
 Peranti teknologi
AI
Memperkenalkan lapan penyelesaian model besar sumber terbuka dan percuma kerana ChatGPT dan Bard terlalu mahal.
Peranti teknologi
AI
Memperkenalkan lapan penyelesaian model besar sumber terbuka dan percuma kerana ChatGPT dan Bard terlalu mahal.
Memperkenalkan lapan penyelesaian model besar sumber terbuka dan percuma kerana ChatGPT dan Bard terlalu mahal.

1.LLaMA
Projek LLaMA mengandungi satu set model bahasa asas, bersaiz antara 7 bilion hingga 65 bilion parameter. Model ini dilatih menggunakan berjuta-juta token, dan ia dilatih sepenuhnya pada set data yang tersedia untuk umum. Hasilnya, LLaMA-13B mengatasi GPT-3 (175B), manakala LLaMA-65B menunjukkan prestasi yang sama dengan model terbaik seperti Chinchilla-70B dan PaLM-540B.
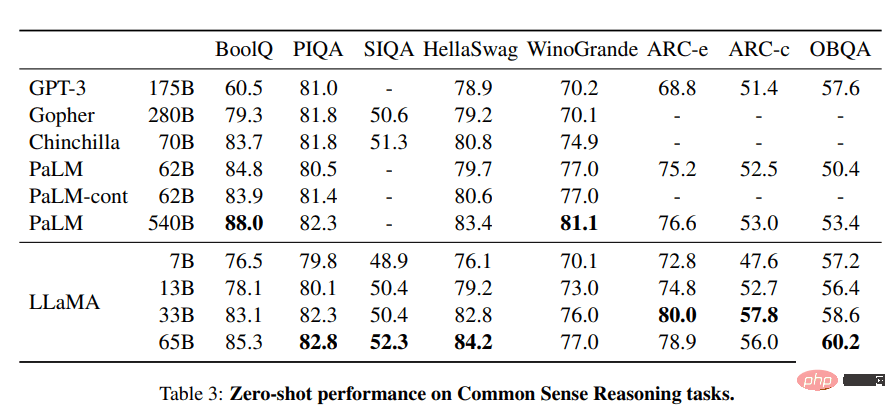
Imej daripada LLaMA
Sumber:
- Kertas penyelidikan: “LLaMA: Model Bahasa Asas Terbuka dan Cekap (arxiv. org)" [https://arxiv.org/abs/2302.13971]
- GitHub: facebookresearch/llama [https://github.com/facebookresearch/llama]
- Demo: Baize Lora 7B [https://huggingface.co/spaces/project-baize/Baize-7B]
2.Alpaca
Alpaca Stanford mendakwa ia boleh bersaing dengan ChatGPT dan sesiapa sahaja boleh menyalinnya dengan harga kurang daripada $600. Alpaca 7B diperhalusi daripada model LLaMA 7B pada demonstrasi ikut arahan 52K.
Kandungan latihan|Gambar dari Stanford University CRFM
Sumber:
- Blog: Stanford CRFM. [https://crfm.stanford.edu/2023/03/13/alpaca.html]
- GitHub: tatsu-lab/stanford_alpaca [https://github.com/tatsu-lab/stanford_alpaca]
- Demo: Alpaca-LoRA (demo rasmi telah hilang, ini adalah persembahan model Alpaca) [https://huggingface.co/spaces/tloen/alpaca-lora]
3.Vicuna
Vicuna diperhalusi berdasarkan model LLaMA pada perbualan kongsi pengguna yang dikumpulkan daripada ShareGPT. Model Vicuna-13B telah mencapai lebih daripada 90% kualiti OpenAI ChatGPT dan Google Bard. Ia juga mengatasi model LLaMA dan Stanford Alpaca 90% pada masa itu. Kos untuk melatih Vicuna adalah lebih kurang $300.
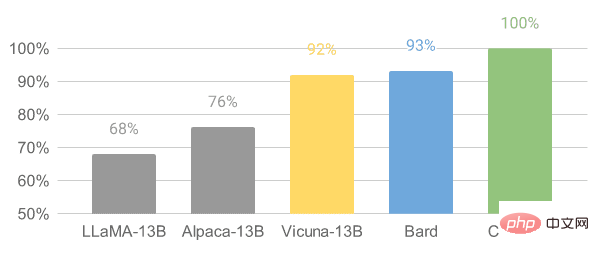
Imej daripada Vicuna
Sumber:
- Catatan blog: “Vicuna: Chatbot Sumber Terbuka Mengesankan GPT-4 dengan 90%* Kualiti ChatGPT” [https://vicuna.lmsys.org/]
- GitHub: lm-sys/FastChat [https://github.com/lm-sys/FastChat#fine-tuning ]
- Demo: FastChat (lmsys.org) [https://chat.lmsys.org/]
4.OpenChatKit
OpenChatKit: Alternatif sumber terbuka kepada ChatGPT, kit alat lengkap untuk mencipta chatbots. Ia menyediakan model bahasa yang besar untuk melatih pelarasan arahan pengguna sendiri, model yang diperhalusi, sistem dapatkan semula berskala untuk mengemas kini respons bot dan arahan untuk menapis semakan bot bagi soalan.
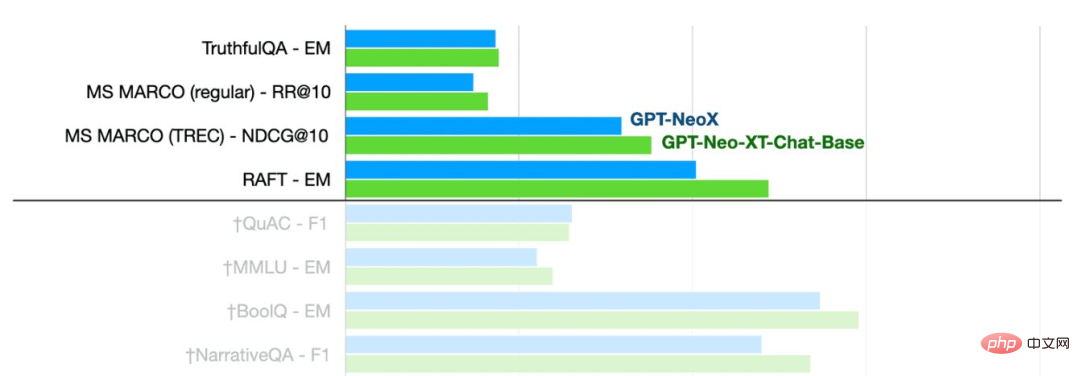
Gambar dari BERSAMA
Seperti yang anda lihat, model GPT-NeoXT-Chat-Base-20B berprestasi lebih baik daripada mod Asas GPT-NoeX.
Sumber:
- Catatan blog: "Mengumumkan OpenChatKit" - BERSAMA [https://www.together.xyz/blog/openchatkit]
- GitHub: togethercomputer /OpenChatKit [https://github.com/togethercomputer/OpenChatKit]
- Demo: OpenChatKit [https://huggingface.co/spaces/togethercomputer/OpenChatKit]
- Kad Model: togethercomputer/ GPT-NeoXT-Chat-Base-20B [https://huggingface.co/togethercomputer/GPT-NeoXT-Chat-Base-20B]
5.GPT4ALL
GPT4ALL ialah projek dipacu komuniti dan dilatih pada korpus besar interaksi tambahan, termasuk kod, cerita, perihalan dan perbualan berbilang pusingan. Pasukan itu menyediakan set data, berat model, proses pengurusan data dan kod latihan untuk memudahkan sumber terbuka. Selain itu, mereka mengeluarkan versi model 4-bit terkuantisasi yang boleh dijalankan pada komputer riba. Anda juga boleh menggunakan klien Python untuk menjalankan inferens model.
Imej daripada GPT4ALL
Sumber:
- Laporan Teknikal: GPT4All [https://s3.amazonaws.com/static.nomic.ai/gpt4all/2023_GPT4All_Technical_Report.pdf]
- GitHub: nomic-ai/gpt4al [https:/ /github.com/nomic-ai/gpt4all]
- Demo: GPT4All (tidak rasmi). [https://huggingface.co/spaces/rishiraj/GPT4All]
- Kad model: nomic-ai/gpt4all-lora · Muka Memeluk [https://huggingface.co/nomic-ai/gpt4all-lora ]
6.Raven RWKV
Raven RWKV 7B ialah robot sembang sumber terbuka yang digerakkan oleh model bahasa RWKV untuk menjana Keputusan adalah serupa dengan ChatGPT. Model ini menggunakan RNN, yang boleh memadankan pengubah dari segi kualiti dan kebolehskalaan, sambil lebih pantas dan menjimatkan VRAM. Raven diperhalusi pada Stanford Alpaca, kod-alpaca dan lebih banyak set data.
Imej daripada Raven RWKV 7B
Sumber:
- GitHub: BlinkDL/ChatRWKV [https://github.com /BlinkDL/ChatRWKV]
- Demo: Raven RWKV 7B [https://huggingface.co/spaces/BlinkDL/Raven-RWKV-7B]
- Kad model: BlinkDL/rwkv-4- gagak [https://huggingface.co/BlinkDL/rwkv-4-raven]
7.OPT
OPT: Model bahasa Transformer Pra-terlatih Terbuka tidak sekuat ChatGPT, tetapi ia menunjukkan keupayaan yang sangat baik dalam pembelajaran sifar dan beberapa pukulan dan analisis bias stereotaip. Ia juga boleh disepadukan dengan Alpa, Colossal-AI, CTranslate2 dan FasterTransformer untuk hasil yang lebih baik. NOTA: Sebab ia membuat senarai adalah popularitinya, kerana ia mempunyai 624,710 muat turun sebulan dalam kategori penjanaan teks.
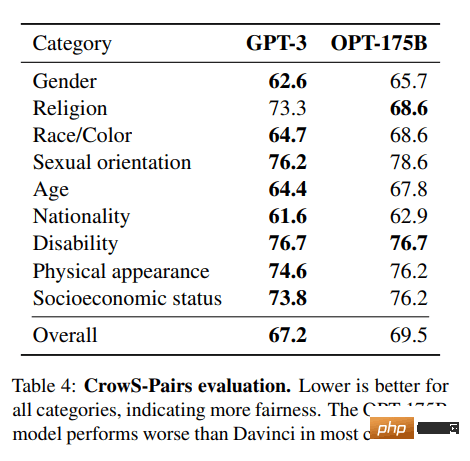
Imej daripada (arxiv.org)
Sumber:
- Kertas penyelidikan: "OPT: Buka Transformer Pra-latihan Model Bahasa (arxiv.org)” [https://arxiv.org/abs/2205.01068]
- GitHub: facebookresearch/metaseq [https://github.com/facebookresearch/metaseq]
- Demo: Tera Air untuk LLM [https://huggingface.co/spaces/tomg-group-umd/lm-watermarking]
- Kad model: facebook/opt-1.3b [https://huggingface. co/facebook/opt-1.3b]
8.Flan-T5-XXL
Flan-T5-XXL in The Model T5 diperhalusi pada set data yang dinyatakan dalam bentuk arahan. Penalaan halus arahan telah meningkatkan prestasi pelbagai kelas model seperti PaLM, T5 dan U-PaLM. Model Flan-T5-XXL diperhalusi pada lebih daripada 1000 tugasan tambahan, meliputi lebih banyak bahasa.
Imej daripada Flan-T5-XXL
Sumber:
- Kertas penyelidikan: "Menskalakan Model Bahasa Pengajaran-Ditala Halus ” [https://arxiv.org/pdf/2210.11416.pdf]
- GitHub: google-research/t5x [https://github.com/google-research/t5x]
- Demo: Penstriman Llm Sembang [https://huggingface.co/spaces/olivierdehaene/chat-llm-streaming]
- Kad model: google/flan-t5-xxl [https://huggingface.co/google /flan-t5-xxl?text=Q%3A+%28+Salah+atau+tidak+Salah+atau+Salah+%29+adalah%3F+A%3A+Biarkan%27s+berfikir+langkah+demi+langkah]
Ringkasan
Terdapat banyak model besar sumber terbuka untuk dipilih daripada 8 model besar yang lebih popular.
Atas ialah kandungan terperinci Memperkenalkan lapan penyelesaian model besar sumber terbuka dan percuma kerana ChatGPT dan Bard terlalu mahal.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Sepuluh alat anotasi teks percuma sumber terbuka yang disyorkan
Mar 26, 2024 pm 08:20 PM
Sepuluh alat anotasi teks percuma sumber terbuka yang disyorkan
Mar 26, 2024 pm 08:20 PM
Anotasi teks ialah kerja label atau teg yang sepadan dengan kandungan tertentu dalam teks. Tujuan utamanya adalah untuk memberikan maklumat tambahan kepada teks untuk analisis dan pemprosesan yang lebih mendalam, terutamanya dalam bidang kecerdasan buatan. Anotasi teks adalah penting untuk tugas pembelajaran mesin yang diawasi dalam aplikasi kecerdasan buatan. Ia digunakan untuk melatih model AI untuk membantu memahami maklumat teks bahasa semula jadi dengan lebih tepat dan meningkatkan prestasi tugasan seperti klasifikasi teks, analisis sentimen dan terjemahan bahasa. Melalui anotasi teks, kami boleh mengajar model AI untuk mengenali entiti dalam teks, memahami konteks dan membuat ramalan yang tepat apabila data baharu yang serupa muncul. Artikel ini terutamanya mengesyorkan beberapa alat anotasi teks sumber terbuka yang lebih baik. 1.LabelStudiohttps://github.com/Hu
 ChatGPT kini membenarkan pengguna percuma menjana imej dengan menggunakan DALL-E 3 dengan had harian
Aug 09, 2024 pm 09:37 PM
ChatGPT kini membenarkan pengguna percuma menjana imej dengan menggunakan DALL-E 3 dengan had harian
Aug 09, 2024 pm 09:37 PM
DALL-E 3 telah diperkenalkan secara rasmi pada September 2023 sebagai model yang jauh lebih baik daripada pendahulunya. Ia dianggap sebagai salah satu penjana imej AI terbaik setakat ini, mampu mencipta imej dengan perincian yang rumit. Walau bagaimanapun, semasa pelancaran, ia adalah tidak termasuk
 15 alat anotasi imej percuma sumber terbuka disyorkan
Mar 28, 2024 pm 01:21 PM
15 alat anotasi imej percuma sumber terbuka disyorkan
Mar 28, 2024 pm 01:21 PM
Anotasi imej ialah proses mengaitkan label atau maklumat deskriptif dengan imej untuk memberi makna dan penjelasan yang lebih mendalam kepada kandungan imej. Proses ini penting untuk pembelajaran mesin, yang membantu melatih model penglihatan untuk mengenal pasti elemen individu dalam imej dengan lebih tepat. Dengan menambahkan anotasi pada imej, komputer boleh memahami semantik dan konteks di sebalik imej, dengan itu meningkatkan keupayaan untuk memahami dan menganalisis kandungan imej. Anotasi imej mempunyai pelbagai aplikasi, meliputi banyak bidang, seperti penglihatan komputer, pemprosesan bahasa semula jadi dan model penglihatan graf Ia mempunyai pelbagai aplikasi, seperti membantu kenderaan dalam mengenal pasti halangan di jalan raya, dan membantu dalam proses. pengesanan dan diagnosis penyakit melalui pengecaman imej perubatan. Artikel ini terutamanya mengesyorkan beberapa alat anotasi imej sumber terbuka dan percuma yang lebih baik. 1.Makesen
 Disyorkan: Projek pengesanan dan pengecaman muka sumber terbuka JS yang sangat baik
Apr 03, 2024 am 11:55 AM
Disyorkan: Projek pengesanan dan pengecaman muka sumber terbuka JS yang sangat baik
Apr 03, 2024 am 11:55 AM
Teknologi pengesanan dan pengecaman muka adalah teknologi yang agak matang dan digunakan secara meluas. Pada masa ini, bahasa aplikasi Internet yang paling banyak digunakan ialah JS Melaksanakan pengesanan muka dan pengecaman pada bahagian hadapan Web mempunyai kelebihan dan kekurangan berbanding dengan pengecaman muka bahagian belakang. Kelebihan termasuk mengurangkan interaksi rangkaian dan pengecaman masa nyata, yang sangat memendekkan masa menunggu pengguna dan meningkatkan pengalaman pengguna termasuk: terhad oleh saiz model, ketepatannya juga terhad. Bagaimana untuk menggunakan js untuk melaksanakan pengesanan muka di web? Untuk melaksanakan pengecaman muka di Web, anda perlu biasa dengan bahasa dan teknologi pengaturcaraan yang berkaitan, seperti JavaScript, HTML, CSS, WebRTC, dll. Pada masa yang sama, anda juga perlu menguasai visi komputer yang berkaitan dan teknologi kecerdasan buatan. Perlu diingat bahawa kerana reka bentuk bahagian Web
 Dokumen berbilang modal Alibaba 7B memahami model besar memenangi SOTA baharu
Apr 02, 2024 am 11:31 AM
Dokumen berbilang modal Alibaba 7B memahami model besar memenangi SOTA baharu
Apr 02, 2024 am 11:31 AM
SOTA baharu untuk keupayaan memahami dokumen multimodal! Pasukan Alibaba mPLUG mengeluarkan kerja sumber terbuka terkini mPLUG-DocOwl1.5, yang mencadangkan satu siri penyelesaian untuk menangani empat cabaran utama pengecaman teks imej resolusi tinggi, pemahaman struktur dokumen am, arahan mengikut dan pengenalan pengetahuan luaran. Tanpa berlengah lagi, mari kita lihat kesannya dahulu. Pengecaman satu klik dan penukaran carta dengan struktur kompleks ke dalam format Markdown: Carta gaya berbeza tersedia: Pengecaman dan kedudukan teks yang lebih terperinci juga boleh dikendalikan dengan mudah: Penjelasan terperinci tentang pemahaman dokumen juga boleh diberikan: Anda tahu, "Pemahaman Dokumen " pada masa ini Senario penting untuk pelaksanaan model bahasa yang besar. Terdapat banyak produk di pasaran untuk membantu pembacaan dokumen. Sesetengah daripada mereka menggunakan sistem OCR untuk pengecaman teks dan bekerjasama dengan LLM untuk pemprosesan teks.
 Bagaimana untuk memasang chatgpt pada telefon bimbit
Mar 05, 2024 pm 02:31 PM
Bagaimana untuk memasang chatgpt pada telefon bimbit
Mar 05, 2024 pm 02:31 PM
Langkah pemasangan: 1. Muat turun perisian ChatGTP dari laman web rasmi ChatGTP atau kedai mudah alih 2. Selepas membukanya, dalam antara muka tetapan, pilih bahasa sebagai bahasa Cina 3. Dalam antara muka permainan, pilih permainan mesin manusia dan tetapkan Spektrum bahasa Cina; 4 Selepas memulakan, masukkan arahan dalam tetingkap sembang untuk berinteraksi dengan perisian.
 Baru dikeluarkan! Model sumber terbuka untuk menghasilkan imej gaya anime dengan satu klik
Apr 08, 2024 pm 06:01 PM
Baru dikeluarkan! Model sumber terbuka untuk menghasilkan imej gaya anime dengan satu klik
Apr 08, 2024 pm 06:01 PM
Izinkan saya memperkenalkan kepada anda projek sumber terbuka AIGC terkini-AnimagineXL3.1. Projek ini adalah lelaran terkini model teks-ke-imej bertema anime, yang bertujuan untuk menyediakan pengguna pengalaman penjanaan imej anime yang lebih optimum dan berkuasa. Dalam AnimagineXL3.1, pasukan pembangunan menumpukan pada mengoptimumkan beberapa aspek utama untuk memastikan model mencapai tahap prestasi dan kefungsian yang baharu. Pertama, mereka mengembangkan data latihan untuk memasukkan bukan sahaja data watak permainan daripada versi sebelumnya, tetapi juga data daripada banyak siri anime terkenal lain ke dalam set latihan. Langkah ini memperkayakan pangkalan pengetahuan model, membolehkannya memahami pelbagai gaya dan watak anime dengan lebih lengkap. AnimagineXL3.1 memperkenalkan set teg khas dan estetika baharu
 Satu kad menjalankan Llama 70B lebih pantas daripada dua kad, Microsoft hanya meletakkan FP6 ke dalam A100 |
Apr 29, 2024 pm 04:55 PM
Satu kad menjalankan Llama 70B lebih pantas daripada dua kad, Microsoft hanya meletakkan FP6 ke dalam A100 |
Apr 29, 2024 pm 04:55 PM
FP8 dan ketepatan pengiraan titik terapung yang lebih rendah bukan lagi "paten" H100! Lao Huang mahu semua orang menggunakan INT8/INT4, dan pasukan Microsoft DeepSpeed memaksa diri mereka menjalankan FP6 pada A100 tanpa sokongan rasmi daripada Nvidia. Keputusan ujian menunjukkan bahawa kaedah baharu TC-FPx FP6 kuantisasi pada A100 adalah hampir atau kadangkala lebih pantas daripada INT4, dan mempunyai ketepatan yang lebih tinggi daripada yang terakhir. Selain itu, terdapat juga sokongan model besar hujung ke hujung, yang telah bersumberkan terbuka dan disepadukan ke dalam rangka kerja inferens pembelajaran mendalam seperti DeepSpeed. Keputusan ini juga mempunyai kesan serta-merta pada mempercepatkan model besar - di bawah rangka kerja ini, menggunakan satu kad untuk menjalankan Llama, daya pemprosesan adalah 2.65 kali lebih tinggi daripada dua kad. satu
