = 'larger than previously allocated storage space' Traceback (most recent call last): ... ValueError: exceeds available storage for existing str >>> a[2] 'dry ice' >>> len(a) 7 >>> a.index(42) 6 >>> a.count(b'howdy') 0 >>> a.count(b'HoWdY') 1 >>> a.shm.close() >>> a.shm.unlink() >>> del a # Use of a ShareableList after call to unlink() is unsupported b = shared_memory.ShareableList(range(5)) # In a first process >>> c = shared_memory.ShareableList(name=b.shm.name) # In a second process >>> c ShareableList([0, 1, 2, 3, 4], name='...') >>> c[-1] = -999 >>> b[-1] -999 >>> b.shm.close() >>> c.shm.close() >>> c.shm.unlink()
6、共享内存管理器Manager
Multiprocessing 提供了 Manager 内存管理器类,当调用1个Manager实例对象的start()方法时,会创建1个manager进程,其唯一目的就是管理共享内存, 避免出现进程间共享数据不同步,内存泄露等现象。
其原理如下:
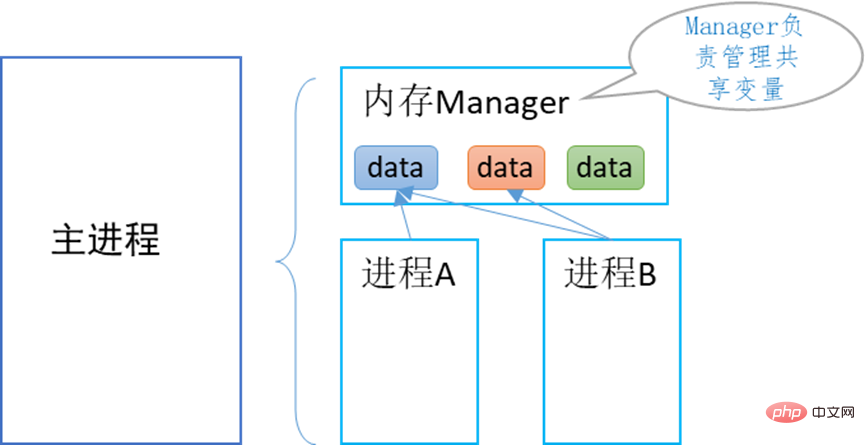
Manager管理器相当于提供了1个共享内存的服务,不仅可以被主进程创建的多个子进程使用,还可以被其它进程访问,甚至跨网络访问。本文仅聚焦于由单一主进程创建的各进程之间的通信。
1) Manager的主要数据结构
相关类:multiprocessing.Manager
子类有:
multiprocessing.managers.SharedMemoryManager
multiprocessing.managers.BaseManager
支持共享变量类型:
python基本类型 int, str, list, tuple, list
进程通信对象: Queue, Lock, Event,
Condition, Semaphore, Barrier ctypes类型: Value, Array
2) 使用步骤
1)创建管理器对象
snm = Manager() snm = SharedMemoryManager()
2)创建共享内存变量
新建list, dict
sl = snm.list(), snm.dict()
新建1块bytes共享内存变量,需要指定大小
sx = snm.SharedMemory(size)
新建1个共享列表变量,可用列表来初始化
sl = snm.ShareableList(sequence) 如 sl = smm.ShareableList([‘howdy', b'HoWdY', -273.154, 100, True])
新建1个queue, 使用multiprocessing 的Queue类型
snm = Manager() q = snm.Queue()
示例 :
from multiprocessing import Process, Manager
def f(d, l):
d[1] = '1'
d['2'] = 2
d[0.25] = None
l.reverse()
if __name__ == '__main__':
with Manager() as manager:
d = manager.dict()
l = manager.list(range(10))
p = Process(target=f, args=(d, l))
p.start()
p.join()
print(d)
print(l)将打印
{0.25: None, 1: '1', '2': 2}
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
3) 销毁共享内存变量
方法一:
调用snm.shutdown()方法,会自动调用每个内存块的unlink()方法释放内存。或者 snm.close()
方法二:
使用with语句,结束后会自动释放所有manager变量
>>> with SharedMemoryManager() as smm: ... sl = smm.ShareableList(range(2000)) ... # Divide the work among two processes, storing partial results in sl ... p1 = Process(target=do_work, args=(sl, 0, 1000)) ... p2 = Process(target=do_work, args=(sl, 1000, 2000)) ... p1.start() ... p2.start() # A multiprocessing.Pool might be more efficient ... p1.join() ... p2.join() # Wait for all work to complete in both processes ... total_result = sum(sl) # Consolidate the partial results now in sl
4) 向管理器注册自定义类型
managers的子类BaseManager提供register()方法,支持注册自定义数据类型。如下例,注册1个自定义MathsClass类,并生成实例。
from multiprocessing.managers import BaseManager
class MathsClass:
def add(self, x, y):
return x + y
def mul(self, x, y):
return x * y
class MyManager(BaseManager):
pass
MyManager.register('Maths', MathsClass)
if __name__ == '__main__':
with MyManager() as manager:
maths = manager.Maths()
print(maths.add(4, 3)) # prints 7
print(maths.mul(7, 8))Atas ialah kandungan terperinci Bagaimana untuk menggunakan multiprocessing untuk melaksanakan komunikasi antara proses dalam Python?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python mempunyai kelebihan dan kekurangan mereka sendiri, dan pilihannya bergantung kepada keperluan projek dan keutamaan peribadi. 1.PHP sesuai untuk pembangunan pesat dan penyelenggaraan aplikasi web berskala besar. 2. Python menguasai bidang sains data dan pembelajaran mesin.
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Latihan yang cekap model pytorch pada sistem CentOS memerlukan langkah -langkah, dan artikel ini akan memberikan panduan terperinci. 1. Penyediaan Persekitaran: Pemasangan Python dan Ketergantungan: Sistem CentOS biasanya mempamerkan python, tetapi versi mungkin lebih tua. Adalah disyorkan untuk menggunakan YUM atau DNF untuk memasang Python 3 dan menaik taraf PIP: Sudoyumupdatepython3 (atau SudodnfupdatePython3), pip3install-upgradepip. CUDA dan CUDNN (Percepatan GPU): Jika anda menggunakan Nvidiagpu, anda perlu memasang Cudatool
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python dan JavaScript mempunyai kelebihan dan kekurangan mereka sendiri dari segi komuniti, perpustakaan dan sumber. 1) Komuniti Python mesra dan sesuai untuk pemula, tetapi sumber pembangunan depan tidak kaya dengan JavaScript. 2) Python berkuasa dalam bidang sains data dan perpustakaan pembelajaran mesin, sementara JavaScript lebih baik dalam perpustakaan pembangunan dan kerangka pembangunan depan. 3) Kedua -duanya mempunyai sumber pembelajaran yang kaya, tetapi Python sesuai untuk memulakan dengan dokumen rasmi, sementara JavaScript lebih baik dengan MDNWebDocs. Pilihan harus berdasarkan keperluan projek dan kepentingan peribadi.
 Cara Memilih Versi PyTorch Di Bawah Centos
Apr 14, 2025 pm 02:51 PM
Cara Memilih Versi PyTorch Di Bawah Centos
Apr 14, 2025 pm 02:51 PM
Apabila memilih versi pytorch di bawah CentOS, faktor utama berikut perlu dipertimbangkan: 1. Keserasian versi CUDA Sokongan GPU: Jika anda mempunyai NVIDIA GPU dan ingin menggunakan pecutan GPU, anda perlu memilih pytorch yang menyokong versi CUDA yang sepadan. Anda boleh melihat versi CUDA yang disokong dengan menjalankan arahan NVIDIA-SMI. Versi CPU: Jika anda tidak mempunyai GPU atau tidak mahu menggunakan GPU, anda boleh memilih versi CPU PyTorch. 2. Pytorch versi python
 Cara Memasang Nginx di CentOs
Apr 14, 2025 pm 08:06 PM
Cara Memasang Nginx di CentOs
Apr 14, 2025 pm 08:06 PM
CentOS Memasang Nginx memerlukan mengikuti langkah-langkah berikut: memasang kebergantungan seperti alat pembangunan, pcre-devel, dan openssl-devel. Muat turun Pakej Kod Sumber Nginx, unzip dan menyusun dan memasangnya, dan tentukan laluan pemasangan sebagai/usr/local/nginx. Buat pengguna Nginx dan kumpulan pengguna dan tetapkan kebenaran. Ubah suai fail konfigurasi nginx.conf, dan konfigurasikan port pendengaran dan nama domain/alamat IP. Mulakan perkhidmatan Nginx. Kesalahan biasa perlu diberi perhatian, seperti isu ketergantungan, konflik pelabuhan, dan kesilapan fail konfigurasi. Pengoptimuman prestasi perlu diselaraskan mengikut keadaan tertentu, seperti menghidupkan cache dan menyesuaikan bilangan proses pekerja.
 Cara melakukan pra -proses data dengan pytorch di centOs
Apr 14, 2025 pm 02:15 PM
Cara melakukan pra -proses data dengan pytorch di centOs
Apr 14, 2025 pm 02:15 PM
Dengan cekap memproses data pitorch pada sistem CentOS, langkah-langkah berikut diperlukan: Pemasangan Ketergantungan: Kemas kini pertama sistem dan pasang Python3 dan PIP: Sudoyumupdate-iSudoyumStallpython3-Isudoyumstallpython3-y Konfigurasi Persekitaran Maya (disyorkan): Gunakan Conda untuk membuat dan mengaktifkan persekitaran maya baru, contohnya: condacreate-n
